OLTP vs OLAP: Chúng là gì (không vòng vo)
Khi người ta nói “OLTP” và “OLAP”, họ đang nói về hai cách sử dụng cơ sở dữ liệu rất khác nhau.
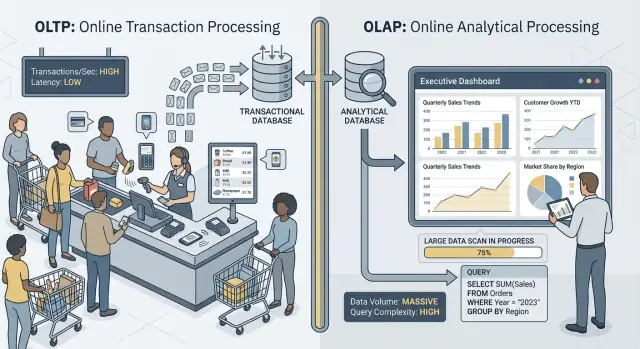
OLTP: cơ sở dữ liệu vận hành doanh nghiệp
OLTP (Online Transaction Processing) là khối lượng công việc đứng sau các hành động hằng ngày phải nhanh và đúng mọi lần. Nghĩ tới: “lưu thay đổi này ngay bây giờ.”
Các tác vụ OLTP điển hình bao gồm tạo đơn, cập nhật tồn kho, ghi nhận thanh toán, hoặc thay đổi địa chỉ khách hàng. Những thao tác này thường nhỏ (vài hàng), xảy ra thường xuyên, và phải phản hồi trong mili-giây vì một người hoặc hệ thống khác đang chờ.
OLAP: cơ sở dữ liệu giải thích doanh nghiệp
OLAP (Online Analytical Processing) là khối lượng công việc dùng để hiểu chuyện gì đã xảy ra và tại sao. Nghĩ tới: “quét nhiều dữ liệu và tổng hợp nó.”
Các tác vụ OLAP điển hình bao gồm dashboard, báo cáo xu hướng, phân tích cohort, dự báo, và các câu hỏi “cắt-sẻ” như: “Doanh thu thay đổi theo vùng và loại sản phẩm ra sao trong 18 tháng qua?” Những truy vấn này thường đọc nhiều hàng, thực hiện các phép tổng hợp nặng, và có thể chạy vài giây (hoặc vài phút) mà không bị coi là “sai”.
Cùng dữ liệu, mục tiêu khác nhau — và nhu cầu khác nhau
Ý chính đơn giản: OLTP tối ưu cho ghi nhanh, nhất quán và các đọc nhỏ, trong khi OLAP tối ưu cho đọc lớn và tính toán phức tạp. Vì mục tiêu khác nhau, các cài đặt cơ sở dữ liệu tốt nhất, chỉ mục, bố cục lưu trữ và cách scale thường khác nhau.
Cần lưu ý từ ngữ: hiếm khi, chứ không phải không bao giờ. Một số đội nhỏ có thể chia sẻ một cơ sở dữ liệu trong một thời gian, đặc biệt khi khối lượng dữ liệu khiêm tốn và có kỷ luật truy vấn. Các phần sau sẽ nói rõ điều gì hỏng trước, các mẫu phân tách phổ biến và cách chuyển báo cáo khỏi môi trường sản xuất an toàn.
Ví dụ nhanh
- Thanh toán (OLTP): khách hàng bấm “Thanh toán”, app ghi một đơn, trạng thái thanh toán và cập nhật tồn kho.
- Dashboard báo cáo (OLAP): quản lý mở dashboard tổng hợp hàng nghìn (hoặc triệu) đơn để hiển thị tỷ lệ chuyển đổi, giá trị trung bình đơn hàng và xu hướng tuần.
Mục tiêu khác nhau, chỉ số thành công khác nhau
OLTP và OLAP đều “dùng SQL”, nhưng tối ưu cho công việc khác nhau — và điều đó thể hiện ở việc mỗi bên coi gì là thành công.
OLTP: tốc độ, đồng thời và đúng đắn
Hệ thống OLTP (giao dịch) phục vụ hoạt động thường nhật: luồng thanh toán, cập nhật tài khoản, đặt chỗ, công cụ hỗ trợ. Ưu tiên rõ ràng:
- Thời gian phản hồi nhanh cho các đọc/ghi nhỏ (nghĩ tới mili-giây)
- Nhiều người dùng đồng thời mà không bị chậm
- Độ đúng đắn và nhất quán, vì số dư sai hay đơn hàng trùng là vấn đề kinh doanh thật
Thành công thường được theo dõi bằng các chỉ số độ trễ như p95/p99, tỷ lệ lỗi và cách hệ thống hoạt động dưới tải đồng thời đỉnh.
OLAP: quét, tổng hợp và linh hoạt
Hệ thống OLAP (phân tích) trả lời các câu hỏi như “Quý này thay đổi gì?” hay “Phân đoạn nào churn sau thay đổi giá?” Những truy vấn này thường:
- Quét lượng lớn dữ liệu trên nhiều hàng
- Thực hiện tổng hợp (SUM, COUNT, percentiles) và join
- Thay đổi thường xuyên khi analyst khám phá và chỉnh câu hỏi
Thành công ở đây giống như thông lượng truy vấn, thời gian có insight và khả năng chạy truy vấn phức tạp mà không cần chỉnh tay cho từng báo cáo.
Tại sao “một hệ thống cho mọi thứ” tạo ra đánh đổi
Khi ép cả hai workload vào một cơ sở dữ liệu, bạn yêu cầu nó vừa xuất sắc cho giao dịch nhỏ, vừa xuất sắc cho lượt quét lớn khám phá. Kết quả thường là thỏa hiệp: OLTP bị độ trễ không đoán trước, OLAP bị giới hạn để bảo vệ sản xuất, và các đội tranh luận xem truy vấn của ai được “cho phép”. Mục tiêu riêng nên có chỉ số thành công riêng — và thường là hệ thống riêng.
Cạnh tranh tài nguyên: Khi phân tích lấy tài nguyên của giao dịch
Khi OLTP (giao dịch hằng ngày) và OLAP (báo cáo, phân tích) chạy trên cùng một cơ sở dữ liệu, chúng tranh nhau nguồn lực hữu hạn. Hệ quả không chỉ là “báo cáo chậm”. Thường là checkout chậm hơn, đăng nhập bị treo và các trục trặc app không dự đoán được.
CPU và bộ nhớ: truy vấn dài vs truy vấn ngắn
Truy vấn phân tích thường chạy lâu và nặng: join trên bảng lớn, tổng hợp, sắp xếp và nhóm. Chúng có thể chiếm lõi CPU và, quan trọng không kém, bộ nhớ cho hash join và bộ đệm sắp xếp.
Trong khi đó, truy vấn giao dịch thường nhỏ nhưng nhạy độ trễ. Nếu CPU đầy hoặc áp lực bộ nhớ buộc phải đẩy bộ đệm, những truy vấn nhỏ đó bắt đầu chờ phía sau các truy vấn lớn — ngay cả khi mỗi giao dịch chỉ cần vài mili-giây công việc thực sự.
Đĩa I/O: lượt quét lớn vs nhiều đọc/ghi nhỏ
Phân tích thường kích hoạt các lượt quét bảng lớn và đọc nhiều trang theo tuần tự. OLTP thì ngược lại: nhiều đọc/ghi nhỏ, ngẫu nhiên cùng với ghi liên tục vào index và log.
Đặt chúng chung thì hệ thống lưu trữ phải xử lý các mẫu truy cập xung khắc. Cache giúp OLTP có thể bị “rửa sạch” bởi lượt quét phân tích, và độ trễ ghi có thể tăng khi đĩa bận truyền dữ liệu cho báo cáo.
Áp lực pool kết nối và hàng đợi
Vài analyst chạy truy vấn rộng có thể chiếm kết nối trong vài phút. Nếu app dùng pool kích thước cố định, các request sẽ xếp hàng chờ kết nối trống. Hiệu ứng hàng đợi làm hệ thống lành mạnh trông như hỏng: độ trễ trung bình có thể ổn, nhưng độ trễ ngóc (p95/p99) đau đớn.
Người dùng thấy gì
Bên ngoài, biểu hiện là timeout, quy trình checkout chậm, kết quả tìm kiếm dời trễ và hành vi lởm chởm — thường “chỉ khi báo cáo chạy” hoặc “chỉ cuối tháng”. Đội app thấy lỗi; đội analytics thấy truy vấn chậm; vấn đề thực sự là cạnh tranh tài nguyên chung bên dưới.
Bố cục dữ liệu và nhu cầu chỉ mục kéo theo hướng ngược nhau
OLTP và OLAP không chỉ “dùng cơ sở dữ liệu khác nhau” — chúng khuyến khích các thiết kế vật lý trái chiều. Khi bạn cố làm vừa cho cả hai, thường sẽ nhận được giải pháp làm nhiều thứ nhưng đều dưới mức tối ưu.
OLTP: tối ưu cho tra cứu nhanh, chọn lọc
Workload giao dịch thống trị bởi các truy vấn ngắn chạm vào lát dữ liệu nhỏ: lấy một đơn, cập nhật một dòng tồn kho, liệt kê 20 sự kiện gần nhất cho một user.
Điều đó đẩy schema OLTP về lưu trữ theo hàng và chỉ mục hỗ trợ tìm điểm và scan phạm vi nhỏ (thường trên primary key, foreign key và vài secondary index giá trị cao). Mục tiêu là độ trễ dự đoán thấp — đặc biệt cho ghi.
OLAP: tối ưu cho quét, nhóm và tóm tắt
Workload phân tích thường cần đọc nhiều hàng nhưng ít cột: “doanh thu theo tuần theo vùng”, “tỷ lệ chuyển đổi theo chiến dịch”, “sản phẩm bán chạy theo biên lợi nhuận”.
OLAP hưởng lợi từ lưu trữ cột (chỉ đọc những cột cần), partitioning (lọc nhanh dữ liệu cũ/không liên quan) và tiền tổng hợp (materialized views, rollups, bảng tóm tắt) để báo cáo không phải tính lại cùng số liệu nhiều lần.
Tại sao “tạo chỉ mục cho mọi thứ” phản tác dụng
Phản ứng phổ biến là thêm chỉ mục cho đến khi mọi dashboard nhanh. Nhưng mỗi chỉ mục thêm tăng chi phí ghi: insert, update, delete phải duy trì thêm cấu trúc. Nó cũng tăng lưu trữ và làm chậm các tác vụ bảo trì như vacuum, reindex và backup.
Bộ lập kế hoạch truy vấn và thống kê lệch (nói dễ hiểu)
Cơ sở dữ liệu chọn kế hoạch truy vấn dựa trên thống kê — ước lượng bao nhiêu hàng khớp filter, độ chọn lọc của chỉ mục và phân phối dữ liệu. OLTP thay đổi dữ liệu liên tục. Khi phân phối trôi dạt, thống kê lệch và planner có thể chọn kế hoạch tốt cho ngày hôm qua nhưng chậm hôm nay.
Thêm các truy vấn OLAP nặng quét và join lớn, bạn có tính biến động cao hơn: “kế hoạch tốt nhất” khó dự đoán, và tuning cho workload này thường làm workload kia tệ đi.
Khóa, MVCC và tác dụng phụ bảo trì
Ngay cả khi cơ sở dữ liệu “hỗ trợ đồng thời”, việc trộn báo cáo nặng với giao dịch trực tiếp tạo ra các chậm trễ tinh vi khó dự đoán — và càng khó giải thích với khách hàng đang nhìn vòng xoay chờ thanh toán.
Truy vấn dài vẫn gây rối khóa
Truy vấn kiểu OLAP thường quét nhiều hàng, join nhiều bảng và chạy vài giây hoặc vài phút. Trong thời gian đó chúng có thể giữ khóa (ví dụ trên đối tượng schema, hoặc khi cần sắp xếp/tổng hợp vào cấu trúc tạm) và chúng thường tăng cạnh tranh khóa gián tiếp bằng cách giữ nhiều hàng “đang chơi”.
Ngay cả với MVCC (multi-version concurrency control), cơ sở dữ liệu phải theo dõi nhiều phiên bản của cùng một dòng để reader và writer không chặn nhau. Điều đó giúp, nhưng không loại bỏ cạnh tranh — đặc biệt khi truy vấn chạm vào các bảng nóng mà giao dịch cập nhật liên tục.
MVCC có chi phí ẩn: dọn dẹp trở nên khó hơn
MVCC nghĩa là phiên bản hàng cũ tồn tại cho tới khi DB có thể an toàn xóa chúng. Một báo cáo chạy lâu có thể giữ snapshot cũ mở, ngăn dọn dẹp giải phóng không gian.
Điều đó ảnh hưởng đến:
- Vacuum/garbage collection: không thể xóa dead tuples/phiên bản nhanh.
- Bloat/fragmentation: lưu trữ phình to, index kém hiệu quả, cache kém hữu ích.
- Áp lực compact: một số engine làm việc nền nặng hơn, lấy I/O và CPU từ giao dịch.
Kết quả là một đòn kép: báo cáo làm DB làm việc nhiều hơn và làm hệ thống chậm dần theo thời gian.
Mức cô lập làm tăng biến động độ trễ
Công cụ báo cáo thường yêu cầu mức cô lập cao hơn (hoặc vô tình chạy trong transaction dài). Mức cô lập cao hơn có thể tăng thời gian chờ các khóa và lượng phiên bản engine phải quản lý. Từ góc OLTP, bạn thấy spike không đoán trước: phần lớn đơn ghi nhanh, nhưng vài đơn đột nhiên bị chậm.
Ví dụ thực tế: báo cáo cuối tháng làm chậm đơn hàng
Cuối tháng, finance chạy truy vấn “doanh thu theo sản phẩm” quét orders và line items cả tháng. Trong khi nó chạy, các ghi đơn mới vẫn được chấp nhận, nhưng vacuum không thể thu hồi phiên bản cũ và index churn. API đặt hàng bắt đầu gặp timeouts — không phải vì nó “sập”, mà vì cạnh tranh và overhead dọn dẹp âm thầm đẩy độ trễ vượt quá giới hạn.
Tính nhấp nhô của workload và độ trễ không đoán trước
Tạo bảng và API tự động
Mô tả orders, payments và báo cáo để Koder.ai phác thảo bảng và API.
Hệ thống OLTP sống và chết bởi tính dự đoán. Một checkout, ticket hỗ trợ hay cập nhật số dư không thể chỉ “ổn phần lớn” — người dùng để ý tới các khoảnh khắc chậm. OLAP thì thường đột biến: vài truy vấn nặng có thể im lặng hàng giờ rồi bất ngờ tiêu thụ nhiều CPU, bộ nhớ và I/O.
Spikes xảy ra vì lý do bình thường
Lưu lượng phân tích hay tụ tập quanh các thói quen:
- Dashboard "standup buổi sáng" nơi nhiều người refresh cùng lúc
- Báo cáo theo lịch cùng khởi chạy đúng giờ
- Đóng sổ cuối tháng/quý kích hoạt các lượt quét và join dài
Trong khi đó, tải OLTP thường ổn định hơn. Khi cả hai chia sẻ một DB, các đợt spike phân tích biến thành độ trễ không đoán cho giao dịch — timeouts, trang chậm và retry khiến tải tăng thêm.
Tại sao giới hạn và lịch trình giúp — nhưng không giải quyết triệt để
Bạn có thể giảm tổn thất với chiến thuật như chạy báo cáo ban đêm, giới hạn concurrency, enforce statement timeouts hoặc đặt query cost caps. Đây là các biện pháp bảo vệ hữu ích, đặc biệt khi “báo cáo trên production”.
Nhưng chúng không loại bỏ mâu thuẫn cơ bản: truy vấn OLAP được thiết kế để dùng nhiều tài nguyên để trả lời câu hỏi lớn, trong khi OLTP cần lát tài nguyên nhỏ, nhanh suốt ngày. Khi một dashboard bất ngờ refresh, truy vấn ad-hoc hoặc backfill lọt qua, cơ sở dữ liệu chia sẻ lại lộ ra điểm yếu.
Vấn đề hàng xóm ồn ào
Trên hạ tầng chia sẻ, một người dùng phân tích hoặc job “ồn” có thể chiếm cache, làm bão hoà đĩa hoặc áp lực schedule CPU — mà không làm gì sai. Workload OLTP trở thành thiệt hại phụ, và khó nhất là các lỗi trông ngẫu nhiên: spike độ trễ thay vì lỗi lặp lại rõ ràng.
Độ phức tạp vận hành: Backup, bảo mật và hoạch định dung lượng
Trộn OLTP (giao dịch) và OLAP (phân tích) không chỉ tạo ra đau đầu hiệu năng — nó còn làm các công việc vận hành hàng ngày khó hơn. Cơ sở dữ liệu trở thành một “hộp mọi thứ”, và mọi nhiệm vụ vận hành mang rủi ro kết hợp của cả hai workload.
Backup, restore và DR chậm lại
Bảng phân tích thường lớn và mở rộng nhanh (nhiều lịch sử, nhiều cột, nhiều tổng hợp). Khối lượng này thay đổi câu chuyện phục hồi.
Một backup đầy đủ mất lâu hơn, tiêu thụ nhiều lưu trữ hơn và làm tăng khả năng bạn trễ cửa sổ backup. Restore tệ hơn: khi cần phục hồi nhanh, bạn đang restore cả dữ liệu giao dịch cần cho app lẫn các dataset phân tích lớn không cần để doanh nghiệp hoạt động lại. Kiểm thử disaster recovery cũng lâu hơn, nên xảy ra ít hơn — điều ngược lại với mong muốn.
Hoạch định dung lượng trở nên đoán mò
Tăng trưởng giao dịch thường có thể dự đoán: nhiều khách hàng hơn, nhiều đơn hơn, nhiều hàng hơn. Tăng trưởng phân tích lại lồi lõm: một dashboard mới, chính sách retention mới, hoặc một đội quyết định lưu “thêm một năm” các event thô.
Khi cả hai sống chung, bạn khó trả lời:
- Thuật toán tăng vì sản phẩm thành công hay vì báo cáo lưu thêm lịch sử?
- Chúng ta cần storage nhanh cho giao dịch, hay storage rẻ cho analytics?
Sự không chắc này dẫn đến overprovisioning (trả tiền cho headroom không cần) hoặc underprovisioning (outage bất ngờ).
Khung bảo vệ khó áp dụng công bằng
Trong DB chia sẻ, một truy vấn “vô hại” có thể biến thành incident. Bạn sẽ thêm guardrail như statement timeouts, quota workload, cửa sổ báo cáo theo lịch, hoặc quy tắc quản lý workload. Chúng hữu ích, nhưng mong manh: app và analyst giờ cạnh tranh cùng giới hạn, và thay đổi chính sách cho nhóm này có thể phá nhóm kia.
Bảo mật và kiểm soát truy cập trở nên lộn xộn
Ứng dụng thường cần quyền hẹp, mục đích rõ ràng. Các analyst thì cần quyền đọc rộng, đôi khi trên nhiều bảng, để khám phá và kiểm chứng. Đặt cả hai trong một DB tăng áp lực cấp quyền rộng hơn “để báo cáo chạy”, làm tăng phạm vi lỗi và mở rộng số người có thể thấy dữ liệu nhạy cảm.
Scale và chi phí: Bạn sẽ trả gấp đôi (hoặc hơn)
Kiếm credits cho bài viết của bạn
Xuất bản về dự án của bạn và nhận credits Koder.ai để tiếp tục phát triển.
Cố gắng chạy OLTP và OLAP cùng một DB thường trông rẻ hơn — cho tới khi bạn bắt đầu scale. Vấn đề không chỉ là hiệu năng. Cách “đúng” để scale mỗi workload đẩy bạn tới hạ tầng khác nhau, và kết hợp chúng ép bạn vào các đánh đổi tốn kém.
Scale OLTP thiên về ghi (và thường đau đầu)
Hệ thống giao dịch bị giới hạn bởi ghi: nhiều cập nhật nhỏ, độ trễ nghiêm ngặt, và đợt tăng phải chịu ngay lập tức. Scale OLTP thường nghĩa là scale theo chiều dọc (CPU lớn hơn, đĩa nhanh hơn, nhiều bộ nhớ) vì workload ghi khó phân tán.
Khi đạt giới hạn chiều dọc, bạn nghĩ tới sharding hoặc các pattern scale write khác. Điều đó làm tăng overhead engineering và thường yêu cầu thay đổi cẩn thận ở tầng ứng dụng.
Scale OLAP thiên về compute (và thường có thể co dãn)
Workload phân tích scale khác: lượt quét dài, tổng hợp nặng và throughput đọc lớn. Hệ thống OLAP thường scale bằng cách thêm compute phân tán, và nhiều kiến trúc hiện đại tách compute khỏi storage để có thể mở rộng sức mạnh truy vấn mà không phải nhân bản dữ liệu.
Nếu OLAP chia sẻ DB OLTP, bạn không thể scale analytics độc lập. Bạn phải scale toàn bộ DB — dù giao dịch có ổn hay không.
Hoá đơn ẩn: trả giá cho tài nguyên kiểu OLTP để chạy analytics
Để giữ giao dịch nhanh khi chạy báo cáo, các đội over-provision DB production: CPU thừa, storage cao cấp, và instance lớn “phòng hờ”. Điều đó nghĩa là bạn trả giá OLTP để hỗ trợ OLAP.
Tách biệt làm giảm over-provisioning vì mỗi hệ thống được sizing theo nhiệm vụ của nó: OLTP cho ghi độ trễ thấp, OLAP cho đọc nặng. Kết quả thường rẻ hơn tổng thể — dù là “hai hệ thống” — vì bạn không còn mua tài nguyên cao cấp cho mục đích báo cáo.
Kiến trúc phổ biến giữ OLTP và OLAP tách biệt
Hầu hết đội tách workload giao dịch (OLTP) khỏi workload phân tích (OLAP) bằng cách thêm hệ thống thứ hai “hướng đọc” thay vì ép một DB phục vụ cả hai.
Mô hình 1: Read replica cho báo cáo
Bước đầu phổ biến là một read replica (follower) của DB OLTP, nơi các công cụ BI chạy truy vấn.
Ưu: thay đổi app tối thiểu, SQL quen thuộc, thiết lập nhanh.
Nhược: vẫn cùng engine và schema, nên báo cáo nặng có thể saturate CPU/I/O của replica; một số báo cáo cần tính năng không có trên replica; và độ trễ sao chép có thể khiến số liệu chênh vài phút (hoặc hơn). Độ trễ còn gây nhầm lẫn "tại sao không khớp production?" khi điều tra sự cố.
Phù hợp nhất: đội nhỏ, dữ liệu khiêm tốn, "gần thời gian thực" là tốt nhưng không bắt buộc, và truy vấn báo cáo được kiểm soát.
Mô hình 2: Data warehouse / DB phân tích riêng
Ở đây, OLTP vẫn tối ưu cho ghi và tra cứu điểm, trong khi phân tích chuyển sang data warehouse (hoặc DB columnar) thiết kế cho quét, nén và tổng hợp lớn.
Ưu: hiệu năng OLTP ổn định, dashboard nhanh hơn, concurrency tốt hơn cho analyst, và dễ tinh chỉnh chi phí/hiệu năng.
Nhược: bạn phải vận hành thêm một hệ thống và cần mô hình dữ liệu (thường star schema) thân thiện cho phân tích.
Phù hợp nhất: dữ liệu lớn hơn, nhiều stakeholder, báo cáo phức tạp, hoặc yêu cầu độ trễ OLTP nghiêm ngặt.
Mô hình 3: Pipeline dựa trên CDC vào analytics
Thay vì ETL theo lịch, bạn stream thay đổi bằng CDC (change data capture) từ log OLTP vào warehouse (thường cùng với ELT).
Ưu: dữ liệu tươi hơn với tải nhỏ lên OLTP, dễ xử lý tăng dần, và audit tốt hơn.
Nhược: nhiều thành phần hơn và cần xử lý cẩn thận khi schema thay đổi.
Phù hợp nhất: khối lượng lớn, yêu cầu độ tươi cao và đội sẵn sàng vận hành pipeline dữ liệu.
Chuyển dữ liệu từ OLTP sang OLAP an toàn
Di chuyển dữ liệu từ DB giao dịch vào hệ thống phân tích không chỉ là “sao chép bảng” mà là xây dựng pipeline đáng tin cậy, ít ảnh hưởng. Mục tiêu đơn giản: analytics có những gì cần, mà không gây rủi ro cho traffic production.
ETL vs ELT (phiên bản dễ hiểu)
ETL (Extract, Transform, Load) nghĩa là bạn làm sạch và biến đổi dữ liệu trước khi đưa vào warehouse. Hữu ích khi tính toán trong warehouse tốn kém hoặc bạn muốn kiểm soát chặt dữ liệu lưu.
ELT (Extract, Load, Transform) nạp dữ liệu thô trước, rồi biến đổi bên trong warehouse. Thường triển khai nhanh hơn và dễ thay đổi: bạn giữ lịch sử nguồn và có thể điều chỉnh biến đổi khi yêu cầu thay đổi.
Quy tắc thực tế: nếu logic nghiệp vụ thay đổi thường xuyên, ELT giảm lượng làm lại; nếu governance yêu cầu chỉ lưu dữ liệu đã curate, ETL có thể phù hợp hơn.
CDC cơ bản: bắt thay đổi mà không quét nặng
Change Data Capture (CDC) stream insert/update/delete từ OLTP (thường từ log) vào hệ thống phân tích. Thay vì quét lặp các bảng lớn, CDC cho phép bạn chuyển chỉ những gì thay đổi.
Nó cho phép:
- Báo cáo gần thời gian thực mà không chạy đọc lớn trên production
- Replay và backfill khi cần dựng lại bảng phân tích
- Theo dõi lịch sử (ai thay đổi gì, khi nào) nếu bạn lưu event thay đổi
Độ tươi dữ liệu: realtime vs near-real-time vs hàng ngày
Độ tươi là quyết định kinh doanh với chi phí kỹ thuật.
- Real-time (giây): tốt cho dashboard vận hành, nhưng khó duy trì ổn định; sự cố pipeline nhỏ thể hiện ngay.
- Near-real-time (phút): điểm cân bằng phổ biến — đủ tốt để ra quyết định mà không quá phức tạp.
- Batches hàng ngày: đơn giản và rẻ nhất, phù hợp báo cáo kiểu tài chính "hôm qua".
Đặt SLA rõ (ví dụ: “dữ liệu trễ tối đa 15 phút”) để các bên hiểu "tươi" nghĩa là gì.
Kiểm tra chất lượng dữ liệu để tránh lỗi im lặng
Pipeline thường vỡ âm thầm — cho tới khi ai đó phát hiện số liệu sai. Thêm các kiểm tra nhẹ cho:
- Thay đổi schema: cột mới, đổi tên, hoặc thay đổi kiểu có thể làm mất dữ liệu.
- Sự kiện đến muộn: đơn hoặc thanh toán xuất hiện sau giờ; xử lý bằng "lookback window".
- Deduplication: retry và replay có thể đếm đôi; dùng ID ổn định và nạp idempotent.
Những biện pháp này giữ OLAP đáng tin cậy trong khi bảo vệ OLTP.
Khi chia sẻ một DB có thể chấp nhận được
Giới thiệu đồng đội và nhận thưởng
Mời đồng đội tham gia và nhận credits khi người mới đăng ký.
Giữ OLTP và OLAP cùng nhau không tự động sai. Nó có thể hợp lý tạm thời khi app nhỏ, nhu cầu báo cáo hẹp, và bạn có thể thực thi ranh giới cứng để analytics không bất ngờ làm chậm checkout, thất bại thanh toán hoặc timeout.
Tình huống phù hợp
Ứng dụng nhỏ với phân tích nhẹ và giới hạn truy vấn chặt thường ổn trên một DB — đặc biệt ở giai đoạn đầu. Chìa khóa là trung thực về “nhẹ”: vài dashboard, số hàng khiêm tốn và giới hạn rõ thời gian chạy/concurrency.
Cho một tập báo cáo định kỳ hẹp, materialized views hoặc bảng tóm tắt có thể giảm chi phí phân tích. Thay vì quét giao dịch thô, bạn tiền tính toán tổng theo ngày, top category, hay rollup theo khách hàng. Điều này giữ truy vấn ngắn và dự đoán được.
Nếu người dùng chấp nhận số liệu trễ, chạy báo cáo ngoài giờ cao điểm giúp. Lên lịch job nặng vào đêm hoặc giờ thấp tải, và cân nhắc role báo cáo riêng với quyền và giới hạn tài nguyên chặt hơn.
Quy tắc bảo vệ nên thêm
- Đặt statement timeouts và huỷ truy vấn chạy quá lâu.
- Hạn chế concurrency cho người dùng báo cáo.
- Giám sát p95/p99 độ trễ cho giao dịch riêng biệt với báo cáo.
Dấu hiệu rõ ràng nên tách
Nếu bạn thấy latency giao dịch tăng, incident tái diễn khi báo cáo chạy, pool kết nối cạn kiệt, hoặc câu chuyện “một truy vấn làm sập production”, bạn đã vượt khỏi vùng an toàn. Khi đó, tách DB (hoặc ít nhất dùng replica) là vệ sinh vận hành cơ bản chứ không còn là tối ưu nữa.
Checklist di chuyển thực tế: từ chia sẻ sang tách biệt
Chuyển analytics ra khỏi DB production ít là một "việc lớn" mà là làm cho công việc hiển hiện, đặt mục tiêu và di chuyển từng bước kiểm soát.
1) Kiểm kê hiện trạng
Bắt đầu từ bằng chứng, không phải giả định. Lấy danh sách:
- Các endpoint/truy vấn OLTP hàng đầu theo tần suất và p95/p99 latency (checkout, login, create order, v.v.)
- Các báo cáo/dashboard OLAP hàng đầu theo thời gian chạy, khối lượng quét và tầm quan trọng kinh doanh
Bao gồm cả "analytics ẩn": SQL ad-hoc từ BI tools, export theo lịch, và download CSV.
2) Đặt mục tiêu: SLO OLTP và độ tươi analytics
Ghi rõ mục tiêu bạn sẽ tối ưu:
- OLTP SLO: p95/p99 latency, tỷ lệ lỗi và throughput đỉnh
- Độ tươi analytics: trễ chấp nhận được (5 phút, 1 giờ, ngày hôm sau), và thời gian rebuild khi pipeline gãy
Điều này tránh tranh luận kiểu “chậm” vs “ổn” và giúp chọn kiến trúc phù hợp.
3) Chọn lộ trình tách
Chọn phương án đơn giản nhất đạt mục tiêu:
- Read replica: nhanh để áp dụng cho báo cáo đọc nặng, nhưng vẫn có điểm yếu về lag và giới hạn CPU của replica
- Warehouse: phù hợp cho quét lớn, nhiều join và lịch sử dài; thường là nhà của BI
- CDC pipeline (ETL/ELT): phù hợp khi cần gần thời gian thực mà không ảnh hưởng sản xuất
4) Triển khai an toàn (chạy song song trước)
- Xác thực định nghĩa (timezone, refund, "user active", v.v.) để số liệu khớp.
- Chạy dashboard cũ và mới song song trong một chu kỳ kinh doanh đầy đủ.
- Chuyển từng báo cáo một, bắt đầu với truy vấn đau đầu nhất.
- Khoá quyền truy cập trực tiếp "báo cáo trên production" khi stakeholders tin nguồn mới.
5) Thêm guardrail tránh tụt lùi
Giám sát replica lag/pipeline delays, thời gian chạy dashboard và chi phí warehouse. Đặt ngân sách truy vấn (timeouts, concurrency limits) và giữ playbook incident: làm gì khi độ tươi trượt, tải spike hoặc số liệu lệch.
Ghi chú thực tế nếu bạn xây app
Nếu bạn đang ở giai đoạn đầu và phát triển nhanh, rủi ro lớn là vô tình xây analytics dính vào đường dẫn cơ sở dữ liệu same-as-core transactions (ví dụ truy vấn dashboard trở thành “quan trọng cho production”). Cách tránh là thiết kế tách biệt ngay từ đầu — dù khởi đầu bằng read replica khiêm tốn — và đưa điều đó vào checklist kiến trúc.
Các nền tảng như Koder.ai có thể giúp vì bạn có thể prototype phần OLTP (React app + Go services + PostgreSQL) và phác thảo ranh giới reporting/warehouse trong planning mode trước khi release. Khi sản phẩm lớn lên, bạn có thể xuất code, phát triển schema và thêm thành phần CDC/ELT mà không biến "báo cáo trên production" thành thói quen vĩnh viễn.