09 thg 9, 2025·8 phút
Cách tạo một trang trạng thái SaaS kèm lịch sử sự cố
Học cách lập kế hoạch, xây dựng và xuất bản trang trạng thái SaaS có lịch sử sự cố, thông điệp rõ ràng và đăng ký nhận thông báo để khách hàng luôn được cập nhật khi có gián đoạn.
Trang trạng thái SaaS là gì (và tại sao nó quan trọng)
Trang trạng thái SaaS là một trang công khai (hoặc chỉ cho khách hàng) cho biết sản phẩm của bạn có hoạt động ngay bây giờ hay không — và bạn đang làm gì nếu nó không hoạt động. Nó trở thành nguồn thông tin duy nhất khi có sự cố, tách biệt với mạng xã hội, vé hỗ trợ và tin đồn.
Nó giúp nhiều nhóm hơn bạn nghĩ:\n
- Khách hàng có thể nhanh chóng xác nhận “Có phải chỉ mình tôi bị không?” và quyết định chờ, thử lại, hoặc dùng biện pháp tạm thời.\n- Đội hỗ trợ có thể liên kết đến một cập nhật chính thức thay vì lặp lại giải thích trong hàng chục vé.\n- Bán hàng và Customer Success có thể chủ động quản lý gia hạn và tài khoản quan trọng bằng thông tin chính xác có dấu thời gian.
Trạng thái thời gian thực vs. lịch sử sự cố vs. postmortem
Một trang trạng thái tốt thường có ba lớp liên quan (nhưng khác nhau):
- Trạng thái thời gian thực: phần nào đang hoạt động, ngưng, hoặc suy giảm ngay bây giờ trên các thành phần (API, bảng điều khiển, thanh toán, v.v.).
- Trang lịch sử sự cố: một dòng thời gian các sự cố và bảo trì trong quá khứ, để khách hàng hiểu xu hướng và thấy rằng các vấn đề đã được xử lý.
- Báo cáo sau sự cố (postmortem): bài viết chi tiết hơn giải thích nguyên nhân gốc rễ, bản sửa và các bước phòng ngừa. Chúng có thể công khai hoặc chia sẻ riêng với các khách hàng bị ảnh hưởng.
Mục tiêu là rõ ràng: trạng thái thời gian thực trả lời “Tôi có thể dùng sản phẩm không?” trong khi lịch sử trả lời “Việc này xảy ra thường xuyên thế nào?” và postmortem trả lời “Tại sao điều này xảy ra, và đã thay đổi gì?”.
Thiết lập kỳ vọng: minh bạch, nhanh chóng và rõ ràng
Trang trạng thái chỉ hiệu quả khi các cập nhật nhanh, dễ hiểu, và thẳng thắn về mức độ ảnh hưởng. Bạn không cần chẩn đoán hoàn hảo để thông báo. Bạn cần có dấu thời gian, phạm vi (ai bị ảnh hưởng), và thời gian cập nhật tiếp theo.
Những lúc bạn sẽ dùng trang trạng thái
Bạn sẽ cần nó khi mất dịch vụ, hiệu năng suy giảm (đăng nhập chậm, webhook bị trễ), và bảo trì theo lịch có thể gây gián đoạn ngắn.
Khi bạn coi trang trạng thái như một giao diện sản phẩm (không phải một trang vận hành làm một lần), phần còn lại của quy trình sẽ dễ dàng hơn: bạn có thể định nghĩa người chịu trách nhiệm, tạo mẫu, và kết nối giám sát mà không phải phát minh lại trong mỗi sự cố.
Đặt mục tiêu, xác định khán giả và người chịu trách nhiệm
Trước khi chọn công cụ hay thiết kế giao diện, quyết định trang trạng thái của bạn nhằm làm gì. Một mục tiêu rõ ràng và một người chịu trách nhiệm rõ ràng giữ trang trạng thái hữu ích trong sự cố — khi mọi người bận rộn và thông tin lộn xộn.
Xác định mục tiêu (thành công trông như thế nào)
Hầu hết đội SaaS tạo trang trạng thái để đạt ba kết quả thực tế:
- Giảm vé hỗ trợ bằng cách trả lời “Có bị sập không?” ở một nơi công khai\n- Xây dựng niềm tin bằng các cập nhật kịp thời, dễ hiểu\n- Tăng tốc giao tiếp giữa Hỗ trợ, Kỹ thuật, Bán hàng và Customer Success
Ghi lại 2–3 tín hiệu có thể đo lường sau khi ra mắt: ít vé trùng lặp hơn trong sự cố, thời gian đến cập nhật đầu tiên nhanh hơn, hoặc nhiều khách hàng đăng ký nhận thông báo.
Xác định khán giả và mức độ hiểu biết
Độc giả chính thường là khách hàng không chuyên kỹ thuật muốn biết:\n
- Sản phẩm có hoạt động ngay bây giờ không?\n- Điều gì bị ảnh hưởng (đăng nhập, API, thanh toán, v.v.)?\n- Tôi nên làm gì tiếp theo?\n- Khi nào sẽ được khắc phục?
Điều này có nghĩa là hạn chế thuật ngữ. Ưu tiên “Một số khách hàng không thể đăng nhập” hơn “Elevated 5xx rates on auth.” Nếu cần chi tiết kỹ thuật, để nó thành một câu ngắn phụ.
Chọn tông giọng, quy tắc và người chịu trách nhiệm
Chọn tông bạn có thể duy trì khi áp lực: bình tĩnh, thực tế và minh bạch. Quyết định trước:\n
- Ai được đăng cập nhật (một vai trò duy nhất hoặc vòng trực)
- Ai phê duyệt cập nhật (nếu có) và thời gian phê duyệt cho phép\n- Tần suất cập nhật tối thiểu khi sự cố đang diễn ra (ví dụ, mỗi 30 phút)
Làm cho việc chịu trách nhiệm rõ ràng: trang trạng thái không nên là “việc của mọi người”, nếu không sẽ thành việc của không ai.
Quyết định nơi đặt trang trạng thái
Có hai lựa chọn phổ biến:\n
- Site độc lập (ví dụ, status.yourcompany.com): tách biệt rõ ràng và thường chống chịu sự cố tốt hơn\n- Subpath (ví dụ, /status): đơn giản về thương hiệu và phân tích
Nếu ứng dụng chính của bạn có thể sập, site độc lập thường an toàn hơn. Bạn vẫn có thể liên kết nổi bật từ app và trung tâm trợ giúp (ví dụ, /help).
Lập bản đồ dịch vụ và mô hình trạng thái thành phần
Trang trạng thái chỉ hữu ích bằng “bản đồ” đằng sau nó. Trước khi chọn màu hay viết nội dung, quyết định bạn đang báo cáo gì. Mục tiêu là phản ánh cách khách hàng trải nghiệm sản phẩm — không phải cách tổ chức của bạn được sắp xếp.
Bắt đầu với kiểm kê thành phần
Liệt kê các phần mà khách hàng có thể mô tả khi họ nói “nó hỏng”. Với nhiều SaaS, bộ khởi đầu thực tế thường là:\n
- API\n- Ứng dụng web\n- Bảng điều khiển / admin\n- Xác thực (đăng nhập, SSO)\n- Thanh toán\n- Tích hợp (Slack, Salesforce, webhooks, v.v.)
Nếu bạn cung cấp nhiều vùng hoặc bậc dịch vụ, ghi cả vào (ví dụ, “API – US” và “API – EU”). Giữ tên dễ hiểu cho khách hàng: “Đăng nhập” rõ ràng hơn “IdP Gateway.”
Quyết định cách nhóm các thành phần
Chọn nhóm phù hợp với cách khách hàng nghĩ về dịch vụ của bạn:\n
- Theo sản phẩm: tốt nếu bạn có các dịch vụ riêng biệt (Sản phẩm A vs. Sản phẩm B)\n- Theo vùng: tốt nếu khả năng sẵn có khác biệt đáng kể theo địa lý\n- Theo tính năng/quy trình: tốt nếu khách hàng phụ thuộc vào công việc cụ thể (Báo cáo, Nhập liệu, Thông báo)
Tránh danh sách dài vô tận. Nếu bạn có hàng chục tích hợp, cân nhắc một thành phần cha (“Tích hợp”) và vài con con quan trọng (ví dụ, “Salesforce”, “Webhooks”).
Định nghĩa các mức trạng thái (và ý nghĩa của chúng)
Một mô hình đơn giản, nhất quán ngăn nhầm lẫn trong sự cố. Các mức phổ biến gồm:\n
- Operational: hoạt động như mong đợi\n- Degraded Performance: chậm hơn bình thường hoặc lỗi gián đoạn\n- Partial Outage: một tập con người dùng/tính năng bị mất\n- Major Outage: dịch vụ bị gián đoạn rộng rãi
Viết tiêu chí nội bộ cho từng mức (dù bạn không công bố). Ví dụ, “Partial Outage = một vùng bị sập” hoặc “Degraded = p95 latency vượt X trong Y phút.” Tính nhất quán xây dựng niềm tin.
Ghi lại phụ thuộc — và chọn những gì hiển thị
Hầu hết sự cố liên quan bên thứ ba: cloud hosting, gửi email, nhà cung cấp thanh toán, hoặc nhà cung cấp danh tính. Ghi lại các phụ thuộc này để cập nhật sự cố chính xác.
Có hiển thị chúng công khai hay không tuỳ vào khán giả. Nếu khách hàng bị ảnh hưởng trực tiếp (ví dụ, thanh toán), hiển thị phụ thuộc có thể hữu ích. Nếu nó gây nhiễu hoặc đổ lỗi, giữ nội bộ nhưng tham chiếu khi cần (ví dụ, “Chúng tôi đang điều tra lỗi tăng cao từ nhà cung cấp thanh toán”).
Khi có mô hình thành phần, phần còn lại của việc thiết lập trang trạng thái trở nên dễ dàng hơn: mỗi sự cố có “ở đâu” (thành phần) và “mức độ xấu” (trạng thái) rõ ràng ngay từ đầu.
Thiết kế trang trạng thái thân thiện với khách hàng
Trang trạng thái hữu ích nhất khi nó trả lời câu hỏi của khách hàng trong vài giây. Mọi người thường đến trang khi đang lo lắng và cần sự rõ ràng — không phải nhiều điều hướng.
Bắt đầu với những gì khách hàng cần trước tiên
Ưu tiên những yếu tố cần thiết ở phần đầu trang:\n
- Trạng thái hiện tại: Mọi hệ thống có ổn không, hay suy giảm, hay sập?\n- Ảnh hưởng: Điều gì bị tác động (ai/khu vực/tính năng) và người dùng có thể gặp gì\n- ETA (nếu có): Cẩn trọng — chỉ chia sẻ ước tính thời gian bạn có thể bảo vệ\n- Thời gian cập nhật tiếp theo: Một lời hứa cụ thể như “Cập nhật tiếp trước 14:30 UTC” giảm số vé lặp lại
Viết bằng ngôn ngữ đơn giản. “Tăng tỉ lệ lỗi trên các yêu cầu API” rõ hơn “Partial outage in upstream dependency.” Nếu phải dùng thuật ngữ kỹ thuật, thêm một câu giải thích ngắn (“Một số yêu cầu có thể lỗi hoặc hết thời gian chờ”).
Dùng bố cục đơn giản, dễ quét
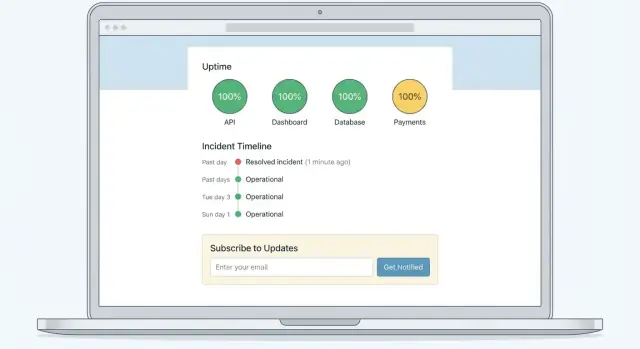
Mô hình đáng tin cậy là:\n
- Thanh đầu cho trạng thái tổng thể (All Systems Operational / Degraded Performance / Major Outage)\n2. Danh sách thành phần với trạng thái rõ ràng (Web App, API, Billing, Integrations, v.v.)\n3. Sự cố đang hoạt động và bảo trì đã lên lịch ngay bên dưới, sắp theo cập nhật mới nhất
Với danh sách thành phần, giữ nhãn dễ hiểu cho khách hàng. Nếu dịch vụ nội bộ là “k8s-cluster-2,” khách hàng có thể cần “API” hoặc “Background Jobs.”
Tiện ích truy cập và cơ bản trên di động
Làm cho trang dễ đọc khi khách hàng căng thẳng:\n
- Tương phản màu sắc mạnh và nhãn chữ (đừng chỉ phụ thuộc vào màu)\n- Biểu tượng rõ ràng với ý nghĩa nhất quán (ví dụ: xanh = hoạt động, vàng = suy giảm, đỏ = sập)\n- Thiết kế thân thiện di động; nhiều người kiểm tra từ điện thoại
Thêm các liên kết nhanh nơi khách hàng mong đợi
Đặt một vài liên kết nhỏ gần đầu (header hoặc ngay dưới banner):\n
- Subscribe (đăng ký nhận thông báo qua email/SMS/webhook)\n- Incident History (cho lịch sử sự cố và dòng thời gian)\n- Contact Support tại /support
Mục tiêu là sự tin tưởng: khách hàng nên hiểu ngay điều gì đang xảy ra, bị ảnh hưởng ra sao, và khi nào họ sẽ nhận được tin tiếp theo.
Tạo mẫu cập nhật sự cố và bảo trì
Khi có sự cố, đội bạn phải vừa chẩn đoán, vừa khắc phục, vừa trả lời thắc mắc khách hàng. Mẫu sẵn có loại bỏ sự bối rối để cập nhật nhất quán, rõ ràng và nhanh — nhất là khi nhiều người khác nhau đăng.
Xác định các trường thông tin bạn luôn công bố
Một cập nhật tốt bắt đầu với cùng những thông tin cốt lõi mỗi lần. Tối thiểu, chuẩn hóa các trường sau để khách hàng hiểu nhanh:\n
- Thời gian bắt đầu sự cố (có múi giờ)\n- Thành phần/dịch vụ bị ảnh hưởng (theo mô hình trạng thái của bạn)\n- Ảnh hưởng tới khách hàng (ai bị ảnh hưởng và như thế nào)\n- Trạng thái hiện tại (Investigating, Identified, Monitoring, Resolved)\n- Nhật ký cập nhật (các mục có dấu thời gian)\n- Thời gian khắc phục (khi dịch vụ trở lại bình thường)
Nếu bạn công bố trang lịch sử sự cố, giữ các trường này nhất quán giúp sự cố trong quá khứ dễ so sánh.
Dùng mẫu cập nhật sự cố đơn giản, lặp lại được
Hãy ngắn gọn và trả lời cùng nhóm câu hỏi mỗi lần. Mẫu thực tế bạn có thể sao chép vào công cụ trạng thái:
Title: Tóm tắt ngắn, cụ thể (ví dụ, “Lỗi API khu vực EU”)
Start time: YYYY-MM-DD HH:MM (TZ)
Affected components: API, Dashboard, Payments
Impact: Người dùng thấy gì (lỗi, hết thời gian chờ, hiệu năng kém) và ai bị ảnh hưởng
What we know: Một câu về nguyên nhân nếu đã xác nhận (tránh suy đoán)
What we’re doing: Các hành động cụ thể (rollback, mở rộng, liên hệ nhà cung cấp)
Next update: Thời gian bạn sẽ đăng tiếp
Updates:
- HH:MM (TZ) — Investigating: …\n- HH:MM (TZ) — Identified: …\n- HH:MM (TZ) — Monitoring: …\n- HH:MM (TZ) — Resolved: …
Đặt quy tắc tần suất cập nhật rõ ràng
Khách hàng không chỉ muốn thông tin — họ muốn tính dự đoán.\n
- Với sự cố lớn, cam kết cập nhật mỗi 30–60 phút, ngay cả khi nội dung là “Vẫn đang điều tra; chưa có ETA; cập nhật tiếp lúc X.”\n- Với vấn đề nhỏ, có thể ít thường xuyên hơn, nhưng vẫn hứa thời gian cập nhật tiếp theo.\n- Nếu bạn không thể giữ được tần suất, đăng ghi chú ngắn thừa nhận chậm trễ và điều chỉnh kỳ vọng.
Thêm mẫu thông báo bảo trì
Bảo trì đã lên lịch nên cảm thấy bình tĩnh và có cấu trúc. Chuẩn hóa bài đăng bảo trì với:
- Khung bảo trì: thời gian bắt đầu/kết thúc (có múi giờ)
- Ảnh hưởng mong đợi: none / degraded / intermittent / downtime
- Thành phần bị ảnh hưởng
- Hành động khách hàng (nếu có): “Không cần làm gì” hoặc các bước rõ ràng
- Cập nhật nhắc nhở: đăng khi bảo trì bắt đầu và khi kết thúc
Ngôn ngữ bảo trì nên cụ thể (thay đổi gì, người dùng có thể thấy gì), và tránh hứa hẹn quá mức — khách hàng trân trọng tính chính xác hơn là lạc quan.
Xây dựng lịch sử sự cố dễ quét
Keep control with export
Own the full codebase and adapt it to your stack when you are ready.
Trang lịch sử sự cố là hơn một nhật ký — nó giúp khách hàng (và đội bạn) nhanh chóng hiểu tần suất sự cố, loại vấn đề lặp lại, và cách phản ứng.\n
Tại sao lịch sử sự cố đáng đầu tư
Lịch sử rõ ràng xây dựng niềm tin qua minh bạch. Nó cũng tạo ra khả năng nhìn thấy xu hướng: nếu thấy “độ trễ API” lặp lại mỗi vài tuần, đó là dấu hiệu cần đầu tư cải thiện hiệu năng và ưu tiên post-incident review. Theo thời gian, báo cáo nhất quán có thể giảm vé hỗ trợ vì khách hàng tự trả lời được.
Quyết định thời gian lưu trữ: giữ bao lâu?
Chọn cửa sổ lưu trữ phù hợp với kỳ vọng khách hàng và độ trưởng thành sản phẩm.
- 90 ngày: phổ biến cho SaaS giai đoạn đầu, giữ trang nhẹ\n- 6–12 tháng: tốt cho khách hàng doanh nghiệp đánh giá độ tin cậy\n- Dài hơn: cân nhắc xuất bản bản ghi cũ ra trang lưu trữ riêng nếu dòng thời gian trở nên ồn
Dù chọn gì, nêu rõ (ví dụ: “Lịch sử sự cố được lưu 12 tháng”).
Làm cho mỗi mục dễ hiểu ngay lập tức
Sự nhất quán giúp quét nhanh. Dùng định dạng tên dễ đoán như:
YYYY-MM-DD — Tóm tắt ngắn (ví dụ, “2025-10-14 — Gửi email trễ”)
Mỗi sự cố nên hiển thị ít nhất:
- thành phần bị ảnh hưởng\n- thời gian bắt đầu/kết thúc (có múi giờ)\n- mức độ ảnh hưởng (nhỏ/lớn)\n- ghi chú ngắn về cách khắc phục
Liên kết tới nội dung chi tiết khi có
Nếu bạn xuất bản postmortem, liên kết từ chi tiết sự cố tới bài viết (ví dụ: “Đọc postmortem” liên kết tới blog postmortems). Điều này giữ cho dòng thời gian gọn nhưng vẫn cung cấp chi tiết cho khách muốn đọc thêm.
Thêm đăng ký và thông báo
Trang trạng thái hữu ích khi khách hàng nhớ kiểm tra nó. Đăng ký biến việc đó thành tự động: khách sẽ nhận cập nhật mà không cần làm mới trang hay gửi email cho hỗ trợ.
Cung cấp các kênh khách hàng đang dùng
Hầu hết đội cung cấp ít nhất một vài tùy chọn:\n
- Email (mặc định cho nhiều khách hàng)\n- SMS (tốt cho cảnh báo khẩn cấp)\n- Slack hoặc Microsoft Teams (lý tưởng cho khách doanh nghiệp và đội ops)\n- RSS/Atom (vẫn phổ biến với người dùng kỹ thuật và công cụ nội bộ)
Nếu hỗ trợ nhiều kênh, giữ luồng thiết lập nhất quán để khách không cảm thấy đang đăng ký theo bốn cách khác nhau.
Làm rõ việc đồng ý và tuỳ chọn
Đăng ký luôn phải opt-in. Rõ ràng về những gì người đăng ký sẽ nhận trước khi họ xác nhận — đặc biệt với SMS.
Cho phép người đăng ký kiểm soát:\n
- Phạm vi: tất cả sự cố vs chỉ thành phần chọn (ví dụ, “API” nhưng không phải “Marketing site”)\n- Loại: chỉ sự cố, chỉ bảo trì, hoặc cả hai\n- Mức độ (tuỳ chọn): chỉ “Major outage” vs “Tất cả cập nhật”\n Những tuỳ chọn này giảm mệt mỏi thông báo và giữ độ tin cậy cho thông báo. Nếu chưa có đăng ký theo thành phần, bắt đầu với “All updates” và bổ sung lọc sau.
Đừng để thông báo thất bại ngay khi cần nhất
Khi sự cố xảy ra, lưu lượng tin nhắn tăng và nhà cung cấp bên thứ ba có thể giới hạn. Kiểm tra:\n
- Khả năng gửi: SPF/DKIM/DMARC cho email; domain gửi đã xác thực; địa chỉ “from” mà khách nhận ra\n- Giới hạn tỷ lệ và throttling: giới hạn nhà cung cấp email/SMS, giới hạn webhook Slack/Teams, và hành vi thử lại\n- Phương án dự phòng: nếu Slack không gửi được, bạn có còn gửi email? Nếu SMS chậm, bạn có hiển thị banner rõ ràng trên trang trạng thái không?
Nên chạy bài kiểm tra định kỳ (khoảng hàng quý) để đảm bảo đăng ký hoạt động như mong muốn.
Đặt “Subscribe to updates” ở nơi ai cũng thấy
Thêm lời kêu gọi đăng ký rõ ràng trên trang trạng thái — ưu tiên trên màn hình nếu có thể — để khách đăng ký trước sự cố tiếp theo. Làm nó hiển thị trên di động và đưa liên kết này tới nơi khách tìm trợ giúp (như trong footer app hoặc trung tâm trợ giúp).
Chọn phương pháp xây dựng: Công cụ hosted hay tự làm
Plan the workflow first
Use Planning Mode to define owners, cadence rules, and workflows before you build.
Chọn cách xây dựng không phải “có thể xây không?” mà là bạn tối ưu cho điều gì: tốc độ ra mắt, độ bền khi có sự cố, và công sức bảo trì.
Lựa chọn 1: Dùng công cụ trạng thái hosted
Công cụ hosted thường là con đường nhanh nhất. Bạn có trang trạng thái sẵn, đăng ký, dòng thời gian sự cố, và thường tích hợp với hệ thống giám sát.
Nên tìm gì ở công cụ hosted:\n
- Độ tin cậy và độc lập: trang trạng thái nên truy cập được ngay cả khi app chính của bạn sập\n- API và tự động hóa: tạo sự cố, cập nhật thành phần và đăng tiến trình qua API hoặc webhook\n- Kiểm soát truy cập: vai trò ai được đăng so với draft; SSO là điểm cộng\n- Branding và domain tuỳ chỉnh: logo/màu, và domain như status.yourcompany.com\n- Phân tích: số lượng người đăng ký, lượt xem cập nhật, và số liệu giao hàng email\n- Yêu cầu tuân thủ: audit log và lưu trữ nếu bạn hoạt động trong môi trường bị quy định
Lựa chọn 2: Tự xây (DIY)
DIY phù hợp nếu bạn muốn toàn quyền kiểm soát thiết kế, dữ liệu và cách hiển thị lịch sử sự cố. Đổi lại, bạn phải chịu trách nhiệm về độ bền và vận hành.
Kiến trúc DIY thực tế:
- Site tĩnh (nhanh, thân thiện cache) cho giao diện và trang lịch sử sự cố\n- Nguồn dữ liệu có API (hoặc CMS nhẹ) lưu sự cố, thành phần và cập nhật\n- Cache quyết liệt + CDN để trang trạng thái vẫn nhanh khi lưu lượng đột biến
Nếu tự host, lên kế hoạch cho chế độ lỗi: nếu database chính không truy cập được, hoặc pipeline deploy bị lỗi thì sao? Nhiều đội giữ trang trạng thái trên hạ tầng tách biệt (hoặc nhà cung cấp khác) so với sản phẩm chính.
Nếu bạn muốn quyền kiểm soát nhưng không muốn viết lại mọi thứ, nền tảng dạng vibe-coding như Koder.ai có thể giúp dựng trang tùy chỉnh nhanh từ mô tả chat-driven. Điều này hữu ích cho đội muốn mô hình thành phần riêng, UX lịch sử sự cố tùy chỉnh, hoặc workflow admin nội bộ—vẫn có thể xuất mã nguồn và triển khai.
Kế hoạch chi phí
Công cụ hosted có giá hàng tháng dự đoán được; DIY có chi phí thời gian kỹ sư, hosting/CDN và bảo trì liên tục. So sánh chi phí hàng tháng dự kiến và thời gian nội bộ, rồi kiểm tra với ngân sách (xem /pricing).
Kết nối giám sát và quy trình xử lý sự cố
Trang trạng thái chỉ hữu ích nếu phản ánh hiện trạng nhanh. Cách dễ nhất là kết nối hệ thống phát hiện vấn đề (giám sát) với hệ thống điều phối phản ứng (incident workflow), để cập nhật nhất quán và kịp thời.
Nguồn cập nhật trạng thái nên đến từ đâu
Hầu hết đội kết hợp ba nguồn dữ liệu:\n
- Cảnh báo giám sát (health checks, synthetic tests, tỷ lệ lỗi, độ trễ, độ dài hàng đợi). Tốt cho phát hiện, nhưng không phải lúc nào cũng mô tả ảnh hưởng khách hàng.\n- Cập nhật thủ công từ người trực hoặc đội hỗ trợ. Con người thêm ngữ cảnh: ai bị ảnh hưởng, cách khắc phục tạm, điều gì đã thay đổi.\n- Công cụ quản lý sự cố (PagerDuty, Opsgenie, Jira Service Management, v.v.). Chúng cung cấp timeline, vai trò và ghi chú khắc phục mà trang trạng thái có thể tóm tắt.
Quy tắc thực tế: giám sát phát hiện; workflow điều phối; trang trạng thái truyền đạt.
Tự động hóa hữu ích (không hứa quá mức)
Tự động hóa có thể tiết kiệm thời gian quan trọng:\n
- Tạo sự cố từ cảnh báo khi monitor mức cao kích hoạt (ví dụ, “tỉ lệ lỗi API > 5% trong 5 phút”). Tiền điền tiêu đề, thành phần bị ảnh hưởng và mức độ ban đầu.\n- Cập nhật thành phần từ health checks cho tín hiệu khách quan (ví dụ, “Web app: Degraded Performance” khi ngưỡng độ trễ bị phá).\n- Đồng bộ thay đổi trạng thái tới kênh sự cố (Slack/Teams) để người xử lý thấy những gì khách hàng thấy.
Giữ thông điệp công khai đầu tiên thận trọng. “Investigating elevated errors” an toàn hơn “Outage confirmed” khi đang xác nhận.
Đừng tự động hoàn toàn nếu không có review của con người
Tin nhắn hoàn toàn tự động có thể gây hại:\n
- Cảnh báo ồn ào có thể đăng sự cố giả.\n- Hỏng một phần có thể khiến monitor báo “down” trong khi khách hàng vẫn dùng bình thường.\n- Auto-resolve có thể đóng sự cố trong khi người dùng vẫn bị ảnh hưởng.
Dùng tự động hóa để soạn và gợi ý cập nhật, nhưng yêu cầu con người phê duyệt nội dung hướng tới khách hàng — đặc biệt cho trạng thái Identified, Mitigated, và Resolved.
Giữ nhật ký kiểm toán
Xử lý trang trạng thái như sổ nhật ký hướng tới khách hàng. Đảm bảo trả lời được:\n
- Ai đã thay đổi trạng thái sự cố?\n- Đã thay đổi gì (văn bản, thành phần, dấu thời gian)?\n- Khi nào thay đổi?\n Nhật ký kiểm toán hữu ích cho post-incident review, giảm nhầm lẫn khi bàn giao, và xây dựng niềm tin khi khách hàng hỏi rõ.
Làm cho nó đáng tin: Hosting, DNS và chống sập
Trang trạng thái chỉ hữu ích nếu truy cập được khi sản phẩm của bạn không hoạt động. Hỏng thường gặp nhất là xây trang trạng thái trên cùng hạ tầng với app — khi app sập, trang trạng thái cũng biến mất, khách hàng mất nguồn tin chính.
Tách biệt nó khỏi stack chính
Khi có thể, host trang trạng thái trên nhà cung cấp khác so với app sản xuất (hoặc ít nhất khác vùng/tài khoản). Mục tiêu là tách blast-radius: sự cố nền tảng app không nên làm mất thông tin sự cố.
Cân nhắc tách DNS. Nếu DNS tên miền chính được quản lý cùng nơi với app edge/CDN, sự cố DNS/certificate có thể chặn cả hai. Nhiều đội dùng subdomain riêng (ví dụ, status.yourcompany.com) với DNS quản lý độc lập.
Giữ trang nhanh và chịu lỗi
Giảm thiểu tài nguyên: JavaScript tối giản, CSS nén, và không phụ thuộc API của app để render. Đặt CDN trước trang trạng thái và bật cache cho tài nguyên tĩnh để trang vẫn tải nhanh khi lưu lượng cao.
Một phương án an toàn thực tế là chế độ tĩnh dự phòng:
- render trước trạng thái và banner sự cố gần nhất\n- phục vụ từ object storage hoặc hosting tĩnh\n- cập nhật động khi hệ thống khỏe, nhưng xuống chế độ an toàn khi không được
Công khai mặc định, bảo mật quản trị
Khách hàng không nên cần đăng nhập để xem trạng thái. Giữ trang công khai, nhưng đặt công cụ admin/chỉnh sửa sau xác thực (SSO nếu có), với kiểm soát truy cập mạnh và nhật ký kiểm toán.
Cuối cùng, thử các kịch bản thất bại: chặn origin app trong môi trường staging và xác nhận trang trạng thái vẫn giải quyết, tải nhanh và có thể cập nhật khi cần nhất.
Quy trình vận hành: Ai cập nhật và khi nào
Get rewarded for sharing
Share what you built with Koder.ai or refer a teammate to earn platform credits.
Trang trạng thái chỉ xây dựng niềm tin nếu được cập nhật nhất quán trong sự cố thực tế. Sự nhất quán này không xảy ra ngẫu nhiên — bạn cần trách nhiệm rõ ràng, quy tắc đơn giản và nhịp điệu dự đoán được.
Xác định vai trò (trước khi mọi thứ hỏng)
Giữ đội cốt lõi nhỏ và rõ ràng:\n
- Incident Commander (IC): điều phối phản ứng, quyết định ưu tiên và xác nhận khi ổn định\n- Communications Lead: đăng cập nhật lên trang trạng thái và giữ ngôn ngữ thân thiện với khách hàng\n- Kỹ sư trực: điều tra, khắc phục và đưa thông tin đã xác nhận cho IC
Nếu đội nhỏ, một người có thể kiêm hai vai — chỉ cần quyết định trước. Ghi lại bàn giao vai trò và đường leo thang trong sổ tay on-call (xem /docs/on-call).
Một checklist cập nhật đơn giản theo mỗi lần
Khi một cảnh báo trở thành sự cố ảnh hưởng khách hàng, theo một luồng lặp lại:\n
- Xác nhận: đăng “Investigating” nhanh (dù chi tiết còn ít)\n2. Đánh giá ảnh hưởng: xác nhận thành phần, vùng hoặc phân khúc khách hàng bị ảnh hưởng\n3. Đăng cập nhật: nêu người dùng có thể thấy gì, phương án tạm (nếu có), và khi nào cập nhật tiếp\n4. Khắc phục: xác nhận dịch vụ đã phục hồi và điều gì đang được giám sát\n5. Tổng kết: thêm bản tóm tắt ngắn và liên kết tới báo cáo đầy đủ khi có
Quy tắc thực tế: đăng cập nhật đầu tiên trong 10–15 phút, sau đó mỗi 30–60 phút trong thời gian còn ảnh hưởng — ngay cả khi nội dung là “Không thay đổi, vẫn đang điều tra.”
Sau khi khắc phục: xem xét và cải thiện
Trong 1–3 ngày làm việc, thực hiện review nhẹ sau sự cố:\n
- Dòng thời gian: các sự kiện chính từ phát hiện đến khôi phục\n- Nguyên nhân gốc (tốt nhất có thể): giải thích bằng ngôn ngữ đơn giản\n- Hành động: các bản vá cụ thể, người chịu trách nhiệm và hạn chót
Sau đó cập nhật mục sự cố với bản tóm tắt cuối cùng để lịch sử hữu ích — không chỉ là nhật ký các thông báo “resolved”.
Danh sách kiểm tra khi ra mắt và cải tiến liên tục
Trang trạng thái chỉ hữu ích khi dễ tìm, đáng tin và được cập nhật nhất quán. Trước khi công bố, chạy một kiểm tra “sẵn sàng production” — rồi đặt nhịp cải tiến nhẹ để hoàn thiện theo thời gian.
Danh sách kiểm tra khi ra mắt (phiên bản thực tế)
Nội dung và cấu trúc\n
- Xác nhận tên thành phần trùng với cách khách hàng gọi (ví dụ, “Dashboard” thay vì tên nội bộ).\n- Thêm một phần “Trang này hiển thị gì” ngắn và liên kết rõ tới hỗ trợ (ví dụ, /support) cho vấn đề cụ thể tài khoản.\n- Đảm bảo cập nhật sự cố giải thích ảnh hưởng khách hàng (“thanh toán thất bại”) và đưa bước tiếp theo (“thử lại sau 10 phút”).
Branding và độ tin cậy\n
- Thêm logo, favicon và hệ thống màu cho trạng thái (tránh sắc thái quá tinh tế).\n- Bao gồm định dạng dấu thời gian rõ ràng và múi giờ.
Quyền truy cập và quyền hạn\n
- Xác minh ai có thể đăng sự cố, lên lịch bảo trì và sửa trang.\n- Thiết lập “dự phòng on-call” để cập nhật không bị chặn bởi một người duy nhất.
Kiểm tra quy trình đầy đủ\n
- Chạy sự cố thử (đánh dấu rõ là test và đã giải quyết).\n- Đăng ký qua email/SMS và xác nhận thông báo tới và có chứa liên kết đúng.
Công bố\n
- Thêm liên kết trang trạng thái vào footer app, trung tâm trợ giúp và trả lời tự động hỗ trợ.\n- Gửi thông báo ngắn tới khách giải thích kỳ vọng và cách đăng ký.
Nếu bạn tự xây, cân nhắc chạy danh sách kiểm tra này trong staging trước. Các công cụ như Koder.ai có thể tăng tốc vòng lặp này bằng cách tạo giao diện web, màn hình admin và endpoint backend từ một spec duy nhất — rồi cho phép xuất mã và triển khai.
Đo lường thế nào là “tốt hơn”
Theo dõi vài kết quả đơn giản và xem lại hàng tháng:\n
- Giảm vé: so sánh khối lượng vé liên quan sự cố trước/sau ra mắt.\n- Cập nhật đầu tiên nhanh hơn: đo thời gian từ phát hiện đến cập nhật công khai đầu tiên.\n- Tăng người đăng ký: theo dõi số người đăng ký theo kênh và thành phần họ theo dõi.
Học hỏi từ mô hình sự cố
Giữ một phân loại cơ bản để lịch sử trở nên có thể hành động:\n
- Gắn thẻ sự cố theo loại (hiệu năng, mất một phần, bên thứ ba, bảo trì, bảo mật).\n- Ghi lại thành phần lặp lại và những kẻ gây lỗi thường xuyên.\n- Dùng điều này để ưu tiên sửa và hướng dẫn quy trình post-incident.
Những điều cơ bản về SEO (để khách tìm đúng trang)
- Dùng tiêu đề rõ ràng như “Service Status” và “Incident History.”\n- Giữ cấu trúc heading (H2/H3) để trang lịch sử dễ quét.\n- Ưu tiên indexable incident history pages (trừ khi có lý do bảo mật/riêng tư), và đảm bảo liên kết giữa trang trạng thái chính và từng sự cố có thể được crawl.
Theo thời gian, những cải tiến nhỏ — từ cách diễn đạt rõ ràng hơn, cập nhật nhanh hơn, đến phân loại tốt hơn — sẽ góp lại thành ít gián đoạn hơn, ít vé hơn và nhiều niềm tin hơn từ khách hàng.
Câu hỏi thường gặp
Trang trạng thái SaaS là gì và tại sao nó quan trọng?
Một trang trạng thái SaaS là một trang chuyên dụng hiển thị tình trạng dịch vụ hiện tại và các cập nhật về sự cố ở một nơi chính thức. Nó quan trọng vì giảm tải câu hỏi “Có bị sập không?” cho bộ phận hỗ trợ, thiết lập kỳ vọng khi xảy ra gián đoạn và xây dựng niềm tin bằng các thông tin cập nhật có dấu thời gian rõ ràng.
Sự khác nhau giữa trạng thái thời gian thực, lịch sử sự cố và postmortem là gì?
Trạng thái thời gian thực trả lời “Tôi có thể dùng sản phẩm ngay bây giờ không?” bằng các trạng thái theo thành phần.
Lịch sử sự cố trả lời “Việc này xảy ra thường xuyên thế nào?” bằng dòng thời gian các sự cố và bảo trì trong quá khứ.
Postmortem (báo cáo sau sự cố) trả lời “Tại sao nó xảy ra và đã thay đổi gì?” với nguyên nhân gốc rễ và bước phòng ngừa (thường được liên kết từ mục chi tiết sự cố).
Làm thế nào để đặt mục tiêu rõ ràng cho trang trạng thái trước khi xây dựng?
Bắt đầu với 2–3 kết quả đo lường được:
- Giảm các vé hỗ trợ trùng lặp khi có sự cố
- Cải thiện thời gian đến cập nhật đầu tiên (ví dụ, trong 10–15 phút)
- Tăng số người đăng ký nhận thông báo (email/SMS/Slack)
Ghi những mục tiêu này lại và xem xét hàng tháng để trang không bị bỏ quên.
Ai nên phụ trách cập nhật trang trạng thái và làm sao tránh nhầm lẫn khi có sự cố?
Giao quyền rõ ràng và có phương án dự phòng (thường là on-call rotation). Nhiều đội dùng:
- Người chỉ huy sự cố (Incident Commander) để xác nhận sự kiện và mức độ ưu tiên
- Người phụ trách truyền thông để đăng cập nhật thân thiện với khách hàng
Định nghĩa trước: ai được phép đăng, có cần phê duyệt không, và tần suất cập nhật tối thiểu (ví dụ, mỗi 30–60 phút trong sự cố lớn).
Làm sao để quyết định những thành phần nào cần hiển thị trên trang trạng thái?
Chọn thành phần dựa trên cách khách hàng mô tả vấn đề, không phải tên dịch vụ nội bộ. Các thành phần phổ biến bao gồm:
- API
- Ứng dụng web / Bảng điều khiển
- Xác thực (Đăng nhập/SSO)
- Thanh toán
- Tích hợp (với một vài con quan trọng như Webhooks hoặc Salesforce)
Nếu độ tin cậy khác nhau theo vùng, tách theo khu vực (ví dụ: “API – US” và “API – EU”).
Nên sử dụng những mức trạng thái nào và làm sao giữ chúng nhất quán?
Dùng một bộ mức trạng thái nhỏ, nhất quán và ghi rõ tiêu chí nội bộ cho từng mức:
- Operational (Hoạt động)
- Degraded Performance (Hiệu năng giảm)
- Partial Outage (Mất một phần)
- Major Outage (Mất toàn bộ)
Sự nhất quán còn quan trọng hơn mức độ chính xác hoàn hảo: khách hàng sẽ học ý nghĩa mỗi mức qua việc sử dụng lặp lại.
Mỗi cập nhật sự cố nên bao gồm những gì để hữu ích cho khách hàng?
Một cập nhật sự cố hữu ích nên luôn bao gồm:
- Thời gian bắt đầu (có múi giờ)
- Thành phần/khu vực bị ảnh hưởng
- Ảnh hưởng với ngôn ngữ đơn giản cho khách hàng
- Trạng thái hiện tại (Investigating/Identified/Monitoring/Resolved)
- Một thời gian cập nhật tiếp theo mà bạn có thể đảm bảo
Ngay cả khi chưa biết nguyên nhân, vẫn có thể truyền đạt phạm vi, ảnh hưởng và bước tiếp theo.
Bao lâu chúng ta nên cập nhật trang trạng thái trong khi có sự cố?
Đăng cập nhật “Investigating” ban đầu nhanh chóng (thường trong 10–15 phút sau khi xác nhận có ảnh hưởng). Sau đó:
- Sự cố lớn: cập nhật mỗi 30–60 phút
- Sự cố nhỏ: ít thường xuyên hơn, nhưng luôn kèm thời gian cập nhật tiếp theo
Nếu bạn không thể giữ lịch đã hứa, đăng một ghi chú ngắn để điều chỉnh kỳ vọng thay vì im lặng.
Nên dùng công cụ hosted hay tự xây trang trạng thái?
Công cụ hosted giúp nhanh chóng ra mắt và thường tồn tại ngay cả khi ứng dụng chính bị lỗi; chúng thường hỗ trợ đăng ký, dòng sự cố và tích hợp.
DIY (tự xây) cho phép kiểm soát hoàn toàn nhưng bạn phải đảm bảo độ bền:
- Ưu tiên trang tĩnh + CDN
- Tách hạ tầng (và tốt nhất là DNS) khỏi stack sản xuất
- Đảm bảo vẫn có thể đăng cập nhật khi hệ thống chính suy giảm
Chúng ta nên cung cấp kênh thông báo nào, và làm sao tránh gây mệt mỏi do quá nhiều thông báo?
Cung cấp những kênh mà khách hàng đang dùng (thường là email và SMS, thêm Slack/Teams hoặc RSS). Giữ đăng ký opt-in và làm rõ:
- Họ sẽ nhận gì (sự cố, bảo trì hay cả hai)
- Tùy chọn lọc theo thành phần hoặc mức độ (nếu có)
Kiểm tra khả năng gửi và giới hạn tỷ lệ định kỳ để đảm bảo thông báo vẫn hoạt động khi lưu lượng tăng trong sự cố.