15 thg 11, 2025·8 phút
Tạo ứng dụng web theo dõi sức khỏe ứng dụng và KPI kinh doanh
Tìm hiểu cách xây ứng dụng web gom uptime, latency và lỗi cùng doanh thu, chuyển đổi và churn—kèm dashboard, cảnh báo và thiết kế dữ liệu.
Tìm hiểu cách xây ứng dụng web gom uptime, latency và lỗi cùng doanh thu, chuyển đổi và churn—kèm dashboard, cảnh báo và thiết kế dữ liệu.
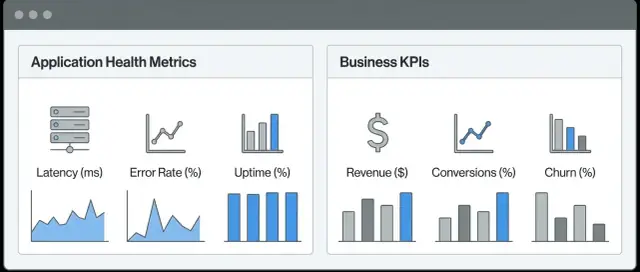
Một góc nhìn kết hợp “Sức khỏe ứng dụng + KPI kinh doanh” là nơi duy nhất mà các nhóm có thể thấy hệ thống có hoạt động và sản phẩm có đang tạo ra kết quả mà doanh nghiệp quan tâm hay không. Thay vì nhảy giữa công cụ observability để xử lý sự cố và công cụ analytics để xem hiệu suất, bạn nối các mối liên hệ trong cùng một quy trình công việc.
Metrics kỹ thuật mô tả hành vi phần mềm và hạ tầng. Chúng trả lời các câu như: Ứng dụng có phản hồi không? Có lỗi không? Có chậm không? Ví dụ phổ biến gồm latency, tỷ lệ lỗi, throughput, sử dụng CPU/memory, độ sâu hàng đợi và khả dụng của phụ thuộc.
Metrics kinh doanh (KPI) mô tả kết quả người dùng và doanh thu. Chúng trả lời: Người dùng có đạt được mục tiêu không? Chúng ta có kiếm được tiền không? Ví dụ gồm đăng ký, tỷ lệ kích hoạt, chuyển đổi, hoàn tất thanh toán, giá trị đơn hàng trung bình, churn, hoàn tiền và khối lượng ticket hỗ trợ.
Mục tiêu không phải thay thế bất kỳ nhóm nào — mà là liên kết chúng, để một spike 500 error không chỉ là “màu đỏ trên biểu đồ” mà được kết nối rõ ràng với “tỷ lệ hoàn tất thanh toán giảm 12%.”
Khi các tín hiệu sức khỏe và KPI chia sẻ cùng giao diện và cửa sổ thời gian, các nhóm thường thấy:
Hướng dẫn tập trung vào cấu trúc và quyết định: cách định nghĩa metrics, nối identifiers, lưu trữ và truy vấn dữ liệu, rồi trình bày dashboard và cảnh báo. Nó cố ý không gắn vào nhà cung cấp cụ thể, nên bạn có thể áp dụng dù dùng công cụ sẵn có, tự xây, hay kết hợp.
Nếu cố gắng theo dõi mọi thứ, bạn sẽ có một dashboard không ai tin tưởng. Bắt đầu bằng cách quyết định ứng dụng giám sát cần giúp bạn làm gì khi áp lực: đưa ra quyết định nhanh và chính xác trong sự cố và theo dõi tiến độ tuần này qua tuần khác.
Khi có sự cố, dashboard của bạn nên nhanh chóng trả lời:
Nếu một biểu đồ không giúp trả lời một trong những câu này, nó là ứng viên để loại bỏ.
Giữ tập core nhỏ và nhất quán giữa các đội. Danh sách khởi điểm tốt:
Những metric này phù hợp với các failure mode phổ biến và dễ cảnh báo sau này.
Chọn metrics đại diện cho funnel khách hàng và thực tế doanh thu:
Với mỗi metric, định nghĩa owner, định nghĩa/nguồn-thật, và chu kỳ rà soát (hàng tuần hoặc hàng tháng). Nếu không ai sở hữu metric, nó sẽ lặng lẽ trở nên sai lệch—và quyết định khi sự cố sẽ bị ảnh hưởng.
Nếu biểu đồ sức khỏe và dashboard KPI nằm ở hai công cụ khác nhau, rất dễ tranh cãi về “chuyện gì đã xảy ra” trong sự cố. Neo monitoring quanh vài hành trình khách hàng mà hiệu suất ảnh hưởng rõ rệt tới kết quả.
Chọn các flow trực tiếp tạo doanh thu hoặc giữ chân khách hàng, như onboarding, search, checkout/payment, đăng nhập, hoặc xuất bản nội dung. Với mỗi hành trình, định nghĩa các bước chính và thế nào là “thành công.”
Ví dụ (checkout):
Map các tín hiệu kỹ thuật ảnh hưởng mạnh nhất tới mỗi bước. Đây là nơi monitoring trở nên gắn với kinh doanh.
Với checkout, leading indicator có thể là “p95 latency của payment API,” còn lagging indicator là “tỷ lệ chuyển đổi checkout.” Thấy cả hai trên cùng timeline làm chuỗi nhân quả rõ hơn.
Một từ điển metrics ngăn nhầm lẫn và tranh luận “cùng KPI nhưng toán khác”. Với mỗi metric, ghi:
Page views, raw signups hay “tổng sessions” có thể ồn mà không có ngữ cảnh. Ưu tiên metrics gắn với quyết định (completion rate, burn rate của error budget, doanh thu trên lượt truy cập). Đồng thời loại bỏ KPI trùng lặp: một định nghĩa chính thức tốt hơn ba dashboard cạnh tranh chênh 2%.
Trước khi viết UI, quyết định bạn đang xây gì. Một app “sức khỏe + KPI” thường có năm thành phần chính: collectors (metrics/logs/traces và sự kiện sản phẩm), ingestion (queue/ETL/streaming), storage (time-series + warehouse), data API (cho truy vấn nhất quán và quyền) và UI (dashboards + drill-down). Alerting có thể nằm trong UI hoặc ủy quyền cho hệ thống on-call hiện có.
Nếu đang prototype UI và workflow nhanh, một nền tảng vibe-coding như Koder.ai có thể giúp dựng nhanh shell dashboard React với backend Go + PostgreSQL từ spec chat, rồi lặp trên navigation và filters trước khi quyết định viết lại nền dữ liệu đầy đủ.
Lên kế hoạch các môi trường sớm: dữ liệu production không nên trộn với staging/dev. Giữ project ID, API key và bucket/bảng storage riêng biệt. Nếu muốn “so sánh prod vs staging,” làm qua view có kiểm soát trong API — không chia sẻ pipeline thô.
Một single pane không có nghĩa re-implement mọi visualization. Bạn có thể:
Nếu chọn embedding, định nghĩa chuẩn điều hướng rõ ràng (ví dụ: “từ thẻ KPI tới view trace”) để người dùng không cảm thấy bị đá giữa các công cụ.
Dashboard chỉ đáng tin như nguồn dữ liệu phía sau. Trước khi xây pipeline, liệt kê hệ thống đã “biết” chuyện gì đang xảy ra, rồi quyết định tần suất cần làm mới cho từng hệ thống.
Bắt đầu với các nguồn giải thích reliability và performance:
Quy tắc thực tế: xem các tín hiệu sức khỏe là gần thời gian thực mặc định, vì chúng điều khiển cảnh báo và phản ứng sự cố.
KPI kinh doanh thường nằm trong công cụ của các đội khác nhau:
Không phải KPI nào cũng cần cập nhật từng giây. Doanh thu hàng ngày có thể batch; tỷ lệ hoàn tất checkout có thể cần dữ liệu tươi hơn.
Với mỗi KPI, viết kỳ vọng độ trễ đơn giản: “Cập nhật mỗi 1 phút,” “Hàng giờ,” hoặc “Ngày làm việc kế tiếp.” Hiển thị điều đó trong UI (ví dụ: “Dữ liệu cập nhật tới 10:35 UTC”). Điều này tránh cảnh báo sai và tranh luận về số liệu “sai” chỉ vì bị trễ.
Để nối spike lỗi với doanh thu mất mát, bạn cần ID nhất quán:
Định nghĩa một “nguồn-thật” cho mỗi identifier và đảm bảo mọi hệ thống mang nó (event analytics, logs, billing). Nếu hệ thống dùng key khác nhau, thêm bảng mapping sớm—nối ngược sau này thường đắt và dễ sai.
Nếu cố gắng lưu mọi thứ trong một DB, thường sẽ bị dashboard chậm hoặc truy vấn tốn kém. Cách sạch sẽ hơn là coi telemetry sức khỏe và KPI kinh doanh là hai hình dữ liệu khác nhau với pattern đọc khác nhau.
Metrics sức khỏe (latency, error rate, CPU, queue depth) có volume cao và được truy vấn theo phạm vi thời gian: “15 phút gần nhất,” “so sánh với hôm qua,” “p95 theo service.” Một time-series DB tối ưu cho rollup và range scan nhanh.
Giữ tags/labels hạn chế và nhất quán (service, env, region, endpoint group). Quá nhiều label độc nhất có thể làm tăng cardinality và chi phí.
KPI kinh doanh (signups, paid conversions, churn, revenue, orders) thường cần joins, backfills và báo cáo “as-of”. Warehouse/lake phù hợp cho:
Ứng dụng web không nên gọi trực tiếp cả hai store từ trình duyệt. Xây một backend API truy vấn từng store, thực thi phân quyền và trả schema nhất quán. Mẫu phổ biến: panel sức khỏe gọi time-series; panel KPI gọi warehouse; endpoint drill-down có thể gọi cả hai và ghép theo cửa sổ thời gian.
Đặt các tầng rõ ràng:
Pre-aggregate các view dashboard phổ biến (theo giờ/ngày) để hầu hết người dùng không kích hoạt truy vấn quét toàn bộ.
UI chỉ hữu dụng khi API phía sau tốt. Một data API tốt làm cho view dashboard phổ biến nhanh và dự đoán được, đồng thời cho phép người dùng click vào chi tiết mà không phải load một sản phẩm hoàn toàn khác.
Thiết kế endpoint tương ứng với điều hướng chính, không phải DB bên dưới:
GET /api/dashboards và GET /api/dashboards/{id} để lấy layout đã lưu, định nghĩa biểu đồ và bộ lọc mặc định.GET /api/metrics/timeseries cho biểu đồ sức khỏe và KPI với from, to, interval, timezone, và filters.GET /api/drilldowns (hoặc /api/events/search) cho “hiển thị các request/orders/users” nằm sau một phân đoạn biểu đồ.GET /api/filters cho danh sách (vùng, gói, môi trường) và để cấp năng lượng cho typeahead.Dashboard hiếm khi cần dữ liệu thô; chúng cần tóm tắt:
Thêm cache cho yêu cầu lặp (cùng dashboard, cùng phạm vi thời gian) và áp rate limit cho các truy vấn rộng. Cân nhắc giới hạn riêng cho drill-down tương tác so với refresh theo lịch.
Làm cho biểu đồ so sánh được bằng cách luôn trả về cùng ranh giới bucket và đơn vị: timestamps căn chỉnh theo interval, trường unit rõ ràng (ms, %, USD), và quy tắc làm tròn ổn định. Nhất quán ngăn nhảy biểu đồ khi đổi bộ lọc hoặc so sánh môi trường.
Một dashboard thành công khi trả lời nhanh một câu: “Chúng ta ổn không?” và “Nếu không, nhìn đâu tiếp theo?” Thiết kế xoay quanh quyết định, không phải mọi thứ có thể đo.
Hầu hết đội làm tốt hơn với vài view có mục đích hơn là một mega-dashboard:
Đặt một time picker ở đầu mọi trang, và giữ nhất quán. Thêm bộ lọc toàn cục người dùng thực sự dùng—vùng, gói, nền tảng, và có thể phân đoạn khách hàng. Mục tiêu là so sánh “US + iOS + Pro” với “EU + Web + Free” mà không rebuild biểu đồ.
Bao gồm ít nhất một panel tương quan mỗi trang overlay tín hiệu kỹ thuật và kinh doanh trên cùng trục thời gian. Ví dụ:
Điều này giúp các bên không chuyên thấy ảnh hưởng và giúp kỹ sư ưu tiên sửa để bảo vệ kết quả.
Tránh lộn xộn: ít biểu đồ hơn, font to hơn, nhãn rõ ràng. Mỗi biểu đồ chính nên hiển thị ngưỡng (tốt / cảnh báo / xấu) và trạng thái hiện tại đọc được mà không phải hover. Nếu metric chưa có ngưỡng đồng thuận, thường chưa sẵn sàng cho trang chủ.
Monitoring chỉ hữu dụng khi dẫn tới hành động đúng. SLO giúp bạn định nghĩa “đủ tốt” phù hợp trải nghiệm người dùng—và cảnh báo giúp phản ứng trước khi khách hàng nhận ra.
Chọn SLI mà người dùng cảm nhận được: lỗi, latency, và availability trên hành trình then chốt như login, search, payment—không phải metric nội bộ.
Khi có thể, cảnh báo trên triệu chứng ảnh hưởng người dùng trước, rồi mới cảnh báo nguyên nhân:
Cảnh báo nguyên nhân vẫn có giá trị, nhưng cảnh báo dựa trên triệu chứng giảm nhiễu và tập trung vào trải nghiệm khách hàng.
Để nối monitoring với KPI, thêm một số cảnh báo đại diện cho rủi ro doanh thu hoặc tăng trưởng, như:
Liên kết mỗi cảnh báo với “hành động mong đợi”: điều tra, rollback, đổi provider, hoặc thông báo support.
Định nghĩa mức độ nghiêm trọng và routing trước:
Mỗi cảnh báo phải trả lời: cái gì bị ảnh hưởng, nghiêm trọng thế nào, và người nhận phải làm gì tiếp theo?
Khi ghép monitoring ứng dụng với dashboard KPI, rủi ro tăng lên: một màn hình có thể hiển thị lỗi bên cạnh doanh thu, churn hoặc tên khách hàng. Nếu phân quyền và quyền riêng tư thêm vào muộn, bạn sẽ hoặc quá hạn chế (không ai dùng được) hoặc phơi bày dữ liệu (rủi ro thực sự).
Bắt đầu bằng cách định nghĩa vai trò xoay quanh quyết định, không phải sơ đồ tổ chức. Ví dụ:
Rồi áp chính sách least-privilege: người dùng thấy dữ liệu tối thiểu cần thiết và xin quyền mở rộng khi cần.
Xử lý PII như lớp dữ liệu riêng với kiểm soát nghiêm ngặt:
Nếu cần join observability với hồ sơ khách hàng, dùng identifier không chứa PII (tenant_id, account_id) và giữ mapping ở sau lớp kiểm soát truy cập.
Đội mất niềm tin khi công thức KPI thay đổi lặng lẽ. Theo dõi:
Hiển thị điều này dưới dạng audit log và đính kèm vào widget chính.
Nếu nhiều đội hoặc khách hàng dùng app, thiết kế tenancy sớm: token scoped, truy vấn nhận diện tenant, và isolation nghiêm ngặt theo mặc định. Dễ làm hơn nhiều so với sửa sau khi tích hợp analytics và incident response đã sống.
Kiểm thử một sản phẩm “sức khỏe ứng dụng + KPI” không chỉ là biểu đồ có load hay không. Làm sao để người dùng tin con số và hành động nhanh. Trước khi ai ngoài đội thấy, xác thực cả độ đúng và tốc độ trong điều kiện thực tế.
Đối xử với app monitoring như sản phẩm hạng nhất với mục tiêu riêng. Đặt mục tiêu hiệu năng chẳng hạn:
Chạy test trong “ngày xấu” thực tế—metrics độ cardinal cao, phạm vi thời gian lớn, và peak traffic.
Dashboard có thể trông bình thường trong khi pipeline lặng lẽ hỏng. Thêm kiểm tra tự động và hiện chúng trong view nội bộ:
Các check này nên fail to rõ rệt ở staging để không phát hiện vấn đề ở production.
Tạo dataset synthetic gồm các trường hợp biên: zero, spike, refund, event trùng lặp, ranh giới timezone. Rồi replay pattern traffic production (với identifier ẩn danh) vào staging để validate dashboard và cảnh báo mà không rủi ro khách hàng.
Với mỗi KPI cốt lõi, định nghĩa quy trình kiểm tra lặp lại:
Nếu bạn không thể giải thích một con số cho người không chuyên trong một phút, nó chưa sẵn sàng để phát hành.
Một app kết hợp “sức khỏe + KPI” chỉ hoạt động nếu mọi người tin, dùng, và giữ nó cập nhật. Đối xử rollout như một launch sản phẩm: bắt đầu nhỏ, chứng minh giá trị, và xây thói quen.
Chọn một hành trình khách hàng mọi người quan tâm (ví dụ: checkout) và một service backend chịu trách nhiệm chính. Với lát mỏng đó, phát hành:
Cách “một hành trình + một service” làm rõ mục đích app và giữ tranh luận về “metrics nào quan trọng” trong tầm kiểm soát.
Đặt review 30–45 phút hàng tuần với product, support và engineering. Giữ thực tế:
Xem dashboard không dùng là tín hiệu cần đơn giản hóa. Xem alert ồn là bug.
Phân công ownership (dù chia sẻ) và chạy checklist nhẹ nhàng hàng tháng:
Khi lát mỏng đầu tiên ổn định, mở rộng sang hành trình hoặc service tiếp theo bằng cùng pattern.
Nếu bạn muốn ý tưởng triển khai và ví dụ, xem /blog. Nếu đang cân nhắc build vs buy, so sánh lựa chọn và phạm vi trên /pricing.
Nếu muốn tăng tốc phiên bản đầu (UI dashboard + lớp API + auth), Koder.ai có thể là khởi điểm thực dụng—nhất là cho đội muốn frontend React với backend Go + PostgreSQL, và khả năng xuất source code khi sẵn sàng đưa vào workflow engineering chuẩn.
Đó là một workflow duy nhất (thường là một dashboard + trải nghiệm drill-down) nơi bạn có thể xem cả tín hiệu sức khỏe kỹ thuật (độ trễ, lỗi, quá tải) và kết quả kinh doanh (tỷ lệ chuyển đổi, doanh thu, churn) trên cùng một trục thời gian.
Mục tiêu là tìm mối tương quan: không chỉ “có gì đó hỏng,” mà là “lỗi checkout tăng và chuyển đổi giảm,” từ đó ưu tiên sửa theo ảnh hưởng.
Bởi vì incident dễ chẩn đoán hơn khi bạn có thể xác nhận ảnh hưởng tới khách hàng ngay lập tức.
Thay vì đoán liệu một spike độ trễ có quan trọng hay không, bạn có thể đối chiếu nó với KPI như mua hàng/ phút hoặc tỷ lệ kích hoạt và quyết định có cần paging, rollback hay theo dõi tiếp không.
Bắt đầu từ các câu hỏi của incident:
Sau đó chọn 5–10 metrics sức khỏe (availability, latency, error rate, saturation, traffic) và 5–10 KPI (signups, activation, conversion, doanh thu, retention). Giữ trang chủ tối giản.
Chọn 3–5 hành trình quan trọng gắn trực tiếp với doanh thu hoặc retention (checkout/payment, login, onboarding, search, publishing).
Với mỗi hành trình, định nghĩa:
Điều này giúp dashboard tập trung vào kết quả thay vì chi tiết hạ tầng.
Một từ điển metric tránh nhầm lẫn “cùng KPI, toán khác nhau”. Với mỗi metric ghi:
Xử lý các metric không có owner như deprecated cho đến khi ai đó nhận duy trì.
Nếu các hệ thống không chia sẻ ID nhất quán, bạn không thể nối lỗi tới kết quả.
Chuẩn hóa và truyền khắp nơi:
user_idaccount_id/org_idorder_id/invoice_idNếu key khác nhau giữa công cụ, tạo bảng mapping sớm; việc nối ngược (retroactive stitching) thường tốn kém và không chính xác.
Một phân tách thực dụng:
Thêm một data API backend để truy vấn cả hai, thực thi phân quyền và trả về buckets/đơn vị nhất quán cho UI.
Quy tắc:
“Single pane” không đồng nghĩa với việc tái hiện mọi biểu đồ từ đầu.
Ưu tiên cảnh báo trên triệu chứng ảnh hưởng người dùng trước, rồi mới cảnh báo nguyên nhân.
Ví dụ triệu chứng tốt:
Thêm một bộ nhỏ cảnh báo ảnh hưởng kinh doanh (giảm conversion, spike lỗi thanh toán, giảm orders/phút) và kèm hành động mong đợi (điều tra, rollback, đổi nhà cung cấp, thông báo support).
Trộn dữ liệu doanh thu/KPI với dữ liệu vận hành làm tăng rủi ro về quyền riêng tư và niềm tin.
Thực hiện:
Ưu tiên dùng ID không chứa PII (như account_id) khi cần join.