Xác định mục tiêu và tín hiệu tiếp nhận
Trước khi xây điểm sức khỏe tiếp nhận khách hàng, hãy quyết định bạn muốn điểm đó làm gì cho doanh nghiệp. Điểm dùng để kích hoạt cảnh báo rủi ro churn sẽ khác so với điểm dùng để hướng dẫn onboarding, đào tạo khách hàng hoặc cải tiến sản phẩm.
Định nghĩa “tiếp nhận” cho sản phẩm của bạn
Tiếp nhận không chỉ là “đã đăng nhập gần đây.” Viết ra vài hành vi thực sự cho thấy khách hàng đang đạt được giá trị:
- Kích hoạt: khoảnh khắc đầu tiên người dùng đạt được kết quả có ý nghĩa (ví dụ: “mời đồng nghiệp,” “kết nối nguồn dữ liệu,” “xuất bản báo cáo”).
- Hành động cốt lõi: những hành vi lặp lại, tín hiệu cao liên quan tới tài khoản thành công (ví dụ: xuất báo cáo hàng tuần, chạy automation, dashboard được nhiều người xem).
- Giữ chân: tiếp tục sử dụng ở tần suất phù hợp với sản phẩm của bạn (hằng ngày, hằng tuần, hằng tháng), lý tưởng là bởi nhiều người dùng trong tài khoản.
Đây sẽ là các tín hiệu tiếp nhận ban đầu cho phân tích sử dụng tính năng và phân tích cohort sau này.
Liệt kê các quyết định ứng dụng của bạn nên hỗ trợ
Hãy cụ thể về những gì xảy ra khi điểm thay đổi:
- Ai sẽ được thông báo khi một tài khoản rơi xuống dưới ngưỡng?
- Những playbook nào nên được kích hoạt (liên hệ, đào tạo, kiểm tra hỗ trợ)?
- Những insight nào nên ảnh hưởng đến việc giám sát tiếp nhận sản phẩm (điểm ma sát, tính năng ít được dùng, thời gian tới giá trị)?
Nếu bạn không thể nêu được một quyết định, đừng theo dõi metric đó ngay.
Xác định người dùng, vai trò và cửa sổ thời gian
Làm rõ ai sẽ dùng bảng điều khiển customer success:
- CS managers cần ưu tiên và ngữ cảnh tài khoản.
- Product cần các pattern, cohort và chuyển động ở cấp tính năng.
- Support cần hoạt động gần đây liên quan tới ticket và sự cố.
- Leadership cần một tổng hợp dễ hiểu và xu hướng.
Chọn các cửa sổ tiêu chuẩn—7/30/90 ngày gần nhất—và cân nhắc các giai đoạn vòng đời (trial, onboarding, steady-state, renewal). Điều này tránh so sánh tài khoản mới với tài khoản trưởng thành.
Đặt tiêu chí thành công
Định nghĩa “xong” cho mô hình điểm sức khỏe của bạn:
- Độ chính xác: nó có dự đoán rủi ro và tín hiệu mở rộng tốt hơn cách tiếp cận hiện tại không?
- Dễ giải thích: CSM có thể giải thích tại sao điểm cao/thấp trong một phút không?
- Dễ dùng: nó có tiết kiệm thời gian và thúc đẩy hành động nhất quán không?
Những mục tiêu này sẽ định hình mọi thứ phía sau: theo dõi sự kiện, logic chấm điểm và workflow bạn xây quanh điểm.
Chọn các chỉ số cho Điểm Sức Khỏe
Việc chọn chỉ số quyết định điểm sức khỏe là tín hiệu hữu ích hay chỉ là con số nhiễu. Hướng tới một tập nhỏ chỉ số phản ánh tiếp nhận thực sự—không chỉ hoạt động.
Bắt đầu với các tín hiệu tiếp nhận sản phẩm
Chọn các metric cho thấy người dùng lặp lại đạt được giá trị:
- Đăng nhập / người dùng hoạt động: ví dụ WAU và xu hướng trong 4–8 tuần gần nhất.
- Số ngày hoạt động: bao nhiêu ngày khác nhau tài khoản hoạt động trong tuần/tháng (giúp tránh “một phiên dài” gây dương tính giả).
- Độ sâu tính năng: sử dụng các “tính năng tạo giá trị”, không phải mọi cú click.
- Kết nối tích hợp: đặc biệt khi tích hợp tăng chi phí chuyển đổi hoặc mở khóa workflow quan trọng.
- Tỷ lệ sử dụng seat: phần trăm seat đã mua được mời, kích hoạt và thực sự hoạt động.
Giữ danh sách tập trung. Nếu bạn không giải thích được tại sao một metric quan trọng trong một câu, có lẽ nó không phải input cốt lõi.
Thêm ngữ cảnh doanh nghiệp (để điểm công bằng)
Tiếp nhận cần được diễn giải theo ngữ cảnh. Một đội 3 người sẽ hành xử khác với rollout 500 seat.
Các tín hiệu ngữ cảnh phổ biến:
- Hạng gói và quyền lợi tính năng
- Quy mô hợp đồng / băng ARR
- Giai đoạn vòng đời: trial vs mới trả tiền vs đến ngày gia hạn
Những yếu tố này không cần “cộng điểm,” nhưng giúp bạn đặt mong đợi và ngưỡng thực tế theo phân khúc.
Quyết định chỉ số dẫn/đuổi
Một điểm hữu ích kết hợp:
- Chỉ số dẫn (dự đoán thành công trong tương lai): tăng số ngày hoạt động, hoàn thành onboarding, kết nối tích hợp đầu tiên.
- Chỉ số đuôi (xác nhận kết quả): gia hạn, mở rộng, giữ chân dài hạn.
Tránh cho trọng số quá lớn với chỉ số đuôi; chúng cho biết điều đã xảy ra rồi.
Tùy chọn: đầu vào định tính (dùng cẩn trọng)
Nếu có, NPS/CSAT, tần suất ticket hỗ trợ, và ghi chú CSM có thể thêm sắc thái. Dùng chúng như bộ điều chỉnh hoặc cờ—không nên là nền tảng—vì dữ liệu định tính thường thưa và mang tính chủ quan.
Tạo từ điển dữ liệu đơn giản
Trước khi xây biểu đồ, thống nhất tên và định nghĩa. Một từ điển dữ liệu nhẹ nên bao gồm:
- Tên metric (ví dụ
active_days_28d)
- Định nghĩa rõ ràng (điều gì được tính, điều gì không)
- Cửa sổ thời gian và tần suất làm mới
- Hệ thống nguồn (sự kiện sản phẩm, CRM, hỗ trợ)
Điều này ngăn “cùng một metric, nghĩa khác” khi bạn triển khai dashboard và cảnh báo.
Thiết kế Mô Hình Điểm Sức Khỏe Có Thể Giải Thích
Một điểm tiếp nhận chỉ có tác dụng nếu đội tin vào nó. Hướng tới một mô hình bạn có thể giải thích trong một phút cho CSM và trong năm phút cho khách hàng.
Bắt đầu đơn giản: điểm trọng số (trước ML)
Khởi đầu với mô hình quy tắc minh bạch. Chọn vài tín hiệu tiếp nhận (ví dụ: người dùng hoạt động, sử dụng tính năng chính, tích hợp kích hoạt) và gán trọng số phản ánh những khoảnh khắc “aha” của sản phẩm.
Ví dụ phân trọng số:
- Weekly active users per seat: 0–40 điểm
- Tần suất sử dụng tính năng chính: 0–35 điểm
- Độ rộng tính năng được dùng: 0–15 điểm
- Thời gian kể từ hoạt động có ý nghĩa gần nhất: 0–10 điểm
Giữ trọng số dễ bảo vệ. Bạn có thể điều chỉnh sau—đừng chờ mô hình hoàn hảo.
Chuẩn hoá để giảm bias
Các số đếm thô phạt các tài khoản nhỏ và làm phẳng các tài khoản lớn. Chuẩn hoá khi cần:
- Theo seat (sử dụng / seat được cấp phép)
- Theo tuổi tài khoản (mới vs trưởng thành)
- Theo hạng gói (tính năng khả dụng)
Điều này giúp điểm phản ánh hành vi chứ không chỉ kích thước.
Định nghĩa xanh/vàng/đỏ với lý do rõ ràng
Đặt ngưỡng (ví dụ Green ≥ 75, Yellow 50–74, Red < 50) và ghi chú lý do mỗi ngưỡng tồn tại. Liên kết ngưỡng với kết quả kỳ vọng (rủi ro gia hạn, hoàn tất onboarding, sẵn sàng mở rộng), và lưu ghi chú trong tài liệu nội bộ hoặc blog/health-score-playbook.
Làm nó dễ giải thích: các yếu tố đóng góp và xu hướng
Mỗi điểm nên hiển thị:
- 3 đóng góp hàng đầu (điều gì giúp/hại)
- Thay đổi theo thời gian (7/30 ngày gần nhất)
- Tóm tắt bằng ngôn ngữ đơn giản (“Sử dụng Tính năng X giảm 35% tuần trên tuần”)
Lên kế hoạch lặp: phiên bản hoá mô hình
Xem chấm điểm như một sản phẩm. Phiên bản hoá nó (v1, v2) và theo dõi tác động: Cảnh báo rủi ro churn có chính xác hơn không? CSM hành động nhanh hơn không? Lưu phiên bản mô hình cùng mỗi lần tính toán để so sánh kết quả theo thời gian.
Ghi lại Sự kiện Sản phẩm và Nguồn Dữ liệu
Một điểm sức khỏe đáng tin cậy phụ thuộc vào dữ liệu hoạt động phía sau nó. Trước khi xây logic chấm điểm, xác nhận các tín hiệu đúng được bắt giữ nhất quán giữa các hệ thống.
Chọn nguồn sự kiện
Hầu hết chương trình tiếp nhận kéo dữ liệu từ hỗn hợp:
- Sự kiện frontend (xem trang, click, tương tác tính năng)
- Hành động backend (gọi API, job hoàn thành, bản ghi tạo)
- Billing (gói, gia hạn, trạng thái thanh toán, số seat)
- Công cụ hỗ trợ và success (ticket, CSAT, cột mốc onboarding)
Quy tắc thực tế: theo dõi hành động quan trọng ở server-side (khó giả mạo, ít ảnh hưởng bởi ad blocker) và dùng frontend cho tương tác UI.
Định nghĩa schema sự kiện rõ ràng
Giữ hợp đồng nhất quán để sự kiện dễ join, truy vấn, và giải thích cho các bên liên quan. Một baseline phổ biến:
event_nameuser_idaccount_idtimestamp (UTC)properties (feature, plan, device, workspace_id, v.v.)
Dùng từ vựng kiểm soát cho event_name (ví dụ project_created, report_exported) và ghi nó trong tracking plan đơn giản.
Quyết định dùng SDK hay server-side (hoặc cả hai)
- SDK tracking nhanh để triển khai và phù hợp cho sự kiện UI.
- Server-side tracking tốt cho hành động hệ thống làm nguồn dữ liệu chính.
Nhiều đội làm cả hai, nhưng đảm bảo không double-count cùng hành động thực.
Xử lý nhận dạng đúng cách
Điểm sức khỏe thường roll up ở cấp account, nên bạn cần mapping user→account đáng tin cậy. Lên kế hoạch cho:
- Người dùng thuộc nhiều account
- Gộp account (mua lại, hợp nhất workspace)
- ID ẩn danh cho hành vi trước khi đăng nhập (với merge an toàn sau khi đăng ký)
Bổ sung kiểm tra chất lượng dữ liệu
Tối thiểu, giám sát sự kiện thiếu, bùng nổ trùng lặp, và tính nhất quán timezone (lưu UTC; chuyển cho hiển thị). Flag sớm để cảnh báo rủi ro churn không kích hoạt vì tracking bị lỗi.
Mô hình hoá Dữ liệu và Lưu trữ
Ứng dụng điểm sức khỏe khách hàng sống hay chết bởi cách bạn mô hình “ai đã làm gì, và khi nào.” Mục tiêu là trả lời nhanh các câu hỏi phổ biến: Tài khoản này đang hoạt động thế nào tuần này? Tính năng nào đang tăng/giảm? Mô hình dữ liệu tốt giữ cho chấm điểm, dashboard và cảnh báo đơn giản.
Thực thể cốt lõi cần mô hình hoá
Bắt đầu với tập nhỏ các bảng “nguồn chân lý”:
- Accounts: account_id, plan, segment, lifecycle stage, CSM owner
- Users: user_id, account_id, role/persona, created_at, status
- Subscriptions (hoặc contracts): account_id, start/end, seats, MRR, renewal date
- Features: feature_id, name, category (activation, collaboration, admin, v.v.)
- Events: event_id, account_id, user_id, feature_id (nullable), event_name, timestamp, properties
- Scores: account_id, score_date (or computed_at), overall_score, component scores, explanation fields
Giữ các thực thể này nhất quán bằng cách dùng ID ổn định (account_id, user_id) mọi nơi.
Tách lưu trữ: relational + analytics
Dùng relational database (ví dụ Postgres) cho accounts/users/subscriptions/scores—những thứ bạn cập nhật và join thường xuyên.
Lưu sự kiện khối lượng lớn trong kho dữ liệu/analytics (ví dụ BigQuery/Snowflake/ClickHouse). Điều này giữ dashboard và phân tích cohort phản hồi nhanh mà không làm quá tải DB giao dịch.
Lưu các tổng hợp để tăng tốc
Thay vì tính lại mọi thứ từ sự kiện thô, duy trì:
- Tóm tắt hàng ngày theo tài khoản (một hàng cho mỗi tài khoản mỗi ngày): người dùng hoạt động, số sự kiện chính, hoạt động gần nhất, cột mốc tiếp nhận
- Bộ đếm tính năng: theo account/ngày/tính năng: số lần dùng, người dùng duy nhất, thời gian nếu có
Những bảng này cung cấp biểu đồ xu hướng, insight “điều gì thay đổi”, và các thành phần điểm sức khỏe.
Retention, phân vùng và hiệu năng truy vấn
Với bảng sự kiện lớn, lên kế hoạch lưu trữ (ví dụ 13 tháng thô, lâu hơn cho tổng hợp) và partition theo ngày. Cluster/index theo account_id và timestamp/date để tăng tốc truy vấn “tài khoản theo thời gian”.
Trong bảng quan hệ, index các filter và join phổ biến: account_id, (account_id, date) trên các bảng tóm tắt, và foreign keys để giữ dữ liệu sạch.
Lên kế hoạch Kiến trúc Ứng dụng Web
Make it team-ready
Put your CS dashboard on a custom domain for easier internal access.
Kiến trúc nên giúp bạn ship v1 đáng tin cậy rồi mở rộng mà không phải viết lại. Bắt đầu bằng việc quyết định bao nhiêu thành phần thực sự cần.
Monolith vs. services (giữ v1 đơn giản)
Với đa số đội, một monolith mô-đun là đường nhanh nhất: một codebase với ranh giới rõ ràng (ingestion, scoring, API, UI), deploy đơn, và ít rủi ro vận hành hơn.
Chỉ tách thành services khi có lý do rõ ràng—quy mô độc lập, yêu cầu cô lập dữ liệu nghiêm ngặt, hoặc đội khác nhau quản lý. Nếu không, dịch vụ sớm gây tăng điểm lỗi và chậm lặp.
Định nghĩa các thành phần cốt lõi
Ít nhất, lên kế hoạch các trách nhiệm sau (dù chúng nằm trong cùng app lúc đầu):
- Ingestion: nhận sự kiện sản phẩm (SDK, Segment, webhook, batch import).
- Aggregation: biến sự kiện thô thành facts sử dụng hàng ngày/tuần theo account/user.
- Scoring: tính điểm sức khỏe tiếp nhận và giải thích kèm theo.
- API: phục vụ điểm, xu hướng và giải thích cho UI và tích hợp.
- UI: dashboard customer success với view tài khoản, cohort, và drill-down.
Nếu muốn prototype nhanh, cách làm “vibe-coding” có thể giúp bạn có dashboard hoạt động mà không đầu tư quá nhiều vào phần nền. Ví dụ, Koder.ai có thể sinh React UI và backend Go từ mô tả các thực thể (accounts, events, scores), endpoint và màn hình—hữu ích để dựng v1 để CS phản hồi sớm.
Job theo lịch vs streaming
Chấm điểm theo batch (ví dụ hourly/overnight) thường đủ cho giám sát tiếp nhận và đơn giản hơn vận hành. Streaming phù hợp nếu cần cảnh báo gần như realtime (ví dụ sụt dùng đột ngột) hoặc khối lượng sự kiện rất cao.
Một hybrid thực tế: ingest sự kiện liên tục, aggregate/chấm điểm theo lịch, và dành streaming cho vài tín hiệu khẩn cấp.
Môi trường, secrets và yêu cầu phi chức năng
Thiết lập dev/stage/prod sớm, với sample account được seed ở stage để kiểm tra dashboard. Dùng quản lý secrets và xoay khóa.
Ghi tài liệu yêu cầu: khối lượng sự kiện dự kiến, độ tươi của điểm (SLA), mục tiêu latency API, availability, lưu trữ dữ liệu, và ràng buộc riêng tư (xử lý PII và kiểm soát truy cập). Điều này tránh quyết định kiến trúc bị trì hoãn dưới áp lực.
Xây pipeline dữ liệu và job chấm điểm
Điểm sức khỏe chỉ đáng tin khi pipeline tạo ra nó cũng đáng tin. Xử lý chấm điểm như hệ thống production: có thể tái tạo, quan sát được, và dễ giải thích khi ai đó hỏi “Tại sao tài khoản này giảm hôm nay?”.
Pipeline đơn giản: raw → validated → aggregates
Bắt đầu với flow có giai đoạn để thu gọn dữ liệu thành cái bạn có thể chấm an toàn:
- Raw events: ingest append-only từ app, mobile, tích hợp, và export billing/CRM.
- Validated events: sự kiện qua kiểm tra schema (field bắt buộc, kiểu đúng), kiểm tra identity (mapping user→account), và dedupe.
- Daily aggregates: rollup theo account (và tuỳ chọn workspace/team) như người dùng hoạt động, số sự kiện chính, cột mốc time-to-value, và delta xu hướng.
Cấu trúc này giữ job chấm điểm nhanh và ổn định vì chúng chạy trên bảng sạch, gọn thay vì hàng tỷ dòng thô.
Lịch tái tính và backfills
Quyết định độ “tươi” của điểm:
- Hourly phù hợp cho motion high-touch nơi CSM hành động nhanh.
- Daily thường đủ cho SMB/self-serve và tiết kiệm chi phí.
Xây scheduler hỗ trợ backfills (ví dụ tái xử lý 30/90 ngày gần nhất) khi sửa tracking, thay đổi trọng số, hoặc thêm tín hiệu. Backfill nên là tính năng chính, không phải script khẩn cấp.
Idempotency: tránh đếm đôi
Job chấm điểm sẽ retry. Import sẽ chạy lại. Webhook có thể gửi hai lần. Thiết kế để chịu được điều đó.
Dùng idempotency key cho sự kiện (event_id hoặc hash ổn định của timestamp + user_id + event_name + properties) và enforce uniqueness ở lớp validated. Với aggregates, upsert theo (account_id, date) để tái tính thay thế kết quả cũ thay vì cộng dồn.
Giám sát và kiểm tra bất thường
Thêm monitoring vận hành cho:
- Job success/failure và số lần retry
- Data lag (dữ liệu mới nhất trễ bao xa so với “now”)
- Volume anomalies (sụt/đột biến sự kiện, người dùng hoạt động, hành động chính)
Ngay cả threshold nhẹ (ví dụ “events giảm 40% so với trung bình 7 ngày”) cũng tránh lỗi im lặng làm sai lệch dashboard customer success.
Lưu audit cho mỗi lần chấm điểm
Lưu bản ghi audit cho mỗi account cho mỗi lần chạy chấm điểm: các metric input, tính năng dẫn xuất (như thay đổi tuần trên tuần), phiên bản mô hình, và điểm cuối cùng. Khi CSM bấm “Tại sao?”, bạn có thể hiện chính xác cái gì thay đổi và khi nào—không cần lục logs.
Tạo API an toàn cho Điểm và Insight
Generate the app skeleton
Describe your entities and screens, and let Koder.ai generate the React UI and Go backend.
Ứng dụng web của bạn sống hay chết dựa trên API. Nó là hợp đồng giữa job chấm điểm, UI và công cụ hạ nguồn. Hướng tới API nhanh, dự đoán được và an toàn theo mặc định.
Endpoint cốt lõi hỗ trợ workflow thực tế
Thiết kế endpoint quanh cách Customer Success thực sự khám phá tiếp nhận:
- Account health:
GET /api/accounts/{id}/health trả về điểm mới nhất, băng trạng thái (Green/Yellow/Red), và timestamp tính toán cuối.
- Trends:
GET /api/accounts/{id}/health/trends?from=&to= cho điểm theo thời gian và delta metric chính.
- Drivers (“why”):
GET /api/accounts/{id}/health/drivers hiển thị yếu tố tích cực/tiêu cực hàng đầu (ví dụ “weekly active seats down 35%”).
- Cohorts:
GET /api/cohorts/health?definition= cho phân tích cohort và benchmark đồng nghiệp.
- Exports:
POST /api/exports/health để sinh CSV/Parquet với schema nhất quán.
Filter, phân trang và caching
Làm cho các endpoint danh sách dễ cắt lát:
- Filters:
plan, segment, csm_owner, lifecycle_stage, và date_range là những thứ cần có.
- Pagination: dùng cursor-based (
cursor, limit) để ổn định khi dữ liệu thay đổi.
- Caching: cache truy vấn nặng (cohort rollups, chuỗi xu hướng) và trả
ETag/If-None-Match để giảm tải. Khóa cache cần nhận biết filter và permissions.
Bảo mật với RBAC
Bảo vệ dữ liệu ở cấp tài khoản. Triển khai RBAC (Admin, CSM, Read-only) và enforce server-side ở mọi endpoint. CSM chỉ nên thấy account họ quản lý; vai trò finance có thể thấy tổng hợp theo gói nhưng không thấy chi tiết user.
Luôn trả về giải thích
Bên cạnh con số điểm sức khỏe, trả về các trường “tại sao”: drivers hàng đầu, metric bị ảnh hưởng, và baseline so sánh (kỳ trước, median cohort). Điều này biến giám sát tiếp nhận sản phẩm thành hành động, không chỉ báo cáo, và làm cho bảng điều khiển customer success đáng tin.
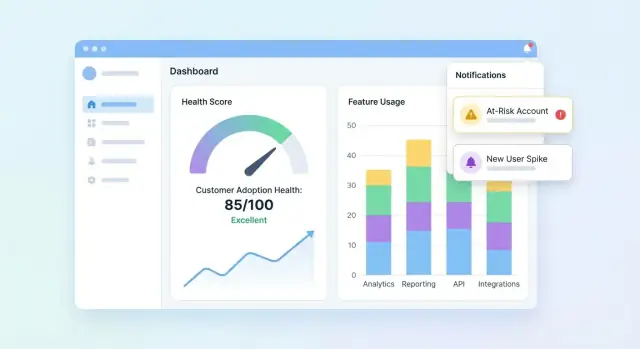
Thiết kế Dashboard và View Tài khoản
UI của bạn nên trả lời ba câu nhanh: Ai khỏe? Ai đang giảm? Tại sao? Bắt đầu với dashboard tổng quát, sau đó cho phép drill vào tài khoản để hiểu câu chuyện phía sau điểm.
Những gì cần có trên dashboard danh mục
Bao gồm một bộ gạch và biểu đồ gọn để đội CS quét trong vài giây:
- Phân bố điểm (histogram hoặc buckets như Healthy / Watch / At-risk)
- Danh sách At-risk với vài trường cần để hành động (account, owner, score, last activity, top driver)
- Xu hướng điểm theo thời gian (line chart) với tuỳ chọn filter theo phân khúc
Làm cho danh sách at-risk có thể nhấp để mở tài khoản và xem thay đổi.
View tài khoản: giải thích điểm
Trang tài khoản nên đọc như timeline tiếp nhận:
- Timeline của sự kiện chính (bước onboarding hoàn thành, tích hợp kết nối, thay đổi admin, lần đầu dùng tính năng lớn)
- Metric chính (người dùng hoạt động, hành động tính năng chính, thời gian kể từ hoạt động có ý nghĩa gần nhất)
- Phân tích tiếp nhận tính năng hiển thị tính năng nào được dùng, bị bỏ qua, hoặc giảm
Thêm panel “Tại sao điểm này?”: bấm vào điểm để thấy tín hiệu đóng góp (tích cực và tiêu cực) với giải thích bằng ngôn ngữ đơn giản.
View cohort và phân khúc
Cung cấp filter cohort phù hợp cách đội quản lý account: cohort onboarding, hạng gói, ngành. Kết hợp mỗi cohort với đường xu hướng và một bảng nhỏ các mover hàng đầu để so sánh kết quả và phát hiện pattern.
Hiển thị dễ tiếp cận, đáng tin
Dùng nhãn rõ ràng và đơn vị, tránh icon mơ hồ, và cung cấp màu + hình dạng an toàn cho người mù màu. Xử lý biểu đồ như công cụ ra quyết định: chú thích đột biến, hiển thị khoảng ngày, và làm drill-down nhất quán.
Thêm Cảnh báo, Task và Workflow
Điểm sức khỏe chỉ hữu ích khi nó thúc đẩy hành động. Cảnh báo và workflow biến “dữ liệu thú vị” thành outreach kịp thời, sửa onboarding, hoặc nudges sản phẩm—mà không bắt đội phải dán mắt vào dashboard.
Định nghĩa rule cảnh báo gắn với rủi ro thực
Bắt đầu với tập nhỏ trigger có tín hiệu cao:
- Score drops (ví dụ giảm 15 điểm tuần trên tuần)
- Red status (vượt ngưỡng quan trọng)
- Sudden usage decline (sử dụng tính năng chính dưới baseline)
- Failed onboarding step (item checklist bị dừng, tích hợp chưa hoàn thành)
Làm rõ từng rule. Thay vì “sức khỏe xấu,” cảnh báo cụ thể như “Không có hoạt động trên Tính năng X trong 7 ngày + onboarding chưa xong.”
Chọn kênh và cho phép cấu hình
Các đội khác nhau làm việc khác nhau, nên xây kênh và tuỳ chọn:
- Email cho owner và manager
- Slack cho visibility đội và phản ứng nhanh
- In-app tasks trong dashboard để công việc không bị lạc
Cho phép mỗi đội cấu hình: ai được thông báo, rule nào bật, và ngưỡng nào là “khẩn cấp.”
Giảm tiếng ồn với guardrails
Alert fatigue giết chết việc giám sát. Thêm kiểm soát như:
- Cooldown windows (không cảnh báo lại cùng tài khoản trong N giờ/ngày)
- Ngưỡng dữ liệu tối thiểu (bỏ cảnh báo nếu tài khoản có quá ít dữ liệu gần đây)
- Batching/digests cho tín hiệu không khẩn cấp (tóm tắt hàng ngày/tuần)
Thêm ngữ cảnh và bước tiếp theo
Mỗi cảnh báo nên trả lời: cái gì thay đổi, tại sao quan trọng, và làm gì tiếp theo. Bao gồm drivers gần đây, timeline ngắn (ví dụ 14 ngày gần nhất), và task gợi ý như “Đặt lịch onboarding” hoặc “Gửi hướng dẫn tích hợp.” Giữ text dẫn tới view tài khoản (ví dụ /accounts/{id}).
Theo dõi kết quả để vòng lặp khép kín
Xử lý cảnh báo như công việc với trạng thái: acknowledged, contacted, recovered, churned. Báo cáo kết quả giúp tinh chỉnh rule, cải thiện playbook và chứng minh điểm sức khỏe tạo ra tác động giữ chân đo lường được.
Đảm bảo Chất lượng Dữ liệu, Quyền Riêng tư và Quản trị
Reduce build costs
Get credits by sharing your build process or referring teammates to Koder.ai.
Nếu điểm sức khỏe xây trên dữ liệu không tin cậy, đội sẽ ngừng tin và ngừng hành động. Xem chất lượng, quyền riêng tư và quản trị như tính năng sản phẩm, không phải phần sau cùng.
Đặt kiểm tra dữ liệu tự động
Bắt đầu với validation nhẹ ở mọi nút chuyển (ingest → warehouse → output chấm điểm). Một vài test tín hiệu cao bắt hầu hết lỗi sớm:
- Schema checks: cột mong đợi tồn tại, kiểu không thay đổi, enum hợp lệ.
- Range checks: giá trị không thể (session âm, timestamp trong tương lai) fail nhanh.
- Null checks: field bắt buộc (
account_id, event_name, occurred_at) không được rỗng.
Khi test fail, chặn job chấm điểm (hoặc đánh dấu kết quả là “stale”) để pipeline hỏng không tạo cảnh báo rủi ro sai lệch.
Xử lý các edge case phổ biến rõ ràng
Chấm điểm xấu ở những scenario “kỳ lạ nhưng bình thường.” Đặt rule cho:
- Tài khoản mới ít dữ liệu: hiển thị “dữ liệu không đủ” hoặc dùng baseline ramp-up thay vì cho điểm thấp.
- Sử dụng theo mùa: so sánh với kỳ trước của tài khoản hoặc benchmark cohort thay vì ngưỡng chung.
- Sự cố và mất tracking: đánh dấu cửa sổ bị ảnh hưởng và tránh phạt khách hàng vì downtime của bạn.
Thêm quyền và kiểm soát riêng tư
Hạ PII theo mặc định: lưu chỉ những gì cần cho giám sát tiếp nhận. Áp RBAC trong web app, log ai xem/xuất dữ liệu, và redact export khi field không cần thiết (ví dụ ẩn email trong CSV).
Tạo runbook và thói quen quản trị
Viết runbook ngắn cho phản ứng sự cố: cách tạm dừng chấm điểm, backfill dữ liệu, và chạy lại job lịch sử. Review metric customer success và trọng số điểm định kỳ—hàng tháng hoặc quý—để tránh drift khi sản phẩm thay đổi. Đối với alignment quy trình, link checklist nội bộ từ blog/health-score-governance.
Xác thực, Lặp và Mở rộng Điểm Sức Khỏe
Xác thực là nơi điểm sức khỏe ngừng là “biểu đồ đẹp” và bắt đầu được tin tưởng để hành động. Xem phiên bản đầu tiên như giả thuyết, không phải câu trả lời cuối cùng.
Chạy pilot và hiệu chỉnh theo đánh giá con người
Bắt đầu với pilot nhóm tài khoản (ví dụ 20–50 theo phân khúc). Với mỗi tài khoản, so sánh điểm và lý do rủi ro với đánh giá của CSM.
Tìm pattern:
- Điểm thường cao/thấp hơn đánh giá CSM (calibration)
- “Cảnh báo sai” (rủi ro cao nhưng tài khoản ổn) vs “bỏ sót” (điểm khỏe nhưng churn)
- Lý do không khớp thực tế (khoảng cách giải thích)
Đo xem nó thực sự hữu ích không
Độ chính xác thì tốt, nhưng hữu dụng mới đem lại lợi ích. Theo dõi kết quả vận hành như:
- Time-to-detect risk (phát hiện sớm đến đâu)
- Outreach success rate (tỷ lệ tài khoản rủi ro cải thiện sau can thiệp)
- Proxies giảm churn (di chuyển xác suất gia hạn, tín hiệu mở rộng, thay đổi gánh nặng support)
Thử thay đổi an toàn với versioning
Khi điều chỉnh ngưỡng, trọng số, hoặc thêm tín hiệu, xử lý như phiên bản mô hình mới. A/B test trên cohort tương đương, và giữ phiên bản lịch sử để giải thích vì sao điểm thay đổi.
Thu thập phản hồi trong UI
Thêm control nhẹ như “Score feels wrong” kèm lý do (ví dụ “hoàn tất onboarding chưa phản ánh,” “sử dụng theo mùa,” “mapping tài khoản sai”). Điều hướng feedback này vào backlog và tag với account + phiên bản mô hình để debug nhanh hơn.
Mở rộng theo roadmap
Khi pilot ổn, lên kế hoạch scale: tích hợp sâu hơn (CRM, billing, support), phân đoạn (theo gói, ngành, lifecycle), automation (task và playbook), và self-serve để đội tuỳ chỉnh view không cần engineering.
Khi mở rộng, giữ vòng build/iterate ngắn. Nhiều đội dùng Koder.ai để dựng trang dashboard mới, hoàn thiện shape API, hoặc thêm workflow (task, export, release rollback) trực tiếp từ chat—hữu ích khi versioning mô hình và cần ship UI + backend cùng lúc mà không làm chậm vòng phản hồi CS.