21 thg 9, 2025·8 phút
Tư duy CAP của Eric Brewer: tại sao hệ thống phân tán phải đánh đổi
Hiểu định lý CAP của Eric Brewer như một mô hình tư duy thực dụng: cách nhất quán, khả dụng và phân vùng ảnh hưởng tới quyết định hệ thống phân tán.
Hiểu định lý CAP của Eric Brewer như một mô hình tư duy thực dụng: cách nhất quán, khả dụng và phân vùng ảnh hưởng tới quyết định hệ thống phân tán.
Khi bạn lưu cùng một dữ liệu trên hơn một máy, bạn có được tốc độ và khả năng chịu lỗi—nhưng đồng thời cũng gặp một vấn đề mới: bất đồng. Hai máy chủ có thể nhận các cập nhật khác nhau, thông điệp có thể đến muộn hoặc không đến, và người dùng có thể đọc kết quả khác nhau tùy theo bản sao họ chạm tới. CAP trở nên phổ biến vì nó cho các kỹ sư một cách rõ ràng để nói về thực tế lộn xộn đó mà không phải vòng vo.
Eric Brewer, nhà khoa học máy tính và đồng sáng lập Inktomi, đưa ra ý tưởng cốt lõi vào năm 2000 như một phát biểu thực dụng về hệ thống sao chép khi có lỗi. Nó lan nhanh vì phù hợp với những gì các đội đã trải nghiệm trong sản xuất: hệ thống phân tán không chỉ hỏng bằng cách sập; chúng hỏng bằng cách chia tách.
CAP hữu ích nhất khi mọi thứ trở nên sai—nhất là khi mạng không hoạt động đúng. Vào ngày hoạt động bình thường, nhiều hệ thống có thể trông đủ nhất quán và khả dụng. Thử thách là khi các máy không thể giao tiếp tin cậy và bạn phải quyết định xử lý đọc/ghi thế nào trong khi hệ thống bị chia.
Khung suy nghĩ này là lý do CAP trở thành mô hình thường dùng: nó không tranh luận về thực hành hay không; nó buộc đặt ra câu hỏi cụ thể—chúng ta sẽ hy sinh gì khi phân vùng xảy ra?
Sau khi đọc xong, bạn nên có thể:
CAP tồn tại vì nó biến câu “phân tán là khó” mơ hồ thành một quyết định bạn có thể đưa ra—và bảo vệ.
Một hệ thống phân tán nói nôm na là nhiều máy cố gắng hoạt như một. Bạn có thể có nhiều máy chủ ở các rack, vùng hoặc zone khác nhau, nhưng với người dùng đó là “ứng dụng” hay “cơ sở dữ liệu”.
Để hệ thống chia sẻ đó hoạt động ở quy mô thực, ta thường sao chép: giữ nhiều bản sao cùng dữ liệu trên các máy khác nhau.
Sao chép phổ biến vì ba lý do thực tế:
Nghe có vẻ là một thắng lợi đơn giản. Khúc mắc là sao chép sinh ra một nhiệm vụ mới: giữ các bản sao đồng thuận.
Nếu mọi bản sao luôn có thể nói chuyện ngay lập tức, chúng có thể phối hợp cập nhật và giữ đồng bộ. Nhưng mạng thực tế không hoàn hảo. Gói tin có thể bị trễ, bị rơi hoặc bị định tuyến qua chỗ hỏng.
Khi giao tiếp tốt, các bản sao thường trao đổi cập nhật và hội tụ về cùng trạng thái. Nhưng khi giao tiếp đứt (thậm chí tạm thời), bạn có thể có hai phiên bản “sự thật” đều hợp lệ.
Ví dụ: một người dùng thay đổi địa chỉ giao hàng. Bản sao A nhận cập nhật, bản sao B thì không. Bây giờ hệ thống phải trả lời một câu hỏi tưởng đơn giản: địa chỉ hiện tại là gì?
Đây là sự khác biệt giữa:
Tư duy CAP bắt đầu chính xác từ đây: một khi có sao chép, bất đồng khi giao tiếp bị gián đoạn không phải là trường hợp ngoại lệ—mà là vấn đề thiết kế trung tâm.
CAP là một mô hình tư duy cho cảm nhận thực tế của người dùng khi hệ thống trải trên nhiều máy (thường ở nhiều nơi). Nó không mô tả hệ thống “tốt” hay “xấu”—chỉ là sự căng thẳng bạn phải quản lý.
Nhất quán là về đồng thuận. Nếu bạn cập nhật gì đó, lần đọc kế tiếp (từ bất kỳ đâu) có phản ánh cập nhật đó không?
Với người dùng, đó là sự khác nhau giữa “tôi vừa thay đổi, và mọi người đều thấy giá trị mới” và “một số người vẫn thấy giá trị cũ một thời gian”.
Khả dụng có nghĩa hệ thống phản hồi các yêu cầu—đọc và ghi—với kết quả thành công. Không phải “nhanh nhất có thể,” mà là “không từ chối phục vụ bạn.”
Khi có sự cố (server down, sự cố mạng), hệ thống khả dụng tiếp tục nhận yêu cầu, ngay cả khi phải trả lời bằng dữ liệu có thể hơi lỗi thời.
Phân vùng là khi mạng bị chia: máy vẫn chạy, nhưng thông điệp giữa một số máy không thể tới (hoặc tới muộn đến mức vô ích). Trong hệ thống phân tán, bạn không thể coi đó là không xảy ra—bạn phải xác định hành vi khi điều đó xảy ra.
Tưởng tượng hai cửa bán cùng một sản phẩm và chia “1 số lượng tồn”. Một khách mua chiếc cuối ở Cửa A, nên Cửa A ghi inventory = 0. Cùng lúc, phân vùng mạng khiến Cửa B không nghe thấy cập nhật.
Nếu Cửa B giữ khả dụng, nó có thể bán một món mà nó thực ra không còn (chấp nhận bán trong khi phân vùng). Nếu Cửa B ép buộc nhất quán, nó có thể từ chối bán cho tới khi xác nhận tồn kho mới nhất (từ chối phục vụ trong lúc chia).
“Phân vùng” không chỉ là “internet sập.” Đó là bất kỳ tình huống nào mà các phần của hệ thống không thể giao tiếp đáng tin cậy—mặc dù từng phần có thể vẫn chạy tốt.
Trong hệ thống sao chép, các node liên tục trao đổi thông điệp: ghi, xác nhận, heartbeat, bầu lãnh đạo, yêu cầu đọc. Phân vùng là khi những thông điệp đó ngừng đến (hoặc đến quá muộn), tạo ra bất đồng về thực tế: “Ghi đó có xảy ra không?” “Ai là lãnh đạo?” “Node B còn sống không?”
Giao tiếp có thể thất bại theo nhiều cách lộn xộn, ví dụ:
Điểm quan trọng: phân vùng thường là suy giảm, không phải ngắt/bật sạch sẽ. Với ứng dụng, “đủ chậm” có thể không khác gì “sập”.
Khi bạn thêm nhiều máy, nhiều mạng, nhiều vùng, và nhiều thành phần chuyển động, sẽ có nhiều cơ hội cho giao tiếp tạm thời hỏng. Ngay cả khi từng thành phần đáng tin cậy, tổng thể vẫn gặp lỗi vì có nhiều phụ thuộc và phối hợp xuyên-node.
Bạn không cần giả định tỷ lệ lỗi chính xác để chấp nhận thực tế: nếu hệ thống của bạn chạy đủ lâu và trải trên đủ hạ tầng, phân vùng sẽ xảy ra.
Chịu phân vùng có nghĩa hệ thống được thiết kế để tiếp tục hoạt động trong khi bị chia—ngay cả khi các node không thể đồng thuận hoặc không thể xác nhận những gì bên kia đã thấy. Điều đó buộc phải lựa chọn: hoặc tiếp tục phục vụ yêu cầu (rủi ro không nhất quán) hoặc dừng/từ chối một số yêu cầu (bảo vệ nhất quán).
Khi đã có sao chép, phân vùng là đơn giản một đứt gãy giao tiếp: hai phần của hệ thống không thể nói chuyện tin cậy trong một khoảng thời gian. Các bản sao vẫn chạy, người dùng vẫn bấm, dịch vụ vẫn nhận yêu cầu—nhưng các bản sao không thể đồng ý về sự thật mới nhất.
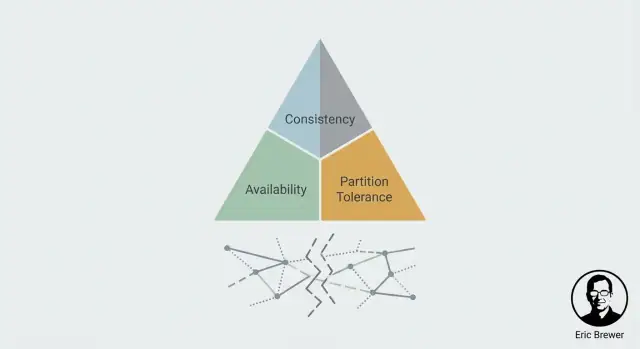
Đó là căng thẳng CAP trong một câu: khi phân vùng, bạn phải chọn ưu tiên Consistency (C) hay Availability (A). Bạn không thể có cả hai cùng lúc.
Bạn muốn: “Tôi thà đúng còn hơn phản hồi.” Khi hệ thống không thể xác nhận một yêu cầu sẽ giữ các bản sao đồng bộ, nó phải thất bại hoặc chờ.
Ảnh hưởng thực tế: một số người dùng sẽ gặp lỗi, timeout, hoặc thông báo “thử lại”—nhất là cho thao tác thay đổi dữ liệu. Điều này phổ biến khi bạn thà từ chối một giao dịch hơn là rủi ro trừ tiền đôi lần, hoặc khóa ghế ngồi hơn là bán quá số lượng.
Bạn nói: “Tôi thà trả lời còn hơn chặn.” Mỗi bên của phân vùng sẽ tiếp tục nhận yêu cầu, ngay cả khi không thể phối hợp.
Ảnh hưởng thực tế: người dùng nhận được phản hồi thành công, nhưng dữ liệu họ đọc có thể lỗi thời, và các cập nhật đồng thời có thể xung đột. Bạn sau đó dựa vào hòa giải (quy tắc hợp nhất, last-write-wins, kiểm tra thủ công, v.v.).
Đây không luôn là một cấu hình toàn cục. Nhiều sản phẩm trộn chiến lược:
Điểm then chốt là quyết định—cho từng thao tác—cái gì tệ hơn: chặn người dùng bây giờ, hay sửa sự thật mâu thuẫn sau khi phân vùng hồi phục.
Khẩu hiệu “chọn hai” dễ nhớ, nhưng thường khiến người ta hiểu sai là CAP là thực đơn ba tính năng mà bạn chỉ giữ được hai mãi mãi. CAP nói về điều xảy ra khi mạng không chịu hợp tác: trong phân vùng (hoặc bất cứ thứ gì trông giống phân vùng), hệ thống phân tán phải chọn giữa trả về câu trả lời nhất quán và luôn khả dụng cho mọi yêu cầu.
Trong hệ thống phân tán thực, phân vùng không phải cài đặt có thể tắt. Nếu hệ thống của bạn trải trên nhiều máy, rack, zone hoặc region, thì thông điệp có thể bị trễ, rơi, đảo thứ tự hoặc định tuyến lạ. Đó là phân vùng với góc nhìn của phần mềm: các node không thể đồng thuận tin cậy.
Ngay cả khi mạng vật lý ổn, lỗi ở nơi khác tạo cùng hiệu ứng—node quá tải, dừng GC, neighbor ồn, DNS chập chờn, load balancer khó đoán. Kết quả giống nhau: một số phần không thể nói chuyện với phần khác đủ để phối hợp.
Ứng dụng không trải nghiệm “phân vùng” như một sự kiện nhị phân gọn gàng. Ứng dụng trải nghiệm đột biến độ trễ và timeout. Nếu một yêu cầu timeout sau 200 ms, không quan trọng là gói đến sau 201 ms hay không đến nữa: app phải quyết định bước tiếp. Với app, giao tiếp chậm thường không khác gì giao tiếp hỏng.
Nhiều hệ thống thực tế là hầu hết nhất quán hoặc hầu hết khả dụng, tùy cấu hình và điều kiện vận hành. Timeout, chính sách retry, kích thước quorum, và tùy chọn “read your writes” có thể dịch chuyển hành vi.
Dưới điều kiện bình thường, một cơ sở dữ liệu có thể trông mạnh về nhất quán; khi stress hoặc sự cố xuyên vùng, nó có thể bắt đầu từ chối yêu cầu (ưu tiên consistency) hoặc trả về dữ liệu cũ (ưu tiên availability).
CAP không phải gán nhãn sản phẩm mà là hiểu đánh đổi bạn đang làm khi bất đồng xảy ra—nhất là khi bất đồng do độ trễ bình thường gây ra.
Thảo luận CAP thường làm nhất quán nghe có vẻ nhị phân: hoặc “hoàn hảo” hoặc “tùy tiện.” Hệ thống thực tế cung cấp một thực đơn các bảo đảm, mỗi loại mang trải nghiệm người dùng khác nhau khi bản sao bất đồng hoặc liên kết mạng bị hỏng.
Nhất quán mạnh (thường là hành vi “linearizable”) nghĩa là khi một ghi được xác nhận, mọi lần đọc sau đó—bất kể tới bản sao nào—sẽ trả về ghi đó.
Cái giá phải trả: khi phân vùng hoặc một số bản sao không đạt tới, hệ thống có thể trì hoãn hoặc từ chối đọc/ghi để tránh trạng thái xung đột. Người dùng nhận thấy điều này như timeout, “thử lại”, hoặc chế độ tạm thời chỉ đọc.
Nhất quán cuối cùng hứa rằng nếu không có cập nhật mới, tất cả bản sao sẽ hội tụ. Nó không hứa rằng hai người đọc ngay lúc đó sẽ thấy cùng một thứ.
Người dùng có thể thấy: ảnh profile vừa cập nhật “lùi lại”, bộ đếm chậm, hoặc tin nhắn vừa gửi không hiển thị trên thiết bị khác trong thời gian ngắn.
Bạn thường có thể cải thiện trải nghiệm mà không cần yêu cầu nhất quán mạnh hoàn toàn:
Những bảo đảm này khớp tốt với suy nghĩ người dùng (“đừng cho tôi thấy thay đổi của tôi biến mất”) và dễ duy trì hơn khi có lỗi cục bộ.
Bắt đầu từ lời hứa với người dùng, không phải thuật ngữ:
Nhất quán là quyết định sản phẩm: mô tả “sai” trông như thế nào với người dùng, rồi chọn bảo đảm yếu nhất ngăn được điều đó.
Khả dụng trong CAP không phải một chỉ số khoe khoang (“năm 9”), mà là một lời hứa bạn đưa ra với người dùng về điều gì xảy ra khi hệ thống không thể chắc chắn.
Khi các bản sao không thể đồng thuận, bạn thường chọn giữa:
Người dùng cảm nhận điều này như “app hoạt động” so với “app là chính xác.” Không có lựa chọn nào luôn tốt hơn; phù hợp phụ thuộc vào việc “sai” nghĩa là gì trong sản phẩm của bạn. Một feed xã hội hơi lỗi thời gây khó chịu. Số dư tài khoản lỗi thời có thể gây hậu quả nghiêm trọng.
Hai hành vi phổ biến trong bất định:
Đây không phải quyết định kỹ thuật thuần túy; đó là chính sách sản phẩm. Sản phẩm cần xác định cái gì chấp nhận được để đoán và cái gì không bao giờ được đoán.
Khả dụng hiếm khi toàn bộ hoặc không. Trong phân vùng, bạn có thể thấy khả dụng cục bộ: một số vùng, mạng hoặc nhóm người dùng thành công trong khi những nơi khác thất bại. Đây có thể là thiết kế chủ ý (phục vụ nơi bản sao địa phương khỏe) hoặc ngẫu nhiên (cân bằng định tuyến, quorum không đều).
Một thỏa hiệp thực tế là chế độ suy giảm: tiếp tục phục vụ các hành động an toàn trong khi hạn chế các hành động rủi ro. Ví dụ, cho phép duyệt và tìm kiếm, nhưng tạm vô hiệu “chuyển tiền”, “đổi mật khẩu”, hoặc các thao tác cần tính đúng duy nhất.
CAP trừu tượng cho đến khi bạn ánh xạ nó tới trải nghiệm người dùng trong phân vùng: bạn muốn hệ thống tiếp tục trả lời, hay ngừng để tránh dữ liệu xung đột?
Tưởng tượng hai data center cùng chấp nhận đơn hàng khi không nói chuyện được.
Nếu bạn giữ flow checkout khả dụng, mỗi bên có thể bán “món cuối” và bạn sẽ oversell. Điều này có thể chấp nhận cho hàng ít rủi ro (bạn bù hàng hoặc xin lỗi), nhưng đau cho các đợt giảm hàng giới hạn.
Nếu bạn chọn ưu tiên nhất quán, bạn có thể chặn đơn hàng mới khi không thể xác nhận tồn kho toàn cục. Người dùng thấy “thử lại sau”, nhưng bạn tránh bán vượt khả năng.
Tiền là miền điển hình “sai là đắt.” Nếu hai bản sao chấp nhận rút tiền độc lập trong phân vùng, tài khoản có thể âm.
Hệ thống thường ưu tiên nhất quán cho các ghi quan trọng: từ chối hoặc trì hoãn hành động nếu không thể xác nhận số dư mới nhất. Bạn đánh đổi khả dụng (lỗi thanh toán tạm thời) để lấy tính đúng, audit và niềm tin.
Trong chat và feed xã hội, người dùng thường chịu được mâu thuẫn nhỏ: tin nhắn đến muộn vài giây, số like lệch, metric cập nhật sau.
Ở đây, thiết kế cho khả dụng là lựa chọn sản phẩm hợp lý, miễn là bạn rõ ràng phần nào “sẽ hội tụ về sau” và có cách hợp nhất cập nhật tốt.
Lựa chọn CAP “đúng” phụ thuộc vào chi phí khi sai: hoàn tiền, trách nhiệm pháp lý, mất niềm tin người dùng, hoặc hỗn loạn vận hành. Quyết định chỗ nào chấp nhận tạm thời lỗi thời—và chỗ nào phải fail closed.
Khi bạn đã quyết định sẽ làm gì khi phân vùng, bạn cần cơ chế biến quyết định đó thành hiện thực. Các mẫu này xuất hiện ở cơ sở dữ liệu, hệ thống nhắn tin và API—ngay cả khi sản phẩm không bao giờ nhắc “CAP.”
Quorum đơn giản là “đa số bản sao đồng ý.” Nếu có 5 bản sao, đa số là 3.
Bằng việc yêu cầu đọc/ghi tới đa số, bạn giảm khả năng trả về dữ liệu cũ hoặc xung đột. Ví dụ, nếu một ghi phải được xác nhận bởi 3 bản sao, thì khó xảy ra hai nhóm cô lập đều chấp nhận các “sự thật” khác nhau.
Đổi lại là tốc độ và phạm vi: nếu bạn không đạt đa số (do phân vùng hoặc outage), hệ thống có thể từ chối thao tác—ưu tiên nhất quán hơn là khả dụng.
Nhiều vấn đề “khả dụng” không phải lỗi cứng mà là phản hồi chậm. Đặt timeout ngắn khiến hệ thống cảm thấy nhanh, nhưng cũng tăng khả năng coi thành công chậm là thất bại.
Retry có thể cứu các trục trặc thoáng qua, nhưng retry quá mức có thể quá tải dịch vụ đang gặp khó. Backoff (chờ lâu hơn giữa các lần thử) và jitter (ngẫu nhiên) giúp đỡ việc retry không biến thành spike traffic.
Chìa khóa là căn chỉnh các thiết lập này với lời hứa của bạn: “luôn trả lời” thường cần nhiều retry và fallback; “không bao giờ nói dối” thường cần giới hạn chặt và lỗi rõ ràng.
Nếu bạn chọn khả dụng trong phân vùng, các bản sao có thể chấp nhận cập nhật khác nhau và bạn phải hòa giải sau. Cách làm phổ biến gồm:
Retry có thể tạo bản sao: trừ tiền đôi, gửi đơn hai lần. Idempotency ngăn điều đó.
Một mẫu phổ biến là idempotency key (request ID) gửi kèm yêu cầu. Server lưu kết quả lần đầu và trả lại kết quả đó cho các lần lặp lại—vậy retry tăng khả dụng mà không phá hỏng dữ liệu.
Hầu hết nhóm “chọn” chiến lược CAP trên bảng trắng—rồi phát hiện trong production hệ thống hành xử khác khi stress. Xác thực nghĩa là chủ ý tạo điều kiện để đánh đổi CAP hiện ra, và kiểm tra hệ thống phản ứng đúng như thiết kế.
Bạn không cần cắt cáp thật để học điều gì đó. Dùng fault injection có kiểm soát trong staging (và cẩn thận trong production) để mô phỏng phân vùng:
Mục tiêu là trả lời câu hỏi cụ thể: Ghi có bị từ chối hay chấp nhận? Đọc có trả về dữ liệu cũ không? Hệ thống tự phục hồi thế nào và hòa giải mất bao lâu?
Nếu bạn muốn kiểm chứng sớm (trước khi đầu tư nhiều), việc dựng nhanh một prototype thực tế giúp ích. Ví dụ, các đội dùng Koder.ai thường bắt đầu bằng sinh một dịch vụ nhỏ (thường là backend Go với PostgreSQL và UI React) rồi lặp để thử các hành vi như retry, idempotency key, và luồng “chế độ suy giảm” trong sandbox.
Các kiểm tra uptime truyền thống sẽ không bắt được “khả dụng nhưng sai.” Hãy theo dõi:
Operator cần hành động có sẵn khi phân vùng xảy ra: khi nào đóng ghi, khi nào chuyển dự phòng, khi nào suy giảm tính năng, và cách xác thực an toàn khi gộp lại.
Cũng lập sẵn thông điệp cho người dùng. Nếu bạn chọn nhất quán, thông báo có thể là “Chúng tôi không thể xác nhận cập nhật ngay—vui lòng thử lại.” Nếu bạn chọn khả dụng, hãy rõ ràng: “Cập nhật của bạn có thể mất vài phút để xuất hiện ở mọi nơi.” Thông tin rõ ràng giảm tải hỗ trợ và giữ niềm tin.
Khi bạn ra quyết định hệ thống, CAP hữu ích nhất như một cuộc rà soát nhanh “cái gì hỏng khi phân vùng?”—không phải tranh luận lý thuyết. Dùng checklist này trước khi chọn tính năng DB, chiến lược cache, hoặc chế độ sao chép.
Hỏi theo thứ tự:
Nếu phân vùng xảy ra, bạn đang quyết bảo vệ cái nào trước.
Tránh một cấu hình toàn cục kiểu “chúng tôi là hệ AP.” Thay vào đó, quyết cho từng:
Ví dụ: trong phân vùng bạn có thể chặn ghi tới payments (ưu tiên consistency) nhưng cho đọc product_catalog bằng dữ liệu cache.
Ghi rõ điều bạn chấp nhận, với ví dụ:
Nếu bạn không thể mô tả không nhất quán bằng ví dụ đơn giản, bạn sẽ khó test và giải thích sự cố.
Các chủ đề tiếp theo phù hợp: consensus, consistency models, và SLOs/error budgets.
CAP là một mô hình tư duy cho hệ thống sao chép khi gặp lỗi giao tiếp. Nó hữu ích nhất khi mạng chậm, mất gói hoặc bị chia tách, vì đó là lúc các bản sao không thể đồng thuận và bạn buộc phải chọn giữa:
Nó giúp biến câu nói “hệ thống phân tán khó” thành một quyết định cụ thể về sản phẩm và kỹ thuật.
Một tình huống CAP thực sự đòi hỏi cả hai:
Nếu hệ thống bạn chạy trên một node duy nhất, hoặc bạn không sao chép trạng thái, thì các đánh đổi CAP không phải là vấn đề trung tâm.
Một phân vùng là bất kỳ tình huống nào mà các phần của hệ thống không thể giao tiếp đáng tin cậy hoặc trong giới hạn thời gian yêu cầu—ngay cả khi từng máy vẫn chạy.
Thực tế, “phân vùng” thường biểu hiện dưới dạng:
Với ứng dụng, “quá chậm” đôi khi cũng tương đương với “đã chết”.
Consistency (C) có nghĩa là các lần đọc phản ánh ghi mới nhất đã được xác nhận từ bất kỳ đâu. Người dùng cảm nhận nó như “tôi vừa thay đổi và mọi người đều thấy”.
Availability (A) có nghĩa là mọi yêu cầu đều nhận được phản hồi thành công (không nhất thiết là dữ liệu mới nhất). Người dùng cảm nhận nó như “ứng dụng vẫn hoạt động”, có thể với dữ liệu cũ hơn.
Trong phân vùng, bạn thường không thể đảm bảo cả hai cùng lúc cho mọi thao tác.
Bởi vì phân vùng là không thể loại trừ trong hệ thống phân tán trải trên nhiều máy, rack, vùng hoặc region. Nếu bạn sao chép, bạn phải định nghĩa hành vi khi các node không thể phối hợp.
“Chấp nhận phân vùng” thường có nghĩa: khi giao tiếp bị gián đoạn, hệ thống vẫn có cách hoạt động đã định—hoặc từ chối/tạm dừng một số hành động (ưu tiên consistency), hoặc phục vụ kết quả nỗ lực tốt nhất (ưu tiên availability).
Nếu bạn ưu tiên consistency, bạn thường sẽ:
Mô hình này phổ biến cho chuyển tiền, giữ hàng tồn kho, và thay đổi quyền — nơi sai sót còn tệ hơn tạm thời không phục vụ.
Nếu bạn ưu tiên availability, bạn thường sẽ:
Người dùng sẽ thấy ít lỗi cứng hơn, nhưng có thể gặp dữ liệu cũ, hiệu ứng trùng lặp nếu không có idempotency, hoặc các cập nhật mâu thuẫn cần làm sạch sau.
Bạn có thể chọn khác nhau theo endpoint/loại dữ liệu. Các chiến lược hỗn hợp phổ biến gồm:
Điều này tránh gắn nhãn hệ thống toàn cục là AP/CP khi thực tế cần sự phân loại chi tiết hơn.
Các lựa chọn hữu ích bao gồm:
Xác thực bằng cách tạo các điều kiện để mâu thuẫn hiện ra:
Chọn bảo đảm yếu nhất mà vẫn ngăn được “sai” thấy được bởi người dùng mà bạn không chấp nhận.
Chuẩn bị cả runbook và thông điệp người dùng phù hợp với hành vi bạn chọn (fail closed vs fail open).