Cơ sở dữ liệu đồ thị là gì (không bàn về quảng cáo)
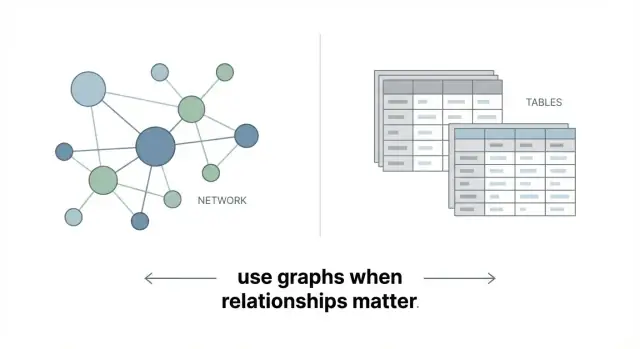
Cơ sở dữ liệu đồ thị lưu trữ dữ liệu như một mạng lưới thay vì một tập các bảng. Ý tưởng chính rất đơn giản:
- Nodes là những “thứ” bạn quan tâm (một khách hàng, sản phẩm, tài khoản, thiết bị, vị trí).
- Relationships nối các node (khách hàng MUA sản phẩm, tài khoản CHUYỂN_TIỀN_ĐẾN tài khoản, người dùng THEO_DÕI người dùng).
- Properties là chi tiết bạn gắn vào cả node và relationship (tên, giá, dấu thời gian, số tiền, trạng thái).
Chỉ vậy thôi: cơ sở dữ liệu đồ thị được xây để biểu diễn dữ liệu có kết nối một cách trực tiếp.
Mối quan hệ là “đối tượng hạng nhất”
Trong cơ sở dữ liệu đồ thị, mối quan hệ không phải là điều phụ; chúng được lưu như các đối tượng thực tế có thể truy vấn. Một relationship có thể có thuộc tính riêng (ví dụ, một relationship MUA có thể lưu ngày, kênh, và giảm giá), và bạn có thể duyệt từ node này sang node khác một cách hiệu quả.
Điều này quan trọng vì nhiều câu hỏi kinh doanh tự nhiên là về đường đi và kết nối: “Ai liên kết với ai?”, “Thực thể này cách bao nhiêu bước?”, hay “Những liên kết chung giữa hai thứ này là gì?”
Khác biệt so với bảng và JOIN
Cơ sở dữ liệu quan hệ mạnh ở các bản ghi có cấu trúc: khách hàng, đơn hàng, hóa đơn. Các mối quan hệ ở đó cũng tồn tại, nhưng thường biểu diễn gián tiếp qua khóa ngoại, và nối nhiều bước thường cần viết JOIN qua nhiều bảng.
Đồ thị giữ kết nối sát cạnh dữ liệu, nên khám phá các mối quan hệ nhiều bước thường dễ mô hình hóa và truy vấn hơn.
Kỳ vọng thực tế
Cơ sở dữ liệu đồ thị tuyệt vời khi mối quan hệ là điểm chính—đề xuất, nhóm gian lận, bản đồ phụ thuộc, knowledge graphs. Chúng không tự động tốt hơn cho báo cáo đơn giản, tổng hợp, hoặc các khối lượng công việc dạng bảng thuần túy. Mục tiêu không phải thay thế mọi cơ sở dữ liệu, mà dùng đồ thị khi kết nối là nguồn giá trị.
Tại sao mối quan hệ thay đổi cục diện
Hầu hết câu hỏi kinh doanh không chỉ về một bản ghi duy nhất—mà là cách mọi thứ kết nối.
Một khách hàng không chỉ là một hàng; họ liên kết tới đơn hàng, thiết bị, địa chỉ, ticket hỗ trợ, giới thiệu, và đôi khi những khách hàng khác. Một giao dịch không chỉ là một sự kiện; nó nối tới người bán, phương thức thanh toán, vị trí, khung thời gian, và một chuỗi hoạt động liên quan. Khi câu hỏi là “ai/cái gì liên kết với ai, và bằng cách nào?”, dữ liệu quan hệ trở thành nhân vật chính.
Traversal: đi theo kết nối từng bước một
Cơ sở dữ liệu đồ thị được thiết kế cho traversal: bạn bắt đầu ở một node và “đi” mạng bằng cách theo các cạnh.
Thay vì JOIN các bảng lặp đi lặp lại, bạn diễn đạt con đường bạn cần: Customer → Device → Login → IP Address → Other Customers. Cách diễn đạt từng bước này khớp với cách con người điều tra gian lận, truy vết phụ thuộc, hoặc giải thích đề xuất.
Tại sao truy vấn nhiều bước đơn giản hơn
Khác biệt thực sự xuất hiện khi bạn cần nhiều bước (hai, ba, năm bước) và bạn không biết trước nơi xuất hiện các kết nối thú vị.
Trong mô hình quan hệ, câu hỏi nhiều bước thường biến thành chuỗi JOIN dài kèm logic bổ sung để tránh trùng lặp và kiểm soát độ dài đường đi. Trong đồ thị, “tìm tất cả đường đi lên đến N bước” là một mẫu bình thường và dễ đọc—đặc biệt với mô hình property graph mà nhiều hệ đồ thị sử dụng.
Thuộc tính của mối quan hệ làm tăng ý nghĩa
Các cạnh không chỉ là đường nối; chúng có thể mang dữ liệu:
- Loại: purchased, referred, works_with
- Thời gian: khi mối quan hệ bắt đầu, kết thúc, hoặc xảy ra lần cuối
- Trọng số: tần suất, điểm tin cậy, số tiền, mức rủi ro
Những thuộc tính này cho phép bạn hỏi các câu tốt hơn: “liên kết trong 30 ngày qua,” “mối quan hệ mạnh nhất,” hoặc “đường đi bao gồm giao dịch rủi ro cao”—mà không buộc mọi thứ vào các bảng tra cứu riêng biệt.
Các trường hợp dùng phù hợp nhất cho cơ sở dữ liệu đồ thị
Cơ sở dữ liệu đồ thị tỏa sáng khi các câu hỏi của bạn phụ thuộc vào kết nối: “ai liên kết với ai, qua cái gì, và cách bao nhiêu bước?” Nếu giá trị dữ liệu nằm ở các mối quan hệ (không chỉ các hàng thuộc tính), mô hình đồ thị có thể khiến việc mô hình hóa dữ liệu và truy vấn trở nên tự nhiên hơn.
Mạng xã hội và nghề nghiệp
Bất cứ thứ gì có hình dạng mạng—bạn bè, người theo dõi, đồng nghiệp, đội, giới thiệu—khớp vào nodes và relationships dễ dàng. Các câu hỏi điển hình gồm “kết nối chung,” “đường ngắn nhất đến một người,” hoặc “ai nối hai nhóm này?” Những truy vấn này thường trở nên khó xử (hoặc chậm) khi bị ép vào nhiều bảng JOIN.
Đề xuất (và khám phá)
Các bộ máy đề xuất thường dựa trên kết nối nhiều bước: user → item → category → items tương tự → other users. Cơ sở dữ liệu đồ thị phù hợp cho “người thích X cũng thích Y,” “sản phẩm thường được xem cùng nhau,” và “tìm sản phẩm nối bằng thuộc tính hoặc hành vi chung.” Điều này càng hữu ích khi tín hiệu đa dạng và bạn liên tục thêm loại quan hệ mới.
Điều tra gian lận và rủi ro
Đồ thị phát hiện gian lận tốt bởi vì hành vi đáng ngờ hiếm khi cô lập. Tài khoản, thiết bị, giao dịch, số điện thoại, email và địa chỉ tạo thành mạng các định danh chung. Đồ thị giúp dễ phát hiện vòng gian lận, mẫu lặp lại, và liên kết gián tiếp (ví dụ, hai tài khoản “không liên quan” dùng cùng một thiết bị qua một chuỗi hoạt động).
Bản đồ phụ thuộc mạng và IT
Với dịch vụ, host, API, cuộc gọi và quyền sở hữu, câu hỏi chính là phụ thuộc: “cái gì sẽ hỏng nếu cái này thay đổi?” Đồ thị hỗ trợ phân tích tác động, truy vết nguyên nhân gốc rễ, và truy vấn “vùng ảnh hưởng” khi hệ thống liên kết với nhau.
Knowledge graphs
Knowledge graphs nối thực thể (người, công ty, sản phẩm, tài liệu) tới các facts và nguồn. Điều này giúp tìm kiếm, hợp nhất thực thể, và truy vết “tại sao” một fact được biết (provenance) qua nhiều nguồn liên kết.
Các câu hỏi đồ thị phổ biến bạn có thể trả lời dễ dàng
Cơ sở dữ liệu đồ thị tỏa sáng khi câu hỏi thực sự là về kết nối: ai nối với ai, qua chuỗi nào, và các mẫu nào lặp lại. Thay vì JOIN các bảng liên tục, bạn hỏi trực tiếp câu hỏi về mối quan hệ và giữ cho truy vấn dễ đọc khi mạng lớn lên.
1) Tìm đường đi: “A và B kết nối thế nào?”
Câu hỏi điển hình:
- “Đường ngắn nhất từ khách hàng này đến merchant kia là gì?”
- “Những đồng nghiệp nào nối Alice và Bob, và qua bao nhiêu bước?”
- “Cho tôi tất cả các tuyến từ thiết bị này đến tài khoản kia trong 3 hops.”
Điều này hữu ích cho hỗ trợ khách hàng (“tại sao chúng tôi đề xuất điều này?”), tuân thủ (“cho thấy chuỗi sở hữu”), và điều tra (“nó lan như thế nào?”).
2) Phát hiện cộng đồng: nhóm và cụm trong mạng
Đồ thị giúp bạn nhận ra các nhóm tự nhiên:
- “Những khách hàng nào tạo thành cụm dựa trên địa chỉ, điện thoại và thiết bị chung?”
- “Cộng đồng chặt chẽ trong mạng nhà cung cấp của chúng ta ở đâu?”
Bạn có thể dùng điều này để phân đoạn người dùng, tìm băng nhóm gian lận, hoặc hiểu cách sản phẩm được mua cùng nhau. Mấu chốt là “nhóm” được định nghĩa bởi cách kết nối, không phải bởi một cột đơn.
3) Trung tâm và ảnh hưởng: tìm node quan trọng
Đôi khi câu hỏi không chỉ là “ai được kết nối,” mà là “ai quan trọng nhất” trong mạng:
- “Tài khoản nào xuất hiện trên nhiều đường đi nhất giữa các tài khoản khác?”
- “Sản phẩm nào là cầu nối mạnh nhất giữa hai phân khúc khách hàng?”
Các node trung tâm này thường chỉ ra influencer, hạ tầng quan trọng, hoặc nút nghẽn cần giám sát.
4) So khớp mẫu: “tìm tam giác” và “tìm vòng nghi ngờ”
Đồ thị rất giỏi trong việc tìm các hình lặp:
- Tam giác: “A biết B, B biết C, và C biết A.”
- Vòng: “Tài khoản chuyển tiền theo vòng.”
Trong Cypher (một ngôn ngữ truy vấn đồ thị phổ biến), mẫu tam giác có thể trông như sau:
MATCH (a)-[:KNOWS]->(b)-[:KNOWS]->(c)-[:KNOWS]->(a)
RETURN a,b,c
Ngay cả khi bạn không bao giờ viết Cypher, ví dụ này minh họa vì sao đồ thị dễ tiếp cận: truy vấn phản chiếu đúng hình ảnh trong đầu bạn.
Đồ thị vs Quan hệ: Khác biệt thực sự
Cơ sở dữ liệu quan hệ tuyệt vời ở những thứ chúng được thiết kế: giao dịch và bản ghi có cấu trúc rõ ràng. Nếu dữ liệu của bạn phù hợp bảng (khách hàng, đơn hàng, hóa đơn) và bạn chủ yếu truy xuất theo ID, bộ lọc và tổng hợp, hệ quan hệ thường là lựa chọn đơn giản và an toàn.
Vấn đề JOIN không phải là “JOIN xấu”—mà là JOIN sâu
JOIN ổn khi chúng thỉnh thoảng và nông. Trò khó bắt đầu khi các câu hỏi quan trọng yêu cầu nhiều JOIN, liên tục, qua nhiều bảng.
Ví dụ:
- “Những khách hàng nào mua từ người bán kết nối tới nhà cung cấp này qua hai trung gian?”
- “Tìm tất cả thiết bị từng chia sẻ mạng với thiết bị do các mối liên hệ gần của tài khoản này dùng.”
Trong SQL, những thứ này có thể trở thành truy vấn dài với nhiều self-join và logic phức tạp, và khó tối ưu khi độ sâu quan hệ tăng.
Đồ thị biến các “đi bộ” nhiều bước thành thao tác hạng nhất
Cơ sở dữ liệu đồ thị lưu trữ các mối quan hệ một cách rõ ràng, nên traversal nhiều bước là thao tác tự nhiên. Thay vì khâu các bảng lại khi truy vấn, bạn duyệt các node và cạnh liên kết.
Điều này thường có nghĩa là:
- Truy vấn ngắn hơn cho các mẫu nhiều-hop (truy vấn đọc giống như câu hỏi)
- Độ phức tạp dễ dự đoán hơn khi khám phá độ sâu biến thiên (ví dụ 2 đến 6 hops)
Một quy tắc thực tế
Nếu nhóm của bạn thường hỏi các câu nhiều-hop—“liên kết tới,” “qua,” “trong cùng mạng với,” “trong N bước”—thì đáng cân nhắc cơ sở dữ liệu đồ thị.
Nếu khối lượng chính của bạn là giao dịch khối lượng lớn, schema nghiêm ngặt, báo cáo và JOIN trực tiếp, SQL thường là mặc định tốt hơn. Nhiều hệ thống thực tế dùng cả hai; xem /blog/practical-architecture-graph-alongside-other-databases.
Khi cơ sở dữ liệu đồ thị không phải công cụ phù hợp
Trình bày chuyên nghiệp
Chia sẻ một demo bóng bẩy với tên miền tùy chỉnh cho buổi review nội bộ hoặc thử nghiệm với khách hàng.
Đồ thị tỏa sáng khi mối quan hệ là “điểm chính.” Nếu giá trị ứng dụng của bạn không phụ thuộc vào duyệt kết nối (ai quen ai, cách các mục liên hệ, đường đi, lân cận), đồ thị có thể thêm độ phức tạp mà không mang lại nhiều lợi ích.
CRUD đơn giản với tra cứu một bản ghi
Nếu hầu hết yêu cầu là “lấy user theo ID,” “cập nhật profile,” “tạo order,” và dữ liệu bạn cần nằm trong một bản ghi (hoặc vài bảng cố định), đồ thị thường không cần thiết. Bạn sẽ mất thời gian mô hình nodes/edges, tinh chỉnh traversal, và học kiểu truy vấn mới—trong khi cơ sở dữ liệu quan hệ xử lý mẫu này hiệu quả với công cụ quen thuộc.
Báo cáo/BI chủ yếu là tổng hợp
Bảng điều khiển dựa trên tổng, trung bình và nhóm (doanh thu theo tháng, đơn hàng theo vùng, tỷ lệ chuyển đổi theo kênh) thường phù hợp SQL và hệ phân tích cột hơn truy vấn đồ thị. Động cơ đồ thị có thể trả lời một số câu tổng hợp, nhưng hiếm khi là đường ngắn hoặc nhanh nhất cho khối lượng OLAP nặng.
Nhu cầu giao dịch mạnh và tính năng “SQL-native”
Khi bạn phụ thuộc các tính năng SQL trưởng thành—JOIN phức tạp với ràng buộc chặt, chiến lược chỉ mục nâng cao, stored procedures, hoặc mô hình giao dịch ACID đã thiết lập—hệ quan hệ thường là lựa chọn tự nhiên. Nhiều DB đồ thị hỗ trợ giao dịch, nhưng hệ sinh thái và mô hình vận hành có thể khác so với thứ nhóm bạn quen dùng.
Các bản ghi độc lập, ít liên kết
Nếu dữ liệu chủ yếu là các thực thể độc lập (ticket, hóa đơn, đọc cảm biến) với ít liên kết có ý nghĩa, mô hình đồ thị có thể bị ép. Trong các trường hợp này, tập trung vào schema quan hệ sạch (hoặc mô hình document) và chỉ cân nhắc đồ thị khi các câu hỏi nặng về quan hệ trở nên trung tâm.
Một quy tắc tốt: nếu bạn có thể mô tả các truy vấn hàng đầu mà không dùng từ như “connected,” “path,” “neighborhood,” hoặc “recommend,” đồ thị có thể không phải lựa chọn khởi đầu tốt.
Những đánh đổi cần biết trước khi chọn đồ thị
Đồ thị mạnh khi bạn cần theo kết nối nhanh—nhưng sức mạnh đó có giá. Trước khi cam kết, tốt nhất hiểu các nơi đồ thị thường kém hiệu quả hơn, tốn kém hơn, hoặc khác biệt trong vận hành hàng ngày.
Đồ thị thường lưu và đánh chỉ mục các mối quan hệ để các “hop” nhanh (ví dụ, từ khách hàng đến thiết bị đến giao dịch). Đổi lại, chúng có thể tốn hơn về bộ nhớ và lưu trữ so với thiết lập tương đương quan hệ, đặc biệt khi bạn thêm chỉ mục cho các tra cứu phổ biến và giữ dữ liệu mối quan hệ dễ tiếp cận.
Không phải mọi truy vấn đều nhanh hơn
Nếu khối lượng của bạn trông như một bảng tính—quét bảng lớn, truy vấn báo cáo trên hàng triệu hàng, hoặc tổng hợp nặng—cơ sở dữ liệu đồ thị có thể chậm hoặc đắt hơn để có cùng kết quả. Đồ thị tối ưu cho traversal (“ai liên kết với gì?”), không phải cho xử lý hàng loạt các bản ghi độc lập.
Khác biệt vận hành
Độ phức tạp vận hành có thể là yếu tố thực sự. Sao lưu, scaling và giám sát khác với những gì nhiều nhóm quen với hệ quan hệ. Một số nền tảng đồ thị scale tốt bằng cách tăng cỡ máy, trong khi khác hỗ trợ scale out nhưng đòi hỏi hoạch định kỹ về consistency, replication và pattern truy vấn.
Nhóm bạn có thể cần thời gian để học mô hình mới và cách truy vấn (ví dụ mô hình property graph và các ngôn ngữ như Cypher). Đường cong học tập có thể quản lý được, nhưng vẫn là chi phí—đặc biệt nếu bạn thay thế luồng báo cáo SQL đã trưởng thành.
Cách thực tế là dùng đồ thị nơi mối quan hệ là sản phẩm, và giữ hệ thống hiện có cho báo cáo, tổng hợp và phân tích dạng bảng.
Những điều cơ bản về mô hình dữ liệu: Nodes, Edges và Schema
Triển khai một pilot rủi ro thấp
Biến các câu hỏi về quan hệ thành giao diện, API và luồng dữ liệu để kiểm thử trong tuần này.
Một cách hữu ích để nghĩ về mô hình đồ thị rất đơn giản: nodes là các thứ, và edges là các mối quan hệ giữa các thứ. Người, tài khoản, thiết bị, đơn hàng, sản phẩm, vị trí—đó là nodes. “Bought,” “logged_in_from,” “works_with,” “is parent of”—đó là edges.
Property graphs vs. RDF triples
Hầu hết các DB đồ thị hướng sản phẩm dùng mô hình property graph: cả nodes và edges có thể có properties (trường key–value). Ví dụ, một edge PURCHASED có thể lưu date, amount, và channel. Điều này tự nhiên để mô hình “mối quan hệ có chi tiết.”
RDF biểu diễn tri thức như triples: subject – predicate – object. Nó phù hợp cho các từ vựng tương tác và liên kết dữ liệu giữa hệ thống, nhưng thường đẩy “chi tiết mối quan hệ” thành các node/triple bổ sung. Thực tế, bạn sẽ thấy RDF hướng bạn tới ontology chuẩn và mẫu SPARQL, trong khi property graph thân thiện hơn với mô hình dữ liệu ứng dụng.
Ngôn ngữ truy vấn nói nôm na
- Cypher (phổ biến với property graphs) đọc như một mẫu bạn muốn tìm: “(Customer)-[PURCHASED]->(Product).”
- Gremlin giống như traversal từng bước: bắt đầu đây, đi theo các cạnh theo cách này, lọc, rồi tổng hợp.
- SPARQL là ngôn ngữ thế giới RDF, so khớp mẫu đồ thị với các triples, thường dùng từ vựng chia sẻ.
Bạn không cần ghi nhớ cú pháp sớm—quan trọng là truy vấn đồ thị thường được diễn đạt dưới dạng đường đi và mẫu, không phải JOIN bảng.
“Schema” nghĩa là gì trong hệ đồ thị
Đồ thị thường linh hoạt về schema, nghĩa là bạn có thể thêm label node hoặc property mới mà không cần migration nặng. Nhưng linh hoạt vẫn cần kỷ luật: định nghĩa quy ước đặt tên, các thuộc tính bắt buộc (ví dụ id), và luật cho loại relationship.
Loại relationship, hướng, và thuộc tính
Chọn loại relationship làm rõ ý nghĩa (“FRIEND_OF” vs “CONNECTED”). Dùng hướng để làm rõ ngữ nghĩa (ví dụ FOLLOWS từ follower tới creator), và thêm thuộc tính cạnh khi mối quan hệ có sự kiện riêng (thời gian, độ tin cậy, vai trò, trọng số).
Làm sao quyết định vấn đề của bạn có phải là “dựa trên quan hệ” không
Một vấn đề là “dựa trên quan hệ” khi phần khó không phải là lưu trữ bản ghi—mà là hiểu cách các thứ kết nối, và cách các kết nối đó thay đổi ý nghĩa tùy theo đường đi bạn đi.
Bắt đầu bằng câu hỏi, không phải bảng
Bắt đầu bằng cách viết 5–10 câu hỏi hàng đầu bằng ngôn ngữ thường — những câu mà các bên liên quan hay hỏi và hệ thống hiện tại trả lời chậm hoặc không nhất quán. Ứng viên đồ thị thường có cụm từ như “connected to,” “through,” “similar to,” “within N steps,” hoặc “who else.”
Ví dụ:
- “Những khách hàng nào liên kết với vòng gian lận này qua thiết bị và địa chỉ chung?”
- “Sản phẩm nào thường được mua cùng bởi những người cũng xem X?”
- “Nhà cung cấp nào bị ảnh hưởng gián tiếp nếu nhà máy này ngừng hoạt động?”
Dịch câu hỏi sang thực thể và tương tác
Khi có câu hỏi, map ra danh từ và động từ:
- Thực thể chính trở thành nodes (Customer, Account, Device, Product, Supplier).
- Tương tác trở thành relationships (PAID_WITH, LOGGED_IN_FROM, BOUGHT, SUPPLIES).
Rồi quyết định cái gì phải là relationship vs node. Quy tắc thực tế: nếu một thứ cần thuộc tính riêng và bạn sẽ nối nhiều bên tới nó, hãy làm nó thành node (ví dụ, một “Order” hoặc “Login event” có thể là node khi nó mang chi tiết và nối nhiều thực thể).
Làm cho lọc và điểm số dễ dàng
Thêm thuộc tính để giúp thu hẹp kết quả và xếp hạng mà không cần JOIN hay xử lý sau. Các thuộc tính giá trị cao thường là thời gian, số tiền, trạng thái, kênh, và điểm tin cậy.
Nếu hầu hết các câu hỏi quan trọng của bạn cần kết nối nhiều bước kèm lọc theo những thuộc tính đó, bạn rất có thể đang giải quyết vấn đề dựa trên quan hệ, nơi đồ thị tỏa sáng.
Kiến trúc thực tế: Dùng đồ thị cùng các DB khác
Hầu hết nhóm không thay thế mọi thứ bằng đồ thị. Cách thực tế hơn là giữ “system of record” nơi nó đang hoạt động tốt (thường SQL), và dùng đồ thị như engine chuyên dụng cho các câu hỏi nặng về mối quan hệ.
Giữ nguồn sự thật trong SQL (hoặc datastore chính của bạn)
Dùng cơ sở dữ liệu quan hệ cho giao dịch, ràng buộc và thực thể chuẩn (customers, orders, accounts). Sau đó chiếu một view quan hệ vào cơ sở dữ liệu đồ thị—chỉ những nodes và edges bạn cần cho các truy vấn kết nối.
Điều này giữ audit và quản trị dữ liệu đơn giản trong khi vẫn mở khóa các truy vấn traversal nhanh.
Xây đồ thị cho một tính năng, không toàn công ty
Cơ sở dữ liệu đồ thị tỏa sáng khi bạn gắn nó vào một tính năng có phạm vi rõ ràng, như:
- Đề xuất (“người mua X cũng mua Y”)
- Điểm rủi ro (vòng gian lận, thiết bị chung, phương tiện thanh toán chung)
- Hợp nhất định danh (liên kết hồ sơ giữa các hệ thống)
Bắt đầu với một tính năng, một nhóm, và một kết quả đo lường được. Mở rộng sau khi đã chứng minh giá trị.
Nếu nút nghẽn của bạn là triển khai prototype (không phải tranh luận về mô hình), một nền tảng tạo giao diện như Koder.ai có thể giúp bạn dựng nhanh một app đồ thị đơn giản: bạn mô tả tính năng trong chat, sinh UI React và backend Go/PostgreSQL, và lặp trong khi team dữ liệu xác thực schema đồ thị và truy vấn.
Chiến lược đồng bộ: batch vs near-real-time
Dữ liệu trong đồ thị cần tươi mới đến mức nào?
- Cập nhật theo lô (hàng giờ/hàng đêm) đơn giản hơn và thường đủ cho phân tích, khám phá, và nhiều hệ đề xuất.
- Luồng gần thời gian thực (phút/giây) phù hợp với đồ thị phát hiện gian lận và quyết định vận hành.
Mô hình phổ biến: ghi transaction vào SQL → publish change events → cập nhật đồ thị.
ID nhất quán và quyền sở hữu rõ ràng
Đồ thị trở nên lộn xộn khi ID trôi dạt.
Định nghĩa identifier ổn định (ví dụ customer_id, account_id) trùng khớp giữa các hệ thống, và ghi rõ ai “sở hữu” mỗi trường và relationship. Nếu hai hệ cùng tạo cùng một edge (ví dụ, “knows”), quyết định hệ nào thắng.
Nếu bạn lập pilot, xem /blog/getting-started-a-low-risk-pilot-plan để có cách triển khai từng bước.
Bắt đầu: Kế hoạch pilot rủi ro thấp
Mô hình hóa nodes và edges
Dùng chế độ lập kế hoạch để vẽ bản đồ nodes, edges và các truy vấn trước khi viết bất kỳ chi tiết triển khai nào.
Một pilot đồ thị nên cảm thấy như thí nghiệm, không phải rewrite. Mục tiêu là chứng minh (hoặc bác bỏ) rằng các truy vấn nặng về quan hệ trở nên đơn giản và nhanh hơn—mà không đặt cược toàn bộ stack dữ liệu.
1) Chọn lát nhỏ có giá trị cao
Bắt đầu với một tập dữ liệu hẹp đã gây đau đầu: quá nhiều JOIN, SQL mỏng manh, hoặc các câu hỏi “ai liên kết với ai?” chậm. Giữ phạm vi một workflow (ví dụ: customer ↔ account ↔ device, hoặc user ↔ product ↔ interaction) và định nghĩa vài truy vấn bạn muốn trả lời end-to-end.
2) Định nghĩa chỉ số thành công trước khi xây
Đo nhiều hơn tốc độ:
- Độ phức tạp truy vấn: Bao nhiêu dòng, bao nhiêu JOIN, hoặc bảng trung gian so với trước vs sau?
- Độ trễ: Thời gian trả kết quả trên khối lượng dữ liệu thực tế.
- Thời gian dev: Mất bao lâu để xây và thay đổi truy vấn khi yêu cầu thay đổi?
Nếu bạn không thể nắm con số “trước”, bạn sẽ khó tin con số “sau”.
3) Giữ mô hình có mục đích (tránh lan rộng đồ thị)
Dễ bị cám dỗ muốn mô hình mọi thứ như nodes và edges. Cần chống lại. Để ý "graph sprawl": quá nhiều loại node/edge mà không có truy vấn rõ ràng cần chúng. Mỗi label hay relationship mới nên chứng minh giá trị bằng cách giải quyết một câu hỏi thực tế.
4) Đưa quản trị dữ liệu vào pilot
Lên kế hoạch cho quyền riêng tư, kiểm soát truy cập và lưu giữ dữ liệu từ đầu. Dữ liệu quan hệ có thể tiết lộ nhiều hơn từng bản ghi riêng lẻ (ví dụ, các kết nối ngụ ý hành vi). Xác định ai được truy vấn gì, cách audit kết quả, và cách xóa dữ liệu khi cần.
5) Chạy song song với DB hiện tại
Dùng sync đơn giản (batch hoặc streaming) để đưa dữ liệu vào đồ thị trong khi hệ thống hiện tại vẫn là nguồn sự thật. Khi pilot chứng minh giá trị, mở rộng cẩn trọng, từng use case một.
Bảng kiểm quyết định nhanh: Dùng đồ thị khi quan hệ quan trọng
Khi chọn DB, đừng bắt đầu từ công nghệ—bắt đầu từ câu hỏi bạn cần trả lời. Cơ sở dữ liệu đồ thị tỏa sáng khi vấn đề khó nhất của bạn là kết nối và đường đi, không chỉ lưu trữ bản ghi.
Bảng kiểm “có phải dựa trên quan hệ không?”
Dùng bảng này để kiểm tra trước khi đầu tư:
- Độ sâu quan hệ: Bạn có thường xuyên cần theo quan hệ 2+ hops (A→B→C→D) để có câu trả lời không?
- Mẫu truy vấn: Các câu hỏi chính có liên quan đến mẫu (ví dụ, “người cùng công ty và cùng số điện thoại”) hơn là lọc trên một bảng?
- Tần suất cập nhật: Quan hệ có thay đổi thường xuyên không, và bạn cần phản ánh nhanh những thay đổi đó?
- Qui mô: Dữ liệu có lớn đến mức JOIN nhiều bảng (hoặc khâu trong code ứng dụng) trở nên chậm, tốn kém, hoặc mong manh không?
Nếu bạn trả “có” cho hầu hết, đồ thị có thể phù hợp—đặc biệt khi bạn cần so khớp mẫu nhiều-hop như:
- “Tìm đường ngắn nhất giữa hai thực thể.”
- “Hiện tất cả tài khoản liên kết tới thiết bị này trong 3 bước.”
- “Đề xuất mục dựa trên neighbors chia sẻ, không chỉ category.”
Khi nên giữ SQL/NoSQL
Nếu công việc chủ yếu là tra cứu đơn giản (theo ID/email) hoặc tổng hợp (“tổng doanh thu theo tháng”), cơ sở dữ liệu quan hệ hoặc kho lưu trữ key-value/document thường đơn giản và rẻ hơn.
Cách giảm rủi ro khi quyết định
Viết ra 10 câu hỏi kinh doanh hàng đầu bằng câu đầy đủ, rồi thử trên dữ liệu thực trong pilot nhỏ. Đo thời gian truy vấn, ghi lại điều gì khó diễn đạt, và lưu nhật ký các thay đổi mô hình bạn cần. Nếu pilot chủ yếu thành “thêm nhiều JOIN” hoặc “thêm caching”, đó là tín hiệu đồ thị có thể mang lại lợi ích. Nếu chủ yếu là đếm và lọc, có lẽ không.