13 thg 8, 2025·7 phút
Khái niệm hệ thống phân tán: ý tưởng Kleppmann cho mở rộng SaaS
Các khái niệm hệ thống phân tán giải thích bằng những lựa chọn thực tế khi biến prototype thành SaaS đáng tin cậy: luồng dữ liệu, nhất quán và kiểm soát tải.
Các khái niệm hệ thống phân tán giải thích bằng những lựa chọn thực tế khi biến prototype thành SaaS đáng tin cậy: luồng dữ liệu, nhất quán và kiểm soát tải.
Một prototype chứng minh ý tưởng. Một SaaS phải sống sót với việc sử dụng thực tế: lưu lượng đỉnh, dữ liệu lộn xộn, retry, và khách hàng để ý mọi trục trặc. Đó là lúc vấn đề phức tạp, vì câu hỏi chuyển từ “nó có chạy không?” sang “nó có tiếp tục chạy không?”
Với người dùng thực, “hôm qua chạy được” thất bại vì những lý do nhàm chán. Một job nền chạy muộn hơn bình thường. Một khách hàng tải lên tệp lớn gấp 10 lần dữ liệu test của bạn. Một nhà cung cấp thanh toán chậm 30 giây. Không có gì trong số này là hiếm, nhưng hiệu ứng lan truyền trở nên ồn khi các phần hệ thống phụ thuộc lẫn nhau.
Hầu hết phức tạp xuất hiện ở bốn chỗ: dữ liệu (cùng một thực tế tồn tại ở nhiều nơi và trôi), độ trễ (gọi 50 ms đôi khi thành 5 giây), lỗi (timeout, cập nhật một phần, retry), và đội ngũ (những người khác nhau phát hành dịch vụ khác nhau theo lịch khác nhau).
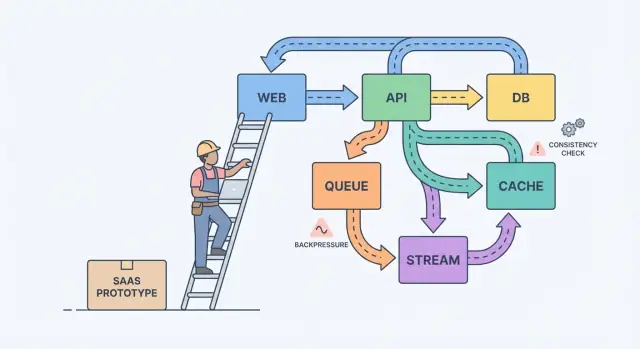
Một mô hình tư duy đơn giản giúp: components, messages và state.
Components làm việc (web app, API, worker, database). Messages chuyển công việc giữa components (request, event, job). State là thứ bạn nhớ (đơn hàng, cài đặt user, trạng thái thanh toán). Đau đầu khi scale thường là sự không khớp: bạn gửi messages nhanh hơn component có thể xử lý, hoặc bạn cập nhật state ở hai nơi mà không có nguồn sự thật rõ ràng.
Ví dụ cổ điển là billing. Một prototype có thể tạo hóa đơn, gửi email và cập nhật plan của user trong cùng một request. Khi tải tăng, email chậm lại, request timeout, client retry, và giờ bạn có hai hóa đơn và một thay đổi plan. Công việc độ tin cậy chủ yếu là ngăn những lỗi hàng ngày đó trở thành bug mà khách hàng thấy được.
Hầu hết hệ thống trở nên khó hơn vì chúng phát triển mà không có thỏa thuận về cái gì phải đúng, cái gì chỉ cần nhanh, và điều gì xảy ra khi có lỗi.
Bắt đầu bằng cách vẽ một ranh giới quanh những gì bạn hứa với người dùng. Trong ranh giới đó, đặt tên các hành động phải chính xác mọi lần (chuyển tiền, kiểm soát truy cập, quyền sở hữu tài khoản). Rồi đặt tên những phần mà “cuối cùng sẽ đúng” là được (đếm analytics, chỉ mục tìm kiếm, gợi ý). Sự phân chia này biến lý thuyết mơ hồ thành ưu tiên.
Tiếp theo, ghi lại nguồn sự thật (source of truth) của bạn. Đó là nơi các sự thật được ghi một lần, bền, với quy tắc rõ ràng. Mọi thứ khác là dữ liệu phái sinh xây cho tốc độ hoặc tiện lợi. Nếu một view phái sinh bị hỏng, bạn nên có thể xây lại từ source of truth.
Khi đội gặp bế tắc, các câu hỏi này thường bộc lộ điều quan trọng:
Nếu người dùng cập nhật plan, dashboard có thể trễ. Nhưng bạn không thể chấp nhận trạng thái thanh toán khác với quyền truy cập thực tế.
Nếu người dùng bấm nút và phải thấy kết quả ngay (lưu profile, tải dashboard, kiểm tra quyền), API request-response thường đủ. Giữ cho nó trực tiếp.
Ngay khi công việc có thể làm sau, chuyển nó sang async. Nghĩ về gửi email, charge thẻ, tạo báo cáo, thay đổi kích thước upload, hoặc đồng bộ dữ liệu đến search. Người dùng không nên đợi những việc này, và API của bạn không nên bị chiếm khi chúng chạy.
Queue là danh sách việc cần làm: mỗi task nên được một worker xử lý một lần. Stream (hoặc log) là bản ghi: sự kiện được giữ theo thứ tự để nhiều reader có thể replay, bắt kịp, hoặc xây tính năng sau này mà không thay đổi producer.
Cách thực tế để chọn:
Ví dụ: SaaS của bạn có nút “Create invoice”. API validate input và lưu invoice vào Postgres. Rồi một queue xử lý “send invoice email” và “charge card.” Nếu sau này bạn thêm analytics, thông báo và kiểm tra gian lận, một stream của InvoiceCreated cho phép mỗi tính năng subscribe mà không biến service lõi thành mê cung.
Khi sản phẩm lớn lên, event không còn là “nice to have” mà thành lưới an toàn. Thiết kế event tốt xoay quanh hai câu hỏi: bạn ghi lại những sự thật nào, và các phần khác của sản phẩm phản ứng mà không phải đoán như thế nào?
Bắt đầu với một tập nhỏ event nghiệp vụ. Chọn khoảnh khắc quan trọng với người dùng và tiền: UserSignedUp, EmailVerified, SubscriptionStarted, PaymentSucceeded, PasswordResetRequested.
Tên tồn tại lâu hơn code. Dùng thì quá khứ cho các sự kiện hoàn thành, giữ cụ thể và tránh từ ngữ UI. PaymentSucceeded vẫn có ý nghĩa ngay cả khi bạn thêm coupon, retry, hay nhiều nhà cung cấp thanh toán.
Đối xử event như hợp đồng. Tránh một cái chung chung như “UserUpdated” với nhiều trường thay đổi mỗi sprint. Ưu tiên sự thật nhỏ nhất bạn có thể cam kết trong nhiều năm.
Để tiến hoá an toàn, ưu tiên thay đổi bổ sung (thêm trường optional). Nếu cần thay đổi phá vỡ, xuất bản tên sự kiện mới (hoặc version rõ ràng) và chạy cả hai cho tới khi consumer cũ biến mất.
Nên lưu gì? Nếu bạn chỉ giữ các hàng mới nhất trong DB, bạn mất câu chuyện về cách mình đến đó.
Event thô rất tốt cho audit, replay và debug. Snapshot tốt cho đọc nhanh và khôi phục nhanh. Nhiều SaaS dùng cả hai: lưu event thô cho luồng chính (billing, quyền) và duy trì snapshot cho màn hình người dùng.
Nhất quán xuất hiện qua các khoảnh khắc như: “Tôi đổi plan, sao vẫn hiện Free?” hay “Tôi gửi invite, sao đồng đội không đăng nhập được?”
Nhất quán mạnh có nghĩa là khi bạn nhận được thông báo thành công, mọi màn hình nên phản ánh trạng thái mới ngay lập tức. Nhất quán cuối cùng có nghĩa là thay đổi lan dần theo thời gian, và trong một khoảng ngắn các phần app có thể không đồng bộ. Không có cái nào “tốt hơn” — bạn chọn dựa trên thiệt hại khi có mismatch.
Nhất quán mạnh phù hợp với tiền, quyền truy cập và an toàn: charge thẻ, đổi mật khẩu, thu hồi API key, thi hành giới hạn chỗ ngồi. Nhất quán cuối cùng thường phù hợp với feed hoạt động, tìm kiếm, analytics, “last seen” và thông báo.
Nếu bạn chấp nhận dữ liệu cũ, thiết kế cho nó thay vì che giấu. Giữ UI trung thực: hiển thị trạng thái “Đang cập nhật…” sau khi ghi cho đến khi xác nhận, cung cấp làm mới thủ công cho danh sách, và dùng optimistic UI chỉ khi bạn có thể rollback sạch sẽ.
Retry là nơi nhất quán trở nên tinh vi. Mạng rớt, client nhấp đúp, worker restart. Với các thao tác quan trọng, làm cho request idempotent để lặp lại không tạo hai hóa đơn, hai invite, hay hai refund. Một cách phổ biến là idempotency key cho mỗi hành động cộng quy tắc server trả về kết quả gốc cho lần lặp lại.
Backpressure là thứ bạn cần khi request hoặc event đến nhanh hơn hệ thống có thể xử lý. Không có nó, công việc chất đống trong bộ nhớ, queue tăng, và phụ thuộc chậm nhất (thường là DB) quyết định khi nào mọi thứ fail.
Nói nôm na: producer cứ nói trong khi consumer đang đuối. Nếu bạn vẫn chấp nhận thêm công việc, bạn không chỉ chậm lại. Bạn kích hoạt phản ứng dây chuyền của timeout và retry nhân lực lượng tải.
Các dấu hiệu thường thấy trước khi outage: backlog chỉ tăng, độ trễ nhảy sau spike hoặc deploy, retry tăng do timeout, endpoint không liên quan fail khi một phụ thuộc chậm, và kết nối DB đầy.
Khi tới điểm đó, chọn một quy tắc rõ ràng cho chuyện gì xảy ra khi bạn đầy. Mục tiêu không phải xử lý mọi thứ bằng mọi giá. Mà là sống sót và phục hồi nhanh. Các đội thường bắt đầu với một hoặc hai kiểm soát: giới hạn tần suất (per user hoặc API key), queue có giới hạn với chính sách drop/delay rõ ràng, circuit breaker cho phụ thuộc đang lỗi, và ưu tiên để request tương tác thắng job nền.
Bảo vệ DB trước tiên. Giữ pool kết nối nhỏ và đoán trước được, đặt timeout cho truy vấn, và đặt giới hạn cứng cho các endpoint tốn kém như báo cáo ad-hoc.
Độ tin cậy hiếm khi cần rewrite lớn. Nó thường đến từ vài quyết định khiến lỗi hiển hiện, bị giới hạn và có thể khôi phục.
Bắt đầu với những luồng kiếm hoặc mất uy tín, rồi thêm rào an toàn trước khi thêm tính năng:
Map critical paths. Ghi lại các bước chính xác cho signup, login, reset mật khẩu, và bất kỳ luồng thanh toán nào. Với mỗi bước, liệt kê phụ thuộc (DB, nhà cung cấp email, worker). Điều này buộc bạn rõ ràng về cái gì phải ngay lập tức và cái gì có thể sửa “theo thời gian.”
Thêm observability cơ bản. Gán mỗi request một ID xuất hiện trong logs. Theo dõi một tập nhỏ metrics khớp với nỗi đau người dùng: tỉ lệ lỗi, độ trễ, độ sâu queue, và truy vấn chậm. Thêm tracing chỉ nơi request băng qua nhiều service.
Cô lập công việc chậm hoặc flaky. Bất cứ thứ gì gọi tới dịch vụ bên ngoài hoặc thường tốn hơn một giây nên chuyển thành job và worker.
Thiết kế cho retry và lỗi một phần. Giả định timeout xảy ra. Làm cho thao tác idempotent, dùng backoff, đặt giới hạn thời gian, và giữ hành động phía người dùng ngắn.
Luyện phục hồi. Backup chỉ hữu ích nếu bạn có thể restore. Dùng release nhỏ và giữ đường rollback nhanh.
Nếu công cụ của bạn hỗ trợ snapshot và rollback (Koder.ai làm được), tích hợp đó vào thói quen triển khai thay vì coi là mánh khi khẩn cấp.
Hãy tưởng tượng một SaaS nhỏ giúp đội onboard khách hàng mới. Luồng đơn giản: user đăng ký, chọn plan, trả tiền, và nhận email chào mừng cùng vài bước “bắt đầu”.
Trong prototype, mọi thứ xảy ra trong một request: tạo account, charge thẻ, bật “paid” trên user, gửi email. Nó chạy cho đến khi lưu lượng tăng, retry xảy ra, và dịch vụ ngoài chậm.
Để đáng tin cậy, đội biến các hành động chính thành event và giữ lịch sử append-only. Họ giới thiệu vài event: UserSignedUp, PaymentSucceeded, EntitlementGranted, WelcomeEmailRequested. Điều này cho họ trail audit, giúp analytics dễ hơn, và cho phép công việc chậm chạy nền mà không block signup.
Một vài quyết định làm phần lớn công việc:
PaymentSucceeded với idempotency key rõ ràng để retry không cấp hai lần.Nếu payment thành công nhưng access chưa được cấp, user cảm thấy bị lừa. Cách sửa không phải là “nhất quán hoàn hảo mọi nơi.” Mà là quyết định cái gì phải nhất quán ngay bây giờ, rồi phản ánh quyết định đó trên UI với trạng thái như “Đang kích hoạt plan” cho tới khi EntitlementGranted đến.
Vào ngày xấu, backpressure tạo khác biệt. Nếu API email chậm trong chiến dịch marketing, thiết kế cũ timeout checkout và user retry, tạo charge và email trùng lặp. Trong thiết kế tốt hơn, checkout thành công, yêu cầu email được queue, và job replay rút backlog khi nhà cung cấp hồi phục.
Hầu hết outage không đến từ một bug hoành tráng. Chúng đến từ các quyết định nhỏ hợp lý trong prototype rồi thành thói quen.
Một bẫy phổ biến là tách microservices quá sớm. Bạn có các service chủ yếu gọi lẫn nhau, quyền sở hữu không rõ, và thay đổi cần năm deploy thay vì một.
Một bẫy khác là dùng “eventual consistency” như một tấm vé miễn phí. Người dùng không quan tâm thuật ngữ. Họ quan tâm rằng họ bấm Lưu và sau đó trang vẫn hiện dữ liệu cũ, hoặc trạng thái hóa đơn nhảy đi nhảy lại. Nếu bạn chấp nhận trễ, bạn vẫn cần phản hồi người dùng, timeout và định nghĩa “đủ tốt” cho mỗi màn hình.
Các lỗi lặp lại khác: xuất bản event mà không có kế hoạch reprocess, retry không giới hạn làm nhân tải trong sự cố, và để mọi service truy cập trực tiếp cùng schema DB khiến một thay đổi phá nhiều team.
“Sẵn sàng production” là một tập các quyết định bạn có thể chỉ ra lúc 2 giờ sáng. Rõ ràng thắng tinh tế.
Bắt đầu bằng cách đặt tên các nguồn sự thật. Với mỗi loại dữ liệu chính (khách hàng, subscription, invoice, quyền), quyết định nơi lưu bản ghi cuối cùng. Nếu app đọc “sự thật” từ hai nơi, bạn sẽ rồi hiện khác nhau cho người dùng khác nhau.
Rồi nhìn vào retry. Giả định mọi hành động quan trọng sẽ chạy hai lần vào lúc nào đó. Nếu cùng request chạm hệ thống hai lần, bạn tránh được charge kép, gửi kép hay tạo bản ghi kép không?
Checklist nhỏ bắt được hầu hết lỗi:
Việc mở rộng dễ hơn khi bạn coi thiết kế hệ thống như một danh sách ngắn các quyết định, không phải một đống lý thuyết.
Ghi lại 3–5 quyết định bạn sẽ đối mặt trong tháng tới, bằng ngôn ngữ đơn giản: “Chúng ta có chuyển gửi email vào background job không?” “Chúng ta chấp nhận analytics hơi cũ không?” “Hành động nào phải nhất quán ngay?” Dùng danh sách đó để đồng bộ product và engineering.
Rồi chọn một luồng hiện đang đồng bộ và chỉ chuyển luồng đó sang async. Biên lai, thông báo, báo cáo và xử lý file là những bước đi đầu phổ biến. Đo hai thứ trước và sau: độ trễ người dùng (trang có cảm thấy nhanh hơn không?) và hành vi lỗi (retry có tạo duplicate hay nhầm lẫn không?).
Nếu bạn muốn prototyping nhanh các thay đổi này, Koder.ai có thể hữu ích để lặp nhanh trên React + Go + PostgreSQL SaaS trong khi giữ snapshot và rollback sẵn tay. Tiêu chí đơn giản: deploy một cải tiến, học từ lưu lượng thực, rồi quyết định bước tiếp theo.
Một prototype trả lời “chúng ta có thể xây được không?” Còn một SaaS phải trả lời “nó có tiếp tục hoạt động khi người dùng, dữ liệu và lỗi xuất hiện không?”
Sự chuyển đổi lớn nhất là thiết kế cho:
Chọn một ranh giới xung quanh những gì bạn hứa với người dùng, rồi gán nhãn hành động theo ảnh hưởng.
Bắt đầu với phải chính xác mọi lúc:
Rồi đánh dấu có thể nhất quán theo thời gian:
Chọn một nơi duy nhất nơi mỗi “sự thật” được ghi một lần và được coi là cuối cùng (thường là Postgres cho một SaaS nhỏ). Đó là source of truth của bạn.
Mọi thứ khác là dữ liệu phái sinh để tăng tốc hoặc tiện lợi (cache, read models, chỉ mục tìm kiếm). Một thử nghiệm tốt: nếu dữ liệu phái sinh sai, bạn có thể xây lại từ source of truth mà không phải đoán?
Dùng request-response khi người dùng cần kết quả ngay và công việc nhỏ.
Chuyển sang bất đồng bộ khi có thể làm sau hoặc khi công việc có thể chậm:
Bất đồng bộ giữ API của bạn nhanh và giảm timeout khiến client retry.
Một queue là danh sách việc cần làm: mỗi job nên được một worker xử lý một lần (với retry).
Một stream/log là bản ghi sự kiện theo thứ tự: nhiều consumer có thể replay để xây tính năng hoặc khôi phục.
Mặc định thực tế:
Làm các hành động quan trọng idempotent: lặp lại cùng một request phải trả về cùng kết quả, không tạo hóa đơn hoặc charge thứ hai.
Mô hình phổ biến:
Cũng dùng ràng buộc unique khi có thể (ví dụ một hóa đơn cho một order).
Xuất bản một tập nhỏ các sự kiện nghiệp vụ ổn định, đặt tên ở thì quá khứ, như PaymentSucceeded hoặc SubscriptionStarted.
Giữ event:
Điều này giúp consumer không phải đoán chuyện gì đã xảy ra.
Dấu hiệu bạn cần backpressure:
Các biện pháp khởi đầu tốt:
Bắt đầu với cơ bản phù hợp với nỗi đau người dùng:
Thêm tracing chỉ nơi request băng qua dịch vụ; đừng instrument mọi thứ trước khi biết cần tìm gì.
“Production ready” nghĩa là bạn có thể trả lời các câu hỏi khó lúc 2 giờ sáng. Rõ ràng > tinh tế.
Checklist nhỏ bắt được hầu hết lỗi đau đớn:
Ghi lại như một quyết định ngắn để mọi người cùng xây theo cùng một quy tắc.
Nếu nền tảng bạn dùng hỗ trợ snapshot và rollback (như Koder.ai), tích hợp chúng vào thói quen release thay vì coi đó là mánh khóe khẩn cấp.