18 thg 10, 2025·8 phút
Cách xây dựng ứng dụng web cho nhập, xuất và xác thực dữ liệu
Tìm hiểu cách thiết kế ứng dụng web nhập/xuất CSV/Excel/JSON, xác thực dữ liệu với lỗi rõ ràng, hỗ trợ vai trò, nhật ký kiểm toán và xử lý đáng tin cậy.
Tìm hiểu cách thiết kế ứng dụng web nhập/xuất CSV/Excel/JSON, xác thực dữ liệu với lỗi rõ ràng, hỗ trợ vai trò, nhật ký kiểm toán và xử lý đáng tin cậy.
Trước khi thiết kế màn hình hay chọn bộ phân tích file, hãy cụ thể hóa ai đang di chuyển dữ liệu vào/ra sản phẩm của bạn và tại sao. Một ứng dụng web nhập dữ liệu cho đội nội bộ sẽ khác nhiều so với công cụ nhập Excel tự phục vụ dành cho khách hàng.
Bắt đầu bằng cách liệt kê các vai trò sẽ tương tác với chức năng nhập/xuất:
Với mỗi vai trò, xác định trình độ và mức chịu được độ phức tạp. Khách hàng thường cần ít tuỳ chọn hơn và giải thích trong sản phẩm rõ ràng hơn nhiều.
Ghi lại các kịch bản hàng đầu và ưu tiên chúng. Các trường hợp phổ biến gồm:
Rồi xác định các chỉ số thành công có thể đo được. Ví dụ: giảm số lần nhập thất bại, rút ngắn thời gian xử lý lỗi, và giảm ticket hỗ trợ về “tệp của tôi không tải lên được.” Những chỉ số này giúp bạn đánh đổi sau này (ví dụ: đầu tư vào báo lỗi rõ ràng so với hỗ trợ nhiều định dạng file hơn).
Hãy rõ ràng về những gì bạn sẽ hỗ trợ ngay từ ngày đầu:
Cuối cùng, xác định nhu cầu tuân thủ sớm: liệu file có chứa PII không, yêu cầu lưu trữ bao lâu, và yêu cầu kiểm toán (ai nhập cái gì, khi nào, và gì đã thay đổi). Những quyết định này ảnh hưởng tới lưu trữ, ghi log và quyền khắp hệ thống.
Trước khi nghĩ về giao diện ánh xạ cột hay quy tắc xác thực CSV, hãy chọn kiến trúc mà đội bạn có thể triển khai và vận hành tự tin. Nhập/xuất là hạ tầng “nhàm” — tốc độ lặp và khả năng gỡ lỗi quan trọng hơn cái mới lạ.
Bất kỳ ngăn xếp web phổ biến nào cũng có thể làm nền cho ứng dụng nhập dữ liệu. Chọn dựa trên kỹ năng hiện có và thực tế tuyển dụng:
Chìa khoá là sự nhất quán: ngăn xếp nên giúp dễ thêm loại nhập mới, quy tắc xác thực mới và định dạng xuất mới mà không phải viết lại.
Nếu bạn muốn tăng tốc scaffold mà không ràng buộc vào prototype một lần, nền tảng vibe-coding như Koder.ai có thể hữu ích: bạn mô tả luồng nhập (upload → preview → mapping → validation → background processing → history) bằng chat, tạo UI React với backend Go + PostgreSQL, và lặp nhanh bằng planning mode và snapshot/rollback.
Dùng cơ sở dữ liệu quan hệ (Postgres/MySQL) cho bản ghi có cấu trúc, upsert và nhật ký kiểm toán cho thay đổi dữ liệu.
Lưu bản tải lên gốc (CSV/Excel) trong object storage (S3/GCS/Azure Blob). Việc giữ file thô rất quý giá cho hỗ trợ: bạn có thể tái tạo lỗi phân tích, chạy lại job và giải thích quyết định xử lý lỗi.
File nhỏ có thể chạy đồng bộ (upload → validate → apply) để UX nhanh. Với file lớn, chuyển công việc sang tác vụ nền:
Điều này cũng cho phép retry và giới hạn tốc độ ghi.
Nếu xây SaaS, quyết định sớm cách tách dữ liệu tenant (phân quyền theo hàng, schema riêng, hay DB riêng). Quyết định này ảnh hưởng API xuất, quyền và hiệu năng.
Ghi các mục tiêu cho uptime, kích thước file tối đa, số hàng kỳ vọng mỗi import, thời gian hoàn thành và giới hạn chi phí. Những con số này quyết định lựa chọn hàng đợi, chiến lược batch và indexing — trước khi bạn mài giũa UI.
Luồng tiếp nhận quyết định cảm nhận toàn bộ quá trình nhập. Nếu nó ổn định và dễ chịu, người dùng sẽ thử lại khi có lỗi — và ticket hỗ trợ giảm.
Cung cấp vùng kéo-thả và cả chọn file truyền thống cho UI web. Kéo-thả nhanh cho người dùng mạnh, còn chọn file quen thuộc và dễ truy cập hơn.
Nếu khách hàng nhập từ hệ thống khác, thêm endpoint API. Nó có thể chấp nhận multipart (file + metadata) hoặc luồng pre-signed URL cho file lớn.
Khi tải lên, thực hiện phân tích nhẹ để tạo “preview” mà không commit dữ liệu:
Preview này hỗ trợ các bước sau như ánh xạ cột và xác thực.
Luôn lưu file gốc một cách an toàn (object storage là điển hình). Giữ nó bất biến để bạn có thể:
Xử lý mỗi upload như một bản ghi quan trọng. Lưu metadata như người tải, timestamp, hệ thống nguồn, tên file và checksum (để phát hiện trùng lặp và đảm bảo toàn vẹn). Điều này vô cùng hữu ích cho truy vết và gỡ lỗi.
Chạy các kiểm tra nhanh ngay lập tức và từ chối sớm khi cần:
Nếu kiểm tra thất bại, trả về thông báo rõ ràng và cho biết cách sửa. Mục tiêu là chặn các file thực sự tệ — nhưng không chặn dữ liệu hợp lệ nhưng có thể được ánh xạ/chỉnh sửa sau.
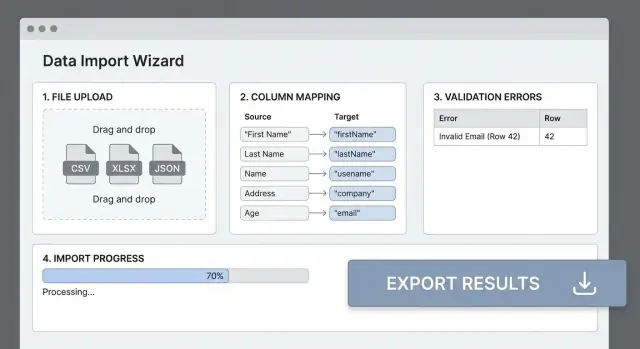
Hầu hết lỗi nhập xảy ra vì header file không khớp trường trong ứng dụng. Bước ánh xạ cột rõ ràng biến CSV lộn xộn thành đầu vào dự đoán được và cứu người dùng khỏi thử-sai.
Hiển thị bảng đơn giản: Source column → Destination field. Tự động phát hiện khớp có khả năng (so sánh không phân biệt hoa thường, từ đồng nghĩa như “E-mail” → email), nhưng luôn cho phép người dùng ghi đè.
Bao gồm vài tiện ích cải thiện trải nghiệm:
Nếu khách hàng nhập cùng định dạng hàng tuần, làm cho việc ấy chỉ bằng một cú nhấp. Cho phép họ lưu template theo:
Khi file mới được tải lên, đề xuất template dựa trên độ chồng lấp cột. Hỗ trợ versioning để người dùng cập nhật template mà không làm hỏng các lần chạy cũ.
Thêm các biến đổi nhẹ có thể áp dụng cho từng trường ánh xạ:
ACTIVE)Giữ biến đổi rõ ràng trong UI (“Applied: Trim → Parse Date”) để đầu ra có thể giải thích được.
Trước khi xử lý toàn bộ file, hiển thị preview kết quả đã ánh xạ cho (ví dụ) 20 hàng. Hiển thị giá trị gốc, giá trị sau biến đổi và cảnh báo (như “Could not parse date”). Đây là nơi người dùng phát hiện vấn đề sớm.
Yêu cầu người dùng chọn một key field (email, external_id, SKU) và giải thích điều gì xảy ra khi trùng lặp. Ngay cả khi bạn xử lý upsert sau này, bước này đặt kỳ vọng: bạn có thể cảnh báo về khoá trùng trong file và đề xuất record “win” (first, last, hoặc lỗi).
Xác thực là điểm phân biệt giữa “trình tải file” và tính năng import mà người dùng tin tưởng. Mục tiêu không phải là nghiêm ngặt vì mục đích nghiêm ngặt — mà là ngăn dữ liệu xấu lan rộng trong khi cung cấp phản hồi rõ ràng, có thể hành động.
Xem validation như ba kiểm tra riêng biệt, mỗi kiểm tra có mục đích khác nhau:
email có phải là string?”, “amount có phải là số?”, “customer_id có tồn tại không?” Đây nhanh và có thể chạy ngay sau parsing.country=US thì state là bắt buộc”, “end_date phải sau start_date”, “Plan name phải tồn tại trong workspace này.” Những cái này thường cần ngữ cảnh (các cột khác hoặc tra DB).Tách các lớp giúp hệ thống dễ mở rộng và dễ giải thích trong UI.
Quyết định sớm import sẽ:
Bạn cũng có thể hỗ trợ cả hai: strict mặc định, với tuỳ chọn “Allow partial import” cho admins.
Mỗi lỗi nên trả lời: đã xảy ra gì, ở đâu, và cách sửa thế nào.
Ví dụ: “Row 42, Column ‘Start Date’: must be a valid date in YYYY-MM-DD format.”
Phân biệt:
Người dùng hiếm khi sửa hết trong lần đầu. Làm cho việc tải lại dễ dàng bằng cách giữ kết quả xác thực gắn với một lần thử import và cho phép người dùng tải lên file đã sửa. Kết hợp với báo cáo lỗi có thể tải xuống để họ sửa hàng loạt.
Một cách tiếp cận thực tế là hybrid:
Điều này giữ validation linh hoạt mà không biến thành mê cung setting khó gỡ.
Nhập thường thất bại vì lý do tẻ nhạt: DB chậm, spike file vào giờ cao điểm, hoặc một hàng “xấu” làm block toàn bộ batch. Độ tin cậy chủ yếu là đưa công việc nặng ra khỏi đường đi request/response và làm cho mọi bước an toàn để chạy lại.
Chạy parsing, validation và ghi trong các tác vụ nền (queue/worker) để upload không gặp timeout web. Điều này cũng cho phép bạn scale worker độc lập khi khách hàng mở file lớn hơn.
Mẫu thực tế là chia công việc thành các chunk (ví dụ 1,000 hàng mỗi job). Một job “parent” lên lịch các chunk job, tổng hợp kết quả và cập nhật tiến trình.
Mô hình hoá import như một state machine để UI và đội ops luôn biết chuyện gì đang xảy ra:
Lưu timestamp và số lần thử của mỗi chuyển trạng thái để trả lời “khi nào bắt đầu?” và “đã thử bao nhiêu lần?” mà không cần mò log.
Hiển thị tiến độ đo được: số hàng đã xử lý, số còn lại, và lỗi tìm thấy đến giờ. Nếu bạn có thể ước lượng throughput, thêm ETA ước chừng — nhưng ưu tiên “~3 min” hơn đếm ngược chính xác.
Retry không nên tạo bản ghi trùng hay áp dụng cập nhật hai lần. Kỹ thuật thường gặp:
import_id + row_number (hoặc row hash) làm idempotency key ổn định.external_id) thay vì “luôn insert.”Giới hạn concurrent imports mỗi workspace và throttle các bước ghi nặng (ví dụ max N rows/sec) để tránh làm quá tải DB và giảm trải nghiệm người khác.
Nếu người ta không hiểu lỗi, họ sẽ thử tải lại cùng file cho tới khi từ bỏ. Xử lý mỗi import như một “lần chạy” quan trọng với dấu vết rõ ràng và lỗi có thể hành động.
Bắt đầu bằng việc tạo một import run ngay khi file được nộp. Bản ghi này nên chứa yếu tố thiết yếu:
Đây sẽ là màn hình lịch sử import: danh sách các lần chạy với trạng thái, các con số và trang “xem chi tiết”.
Log ứng dụng tốt cho kỹ sư, nhưng người dùng cần lỗi có thể truy vấn. Lưu lỗi như bản ghi có cấu trúc gắn với import run, lý tưởng ở cả hai mức:
Với cấu trúc này bạn có thể cung cấp lọc nhanh và insight tổng hợp như “Top 3 loại lỗi tuần này.”
Trong trang chi tiết run, cung cấp bộ lọc theo loại, cột và mức độ, cộng ô tìm kiếm (ví dụ “email”). Rồi cho phép tải CSV báo cáo lỗi bao gồm hàng gốc cộng các cột error_columns và error_message, kèm hướng dẫn rõ ràng như “Sửa định dạng ngày về YYYY-MM-DD.”
Một “dry run” xác thực mọi thứ theo cùng mapping và quy tắc, nhưng không ghi dữ liệu. Rất hữu ích cho import lần đầu và cho phép người dùng lặp lại an toàn trước khi commit thay đổi.
Import cảm thấy “xong” khi hàng lên DB — nhưng chi phí dài hạn thường nằm ở cập nhật lẫn lộn, trùng lặp và lịch sử thay đổi mơ hồ. Phần này nói về thiết kế mô hình dữ liệu để import dự đoán được, có thể hoàn tác và giải thích được.
Bắt đầu xác định cách một hàng import ánh xạ vào domain model. Với mỗi thực thể, quyết định import có thể:
Quyết định này nên rõ ràng trong UI cài đặt import và lưu cùng job để hành vi có thể lặp lại.
Nếu hỗ trợ “tạo hoặc cập nhật”, bạn cần khoá upsert ổn định — các trường nhận dạng cùng record mỗi lần. Lựa chọn phổ biến:
external_id (tốt khi từ hệ thống khác)account_id + sku)Định nghĩa quy tắc va chạm: nếu hai hàng cùng khoá, hoặc khoá khớp nhiều record thì sao? Mặc định tốt là “fail hàng với lỗi rõ ràng” hoặc “last row wins”, nhưng hãy chọn có chủ ý.
Dùng transaction nơi cần bảo toàn nhất quán (ví dụ tạo parent và children). Tránh một transaction khổng lồ cho file 200k hàng; nó có thể khoá bảng và làm retries đau đầu. Ưu tiên ghi theo chunk (ví dụ 500–2,000 hàng mỗi batch) với upsert idempotent.
Import nên tôn trọng quan hệ: nếu hàng tham chiếu parent (như Company), hoặc yêu cầu nó tồn tại hoặc tạo ra trong bước có kiểm soát. Fail sớm với lỗi “parent missing” ngăn dữ liệu nửa kết nối.
Thêm nhật ký kiểm toán cho thay đổi do import: ai kích hoạt import, khi nào, file nguồn, và tóm tắt per-record về gì đã thay đổi (cũ vs mới). Điều này hỗ trợ đội hỗ trợ, xây dựng lòng tin người dùng và đơn giản hoá rollback.
Xuất dữ liệu trông đơn giản cho tới khi khách hàng cố tải “mọi thứ” ngay trước hạn chót. Hệ thống export có thể mở rộng nên xử lý dataset lớn mà không làm chậm app hoặc tạo file không nhất quán.
Bắt đầu với ba tuỳ chọn:
Export incremental đặc biệt hữu ích cho tích hợp và giảm tải so với dump toàn bộ lặp lại.
Dù chọn gì, giữ header ổn định và thứ tự cột cố định để downstream không bị vỡ.
Export lớn không nên load toàn bộ hàng vào bộ nhớ. Dùng phân trang/stream để ghi hàng khi lấy. Điều này tránh timeout và giữ app phản hồi.
Với dataset lớn, sinh file trong job nền và thông báo khi sẵn sàng. Mô hình phổ biến:
Đi cùng pattern job nền cho import và cùng mẫu “lịch sử chạy + artifact tải xuống” mà bạn dùng cho báo cáo lỗi.
Export thường được kiểm toán. Luôn bao gồm:
Những chi tiết này giảm nhầm lẫn và hỗ trợ đối chiếu đáng tin cậy.
Nhập/xuất là tính năng mạnh vì nó di chuyển nhiều dữ liệu nhanh. Điều đó cũng làm nó là nơi dễ có lỗi bảo mật: một vai trò cho phép quá mức, một URL file bị lộ, hoặc một dòng log vô tình chứa dữ liệu cá nhân.
Bắt đầu với cùng cơ chế xác thực dùng trong toàn app — đừng tạo đường dẫn auth “đặc biệt” chỉ cho import.
Nếu người dùng làm việc trong trình duyệt, auth theo session (kèm SSO/SAML tuỳ chọn) thường phù hợp. Nếu import/export tự động (job hàng đêm, đối tác tích hợp), xem xét API keys hoặc OAuth token với scope rõ ràng và khả năng xoay khóa.
Quy tắc thực tế: UI import và API import nên áp cùng quyền, dù dùng cho đối tượng khác nhau.
Xử lý khả năng import/export như privilege rõ ràng. Vai trò phổ biến:
Đặt “download files” thành quyền riêng. Nhiều rò rỉ nhạy cảm xảy ra khi ai đó có thể xem import run và hệ thống giả định họ cũng có thể tải file gốc.
Cân nhắc cả ranh giới theo hàng hoặc tenant: user chỉ nên import/export dữ liệu cho account/workspace họ thuộc về.
Với file lưu (uploads, báo cáo lỗi tạo ra, archive export), dùng object storage riêng tư và link tải ngắn hạn. Mã hoá khi nghỉ nếu ngành/tuân thủ yêu cầu, và nhất quán: upload gốc, file staging xử lý và mọi báo cáo đều theo cùng quy tắc.
Cẩn trọng với logs. Ẩn các trường nhạy cảm (email, phone, ID, địa chỉ) và không log hàng thô mặc định. Khi cần gỡ lỗi, bật “verbose row logging” chỉ cho admin và đảm bảo nó hết hạn.
Xem mỗi upload là input không tin cậy:
Cũng xác thực cấu trúc sớm: từ chối file hỏng cấu trúc rõ ràng trước khi vào job nền, và trả thông báo rõ ràng cho người dùng.
Ghi lại sự kiện bạn cần khi điều tra: ai tải file, ai bắt đầu import, ai tải export, thay đổi quyền, và cố gắng truy cập thất bại.
Entry audit nên bao gồm actor, timestamp, workspace/tenant, và đối tượng ảnh hưởng (import run ID, export ID), không lưu dữ liệu hàng nhạy cảm. Điều này bổ trợ UI lịch sử import và giúp trả lời “ai thay đổi gì, khi nào?” nhanh chóng.
Nếu import/export chạm dữ liệu khách hàng, bạn sẽ gặp edge case: mã hoá lạ, ô gộp, hàng nửa đầy, trùng lặp, và “hôm qua chạy được mà hôm nay không.” Vận hành giữ những vụ này không thành thảm hoạ hỗ trợ.
Bắt đầu với test tập trung quanh các phần dễ lỗi nhất: parsing, mapping và validation.
Rồi thêm ít nhất một test end-to-end cho toàn bộ flow: upload → background processing → generate report. Những test này bắt lỗi hợp đồng giữa UI, API và worker.
Theo dõi tín hiệu phản ánh tác động người dùng:
Nối cảnh báo tới triệu chứng (tăng failure, queue sâu) thay vì mọi exception.
Cho đội nội bộ một admin surface nhỏ để chạy lại job, hủy import mắc kẹt, và kiểm tra lỗi (metadata file input, mapping dùng, tóm tắt lỗi và link tới logs/traces).
Với người dùng, giảm lỗi có thể tránh bằng tip nội tuyến, mẫu template tải xuống, và bước tiếp theo rõ ràng trong màn hình lỗi. Giữ 1 trang help trung tâm và link từ UI import (ví dụ: /docs).
Đưa hệ thống import/export không chỉ là “push production.” Xem nó như tính năng sản phẩm với mặc định an toàn, con đường recovery rõ ràng và chỗ để phát triển.
Thiết lập dev/staging/prod riêng với DB tách biệt và bucket object storage riêng (hoặc prefix) cho upload và export. Dùng key mã hoá và credentials khác cho mỗi môi trường, và đảm bảo worker trỏ tới queue phù hợp.
Staging nên mirror production: concurrency job, timeout và giới hạn kích thước file giống nhau. Ở đó bạn kiểm tra hiệu năng và quyền mà không rủi ro dữ liệu thật.
Import sống rất lâu vì khách hàng giữ CSV cũ. Dùng migration như bình thường, nhưng version template import (và preset mapping) để change schema không phá CSV quý khách hàng.
Cách thực tế là lưu template_version với mỗi import run và giữ code tương thích cho các version cũ cho tới khi deprecate chúng.
Dùng feature flag để triển khai an toàn:
Flags cho phép thử với internal users hoặc cohort nhỏ trước khi bật rộng.
Tài liệu hoá cách support điều tra lỗi dùng import history, job IDs và logs. Checklist đơn giản giúp: confirm template version, xem hàng lỗi đầu tiên, kiểm tra truy cập storage, rồi xem logs worker. Link checklist này từ runbook nội bộ và, nếu thích hợp, từ admin UI (ví dụ: /admin/imports).
Khi luồng core ổn định, mở rộng ngoài upload:
Những nâng cấp này giảm thao tác thủ công và làm cho ứng dụng import dữ liệu của bạn hoà nhập tự nhiên vào quy trình khách hàng.
Nếu bạn xây tính năng này và muốn rút ngắn thời gian tới “phiên bản dùng được”, cân nhắc dùng Koder.ai để prototype import wizard, trang trạng thái job và màn hình lịch sử run end-to-end, rồi export source code cho workflow engineering thông thường. Cách này đặc biệt thực tế khi mục tiêu là độ tin cậy và tốc độ lặp (không phải hoàn thiện giao diện ngày đầu).
Start by clarifying who is importing/exporting (admins, operators, customers) and your top use cases (onboarding bulk load, periodic sync, one-off exports).
Write down day-one constraints:
These decisions drive architecture, UI complexity, and support load.
Use synchronous processing when files are small and validation + writes reliably finish within your web request timeouts.
Use background jobs when:
A common pattern is: upload → enqueue → show run status/progress → notify on completion.
Store both, for different reasons:
Keep the raw upload immutable, and tie it to an import run record.
Build a preview step that detects headers and parses a small sample (e.g., 20–100 rows) before committing anything.
Handle common variability:
Fail fast on true blockers (unreadable file, missing required columns), but don’t reject data that can be mapped or transformed later.
Use a simple mapping table: Source column → Destination field.
Best practices:
Always show a mapped preview so users can catch mistakes before processing the full file.
Keep transformations lightweight and explicit so users can predict results:
ACTIVE)Show “original → transformed” in the preview, and surface warnings when a transform can’t be applied.
Separate validation into layers:
In the UI, provide actionable messages with row/column references (e.g., “Row 42, Start Date: must be YYYY-MM-DD”).
Decide whether imports are (fail whole file) or (accept valid rows), and consider offering both for admins.
Make processing retry-safe:
import_id + row_number or row hash)external_id) over “insert always”Create an import run record as soon as a file is submitted, and store structured, queryable errors—not just logs.
Useful error-reporting features:
This reduces “retry until it works” behavior and support tickets.
Treat import/export as privileged actions:
If you handle PII, decide retention and deletion rules early so you don’t accumulate sensitive files indefinitely.
Also throttle concurrent imports per workspace to protect the database and other users.