06 thg 11, 2025·8 phút
Cách xây ứng dụng web để theo dõi sự cố & postmortem
Bản hướng dẫn thực tế để thiết kế, xây dựng và ra mắt ứng dụng web theo dõi sự cố và postmortem — từ workflow đến mô hình dữ liệu và UX.
Bản hướng dẫn thực tế để thiết kế, xây dựng và ra mắt ứng dụng web theo dõi sự cố và postmortem — từ workflow đến mô hình dữ liệu và UX.
Trước khi phác thảo màn hình hoặc chọn cơ sở dữ liệu, hãy thống nhất xem nhóm bạn hiểu thế nào về ứng dụng web theo dõi sự cố — và “quản lý postmortem” nên đạt được điều gì. Các nhóm thường dùng cùng từ ngữ nhưng với ý khác nhau: với nhóm này, một incident là bất kỳ vấn đề do khách hàng báo; với nhóm khác, chỉ là outage Sev-1 có escalation on-call.
Viết một định nghĩa ngắn trả lời:
Định nghĩa này quyết định quy trình phản ứng sự cố và ngăn app trở nên quá chặt (không ai dùng) hoặc quá lỏng (dữ liệu không nhất quán).
Quyết định postmortem là gì trong tổ chức của bạn: một bản tóm tắt nhẹ cho mọi sự cố, hay RCA đầy đủ chỉ cho các sự cố mức cao. Rõ ràng mục tiêu là học hỏi, tuân thủ, giảm tái diễn, hay cả ba.
Một quy tắc hữu ích: nếu bạn mong đợi postmortem phải dẫn đến thay đổi, công cụ của bạn phải hỗ trợ theo dõi action items, không chỉ lưu trữ tài liệu.
Hầu hết các đội xây app kiểu này để khắc phục một vài nỗi đau lặp lại:
Giữ danh sách này gọn. Mỗi tính năng thêm vào nên giải quyết ít nhất một trong những vấn đề này.
Chọn vài chỉ số bạn có thể đo tự động từ mô hình dữ liệu app:
Những thứ này trở thành chỉ số vận hành và “định nghĩa hoàn thành” cho bản phát hành đầu tiên.
Cùng một app phục vụ nhiều vai trò trong vận hành on-call:
Nếu bạn thiết kế cho tất cả cùng lúc, UI sẽ lộn xộn. Thay vào đó, chọn người dùng chính cho v1 — và đảm bảo những người còn lại vẫn có thể lấy thông tin họ cần qua các view, dashboard và quyền truy cập phù hợp sau này.
Một workflow rõ ràng ngăn hai lỗi phổ biến: sự cố bị treo vì không ai biết “bước tiếp theo là gì,” và sự cố được xem là “xong” nhưng không sinh ra bài học. Bắt đầu bằng cách vẽ lifecycle end-to-end rồi gắn vai trò và quyền cho từng bước.
Hầu hết các đội theo vòng đơn giản: phát hiện → phân loại → giảm thiểu → giải quyết → học hỏi. App của bạn nên phản ánh điều này bằng một tập bước dự đoán, không phải menu vô tận.
Định nghĩa thế nào là “xong” cho mỗi giai đoạn. Ví dụ, mitigation có thể có nghĩa là ảnh hưởng tới khách hàng đã bị ngăn lại, dù nguyên nhân gốc còn chưa rõ.
Giữ vai trò rõ ràng để mọi người có thể hành động mà không chờ họp:
UI nên làm nổi bật “owner hiện tại”, và workflow nên hỗ trợ ủy quyền (reassign, thêm responder, quay vòng commander).
Chọn các trạng thái cần thiết và chuyển đổi được phép, ví dụ Investigating → Mitigated → Resolved. Thêm hàng rào:
Tách cập nhật nội bộ (nhanh, chiến thuật, có thể lộn xộn) khỏi cập nhật cho stakeholder (rõ ràng, có dấu thời gian, được tuyển chọn). Xây hai luồng cập nhật với mẫu, phạm vi hiển thị và quy tắc phê duyệt khác nhau — thường commander là người duy nhất xuất bản cho stakeholder.
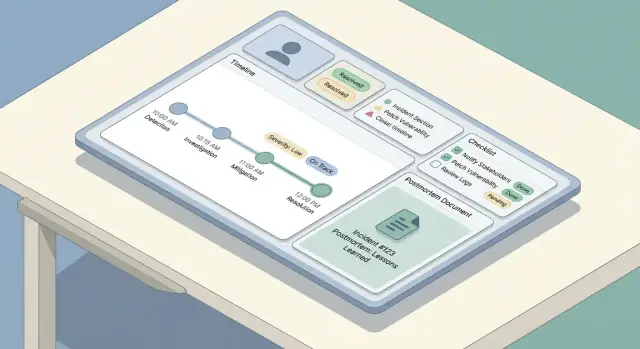
Một công cụ sự cố tốt có cảm giác “đơn giản” ở UI vì mô hình dữ liệu phía sau nhất quán. Trước khi build màn hình, quyết định object nào tồn tại, cách chúng liên hệ và dữ liệu nào phải lưu chính xác theo lịch sử.
Bắt đầu với tập nhỏ các đối tượng first-class:
Hầu hết quan hệ là một-nhiều:
Dùng định danh ổn định (UUID) cho incidents và events. Con người vẫn cần một khoá thân thiện như INC-2025-0042, bạn có thể sinh từ chuỗi số.
Mô hình hoá từ sớm để có thể lọc, tìm và báo cáo:
Dữ liệu sự cố nhạy cảm và thường được xem lại sau này. Xử lý chỉnh sửa như dữ liệu — không ghi đè:
Cấu trúc này giúp những tính năng sau — tìm kiếm, chỉ số, quyền — dễ triển khai mà không phải làm lại.
Khi có sự cố, nhiệm vụ của app là giảm gõ phím và tăng độ rõ ràng. Phần này nói về “đường viết”: cách người ta tạo incident, cập nhật nó và tái dựng sự kiện sau này.
Giữ form intake đủ ngắn để hoàn thành khi đang gỡ sự cố. Bộ trường bắt buộc tốt là:
Các thứ khác nên là tuỳ chọn khi tạo (ảnh hưởng, link ticket khách hàng, nguyên nhân nghi ngờ). Dùng mặc định thông minh: đặt start time là “now”, chọn trước on-call team của người dùng, và có hành động một chạm “Create & open incident room”.
UI cập nhật nên tối ưu cho các sửa nhỏ lặp lại. Cung cấp panel cập nhật gọn với:
Thiết kế cập nhật theo kiểu append: mỗi cập nhật trở thành một mục có timestamp, không ghi đè văn bản trước.
Xây timeline trộn:
Điều này tạo nên câu chuyện đáng tin cậy mà không buộc mọi người nhớ ghi lại mỗi hành động.
Trong outage, nhiều cập nhật xảy ra từ điện thoại. Ưu tiên màn hình nhanh, ít cản trở: target chạm lớn, một trang cuộn, nháp offline-friendly, và hành động một chạm như “Post update” và “Copy incident link”.
Severity là “nút chỉnh tốc” của phản ứng sự cố: nó cho biết mức ưu tiên hành động, phạm vi truyền thông và những đánh đổi chấp nhận được.
Tránh nhãn mơ hồ như “cao/trung bình/thấp.” Làm cho mỗi mức severity tương ứng với kỳ vọng vận hành rõ ràng — đặc biệt là thời gian phản hồi và tần suất truyền thông.
Ví dụ:
Hiển thị các quy tắc này trong UI nơi chọn severity để responder không phải tìm tài liệu bên ngoài khi đang outage.
Checklist giảm tải nhận thức khi mọi người căng thẳng. Giữ chúng ngắn, hành động được và gắn với vai trò.
Một mẫu hữu ích có vài mục:
Ghi thời gian và người thực hiện cho từng mục checklist để chúng trở thành phần của hồ sơ sự cố.
Sự cố hiếm khi sống một nơi. App của bạn nên cho phép đính kèm link tới:
Ưu tiên “typed links” (ví dụ: Runbook, Ticket) để có thể lọc sau này.
Nếu tổ chức theo dõi mục tiêu độ tin cậy, thêm trường nhẹ như SLO affected (yes/no), ước tính tiêu hao error budget, và rủi ro vi phạm SLA khách hàng. Giữ chúng tuỳ chọn — nhưng dễ điền trong hoặc ngay sau sự cố, khi thông tin còn tươi.
Một postmortem tốt dễ bắt đầu, khó quên và nhất quán giữa các đội. Cách đơn giản là cung cấp một mẫu mặc định (với các trường bắt buộc tối thiểu) và tự điền từ record incident để người viết tập trung suy nghĩ chứ không gõ lại.
Mẫu tích hợp nên cân bằng cấu trúc và linh hoạt:
Có thể để “Root cause” là tuỳ chọn ban đầu để xuất bản nhanh, nhưng bắt buộc trước khi phê duyệt cuối.
Postmortem không nên là tài liệu riêng lẻ. Khi tạo postmortem, tự động đính kèm:
Dùng những thứ này để tự điền các phần postmortem. Ví dụ, block “Impact” có thể bắt đầu bằng start/end time và severity, trong khi “What we did” có thể kéo từ các mục timeline.
Thêm workflow nhẹ để postmortem không bị mắc kẹt:
Ở mỗi bước, lưu ghi chú quyết định: đã thay gì, vì sao, và ai phê duyệt. Điều này tránh “chỉnh sửa im lặng” và giúp kiểm tra/audit hay review sau này dễ hơn.
Nếu muốn giữ UI đơn giản, coi review như comment với outcome rõ ràng (Approve / Request changes) và lưu lại phê duyệt cuối cùng như bản ghi không thể sửa.
Với những đội cần, liên kết “Published” tới workflow cập nhật trạng thái (xem /blog/integrations-status-updates) mà không sao chép nội dung thủ công.
Postmortem chỉ giảm sự cố trong tương lai nếu công việc follow-up thực sự được thực hiện. Xử lý action items như đối tượng first-class trong app — không để chúng là đoạn văn cuối tài liệu.
Mỗi action item nên có trường thống nhất để theo dõi và đo lường:
Thêm metadata hữu ích: tags (ví dụ “monitoring”, “docs”), component/service, và “created from” (incident ID và postmortem ID).
Đừng khóa action items trong một trang postmortem. Cung cấp:
Điều này biến follow-up thành hàng đợi vận hành thay vì ghi chú rải rác.
Một số nhiệm vụ lặp lại (đào tạo games, review runbook). Hỗ trợ mẫu định kỳ tạo item mới theo lịch, trong khi mỗi lần vẫn theo dõi riêng.
Nếu đội đã dùng tracker khác, cho phép action item chứa tham chiếu bên ngoài và external ID, trong khi app bạn là nguồn liên kết incident và xác minh.
Tạo các nhắc nhẹ: thông báo owner khi đến hạn, đánh dấu quá hạn cho lead team, và làm nổi mô hình quá hạn thường xuyên trong báo cáo. Giữ quy tắc cấu hình được để các đội phù hợp với vận hành on-call và tải công việc thực tế.
Incident và postmortem thường chứa chi tiết nhạy cảm — PII khách hàng, IP nội bộ, phát hiện bảo mật, hay vấn đề nhà cung cấp. Quy tắc truy cập rõ ràng giúp công cụ hữu dụng cho cộng tác mà không biến thành rò rỉ dữ liệu.
Bắt đầu với tập vai trò nhỏ, dễ hiểu:
Nếu có nhiều team, cân nhắc scope vai trò theo service/team (ví dụ “Payments Editors”) thay vì cấp quyền toàn cục.
Phân loại nội dung sớm, trước khi thói quen xấu hình thành:
Một mẫu thực tế là đánh dấu phần là Internal hoặc Shareable và áp dụng trong export và trang trạng thái. Sự cố bảo mật có thể cần loại incident riêng với mặc định nghiêm ngặt hơn.
Với mọi thay đổi trên incidents và postmortems, ghi lại: ai thay đổi, thay đổi gì, và khi nào. Bao gồm edit severity, timestamps, ảnh hưởng và phê duyệt cuối. Làm cho audit log có thể tìm kiếm và không thể chỉnh sửa.
Hỗ trợ auth mạnh: email + MFA hoặc magic link, và thêm SSO (SAML/OIDC) nếu người dùng mong đợi. Dùng session ngắn hạn, cookie an toàn, CSRF protection và thu hồi session tự động khi thay đổi vai trò. Với các cân nhắc rollout, xem /blog/testing-rollout-continuous-improvement.
Khi một incident đang diễn ra, mọi người lướt qua — không đọc kỹ. UX nên làm cho trạng thái hiện tại hiển thị rõ trong vài giây, đồng thời cho responder khoan sâu vào chi tiết mà không lạc hướng.
Bắt đầu với ba màn hình bao phủ hầu hết workflow:
Quy tắc đơn giản: trang chi tiết phải trả lời “Hiện tại đang xảy ra gì?” ở trên, và “Chúng ta đến đây như thế nào?” phía dưới.
Incident tích tụ nhanh, nên làm cho tìm kiếm nhanh và khoan dung:
Cung cấp view lưu sẵn như My open incidents hoặc Sev-1 this week để kỹ sư on-call không phải tạo lại filter mỗi ca.
Dùng badge màu thống nhất an toàn với màu (color-safe) trên toàn app (tránh sắc độ khó phân biệt khi căng thẳng). Giữ cùng từ vựng trạng thái ở mọi nơi: danh sách, header chi tiết và event timeline.
Trong nháy mắt, responder nên thấy:
Ưu tiên khả năng quét:
Thiết kế cho thời điểm tồi tệ nhất: nếu ai đó thiếu ngủ và được page trên điện thoại, UI vẫn phải hướng họ tới hành động đúng nhanh.
Integrations biến công cụ theo dõi sự cố từ “nơi ghi note” thành hệ thống mà đội thực sự vận hành sự cố trong đó. Bắt đầu bằng cách liệt kê hệ thống cần kết nối: monitoring/observability (PagerDuty/Opsgenie, Datadog, CloudWatch), chat (Slack/Teams), email, ticketing (Jira/ServiceNow), và trang trạng thái.
Hầu hết đội dùng hỗn hợp:
Alerts ồn, retry và thường đến không theo thứ tự. Định nghĩa idempotency key ổn định cho mỗi sự kiện provider (ví dụ: provider + alert_id + occurrence_id), và lưu nó với constraint unique. Với dedup, quyết định quy tắc như “cùng service + cùng signature trong 15 phút” nên append vào incident hiện có thay vì tạo mới.
Rõ ràng về phần app bạn quản lý so với công cụ nguồn:
Khi integration lỗi, giảm mức phục vụ: queue retries, hiển thị cảnh báo trên incident (“Slack posting delayed”), và luôn cho phép operator tiếp tục thủ công.
Xem status update là output first-class: một hành động “Update” cấu trúc trong UI nên có thể publish tới chat, append vào timeline incident, và tùy chọn sync tới trang trạng thái — mà không bắt responder viết cùng một message ba lần.
Công cụ sự cố là hệ thống “khi có outage”, nên ưu tiên đơn giản và độ tin cậy hơn sự mới lạ. Stack tốt nhất thường là thứ đội bạn có thể build, debug và vận hành lúc 2 a.m. với tự tin.
Bắt đầu với những gì kỹ sư của bạn đã deploy vào production. Một web framework phổ biến (Rails, Django, Laravel, Spring, Express/Nest, ASP.NET) thường an toàn hơn framework mới mà chỉ một người hiểu.
Với lưu trữ dữ liệu, cơ sở dữ liệu quan hệ (PostgreSQL/MySQL) phù hợp cho bản ghi incident: incidents, updates, participants, action items và postmortems đều hưởng lợi từ transaction và quan hệ rõ ràng. Thêm Redis chỉ khi thật sự cần caching, queue hoặc locks tạm thời.
Hosting có thể đơn giản như managed platform (Render/Fly/Heroku-like) hoặc cloud hiện có (AWS/GCP/Azure). Ưu tiên managed databases và backup nếu có thể.
Incident hoạt động trông tốt hơn với cập nhật real-time, nhưng không phải lúc nào cũng cần websockets ngày đầu.
Cách thực tế: thiết kế API/events để bắt đầu bằng polling và nâng cấp lên websockets sau mà không phải viết lại UI.
Nếu app này fail trong một sự cố, nó trở thành một phần của sự cố. Thêm:
Xử lý như hệ thống production:
Nếu muốn xác thực workflow và màn hình trước khi đầu tư lớn, phương pháp vibe-coding có thể hiệu quả: dùng công cụ như Koder.ai để sinh prototype hoạt động từ spec chat chi tiết, rồi lặp với responder trong tabletop exercises. Vì Koder.ai có thể tạo React frontend với backend Go + PostgreSQL (và hỗ trợ xuất source), bạn có thể coi phiên bản đầu là prototype dùng thử hoặc làm nền tảng để đội bạn củng cố — mà không mất các bài học thu được từ mô phỏng thực tế.
Phát hành app theo dõi sự cố mà không có diễn tập là một canh bạc. Các đội tốt nhất xử lý công cụ này như hệ thống vận hành khác: thử các đường dẫn quan trọng, chạy drills thực tế, rollout từng bước, và tiếp tục điều chỉnh dựa trên sử dụng thực.
Ưu tiên các flow mà người ta sẽ cần trong stress:
Thêm test hồi quy xác thực những thứ không được hỏng: timestamps, timezone, và thứ tự sự kiện. Incidents là câu chuyện — nếu timeline sai, niềm tin mất.
Bug quyền là rủi ro vận hành và an ninh. Viết tests chứng minh:
Cũng test các “gần lỗi” như người dùng mất quyền giữa chừng hoặc reorg team thay đổi membership.
Trước khi rollout rộng, chạy mô phỏng tabletop dùng app làm nguồn sự thật. Chọn kịch bản tổ chức quen thuộc (outage từng phần, trễ dữ liệu, lỗi bên thứ ba). Quan sát friction: trường gây nhầm, thiếu ngữ cảnh, nhiều click, ownership không rõ.
Thu thập phản hồi ngay và chuyển thành cải tiến nhỏ, nhanh.
Bắt đầu với một team pilot và vài mẫu dựng sẵn (loại incident, checklist, format postmortem). Cung cấp đào tạo ngắn và một trang hướng dẫn một trang “cách chúng ta vận hành sự cố” liên kết từ app (ví dụ /docs/incident-process).
Theo dõi chỉ số áp dụng và lặp trên các điểm gây friction: thời gian tạo, % incidents có cập nhật, tỷ lệ hoàn thành postmortem, và thời gian đóng action-item. Xem đó là chỉ số sản phẩm — không phải chỉ số tuân thủ — và tiếp tục cải thiện mỗi release.
Bắt đầu bằng cách viết một định nghĩa cụ thể mà tổ chức đồng ý:
Định nghĩa này nên liên kết trực tiếp với trạng thái workflow và các trường bắt buộc để dữ liệu giữ nhất quán mà không gây gánh nặng.
Xem postmortem là một workflow, không chỉ là một tài liệu:
Nếu bạn muốn có sự thay đổi thực sự, cần có theo dõi action-item và nhắc nhở — không chỉ lưu trữ tài liệu.
Một bộ tính năng v1 thực tế gồm:
Tránh tự động hoá nâng cao cho đến khi các quy trình này hoạt động mượt trong tình huống stress.
Dùng một số trạng thái dễ dự đoán phù hợp với cách đội thực tế làm việc:
Xác định “xong” cho mỗi giai đoạn, rồi thêm các hàng rào bảo vệ:
Điều này ngăn sự cố bị treo và nâng cao chất lượng phân tích sau này.
Mô hình vài vai trò rõ ràng và gắn chúng với quyền hạn:
Hiện owner/commander rõ ràng trong UI và cho phép ủy quyền (reassign, rotate commander).
Giữ mô hình dữ liệu nhỏ nhưng có cấu trúc:
Dùng định danh ổn định (UUID) kèm khoá thân thiện với người dùng (ví dụ INC-2025-0042). Xử lý chỉnh sửa như lịch sử với created_at/created_by và audit log cho các thay đổi.
Tách luồng nội bộ và luồng dành cho stakeholders, áp dụng quy tắc khác nhau:
Triển khai mẫu/visibility khác nhau và lưu cả hai vào record incident để có thể tái tạo quyết định mà không lộ thông tin nhạy cảm.
Định nghĩa mức độ severity kèm kỳ vọng rõ ràng (khẩn cấp trả lời và tần suất truyền thông). Ví dụ:
Hiển thị quy tắc ở nơi chọn severity để responder không phải mò tài liệu ngoài ứng dụng.
Xem action items là bản ghi có cấu trúc, không phải đoạn văn tự do:
Rồi cung cấp các view toàn cục (overdue, due soon, theo owner/service) và nhắc nhở/escalation nhẹ nhàng để follow-up không biến mất sau cuộc họp.
Dùng khoá idempotency theo nhà cung cấp và quy tắc dedup:
provider + alert_id + occurrence_idLuôn cho phép liên kết thủ công khi API/integration gặp sự cố.