Was API-Evolution für KI-generierte Backends bedeutet
API-Evolution ist der fortlaufende Prozess, eine API zu ändern, nachdem sie bereits von echten Clients genutzt wird. Das kann bedeuten: Felder hinzufügen, Validierungsregeln anpassen, Performance verbessern oder neue Endpunkte einführen. Es wird besonders wichtig, sobald Clients produktiv sind — denn selbst eine „kleine“ Änderung kann eine Mobile-App-Auslieferung, ein Integrationsskript oder den Ablauf eines Partners brechen.
Abwärtskompatibilität, einfach erklärt
Eine Änderung ist abwärtskompatibel, wenn bestehende Clients ohne Updates weiter funktionieren.
Zum Beispiel liefert Ihre API möglicherweise:
{ \"id\": \"123\", \"status\": \"processing\" }
Das Hinzufügen eines neuen optionalen Feldes ist typischerweise abwärtskompatibel:
{ \"id\": \"123\", \"status\": \"processing\", \"estimatedSeconds\": 12 }
Ältere Clients, die unbekannte Felder ignorieren, laufen weiter. Dagegen sind das Umbenennen von status in state, das Ändern eines Feldtyps (string → number) oder das Erzwingen eines vormals optionalen Felds häufige Breaking-Changes.
Was „KI-generiertes Backend“ hier bedeutet
Ein KI-generiertes Backend ist nicht nur ein Code-Snippet. In der Praxis umfasst es:
- Generierten API-Code (Handler, Controller, Serializer)
- Konfiguration (Routing, Auth-Regeln, Rate Limits)
- Infrastruktur-Glue (Migrationen, Deployment-Templates, Umgebungsvariablen)
Weil KI Teile des Systems schnell regenerieren kann, kann die API „driften“, wenn Änderungen nicht bewusst gesteuert werden.
Das gilt besonders, wenn ganze Apps aus einem chat-getriebenen Workflow erzeugt werden. Zum Beispiel kann eine Plattform wie Koder.ai Web-, Server- und Mobile-Apps aus einem einfachen Chat erstellen — oft mit React im Frontend, Go + PostgreSQL im Backend und Flutter für Mobile. Diese Geschwindigkeit ist großartig, macht aber Vertrag-diziplin (und automatisierte Diffs/Tests) noch wichtiger, damit ein regeneriertes Release nicht versehentlich bestehende Clients ändert.
Was automatisiert werden kann vs. was menschliche Prüfung braucht
KI kann viel automatisieren: OpenAPI-Spezifikationen erzeugen, Boilerplate-Code aktualisieren, sichere Defaults vorschlagen und sogar Migrationsschritte entwerfen. Doch menschliche Prüfung bleibt essenziell bei Entscheidungen, die den Client-Contract betreffen — welche Änderungen erlaubt sind, welche Felder stabil sind und wie Randfälle oder Geschäftsregeln gehandhabt werden. Ziel ist Geschwindigkeit mit vorhersehbarem Verhalten, nicht Geschwindigkeit um jeden Preis.
Warum Abwärtskompatibilität oberste Priorität hat
APIs haben selten nur einen „Client“. Selbst ein kleines Produkt kann mehrere Konsumenten haben, die sich auf dasselbe Verhalten verlassen:
- Eine kontinuierlich ausgelieferte Web-App
- Eine Mobile-App, die langsamer über Stores updated
- Partnerintegrationen (oft andere Teams oder Unternehmen)
- Interne Services und Automatisierungen (Billing, Analytics, Support-Tools)
Wenn eine API bricht, sind die Kosten nicht nur Entwicklerzeit. Mobile-Nutzer können für Wochen auf älteren Appversionen festsitzen, sodass eine Breaking-Änderung zu einer langen Fehler- und Supportliste wird. Partner können Ausfälle, fehlende Daten oder gestoppte Workflows erleben — oft mit vertraglichen oder reputativen Folgen. Interne Services können stillschweigend ausfallen und Backlogs erzeugen (z. B. fehlende Events oder unvollständige Datensätze).
KI-generierte Backends fügen eine Besonderheit hinzu: Code kann schnell und häufig in großen Diffs geändert werden, weil Generierung darauf optimiert ist, funktionierenden Code zu produzieren — nicht unbedingt Verhalten über die Zeit zu bewahren. Diese Geschwindigkeit ist wertvoll, erhöht aber das Risiko versehentlicher Breaking-Changes (umbenannte Felder, andere Defaults, strengere Validierung, neue Auth-Anforderungen).
Deshalb muss Abwärtskompatibilität eine bewusst getroffene Produktentscheidung sein, nicht nur eine Gewohnheit. Praktisch heißt das: Definiere einen vorhersagbaren Änderungsprozess und behandle die API wie ein Produkt-Interface: Du darfst Fähigkeiten hinzufügen, aber überrasche bestehende Clients nicht.
Ein nützliches Denkmodell ist, den API-Contract (z. B. eine OpenAPI-Spezifikation) als „Single Source of Truth“ dafür zu sehen, worauf sich Clients verlassen können. Generierung ist dann eine Implementierungsdetail: Du kannst das Backend regenerieren, aber der Vertrag — und die Versprechen, die er macht — bleiben stabil, sofern du nicht bewusst versionierst und kommunizierst.
Der API-Contract als Single Source of Truth
Wenn ein KI-System Backend-Code schnell erzeugen oder verändern kann, ist der einzige zuverlässige Anker der API-Contract: die schriftliche Beschreibung dessen, was Clients aufrufen können, was sie schicken müssen und was sie zurückerwarten.
Was „Contract“ in der Praxis bedeutet
Ein Contract ist eine maschinenlesbare Spezifikation wie:
- OpenAPI für REST-Endpunkte (Paths, Parameter, Auth, Response-Shapes)
- JSON Schema zur Validierung von Request-/Response-Payloads (oft eingebettet in OpenAPI)
- GraphQL-Schema für Typen, Queries, Mutations und Deprecations
Dieser Contract ist, was du externen Konsumenten versprichst — auch wenn die Implementierung dahinter sich ändert.
Contract-first vs. code-first (und wo Generatoren reinpassen)
In einem contract-first Workflow entwirfst oder aktualisierst du zuerst das OpenAPI-/GraphQL-Schema und generierst dann Server-Stubs und füllst die Logik aus. Das ist meist sicherer für Kompatibilität, weil Änderungen absichtlich und reviewbar sind.
In einem code-first Workflow wird der Contract aus Code-Annotationen oder Runtime-Introspektion erzeugt. KI-generierte Backends tendieren oft standardmäßig zu code-first — das ist in Ordnung, sofern das generierte Contract-Artefakt geprüft wird, nicht als Nebensache behandelt.
Ein praktischer Hybrid: Lass die KI Codeänderungen vorschlagen, verlange aber, dass sie auch das Contract-Update (oder die Regeneration) liefert, und behandle Contract-Diffs als zentrales Änderungs-Signal.
Lege den Contract unter Versionskontrolle
Speichere deine API-Specs im selben Repo wie das Backend und prüfe sie via Pull Requests. Eine einfache Regel: kein Merge, solange die Contract-Änderung nicht verstanden und genehmigt wurde. So werden abwärtsinkompatible Änderungen früh sichtbar, bevor sie in Produktion gelangen.
Server und Clients aus einer Quelle generieren
Um Drift zu reduzieren, generiere Server-Stubs und Client-SDKs aus demselben Contract. Wenn das Contract aktualisiert wird, werden beide Seiten zusammen aktualisiert — dadurch wird es deutlich schwerer für ein KI-generiertes Implementation, Verhalten zu „erfinden“, auf das Clients nicht gebaut wurden.
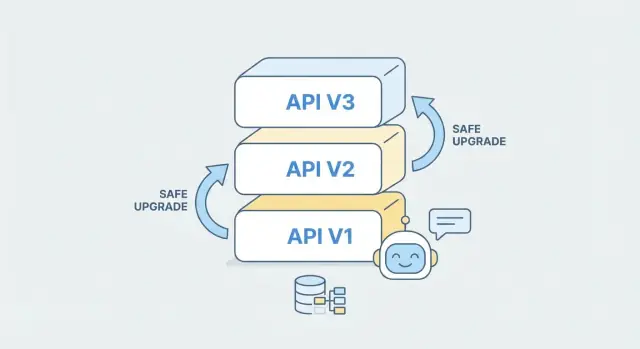
Versionierungsstrategien, die in der Praxis funktionieren
API-Versionierung ist nicht dazu da, jede zukünftige Änderung vorherzusagen — sie bietet Clients einen klaren, stabilen Weg, weiterzuarbeiten, während du das Backend verbesserst. In der Praxis ist die „beste“ Strategie die, die deine Konsumenten sofort verstehen und die dein Team konsistent anwenden kann.
Gängige Strategien (und wie sie sich für Clients anfühlen)
URL-Versionierung legt die Version in den Pfad, z. B. /v1/orders und /v2/orders. Sie ist in jeder Anfrage sichtbar, leicht zu debuggen und funktioniert gut mit Caching und Routing.
Header-Versionierung hält URLs sauber und verschiebt die Version in einen Header (z. B. Accept: application/vnd.myapi.v2+json). Elegant, aber beim Troubleshooting weniger offensichtlich und kann in kopierten Beispielen übersehen werden.
Query-Parameter-Versionierung nutzt z. B. /orders?version=2. Direkt, aber kann unordentlich werden, wenn Clients oder Proxies Query-Strings verändern/entfernen, und es ist leichter, Versionen versehentlich zu mischen.
Eine Default-Empfehlung
Für die meisten Teams — besonders wenn du willst, dass Clients es einfach verstehen — empfehle URL-Versionierung. Sie ist am wenigsten überraschend, leicht zu dokumentieren und macht sofort klar, welche Version ein SDK, eine Mobile-App oder eine Partnerintegration aufruft.
Wie KI-generierte Backends helfen können
Wenn du KI nutzt, um ein Backend zu generieren oder zu erweitern, behandle jede Version als eigene „Contract + Implementation“-Einheit. Du kannst aus einem aktualisierten OpenAPI-Spec ein neues /v2 scaffolden und /v1 intakt lassen, während du Geschäftslogik soweit möglich teilst. Das reduziert Risiko: Bestehende Clients laufen weiter, neue Clients übernehmen v2 bewusst.
Dokumentation und Änderungs-Kommunikation
Versionierung funktioniert nur, wenn deine Docs mithalten. Pflege versionierte API-Dokumentation, halte Beispiele pro Version konsistent und veröffentliche ein Changelog, das klar angibt, was sich geändert hat, was deprecated ist und Migrationshinweise (idealerweise mit nebeneinander stehenden Request/Response-Beispielen).
Kompatible vs. breaking Änderungen: eine praktische Checkliste
Wenn ein KI-generiertes Backend updated wird, ist die sicherste Frage: „Funktioniert ein bestehender Client noch ohne Änderungen?“ Nutze die Checkliste unten, um Änderungen zu klassifizieren, bevor du sie auslieferst.
Meist kompatible (additive) Änderungen
Diese Änderungen brechen typischerweise keine bestehenden Clients, weil sie nicht das, was Clients bereits senden oder erwarten, invalidieren:
- Neue optionale Antwortfelder (z. B.
middleName oder metadata). Bestehende Clients sollten weiterarbeiten, solange sie unbekannte Felder ignorieren.
- Neue Endpunkte (oder neue Methoden an anderem Pfad). Bestehendes ändert sich nicht.
- Neue optionale Anfragefelder, die der Server ignorieren oder mit Defaults behandeln kann.
- Erweiterte Enums in Responses (Clients sollten unbekannte Werte defensiv behandeln).
Meist breaking (riskant) Änderungen
Behandle diese als Breaking, sofern nicht starke Gegenbeweise vorliegen:
- Felder oder Endpunkte entfernen, oder Unterstützung für ein Feld einstellen, das Clients aktuell senden.
- Feldumbenennungen (selbst bei gleicher Semantik). Viele Clients mappen nach Name.
- Typänderungen (string → number, object → array,
nullable → non-nullable).
- Verhaltensänderungen: andere Defaults, geänderte Sortierung, Pagination-Semantik, veränderte Validierung.
- Einschränkung von Constraints: aus optional wird required, maximale Länge verringern, akzeptierte Formate ändern.
„Tolerant readers“ als Kompatibilitäts-Baseline
Ermutige Clients zu tolerant readers: ignoriert unbekannte Felder und behandelt unerwartete Enum-Werte robust. Das erlaubt dem Backend, durch Hinzufügen von Feldern zu evolvieren, ohne Clients zu zwingen, sich sofort zu ändern.
Wie KI-Generatoren Regeln durchsetzen sollten
Ein Generator kann verhindern, dass versehentlich Breaking-Changes passieren, indem er Policies anwendet:
- Blockiere Merges, wenn OpenAPI-Diffs Feldentfernungen, Umbenennungen oder Typänderungen ohne Versionserhöhung enthalten.
- Fordere, dass jedes Breaking-Change zunächst als neues Feld/Endpunkt eingeführt wird und die alten mit Deprecation-Hinweisen versehen werden.
- Gib Warnungen aus, wenn Enums erweitert oder Defaults geändert werden, und verlange eine Kompatibilitätsprüfung.
Datenbank- und Schema-Migrationen ohne Clients zu brechen
API sauber versionieren
Starte eine neue API‑Version, während v1 für bestehende Clients stabil bleibt.
API-Änderungen sind das, was Clients sehen: Request/Response-Shapes, Feldnamen, Validierung und Fehlerverhalten. Datenbankänderungen betreffen, was dein Backend speichert: Tabellen, Spalten, Indizes, Constraints und Datenformate. Sie hängen zusammen, sind aber nicht identisch.
Ein häufiger Fehler ist, eine DB-Migration als „nur intern“ zu behandeln. In KI-generierten Backends wird die API-Layer oft aus dem Schema generiert (oder ist eng daran gekoppelt), sodass eine Schema-Änderung stillschweigend zur API-Änderung werden kann. So brechen ältere Clients, obwohl du die API nicht bewusst geändert hast.
Ein sicherer Migrations-Pattern (expand → migrate → contract)
Nutze einen mehrstufigen Ansatz, der alte und neue Codepfade während Rolling Upgrades weiterlaufen lässt:
- Add: neue Spalten/Tabellen hinzufügen, ohne bestehende zu entfernen oder umzubenennen.
- Backfill: neue Felder für bestehende Zeilen befüllen (ggf. in Batches).
- Dual-write: das Backend schreibt sowohl in alte als auch neue Stellen.
- Switch reads: beginne, aus der neuen Quelle zu lesen, während weiterhin dual geschrieben wird.
- Clean up: entferne Legacy-Felder erst, nachdem alle Clients aktualisiert und alter Code entfernt ist.
Dieses Pattern vermeidet „Big Bang“-Releases und gibt Rollback-Optionen.
Defaults, NULLs und „fehlende“ Felder
Alte Clients gehen oft davon aus, dass ein Feld optional ist oder eine stabile Bedeutung hat. Beim Hinzufügen einer neuen non-null Spalte wähle zwischen:
- einem serverseitigen Default, der das Verhalten erhält, oder
- temporärem Zulassen von NULL und expliziter Handhabung in der API-Schicht.
Vorsicht: Ein DB-Default hilft nicht immer, wenn dein API-Serializer weiterhin null ausgibt oder Validierungsregeln verändert.
KI-generierte Migrationen: hilfreich, aber nicht automatisch
KI-Tools können Migrationsskripte entwerfen und Backfills vorschlagen, aber menschliche Validierung bleibt nötig: Constraints prüfen, Performance (Locks, Index-Builds) evaluieren und Migrationen gegen Staging-Daten testen, damit ältere Clients weiter funktionieren.
Feature Flags und schrittweise Rollouts für sichere Updates
Feature Flags erlauben, Verhalten zu ändern, ohne die Endpoint-Form zu verändern. Das ist besonders nützlich in KI-generierten Backends, wo interne Logik oft regeneriert oder optimiert wird, während Clients konsistente Requests und Responses erwarten.
Statt eines „großen Schalters“ liefert man den neuen Codepfad deaktiviert aus und schaltet ihn schrittweise ein. Wenn etwas schiefgeht, deaktiviert man ihn — ohne ein Notfall-Deploy.
Wie schrittweises Rollout funktioniert
Ein praktischer Plan kombiniert typischerweise drei Techniken:
- Canary Release: neues Verhalten für eine kleine Traffic-Menge (oder einen kleinen Tenant) aktivieren.
- Prozentualer Rollout: Exposure von 1% → 10% → 50% → 100% erhöhen, während Fehler und Auswirkungen beobachtet werden.
- Schneller Rollback-Plan: im Voraus definieren, welche Metriken Rollback triggern (z. B. 5xx-Rate, Validierungsfehler, Support-Tickets) und das Flag innerhalb von Minuten umkehrbar machen.
Für APIs ist wichtig, Responses stabil zu halten, während intern experimentiert wird. Du kannst Implementierungen austauschen (neues Modell, neues Routing, neuer DB-Query-Plan), solange Statuscodes, Feldnamen und Fehlerformate dem Contract entsprechen. Neue Daten sollte man vorzugsweise als additive Felder einführen, die Clients ignorieren können.
Einfaches Beispiel: schärfere Validierung schrittweise einführen
Stell dir POST /orders vor, das bisher phone in vielen Formaten akzeptiert. Du willst E.164 erzwingen — das Verschärfen der Validierung kann bestehende Clients brechen.
Sicherer Ansatz:
- Ship den strengeren Validator hinter einem Flag (z. B.
strict_phone_validation).
- Report-only-Modus: Anfragen akzeptieren, aber protokollieren, was sonst fehlgeschlagen wäre. Responses bleiben unverändert.
- Canary: Erzwingung für interne Nutzer oder 1% des Traffics.
- Ramp: Prozentual erhöhen und Validierungsfehler, Retries und Abbrüche überwachen.
- Rollback sofort, falls Fehler über Schwellwerte steigen.
So verbesserst du Datenqualität, ohne die API abwärtskompatibel in eine Breaking-Änderung zu verwandeln.
Deprecation und Sunsetting: wie man alte Versionen ausmustert
Specs in Endpunkte verwandeln
Erstelle Endpunkte, Modelle und Validierungen und verfeinere Änderungen, ohne die Kontrolle über den API‑Vertrag zu verlieren.
Deprecation ist der „höfliche Abschied“ für altes API-Verhalten: du unterlässt Förderung, warnst Clients früh und gibst einen vorhersagbaren Pfad zur Migration. Sunsetting ist der letzte Schritt: eine alte Version wird an einem veröffentlichten Datum abgeschaltet. Für KI-generierte Backends — wo Endpunkte und Schemata schnell evolvieren können — sorgt ein strikter Ruhestandsprozess dafür, dass Updates sicher bleiben und Vertrauen erhalten bleibt.
Definiere, was „major“ bedeutet (Semantic Versioning)
Wende Semantic Versioning auf Contract-Ebene an, nicht nur im Repo.
- MAJOR: jede Breaking-Änderung (Felder/Endpunkte entfernen, Sinn eines Felds ändern, Validierung verschärfen, Auth-Anforderungen ändern, Default-Verhalten ändern).
- MINOR: abwärtskompatible Erweiterungen (neue optionale Felder, neue Endpunkte, additive Enum-Werte, neue Filter-Parameter).
- PATCH: Bugfixes und nicht-funktionale Verbesserungen (Performance, interne Refactors), die Contract oder beobachtbares Verhalten nicht ändern.
Dokumentiere diese Definition in deinen Docs und wende sie konsistent an. Das verhindert „stille Majors“, bei denen eine KI-unterstützte Änderung klein aussieht, aber Clients bricht.
Praktischer Deprecation-Zeitrahmen
Wähle eine Default-Policy und halte dich daran, damit Nutzer planen können. Ein häufiger Ansatz:
- Deprecation ankündigen: sofort bei Veröffentlichung der neuen Version
- Deprecation-Fenster: alte Version 90–180 Tage weiter laufen lassen (bei Enterprise länger)
- Sunset-Datum: von Anfang an ein festes Abschaltdatum veröffentlichen
Bei Unsicherheit: lieber ein längeres Fenster wählen; die Kosten, eine Version für kurze Zeit länger am Leben zu halten, sind meist geringer als Notfall-Migrationen.
Deprecation-Signale (unübersehbar machen)
Nutze mehrere Kanäle, weil nicht alle Release Notes lesen:
- Response-Header: z. B.
Deprecation: true und Sunset: Wed, 31 Jul 2026 00:00:00 GMT, plus ein Link zur Migrations-Doku.
- Docs-Banner: deutliches Banner in der alten Version mit Sunset-Datum und Migrations-Checklist (Link zu /docs/api/v2/migration).
- SDK-Warnungen: Warnungen in offiziellen SDKs (Runtime-Logs +, wo möglich, Compile-Time-Deprecation-Annotations).
Füge Deprecation-Hinweise auch in Changelogs und Status-Updates ein, damit Beschaffung und Ops-Teams sie sehen.
Entfernung: Sunset mit festem Datum (und sicherem Endzustand)
Lass alte Versionen bis zum Sunset-Datum laufen und deaktiviere sie dann bewusst — nicht durch zufälliges Brechen.
Beim Sunset:
- Eine klare Fehlerantwort für die retirete Version zurückgeben (z. B.
410 Gone) mit Verweis auf die neueste Version und Migrationsseite.
- Für eine Weile eine stabile, menschenlesbare Erklärungsseite bereithalten (z. B. /docs/deprecations/v1).
Wichtig: Behandle Sunsetting als geplante Änderung mit verantwortlichen Personen, Monitoring und Rollback-Plan. Diese Disziplin macht häufige Evolution möglich, ohne Clients zu überraschen.
Tests, die versehentliche Breaking-Changes verhindern
KI-generierter Code kann sich schnell ändern — manchmal an überraschenden Stellen. Die sicherste Methode, Clients funktionsfähig zu halten, ist, den Contract zu testen (was du extern versprichst), nicht nur die Implementierung.
Contract-Tests: Spec-zu-Spec-Vergleiche
Ein praktisches Minimum ist ein Contract-Test, der die vorherige OpenAPI-Spezifikation mit der neu generierten vergleicht. Behandle ihn wie einen Vorher/Nachher-Check:
- entfernte Endpunkte, umbenannte Felder, verschärfte Validierungsregeln oder geänderte Auth-Anforderungen entdecken
- Response-Code-Änderungen aufspüren (z. B. 200 → 204 oder geändertes 404-Verhalten)
- subtile Änderungen wie ein optionales Feld, das plötzlich required wird, finden
Viele Teams automatisieren einen OpenAPI-Diff in CI, sodass kein generierter Change deployed werden kann, ohne Review. Das ist besonders nützlich, wenn Prompts, Templates oder Modellversionen wechseln.
Consumer-driven Contract Testing (in klaren Worten)
Consumer-driven Contract Testing dreht die Perspektive um: statt Backend-Teams zu raten, wie Clients die API nutzen, teilt jeder Client eine kleine Menge Erwartungen (welche Requests er sendet und welche Responses er erwartet). Das Backend muss vor dem Release beweisen, dass es diese Erwartungen weiterhin erfüllt.
Das funktioniert gut, wenn du mehrere Konsumenten hast (Web, Mobile, Partner) und Updates ohne Koordination jeder einzelnen Deployment-Pipeline durchführen willst.
Regressions-Tests für Response-Shapes und Errors
Füge Regressions-Tests hinzu, die festhalten:
- Response-JSON-Shape (Feldnamen, Typen, Verschachtelung)
- Defaults und Nullability (fehlend vs. null)
- Pagination- und Sort-Semantik
- Fehlerformate: stabile Fehlercodes, Message-Struktur und Validierungs-Felder
Wenn du ein Fehler-Schema veröffentlichst, teste es explizit — Clients parsen oft Fehler mehr, als wir gerne hätten.
CI-Gates vor dem Rollout
Kombiniere OpenAPI-Diff-Checks, Consumer-Contracts und Shape/Error-Regressionstests zu einem CI-Gate. Wenn eine generierte Änderung fehlschlägt, ist die übliche Lösung, den Prompt, die Generationsregeln oder eine Kompatibilitätsschicht anzupassen — bevor Nutzer etwas bemerken.
Fehlerbehandlung und Verhaltensstabilität über Versionen hinweg
Clients reagieren selten auf Error-Nachrichten als Text — sie reagieren auf Error-Shapes und Codes. Ein Tippfehler in einer menschenlesbaren Nachricht ist ärgerlich, aber verkraftbar; ein geänderter Statuscode, ein fehlendes Feld oder ein umbenannter Fehler-Identifier kann einen Checkout, einen Sync oder eine Retry-Schleife kaputtmachen.
Stabile Fehler: Machine-Readability priorisieren
Strebe ein konsistentes Fehler-Envelope an (z. B. { code, message, details, request_id }) und behalte stabile Identifier, auf die Clients vertrauen können. Du kannst message inhaltlich verbessern, aber erhalte die Semantik von code und dokumentiere sie.
Wenn du bereits mehrere Formate im Einsatz hast, widerstehe dem Drang, „auf der Stelle aufzuräumen“. Besser: ein neues Format hinter einer Versionsgrenze oder Verhandlungsmechanismus (z. B. Accept-Header) einführen und das alte weiterhin unterstützen.
Neue Fehlercodes hinzufügen ohne alte Clients zu brechen
Neue Fehlercodes sind manchmal nötig, aber führe sie so ein, dass bestehende Integrationen nicht überrascht werden:
- Alte Codes beibehalten: Wenn Clients
VALIDATION_ERROR behandeln, ersetze ihn nicht plötzlich durch INVALID_FIELD.
- Neue Codes als spezifischere Varianten einführen: returne den neuen
code, aber gib auch rückwärtskompatible Hinweise in details (oder mappe auf den allgemeinen alten Code für ältere Versionen).
- Führe eine Fallback-Regel ein: Clients sollen unbekannte Codes anhand des HTTP-Status (400/401/403/404/409/429/500) klassifizieren und weiterhin
message anzeigen.
Wesentlich: Ändere niemals die Bedeutung eines bestehenden Codes. Wenn NOT_FOUND bisher „Resource existiert nicht“ bedeutete, nutze ihn nicht plötzlich für „Zugriff verweigert“ (das wäre 403).
Verhaltensstabilität: Defaults dürfen sich nicht stillschweigend ändern
Abwärtskompatibilität heißt auch „gleiche Anfrage, gleiches Resultat“. Kleine Default-Änderungen können Clients brechen, die Parameter nie explizit gesetzt haben.
Pagination: ändere nicht stillschweigend Default-limit, page_size oder Cursor-Verhalten — das ist breaking, es sei denn, du bietest beide Pfade.
Sortierung: Standard-Sortierung sollte stabil bleiben. Ein Wechsel von created_at desc zu relevance desc kann Listen neu ordnen und UI- oder Sync-Annahmen brechen.
Filtering: Vermeide, implizite Filter zu ändern (z. B. plötzlich „inactive“ Items standardmäßig ausschließen). Wenn neues Verhalten benötigt wird, füge ein explizites Flag hinzu wie include_inactive=true oder status=all.
Manche Kompatibilitätsprobleme betreffen nicht Endpunkte, sondern Interpretation:
- Zeitzonen: gib immer an, ob Timestamps in UTC sind, inklusive Offsets, und bleib konsistent. Ein Wechsel von lokaler Zeit zu UTC ohne Warnung kann Duplikate oder fehlende Events erzeugen.
- Zahlenformate: JSON-Nummern sind eindeutig, aber Strings, die wie Zahlen aussehen (Währungen, Dezimalzahlen) können variieren. Ändere nicht einfach
\"9.99\" zu 9.99 (oder umgekehrt).
- Boolean-Defaults: Defaults wie
include_deleted=false oder send_email=true dürfen sich nicht umdrehen. Wenn ein Default geändert werden muss, mache das opt-in via neuem Parameter.
Für KI-generierte Backends: sperre diese Verhaltensweisen mit expliziten Contracts und Tests — das Modell könnte sonst Antworten „verbessern“, falls Stabilität nicht als Erstes verlangt wird.
Observability: Kompatibilität in der Realwelt überwachen
Schnell v1 starten
Baue heute eine kleine v1‑API und übe Kompatibilitätsregeln vor deiner ersten Partnerintegration.
Abwärtskompatibilität verifiziert man nicht einmalig. Bei KI-generierten Backends ändert sich Verhalten oft schneller als bei handgebauten Systemen, daher brauchst du Feedback-Loops, die zeigen, wer was nutzt und ob ein Update Clients schadet.
Metriken nach API-Version (und Endpoint) tracken
Markiere jede Anfrage mit expliziter API-Version (Pfad wie /v1/..., Header wie X-Api-Version oder verhandelte Schema-Version). Sammle dann segmentierte Metriken:
- Usage: Requests pro Minute nach Version und Route
- Latenz: p50/p95 nach Version (eine kompatible Änderung kann trotzdem zu langsam sein)
- Error-Raten: 4xx vs. 5xx nach Version (Spitzen offenbaren oft versteckte Breakages)
So erkennst du z. B., dass /v1/orders nur 5% des Traffics ist, aber 70% der Fehler nach einem Rollout verursacht.
Erkenne Clients, die noch alte Felder/Endpunkte nutzen
Instrumentiere Gateway oder App, um zu loggen, was Clients tatsächlich senden und welche Routen sie aufrufen:
- Requests an deprecated Endpunkte (z. B.
/v1/legacy-search)
- Payloads mit deprecated Feldern
- Requests ohne neue optionale Felder, die einige generierte Clients vielleicht erwarten
Wenn du SDKs kontrollierst, füge einen leichten Client-Identifier + SDK-Version-Header hinzu, um veraltete Integrationen zu identifizieren.
Logs und Tracing zur Ursacheingrenzung
Bei Fehleranstiegen willst du wissen: „Welches Deployment hat Verhalten geändert?“ Korrelier Spitzen mit:
- Release-IDs (Commit-Hash/Build-ID)
- strukturierten Logs mit Version, Route und Validierungsfehlern
- verteilten Traces, die zeigen, wo Latenz/Exceptions auftraten (Gateway → Handler → DB)
Rollback passend zu generierten Deployments
Halte Rollbacks langweilig: immer das vorherige generierte Artefakt (Container/Image) redeployen und Traffic über den Router zurückschalten. Vermeide Rollbacks, die Daten-Reversionen erfordern; bei Schema-Änderungen nutze additive Migrationsstrategien, sodass ältere Versionen weiter funktionieren, wenn du die API-Schicht revertierst.
Wenn deine Plattform Snapshots und schnelle Rollbacks unterstützt, nutze sie. Z. B. bietet Koder.ai Snapshots und Rollback im Workflow, was gut zu „expand → migrate → contract“-Datenbankänderungen und schrittweisen API-Rollouts passt.
Ein wiederholbarer Workflow für die Evolution KI-generierter APIs
KI-generierte Backends ändern sich schnell — neue Endpunkte tauchen auf, Modelle verschieben sich, Validierungen werden strenger. Der sicherste Weg, Clients stabil zu halten, ist, API-Änderungen wie einen kleinen, wiederholbaren Release-Prozess zu behandeln, nicht wie einmalige Editierungen.
Der Workflow (Proposal → Sunset)
- Change vorschlagen
Schreibe das „Warum“, das beabsichtigte Verhalten und den genauen Contract-Impact (Felder, Typen, required/optional, Fehlercodes) auf.
- Klassifizieren
Markiere als kompatibel (sicher) oder breaking (erfordert Client-Änderung). Wenn unsicher: als breaking annehmen und einen Kompatibilitätspfad entwerfen.
- Kompatibilitätsplan entwerfen
Entscheide, wie alte Clients unterstützt werden: Aliase, Dual-Write/Dual-Read, Default-Werte, tolerant Parsing oder eine neue Version.
- Hinter einer Absicherung implementieren
Führe die Änderung mit Feature Flags oder Konfiguration ein, damit du sie schrittweise ausrollen und schnell zurücknehmen kannst.
- Contract testen
Führe automatisierte Contract-Checks (z. B. OpenAPI-Diff-Regeln) sowie „golden“ Known-Client Request/Response-Tests aus, um Behavior-Drift zu erkennen.
- Mit Dokumentation ausliefern
Jedes Release sollte beinhalten: aktualisierte Referenzdocs in /docs, kurze Migrationshinweise falls nötig und einen Changelog-Eintrag, der angibt, was sich geändert hat und ob es kompatibel ist.
- Deprecate und entfernen nach Plan
Deprecations mit Datum ankündigen, verbleibende Nutzung messen und nach dem Sunset-Fenster entfernen.
Mini-Beispiel: Feld umbenennen ohne Clients zu brechen
Willst du last_name in family_name umbenennen:
- Request-Handling: akzeptiere beide Felder; wenn beide gesendet werden, bevorzuge
family_name.
- Response-Handling: gib während der Übergangszeit beide Felder zurück (oder gib
family_name zurück und behalte last_name als Alias).
- Storage: mappe beides auf dieselbe interne Spalte.
- Docs + Changelog: dokumentiere den neuen Namen, markiere
last_name als deprecated und setze ein Entferndatum.
Wenn dein Angebot planbasierten Support oder langfristige Versionen enthält, weise auf /pricing darauf hin.