Chỉ mục cơ sở dữ liệu thực sự làm gì
Chỉ mục cơ sở dữ liệu là một cấu trúc tra cứu riêng giúp cơ sở dữ liệu tìm hàng nhanh hơn. Nó không phải là bản sao thứ hai của bảng. Hãy tưởng tượng giống như trang mục lục trong một cuốn sách: bạn dùng mục lục để nhảy tới chỗ gần đúng, rồi đọc trang cụ thể (hàng) bạn cần.
Không có chỉ mục, cơ sở dữ liệu thường chỉ có một lựa chọn an toàn: đọc qua nhiều hàng để kiểm tra hàng nào khớp truy vấn. Điều đó có thể ổn khi bảng chỉ có vài nghìn hàng. Khi bảng lớn lên tới hàng triệu hàng, “kiểm tra thêm hàng” chuyển thành nhiều lần đọc đĩa hơn, áp lực bộ nhớ tăng, và CPU phải làm nhiều hơn — vậy truy vấn từng cảm thấy tức thì bắt đầu chậm đi.
Những gì chỉ mục thay đổi (và không thay đổi)
Chỉ mục giảm lượng dữ liệu mà cơ sở dữ liệu phải kiểm tra để trả lời các câu hỏi như “tìm đơn hàng có ID 123” hoặc “lấy người dùng có email này.” Thay vì quét mọi thứ, cơ sở dữ liệu theo cấu trúc cô đọng thu hẹp tìm kiếm nhanh chóng.
Nhưng đánh chỉ mục không phải là giải pháp toàn năng. Một số truy vấn vẫn phải xử lý nhiều hàng (báo cáo rộng, bộ lọc chọn lọc thấp, tính toán tổng hợp nặng). Và chỉ mục có chi phí thực sự: tốn thêm dung lượng lưu trữ và làm chậm ghi, vì khi chèn hoặc cập nhật phải cập nhật cả chỉ mục.
Bạn sẽ học được gì trong hướng dẫn này
Bạn sẽ biết:
- tại sao tránh quét toàn bộ bảng là lợi thế tốc độ lớn
- cách các cấu trúc chỉ mục phổ biến (như B-tree) làm tra cứu nhanh
- truy vấn nào hưởng lợi nhất, và khi nào không
- cách chọn chỉ mục tổng hợp/không phủ và xác thực bằng EXPLAIN
- cách duy trì chỉ mục theo thời gian để hiệu suất không giảm dần âm thầm
Lợi thế tốc độ cốt lõi: tránh quét toàn bộ bảng
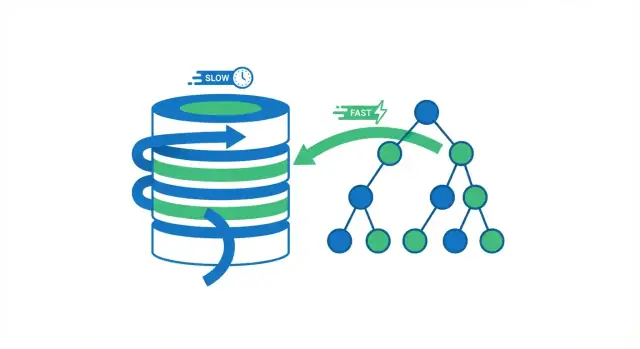
Khi cơ sở dữ liệu chạy một truy vấn, nó có hai lựa chọn rộng: quét toàn bộ bảng từng hàng, hoặc nhảy trực tiếp đến các hàng khớp. Hầu hết lợi ích của chỉ mục đến từ việc tránh đọc không cần thiết.
Quét toàn bộ bảng so với tra cứu bằng chỉ mục
Một quét toàn bộ bảng là đúng như tên gọi: cơ sở dữ liệu đọc mọi hàng, kiểm tra xem nó có khớp điều kiện WHERE hay không, rồi mới trả kết quả. Điều này chấp nhận được cho bảng nhỏ, nhưng nó chậm lại theo cách có thể dự đoán khi bảng tăng—càng nhiều hàng thì càng nhiều công việc.
Dùng chỉ mục, cơ sở dữ liệu thường tránh được việc phải đọc phần lớn các hàng. Thay vào đó, nó tham khảo chỉ mục trước (một cấu trúc cô đọng được xây dựng để tìm kiếm) để biết nơi các hàng khớp nằm, rồi chỉ đọc các hàng cụ thể đó.
Một phép so sánh đơn giản
Hãy tưởng tượng một cuốn sách. Nếu bạn muốn mọi trang đề cập “photosynthesis”, bạn có thể đọc toàn bộ cuốn sách (quét toàn bộ). Hoặc bạn có thể dùng mục lục, nhảy tới các trang được liệt kê và chỉ đọc các phần đó (tra cứu bằng chỉ mục). Cách thứ hai nhanh hơn vì bạn bỏ qua gần như tất cả các trang.
Tại sao đọc ít hơn thường có nghĩa là truy vấn nhanh hơn
Cơ sở dữ liệu tốn nhiều thời gian chờ đọc — đặc biệt khi dữ liệu chưa ở trong bộ nhớ. Cắt giảm số hàng (và trang) mà cơ sở dữ liệu phải chạm tới thường giảm:
- các lần đọc đĩa/SSD
- thời gian CPU để đánh giá bộ lọc
- áp lực bộ nhớ từ việc kéo dữ liệu không cần thiết vào cache
Khi nào lợi thế tốc độ xuất hiện
Chỉ mục giúp nhiều nhất khi dữ liệu lớn và mẫu truy vấn có tính chọn lọc (ví dụ, lấy 20 hàng khớp trong 10 triệu). Nếu truy vấn trả về hầu hết các hàng, hoặc bảng nhỏ đủ để nằm gọn trong bộ nhớ, quét toàn bộ có thể nhanh tương đương — hoặc còn nhanh hơn.
Cách các cấu trúc chỉ mục làm tra cứu nhanh
Chỉ mục hoạt động vì chúng tổ chức giá trị sao cho cơ sở dữ liệu có thể nhảy tới gần nơi bạn cần thay vì kiểm tra từng hàng.
Chỉ mục B-tree: con ngựa thồ mặc định
Cấu trúc chỉ mục phổ biến nhất trong SQL là B-tree (thường viết B-tree hoặc B+tree). Về mặt khái niệm:
- các giá trị được giữ có thứ tự
- chỉ mục được chia thành trang (chunks) trỏ tới các trang khác, và cuối cùng tới các hàng tương ứng
Bởi vì có thứ tự, B-tree rất tốt cho cả tìm chính xác (WHERE email = ...) và truy vấn phạm vi (WHERE created_at >= ... AND created_at < ...). Cơ sở dữ liệu có thể điều hướng tới vùng giá trị phù hợp rồi quét tiếp theo thứ tự.
“Logarithmic” nghĩa là gì (không cần toán)
Người ta nói tra cứu B-tree là “logarithmic”. Thực tế, điều đó có nghĩa: khi bảng tăng từ hàng nghìn lên hàng triệu hàng, số bước để tìm một giá trị tăng chậm, không tỉ lệ thuận. Thay vì “gấp đôi dữ liệu thì gấp đôi công việc”, nó giống kiểu “dữ liệu tăng rất nhiều chỉ thêm vài bước điều hướng”, vì cơ sở dữ liệu đi theo các con trỏ qua vài cấp độ trong cây.
Chỉ mục băm: nhanh cho so sánh chính xác (cũng có giới hạn)
Một số engine cũng cung cấp chỉ mục hash. Chúng rất nhanh cho các phép so sánh bằng vì giá trị được chuyển thành hash và dùng để tìm mục tương ứng trực tiếp.
Đổi lại: chỉ mục hash thường không giúp cho phạm vi hoặc quét theo thứ tự, và tính khả dụng/hành vi khác nhau giữa các cơ sở dữ liệu.
Chi tiết engine khác nhau, ý tưởng vẫn như cũ
PostgreSQL, MySQL/InnoDB, SQL Server và các hệ khác lưu và dùng chỉ mục khác nhau (kích thước trang, clustering, cột bao gồm, kiểm tra tầm nhìn). Nhưng khái niệm cốt lõi giống nhau: chỉ mục tạo ra một cấu trúc cô đọng, có thể điều hướng, giúp cơ sở dữ liệu xác định hàng khớp với ít công việc hơn nhiều so với quét toàn bộ bảng.
Các truy vấn hưởng lợi nhiều nhất từ chỉ mục
Chỉ mục không làm nhanh “SQL” nói chung — chúng làm nhanh các mẫu truy cập cụ thể. Khi chỉ mục khớp cách truy vấn lọc, join hoặc sắp xếp, cơ sở dữ liệu có thể nhảy thẳng tới các hàng liên quan thay vì đọc cả bảng.
Các mẫu truy vấn thân thiện với chỉ mục nhất
1) Bộ lọc WHERE (đặc biệt trên cột có tính chọn lọc)
Nếu truy vấn của bạn thường thu một bảng lớn xuống một tập nhỏ hàng, chỉ mục thường là chỗ đầu tiên nên xem. Ví dụ kinh điển là tìm người dùng theo định danh.
Không có chỉ mục trên users.email, cơ sở dữ liệu có thể phải quét mọi hàng:
SELECT * FROM users WHERE email = '[email protected]';
Với chỉ mục trên email, nó có thể xác định hàng(s) khớp nhanh và dừng lại.
2) Khóa JOIN (foreign keys và các khóa được tham chiếu)
Join là nơi “những bất lợi nhỏ” biến thành chi phí lớn. Nếu bạn join orders.user_id với users.id, việc đánh chỉ mục các cột join (thường là orders.user_id và khóa chính users.id) giúp cơ sở dữ liệu ghép các hàng mà không phải quét lặp lại.
3) ORDER BY (khi bạn muốn kết quả đã sắp xếp)
Sắp xếp tốn kém khi cơ sở dữ liệu phải tập hợp nhiều hàng và sắp xếp sau đó. Nếu bạn thường chạy:
SELECT * FROM orders WHERE user_id = 42 ORDER BY created_at DESC;
một chỉ mục sắp xếp phù hợp với user_id và cột sắp xếp có thể cho phép engine đọc hàng theo thứ tự cần thiết thay vì sắp xếp một tập trung gian lớn.
4) GROUP BY (khi nhóm khớp với chỉ mục)
Grouping có thể hưởng lợi khi cơ sở dữ liệu có thể đọc dữ liệu theo thứ tự nhóm. Không phải luôn luôn, nhưng nếu bạn thường group by một cột cũng dùng để lọc (hoặc cột đó tự nhiên được cluster trong chỉ mục), engine có thể làm ít việc hơn.
Bộ lọc phạm vi: thắng lợi phổ biến của B-tree
Chỉ mục B-tree đặc biệt tốt cho điều kiện phạm vi — nghĩ đến ngày, giá, và truy vấn “between”:
SELECT * FROM orders
WHERE created_at >= '2025-01-01' AND created_at < '2025-02-01';
Cho dashboard, báo cáo, và màn hình “hoạt động gần đây”, mẫu này xuất hiện khắp nơi, và chỉ mục trên cột phạm vi thường mang lại cải thiện ngay lập tức.
Chủ đề đơn giản: chỉ mục giúp nhiều nhất khi chúng phản chiếu cách bạn tìm kiếm và sắp xếp. Nếu truy vấn của bạn khớp với những mẫu truy cập đó, cơ sở dữ liệu có thể thực hiện đọc có mục tiêu thay vì quét rộng.
Độ chọn lọc: tại sao một số chỉ mục không hiệu quả
Chỉ mục giúp nhất khi nó thu hẹp rõ rệt số hàng cơ sở dữ liệu phải chạm tới. Tính chất đó gọi là độ chọn lọc.
“Độ chọn lọc” nghĩa là gì trong thực tế
Độ chọn lọc cơ bản là: có bao nhiêu hàng khớp một giá trị cho trước? Cột có độ chọn lọc cao có nhiều giá trị khác nhau, nên mỗi truy vấn khớp ít hàng.
- Độ chọn lọc cao:
email, user_id, order_number (thường là duy nhất hoặc gần duy nhất)
- Độ chọn lọc thấp:
is_active, is_deleted, status có vài giá trị phổ biến
Với độ chọn lọc cao, chỉ mục có thể nhảy tới một tập hàng nhỏ. Với độ chọn lọc thấp, chỉ mục chỉ ra một phần lớn của bảng — vậy cơ sở dữ liệu vẫn phải đọc và lọc nhiều.
Tại sao chỉ mục trên boolean (và tương tự) thường thất vọng
Hãy nghĩ một bảng 10 triệu hàng với cột is_deleted mà 98% là false. Một chỉ mục trên is_deleted không cứu nhiều cho:
SELECT * FROM orders WHERE is_deleted = false;
“Tập khớp” vẫn gần như toàn bộ bảng. Dùng chỉ mục lúc này còn chậm hơn quét tuần tự vì engine làm thêm công nhảy giữa mục chỉ mục và trang bảng.
Tại sao planner có thể bỏ qua chỉ mục của bạn
Bộ lập kế hoạch truy vấn ước tính chi phí. Nếu một chỉ mục không giảm đủ công việc — vì quá nhiều hàng khớp, hoặc truy vấn cần hầu hết các cột — nó có thể chọn quét toàn bộ bảng.
Độ chọn lọc thay đổi theo thời gian
Phân phối dữ liệu không cố định. Một cột status có thể bắt đầu phân bố đều, rồi trôi dần tới một giá trị chiếm đa số. Nếu thống kê không được cập nhật, planner có thể đưa ra phán đoán tồi, và một chỉ mục từng hữu ích có thể ngừng mang lại lợi ích.
Chỉ mục tổng hợp và chỉ mục phủ (và thứ tự cột)
Chỉ mục một cột là khởi đầu tốt, nhưng nhiều truy vấn thực tế lọc theo một cột và sắp xếp/lọc theo cột khác. Đó là lúc chỉ mục tổng hợp (multi-column) tỏa sáng: một chỉ mục có thể phục vụ nhiều phần trong truy vấn.
Thứ tự cột: quy tắc “bắt đầu từ trái”
Hầu hết cơ sở dữ liệu (đặc biệt với B-tree) chỉ dùng hiệu quả chỉ mục tổng hợp từ các cột bên trái nhất trở đi. Hãy nghĩ chỉ mục được sắp xếp trước theo cột A, rồi trong đó theo cột B, v.v.
Điều đó có nghĩa:
- chỉ mục (account_id, created_at) tuyệt vời cho truy vấn lọc theo
account_id rồi sắp xếp/lọc theo created_at
- cùng chỉ mục có thường không hữu ích cho truy vấn chỉ lọc theo
created_at (vì không phải là cột bên trái)
Mẫu thực tế: timeline per-account
Một workload phổ biến là “hiển thị các sự kiện mới nhất cho tài khoản này.” Mẫu truy vấn này:
SELECT id, created_at, type
FROM events
WHERE account_id = ?
ORDER BY created_at DESC
LIMIT 50;
thường hưởng lợi lớn từ:
CREATE INDEX events_account_created_at
ON events (account_id, created_at);
Cơ sở dữ liệu có thể nhảy thẳng tới phần chỉ mục của một account và đọc các hàng theo thứ tự thời gian, thay vì quét và sắp xếp một tập lớn.
Chỉ mục phủ: khi chỉ mục chính là câu trả lời
Một chỉ mục phủ chứa tất cả các cột truy vấn cần, nên cơ sở dữ liệu có thể trả kết quả từ chỉ mục mà không tra bảng (ít đọc hơn, I/O ngẫu nhiên giảm).
Hãy cẩn trọng: thêm cột vào chỉ mục làm cho nó lớn và đắt hơn.
Đừng tạo chỉ mục tổng hợp rộng “phòng khi cần”
Chỉ mục tổng hợp rộng làm chậm ghi và tốn nhiều lưu trữ. Chỉ thêm cho các truy vấn giá trị cao cụ thể, và xác minh bằng EXPLAIN cùng đo lường thực tế trước và sau.
Đổi chác: chậm ghi và tốn thêm lưu trữ
Chỉ mục thường được miêu tả là “tăng tốc miễn phí,” nhưng không có gì miễn phí. Cấu trúc chỉ mục phải được duy trì mỗi khi bảng thay đổi, và chúng tiêu thụ tài nguyên thực.
Chậm hơn khi INSERT/UPDATE/DELETE (vì mỗi chỉ mục phải được cập nhật)
Khi bạn INSERT một hàng mới, cơ sở dữ liệu không chỉ ghi hàng một lần — nó còn chèn mục tương ứng vào mỗi chỉ mục trên bảng đó. UPDATE và DELETE cũng vậy.
Đó là lý do “nhiều chỉ mục” có thể làm chậm rõ rệt workload ghi. Một UPDATE chạm cột có chỉ mục có thể đặc biệt tốn: cơ sở dữ liệu phải xóa mục chỉ mục cũ và thêm mục mới (và trên một số engine, điều này có thể kích hoạt phân tách trang hoặc cân bằng lại bên trong).
Nếu ứng dụng của bạn ghi nhiều — sự kiện đơn hàng, dữ liệu cảm biến, log audit — đánh chỉ mục mọi thứ có thể khiến cơ sở dữ liệu cảm thấy ì ạch ngay cả khi đọc nhanh.
Tốn thêm lưu trữ và áp lực bộ nhớ
Mỗi chỉ mục chiếm không gian đĩa. Trên bảng lớn, chỉ mục có thể sánh với (hoặc lớn hơn) kích thước bảng, đặc biệt nếu bạn có nhiều chỉ mục chồng chéo.
Nó cũng ảnh hưởng tới bộ nhớ. Cơ sở dữ liệu dựa nhiều vào cache; nếu working set của bạn bao gồm vài chỉ mục lớn, cache phải chứa nhiều trang hơn để giữ nhanh. Nếu không, bạn sẽ thấy nhiều I/O đĩa hơn và hiệu suất ít đoán trước hơn.
Cân bằng thực tế
Đánh chỉ mục là chọn cái cần tăng tốc. Nếu workload chủ yếu là đọc, nhiều chỉ mục có thể đáng giá. Nếu chủ yếu ghi, ưu tiên chỉ các chỉ mục phục vụ truy vấn quan trọng nhất và tránh trùng lặp. Một quy tắc hữu ích: chỉ thêm chỉ mục khi bạn có thể nêu rõ truy vấn mà nó giúp — và xác minh rằng lợi ích đọc vượt trội chi phí ghi và bảo trì.
Cách chứng minh một chỉ mục hữu ích: EXPLAIN và đo lường
Thêm chỉ mục có vẻ sẽ giúp — nhưng bạn nên chứng minh. Hai công cụ làm điều này cụ thể là kế hoạch truy vấn (EXPLAIN) và đo lường thực tế trước/sau.
Đọc kế hoạch: chỉ mục có thực sự được dùng không?
Chạy EXPLAIN (hoặc EXPLAIN ANALYZE) trên chính truy vấn bạn quan tâm.
- Loại quét: Seq Scan / Full Table Scan nghĩa là cơ sở dữ liệu đang đọc toàn bộ bảng. Index Scan / Index Seek (hoặc Index Range Scan) cho thấy nó đang dùng chỉ mục để thu hẹp hàng.
- Ước tính vs. thực tế (đặc biệt trong
EXPLAIN ANALYZE): Nếu kế hoạch ước tính 100 hàng nhưng thực tế chạm 100.000, optimizer đã đoán sai — thường do stats lỗi thời hoặc predicate ít chọn lọc hơn mong đợi.
- Bước sort: Nếu bạn thấy một bước Sort rõ ràng, cơ sở dữ liệu đang sắp xếp kết quả sau khi lấy. Nếu một chỉ mục mới khớp
ORDER BY, bước sort đó có thể biến mất, và đó là cải thiện lớn.
Đo lường đúng cách: trước/sau, cùng điều kiện
Benchmark truy vấn với các tham số giống nhau, trên dữ liệu đại diện về kích thước, và ghi lại cả độ trễ và số hàng đã quét.
Cẩn thận với cache: lần chạy đầu có thể chậm hơn vì dữ liệu chưa vào bộ nhớ; các lần chạy lặp lại có thể trông “đã ổn” ngay cả khi không có chỉ mục. Để tránh tự lừa, so sánh nhiều lần chạy và tập trung vào việc kế hoạch có đổi (chỉ mục được dùng, ít hàng đọc) ngoài thời gian thô.
Nếu EXPLAIN ANALYZE cho thấy ít hàng được chạm và ít bước tốn kém (như sort), bạn đã chứng minh chỉ mục hữu ích — không phải chỉ hy vọng thế.
Sai lầm phổ biến làm mất lợi ích của chỉ mục
Bạn có thể thêm “chỉ mục đúng” nhưng vẫn không thấy tăng tốc nếu truy vấn được viết theo cách khiến cơ sở dữ liệu không thể dùng nó. Những vấn đề này thường tinh tế, vì truy vấn vẫn trả đúng kết quả — chỉ là bị ép vào kế hoạch chậm hơn.
Các anti-pattern chặn dùng chỉ mục
1) Wildcard ở đầu
Khi bạn viết:
WHERE name LIKE '%term'
cơ sở dữ liệu không thể dùng B-tree bình thường để nhảy tới điểm bắt đầu, vì nó không biết “%term” bắt đầu ở đâu trong thứ tự. Nó thường phải quét nhiều hàng.
Giải pháp:
- Nếu được, dùng tìm tiền tố:
WHERE name LIKE 'term%'.
- Nếu thực sự cần tìm “chứa”, cân nhắc kiểu chỉ mục chuyên dụng (ví dụ full-text/trigram) thay vì mong đợi chỉ mục chuẩn giúp.
2) Hàm trên cột có chỉ mục
Ví dụ trông vô hại:
WHERE LOWER(email) = '[email protected]'
Nhưng LOWER(email) thay đổi biểu thức, nên chỉ mục trên email không thể dùng trực tiếp.
Giải pháp:
- Lưu dữ liệu đã chuẩn hóa (ví dụ email viết thường) và truy vấn
WHERE email = ....
- Hoặc tạo chỉ mục biểu thức/fonction-based index (tùy DB) dành cho
LOWER(email).
Các blocker ẩn mà mọi người bỏ sót
Ép kiểu ngầm định: So sánh khác loại dữ liệu có thể khiến DB ép kiểu một phía, vô hiệu hóa chỉ mục. Ví dụ: so sánh cột integer với literal chuỗi.
Collation/encoding không khớp: Nếu so sánh dùng collation khác với collation khi tạo chỉ mục (thường gặp với text theo locale khác nhau), optimizer có thể tránh dùng chỉ mục.
Checklist nhanh: “Tại sao chỉ mục tôi không được dùng?”
- Có điều kiện bắt đầu bằng wildcard (
LIKE '%x')?
- Có áp dụng hàm lên cột có chỉ mục (
LOWER(col), DATE(col), CAST(col)) ?
- Kiểu dữ liệu ở hai phía giống nhau (không ép kiểu ngầm)?
- Collation/locale nhất quán cho so sánh?
- Predicate có đủ chọn lọc (không khớp phần lớn bảng)?
- Bạn lọc/sắp xếp theo các cột bên trái của chỉ mục tổng hợp không?
- Bạn đã kiểm tra plan bằng
EXPLAIN để xác nhận DB thực sự chọn gì chưa?
Bảo trì chỉ mục: stats, bloat và sức khỏe lâu dài
Chỉ mục không phải “cài một lần rồi quên”. Theo thời gian, dữ liệu thay đổi, mẫu truy vấn dịch chuyển, và hình dạng vật lý của bảng và chỉ mục trôi dạt. Một chỉ mục được chọn tốt có thể dần kém hiệu quả — hoặc thậm chí gây hại — nếu bạn không bảo trì.
Thống kê: bản đồ của planner có thể lỗi thời
Hầu hết cơ sở dữ liệu dựa vào planner (optimizer) để chọn cách chạy truy vấn: dùng chỉ mục nào, thứ tự join ra sao, hay lookup có đáng hay không. Để đưa ra quyết định, planner dùng thống kê — tóm tắt phân bố giá trị, số hàng, và skew dữ liệu.
Khi thống kê lỗi thời, ước tính hàng có thể sai lệch. Điều đó dẫn tới lựa chọn kế hoạch tồi, như chọn một chỉ mục trả về nhiều hàng hơn mong đợi, hoặc bỏ qua chỉ mục vốn nhanh hơn.
Sửa thường xuyên: lên lịch cập nhật stats (thường gọi là “ANALYZE” hoặc tương tự). Sau tải dữ liệu lớn, xóa lớn, hoặc churn đáng kể, cập nhật stats sớm hơn.
Bloat và phân mảnh: khi cấu trúc trở nên lộn xộn
Khi hàng được chèn, cập nhật và xóa, chỉ mục có thể tích tụ bloat (các trang thừa không còn dữ liệu hữu ích) và phân mảnh (dữ liệu phân tán tăng I/O). Kết quả là chỉ mục lớn hơn, nhiều đọc hơn, và quét chậm — đặc biệt cho truy vấn phạm vi.
Sửa thường xuyên: rebuild hoặc reorganize các chỉ mục dùng nhiều khi chúng đã lớn không tương xứng hoặc hiệu suất trôi dần. Cụ thể và tác động khác nhau theo DB, nên coi đây là thao tác có đo lường, không phải quy tắc chung.
Giám sát theo thời gian, không chỉ một lần
Thiết lập giám sát cho:
- truy vấn chậm (độ trễ, tần suất, và những truy vấn tồi tệ nhất)
- việc sử dụng chỉ mục (chỉ mục không bao giờ dùng vs. những chỉ mục “nóng”)
- tăng kích thước chỉ mục và thay đổi kế hoạch đột ngột
Vòng phản hồi đó giúp bạn phát hiện khi cần bảo trì — và khi một chỉ mục nên được điều chỉnh hoặc xóa. Để biết thêm về xác thực cải tiến, xem phần nội dung tham khảo trong bài viết về cách chứng minh chỉ mục hữu ích với EXPLAIN và đo lường: /blog/how-to-prove-an-index-helps-explain-and-measurements.
Quy trình thực tế để thêm chỉ mục đúng
Thêm chỉ mục nên là thay đổi có chủ ý, không phải đoán mò. Một quy trình nhẹ giữ bạn tập trung vào các cải tiến có đo lường và ngăn chặn “bùng chỉ mục”.
1) Xác định truy vấn gây vấn đề thực sự
Bắt đầu bằng bằng chứng: logs truy vấn chậm, trace APM, hoặc phản hồi người dùng. Chọn một truy vấn vừa chậm vừa thường xuyên — một báo cáo hiếm 10 giây ít quan trọng hơn một truy vấn lookup 200 ms lặp đi lặp lại.
Ghi lại SQL chính xác và mẫu tham số (ví dụ: WHERE user_id = ? AND status = ? ORDER BY created_at DESC LIMIT 50). Khác biệt nhỏ thay đổi chỉ mục cần thiết.
2) Đo baseline
Ghi lại độ trễ hiện tại (p50/p95), số hàng quét, và tác động CPU/IO. Lưu đầu ra kế hoạch hiện tại (ví dụ EXPLAIN / EXPLAIN ANALYZE) để so sánh sau.
3) Thiết kế chỉ mục nhỏ nhất hữu dụng
Chọn cột khớp cách truy vấn lọc và sắp xếp. Ưu tiên chỉ mục tối thiểu làm cho kế hoạch ngừng quét phạm vi lớn.
Thử ở staging với dữ liệu có quy mô giống sản xuất. Chỉ mục có thể trông tốt trên dữ liệu nhỏ nhưng thất vọng ở quy mô.
4) Tạo an toàn
Trên bảng lớn, dùng các tuỳ chọn online nếu hỗ trợ (ví dụ PostgreSQL CREATE INDEX CONCURRENTLY). Lên lịch thay đổi vào thời điểm ít tải nếu DB của bạn có thể khóa ghi.
5) Xác thực bằng chứng trước/sau
Chạy lại cùng truy vấn và so sánh:
- hình dạng kế hoạch (có chuyển từ quét toàn bộ sang truy cập chỉ mục không?)
- thời gian thực thi và số hàng quét
- tác động tới ghi (độ trễ khi insert/update)
6) Có kế hoạch rollback
Nếu chỉ mục làm chi phí ghi tăng hoặc làm bùng bộ nhớ, xóa nó một cách sạch sẽ (ví dụ DROP INDEX CONCURRENTLY nếu có). Giữ migration có thể đảo ngược.
7) Ghi chú “tại sao”
Trong migration hoặc ghi chú schema, viết rõ truy vấn mà chỉ mục phục vụ và chỉ số nào cải thiện. Bạn (hoặc đồng đội) sau này sẽ biết lý do tồn tại và khi nào an toàn để xóa.
Koder.ai phù hợp ở đâu trong quy trình này
Nếu bạn xây dịch vụ mới và muốn tránh “bùng chỉ mục” từ đầu, Koder.ai giúp bạn lặp nhanh vòng đầy đủ: sinh app React + Go + PostgreSQL từ chat, điều chỉnh schema/migration khi yêu cầu thay đổi, rồi xuất source khi muốn tự quản. Trong thực tế, điều đó giúp bạn từ “endpoint này chậm” tới “đây là EXPLAIN plan, chỉ mục tối thiểu, và migration có thể đảo ngược” mà không chờ pipeline truyền thống lâu.
Khi chỉ mục không đủ (và nên làm gì tiếp theo)
Chỉ mục là đòn bẩy lớn, nhưng không phải nút thần kỳ “làm nhanh mọi thứ”. Đôi khi phần chậm của request xảy ra sau khi DB đã tìm ra các hàng đúng — hoặc mẫu truy vấn khiến chỉ mục không phải lựa chọn hàng đầu.
Các trường hợp chỉ mục không phải là cải tiến hàng đầu
Nếu truy vấn đã dùng chỉ mục tốt mà vẫn chậm, hãy tìm các nguyên nhân sau:
- Phân trang sai (pagination): Lấy trang 1000 bằng
OFFSET 999000 có thể chậm dù có chỉ mục. Ưu tiên phân trang theo khóa (keyset pagination), ví dụ “các hàng sau id/timestamp cuối cùng”.
- Trả về quá nhiều dữ liệu: Chọn
SELECT * hoặc trả hàng chục nghìn bản ghi có thể tắc nghẽn ở mạng, serialize JSON, hoặc xử lý ứng dụng.
- Không phù hợp schema: Quan hệ quá chuẩn hóa, lưu giá trị tìm kiếm trong JSON/text blob, hoặc dùng kiểu dữ liệu sai có thể buộc các thao tác đắt mà chỉ mục không che được.
Tối ưu bổ sung thường còn quan trọng hơn
- Viết lại truy vấn: Loại bỏ join không cần thiết, tránh hàm trên cột có chỉ mục trong WHERE, đơn giản hóa predicate OR nặng.
- Giới hạn cột và hàng: Chỉ select cần thiết, đặt
LIMIT hợp lý, và phân trang có chủ ý.
- Cache: Cache các đọc nóng ở tầng ứng dụng hoặc dùng read-through cache cho truy vấn tốn kém lặp lại.
- Partitioning: Nếu hầu hết truy vấn đánh vào “dữ liệu gần đây”, phân vùng theo thời gian (hoặc ranh giới tự nhiên) để thu nhỏ không gian tìm kiếm.
Nếu bạn muốn chẩn đoán bottleneck sâu hơn, kết hợp quy trình này với hướng dẫn cách chứng minh chỉ mục hữu ích bằng EXPLAIN và đo lường.
Ưu tiên: sửa nút thắt lớn nhất trước
Đừng đoán mò. Đo nơi thời gian được tiêu thụ (thực thi DB vs. hàng trả về vs. mã ứng dụng). Nếu DB nhanh mà API vẫn chậm, thêm chỉ mục sẽ không giúp.
Checklist nhanh