26 thg 11, 2025·8 phút
Cách xây dựng ứng dụng web để theo dõi điểm nghẽn vận hành
Hướng dẫn từng bước để lập kế hoạch, thiết kế và phát hành ứng dụng web ghi nhận dữ liệu luồng công việc, phát hiện điểm nghẽn và giúp đội giảm trễ.
Bắt đầu từ vấn đề và các quyết định
Một ứng dụng theo dõi quy trình chỉ hữu ích nếu nó trả lời một câu hỏi cụ thể: “Chúng ta đang bị kẹt ở đâu, và nên làm gì về điều đó?” Trước khi vẽ màn hình hoặc chọn kiến trúc ứng dụng web, hãy định nghĩa “điểm nghẽn” nghĩa là gì trong hoạt động của bạn.
Định nghĩa điều gì được tính là điểm nghẽn
Một điểm nghẽn có thể là một bước (ví dụ: “Kiểm duyệt QA”), một đội (ví dụ: “thực hiện đơn hàng”), một hệ thống (ví dụ: “cổng thanh toán”), hoặc thậm chí một nhà cung cấp (ví dụ: “đơn vị vận chuyển”). Chọn các định nghĩa mà bạn thực sự sẽ quản lý. Ví dụ:
- Một bước là điểm nghẽn khi thời gian chờ trung bình của nó vượt 24 giờ.
- Một đội là điểm nghẽn khi số công việc đang tiến hành (WIP) duy trì ở trên ngưỡng đặt trước trong 3 ngày.
- Một hệ thống là điểm nghẽn khi các sự cố làm thời gian chu kỳ tăng vọt vượt ngưỡng thỏa thuận.
Liệt kê các quyết định mà ứng dụng phải hỗ trợ
Bảng điều khiển vận hành của bạn nên thúc đẩy hành động, không chỉ báo cáo. Viết ra các quyết định bạn muốn đưa ra nhanh hơn và tự tin hơn, chẳng hạn:
- Nhân sự: “Tuần này chúng ta có nên chuyển một người từ Đội A sang Đội B không?”
- Ưu tiên: “Đơn hàng/ticket nào nên được đẩy lên trước để bảo vệ SLA?”
- Tự động hóa: “Bước nào đủ ổn định (và tốn kém) để tự động hóa trước?”
Xác định người dùng chính và nhu cầu của họ
Người dùng khác nhau cần các cảnh khác nhau:
- Quản lý vận hành cần một cái nhìn rõ ràng “can thiệp ở đâu hôm nay”.
- Trưởng nhóm cần khoan sâu vào từng hàng đợi, các chướng ngại và điểm chuyển giao.
- Chuyên viên phân tích cần định nghĩa nhất quán và xuất dữ liệu cho phân tích luồng công việc.
Thiết lập chỉ số thành công cho chính ứng dụng
Quyết định cách bạn biết ứng dụng đang hoạt động. Các đo lường tốt bao gồm mức độ chấp nhận (người dùng hoạt động hàng tuần), thời gian tiết kiệm cho báo cáo, và thời gian giải quyết nhanh hơn (rút ngắn thời gian phát hiện và thời gian sửa điểm nghẽn). Những chỉ số này giúp bạn tập trung vào kết quả, không phải tính năng.
Chọn luồng công việc và viết một sơ đồ quy trình đơn giản
Trước khi thiết kế bảng, dashboard hoặc cảnh báo, hãy chọn một quy trình bạn có thể mô tả bằng một câu. Mục tiêu là theo dõi nơi công việc chờ—vì vậy hãy bắt đầu nhỏ và chọn một hoặc hai quy trình quan trọng và có khối lượng ổn định, như thực hiện đơn hàng, ticket hỗ trợ, hoặc tuyển dụng nhân viên.
Phạm vi hẹp giúp định nghĩa hoàn thành rõ ràng và ngăn dự án bị đình trệ vì các đội khác nhau không đồng ý về cách quy trình nên hoạt động.
Bắt đầu với 1–2 quy trình có tín hiệu cao
Chọn các luồng công việc mà:
- Xảy ra thường xuyên (đủ dữ liệu để nhận diện mẫu)
- Có ít nhất một điểm chuyển giao (nơi hàng đợi hình thành)
- Có tác động rõ ràng đến khách hàng (thời gian, chi phí, hài lòng)
Ví dụ, “ticket hỗ trợ” thường tốt hơn “customer success” vì nó có đơn vị công việc rõ ràng và các hành động có dấu thời gian.
Vẽ sơ đồ các bước và điểm chuyển giao bằng ngôn ngữ đơn giản
Viết quy trình dưới dạng danh sách các bước bằng từ ngữ mà đội đang dùng. Bạn không đang tài liệu hóa chính sách—bạn đang xác định trạng thái mà mục công việc di chuyển qua.
Một sơ đồ nhẹ có thể trông như:
- Ticket tạo → phân loại → gán → agent xử lý → chờ khách hàng → giải quyết
Ở giai đoạn này, gọi rõ các điểm chuyển giao (phân loại → gán, agent → chuyên gia, v.v.). Điểm chuyển giao thường là nơi thời gian chờ ẩn nấp, và là những khoảnh khắc bạn muốn đo sau này.
Định nghĩa sự kiện bắt đầu/kết thúc và “xong” cho mỗi bước
Với mỗi bước, viết hai điều:
- Sự kiện bắt đầu (điều gì chứng minh bước đã bắt đầu?)
- Sự kiện kết thúc (điều gì chứng minh bước đã kết thúc?)
Giữ cho các sự kiện có thể quan sát được. “Agent bắt đầu điều tra” mang tính chủ quan; “trạng thái đổi sang In Progress” hoặc “ghi chú nội bộ đầu tiên được thêm” thì có thể theo dõi được.
Cũng định nghĩa “xong” để ứng dụng không nhầm lẫn hoàn thành một phần với hoàn thành. Ví dụ, “resolved” có thể nghĩa là “tin nhắn giải pháp đã gửi và ticket được đánh dấu Resolved”, không chỉ “công việc nội bộ đã xong”.
Ghi chú các ngoại lệ phổ biến bạn sẽ theo dõi sau
Thực tế vận hành có những đường đi lộn xộn: làm lại, leo thang, thiếu thông tin, và mở lại mục. Đừng cố mô tả mọi thứ ngay ngày đầu—chỉ ghi lại các ngoại lệ để bạn có thể thêm chúng một cách có chủ ý sau này.
Một ghi chú đơn giản như “10–15% ticket được leo thang lên Tier 2” là đủ. Bạn sẽ dùng các ghi chú này để quyết định ngoại lệ nào trở thành bước riêng, thẻ, hoặc luồng riêng khi mở rộng hệ thống.
Định nghĩa chỉ số thực sự tiết lộ điểm nghẽn
Điểm nghẽn không phải là cảm giác—nó là một sự chậm lại có thể đo được tại một bước cụ thể. Trước khi bạn xây biểu đồ, quyết định con số nào sẽ chứng minh nơi công việc tích tụ và lý do.
Chọn một bộ nhỏ các phép đo cốt lõi
Bắt đầu với bốn chỉ số hoạt động cho hầu hết quy trình:
- Cycle time: thời gian một mục từ bắt đầu đến xong.
- Wait/queue time: thời gian một mục nằm im giữa các bước.
- Throughput: số mục hoàn thành trong một khoảng thời gian.
- WIP (work in progress): số mục đang “trong hệ thống”.
Chúng bao phủ tốc độ (cycle), trạng thái chờ (queue), sản lượng (throughput), và tải (WIP). Phần lớn các “độ trễ bí ẩn” biểu hiện dưới dạng queue time và WIP tăng tại một bước cụ thể.
Định nghĩa phép tính (bao gồm các trường hợp biên)
Viết các định nghĩa mà cả đội bạn có thể đồng ý, rồi triển khai chính xác như vậy.
- Cycle time =
done_timestamp − start_timestamp.- Các trường hợp biên: mục bị mở lại (xử lý như một chu kỳ mới hay kéo dài chu kỳ gốc), mục chưa từng bắt đầu (loại trừ khỏi cycle time nhưng tính vào WIP), thiếu dấu thời gian (đánh dấu là chất lượng dữ liệu kém).
- Queue time = tổng các khoảng trống giữa các bước khi trạng thái là “đang chờ”.
- Các trường hợp biên: ban đêm/cuối tuần (tính theo thời gian lịch hay giờ làm việc), trạng thái bị chặn (đếm riêng nếu bạn muốn biết nguyên nhân rõ hơn).
- Throughput = đếm các mục có
done_timestamptrong cửa sổ thời gian.- Các trường hợp biên: hủy bỏ (loại trừ hoặc theo dõi riêng), hoàn thành một phần.
- WIP = đếm các mục không ở trạng thái kết thúc tại một thời điểm.
- Các trường hợp biên: mục tạm dừng (vẫn là WIP, nhưng bạn có thể muốn một “blocked WIP” riêng).
Chọn các phân tách giúp đưa ra quyết định
Chọn các lát (slices) mà quản lý thực sự dùng: đội, kênh, dòng sản phẩm, khu vực, và độ ưu tiên. Mục tiêu là trả lời: “Nơi nào chậm, với ai, và trong điều kiện nào?”
Thiết lập cửa sổ thời gian và mục tiêu
Quyết định nhịp báo cáo (hàng ngày và hàng tuần là phổ biến) và định nghĩa mục tiêu như ngưỡng SLA/SLO (ví dụ, “80% mục ưu tiên cao hoàn thành trong vòng 2 ngày”). Mục tiêu làm dashboard có thể hành động thay vì chỉ để trang trí.
Lập kế hoạch nguồn dữ liệu và phương pháp thu thập
Cách nhanh nhất để làm dự án theo dõi điểm nghẽn đình trệ là giả sử dữ liệu sẽ “tự có”. Trước khi thiết kế bảng hoặc biểu đồ, hãy liệt kê mỗi sự kiện và dấu thời gian sẽ bắt nguồn từ đâu—và cách bạn giữ nhất quán theo thời gian.
Kiểm kê các nguồn bạn đã có
Hầu hết đội vận hành đã theo dõi công việc ở vài nơi. Các điểm khởi đầu phổ biến gồm:
- Bảng tính dùng cho chuyển giao, nhật ký hàng ngày, hoặc đếm sản xuất
- Hệ thống ERP/CRM (đơn hàng, khách hàng, bước thực hiện)
- Công cụ ticketing (hàng đợi hỗ trợ, yêu cầu thay đổi, công việc bảo trì)
- Cơ sở dữ liệu nội bộ (quét kho, bảng lập lịch công việc, dữ liệu thực thi sản xuất)
Với mỗi nguồn, ghi những gì nó có thể cung cấp: một ID bản ghi ổn định, lịch sử trạng thái (không chỉ trạng thái hiện tại), và ít nhất hai dấu thời gian (vào bước, ra bước). Thiếu những điều này, việc giám sát thời gian chờ và theo dõi thời gian chu kỳ sẽ là phỏng đoán.
Chọn phương pháp ghi nhận phù hợp với nguồn
Bạn thường có ba lựa chọn, và nhiều ứng dụng dùng kết hợp:
- API pull: đồng bộ định kỳ từ ERP/CRM/công cụ ticket. Dễ lý giải, nhưng cần xử lý phân trang, giới hạn tần suất và cập nhật tăng dần.
- Webhooks: đẩy cập nhật khi công việc thay đổi. Tốt cho cảnh báo gần thời gian thực, nhưng phải thiết kế cho việc thử lại và sự kiện đến lệch thứ tự.
- Nhập thủ công / CSV: hữu ích cho đội bắt đầu từ bảng tính hoặc các trường hợp ngoại vi. Làm cho an toàn bằng mẫu, xác thực và thông báo lỗi rõ ràng.
Lên kế hoạch cho chất lượng dữ liệu (vì nó sẽ xảy ra)
Dự kiến thiếu dấu thời gian, bản sao, và trạng thái không đồng nhất (“In Progress” vs “Working”). Xây quy tắc sớm:
- Ưu tiên nhật ký sự kiện bất biến hơn là ghi đè bản ghi
- Loại bỏ trùng lặp bằng source ID + thời gian sự kiện + trạng thái
- Chuẩn hóa trạng thái về các bước chuẩn của ứng dụng
- Đánh dấu các bản ghi không thể tạo ra chu kỳ thời gian đáng tin cậy
Quyết định tần suất làm mới
Không phải quy trình nào cũng cần cập nhật thời gian thực. Chọn dựa trên quyết định:
- Thời gian thực: điều phối, phân loại hỗ trợ, rủi ro SLA
- Hằng giờ: sản lượng kho, giám sát thời gian chờ
- Hằng ngày: báo cáo hàng tuần, rà soát cải tiến liên tục
Viết điều này ra ngay; nó quyết định chiến lược đồng bộ, chi phí và kỳ vọng cho dashboard vận hành.
Thiết kế mô hình dữ liệu tối ưu cho phân tích theo thời gian
Một ứng dụng theo dõi điểm nghẽn sống hay chết nhờ khả năng trả lời các câu hỏi về thời gian: “Mất bao lâu?”, “Đã chờ ở đâu?”, và “Điều gì thay đổi ngay trước khi mọi thứ chậm lại?” Cách dễ nhất để hỗ trợ những câu hỏi đó sau này là mô hình hóa dữ liệu xung quanh các sự kiện và dấu thời gian ngay từ đầu.
Bắt đầu với các thực thể cốt lõi
Giữ mô hình nhỏ và rõ:
- Process: quy trình tổng thể (ví dụ, “Thực hiện đơn hàng”).
- Step: một giai đoạn trong quy trình (ví dụ, “Pick”, “Pack”, “Ship”).
- Work item: đơn vị di chuyển qua các bước (ticket, đơn hàng, khiếu nại).
- Event: một thay đổi trạng thái được ghi nhận (vào bước, gán, chặn, hoàn thành).
- User/Team và Assignment: ai sở hữu công việc tại thời điểm đó.
Cấu trúc này cho phép bạn đo thời gian chu kỳ theo bước, thời gian chờ giữa các bước và throughput trên toàn quy trình mà không phải sáng tạo các trường hợp đặc biệt.
Ưu tiên nhật ký sự kiện hơn các trường “trạng thái hiện tại”
Xử lý mọi thay đổi trạng thái như một bản ghi sự kiện bất biến. Thay vì ghi đè current_step và làm mất lịch sử, hãy thêm một sự kiện như:
- work_item_id
- from_step → to_step (hoặc “entered_step”)
- event_type (assigned, started, blocked, completed)
- event_time
Bạn vẫn có thể lưu snapshot “trạng thái hiện tại” để tối ưu hiệu năng, nhưng phân tích nên dựa trên nhật ký sự kiện.
Làm cho thời gian và khả năng truy vết trở thành điều không thể thương lượng
Lưu dấu thời gian ở UTC một cách nhất quán. Cũng giữ định danh nguồn gốc ban đầu (ví dụ: mã issue Jira, ID đơn hàng ERP) cho work items và events, để mọi biểu đồ có thể truy ngược về bản ghi thực.
Ghi nhận ngoại lệ mà không tạo công việc rườm rà
Lập kế hoạch các trường nhẹ cho những khoảnh khắc giải thích độ trễ:
- reason_code (tùy chọn chuẩn như “Waiting on customer”)
- comment (văn bản tùy chọn)
- blocked_flag hoặc severity
Giữ chúng là tùy chọn và dễ điền, để bạn học từ ngoại lệ mà không biến ứng dụng thành bài tập điền biểu mẫu.
Chọn kiến trúc phù hợp với đội bạn
Thiết lập cảnh báo sớm
Tạo quy tắc ngưỡng đơn giản để các điểm nghẽn được phát hiện giữa các cuộc rà soát hàng tuần.
“Kiến trúc tốt nhất” là thứ đội bạn có thể xây, hiểu và vận hành trong nhiều năm. Bắt đầu bằng việc chọn stack phù hợp với nguồn nhân lực và kỹ năng hiện có—những lựa chọn phổ biến, được hỗ trợ tốt gồm React + Node.js, Django, hoặc Rails. Sự nhất quán đánh bại sự mới lạ khi bạn vận hành một dashboard mà người ta phụ thuộc hàng ngày.
Tách biệt các mối quan tâm để hệ thống dễ chỉnh sửa
Một ứng dụng theo dõi điểm nghẽn thường vận hành tốt hơn khi bạn chia nó thành các lớp rõ ràng:
- Ingestion: nhận sự kiện (thay đổi trạng thái, dấu thời gian, chuyển giao) từ form, tích hợp, hoặc import.
- Storage: cơ sở dữ liệu giao dịch để ghi đáng tin cậy và lịch sử kiểm toán.
- Analytics queries: truy vấn tối ưu cho đọc hoặc view để tính cycle time, queue time và throughput.
- UI/API: endpoint và màn hình giữ dashboard nhanh và đáng tin cậy.
Sự tách biệt này cho phép bạn thay đổi một phần (ví dụ thêm nguồn dữ liệu) mà không phải viết lại mọi thứ.
Quyết định nơi tính toán nên diễn ra
Một số chỉ số đủ đơn giản để tính trong truy vấn cơ sở dữ liệu (ví dụ, “thời gian chờ trung bình theo bước 7 ngày gần nhất”). Những thứ khác tốn kém hoặc cần tiền xử lý (ví dụ, phân vị, phát hiện dị thường, kohort hàng tuần). Một quy tắc thực dụng:
- Làm bộ lọc và phân tách thời gian thực trong cơ sở dữ liệu.
- Dùng công việc nền để tiền tính các tổng hợp nặng và lưu chúng để dashboard tải nhanh.
- Thêm lớp phân tích chỉ khi đội bạn sẽ duy trì tự tin.
Lên kế hoạch hiệu năng từ sớm
Dashboard vận hành thất bại khi nó cảm thấy chậm. Dùng indexing trên các dấu thời gian, ID bước quy trình, và tenant/team ID. Thêm phân trang cho nhật ký sự kiện. Cache các view dashboard phổ biến (như “hôm nay” và “7 ngày gần nhất”) và làm mới cache khi có sự kiện mới.
Nếu bạn muốn thảo luận sâu hơn về các đánh đổi, giữ một ghi chép quyết định ngắn trong repo để các thay đổi sau này không bị trôi.
Con đường nhanh hơn cho đội muốn ra sản phẩm sớm
Nếu mục tiêu là xác thực phân tích luồng công việc và cảnh báo trước khi cam kết xây dựng đầy đủ, một nền tảng tạo giao diện như Koder.ai có thể giúp bạn dựng phiên bản đầu nhanh hơn: bạn mô tả quy trình, thực thể, và dashboard trong chat, rồi lặp trên UI React và backend Go + PostgreSQL được sinh ra khi bạn tinh chỉnh ghi nhận KPI.
Lợi thế thực tế cho ứng dụng theo dõi điểm nghẽn là tốc độ phản hồi: bạn có thể thử nghiệm nhập dữ liệu (API pulls, webhooks, hoặc CSV), thêm màn hình khoan sâu, và điều chỉnh định nghĩa chỉ số mà không cần hàng tuần cơ sở hạ tầng. Khi sẵn sàng, Koder.ai cũng hỗ trợ xuất mã nguồn và triển khai/hosting, giúp dễ chuyển từ prototype sang công cụ nội bộ được duy trì.
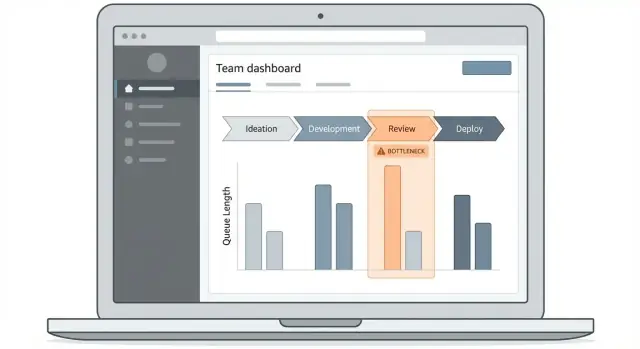
Thiết kế trải nghiệm dashboard và khoan sâu
Một ứng dụng theo dõi điểm nghẽn sống hay chết dựa vào việc người dùng có thể trả lời nhanh một câu: “Hiện tại công việc đang kẹt ở đâu, và những mục nào gây ra?” Dashboard của bạn nên làm con đường đó rõ ràng, ngay cả với người chỉ vào xem một lần một tuần.
Bắt đầu với 2–3 màn hình cốt lõi
Giữ bản phát hành đầu gọn:
- Overview dashboard: bảng trạng thái cho cycle time, queue time và các bước bị chặn hàng đầu.
- Danh sách mục công việc: bảng có tìm kiếm và lọc của các mục bị ảnh hưởng bởi độ trễ.
- Chi tiết quy trình: xem từng bước cho thấy thời gian ở mỗi giai đoạn và các điểm chuyển giao.
Những màn hình này tạo luồng khoan sâu tự nhiên mà không buộc người dùng học UI phức tạp.
Dùng trực quan giúp giải thích thời gian và luồng
Chọn loại biểu đồ phù hợp câu hỏi vận hành:
- Phễu theo bước: hiển thị nơi khối lượng tích tụ (tốt để phát hiện hàng đợi).
- Thanh thời gian ở bước: so sánh các bước theo trung vị và phân vị, không chỉ trung bình.
- Đường xu hướng: trả lời “điều này tốt hơn hay tệ hơn?” theo tuần.
- Heatmap: tiết lộ mẫu như “thứ Hai ở Review” hoặc “chuyển giao ca đêm”.
Giữ nhãn rõ ràng: “Time waiting” thay vì “Queue latency”.
Làm bộ lọc nhất quán và dễ thấy
Dùng thanh lọc chung trên các màn hình (vị trí giống nhau, mặc định giống nhau): khoảng ngày, đội, độ ưu tiên, và bước. Hiển thị các bộ lọc đang hoạt động dưới dạng chip để người dùng không đọc sai số liệu.
Thiết kế đường khoan sâu rõ ràng
Mỗi ô KPI nên có thể nhấp và dẫn đến nơi hữu ích:
KPI → bước → danh sách mục bị ảnh hưởng
Ví dụ: nhấp “Longest queue time” mở phần chi tiết bước, rồi một lần nhấp nữa hiện các mục đang chờ ở đó—sắp xếp theo độ tuổi, độ ưu tiên và người sở hữu. Điều này biến sự tò mò thành danh sách việc cụ thể, và đó là điều khiến dashboard được dùng thay vì bỏ quên.
Thêm cảnh báo và tín hiệu cảnh báo sớm
Lên kế hoạch chỉ số trước
Khóa định nghĩa thực thể, chỉ số và các trường hợp biên trước khi tạo màn hình và bảng.
Dashboard tốt cho rà soát, nhưng điểm nghẽn thường gây hại nhất giữa các cuộc họp. Cảnh báo biến ứng dụng thành hệ thống cảnh báo sớm: bạn phát hiện vấn đề khi nó đang hình thành, không phải sau khi tuần đã mất.
Bắt đầu với các quy tắc rõ ràng, nhàm nhưng hiệu quả
Bắt đầu với một tập nhỏ loại cảnh báo mà đội đã đồng ý là “xấu”:
- Vượt ngưỡng: cycle time hoặc queue time vượt giới hạn biết trước (ví dụ, “Bước Review > 24 giờ”).
- Tăng bất thường: median cycle time hôm nay tăng 30% so với tuần trước.
- Mục bị kẹt: không thay đổi trạng thái trong N giờ/ngày, hoặc mục vượt tuổi tối đa.
Giữ phiên bản đầu đơn giản. Một vài quy tắc xác định bắt được hầu hết vấn đề và dễ tin hơn các mô hình phức tạp.
Thêm kiểm tra dị thường nhẹ nhàng
Khi ngưỡng ổn định, thêm các tín hiệu “có gì đó lạ” cơ bản:
- Thay đổi phần trăm so với tuần trước (so sánh cùng ngày trong tuần giúp giảm cảnh báo sai).
- Trôi dạt trung bình động (ví dụ, trung bình 7 ngày tăng dần).
- Sự không khớp về khối lượng (đầu vào tăng nhanh hơn đầu ra tại một bước).
Biến các dị thường thành gợi ý, không phải khẩn cấp: gắn nhãn “Lưu ý” cho đến khi người dùng xác nhận hữu ích.
Gửi cảnh báo đến nơi người ta làm việc
Hỗ trợ nhiều kênh để đội chọn phù hợp:
- Email cho quản lý và bản tóm tắt hàng ngày
- Slack/Microsoft Teams cho xử lý theo thời gian thực
- Thông báo trong ứng dụng cho người chịu trách nhiệm
Mỗi cảnh báo phải có thể hành động
Một cảnh báo nên trả lời “cái gì, ở đâu, và bước tiếp theo”:
- Bước nào bị ảnh hưởng, và cửa sổ thời gian
- Nguyên nhân chính (ví dụ, đội, danh mục, độ ưu tiên)
- Một đường dẫn trực tiếp để điều tra, ví dụ: /dashboard?step=review&range=7d&filter=stuck
Nếu cảnh báo không dẫn đến hành động cụ thể, người ta sẽ tắt nó—vì vậy coi chất lượng cảnh báo là một tính năng sản phẩm, không phải thêm thắt.
Xử lý quyền, bảo mật và khả năng kiểm toán
Ứng dụng theo dõi điểm nghẽn nhanh chóng trở thành “nguồn dữ liệu đáng tin”. Điều đó tuyệt—cho đến khi người không có quyền chỉnh sửa định nghĩa, xuất dữ liệu nhạy cảm, hoặc chia sẻ dashboard ngoài nhóm. Quyền và nhật ký thay đổi không phải là thủ tục rườm rà; chúng bảo vệ niềm tin vào số liệu.
Định nghĩa vai trò và quy tắc truy cập
Bắt đầu với mô hình vai trò nhỏ, rõ ràng và mở rộng khi cần:
- Viewer: chỉ xem dashboard và báo cáo.
- Manager: có thể lọc theo đội, tạo view lưu, xác nhận cảnh báo và thêm ghi chú (nhưng không thay đổi cài đặt toàn cục).
- Admin: quản lý định nghĩa quy trình, công thức KPI, tích hợp và quyền người dùng.
Rõ ràng về quyền từng vai trò: xem sự kiện thô so với chỉ số tổng hợp, xuất dữ liệu, chỉnh ngưỡng, và quản lý tích hợp.
Tách dữ liệu theo đội hoặc đơn vị kinh doanh
Nếu nhiều đội dùng ứng dụng, ép tách ở tầng dữ liệu—không chỉ trong UI. Các lựa chọn phổ biến:
- Multi-tenant: mỗi bản ghi có
tenant_id, và mọi truy vấn đều được giới hạn theo đó. - Partitions/projects: workspace riêng cho từng đơn vị, với cài đặt và dashboard độc lập.
Quyết định sớm liệu quản lý có được xem dữ liệu đội khác hay không. Làm cho quyền xem chéo là lựa chọn có chủ ý, không phải mặc định.
Xác thực an toàn (SSO hoặc sẵn sàng MFA)
Nếu tổ chức có SSO (SAML/OIDC), dùng nó để tập trung quản lý offboarding và quyền truy cập. Nếu không, triển khai đăng nhập hỗ trợ MFA (TOTP hoặc passkeys), hỗ trợ reset mật khẩu an toàn, và áp dụng timeout phiên.
Ghi lại thay đổi để có thể kiểm toán
Ghi log các hành động có thể thay đổi kết quả hoặc làm lộ dữ liệu: xuất dữ liệu, thay đổi ngưỡng, chỉnh sửa quy trình, cập nhật quyền và cài đặt tích hợp. Ghi ai làm, khi nào, thay đổi gì (trước/sau), và ở đâu (workspace/tenant). Cung cấp view “Audit Log” để nhanh chóng điều tra sự cố.
Biến insight thành hành động và cải tiến quy trình
Dashboard điểm nghẽn chỉ quan trọng nếu nó thay đổi việc mọi người làm tiếp theo. Mục tiêu của phần này là biến “biểu đồ thú vị” thành nhịp vận hành lặp lại: quyết định, hành động, đo lường, và giữ lại những gì hiệu quả.
Tạo buổi rà soát điểm nghẽn nhẹ
Đặt nhịp hàng tuần đơn giản (30–45 phút) với chủ sở hữu rõ ràng. Bắt đầu với 1–3 điểm nghẽn hàng đầu theo tác động (ví dụ, queue time cao nhất hoặc sụt throughput lớn nhất), rồi đồng ý một hành động cho mỗi điểm nghẽn.
Giữ quy trình nhỏ:
- Chủ sở hữu: một người chịu trách nhiệm cho mỗi hành động
- Hạn hoàn thành: mặc định là cuộc rà soát tiếp theo
- Định nghĩa hoàn thành: thay đổi có thể đo được (không phải “điều tra thêm”)
Ghi lại quyết định trực tiếp trong ứng dụng để dashboard và nhật ký hành động luôn kết nối.
Ghi nhận cải tiến như các thử nghiệm
Xử lý sửa chữa như các thử nghiệm để bạn học nhanh và tránh “hành động tối ưu ngẫu nhiên”. Với mỗi thay đổi, ghi:
- Giả thuyết (điều gì làm chậm và vì sao)
- Thay đổi (bạn sẽ làm gì)
- Tác động kỳ vọng (chỉ số nào sẽ thay đổi, và bao nhiêu)
- Kết quả (thực tế diễn ra)
Theo thời gian, đây trở thành playbook về việc gì giảm thời gian chu kỳ, giảm làm lại, và việc gì không hiệu quả.
Thêm bối cảnh qua chú thích
Biểu đồ có thể gây hiểu nhầm nếu thiếu bối cảnh. Thêm chú thích trên dòng thời gian (ví dụ, tuyển dụng nhân viên mới, sự cố hệ thống, cập nhật chính sách) để người xem giải thích đúng các biến động queue time hoặc throughput.
Làm cho việc chia sẻ dễ dàng
Cung cấp tuỳ chọn xuất cho phân tích và báo cáo—tải CSV và báo cáo định kỳ—để các đội đưa kết quả vào bản cập nhật vận hành và báo cáo lãnh đạo. Nếu bạn đã có trang báo cáo, liên kết từ dashboard đến trang đó (ví dụ, /reports).
Triển khai, giám sát và giữ dữ liệu luôn mới
Phát hành bảng điều khiển cốt lõi
Khởi tạo một bảng tổng quan vận hành với cycle time, queue time, throughput và WIP.
Ứng dụng theo dõi điểm nghẽn chỉ hữu ích nếu nó luôn sẵn sàng và số liệu đáng tin. Xem việc triển khai và độ tươi dữ liệu là phần của sản phẩm, không phải sau đó.
Dùng môi trường riêng và triển khai lặp lại được
Thiết lập dev / staging / prod sớm. Staging nên phản chiếu production (cùng engine DB, khối lượng dữ liệu tương tự, cùng công việc nền) để bạn bắt lỗi truy vấn chậm và migration hỏng trước khi người dùng gặp.
Tự động hóa triển khai với pipeline đơn: chạy test, áp migration, triển khai, rồi chạy smoke check nhanh (đăng nhập, tải dashboard, xác nhận ingestion chạy). Giữ triển khai nhỏ và thường xuyên; giảm rủi ro và dễ rollback.
Giám sát ứng dụng và pipeline
Bạn cần giám sát hai mặt:
- Sức khỏe ứng dụng: tỷ lệ lỗi, độ trễ, endpoint chậm, và truy vấn chậm.
- Sức khỏe dữ liệu: lỗi ingestion, kích thước backlog, và “thời gian kể từ sự kiện cuối nhận được”.
Cảnh báo các triệu chứng người dùng cảm thấy (dashboard bị timeout) và các tín hiệu sớm (hàng đợi tăng 30 phút). Theo dõi cả lỗi tính toán chỉ số—thiếu cycle time có thể trông như “cải thiện”.
Giữ dữ liệu tươi: sự kiện đến trễ, sửa đổi và backfill
Dữ liệu vận hành đến trễ, lệch thứ tự, hoặc bị sửa. Lên kế hoạch cho:
- Ingestion idempotent (xử lý lại cùng sự kiện không bị đếm đôi).
- Backfill cho khoảng thời gian khi nguồn bị down.
- Tính lại khi dữ liệu tham chiếu thay đổi (ví dụ, lịch ca làm việc cập nhật).
Định nghĩa “tươi” là gì (ví dụ, 95% sự kiện trong vòng 5 phút) và hiển thị độ tươi trong UI.
Viết runbook để sửa không phải tùy ý
Tài liệu hoá runbook từng bước: cách khởi động lại sync hỏng, xác thực KPI hôm qua, và xác nhận backfill không thay đổi số liệu lịch sử một cách bất ngờ. Lưu chúng cùng dự án và liên kết từ /docs để đội phản ứng nhanh.
Lặp với người dùng và mở rộng phạm vi
Một ứng dụng theo dõi điểm nghẽn thành công khi mọi người tin tưởng nó và thực sự dùng nó. Điều đó chỉ xảy ra sau khi bạn quan sát người dùng thực trả lời câu hỏi thực (“Tại sao phê duyệt chậm tuần này?”) rồi tinh chỉnh sản phẩm quanh các luồng đó.
Bắt đầu với một pilot và học những gì hỏng
Bắt đầu với một đội pilot và vài quy trình. Giữ phạm vi đủ nhỏ để bạn quan sát việc sử dụng và phản hồi nhanh.
Trong tuần đầu hoặc hai, tập trung vào chỗ rối hoặc thiếu:
- Biểu đồ nào người dùng hiểu sai?
- Họ bị kẹt khi khoan sâu ở đâu?
- Dữ liệu nào họ mong thấy nhưng không tìm được?
- Điểm nghẽn nào với họ là “rõ ràng” nhưng lại không phản ánh trong ứng dụng?
Ghi phản hồi trong công cụ (một prompt “Có hữu ích không?” trên các màn hình chính hoạt động tốt) để bạn không phải phụ thuộc vào ký ức từ các cuộc họp.
Xác thực chỉ số để tránh “tranh cãi trên dashboard”
Trước khi mở rộng, khóa định nghĩa với những người chịu trách nhiệm. Nhiều rollout thất bại vì đội không đồng ý về ý nghĩa chỉ số.
Với mỗi KPI (cycle time, queue time, tỷ lệ làm lại, vi phạm SLA), tài liệu hoá:
- Sự kiện bắt đầu và kết thúc chính xác
- Xử lý tạm dừng, cuối tuần, và thiếu dấu thời gian
- Cách tính ngoại lệ (hủy, leo thang, mở lại)
Rồi rà soát định nghĩa đó với người dùng và thêm tooltip ngắn trong UI. Nếu bạn điều chỉnh định nghĩa, hiển thị changelog rõ ràng để mọi người hiểu tại sao số thay đổi.
Mở rộng phạm vi mà không làm phức tạp ứng dụng
Thêm tính năng thận trọng và chỉ khi phân tích quy trình của đội pilot ổn định. Những mở rộng phổ biến tiếp theo: bước tuỳ chỉnh (các đội dùng tên khác nhau), nguồn bổ sung (tickets + CRM + bảng tính), và phân đoạn nâng cao (theo dòng sản phẩm, khu vực, độ ưu tiên, phân khúc khách hàng).
Quy tắc hữu ích: thêm một chiều mới mỗi lần và xác minh nó cải thiện quyết định, không chỉ báo cáo.
Làm cho onboarding dễ và có thể lặp lại
Khi mở rộng cho nhiều đội, bạn cần sự nhất quán. Tạo hướng dẫn onboarding ngắn: cách kết nối dữ liệu, cách đọc dashboard vận hành, và cách hành động với cảnh báo điểm nghẽn.
Liên kết người dùng đến các trang liên quan trong sản phẩm và nội dung, như /pricing và /blog, để người mới tự phục vụ thay vì chờ đào tạo.