21 thg 5, 2025·8 phút
Tạo ứng dụng web cho báo cáo SLA tập trung
Tìm hiểu cách lập kế hoạch, xây dựng và ra mắt ứng dụng web đa-khách hàng thu thập dữ liệu SLA, chuẩn hóa chỉ số và cung cấp dashboard, cảnh báo và báo cáo xuất được.
Tìm hiểu cách lập kế hoạch, xây dựng và ra mắt ứng dụng web đa-khách hàng thu thập dữ liệu SLA, chuẩn hóa chỉ số và cung cấp dashboard, cảnh báo và báo cáo xuất được.
Báo cáo SLA tập trung ra đời vì bằng chứng SLA hiếm khi nằm ở một nơi duy nhất. Thời gian hoạt động có thể ở công cụ giám sát, sự cố ở trang trạng thái, ticket ở hệ thống hỗ trợ, và ghi chú leo thang trong email hoặc chat. Khi mỗi khách hàng có một stack hơi khác nhau (hoặc quy ước đặt tên khác nhau), báo cáo hàng tháng biến thành công việc bảng tính thủ công — và tranh cãi về “chuyện đã xảy ra thực sự” trở nên phổ biến.
Một ứng dụng báo cáo SLA tốt phục vụ nhiều đối tượng với mục tiêu khác nhau:
Ứng dụng nên trình bày cùng một sự thật cơ bản ở các mức chi tiết khác nhau, tùy theo vai trò.
Một bảng điều khiển SLA tập trung nên cung cấp:
Trong thực tế, mọi con số SLA nên có thể truy vết về các sự kiện thô (cảnh báo, ticket, dòng thời gian sự cố) với dấu thời gian và người chịu trách nhiệm.
Trước khi xây dựng bất cứ thứ gì, xác định rõ cái gì trong phạm vi và ngoài phạm vi. Ví dụ:
Ranh giới rõ ràng giúp tránh tranh luận sau này và giữ báo cáo nhất quán giữa các khách hàng.
Ít nhất, báo cáo SLA tập trung nên hỗ trợ năm luồng công việc sau:
Thiết kế xoay quanh những luồng này từ ngày đầu và phần còn lại của hệ thống (mô hình dữ liệu, tích hợp và UX) sẽ giữ phù hợp với nhu cầu báo cáo thực tế.
Trước khi bạn xây màn hình hay pipeline, quyết định ứng dụng sẽ đo gì và những con số đó được diễn giải như thế nào. Mục tiêu là nhất quán: hai người đọc cùng một báo cáo nên đi đến cùng một kết luận.
Bắt đầu với một tập nhỏ mà hầu hết khách hàng công nhận:
Nói rõ từng chỉ số đo gì và không đo gì. Một bảng định nghĩa ngắn trong UI (và một đường dẫn tới /help/sla-definitions) giúp tránh hiểu lầm sau này.
Quy tắc là nơi báo cáo SLA thường gặp trục trặc. Hãy tài liệu hóa bằng các câu mà khách hàng có thể xác thực, rồi dịch chúng thành logic.
Bao phủ những điểm thiết yếu:
Chọn các kỳ mặc định (thường là hàng tháng và hàng quý) và xem có hỗ trợ khoảng tùy chỉnh hay không. Làm rõ múi giờ dùng cho thời điểm cắt.
Với vi phạm, định nghĩa:
Với mỗi chỉ số, liệt kê các đầu vào cần thiết (sự kiện giám sát, bản ghi sự cố, dấu thời gian ticket, cửa sổ bảo trì). Đây sẽ là bản thiết kế cho tích hợp và kiểm tra chất lượng dữ liệu.
Trước khi thiết kế dashboard hoặc KPI, xác định rõ bằng chứng SLA thực tế nằm đâu. Hầu hết đội ngũ phát hiện “dữ liệu SLA” bị phân tán qua nhiều công cụ, thuộc các nhóm khác nhau và được ghi theo ý nghĩa hơi khác nhau.
Bắt đầu với một danh sách đơn giản theo từng khách hàng (và theo dịch vụ):
Với mỗi hệ thống, ghi người sở hữu, thời gian lưu trữ, giới hạn API, độ phân giải thời gian (giây hay phút), và dữ liệu có phạm vi theo khách hàng hay chia sẻ.
Hầu hết ứng dụng báo cáo SLA dùng kết hợp:
Quy tắc thực tế: dùng webhooks khi độ tươi mới quan trọng, và API pulls khi cần đầy đủ.
Các công cụ khác nhau mô tả cùng một việc theo cách khác nhau. Chuẩn hóa thành một tập sự kiện nhỏ ứng dụng có thể dựa vào, ví dụ:
incident_opened / incident_closeddowntime_started / downtime_endedticket_created / first_response / resolvedBao gồm trường nhất quán: client_id, service_id, source_system, external_id, severity, và timestamp.
Lưu tất cả timestamp ở UTC, và chuyển khi hiển thị theo múi giờ ưa thích của khách hàng (đặc biệt với cắt kỳ báo cáo hàng tháng).
Lên kế hoạch cho các khoảng trống: một vài khách hàng sẽ không có status page, một vài dịch vụ không được giám sát 24/7, và một số công cụ có thể mất sự kiện. Hiển thị “phủ sóng không đầy đủ” trong báo cáo (ví dụ: “không có dữ liệu giám sát trong 3 giờ”) để kết quả SLA không gây hiểu lầm.
Nếu ứng dụng báo cáo SLA cho nhiều khách hàng, các quyết định kiến trúc sẽ quyết định bạn có thể mở rộng an toàn mà không làm lộ dữ liệu giữa khách hàng.
Bắt đầu bằng cách đặt tên các lớp bạn cần hỗ trợ. Một “khách hàng” có thể là:
Ghi lại sớm vì chúng ảnh hưởng tới phân quyền, bộ lọc và cách lưu cấu hình.
Phổ biến là chọn một trong:
tenant_id. Tiết kiệm chi phí và vận hành đơn giản hơn, nhưng cần kỷ luật truy vấn chặt chẽ.Một giải pháp trung gian thường là DB chia sẻ cho hầu hết tenant và DB riêng cho khách hàng “enterprise”.
Cô lập phải chắc chắn trên:
tenant_id để kết quả không bị ghi nhầm tenantDùng các guardrail như row-level security, scope truy vấn bắt buộc, và test tự động cho ranh giới tenant.
Khách hàng khác nhau sẽ có mục tiêu và định nghĩa khác nhau. Lập kế hoạch cho cài đặt theo tenant như:
Người dùng nội bộ thường cần “mô phỏng” góc nhìn khách hàng. Triển khai chức năng chuyển đổi có chủ ý (không phải bộ lọc tùy ý), hiển thị tenant đang hoạt động rõ ràng, ghi log chuyển đổi để audit, và ngăn các liên kết có thể vượt qua kiểm tra tenant.
Ứng dụng báo cáo SLA tập trung sống hay chết tùy vào mô hình dữ liệu. Nếu bạn chỉ mô hình “% SLA theo tháng”, bạn sẽ khó giải thích kết quả, xử lý tranh chấp hoặc cập nhật phép tính sau này. Nếu chỉ mô hình sự kiện thô, báo cáo sẽ chậm và tốn kém. Mục tiêu là hỗ trợ cả hai: bằng chứng thô có thể truy vết và các rollup nhanh sẵn sàng cho khách hàng.
Giữ tách biệt rõ ràng giữa ai được báo cáo, cái gì được đo, và cách nó được tính:
Thiết kế bảng (hoặc collection) cho:
Logic SLA thay đổi: giờ làm việc cập nhật, ngoại lệ được làm rõ, quy tắc làm tròn phát triển. Thêm calculation_version (và lý tưởng là tham chiếu bộ quy tắc) vào mọi kết quả tính toán. Bằng cách đó, báo cáo cũ có thể tái tạo chính xác ngay cả sau khi cải thiện.
Bao gồm trường audit ở những nơi quan trọng:
Khách hàng thường hỏi “cho tôi biết vì sao”. Lên kế hoạch schema cho bằng chứng:
Cấu trúc này giữ cho ứng dụng có thể giải thích, tái tạo và nhanh — mà không mất bằng chứng gốc.
Nếu đầu vào lộn xộn, dashboard SLA của bạn cũng sẽ thế. Pipeline đáng tin biến dữ liệu sự cố và ticket từ nhiều công cụ thành kết quả SLA nhất quán, có thể kiểm toán — không bị đếm đôi, không có khoảng trống, hoặc lỗi im lặng.
Xử lý ingestion, normalization và rollups như các giai đoạn riêng. Chạy chúng dưới dạng background jobs để UI luôn nhanh và bạn có thể retry an toàn.
Sự tách biệt này cũng giúp khi nguồn của một khách hàng bị xuống: ingestion có thể thất bại mà không làm hỏng phép tính hiện có.
API ngoài timeout. Webhook có thể gửi hai lần. Pipeline của bạn phải idempotent: xử lý cùng một input nhiều lần không được thay đổi kết quả.
Các cách phổ biến:
Giữa các khách hàng và công cụ, “P1”, “Critical” và “Urgent” có thể đều nghĩa giống nhau — hoặc không. Xây lớp chuẩn hóa chuẩn hóa:
Lưu cả giá trị gốc và giá trị đã chuẩn hóa để truy vết.
Thêm quy tắc xác thực (thiếu timestamp, thời lượng âm, chuyển trạng thái bất khả thi). Đừng bỏ dữ liệu xấu im lặng — đưa vào hàng cách ly với lý do và luồng công việc “fix or map”.
Với mỗi khách hàng và nguồn, tính “last successful sync”, “oldest unprocessed event”, và “rollup up-to date through”. Hiển thị dưới dạng chỉ báo độ tươi để khách hàng tin tưởng con số và đội bạn phát hiện vấn đề sớm.
Nếu khách hàng dùng cổng của bạn để xem hiệu suất SLA, authentication và phân quyền cần được thiết kế cẩn thận như phép toán SLA. Mục tiêu là đơn giản: mỗi người dùng chỉ thấy những gì họ được phép — và bạn có thể chứng minh điều đó sau này.
Bắt đầu với một tập vai trò nhỏ, rõ ràng và mở rộng chỉ khi có lý do mạnh:
Giữ nguyên tắc ít đặc quyền nhất: tài khoản mới mặc định là viewer trừ khi được nâng.
Với đội nội bộ, SSO giảm rối quản lý tài khoản và rủi ro offboarding. Hỗ trợ OIDC (Google Workspace/Azure AD/Okta) và, khi cần, SAML.
Với khách hàng, cung cấp SSO như lựa chọn nâng cấp, nhưng vẫn cho phép email/mật khẩu với MFA cho tổ chức nhỏ.
Thực thi ranh giới tenant ở mọi lớp:
Ghi lại truy cập trang nhạy cảm và download: ai truy cập gì, khi nào và từ đâu. Điều này hỗ trợ tuân thủ và tạo niềm tin với khách hàng.
Xây luồng onboarding để admin hoặc client editor có thể mời người dùng, đặt vai trò, yêu cầu xác nhận email và thu hồi truy cập ngay khi cần.
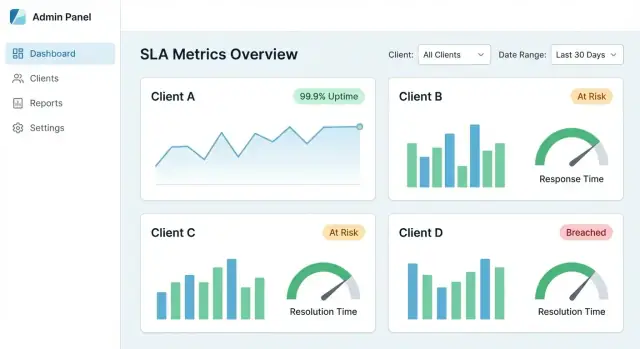
Một bảng SLA tập trung thành công khi khách hàng có thể trả lời ba câu hỏi trong dưới một phút: Chúng tôi có đạt SLA không? Điều gì thay đổi? Nguyên nhân gây ra lỗi là gì? UX nên dẫn họ từ cái nhìn tổng sang bằng chứng — mà không bắt học mô hình dữ liệu nội bộ của bạn.
Bắt đầu với một tập tile và biểu đồ nhỏ khớp với các cuộc trò chuyện SLA phổ biến:
Mỗi thẻ nên có thể click để vào chi tiết, không phải là dead end.
Bộ lọc nên nhất quán trên mọi trang và "dính" khi người dùng điều hướng.
Mặc định khuyến nghị:
Hiển thị chip bộ lọc đang hoạt động ở đầu để người dùng luôn hiểu họ đang xem gì.
Mỗi chỉ số nên có đường dẫn tới “tại sao”. Một luồng drill-down mạnh:
Nếu một con số không thể giải thích bằng bằng chứng, nó sẽ bị nghi ngờ — đặc biệt trong QBR.
Thêm tooltip hoặc panel “info” cho mỗi KPI: cách tính, loại trừ, múi giờ và độ tươi dữ liệu. Kèm ví dụ như “Loại trừ cửa sổ bảo trì” hoặc “Uptime đo tại API gateway.”
Cho phép chế độ xem đã lọc chia sẻ qua URL ổn định (ví dụ: /reports/sla?client=acme&service=api&range=30d). Điều này biến dashboard SLA tập trung thành cổng báo cáo sẵn sàng cho khách hàng, hỗ trợ check-in định kỳ và audit trail.
Dashboard SLA tập trung hữu dụng hàng ngày, nhưng khách hàng thường muốn thứ họ có thể chuyển tiếp nội bộ: PDF cho lãnh đạo, CSV cho analyst và link họ có thể bookmark.
Hỗ trợ ba đầu ra từ cùng nguồn kết quả SLA:
Với báo cáo dạng link, làm rõ bộ lọc (khoảng thời gian, dịch vụ, mức độ) để khách hàng biết chính xác con số đại diện cho gì.
Thêm tính năng scheduling để mỗi khách hàng có thể nhận báo cáo tự động — hàng tuần, hàng tháng, hàng quý — gửi đến danh sách email riêng hoặc inbox chung. Giữ lịch trình theo tenant và có audit (ai tạo, lần gửi cuối, lần chạy tiếp theo).
Nếu cần điểm bắt đầu đơn giản, ra mắt với “tóm tắt hàng tháng” cộng một nút tải xuống từ /reports.
Xây các mẫu đọc như slide QBR/MBR:
SLA thực có ngoại lệ (cửa sổ bảo trì, sự cố bên thứ ba). Cho phép người dùng đính kèm ghi chú tuân thủ và đánh dấu ngoại lệ cần phê duyệt, kèm theo trail phê duyệt.
Export phải tuân thủ cô lập tenant và phân quyền. Người dùng chỉ được xuất những khách hàng, dịch vụ và thời kỳ họ có quyền — và export phải khớp chính xác với view trên portal (không lộ thêm cột dữ liệu bị ẩn).
Cảnh báo là điểm mà một ứng dụng báo cáo SLA chuyển từ “bảng điều khiển hữu ích” thành công cụ vận hành. Mục tiêu không phải gửi nhiều tin hơn — mà là giúp đúng người phản ứng sớm, tài liệu hoá điều đã xảy ra và giữ khách hàng được thông báo.
Bắt đầu với ba loại:
Gắn mỗi cảnh báo với định nghĩa rõ ràng (chỉ số, cửa sổ thời gian, ngưỡng, phạm vi khách hàng) để người nhận tin tưởng.
Cung cấp nhiều kênh giao tiếp để các đội làm việc nơi khách hàng đã dùng:
Với báo cáo đa khách hàng, route thông báo theo quy tắc tenant (ví dụ “Client A breaches đi Channel A; internal breaches đi on-call”). Tránh gửi chi tiết riêng khách hàng vào channel chung.
Alert fatigue sẽ giết trải nghiệm. Triển khai:
Mỗi alert nên hỗ trợ:
Điều này tạo ra trail nhẹ có thể dùng lại trong báo cáo cho khách hàng.
Cung cấp trình chỉnh sửa quy tắc cơ bản cho ngưỡng và routing theo khách hàng (không lộ logic truy vấn phức tạp). Guardrail hữu ích: mặc định, xác thực và preview (“quy tắc này đã kích hoạt 3 lần tháng trước”).
Ứng dụng báo cáo SLA tập trung nhanh chóng trở nên quan trọng vì khách hàng dùng nó để đánh giá chất lượng dịch vụ. Điều đó khiến tốc độ, an toàn và bằng chứng (cho audit) quan trọng không kém biểu đồ.
Khách hàng lớn có thể tạo hàng triệu ticket, sự cố và event. Để các trang phản hồi:
Sự kiện thô giá trị cho điều tra, nhưng giữ mọi thứ mãi tăng chi phí và rủi ro.
Đặt quy tắc rõ ràng như:
Với cổng báo cáo khách hàng, giả định nội dung nhạy cảm: tên khách hàng, timestamp, ghi chú ticket và đôi khi PII.
Ngay cả khi không nhắm tới tiêu chuẩn cụ thể, bằng chứng vận hành tốt tạo niềm tin.
Duy trì:
Ra mắt ứng dụng báo cáo SLA ít liên quan đến big-bang release và nhiều hơn là chứng minh độ chính xác, rồi mở rộng có kiểm soát. Kế hoạch ra mắt tốt giảm tranh chấp bằng cách làm cho kết quả dễ xác minh và dễ tái tạo.
Chọn một khách hàng có tập dịch vụ và nguồn dữ liệu vừa phải. Chạy phép tính SLA của app song song với bảng tính, export ticket hoặc báo cáo nhà cung cấp hiện có của họ.
Tập trung vào những khác biệt hay gặp:
Ghi lại khác biệt và quyết định app nên khớp theo cách hiện tại của khách hàng hay thay bằng tiêu chuẩn rõ ràng hơn.
Tạo checklist lặp lại để mỗi onboarding khách hàng có trải nghiệm dự đoán được:
Checklist cũng giúp ước tính effort và hỗ trợ thảo luận trên /pricing.
Dashboard SLA chỉ đáng tin khi tươi và đầy đủ. Thêm giám sát cho:
Gửi alert nội bộ trước; khi ổn định, có thể hiển thị ghi chú trạng thái cho khách hàng.
Thu thập phản hồi về chỗ gây nhầm lẫn: định nghĩa, tranh chấp ("tại sao đây là breach?"), và "cái gì thay đổi" kể từ tháng trước. Ưu tiên cải tiến UX nhỏ như tooltip, change logs và chú thích rõ ràng về ngoại lệ.
Nếu muốn giao một MVP nội bộ nhanh (mô hình tenant, tích hợp, dashboard, export) mà không tốn nhiều thời gian cho boilerplate, một cách làm “vibe-coding” có thể giúp. Ví dụ, Koder.ai cho phép đội phác thảo và lặp trên app đa-tenant qua chat — rồi xuất mã nguồn và deploy. Phù hợp cho sản phẩm báo cáo SLA, nơi độ phức tạp cốt lõi là quy tắc miền và chuẩn hóa dữ liệu hơn là scaffold UI một lần.
Bạn có thể dùng planning mode của Koder.ai để phác thảo các thực thể (tenants, services, SLA definitions, events, rollups), rồi tạo giao diện React và backend Go/PostgreSQL làm nền tảng để mở rộng với tích hợp và logic tính toán cụ thể.
Giữ một tài liệu sống với các bước tiếp theo: tích hợp mới, định dạng export, và audit trail. Liên kết tới hướng dẫn liên quan trên /blog để khách hàng và đồng đội tự phục vụ thông tin.
Báo cáo SLA tập trung nên tạo ra một nguồn sự thật duy nhất bằng cách gom thông tin uptime, sự cố và lịch sử ticket vào cùng một giao diện có thể truy vết.
Về thực tế, nó nên:
Bắt đầu với một tập nhỏ các chỉ số mà hầu hết khách hàng công nhận, rồi mở rộng khi bạn có thể giải thích và kiểm toán chúng.
Các chỉ số khởi điểm phổ biến:
Với mỗi chỉ số, ghi rõ nó đo gì, loại trừ những gì và nguồn dữ liệu cần thiết.
Viết quy tắc bằng ngôn ngữ đơn giản trước, rồi chuyển thành logic.
Bạn thường cần định nghĩa:
Nếu hai người không đồng ý về bản mô tả bằng chữ, phiên bản code sẽ bị tranh cãi sau này.
Lưu mọi timestamp ở UTC, rồi chuyển đổi khi hiển thị theo múi giờ báo cáo của tenant.
Cũng cần quyết định trước:
Hiển thị rõ trong UI (ví dụ: “Reporting period cutoffs are in America/New_York”).
Dùng kết hợp phương pháp tích hợp tùy theo ưu tiên giữa độ mới và tính đầy đủ:
Quy tắc thực tế: webhooks nơi cần tươi mới, API pulls nơi cần đầy đủ.
Định nghĩa một tập sự kiện chuẩn hóa nhỏ để các công cụ khác nhau map về cùng khái niệm.
Ví dụ:
incident_opened / incident_closedChọn mô hình đa tenant và thực thi cô lập dữ liệu vượt ra ngoài giao diện.
Các biện pháp chính:
tenant_idGiả định rằng export và background job là nơi dễ rò rỉ dữ liệu nhất nếu bạn không thiết kế theo context tenant.
Lưu cả sự kiện thô và kết quả suy ra để vừa nhanh vừa có thể giải thích.
Một phân tách thực tế:
Thêm để báo cáo cũ có thể tái tạo chính xác sau khi thay đổi quy tắc.
Thiết kế pipeline theo giai đoạn và idempotent:
Để đáng tin cậy:
Bao gồm ba loại cảnh báo để hệ thống hoạt động, không chỉ là dashboard:
Giảm nhiễu bằng deduplication, quiet hours, và escalation; đồng thời làm cho mỗi cảnh báo có thể hành động bằng tính năng acknowledgment và ghi chú khắc phục.
downtime_started / downtime_endedticket_created / first_response / resolvedBao gồm các trường nhất quán như tenant_id, service_id, source_system, external_id, severity, và timestamp ở UTC.
calculation_version