21. Juni 2025·7 Min
Wie Abhängigkeitsinjektion (Dependency Injection) Testbarkeit und Modularität verbessert
Lerne, wie Abhängigkeitsinjektion Code besser testbar, refaktorisierbar und erweiterbar macht. Praktische Muster, Beispiele und gängige Fallstricke, die du vermeiden solltest.
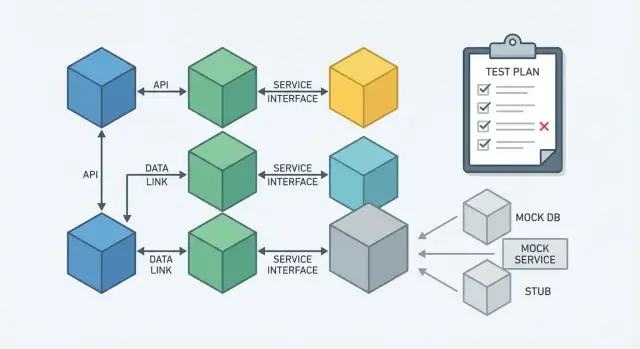
Was Abhängigkeitsinjektion (DI) bedeutet (ohne Fachchinesisch)
Dependency Injection (DI) ist eine einfache Idee: statt dass ein Codeabschnitt die Dinge, die er braucht, selbst erstellt, werden sie ihm von außen gegeben.
Diese „Dinge, die er braucht“ sind seine Abhängigkeiten — zum Beispiel eine Datenbankverbindung, ein Zahlungsdienst, eine Uhr, ein Logger oder ein E-Mail-Versender. Wenn dein Code diese Abhängigkeiten selbst baut, legt er stillschweigend fest, wie diese Abhängigkeiten funktionieren.
Eine Analogie aus dem Alltag
Denk an eine Kaffeemaschine im Büro. Sie ist abhängig von Wasser, Kaffeebohnen und Strom.
- Wenn die Maschine so gebaut ist, dass sie nur mit einer proprietären Wasserpatrone funktioniert, die sie selbst bestellt, bist du an diesen Lieferanten gebunden.
- Wenn die Maschine jede Standard-Wasserquelle akzeptiert, kann jemand anderes die Quelle wählen — Leitungswasser, gefiltert, Flasche — ohne die Maschine zu ändern.
DI ist dieser zweite Ansatz: die „Kaffeemaschine“ (deine Klasse/Funktion) konzentriert sich auf das Zubereiten von Kaffee (ihre Aufgabe), während die „Zutaten“ (Abhängigkeiten) von dem bereitgestellt werden, der sie zusammenstellt.
Was DI nicht ist
DI ist keine Verpflichtung, ein bestimmtes Framework zu verwenden, und es ist nicht dasselbe wie ein DI-Container. Du kannst DI manuell durchführen, indem du Abhängigkeiten als Parameter (oder über den Konstruktor) übergibst.
DI ist auch nicht gleich Mocking. Mocking ist eine Möglichkeit, DI in Tests zu nutzen, aber DI selbst ist nur eine Design-Entscheidung darüber, wo Abhängigkeiten erzeugt werden.
Warum Testbarkeit und Modularität zusammen besser werden
Wenn Abhängigkeiten von außen bereitgestellt werden, wird dein Code leichter in unterschiedlichen Kontexten ausführbar: Produktion, Unit-Tests, Demos und zukünftige Features.
Diese Flexibilität macht Module sauberer: Komponenten können ausgetauscht werden, ohne das ganze System umzukonfigurieren. Dadurch werden Tests schneller und klarer (weil du leichte Stellvertreter einstecken kannst) und der Code insgesamt leichter änderbar (weil Teile weniger verflochten sind).
Das Kernproblem: enge Kopplung erschwert Änderungen
Enge Kopplung entsteht, wenn ein Teil deines Codes direkt entscheidet, welche anderen Teile er verwenden muss. Die häufigste Form ist einfach: new innerhalb der Business-Logik.
Wie direkte Instanziierung versteckte Kopplung erzeugt
Stell dir eine Checkout-Funktion vor, die intern new StripeClient() und new SmtpEmailSender() macht. Das wirkt zunächst bequem — alles ist da. Aber es bindet den Checkout-Flow an genau diese Implementierungen, deren Konfiguration und Erzeugungsregeln (API-Keys, Timeouts, Netzwerkverhalten).
Diese Kopplung ist „versteckt“, weil sie nicht aus der Methodensignatur ersichtlich ist. Die Funktion sieht aus, als würde sie nur eine Bestellung verarbeiten, aber sie hängt heimlich von Zahlungsanbietern, E-Mail-Providern und vielleicht einer Datenbankverbindung ab.
Warum schwer austauschbare Abhängigkeiten Änderungen verlangsamen
Wenn Abhängigkeiten hartcodiert sind, erzeugen selbst kleine Änderungen weite Folgen:
- Provider wechseln (Stripe → Adyen) bedeutet Business-Logik zu ändern, statt eine Komponente zu ersetzen.
- Caching, Retries oder Logging müssen durch viele Aufrufstellen gestrickt werden.
- Bibliotheks-Upgrades können zu großflächigen Refactors werden, weil die Erzeugung verteilt ist.
Enge Kopplung zeigt sich durch langsame oder instabile Tests
Hartcodierte Abhängigkeiten lassen Unit-Tests echte Arbeit tun: Netzwerkaufrufe, Dateisystem-Zugriffe, Uhren, zufällige IDs oder geteilte Ressourcen. Tests werden langsam, weil sie nicht isoliert sind, und instabil, weil Ergebnisse von Timing, externen Diensten oder Reihenfolge abhängen.
Warnsignale
Wenn du folgende Muster siehst, kostet dich enge Kopplung wahrscheinlich bereits Zeit:
- Globaler Zustand als implizite Abhängigkeit
- Singletons, die sich zwischen Tests schwer zurücksetzen lassen
newüberall in der Kernlogik- Code, der ohne DB, Webserver oder echten API-Key nicht testbar ist
Dependency Injection löst das, indem Abhängigkeiten explizit und austauschbar gemacht werden — ohne die Business-Regeln jedes Mal umzuschreiben, wenn sich die Welt ändert.
Inversion of Control: "Was" von "Wie" trennen
Inversion of Control (IoC) ist ein einfacher Rollenwechsel: eine Klasse sollte sich darauf konzentrieren, was sie tun muss, nicht wie sie an die Dinge kommt, die sie dazu braucht.
Wenn eine Klasse ihre Abhängigkeiten selbst erzeugt (z. B. new EmailService() oder eine Datenbankverbindung öffnet), übernimmt sie stillschweigend zwei Aufgaben: Business-Logik und Setup. Das macht die Klasse schwerer zu ändern, schwerer wiederzuverwenden und schwerer zu testen.
Von Abstraktionen abhängig sein, nicht von konkreten Klassen
Mit IoC hängt dein Code von Abstraktionen — z. B. Interfaces oder kleinen Contract-Typen — statt von konkreten Implementierungen ab.
Zum Beispiel muss ein CheckoutService nicht wissen, ob Zahlungen über Stripe, PayPal oder einen Fake-Prozessor laufen. Er braucht einfach „etwas, das eine Karte belasten kann“. Wenn CheckoutService ein IPaymentProcessor akzeptiert, funktioniert er mit jeder Implementierung, die diesen Vertrag erfüllt.
So bleibt die Kernlogik stabil, auch wenn die zugrunde liegenden Tools wechseln.
Erzeugung aus der Klasse herausbewegen
Der praktische Teil von IoC ist, die Erzeugung von Abhängigkeiten aus der Klasse zu verlagern und sie hereinzureichen (oft über den Konstruktor). Hier kommt Dependency Injection ins Spiel: DI ist eine übliche Art, IoC zu erreichen.
Statt:
- die Klasse wählt und baut ihre Kollaborateure
bekommst du:
- die Klasse erhält Kollaborateure von außen
Das Ergebnis ist Flexibilität: Verhalten austauschen wird zur Konfigurationsfrage statt zur Code-Änderung.
Die "composition root": wo das Wiring stattfindet
Wenn Klassen ihre Abhängigkeiten nicht selbst erzeugen, muss etwas anderes das tun. Dieses „etwas“ ist die composition root: der Ort, an dem deine Anwendung zusammengesetzt wird — typischerweise der Startup-Code.
Die composition root ist der Ort, an dem du entscheidest: „In Produktion RealPaymentProcessor, in Tests FakePaymentProcessor.“ Das Wiring an einem Ort zu halten reduziert Überraschungen und hält den Rest des Codes fokussiert.
Warum das für Tests und Refactors wichtig ist
IoC vereinfacht Unit-Tests, weil du kleine, schnelle Testdoubles injizieren kannst statt echte Netzwerke oder Datenbanken zu nutzen.
Außerdem macht es Refactors sicherer: wenn Verantwortlichkeiten getrennt sind, zwingt eine Implementationsänderung selten dazu, die konsumierenden Klassen zu ändern — solange die Abstraktion gleich bleibt.
Gängige DI-Stile und wann man sie verwendet
Dependency Injection ist keine einzelne Technik — es ist eine kleine Menge von Wegen, einer Klasse die Dinge zu "füttern", die sie benötigt (Logger, DB-Client, Zahlungs-Gateway). Der gewählte Stil beeinflusst Lesbarkeit, Testbarkeit und wie leicht er missbraucht werden kann.
Konstruktorinjektion (Standard)
Bei Konstruktorinjektion sind Abhängigkeiten erforderlich, um das Objekt zu bauen. Der große Vorteil: man kann sie nicht versehentlich vergessen.
Sie passt besonders, wenn eine Abhängigkeit:
- immer notwendig ist, damit das Objekt seine Arbeit macht
- über mehrere Methoden geteilt wird
- früh validiert werden sollte (z. B. null/undefined nicht erlaubt)
Konstruktorinjektion erzeugt meist den klarsten Code und die einfachsten Unit-Tests, weil dein Test beim Erzeugen ein Fake oder Mock übergeben kann.
Parameter- / Methoden-Injektion (für Einmalbedarf)
Manchmal wird eine Abhängigkeit nur für eine einzelne Operation gebraucht — z. B. ein temporärer Formatter, eine spezielle Strategie oder ein request-scoped Wert.
In solchen Fällen übergebe sie als Methodenparameter. Das hält das Objekt schlank und verhindert, dass ein einmaliger Bedarf zur permanenten Feld-Abhängigkeit wird.
Property- / Setter-Injektion (vorsichtig nutzen)
Setter-Injektion kann praktisch sein, wenn du eine Abhängigkeit zur Konstruktion nicht bereitstellen kannst (einige Frameworks oder Legacy-Pfade). Der Nachteil ist, dass sie Anforderungen verbergen kann: die Klasse sieht nutzbar aus, obwohl sie nicht vollständig konfiguriert ist.
Das führt oft zu Laufzeit-Überraschungen („warum ist das undefined?“) und macht Tests fragiler, weil Setup leicht vergessen werden kann.
Eine einfache Faustregel
- Wenn die Klasse ohne die Abhängigkeit nicht funktionieren kann: Konstruktorinjektion.
- Wenn sie nur für einen Aufruf gebraucht wird: Methoden-/Parameter-Injektion.
- Wenn späte Verdrahtung nötig ist: Setter-Injektion, aber mit Safeguards (Dokumentation, Validierung, fail-fast).
Wie DI Unit-Tests verbessert (Geschwindigkeit, Isolation, Klarheit)
Modulare App schneller ausliefern
Verwandle dein modulares Design in ein laufendes React-Frontend und ein Go-Backend in wenigen Minuten.
Unit-Tests sind am nützlichsten, wenn sie schnell, wiederholbar und auf ein Verhalten fokussiert sind. Sobald ein Unit-Test eine echte Datenbank, Netzwerkaufruf, Dateisystem oder Systemuhr benötigt, wird er langsamer und anfälliger.
Dependency Injection löst das, indem dein Code die Dinge (DB-Zugriff, HTTP-Clients, Zeitprovider) von außen akzeptiert. In Tests tauschst du diese Abhängigkeiten gegen leichte Ersatzimplementierungen aus.
Geschwindigkeit: Tests im Speicher halten
Eine echte DB- oder API-Anfrage fügt Setup-Zeit und Latenz hinzu. Mit DI kannst du ein In-Memory-Repository oder ein Fake-Client injizieren, das vorbereitete Antworten sofort liefert. Das bedeutet:
- mehr Tests in derselben Zeit
- Tests werden häufiger ausgeführt
- CI-Pipelines bleiben schnell
Isolation: eine Sache nach der anderen testen
Ohne DI muss ein Test oft den gesamten Stack ausführen. Mit DI kannst du:
- Mocks einsetzen, um Interaktionen zu prüfen (z. B. "eine E-Mail gesendet")
- Stubs einsetzen, um bestimmte Werte zurückzugeben (z. B. "Nutzer existiert")
- Fakes nutzen, die einfache funktionale Logik besitzen (z. B. In-Memory-Store)
Keine Hacks, keine globalen Schalter — einfach eine andere Implementierung übergeben.
Klarheit: einfacheres Arrange–Act–Assert
DI macht das Setup explizit. Statt in Konfigurationen, Connection-Strings oder test-spezifischen Umgebungsvariablen zu graben, liest ein Test sofort, was real und was ersetzt ist.
Ein typischer DI-freundlicher Test liest sich so:
-
Arrange: Service mit Fake-Repository und gestubter Uhr erstellen
-
Act: Methode aufrufen
-
Assert: Rückgabewert prüfen und/oder Mock-Interaktionen verifizieren
Diese Direktheit reduziert Rauschen und macht Fehler leichter zu diagnostizieren — genau das, was man von Unit-Tests erwartet.
Test-Seams: Verhalten gezielt austauschbar machen
Ein Test-Seam ist eine bewusste Öffnung im Code, an der du Verhalten austauschen kannst. In Produktion steckt das reale Ding, in Tests ein sicherer, schneller Ersatz. DI ist eine der einfachsten Möglichkeiten, solche Seams ohne Hacks zu erzeugen.
Wo Seams typischerweise sinnvoll sind
Seams sind besonders nützlich um Systemteile, die sich im Test nur schwer kontrollieren lassen:
- Zeit (aktuelle Datum/Uhrzeit)
- Dateisystem (langsam, Berechtigungen, Aufräumen)
- E-Mail/SMS (Side-Effects, externe Dienste)
- Zahlungs-Gateways (echtes Geld, Netzwerkfehler)
Wenn Business-Logik diese Dinge direkt aufruft, werden Tests fragil: sie schlagen fehl wegen externer Umstände statt wegen falscher Logik.
Interfaces (oder Contracts) machen Seams zur einfachen Wahl
Ein Seam ist oft ein Interface — oder in dynamischen Sprachen ein einfacher Contract wie „dieses Objekt muss now() haben“. Wichtig ist: auf was du brauchst abhängen, nicht woher es kommt.
Beispiel: statt die Systemuhr direkt in einem Order-Service zu verwenden, hängst du an ein Clock:
- Produktion:
SystemClock.now() - Test:
FakeClock.now()liefert feste Zeit
Dasselbe Muster funktioniert für Datei-Lesezugriffe (FileStore), E-Mail-Versand (Mailer) oder Kartenzahlungen (PaymentGateway). Die Kernlogik bleibt unverändert; nur die eingesteckte Implementierung wechselt.
Warum Seams bessere Tests bedeuten
Wenn Verhalten gezielt austauschbar ist:
- Tests werden weniger fragil: keine Abhängigkeit von Echtzeit, echtem Netzwerk oder geteiltem Maschinenzustand
- Randfälle lassen sich leichter abdecken: simuliert werden z. B. "Zahlung abgelehnt", "E-Mail-Provider-Timeout" oder "Monatsende"
- Fehler sind klarer: schlägt ein Test fehl, liegt es meist an der Business-Regel, nicht an der Umgebung
Gut platzierte Seams reduzieren die Notwendigkeit für überall schweres Mocking. Stattdessen hast du wenige saubere Austauschpunkte, die Unit-Tests schnell, fokussiert und vorhersagbar halten.
Wie DI modulareren Code ermöglicht
Modularität bedeutet, Software aus unabhängigen Teilen zu bauen, die klare Grenzen haben: jedes Modul hat eine fokussierte Verantwortung und definierte Interaktionswege.
Dependency Injection unterstützt das, indem diese Grenzen explizit gemacht werden. Statt dass ein Modul alles selbst erstellt oder sucht, erhält es seine Abhängigkeiten von außen. Diese kleine Änderung reduziert, wie viel ein Modul über ein anderes wissen muss.
Niedrigere Kopplung per Design
Wenn Code Abhängigkeiten intern konstruiert (z. B. new-ing einen DB-Client), koppelt sich der Aufrufer eng an die Abhängigkeit. DI ermutigt, auf ein Interface (oder einfachen Contract) zu setzen, nicht auf eine konkrete Implementierung.
Das bedeutet, ein Modul muss typischerweise nur wissen:
- was es braucht (z. B.
PaymentGateway.charge()) - nicht, wie das umgesetzt ist (Stripe vs. PayPal vs. Sandbox)
Deshalb ändern sich Module seltener gemeinsam, weil interne Details nicht über Grenzen hinweglecken.
Teile ersetzen, ohne Aufrufer umzuschreiben
Eine modulare Codebasis sollte erlauben, eine Komponente auszutauschen, ohne alle Aufrufer umzuschreiben. DI macht das praktikabel:
- echten E-Mail-Sender durch queued Sender ersetzen
- Dateibasierte Repository durch DB-gestütztes Repository tauschen
- Caching-Decorator um einen bestehenden Service legen
In jedem Fall behalten Aufrufer denselben Vertrag. Das Wiring ändert sich an einer Stelle (Composition Root), nicht verstreut im Code.
Einfacheres paralleles Arbeiten in Teams
Klare Abhängigkeitsgrenzen erleichtern paralleles Arbeiten. Ein Team kann eine neue Implementierung hinter einem vereinbarten Interface bauen, während ein anderes Team weiter an Features arbeitet, die dieses Interface nutzen.
DI unterstützt auch inkrementelles Refactoring: Modul extrahieren, injizieren und schrittweise ersetzen — ohne Big-Bang-Rewrite.
Ein einfaches Vorher-Nachher-Beispiel
Volle Quellkontrolle behalten
Generiere die App und exportiere dann den Quellcode, um in deinen bestehenden Repo-Workflow zu passen.
Codebeispiele machen DI schnell verständlich. Hier ein kleines „Vorher/Nachher“ für eine Notification-Funktion.
Vorher: die Klasse erstellt ihre Abhängigkeit selbst
Wenn eine Klasse intern new aufruft, entscheidet sie welche Implementierung und wie sie gebaut wird.
class EmailService {
send(to, message) {
// talks to real SMTP provider
}
}
class WelcomeNotifier {
notify(user) {
const email = new EmailService();
email.send(user.email, "Welcome!");
}
}
Test-Probleme: ein Unit-Test riskiert echte E-Mail-Aktionen (oder erfordert globales Patchen).
test("sends welcome email", () => {
const notifier = new WelcomeNotifier();
notifier.notify({ email: "[email protected]" });
// Hard to assert without patching EmailService globally
});
Danach: die Abhängigkeit wird injiziert
Jetzt akzeptiert WelcomeNotifier jedes Objekt, das das benötigte Verhalten bietet.
class WelcomeNotifier {
constructor(emailService) {
this.emailService = emailService;
}
notify(user) {
this.emailService.send(user.email, "Welcome!");
}
}
Der Test wird klein, schnell und explizit.
test("sends welcome email", () => {
const fakeEmail = { send: vi.fn() };
const notifier = new WelcomeNotifier(fakeEmail);
notifier.notify({ email: "[email protected]" });
expect(fakeEmail.send).toHaveBeenCalledWith("[email protected]", "Welcome!");
});
Neue Implementationen hinzufügen wird einfacher
SMS später? WelcomeNotifier bleibt unverändert. Du übergibst einfach:
const smsService = { send: (to, msg) => {/* SMS provider */} };
const notifier = new WelcomeNotifier(smsService);
Das ist der praktische Gewinn: Tests müssen sich nicht mit Erzeugungsdetails herumschlagen, und neue Funktionalität kommt durch Austauschen statt Umschreiben.
Manuelle DI vs. DI-Container: Das richtige Maß wählen
DI kann so einfach sein wie „das, was du brauchst, übergeben“. Das ist manuelle DI. Ein DI-Container automatisiert das Wiring. Beide können sinnvoll sein — die Kunst ist, das Maß an Automatisierung passend zur App zu wählen.
Manuelles Wiring: explizit und leicht zu verstehen
Bei manueller DI erzeugst du Objekte selbst und übergibst Abhängigkeiten per Konstruktor oder Parameter. Vorteile:
- Sichtbar, was wo erstellt wird
- Keine versteckte Magie bei Fehlern
- Gut für kleine Apps, Skripte, Services mit wenigen Komponenten
Manuelles Wiring zwingt auch zu gutem Design: braucht ein Objekt sieben Abhängigkeiten, spürst du sofort, dass etwas nicht stimmt.
DI-Container: weniger Boilerplate, besseres Lifecycle-Management
Wenn die Anzahl der Komponenten wächst, wird manuelles Wiring repetitiv. Ein DI-Container kann helfen:
- Objektgraphen automatisch bauen
- Lebensdauern verwalten (Singleton vs per-request vs transient)
- Registrierungen zentralisieren (z. B. in Tests reale Services durch Doubles ersetzen)
Containers glänzen in Web-Apps, langlaufenden Diensten oder Systemen mit vielen Features und gemeinsam genutzter Infrastruktur.
Ein Container darf Designprobleme nicht verstecken
Ein Container kann stark gekoppelte Designs „ordentlich“ erscheinen lassen, weil das Wiring verschwindet. Die zugrunde liegenden Probleme bleiben:
- Zu viele Abhängigkeiten pro Klasse
- Unklare Zuständigkeiten für Erzeugung/Dispose
- Service-Locator-Muster, das Abhängigkeiten unsichtbar macht und Tests erschwert
Wenn ein Container das Verständnis verschlechtert oder Entwickler nicht mehr wissen, was wovon abhängt, ist es zu viel.
Ein skalierender, ausgewogener Ansatz
Beginne mit manueller DI, um die Module sichtbar zu halten. Führe einen Container ein, wenn das Wiring repetitiv oder das Lifecycle-Management komplex wird.
Praktische Regel: manuelle DI im Kern/Geschäftscode, und (optional) ein Container an der App-Grenze (Composition Root), um Boilerplate zu reduzieren. So bleibt das Design klar und trotzdem wartbar.
Häufige Fallstricke (und wie du sie vermeidest)
Mit DI-fähigem Code starten
Erstelle einen DI-freundlichen Dienst direkt im Chat und mache Abhängigkeiten von Anfang an explizit.
DI kann Code leichter testbar und änderbar machen — aber nur bei diszipliniertem Einsatz. Häufige Fehler und Gegenmittel:
Over-Injection (der Konstruktor mit 12 Parametern)
Braucht eine Klasse eine lange Liste an Abhängigkeiten, tut sie oft zu viel. Das ist kein DI-Fehler, sondern ein Entwurfsgeruch. Faustregel: wenn du den Zweck der Klasse nicht in einem Satz beschreiben kannst oder der Konstruktor wächst, extrahiere Verantwortlichkeiten, gruppiere nahe verwandte Operationen hinter einem Interface (vorsichtig, keine God-Services).
Service Locator: DI, die echte Abhängigkeiten verbirgt
Service Locator sieht oft so aus, dass innerhalb der Business-Logik container.get(Foo) aufgerufen wird. Das mag praktisch wirken, macht Abhängigkeiten aber unsichtbar: man kann nicht mehr am Konstruktor ablesen, was gebraucht wird.
Tests werden schwerer, weil globaler Zustand (der Locator) eingerichtet werden muss. Bevorzuge explizite Übergabe (Konstruktorinjektion), damit Tests das Objektgraph bewusst aufbauen können.
Versteckte Laufzeitfehler: fehlende Registrierungen und Zyklen
Container können zur Laufzeit fehlschlagen, wenn:
- eine Abhängigkeit nicht registriert wurde
- eine Registrierung die falsche Implementierung für die Umgebung wählt
- zwei Services sich gegenseitig benötigen (Zyklus)
Solche Probleme sind frustrierend, weil sie erst beim Ausführen des Wiring sichtbar werden.
Praktische Gegenmaßnahmen
Halte Konstruktoren klein und fokussiert. Wenn die Abhängigkeitsliste wächst, refaktoriere. Füge Integrationstests fürs Wiring hinzu: ein leichter Test, der den App-Container (oder das manuelle Wiring) baut, fängt fehlende Registrierungen und Zyklen früh.
Behalte die Objekterzeugung an einem Ort (Startup/Composition Root) und vermeide Container-Aufrufe in der Business-Logik. Das bewahrt die Hauptvorteile von DI: Klarheit darüber, was wovon abhängt.
Praktische Schritte, DI in eine bestehende Codebasis einzuführen
DI lässt sich am besten schrittweise als Reihe kleiner, risikoarmer Refactorings einführen. Beginne dort, wo Tests langsam oder instabil sind und Änderungen oft weite Folgen haben.
Kurze Checkliste: wo DI zuerst wirkt
Suche Abhängigkeiten, die Tests schwer machen oder den Code schwer verständlich:
- I/O: Dateisystem, Datenbank, Netzwerk
- Zeit: "now", Zeitzonen, Scheduler
- Zufall: UUIDs, Zufallszahlen, Shuffle
- Externe APIs/SDKs: Zahlungsanbieter, E-Mail-Services, Analytics, Feature-Flags
Wenn eine Funktion ohne äußere Ressourcen nicht läuft, ist sie meist ein guter Kandidat.
Schritt-für-Schritt-Refactor (wiederholbares Muster)
- Wähle einen Seam: eine externe Abhängigkeit, die aktuell intern erzeugt wird.
- Extrahiere ein Interface/Contract: definiere nur das, was du wirklich brauchst (1–3 Methoden).
- Erstelle eine reale Implementierung: kapsle die existierende konkrete Abhängigkeit.
- Injiziere sie: per Konstruktor oder Parameter (so einfach wie möglich).
- Aktualisiere das Produktions-Wiring: erzeuge die reale Implementierung an einem Ort (Entry Point/Composition Root) und übergib sie.
- Aktualisiere Tests: benutze Fake/Stub/Mock statt der echten Implementierung.
So bleiben Änderungen überschaubar und überprüfbar.
Module kohäsiv halten beim Injizieren
DI kann dazu führen, dass man zu viel injiziert und "alles von allem" abhängig wird. Regel: injiziere Fähigkeiten, keine Details. Beispielsweise Clock injizieren statt "SystemTime + TimeZoneResolver + NtpClient". Wenn eine Klasse fünf unabhängige Services braucht, tut sie vermutlich zu viel — teile sie auf.
Vermeide außerdem, Abhängigkeiten durch viele Schichten durchzureichen "nur für den Fall". Injiziere nur dort, wo sie benutzt werden; zentriere das Wiring an einem Ort.
Hinweis zu DI bei generiertem oder gescaffoldetem Code
Wenn du Generatoren oder „vibe-coding“-Workflows nutzt, bleibt DI besonders nützlich, weil es Struktur bewahrt, wenn das Projekt wächst. Zum Beispiel hilft ein klarer Composition Root und DI-freundliche Interfaces, damit generierter Code (React-Frontends, Go-Services, PostgreSQL-Backends) testbar und austauschbar bleibt, ohne Kerngeschäftslogik umzuschreiben.
Die Regel bleibt: Objekt-Erzeugung und umgebungsabhängiges Wiring an der Grenze halten, Business-Code auf Verhalten fokussieren.
Was du nach der Änderung messen solltest
Du solltest messbare Verbesserungen sehen:
- Schnellere Unit-Tests (weniger Wartezeit auf DB/Netz)
- Mehr isolierte Tests (weniger globales Setup und geteilter Zustand)
- Sauberere Grenzen (klare Verträge zwischen Modulen)
- Einfachere Änderungen (API-Client oder Speicherstrategie mit minimalen Änderungen austauschen)
Als nächster Schritt: dokumentiere deine Composition Root und halte sie unspektakulär: eine Datei, die Abhängigkeiten verdrahtet, während der Rest des Codes auf Verhalten konzentriert bleibt.
FAQ
Was ist Dependency Injection in einfachen Worten?
Dependency Injection (DI) bedeutet, dass dein Code die Dinge, die er braucht (Datenbank, Logger, Clock, Payment-Client), von außen erhält statt sie intern zu erzeugen.
Praktisch sieht das meist so aus, dass Abhängigkeiten als Konstruktor- oder Funktionsparameter übergeben werden, sodass sie explizit und austauschbar sind.
Worin unterscheidet sich DI von Inversion of Control (IoC)?
Inversion of Control (IoC) ist die allgemeinere Idee: eine Klasse sollte sich darauf konzentrieren, was sie tut, nicht wie sie ihre Kollaborateure bekommt.
DI ist eine gängige Technik, um IoC zu erreichen: Erzeugung von Abhängigkeiten wird nach außen verlagert und die Abhängigkeiten werden hereingegeben.
Warum führt ein `new` in der Business-Logik zu enger Kopplung?
Wenn eine Abhängigkeit mit new innerhalb der Business-Logik erzeugt wird, lässt sie sich nur schwer austauschen.
Das führt zu:
- Lieferantenbindung (z. B. Stripe direkt in den Checkout eingebettet)
- verstreuten Konfigurations- und Erzeugungsregeln
- langsameren, unzuverlässigeren Tests wegen echter I/O (Netzwerk/DB/Dateien/Zeit)
Wie macht DI Unit-Tests schneller und weniger fehleranfällig?
DI sorgt dafür, dass Tests schnell und deterministisch bleiben, weil du Testdoubles statt realer externer Systeme injizieren kannst.
Gängige Ersetzungen:
- Fake-/In-Memory-Repository statt echter DB
- gestubte Clock statt Systemzeit
- gemockter Mailer statt realer E-Mails
Brauche ich einen DI-Container, um DI zu nutzen?
Ein DI-Container ist optional. Beginne mit manueller DI (Abhängigkeiten explizit übergeben) wenn:
- die App klein/ mittelgroß ist
- der Objektgraph leicht manuell verdrahtet werden kann
- du maximale Klarheit willst
Ziehe einen Container in Betracht, wenn das Wiring repetitiv wird oder du Lebenszyklusmanagement (Singleton/Per-Request) brauchst.
Wann sollte ich Konstruktor- vs. Methoden- vs. Setter-Injektion verwenden?
Verwende Konstruktorinjektion, wenn die Abhängigkeit nötig ist, damit das Objekt funktioniert und über mehrere Methoden genutzt wird.
Verwende Methoden-/Parameter-Injektion, wenn die Abhängigkeit nur für einen einzelnen Aufruf gebraucht wird.
Vermeide Setter-/Property-Injektion, außer du brauchst wirklich späte Verdrahtung; ergänze dann Validierung, damit beim Fehlen schnell ein Fehler auftaucht.
Was ist eine "composition root" und wo sollte sie liegen?
Die Composition Root ist der Ort, an dem du die Anwendung zusammensetzt: Implementierungen erzeugst und den Services übergibst, was sie brauchen.
Platziere sie nahe beim App-Startup (Einstiegspunkt), damit der Rest des Codes sich auf Verhalten statt auf Wiring konzentriert.
Was ist ein Test-Seam und wo sollte ich ihn anlegen?
Ein Test-Seam ist ein absichtlich offener Punkt im Code, an dem sich Verhalten austauschen lässt.
Gute Stellen für Seams sind schwer testbare Bereiche:
- Zeit (
Clock.now()) - I/O (FileStore, HTTP-Client)
- externe Dienste (Payments, E-Mail)
DI schafft Seams, indem du in Tests einfach eine Ersatzimplementierung injizierst.
Was sind typische DI-Fehler und wie vermeide ich sie?
Häufige Fehler:
- Zu viele Abhängigkeiten: Ein Konstruktor mit vielen Parametern deutet meist darauf hin, dass die Klasse zu viel tut – aufteilen.
- Service Locator:
container.get()in Business-Code macht Abhängigkeiten unsichtbar; bessere Wahl ist explizite Übergabe. - Laufzeitfehler beim Wiring: fehlende Registrierungen oder zyklische Abhängigkeiten – füge einen kleinen Wiring-Test hinzu.
Gegenmaßnahmen: kleine, fokussierte Konstruktoren; Integrationstests für das Wiring; Composition Root zentral halten.
Wie kann ich DI sicher in eine bestehende Codebasis einführen?
Sichere Einführung durch kleine, wiederholbare Refactorings:
- Wähle eine harte Abhängigkeit (DB, Clock, HTTP-Client).
- Definiere ein kleines Interface/Contract mit nur den benötigten Methoden.
- Kapsle die aktuelle Implementierung dahinter.
- Injiziere sie per Konstruktor/Parameter.
- Passe die Startup-Verdrahtung (Composition Root) an.
- Ersetze in Tests durch Fake/Stub/Mock.
So kannst du nach jedem Schritt anhalten, ohne das System komplett umzubauen.