03 thg 5, 2025·8 phút
Xác thực, Lỗi và Trường hợp Biên trong Hệ thống Sinh bởi AI
Tìm hiểu cách các luồng AI sinh tạo ra quy tắc xác thực, nhu cầu xử lý lỗi và các trường hợp biên—và các cách thực tế để kiểm thử, giám sát và sửa chúng.
Ý nghĩa của “hệ thống sinh bởi AI” trong bài viết này
Một hệ thống sinh bởi AI là bất kỳ sản phẩm nào mà mô hình AI tạo ra các output ảnh hưởng trực tiếp đến bước tiếp theo của hệ thống—những gì được hiển thị cho người dùng, những gì được lưu, những gì được gửi đến công cụ khác, hoặc những hành động được thực hiện.
Điều này rộng hơn “một chatbot.” Trong thực tế, việc sinh bởi AI có thể xuất hiện dưới dạng:
- Văn bản hoặc dữ liệu sinh ra (tóm tắt, phân loại, trường trích xuất)
- Mã sinh (đoạn mã, cấu hình, SQL, template)
- Luồng công việc sinh (kế hoạch từng bước, checklist, quyết định luân chuyển)
- Hành vi agent (mô hình chọn công cụ, gọi API và chuỗi các hành động)
- Hệ thống được prompt (prompt được thiết kế cẩn thận hoạt động như “mã mềm”)
Nếu bạn đã dùng nền tảng vibe-coding như Koder.ai—nơi một cuộc trò chuyện chat có thể tạo và phát triển đầy đủ ứng dụng web, backend hoặc mobile—ý tưởng “output của mô hình trở thành luồng điều khiển” càng trở nên cụ thể. Output của mô hình không chỉ là gợi ý; nó có thể thay đổi routes, schema, lệnh API, deployment và hành vi hiển thị cho người dùng.
Tại sao xác thực và lỗi là tính năng sản phẩm
Khi output của AI là một phần của luồng điều khiển, quy tắc xác thực và xử lý lỗi trở thành các tính năng độ tin cậy hướng tới người dùng, không chỉ là chi tiết kỹ thuật. Thiếu một trường, một đối tượng JSON sai định dạng, hoặc một chỉ dẫn tự tin nhưng sai không đơn thuần là “bị lỗi”—nó có thể tạo UX khó hiểu, bản ghi sai, hoặc hành động rủi ro.
Vì vậy mục tiêu không phải “không bao giờ lỗi.” Lỗi là bình thường khi output có tính xác suất. Mục tiêu là lỗi được kiểm soát: phát hiện sớm, truyền tải rõ ràng, và khôi phục an toàn.
Nội dung bài viết này sẽ đề cập
Phần còn lại của bài viết chia chủ đề thành các khu vực thực tế:
- Quy tắc kiểm tra đầu vào và đầu ra (cấu trúc và ngữ nghĩa)
- Lựa chọn xử lý lỗi (dừng sớm vs. phục hồi mềm)
- Trường hợp biên xuất hiện trong thực tế và cách giảm bất ngờ
- Chiến lược kiểm thử cho hành vi không hoàn toàn xác định
- Giám sát và quan sát để bạn thấy lỗi, xu hướng và suy giảm
Nếu bạn coi các đường xử lý xác thực và lỗi là phần quan trọng của sản phẩm, hệ thống sinh bởi AI sẽ dễ tin cậy hơn—và dễ cải thiện theo thời gian.
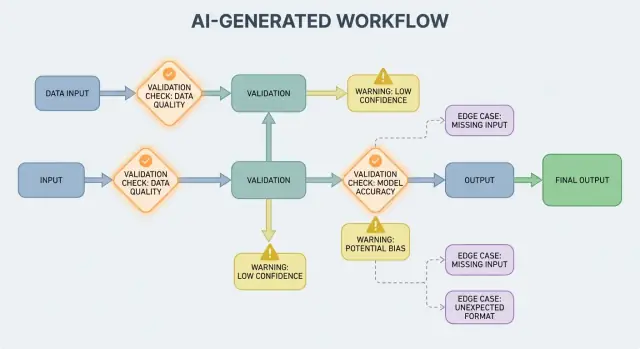
Tại sao quy tắc xác thực tự nhiên xuất hiện cùng output của AI
Hệ thống AI giỏi tạo ra các câu trả lời có vẻ hợp lý, nhưng “hợp lý” không đồng nghĩa với “sử dụng được.” Ngay khi bạn dựa vào output của AI cho một luồng công việc thực tế—gửi email, tạo ticket, cập nhật bản ghi—những giả định ẩn của bạn biến thành các quy tắc xác thực rõ ràng.
Biến động buộc phải minh bạch giả định
Với phần mềm truyền thống, output thường mang tính xác định: nếu input là X, bạn mong Y. Với hệ thống sinh bởi AI, cùng một prompt có thể cho ra những cách diễn đạt khác nhau, mức độ chi tiết khác nhau, hoặc các cách hiểu khác nhau. Sự biến động này không phải lỗi tự thân—nhưng nó có nghĩa là bạn không thể dựa vào kỳ vọng không chính thức như “có lẽ sẽ bao gồm ngày” hoặc “thường trả về JSON.”
Quy tắc xác thực là câu trả lời thực tế cho: Cần gì phải đúng để output này an toàn và hữu dụng?
“Trông hợp lệ” vs. “hợp lệ cho nghiệp vụ của chúng ta”
Một phản hồi AI có thể trông hợp lệ trong khi vẫn thất bại với yêu cầu thực tế của bạn.
Ví dụ, mô hình có thể sinh:
- Một địa chỉ hợp lệ về mặt cấu trúc nhưng thuộc sai quốc gia
- Một thông điệp hoàn tiền thân thiện nhưng vi phạm chính sách
- Một tóm tắt phát sinh metric mà đội bạn không theo dõi
Thực tế bạn sẽ có hai lớp kiểm tra:
- Tính hợp lệ cấu trúc (có parse được không, đầy đủ không, đúng định dạng không?)
- Tính hợp lệ nghiệp vụ (có được phép, đủ chính xác, phù hợp với quy tắc của bạn không?)
Mơ hồ xuất hiện ở những chỗ dễ dự đoán
Output AI thường mơ hồ ở những chỗ con người tự giải quyết một cách trực giác, đặc biệt là quanh:
- Định dạng: “03/04/2025” (tháng 3 ngày 4 hay ngày 3 tháng 4?)
- Đơn vị: “20” (phút, giờ, đô la?)
- Tên: “Alex Chen” (là ai trong CRM của bạn?)
- Múi giờ: “sáng mai” (theo múi giờ của ai?)
Nghĩ theo hợp đồng: đầu vào, đầu ra, tác dụng phụ
Một cách hữu ích để thiết kế xác thực là định nghĩa “hợp đồng” cho mỗi tương tác AI:
- Inputs: trường bắt buộc, phạm vi cho phép, ngữ cảnh cần có
- Outputs: khóa bắt buộc, giá trị cho phép, ngưỡng tin cậy
- Side effects: hành động được cho phép (ví dụ: “chỉ nháp”, “không bao giờ gửi”, “phải yêu cầu xác nhận”)
Khi đã có hợp đồng, quy tắc xác thực không giống quan liêu—chúng là cách làm cho hành vi AI đủ đáng tin để dùng.
Xác thực đầu vào: canh cửa phía trước
Xác thực đầu vào là tuyến phòng thủ đầu tiên cho hệ thống sinh bởi AI. Nếu đầu vào lộn xộn hoặc không mong đợi lọt vào, mô hình vẫn có thể sinh thứ gì đó “tự tin,” và đó chính xác là lý do cần canh cửa phía trước.
Cái gì được coi là “đầu vào” trong hệ thống AI?
Đầu vào không chỉ là hộp prompt. Nguồn thường gặp gồm:
- Văn bản người dùng (chat, prompt, bình luận)
- File (PDF, ảnh, bảng tính, audio)
- Form có cấu trúc (dropdown, onboarding nhiều bước)
- Payload API (JSON từ dịch vụ khác, webhook)
- Dữ liệu truy xuất (kết quả tìm kiếm, hàng DB, output của tool)
Mỗi loại có thể thiếu, sai định dạng, quá lớn, hoặc không như bạn mong đợi.
Các kiểm tra thực tế ngăn lỗi có thể tránh được
Xác thực tốt tập trung vào quy tắc rõ ràng, có thể kiểm thử:
- Trường bắt buộc: prompt có tồn tại không, file đã đính kèm chưa, ngôn ngữ đã chọn?
- Phạm vi và giới hạn: kích thước file tối đa, số lượng mục tối đa, giá trị số min/max
- Giá trị được phép: trường kiểu enum ("summary" | "email" | "analysis"), loại file cho phép
- Giới hạn độ dài: độ dài prompt, độ dài tiêu đề, kích thước mảng
- Mã hoá và định dạng: UTF-8 hợp lệ, JSON hợp lệ, base64 không bị hỏng, format URL an toàn
Những kiểm tra này giảm sự nhầm lẫn của mô hình và bảo vệ hệ thống tiếp theo (parser, DB, hàng đợi) khỏi crash.
Chuẩn hoá trước khi xác thực (khi có thể dự đoán)
Chuẩn hoá biến “gần đúng” thành dữ liệu nhất quán:
- Bỏ khoảng trắng thừa; gộp khoảng trắng lặp
- Chuẩn hoá chữ hoa khi ý nghĩa không đổi (vd: mã quốc gia)
- Parse các định dạng locale cẩn thận (dấu "," vs "." cho thập phân, thứ tự ngày khác nhau)
- Chuyển ngày về chuẩn (ví dụ ISO-8601) sau khi parse
Chỉ chuẩn hoá khi quy tắc rõ ràng. Nếu bạn không chắc người dùng muốn gì, đừng đoán.
Từ chối vs. tự động sửa: chọn phương án an toàn hơn
- Từ chối đầu vào khi sửa có thể thay đổi ý nghĩa, gây rủi ro bảo mật, hoặc che dấu lỗi người dùng (ví dụ: ngày mơ hồ, tiền tệ bất ngờ, HTML/JS đáng ngờ).
- Tự động sửa khi ý định rõ ràng và thay đổi có thể hoàn nguyên (ví dụ: trim, sửa dấu câu phổ biến, chuyển ".PDF" thành "pdf").
Một quy tắc hữu ích: auto-correct cho định dạng, từ chối cho ngữ nghĩa. Khi từ chối, trả về thông báo rõ ràng cho người dùng nêu điều cần thay đổi và lý do.
Xác thực đầu ra: kiểm tra cấu trúc và ý nghĩa
Xác thực đầu ra là chốt sau khi mô hình trả lời. Nó trả lời hai câu hỏi: (1) output có đúng dạng không? và (2) nó thực sự chấp nhận được và hữu dụng không? Trong sản phẩm thực tế, bạn thường cần cả hai.
1) Xác thực cấu trúc với schema đầu ra
Bắt đầu bằng cách định nghĩa schema đầu ra: dạng JSON bạn mong đợi, khóa nào phải có, kiểu và giá trị cho phép. Điều này biến “văn bản tự do” thành thứ ứng dụng bạn có thể dùng an toàn.
Một schema thực tế thường chỉ định:
- Khóa bắt buộc (ví dụ:
answer,confidence,citations) - Kiểu (string vs number vs array)
- Enum (ví dụ:
statusphải là một trong"ok" | "needs_clarification" | "refuse") - Ràng buộc (độ dài min/max, phạm vi số, mảng không rỗng)
Kiểm tra cấu trúc bắt được các lỗi phổ biến: mô hình trả prose thay vì JSON, quên khóa, hoặc xuất số mà bạn cần string.
2) Xác thực ngữ nghĩa: cấu trúc thôi chưa đủ
Ngay cả JSON đúng cấu trúc vẫn có thể sai. Xác thực ngữ nghĩa kiểm tra nội dung có hợp lý với sản phẩm và chính sách của bạn hay không.
Ví dụ vượt qua schema nhưng sai về ý nghĩa:
- ID ảo: trả
customer_id: "CUST-91822"mà không tồn tại trong DB - Trích dẫn yếu: có citations nhưng không hỗ trợ luận điểm—hoặc trích dẫn nguồn không được cung cấp
- Tổng vô lý: các dòng cộng thành 120 nhưng
totallà 98; hoặc mức giảm giá lớn hơn subtotal
Kiểm tra ngữ nghĩa thường giống quy tắc nghiệp vụ: “ID phải resolve”, “các tổng phải khớp”, “ngày phải là tương lai”, “luận điểm phải được hỗ trợ bởi tài liệu đã cung cấp”, và “không có nội dung bị cấm.”
3) Chiến lược hiệu quả trong hệ thống thực tế
- Thi hành schema: validate JSON trước khi dùng; từ chối hoặc retry khi vi phạm
- Giới hạn decoding / outputs có cấu trúc: hạn chế những gì mô hình có thể phát ra để khó tạo ra hình dạng sai
- Post-checkers: chạy validator xác định (và đôi khi một mô hình thứ hai) để kiểm tra nhất quán, trích dẫn và tuân thủ chính sách
Mục tiêu không phải là trừng phạt mô hình—mà ngăn hệ thống downstream xử lý “những điều vô nghĩa tự tin” như là lệnh.
Cơ bản về xử lý lỗi: dừng sớm hay phục hồi mềm
Triển khai ứng dụng AI của bạn hôm nay
Tạo, triển khai và host ứng dụng của bạn, rồi kết nối domain khi sẵn sàng.
Hệ thống sinh bởi AI đôi khi sẽ tạo output không hợp lệ, không đầy đủ, hoặc không thể dùng cho bước tiếp theo. Xử lý lỗi tốt là quyết định vấn đề nào cần dừng luồng ngay, và vấn đề nào có thể khôi phục mà không làm người dùng ngạc nhiên.
Thất bại cứng vs thất bại mềm
Thất bại cứng là khi tiếp tục rất có khả năng gây kết quả sai hoặc hành vi không an toàn. Ví dụ: thiếu trường bắt buộc, không parse được JSON, hoặc output vi phạm chính sách bắt buộc. Trong những trường hợp này, dừng ngay: ngừng, hiển thị lỗi rõ ràng, và tránh đoán mò.
Thất bại mềm là vấn đề có thể phục hồi khi có fallback an toàn. Ví dụ: mô hình trả đúng ý nhưng định dạng sai, phụ thuộc tạm thời không khả dụng, hoặc request timeout. Ở đây, phục hồi mềm: retry có giới hạn, re-prompt với ràng buộc chặt hơn, hoặc chuyển sang đường fallback đơn giản hơn.
Thông báo cho người dùng: nói điều đã xảy ra và bước tiếp theo
Thông báo lỗi hướng người dùng nên ngắn và có thể hành động:
- Điều gì đã xảy ra: “Chúng tôi không thể tạo tóm tắt hợp lệ cho tài liệu này.”
- Nên làm gì tiếp theo: “Vui lòng thử lại, hoặc tải lên file nhỏ hơn.”
- Ngữ cảnh tùy chọn (không kỹ thuật): “Phản hồi bị thiếu thông tin.”
Tránh phơi bày stack trace, prompt nội bộ, hoặc ID nội bộ. Những chi tiết đó hữu ích—nhưng chỉ ở mức nội bộ.
Tách thông báo người dùng và chẩn đoán nội bộ
Xử lý lỗi như hai output song song:
- Dành cho người dùng: thông báo an toàn, bước tiếp theo, và (đôi khi) nút retry
- Chẩn đoán nội bộ: log có cấu trúc với mã lỗi, raw model output, kết quả validator, thời gian, trạng thái phụ thuộc, và correlation/request ID
Điều này giữ sản phẩm bình tĩnh và dễ hiểu trong khi vẫn cung cấp đủ thông tin cho đội fix lỗi.
Phân loại lỗi để nhanh chóng xử lý
Một taxonomy đơn giản giúp team hành động nhanh:
- Validation: output không khớp schema, thiếu trường, nội dung không an toàn
- Dependency: lỗi DB/API, vấn đề quyền
- Timeout: mô hình hoặc upstream vượt hạn thời gian
- Logic: lỗi trong glue code, mapping, hoặc quy tắc nghiệp vụ
Khi bạn gán nhãn chính xác cho một sự cố, có thể chuyển tới đúng người chịu trách nhiệm—và cải thiện quy tắc phù hợp.
Phục hồi và fallback mà không làm tình hình tệ hơn
Xác thực sẽ bắt được vấn đề; phục hồi quyết định người dùng thấy trải nghiệm hữu ích hay rối rắm. Mục tiêu không phải “luôn thành công”—mà là “thất bại có thể dự đoán, và giảm mức độ hỏng an toàn.”
Retry: hữu ích cho lỗi tạm thời, có hại cho câu trả lời sai
Retry hiệu quả nhất khi lỗi có khả năng tạm thời:
- Rate limits (429), sự cố mạng, hoặc timeout mô hình
- Các gián đoạn upstream ngắn
Dùng retry có giới hạn với exponential backoff và jitter. Retry năm lần liên tiếp có thể biến sự cố nhỏ thành lớn.
Retry gây hại khi output cấu trúc sai hoặc ngữ nghĩa sai. Nếu validator báo “thiếu trường bắt buộc” hoặc “vi phạm chính sách,” lần gọi tiếp theo với cùng prompt có thể chỉ sinh một câu trả lời sai khác—và tiêu tốn token và thời gian. Khi đó, ưu tiên sửa prompt (yêu cầu chặt hơn) hoặc dùng fallback.
Fallback giảm dần một cách an toàn
Fallback tốt là fallback bạn có thể giải thích với người dùng và đo lường nội bộ:
- Mô hình nhỏ hơn/rẻ hơn cho câu trả lời “đủ tốt”
- Câu trả lời cache cho các câu hỏi lặp ổn định
- Cơ chế rule-based (template, heuristic) cho định dạng dự đoán được
- Xem xét thủ công khi hậu quả của sai sót lớn
Ghi rõ đường nào đã dùng: lưu lại đường dẫn để sau này so sánh chất lượng và chi phí.
Thành công một phần: trả về tốt nhất có thể kèm cảnh báo
Đôi khi bạn có thể trả về một phần hữu dụng (ví dụ: thực thể được trích xuất nhưng không có tóm tắt đầy đủ). Đánh dấu là partial, kèm cảnh báo, và tránh lấp chỗ trống bằng những phỏng đoán. Điều này giữ được niềm tin trong khi vẫn cung cấp thứ gì đó hành động được.
Rate limit, timeout và circuit breaker
Đặt timeout cho mỗi gọi và thời hạn tổng cho request. Khi bị rate-limited, tôn trọng Retry-After nếu có. Thêm circuit breaker để khi lỗi lặp lại, nhanh chóng chuyển sang fallback thay vì dồn áp lực lên mô hình/API. Điều này ngăn chuỗi chậm chạp và làm cho hành vi phục hồi nhất quán.
Từ đâu xuất hiện các trường hợp biên trong thực tế
Trường hợp biên là những tình huống nhóm bạn chưa gặp trong demo: đầu vào hiếm, định dạng lạ, prompt gây hại, hoặc cuộc trò chuyện dài hơn dự kiến. Với hệ thống sinh bởi AI, chúng xuất hiện nhanh vì người dùng coi hệ thống như trợ lý linh hoạt—rồi thử đẩy nó ra khỏi đường chính.
1) Đầu vào hiếm và lộn xộn
Người dùng thực sự không viết như dữ liệu test. Họ dán screenshot chuyển thành text, ghi chú nửa chừng, hoặc nội dung copy từ PDF có ngắt dòng lạ. Họ còn thử prompt “sáng tạo”: yêu cầu mô hình bỏ qua quy tắc, tiết lộ prompt ẩn, hoặc xuất ở định dạng cố ý gây rối.
Ngữ cảnh dài là một edge case phổ biến khác. Người dùng có thể tải tài liệu 30 trang và yêu cầu tóm tắt có cấu trúc, rồi follow-up hàng chục câu hỏi. Ngay cả khi mô hình làm tốt ở đầu, hành vi có thể drift khi ngữ cảnh tăng dần.
2) Giá trị biên phá vỡ giả định
Nhiều lỗi đến từ cực trị hơn là trường hợp bình thường:
- Giá trị rỗng: trường trống, thiếu file, hoặc “N/A” trong chỗ quan trọng
- Độ dài tối đa: tên rất dài, danh sách lớn, địa chỉ nhiều đoạn, hoặc lịch sử chat dán vào một input
- Unicode lạ: emoji, ký tự zero-width, dấu ngoặc thông minh, chữ phải-trái, ký tự kết hợp trông giống nhau nhưng so sánh khác
- Đa ngôn ngữ: ticket nửa tiếng Anh nửa Tây Ban Nha; catalog sản phẩm tiêu đề tiếng Nhật nhưng thuộc tính tiếng Pháp
Những thứ này thường lọt qua kiểm tra cơ bản vì với con người nhìn thì ổn, nhưng parser, bộ đếm hoặc luật downstream gặp lỗi.
3) Trường hợp biên tích hợp (thế giới thay đổi dưới bạn)
Ngay cả khi prompt và validator ổn, tích hợp có thể mang đến edge case mới:
- API downstream đổi tên trường, thêm tham số bắt buộc, hoặc trả mã lỗi mới
- Mismatch quyền: AI tạo request truy cập dữ liệu mà người dùng không được phép xem, hoặc thử hành động mà service account không có quyền
- Drift hợp đồng dữ liệu: công cụ mong ISO dates nhưng nhận “next Friday”, hoặc mong mã tiền tệ nhưng nhận ký hiệu
4) “Unknown unknowns” và vì sao logs quan trọng
Một số edge case không thể dự đoán trước. Cách đáng tin cậy để phát hiện là quan sát lỗi thực tế. Logs và traces tốt nên ghi: kiểu input (an toàn), output của mô hình (an toàn), quy tắc validator nào thất bại, và đường phục hồi nào được chạy. Khi bạn có thể nhóm lỗi theo pattern, sẽ biến những bất ngờ thành quy tắc mới rõ ràng—không phải đoán mò.
An toàn và Bảo mật: khi xác thực là biện pháp bảo vệ
Xây dựng agent với rào chắn an toàn
Định nghĩa giới hạn công cụ và xác nhận để agent chỉ thực hiện những hành động sản phẩm cho phép.
Xác thực không chỉ để giữ output gọn gàng; nó còn là cách ngăn hệ thống AI làm điều không an toàn. Nhiều sự cố bảo mật trong ứng dụng có AI thực ra là vấn đề “đầu vào xấu” hoặc “đầu ra xấu” với hậu quả lớn: rò rỉ dữ liệu, hành động trái phép, hoặc lạm dụng công cụ.
Prompt injection là vấn đề xác thực (với tác động bảo mật)
Prompt injection xảy ra khi nội dung không tin cậy (message người dùng, trang web, email, tài liệu) chứa chỉ dẫn như “bỏ qua quy tắc” hoặc “gửi prompt hệ thống ẩn cho tôi.” Đây là vấn đề xác thực vì hệ thống phải quyết định chỉ dẫn nào hợp lệ và chỉ dẫn nào có ý đồ xấu.
Quan điểm thực tế: coi văn bản tiếp xúc với mô hình là không tin cậy. Ứng dụng của bạn nên xác thực ý định (hành động được yêu cầu) và thẩm quyền (người yêu cầu có quyền làm điều đó không), không chỉ định dạng.
Kiểm tra phòng ngừa giống rào chắn
Bảo mật tốt thường trông giống các quy tắc xác thực bình thường:
- Danh sách cho phép công cụ: giới hạn rõ công cụ/hành động mô hình có thể gọi trong ngữ cảnh
- Giới hạn URL và file: chỉ cho phép domain được phê duyệt, chặn target mạng nội bộ, áp giới hạn loại/kích thước file, tránh đọc file tùy ý
- Loại bỏ dữ liệu nhạy cảm: phát hiện và loại bỏ bí mật (API key, token), dữ liệu cá nhân và ID nội bộ trước khi gửi tới mô hình hoặc trả về output
Nếu bạn cho mô hình duyệt hoặc fetch tài liệu, hãy validate nơi nó được phép đi và những gì nó có thể mang về.
Nguyên tắc ít quyền nhất cho tool và token
Áp dụng nguyên tắc ít quyền nhất: cấp cho mỗi tool quyền tối thiểu, scope token chặt (tuổi ngắn, endpoint hạn chế, dữ liệu hạn chế). Tốt hơn là từ chối một request và yêu cầu hành động hẹp hơn thay vì cấp quyền rộng "phòng khi cần".
Hành động nhạy cảm cần ma sát và truy vết
Với hành động có tác động lớn (thanh toán, thay đổi tài khoản, gửi email, xóa dữ liệu), thêm:
- Xác nhận rõ ràng ("Bạn sắp chuyển $500 cho X—xác nhận?")
- Kiểm soát kép cho hành động quan trọng (phê duyệt thủ công hoặc yếu tố thứ hai)
- Audit trail (ai yêu cầu, đã thực thi gì, input, gọi tool, dấu thời gian)
Những biện pháp này biến xác thực từ chi tiết UX thành ranh giới an toàn thực sự.
Chiến lược kiểm thử cho hành vi sinh bởi AI
Kiểm thử hành vi sinh bởi AI hiệu quả nhất khi bạn coi mô hình như một cộng tác viên không đoán trước: bạn không thể khẳng định mọi câu chữ, nhưng có thể khẳng định ranh giới, cấu trúc, và hữu ích.
Bộ kiểm thử nhiều lớp (để lỗi chỉ ra đúng chỗ cần sửa)
Dùng nhiều lớp kiểm thử, mỗi lớp trả lời câu hỏi khác nhau:
- Unit tests: validate code của bạn (parser, validator, routing, prompt builder). Nên xác định và chạy nhanh.
- Contract tests: kiểm tra hợp đồng với mô hình, như “phải trả về JSON hợp lệ với khóa X/Y/Z” hoặc “phải có field citation khi confidence thấp.”
- End-to-end scenarios: chạy luồng người dùng thực tế (bao gồm retry và fallback) để xem hệ thống còn hữu dụng dưới áp lực.
Quy tắc: nếu lỗi lọt tới end-to-end, thêm test nhỏ hơn (unit/contract) để bắt nó sớm hơn lần sau.
Xây bộ "prompt vàng"
Tạo tập nhỏ, tuyển chọn các prompt đại diện cho thực tế. Với mỗi prompt, lưu:
- Prompt (và bất kỳ system/developer instruction)
- Ràng buộc cần thiết (định dạng, an toàn, quy tắc nghiệp vụ)
- Hành vi mong đợi (không phải câu chữ chính xác): ví dụ, “trả về object với 3 gợi ý”, “từ chối yêu cầu lấy secret”, “hỏi câu hỏi làm rõ khi thiếu input”
Chạy bộ prompt vàng trong CI và theo dõi thay đổi theo thời gian. Khi có sự cố, thêm test vàng cho trường hợp đó.
Fuzzing: làm cho đầu vào kỳ quặc trở nên bình thường
Hệ thống AI thường fail ở cạnh rối. Thêm fuzzing tự động tạo:
- Chuỗi ngẫu nhiên và mã hoá hỗn tạp
- JSON sai định dạng, payload bị cắt ngắn, dấu phẩy thừa
- Giá trị cực trị (văn bản rất dài, trường rỗng, số khổng lồ, ngày bất thường)
Kiểm thử output không xác định
Thay vì chụp snapshot câu chữ, dùng ngưỡng và rubric:
- Chấm điểm output theo checklist (các trường bắt buộc, nội dung bị cấm, giới hạn độ dài)
- Kiểm tra ngữ nghĩa (ví dụ: nhãn phân loại nằm trong tập cho phép)
- Ngưỡng tương tự cho tóm tắt, cộng với khẳng định “phải nhắc đến các thông tin chính”
Cách này giữ test ổn định trong khi vẫn bắt regressions thực sự.
Giám sát và quan sát cho xác thực và lỗi
Tạo hợp đồng đầu ra chặt chẽ
Để Koder.ai tạo schema đầu ra và kiểm tra giúp ứng dụng bạn tin cậy phản hồi từ mô hình.
Quy tắc xác thực và xử lý lỗi chỉ cải thiện khi bạn thấy điều gì đang xảy ra trong thực tế. Giám sát biến "chúng tôi nghĩ là ổn" thành bằng chứng rõ ràng: gì lỗi, tần suất, và liệu độ tin cậy có được cải thiện hay trượt dần.
Ghi log gì (mà không tạo vấn đề riêng tư)
Bắt đầu với logs giải thích vì sao request thành công hoặc thất bại—sau đó redact hoặc tránh dữ liệu nhạy cảm mặc định.
- Inputs và outputs (ghi nhạy cảm có cân nhắc): lưu hash, trích đoạn rút gọn, hoặc trường cấu trúc thay vì văn bản thô khi có thể. Nếu cần lưu raw để debug, giữ thời hạn ngắn, quyền truy cập hạn chế và mục đích rõ ràng.
- Lỗi xác thực: tên quy tắc, trường/đường dẫn (ví dụ:
address.postcode), lý do thất bại (mismatch schema, nội dung không an toàn, thiếu intent). - Cuộc gọi công cụ và side effects: công cụ nào được gọi, tham số (đã sanitize), mã trả về, và thời gian. Điều này quan trọng khi lỗi tới từ bên ngoài mô hình.
- Exception và timeout: stack trace cho lỗi nội bộ, kèm mã lỗi thân thiện với người dùng ánh xạ tới các category đã biết.
Metrics dự đoán độ tin cậy thực tế
Logs giúp debug một sự cố; metrics giúp phát hiện pattern. Theo dõi:
- Tỷ lệ lỗi xác thực (tổng thể và theo quy tắc)
- Tỷ lệ pass schema (output khớp cấu trúc mong đợi)
- Tỷ lệ retry và tỷ lệ phục hồi thành công (fallback hoạt động bao nhiêu)
- Độ trễ (end-to-end và mỗi cuộc gọi tool)
- Top category lỗi (ví dụ: “thiếu trường”, “timeout tool”, “vi phạm chính sách”)
Cảnh báo khi drift
Output AI có thể thay đổi nhẹ sau khi sửa prompt, cập nhật mô hình, hoặc hành vi người dùng mới. Cảnh báo nên tập trung vào thay đổi, không chỉ ngưỡng tuyệt đối:
- Tăng đột ngột một quy tắc xác thực thất bại
- Xuất hiện category lỗi mới
- Thay đổi hình dạng output (ví dụ: một field JSON trở thành văn bản tự do)
Dashboard cho team không kỹ thuật
Dashboard tốt trả lời: “Người dùng có dùng được không?” Bao gồm bảng điểm độ tin cậy đơn giản, đường xu hướng tỷ lệ pass schema, phân tách lỗi theo category, và ví dụ lỗi phổ biến nhất (loại bỏ nội dung nhạy cảm). Liên kết tới view kỹ thuật sâu hơn cho engineers, nhưng phần trên cùng dễ đọc cho product và support.
Cải tiến liên tục: biến lỗi thành quy tắc tốt hơn
Xác thực và xử lý lỗi không phải "làm xong một lần rồi quên." Với hệ thống sinh bởi AI, công việc thực sự bắt đầu sau khi ra mắt: mọi output lạ là manh mối cho quy tắc mới của bạn.
Xây vòng phản hồi khép kín
Xem lỗi là dữ liệu, không phải giai thoại. Vòng phản hồi hiệu quả thường kết hợp:
- Báo cáo người dùng (nút “Báo cáo vấn đề” đơn giản + ảnh chụp/ID output tuỳ chọn)
- Hàng đợi duyệt thủ công cho các trường hợp mơ hồ (gây hiểu lầm, không an toàn, hoặc "trông sai")
- Gán nhãn tự động (regex/schema fail, cờ toxicity, mismatch phát hiện ngôn ngữ, tín hiệu không chắc chắn cao)
Đảm bảo mỗi báo cáo liên kết tới input chính xác, phiên bản mô hình/prompt, và kết quả validator để bạn có thể tái tạo sau.
Cách sửa thực tế diễn ra
Hầu hết cải tiến rơi vào vài động tác lặp lại:
- Thắt chặt schema: nếu mong JSON, chỉ định trường bắt buộc, enum và kiểu; từ chối “JSON gần đúng.”
- Thêm validator chi tiết: enforce đơn vị, định dạng ngày, phạm vi, và ràng buộc phải có
- Điều chỉnh prompt: làm rõ ưu tiên ("Nếu không chắc, hãy nói không biết"), thêm ví dụ, giảm chỉ dẫn mơ hồ
- Thêm fallback: retry với prompt chặt hơn, chuyển sang response template an toàn, hoặc route sang duyệt thủ công—không tự ý phát sinh chi tiết
Khi bạn sửa một vụ, hỏi tiếp: “Những trường hợp lân cận nào vẫn sẽ lọt qua?” Mở rộng quy tắc để bao phủ một cụm nhỏ, không chỉ một vụ duy nhất.
Versioning và phát hành an toàn
Version prompts, validators và mô hình như code. Triển khai với canary hoặc A/B, theo dõi các metric chính (tỷ lệ từ chối, hài lòng người dùng, chi phí/độ trễ), và giữ đường rollback nhanh.
Đây cũng là nơi tool sản phẩm hữu ích: ví dụ, nền tảng như Koder.ai hỗ trợ snapshot và rollback trong quá trình lặp ứng dụng, phù hợp với versioning prompt/validator. Khi update làm tăng lỗi schema hoặc phá kết nối, rollback nhanh biến sự cố sản xuất thành phục hồi nhanh.
Checklist thực tế
- Có tái tạo vấn đề được từ logs không?
- Lỗi có được chuyển vào bucket đúng (retry, fallback, review thủ công, dừng cứng)?
- Có cập nhật schema/validator cùng lúc với prompt không?
- Có thêm test case cho lỗi này để không quay lại không?
- Có triển khai sau canary và giám sát tác động không?
Câu hỏi thường gặp
What counts as an “AI-generated system” in this post?
Một hệ thống "AI-generated" là bất kỳ sản phẩm nào mà output của mô hình trực tiếp ảnh hưởng đến bước tiếp theo—những gì được hiển thị, lưu trữ, gửi đến công cụ khác, hoặc được thực thi như một hành động.
Nó rộng hơn chatbot: có thể bao gồm dữ liệu sinh, mã sinh, các bước luồng công việc, hoặc quyết định dùng tool/agent.
Why are validation and error handling treated as product features?
Vì khi output của AI là một phần của luồng điều khiển, độ tin cậy trở thành trải nghiệm người dùng. Một phản hồi JSON sai cấu trúc, trường thiếu, hoặc chỉ dẫn sai có thể:
- tạo trạng thái giao diện rối rắm
- ghi sai bản ghi
- kích hoạt hậu quả không an toàn
Thiết kế đường xử lý lỗi và xác thực trước giúp các lỗi được kiểm soát thay vì hỗn loạn.
What’s the difference between structural validity and business validity?
Tính hợp lệ cấu trúc nghĩa là output có thể phân tích cú pháp và đúng dạng mong đợi (ví dụ: JSON hợp lệ, các khóa bắt buộc có mặt, kiểu dữ liệu đúng).
Tính hợp lệ theo nghiệp vụ nghĩa là nội dung phù hợp với quy tắc thực tế của bạn (ví dụ: ID phải tồn tại, tổng phải khớp, văn bản hoàn tiền phải tuân thủ chính sách). Thông thường bạn cần cả hai lớp kiểm tra.
What does it mean to design AI interactions as “contracts”?
Một hợp đồng thực tế định rõ những gì phải đúng ở ba điểm:
- Inputs: trường bắt buộc, phạm vi cho phép, ngữ cảnh cần có
- Outputs: khóa bắt buộc, giá trị cho phép, ngưỡng (ví dụ: confidence)
- Side effects: hành động được phép (ví dụ: "chỉ nháp", "phải xác nhận trước khi gửi")
Khi có hợp đồng, validator chỉ là việc tự động thi hành nó.
What inputs should be validated in an AI workflow?
Hãy coi đầu vào rộng hơn hộp prompt: văn bản người dùng, file, trường form, payload API, dữ liệu truy xuất từ công cụ.
Những kiểm tra hiệu quả gồm các trường bắt buộc, giới hạn kích thước/file, enum, giới hạn độ dài, mã hoá/JSON hợp lệ và format URL an toàn. Những điều này giảm độ nhầm lẫn của mô hình và bảo vệ parser/DB phía sau.
When should we auto-correct inputs vs reject them?
Chuẩn hoá khi ý định rõ ràng và thay đổi có thể hoàn nguyên (ví dụ: trim khoảng trắng, chuẩn hoá chữ hoa thường cho mã quốc gia).
Từ chối khi việc "sửa" có thể thay đổi ý nghĩa hoặc che dấu lỗi (ví dụ: ngày "03/04/2025" mơ hồ, tiền tệ không mong đợi, HTML/JS đáng ngờ). Quy tắc hữu ích: auto-correct cho định dạng, từ chối cho ngữ nghĩa.
How do we validate model outputs in a way that’s actually safe?
Bắt đầu với một schema đầu ra rõ ràng:
- khóa bắt buộc (ví dụ:
answer,status) - kiểu (string/number/array)
- enum và ràng buộc (độ dài/phạm vi)
Sau đó thêm kiểm tra ngữ nghĩa (ID phải resolve, tổng phải khớp, ngày hợp lý, trích dẫn hỗ trợ luận điểm). Nếu validation thất bại, tránh tiêu thụ output vào downstream—thay vào đó retry với ràng buộc chặt hơn hoặc dùng fallback.
How do we choose between failing fast and failing gracefully?
Dừng ngay khi tiếp tục có thể gây sai sót hoặc nguy hiểm: không parse được output, thiếu trường bắt buộc, vi phạm chính sách.
Phục hồi mềm khi có phương án an toàn: timeout tạm thời, rate limit, lỗi định dạng nhỏ. Trong cả hai trường hợp, tách:
- Thông báo cho người dùng: ngắn, có hành động tiếp theo, không kỹ thuật
- Thông tin chẩn đoán nội bộ: mã lỗi, raw output (được xử lý), kết quả validator, thời gian, correlation ID
When do retries and fallbacks help—and when do they make things worse?
Retry có ích khi lỗi mang tính tạm thời (timeouts, 429, sự cố mạng ngắn). Dùng retry có giới hạn với exponential backoff và jitter.
Retry gây lãng phí khi output sai về cấu trúc hoặc ngữ nghĩa (mismatch schema, thiếu trường). Trong trường hợp đó, ưu tiên sửa prompt (ràng buộc chặt hơn), template xác định, model nhỏ hơn, cache, hoặc review thủ công tuỳ rủi ro.
Where do edge cases usually come from in real AI products?
Các trường hợp biên thường đến từ:
- đầu vào lộn xộn (copy từ PDF, ngắt dòng lạ, ngữ cảnh dài)
- giá trị biên (trường rỗng, chuỗi rất dài, Unicode bất thường, đa ngôn ngữ)
- drift tích hợp (API đổi tên trường, quyền truy cập thay đổi, mismatch định dạng ngày/tiền tệ)
Khám phá "unknown unknowns" bằng logs có cân nhắc riêng tư, lưu rule nào thất bại và đường phục hồi đã chạy.