21 thg 7, 2025·8 phút
Xây dựng Ứng dụng Web Phân tích Ảnh hưởng Sự Cố, Từng Bước
Học cách thiết kế và xây dựng ứng dụng web tính toán ảnh hưởng sự cố bằng phụ thuộc dịch vụ, tín hiệu gần-thời-gian-thực và dashboard rõ ràng cho các đội.
Học cách thiết kế và xây dựng ứng dụng web tính toán ảnh hưởng sự cố bằng phụ thuộc dịch vụ, tín hiệu gần-thời-gian-thực và dashboard rõ ràng cho các đội.
Trước khi bạn xây phép tính hay dashboard, hãy quyết định “ảnh hưởng” thực sự có ý nghĩa gì trong tổ chức của bạn. Nếu bỏ qua bước này, bạn sẽ có một điểm số trông khoa học nhưng chẳng giúp ai hành động.
Ảnh hưởng là hệ quả có thể đo lường của một sự cố lên thứ mà doanh nghiệp quan tâm. Các chiều phổ biến gồm:
Chọn 2–4 chiều chính và định nghĩa rõ ràng. Ví dụ: “Ảnh hưởng = số khách hàng trả phí bị ảnh hưởng + số phút SLA có rủi ro”, chứ không phải “Ảnh hưởng = bất cứ thứ gì trông xấu trên đồ thị.”
Các vai trò khác nhau đưa ra quyết định khác nhau:
Thiết kế các đầu ra “ảnh hưởng” sao cho mỗi nhóm trả lời câu hỏi hàng đầu mà không phải dịch các chỉ số.
Quyết định độ trễ chấp nhận được. “Thời gian thực” tốn kém và thường không cần thiết; gần-thời-gian-thực (ví dụ 1–5 phút) thường đủ cho ra quyết định.
Ghi lại điều này như một yêu cầu sản phẩm vì nó ảnh hưởng tới thu thập, cache, và UI.
MVP của bạn nên trực tiếp hỗ trợ hành động như:
Nếu một chỉ số không thay đổi quyết định, có lẽ đó không phải là “impact” — chỉ là telemetry.
Trước khi bạn thiết kế màn hình hay chọn database, hãy ghi ra những gì “phân tích ảnh hưởng” phải trả lời trong một sự cố thực. Mục tiêu không phải chính xác hoàn hảo ngay ngày một — mà là kết quả nhất quán, dễ giải thích để người ứng phó tin tưởng.
Bắt đầu với dữ liệu bạn phải ingest hoặc tham chiếu để tính ảnh hưởng:
Hầu hết đội không có mapping dependency hay khách hàng hoàn hảo ngay ngày đầu. Quyết định những gì bạn cho phép nhập thủ công để app vẫn hữu ích:
Thiết kế chúng như các trường rõ ràng (không phải ghi chú ad-hoc) để có thể truy vấn sau này.
Phiên bản đầu tiên của bạn nên tạo ra đáng tin cậy:
Phân tích ảnh hưởng là công cụ ra quyết định, nên các ràng buộc quan trọng:
Viết các yêu cầu này thành các câu có thể kiểm tra được. Nếu bạn không thể xác minh, bạn không thể tin tưởng khi outage.
Mô hình dữ liệu là hợp đồng giữa ingestion, phép tính, và UI. Nếu làm đúng, bạn có thể đổi nguồn tooling, tinh chỉnh chấm điểm, và vẫn trả lời cùng câu hỏi: “Cái gì hỏng?”, “Ai bị ảnh hưởng?”, và “Trong bao lâu?”.
Ít nhất, mô hình hóa các bản ghi sau là thực thể hạng nhất:
Giữ ID ổn định và nhất quán giữa các nguồn. Nếu bạn đã có service catalog, coi nó là nguồn sự thật và map các identifier từ công cụ bên ngoài vào.
Lưu nhiều timestamp trên incident để hỗ trợ báo cáo và phân tích:
Cũng lưu các cửa sổ thời gian tính toán cho chấm điểm ảnh hưởng (ví dụ: bucket 5 phút). Điều này giúp replay và so sánh dễ dàng.
Mô hình hai đồ thị chính:
Một mẫu đơn giản là customer_service_usage(customer_id, service_id, weight, last_seen_at) để bạn có thể xếp hạng ảnh hưởng theo “mức độ phụ thuộc của khách hàng vào dịch vụ đó.”
Dependencies tiến hóa, và phép tính ảnh hưởng nên phản ánh điều đúng vào thời điểm đó. Thêm effective dating cho các cạnh:
dependency(valid_from, valid_to)Làm tương tự cho subscription khách hàng và snapshot usage. Với các phiên bản lịch sử, bạn có thể chạy lại các sự cố cũ trong post-incident review và tạo báo cáo SLA nhất quán.
Phân tích ảnh hưởng chỉ tốt như các input nuôi nó. Mục tiêu đơn giản: kéo tín hiệu từ các công cụ bạn đang dùng, rồi chuyển thành luồng sự kiện thống nhất mà app có thể suy luận.
Bắt đầu với danh sách ngắn các nguồn đáng tin cậy mô tả “có gì đó thay đổi” trong sự cố:
Đừng cố ingest hết tất cả ngay. Chọn nguồn bao phủ phát hiện, leo thang, và xác nhận.
Các công cụ khác nhau hỗ trợ các pattern tích hợp khác nhau:
Một cách thực tế: webhooks cho tín hiệu quan trọng, cộng batch import để lấp các khoảng trống.
Chuẩn hóa mọi mục đến một dạng “event” duy nhất, dù nguồn gọi nó là alert, incident, hay annotation. Ít nhất chuẩn hóa:
Trông đợi dữ liệu lộn xộn. Dùng idempotency key (source + external_id) để loại trùng, chịu được sự kiện tới muộn bằng cách sắp theo occurred_at (không phải thời gian đến), và áp dụng giá trị mặc định an toàn khi trường thiếu (vừa gắn flag để xem xét).
Một hàng đợi “dịch vụ chưa khớp” nhỏ trong UI ngăn lỗi im lặng và giữ kết quả ảnh hưởng đáng tin.
Nếu bản đồ dependency sai, blast radius cũng sai — dù tín hiệu và chấm điểm hoàn hảo. Mục tiêu là xây một đồ thị dependency bạn có thể tin tưởng khi sự cố và sau đó.
Trước khi map các cạnh, định nghĩa các node. Tạo một mục trong service catalog cho mọi hệ thống bạn có thể tham chiếu trong sự cố: API, worker nền, kho dữ liệu, nhà cung cấp bên thứ ba, và các thành phần chia sẻ quan trọng khác.
Mỗi service nên có ít nhất: owner/team, tier/độ quan trọng (ví dụ: hướng tới khách hàng vs nội bộ), mục tiêu SLA/SLO, và liên kết tới runbooks và tài liệu on-call (ví dụ, /runbooks/payments-timeouts).
Dùng hai nguồn bổ sung:
Xử lý chúng như các loại cạnh khác nhau để mọi người hiểu độ tin cậy: “được đội khai báo” so với “quan sát trong 7 ngày qua.”
Dependencies nên có hướng: Checkout → Payments không giống Payments → Checkout. Hướng giúp suy luận (“nếu Payments suy giảm, upstream nào có thể fail?”).
Cũng mô hình phụ thuộc cứng vs mềm:
Phân biệt này tránh phóng đại ảnh hưởng và giúp ưu tiên.
Kiến trúc thay đổi hàng tuần. Nếu bạn không lưu snapshot, bạn không thể phân tích chính xác một sự cố cách đây hai tháng.
Lưu các phiên bản dependency graph theo thời gian (hàng ngày, theo deploy, hoặc khi có thay đổi). Khi tính blast radius, resolve timestamp sự cố tới snapshot gần nhất, để “ai bị ảnh hưởng” phản ánh thực tế tại thời điểm đó — không phải kiến trúc hiện tại.
Khi bạn đã ingest tín hiệu (alerts, SLO burn, checks tổng hợp, ticket khách hàng), app cần một cách nhất quán để biến các input lộn xộn thành một kết luận rõ ràng: cái gì hỏng, mức độ nặng thế nào, và ai bị ảnh hưởng?
Bạn có thể đạt MVP hữu dụng với các mẫu sau:
Dù chọn cách nào, lưu các giá trị trung gian (ngưỡng bị chạm, trọng số, tier) để mọi người hiểu tại sao điểm xảy ra.
Tránh gộp mọi thứ thành một con số quá sớm. Theo dõi vài chiều riêng, rồi suy ra mức tổng:
Điều này giúp truyền đạt chính xác (ví dụ: “có nhưng chậm” vs “kết quả sai”).
Ảnh hưởng không chỉ là sức khỏe dịch vụ — mà là ai cảm nhận nó.
Dùng usage mapping (tenant → service, gói khách hàng → tính năng, traffic người dùng → endpoint) và tính số khách hàng bị ảnh hưởng trong cửa sổ thời gian phù hợp với sự cố (start time, mitigation time, và bất kỳ backfill nào).
Rõ ràng về giả định: logs lấy mẫu, ước tính traffic, hoặc telemetry một phần.
Operator sẽ cần override: alert false-positive, rollout một phần, subset tenant được biết trước.
Cho phép chỉnh sửa thủ công severity, chiều, và danh sách khách hàng bị ảnh hưởng, nhưng yêu cầu:
Trail audit này bảo vệ niềm tin vào dashboard và giúp review sau sự cố nhanh hơn.
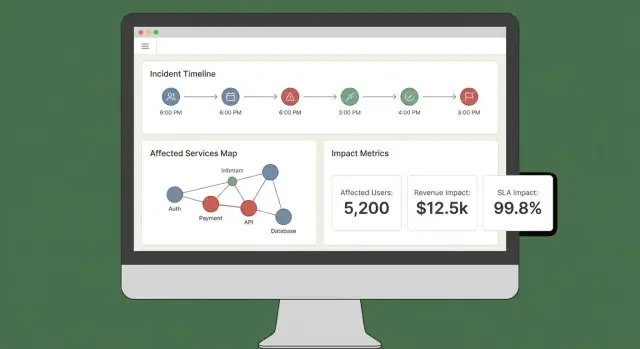
Dashboard ảnh hưởng tốt trả lời ba câu nhanh: Cái gì bị ảnh hưởng? Ai bị ảnh hưởng? Chúng ta chắc tới mức nào? Nếu người dùng phải mở năm tab để ghép thông tin, họ sẽ không tin hay hành động theo kết quả.
Bắt đầu với một tập nhỏ các view “luôn có” phù hợp quy trình sự cố:
Điểm ảnh hưởng mà không có lời giải thích sẽ cảm thấy tùy tiện. Mỗi điểm nên truy nguyên về inputs và quy tắc:
Một ngăn “Giải thích ảnh hưởng” nhẹ có thể làm điều này mà không làm rối view chính.
Cho phép cắt lát theo dịch vụ, vùng, tier khách hàng, và khoảng thời gian. Cho phép click vào bất kỳ điểm chart hoặc hàng nào để khoan sâu vào bằng chứng thô (các monitor, logs, hay event cụ thể đã dẫn đến thay đổi).
Trong sự cố active, mọi người cần cập nhật di động. Bao gồm:
Nếu bạn đã có trang trạng thái, liên kết tới nó bằng route relative như /status để đội truyền thông tham chiếu nhanh.
Phân tích ảnh hưởng chỉ hữu ích nếu mọi người tin tưởng nó — điều đó có nghĩa là kiểm soát ai thấy gì và giữ hồ sơ rõ ràng về thay đổi.
Định nghĩa vài vai trò khớp cách sự cố được vận hành:
Giữ quyền gắn với hành động, không phải chức danh. Ví dụ, “có thể xuất báo cáo ảnh hưởng khách hàng” là quyền bạn có thể cấp cho commanders và một vài admin.
Phân tích ảnh hưởng thường chạm tới định danh khách hàng, tier hợp đồng, và đôi khi chi tiết liên hệ. Áp dụng least privilege mặc định:
Ghi những hành động chính với ngữ cảnh đủ cho review:
Lưu audit log ở dạng append-only với timestamp và danh tính actor. Làm cho chúng có thể tìm kiếm theo incident để hữu dụng trong review sau sự cố.
Tài liệu rõ những gì hỗ trợ được ngay—thời gian lưu trữ, quyền truy cập, mã hóa, và phạm vi audit—và những gì đang trong roadmap.
Một trang “Security & Audit” ngắn trong app (ví dụ, /security) giúp đặt kỳ vọng và giảm câu hỏi ad-hoc trong lúc sự cố.
Phân tích ảnh hưởng chỉ quan trọng nếu nó dẫn tới hành động trong sự cố. App của bạn nên hoạt động như “đồng hành” cho channel sự cố: biến tín hiệu vào thành cập nhật rõ ràng, và thúc đẩy khi ảnh hưởng thay đổi đáng kể.
Bắt đầu tích hợp với nơi responders đang làm việc (thường Slack, Microsoft Teams, hoặc công cụ sự cố chuyên dụng). Mục tiêu không phải thay thế channel — mà là đăng cập nhật có ngữ cảnh và giữ hồ sơ chung.
Một mẫu thực tế là coi channel sự cố như input và output:
Nếu prototype nhanh, hãy xây workflow end-to-end trước (incident view → summarize → notify) rồi mới hoàn thiện chấm điểm. Nền tảng như Koder.ai có thể hữu ích: bạn có thể lặp nhanh trên dashboard React và backend Go/PostgreSQL qua workflow chat-driven, rồi xuất source code khi đội đồng ý UX phù hợp thực tế.
Tránh spam bằng cách trigger thông báo chỉ khi ảnh hưởng vượt ngưỡng rõ ràng. Các trigger phổ biến:
Khi crossing, gửi thông điệp giải thích tại sao (cái gì thay đổi), ai cần hành động, và làm gì tiếp theo.
Mỗi thông báo nên bao gồm link “bước tiếp theo” để responders hành động nhanh:
Giữ các đường dẫn này ổn định và relative để chúng hoạt động trên các môi trường.
Xây hai định dạng tóm tắt từ cùng dữ liệu:
Hỗ trợ tóm tắt theo lịch (ví dụ mỗi 15–30 phút) và hành động “tạo cập nhật” theo yêu cầu, kèm bước phê duyệt trước khi gửi ra ngoài.
Phân tích ảnh hưởng chỉ có ích nếu mọi người tin tưởng trong và sau sự cố. Xác thực phải chứng minh hai điều: (1) hệ thống tạo ra kết quả ổn định, dễ giải thích, và (2) kết quả đó khớp với những gì tổ chức sau này đồng ý đã xảy ra.
Bắt đầu với test tự động bao phủ hai khu vực hay lỗi nhất: logic chấm điểm và ingestion dữ liệu.
Giữ fixtures test dễ đọc: khi ai đó thay quy tắc, họ cần hiểu tại sao điểm thay đổi.
Chế độ replay là con đường nhanh để tạo niềm tin. Chạy các sự cố lịch sử qua app và so sánh những gì hệ thống sẽ hiển thị “tại thời điểm đó” với kết luận mà responders rút ra sau đó.
Mẹo thực tế:
Sự cố thực hiếm khi giống outage sạch. Bộ xác thực nên bao gồm kịch bản như:
Với mỗi trường hợp, assert không chỉ điểm mà còn lời giải thích: tín hiệu nào và những dependency/khách hàng nào đã dẫn đến kết quả.
Định nghĩa độ chính xác bằng cách vận hành, rồi theo dõi nó.
So sánh ảnh hưởng tính toán với kết luận review sau sự cố: dịch vụ bị ảnh hưởng, thời lượng, số khách hàng, vi phạm SLA, và mức độ. Log sai lệch như issue xác thực với category (dữ liệu thiếu, dependency sai, ngưỡng lỗi, tín hiệu trễ).
Theo thời gian, mục tiêu không phải hoàn hảo — mà là ít bất ngờ hơn và nhanh đồng thuận hơn khi sự cố.
Đưa một MVP phân tích ảnh hưởng là chủ yếu về độ tin cậy và vòng phản hồi. Lựa chọn triển khai ban đầu nên ưu tiên tốc độ thay đổi, không phải scale lý thuyết tương lai.
Bắt đầu với modular monolith trừ khi bạn đã có đội nền tảng mạnh và ranh giới dịch vụ rõ ràng. Một unit deployable đơn giản giúp migration, debug, và test end-to-end.
Tách thành services chỉ khi bạn gặp khó khăn thật sự:
Một lựa chọn thực tế là một app + background workers (queue) + edge ingestion riêng nếu cần. Nếu muốn di chuyển nhanh mà không xây nền tảng lớn, Koder.ai có thể giúp tăng tốc MVP: workflow chat-driven phù hợp để xây UI React, API Go, và data model PostgreSQL, với snapshot/rollback khi bạn lặp trên quy tắc chấm điểm và workflow.
Dùng relational storage (Postgres/MySQL) cho thực thể lõi: incidents, services, customers, ownership, và snapshot ảnh hưởng đã tính. Dễ truy vấn, audit, và mở rộng.
Với tín hiệu khối lượng lớn (metrics, event trích xuất từ logs), thêm store time-series (hoặc columnar) khi retention raw và rollup trở nên đắt với SQL.
Xem xét graph DB chỉ khi truy vấn dependency trở thành nút thắt hoặc mô hình dependency rất động. Nhiều đội có thể làm tốt với bảng adjacency cộng cache.
App phân tích ảnh hưởng trở thành một phần của toolchain sự cố, nên instrument nó như phần mềm production:
Expose view “health + freshness” trong UI để responders có thể tin (hoặc nghi ngờ) các con số.
Định nghĩa scope MVP chặt: một tập nhỏ công cụ để ingest, một điểm ảnh hưởng rõ ràng, và dashboard trả lời “ai bị ảnh hưởng và bao nhiêu.” Rồi lặp:
Đối xử với mô hình như một sản phẩm: version nó, migrate an toàn, và document thay đổi cho review sau sự cố.
Impact là hệ quả có thể đo lường của một sự cố lên các kết quả quan trọng với doanh nghiệp.
Một định nghĩa thực dụng sẽ ghi rõ 2–4 chiều chính (ví dụ: khách hàng trả phí bị ảnh hưởng + số phút rủi ro SLA) và loại trừ rõ ràng “bất cứ thứ gì trông xấu trên đồ thị.” Điều này giữ cho kết quả gắn với quyết định, không chỉ telemetry.
Chọn những chiều liên quan trực tiếp tới hành động mà đội thực hiện trong 10 phút đầu.
Các chiều phù hợp cho MVP:
Giới hạn 2–4 để điểm số dễ giải thích.
Thiết kế đầu ra để mỗi vai trò trả lời câu hỏi chính mà họ cần mà không phải dịch các chỉ số:
“Real-time” tốn kém; nhiều đội vẫn ổn với gần-thời-gian-thực (1–5 phút).
Ghi mục tiêu độ trễ làm yêu cầu vì nó ảnh hưởng tới:
Cũng hiển thị kỳ vọng trong UI (ví dụ: “dữ liệu mới nhất cách 2 phút”).
Bắt đầu bằng cách liệt kê các quyết định người ứng phó phải đưa ra, rồi đảm bảo mỗi đầu ra hỗ trợ một quyết định:
Nếu một chỉ số không thay đổi quyết định, để nó là telemetry chứ không phải impact.
Các input tối thiểu thường bao gồm:
Cho phép các trường thủ công rõ ràng, có thể truy vấn để ứng dụng vẫn hữu ích khi dữ liệu thiếu:
Yêu cầu ai/thời gian/tại sao cho mọi thay đổi để giữ niềm tin lâu dài.
MVP đáng tin cậy nên tạo ra:
Tùy chọn: ước tính chi phí (khoản SLA, rủi ro doanh thu) với khoảng độ tin cậy.
Chuẩn hóa mọi nguồn thành một schema sự kiện để phép tính nhất quán.
Ít nhất chuẩn hóa:
occurred_at, detected_at, resolved_atBắt đầu đơn giản và có thể giải thích được:
Lưu các giá trị trung gian (ngưỡng bị chạm, trọng số, tier, độ tin cậy) để người dùng thấy tại sao điểm thay đổi. Theo dõi các chiều (availability/latency/errors/data correctness/security) trước khi gộp thành một số.
Nếu một chỉ số không dùng được cho bất kỳ khán giả nào trong số này, nó có thể không phải là “impact.”
Bộ này đủ để tính “cái gì hỏng”, “ai bị ảnh hưởng” và “trong bao lâu”.
service_id chuẩn (mapping từ tag/tên tool)source + payload gốc (cho audit/debug)Xử lý dữ liệu bừa bộn bằng idempotency key (source + external_id) và dung nạp sự kiện tới muộn dựa trên occurred_at.