21. Aug. 2025·7 Min
6 SQL-Joins, die Sie kennen sollten (mit einfachen, klaren Beispielen)
Lerne die 6 SQL-Joins, die jeder Analyst kennen sollte — INNER, LEFT, RIGHT, FULL OUTER, CROSS und SELF — mit praktischen Beispielen und typischen Fallen.
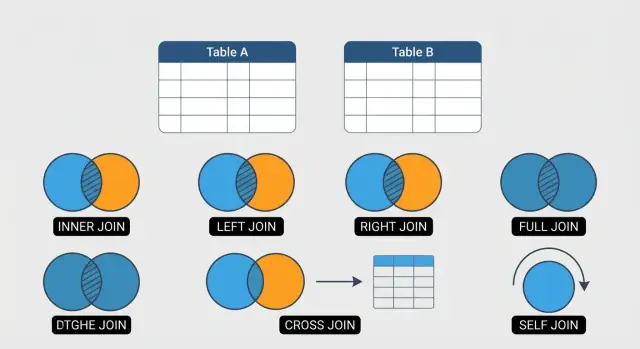
Lerne die 6 SQL-Joins, die jeder Analyst kennen sollte — INNER, LEFT, RIGHT, FULL OUTER, CROSS und SELF — mit praktischen Beispielen und typischen Fallen.
Ein SQL JOIN erlaubt es dir, Zeilen aus zwei (oder mehr) Tabellen zu einer Ergebnismenge zusammenzuführen, indem sie anhand einer verwandten Spalte — meist einer ID — abgeglichen werden.
Die meisten echten Datenbanken sind bewusst auf mehrere Tabellen verteilt, damit sich Informationen nicht wiederholen. Zum Beispiel steht der Name eines Kunden in der Tabelle customers, während seine Käufe in der Tabelle orders liegen. JOINs verbinden diese Teile wieder, wenn du Antworten brauchst.
Deshalb sind JOINs überall in Reporting und Analyse zu finden:
Ohne JOINs müsstest du separate Abfragen ausführen und Ergebnisse manuell zusammenfügen — langsam, fehleranfällig und schwer wiederholbar.
Wenn du Produkte über eine relationale Datenbank baust (Dashboards, Admin-Tools, Kundenportale), sind JOINs auch das Mittel, mit dem „rohe Tabellen“ zu benutzerfreundlichen Ansichten werden. Plattformen wie Koder.ai (die React + Go + PostgreSQL-Apps aus Chats generiert) setzen weiterhin auf solide JOIN-Grundlagen, wenn du genaue Listen, Berichte oder Abgleiche brauchst — die Datenbanklogik verschwindet nicht, nur weil die Entwicklung schneller wird.
Diese Anleitung fokussiert sich auf sechs JOINs, die den Großteil des Alltags abdecken:
Die JOIN-Syntax ist in den meisten SQL-Datenbanken ähnlich (PostgreSQL, MySQL, SQL Server, SQLite). Es gibt ein paar Unterschiede — besonders bei FULL OUTER JOIN-Support und einigen Randfällen — aber Konzepte und Kernmuster übertragen sich gut.
Um die JOIN-Beispiele einfach zu halten, nutzen wir drei kleine Tabellen, die eine gängige reale Struktur widerspiegeln: Kunden tätigen Bestellungen, und Bestellungen können (müssen aber nicht) Zahlungen haben.
Ein Hinweis vorab: die Beispieltabellen zeigen nur wenige Spalten, aber einige Abfragen später referenzieren zusätzliche Felder (wie order_date, created_at, status oder paid_at) zur Demonstration typischer Muster. Betrachte diese Spalten als übliche Felder, die du in Produktionsschemata oft findest.
Primary key: customer_id
| customer_id | name |
|---|---|
| 1 | Ava |
| 2 | Ben |
| 3 | Chen |
| 4 | Dia |
Primary key: order_id
Foreign key: customer_id → customers.customer_id
| order_id | customer_id | order_total |
|---|---|---|
| 101 | 1 | 50 |
| 102 | 1 | 120 |
| 103 | 2 | 35 |
| 104 | 5 | 70 |
Beachte, dass order_id = 104 auf customer_id = 5 verweist, die in customers nicht existiert. Diese „fehlende Übereinstimmung“ ist nützlich, um das Verhalten von LEFT JOIN, RIGHT JOIN und FULL OUTER JOIN zu sehen.
Primary key: payment_id
Foreign key: order_id → orders.order_id
| payment_id | order_id | amount |
|---|---|---|
| 9001 | 101 | 50 |
| 9002 | 102 | 60 |
| 9003 | 102 | 60 |
| 9004 | 999 | 25 |
Zwei wichtige Lehrpunkte hier:
order_id = 102 hat zwei Zahlungszeilen (eine gesplittete Zahlung). Wenn du orders mit payments joinst, erscheint diese Bestellung zweimal — hierüber stolpern viele.payment_id = 9004 verweist auf order_id = 999, die nicht in orders existiert. Das ist ein weiterer „nicht übereinstimmender“ Fall.orders und payments wiederholt Bestellung 102, weil sie zwei zugehörige Zahlungen hat.Ein INNER JOIN gibt nur die Zeilen zurück, bei denen es in beiden Tabellen eine Übereinstimmung gibt. Hat ein Kunde keine Bestellungen, erscheint er nicht. Verweist eine Bestellung auf einen nicht existierenden Kunden (schlechte Daten), erscheint diese Bestellung ebenfalls nicht.
Du wählst eine „linke“ Tabelle, joinst eine „rechte“ Tabelle und verbindest sie mit einer Bedingung in der ON-Klausel.
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id;
Der Schlüssel ist die Zeile ON o.customer_id = c.customer_id: sie sagt SQL, wie Zeilen zusammengehören.
Wenn du nur eine Liste der Kunden willst, die tatsächlich mindestens eine Bestellung aufgegeben haben (inklusive Bestelldetails), ist INNER JOIN die natürliche Wahl:
SELECT
c.name,
o.order_id,
o.total_amount
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY o.order_id;
Das ist nützlich für Dinge wie „sende Follow-up-E-Mails zu Bestellungen“ oder „berechne Umsatz pro Kunde“ (wenn du nur Kunden mit Käufen betrachtest).
Wenn du einen Join schreibst, aber die ON-Bedingung vergisst (oder auf die falschen Spalten joinst), kannst du unbeabsichtigt ein kartesisches Produkt erzeugen (jeder Kunde kombiniert mit jeder Bestellung) oder falsche Übereinstimmungen erhalten.
Schlecht (nicht machen):
SELECT c.name, o.order_id
FROM customers c
JOIN orders o;
Stelle immer sicher, dass du eine klare Join-Bedingung in ON (oder USING in den speziellen Fällen) angibst.
Ein LEFT JOIN gibt alle Zeilen aus der linken Tabelle zurück und ergänzt passende Daten aus der rechten Tabelle sofern vorhanden. Gibt es keine Übereinstimmung, erscheinen die rechten Spalten als NULL.
Verwende LEFT JOIN, wenn du eine vollständige Liste aus deiner Primärtabelle willst, plus optionale zugehörige Daten.
Beispiel: „Zeige mir alle Kunden und füge ihre Bestellungen falls vorhanden hinzu."
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY c.customer_id;
o.order_id (und andere orders-Spalten) sind NULL.Ein sehr häufiger Grund für LEFT JOIN ist das Finden von Elementen, die keine zugehörigen Datensätze haben.
Beispiel: "Welche Kunden haben noch nie bestellt?"
SELECT
c.customer_id,
c.name
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.order_id IS NULL;
Die Bedingung WHERE ... IS NULL behält nur die linken Tabellenzeilen, für die kein Treffer gefunden wurde.
LEFT JOIN kann linke Zeilen „duplizieren“, wenn es mehrere passende rechte Zeilen gibt.
Hat ein Kunde drei Bestellungen, erscheint dieser Kunde dreimal — einmal pro Bestellung. Das ist erwartetes Verhalten, kann aber überraschen, wenn du Kunden zählen willst.
Beispiel, das Bestellungen zählt (nicht Kunden):
SELECT COUNT(*)
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id;
Wenn du Kunden zählen willst, zählst du typischerweise den Kunden-Schlüssel (oft mit COUNT(DISTINCT c.customer_id)), je nachdem, was du messen willst.
Ein RIGHT JOIN behält alle Zeilen der rechten Tabelle und nur die passenden Zeilen der linken Tabelle. Gibt es keine Übereinstimmung, erscheinen die linken Spalten als NULL. Es ist im Grunde die Spiegelung eines LEFT JOIN.
Mit unseren Beispieltabellen willst du vielleicht jede Zahlung auflisten, selbst wenn sie keiner Bestellung zugeordnet werden kann (vielleicht wurde die Bestellung gelöscht oder die Zahlungsdaten sind fehlerhaft):
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM orders o
RIGHT JOIN payments p
ON o.order_id = p.order_id;
Ergebnis:
payments rechts steht).o.order_id und o.customer_id NULL.In den meisten Fällen kannst du ein RIGHT JOIN als LEFT JOIN umschreiben, indem du die Tabellenreihenfolge tauschst:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM payments p
LEFT JOIN orders o
ON o.order_id = p.order_id;
Das liefert dasselbe Ergebnis, aber viele finden es lesbarer: du beginnst mit der „Haupt“-Tabelle, die dich interessiert (hier payments) und ziehst optional verwandte Daten hinzu.
Viele SQL-Styleguides raten von RIGHT JOIN ab, weil Leser die Reihenfolge mental umkehren müssen:
Wenn optionale Beziehungen konsistent als LEFT JOIN geschrieben werden, sind Abfragen leichter zu überfliegen.
Ein RIGHT JOIN kann praktisch sein, wenn du eine bestehende, lange Abfrage bearbeitest und bemerkst, dass die „beizubehaltende“ Tabelle auf der rechten Seite steht. Anstatt die ganze Abfrage umzuschreiben, kann das Umschalten einer JOIN-Art auf RIGHT JOIN eine schnelle, risikoarme Änderung sein.
Ein FULL OUTER JOIN gibt jede Zeile aus beiden Tabellen zurück.
NULL für die rechte Seite.NULL für die linke Seite.Ein klassischer Business-Use-Case ist die Abstimmung von Bestellungen und Zahlungen:
Beispiel:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount
FROM orders o
FULL OUTER JOIN payments p
ON p.order_id = o.order_id;
FULL OUTER JOIN wird in PostgreSQL, SQL Server und Oracle unterstützt.
Es ist nicht verfügbar in MySQL und SQLite (dort brauchst du eine Umgehung).
Wenn deine Datenbank FULL OUTER JOIN nicht unterstützt, kannst du es simulieren, indem du kombinierst:
orders (mit passenden Zahlungen, wenn vorhanden), undpayments, die keine Bestellung matched haben.Ein gängiges Muster:
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
LEFT JOIN payments p
ON p.order_id = o.order_id
UNION
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
RIGHT JOIN payments p
ON p.order_id = o.order_id;
Tipp: Wenn du NULLs auf einer Seite siehst, ist das dein Signal, dass die Zeile in der anderen Tabelle fehlte — genau das, was du für Prüfungen und Reconciliation suchst.
Ein CROSS JOIN liefert jede mögliche Paarung von Zeilen aus zwei Tabellen. Hat Tabelle A 3 Zeilen und Tabelle B 4 Zeilen, enthält das Ergebnis 3 × 4 = 12 Zeilen. Das nennt man auch ein kartesisches Produkt.
Das klingt beängstigend — und kann es sein — aber es ist wirklich nützlich, wenn du Kombinationen erzeugen willst.
Angenommen, du hältst Produktoptionen in separaten Tabellen:
sizes: S, M, Lcolors: Red, BlueEin CROSS JOIN kann alle Varianten erzeugen (praktisch zum Erzeugen von SKUs, Vorbefüllen eines Katalogs oder zum Testen):
SELECT
s.size,
c.color
FROM sizes AS s
CROSS JOIN colors AS c;
Ergebnis (3 × 2 = 6 Zeilen):
Da sich Zeilenzahlen multiplizieren, kann ein CROSS JOIN schnell explodieren:
Das kann Abfragen verlangsamen, Speicher überfordern und Ausgaben erzeugen, die niemand nutzen kann. Wenn du Kombinationen brauchst, halte die Eingabetabellen klein und erwäge Beschränkungen oder gezielte Filter.
Ein SELF JOIN ist genau das: du verbindest eine Tabelle mit sich selbst. Das ist nützlich, wenn eine Zeile in einer Tabelle zu einer anderen Zeile derselben Tabelle in Beziehung steht — typischerweise für Parent/Child-Beziehungen wie Mitarbeiter und deren Manager.
Da du dieselbe Tabelle zweimal verwendest, musst du jeder „Kopie“ einen eigenen Alias geben. Aliase machen die Abfrage lesbar und zeigen SQL, welche Seite du meinst.
Übliche Konventionen sind:
e für employee (Mitarbeiter)m für manager (Manager)Stell dir eine employees-Tabelle vor mit:
idnamemanager_id (zeigt auf die id eines anderen Mitarbeiters)Um jeden Mitarbeiter mit dem Namen seines Managers aufzulisten:
SELECT
e.id,
e.name AS employee_name,
m.name AS manager_name
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id;
Beachte, dass die Abfrage einen LEFT JOIN verwendet, nicht einen INNER JOIN. Das ist wichtig, weil einige Mitarbeiter keinen Manager haben (z. B. der CEO). In solchen Fällen ist manager_id oft NULL, und ein LEFT JOIN behält die Mitarbeiterzeile bei und zeigt manager_name als NULL.
Verwendest du stattdessen INNER JOIN, würden diese Top-Level-Mitarbeiter aus dem Ergebnis verschwinden, weil es keine passende Managerzeile gibt.
Ein JOIN weiß nicht „magisch“, wie zwei Tabellen zusammengehören — du musst es sagen. Diese Beziehung wird in der Join-Bedingung definiert, und sie gehört direkt neben das JOIN, weil sie erklärt, wie die Tabellen gematcht werden, nicht wie du das finale Ergebnis filtern willst.
ON: flexibel und am gebräuchlichstenVerwende ON, wenn du volle Kontrolle über die Matching-Logik brauchst — unterschiedliche Spaltennamen, mehrere Bedingungen oder zusätzliche Regeln.
SELECT
c.customer_id,
c.name,
o.order_id,
o.created_at
FROM customers AS c
INNER JOIN orders AS o
ON o.customer_id = c.customer_id;
ON ist auch der richtige Ort für komplexere Matches (z. B. Matching auf zwei Spalten), ohne die Abfrage unübersichtlich zu machen.
USING: kürzer, aber nur für gleichnamige SpaltenEinige Datenbanken (z. B. PostgreSQL und MySQL) unterstützen USING. Es ist eine bequeme Kurzform, wenn beide Tabellen eine Spalte mit dem gleichen Namen haben und du genau auf dieser Spalte joinen willst.
SELECT
customer_id,
name,
order_id
FROM customers
JOIN orders
USING (customer_id);
Ein Vorteil: USING gibt typischerweise nur eine customer_id-Spalte im Ergebnis zurück (statt zwei Duplikate).
Nach einem Join überlappen Spaltennamen oft (id, created_at, status). Schreibst du SELECT id, kann die Datenbank einen „ambiguous column“-Fehler werfen — oder noch schlimmer, du liest aus Versehen das falsche id.
Nutze Tabellenpräfixe (oder Aliase) zur Klarheit:
SELECT c.customer_id, o.order_id
FROM customers AS c
JOIN orders AS o
ON o.customer_id = c.customer_id;
SELECT * in Join-AbfragenSELECT * wird bei Joins schnell unübersichtlich: du ziehst unnötige Spalten, riskierst Namenskonflikte und verschlechterst die Lesbarkeit. Wähle stattdessen genau die Spalten, die du brauchst. Das Ergebnis ist sauberer, wartbarer und oft effizienter — besonders bei breiten Tabellen.
Bei Joins „filtern“ sowohl WHERE als auch ON, aber zu unterschiedlichen Zeitpunkten:
Dieser Zeitunterschied ist der Grund, warum Leute unbeabsichtigt einen LEFT JOIN in einen INNER JOIN verwandeln.
Angenommen, du willst alle Kunden, selbst diejenigen ohne kürzliche bezahlte Bestellungen:
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.status = 'PAID'
AND o.order_date >= DATE '2025-01-01';
Problem: Für Kunden ohne passende Bestellung sind o.status und o.order_date NULL. Die WHERE-Klausel verwirft diese Zeilen, sodass die nicht übereinstimmenden Kunden verschwinden — dein LEFT JOIN verhält sich wie ein INNER JOIN.
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
AND o.status = 'PAID'
AND o.order_date >= DATE '2025-01-01';
Jetzt erscheinen Kunden ohne passende Bestellungen weiterhin (mit NULL-Bestellspalten), was normalerweise der Zweck eines LEFT JOIN ist.
WHERE o.order_id IS NOT NULL).Joins fügen nicht nur Spalten hinzu — sie können auch Zeilen multiplizieren. Das ist häufig richtig, überrascht aber oft, wenn Summen plötzlich doppelt so groß sind.
Ein Join gibt eine Ausgabezeile für jedes Paar passender Zeilen zurück.
customers zu orders lassen Kunden mehrfach erscheinen — einmal pro Bestellung.orders zu payments, wenn jede Bestellung mehrere Zahlungen hat, ergeben mehrere Zeilen pro Bestellung. Joins zu einer weiteren Many-Tabelle (z. B. order_items) können eine Multiplikationseffekte erzeugen: payments × items pro Bestellung.Wenn du „eine Zeile pro Kunde“ oder „eine Zeile pro Bestellung“ willst, fasse zuerst die Many-Seite zusammen und joine dann:
-- Eine Zeile pro Bestellung aus payments
WITH payment_totals AS (
SELECT
order_id,
SUM(amount) AS total_paid,
COUNT(*) AS payment_count
FROM payments
GROUP BY order_id
)
SELECT
o.order_id,
o.customer_id,
COALESCE(pt.total_paid, 0) AS total_paid,
COALESCE(pt.payment_count, 0) AS payment_count
FROM orders o
LEFT JOIN payment_totals pt
ON pt.order_id = o.order_id;
Das hält die Join-Form überschaubar: eine Bestellung bleibt eine Bestellung.
SELECT DISTINCT kann Duplikate scheinbar beheben, aber es kann das eigentliche Problem verbergen:
Verwende es nur, wenn du sicher bist, dass Duplikate rein zufällig sind und du verstehst, warum sie aufgetreten sind.
Bevor du Ergebnissen vertraust, vergleiche Zeilenzahlen:
JOINs werden oft für „langsame Abfragen“ verantwortlich gemacht, aber die echte Ursache ist meist, wie viele Daten du kombinieren willst und wie leicht die Datenbank passende Zeilen finden kann.
Denk an einen Index wie an das Inhaltsverzeichnis eines Buches. Ohne Index muss die Datenbank möglicherweise viele Zeilen scannen, um passende Join-Zeilen zu finden. Mit einem Index auf dem Join-Key (z. B. customers.customer_id und orders.customer_id) kann die Datenbank schneller zu relevanten Zeilen springen.
Du musst die Interna nicht kennen: Wenn eine Spalte oft zum Matchen verwendet wird (ON a.id = b.a_id), ist sie ein guter Kandidat für einen Index.
Soweit möglich, join auf stabilen, eindeutigen Identifikatoren:
customers.customer_id = orders.customer_idcustomers.email = orders.email oder customers.name = orders.nameNamen ändern sich und sind nicht eindeutig. E-Mails können sich ändern oder unterschiedlich formatiert sein. IDs sind dafür gedacht, konsistent zu matchen und sind oft indiziert.
Zwei Gewohnheiten machen JOINs deutlich schneller:
SELECT * bei mehreren Joins — unnötige Spalten erhöhen Speicher- und Netzwerkbedarf.Beispiel: Bestellungen zuerst einschränken, dann joinen:
SELECT c.customer_id, c.name, o.order_id, o.created_at
FROM customers c
JOIN (
SELECT order_id, customer_id, created_at
FROM orders
WHERE created_at >= DATE '2025-01-01'
) o
ON o.customer_id = c.customer_id;
Wenn du diese Abfragen in einer App erstellst (z. B. für eine Reporting-Seite mit PostgreSQL), können Tools wie Koder.ai das Scaffolding beschleunigen — Schema, Endpunkte, UI — während du die JOIN-Logik kontrollierst, die die Korrektheit bestimmt.
NULL)NULL wenn fehlend)NULLEin SQL-JOIN kombiniert Zeilen aus zwei (oder mehr) Tabellen zu einem Ergebnis, indem verwandte Spalten abgeglichen werden — meist ein Primary Key zu einem Foreign Key (zum Beispiel customers.customer_id = orders.customer_id). So „verknüpfst“ du normalisierte Tabellen wieder, wenn du Berichte, Prüfungen oder Analysen brauchst.
Verwende INNER JOIN, wenn du nur die Zeilen möchtest, bei denen die Beziehung in beiden Tabellen vorhanden ist.
Ideal für „bestätigte Beziehungen“, zum Beispiel eine Liste nur der Kunden, die tatsächlich Bestellungen getätigt haben.
Verwende LEFT JOIN, wenn du alle Zeilen aus deiner Haupttabelle (links) brauchst und zusätzlich optionale zugehörige Daten aus der rechten Tabelle.
Um „fehlende Übereinstimmungen“ zu finden, joine und filtere die rechte Seite auf NULL:
c.customer_id, c.name
customers c
orders o o.customer_id c.customer_id
o.order_id ;
RIGHT JOIN behält jede Zeile aus der rechten Tabelle und füllt linke Tabellenspalten mit NULL, wenn keine Übereinstimmung existiert. Viele Teams vermeiden es, weil es „rückwärts“ zu lesen ist.
In den meisten Fällen kannst du es als LEFT JOIN schreiben, indem du die Tabellenreihenfolge tauschst:
payments p
orders o o.order_id p.order_id
Verwende FULL OUTER JOIN zur Abstimmung/Abstimmung (Reconciliation): du willst Treffer, nur-links-Zeilen und nur-rechts-Zeilen in einer Ausgabe.
Das ist ideal für Prüfungen wie „Bestellungen ohne Zahlungen“ und „Zahlungen ohne Bestellungen“, weil die nicht übereinstimmenden Seiten als NULL erscheinen.
Einige Datenbanken (insbesondere MySQL und SQLite) unterstützen FULL OUTER JOIN nicht direkt. Eine gängige Umgehung ist, zwei Abfragen zu kombinieren:
orders LEFT JOIN paymentsDies wird typischerweise mit UNION (oder UNION ALL plus gezielter Filterung) gemacht, damit du sowohl „nur-links“ als auch „nur-rechts“ behältst.
CROSS JOIN liefert jede Kombination von Zeilen zwischen zwei Tabellen (kartesisches Produkt). Nützlich, um Szenarien zu erzeugen (z. B. Größen × Farben) oder ein Kalendergitter zu bauen.
Vorsicht: Die Anzahl der Zeilen multipliziert sich schnell, also kann es die Ausgabegröße explodieren lassen und Abfragen verlangsamen, wenn die Eingaben nicht klein und kontrolliert sind.
Ein Self-Join ist das Zusammenführen einer Tabelle mit sich selbst, um Zeilen innerhalb derselben Tabelle zu verknüpfen (häufig bei Hierarchien wie Mitarbeiter → Manager).
Du musst Aliase verwenden, um die beiden „Kopien“ zu unterscheiden:
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id
ON definiert, wie Zeilen während des Joins zusammenpassen; WHERE filtert das finale Ergebnis, nachdem der Join gebildet wurde. Bei einem LEFT JOIN kann eine WHERE-Bedingung auf die rechte Tabelle die NULL-gekennzeichneten Zeilen ausschließen und damit unbeabsichtigt aus dem LEFT JOIN ein INNER JOIN machen.
Joins können Zeilen vervielfachen, wenn Beziehungen One-to-Many oder Many-to-Many sind. Zum Beispiel erscheint eine Bestellung mit zwei Zahlungen zweimal, wenn du orders mit payments verbindest.
Um „Double-Counting“ zu vermeiden, aggregiere zuerst die Many-Seite (z. B. SUM(amount) gruppiert nach order_id) und joine dann. DISTINCT ist nur die letzte Option, weil es echte Probleme verschleiern kann und Summen/Counts verfälschen könnte.
Wenn du alle linken Zeilen behalten, aber die rechten Zeilen einschränken willst, setze die Bedingungen für die rechte Tabelle in ON.