Warum Schema-Änderungen Ausfälle verursachen
Ausfälle durch eine Datenbankänderung sind nicht immer ein sauberer, offensichtlicher Ausfall. Für Nutzer kann es so aussehen, als würde eine Seite endlos laden, ein Checkout fehlschlägt oder die App plötzlich „etwas ist schiefgelaufen“ anzeigt. Für Teams zeigt es sich in Alerts, steigenden Fehlerraten und einem Berg fehlgeschlagener Schreibvorgänge, die bereinigt werden müssen.
Schema-Änderungen sind riskant, weil die Datenbank von allen laufenden Versionen deiner App geteilt wird. Während eines Releases laufen oft alte und neue Versionen gleichzeitig (Rolling Deploys, mehrere Instanzen, Background Jobs). Eine Migration, die korrekt aussieht, kann trotzdem eine dieser Versionen kaputtmachen.
Gängige Fehlerfälle sind:
- Neuer Code schreibt in eine Spalte, die noch nicht existiert, und erzeugt sofort Fehler.
- Alter Code liest eine Spalte oder Tabelle, die eine Migration umbenannt oder gelöscht hat, und stürzt nach dem Deploy ab.
- Ein Backfill oder Index-Build treibt die CPU in die Höhe oder sperrt Zeilen, sodass normale Anfragen langsam werden oder timeouten.
- Eine vermeintlich „schnelle" Constraint-Änderung (wie NOT NULL) blockiert Schreibvorgänge, während die Tabelle geprüft wird.
Selbst wenn der Code korrekt ist, werden Releases blockiert, weil das eigentliche Problem Timing und Kompatibilität zwischen Versionen ist.
Ausfallfreie Schema-Änderungen folgen einer einfachen Regel: jeder Zwischenzustand muss für alten und neuen Code sicher sein. Du änderst die Datenbank, ohne bestehende Lese- und Schreibvorgänge zu zerstören, rollst Code aus, der mit beiden Formen umgehen kann, und entfernst den alten Pfad erst, wenn nichts mehr darauf angewiesen ist.
Dieser Mehraufwand zahlt sich aus, wenn du echten Traffic, strenge SLAs oder viele App-Instanzen und Worker hast. Für ein kleines internes Tool mit ruhiger Datenbank kann ein geplantes Wartungsfenster einfacher sein.
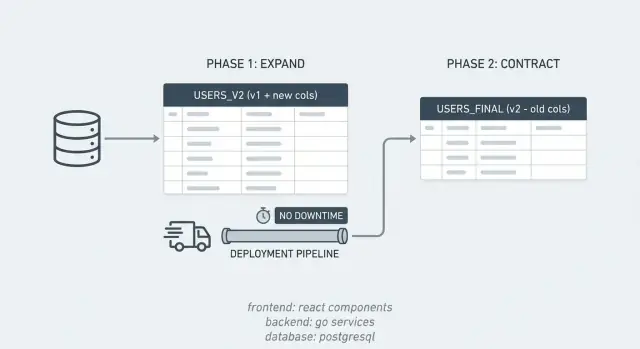
Expand/Contract in einfachen Worten
Die meisten Zwischenfälle bei Datenbankarbeit entstehen, weil die App erwartet, dass die DB sofort umgestellt ist, während die Änderung Zeit braucht. Das Expand/Contract-Muster vermeidet das, indem es eine riskante Änderung in kleinere, sichere Schritte aufteilt.
Für eine kurze Zeit unterstützt dein System zwei „Dialekte“ gleichzeitig. Du führst die neue Struktur zuerst ein, lässt die alte weiter bestehen, verschiebst Daten graduell und räumst dann auf.
Das Muster ist einfach:
- Expand: Füge hinzu, was du brauchst (Spalten, Tabellen, Indizes), ohne die aktuelle App zu brechen.
- Beide Pfade laufen lassen: Rolle Code aus, der mit altem und neuem Schema funktioniert, damit gemischte Versionen korrekt arbeiten.
- Contract: Sobald alles den neuen Pfad nutzt, entferne das alte Schema und den alten Code.
Das passt gut zu Rolling Deploys. Wenn du 10 Server nacheinander aktualisierst, laufen alte und neue Versionen kurz parallel. Expand/Contract sorgt dafür, dass beide Versionen während dieser Überschneidung mit derselben Datenbank kompatibel bleiben.
Es macht Rollbacks ebenfalls weniger beängstigend. Wenn ein neues Release einen Fehler hat, kannst du die App zurücksetzen, ohne die Datenbank zu rollbacken, weil die alten Strukturen während des Expand-Fensters noch vorhanden sind.
Beispiel: Du willst eine PostgreSQL-Spalte full_name in first_name und last_name aufteilen. Du fügst die neuen Spalten hinzu (expand), rollst Code, der beide Formen lesen und schreiben kann, füllst alte Zeilen nach und entfernst full_name, sobald nichts mehr davon abhängt (contract).
Was „Expand" üblicherweise beinhaltet
Die Expand-Phase bedeutet, neue Optionen hinzuzufügen, nicht alte zu entfernen.
Ein häufiger erster Schritt ist eine neue Spalte. In PostgreSQL ist es meist am sichersten, sie nullable und ohne Default hinzuzufügen. Eine nicht-nullbare Spalte mit Default kann je nach Postgres-Version und Änderung einen Table-Rewrite oder stärkere Locks auslösen. Eine sicherere Reihenfolge ist: nullable hinzufügen, toleranten Code deployen, backfill durchführen und erst später NOT NULL erzwingen.
Indizes brauchen ebenfalls Aufmerksamkeit. Das Erstellen eines normalen Index kann Schreibvorgänge länger blockieren als erwartet. Nutze, wenn möglich, concurrent Index-Erstellung, damit Lesen und Schreiben weiterlaufen. Das dauert länger, verhindert aber freigabestoppende Locks.
Expand kann auch das Hinzufügen neuer Tabellen bedeuten. Wenn du von einer einzelnen Spalte zu einer Many-to-Many-Beziehung wechselst, fügst du vielleicht eine Join-Tabelle hinzu und lässt die alte Spalte noch bestehen. Der alte Pfad bleibt funktionsfähig, während die neue Struktur Daten sammelt.
In der Praxis umfasst Expand oft:
- Hinzufügen neuer nullable Spalten oder neuer Tabellen neben bestehenden
- Indizes so weit möglich nicht-blockierend anlegen
- Feature-Flags nutzen, um zu steuern, wann neue Reads/Writes aktiviert werden
- Bei Bedarf in beide Felder schreiben (Dual-Write)
- Lesezugriffe rückwärtskompatibel halten (alt, neu oder Fallback)
Nach Expand sollten alte und neue App-Versionen gleichzeitig laufen können, ohne Überraschungen.
Code deployen, der kompatibel bleibt
Der meiste Schmerz entsteht in der Mitte: Einige Server laufen mit neuem Code, andere noch mit altem, während die Datenbank sich bereits ändert. Dein Ziel ist einfach: Jede Version im Rollout muss mit altem und erweitertem Schema funktionieren.
Ein gängiger Ansatz ist Dual-Write. Wenn du eine neue Spalte hinzufügst, schreibt die neue App sowohl in die alte als auch in die neue Spalte. Alte App-Versionen schreiben weiter nur in die alte Spalte, was in Ordnung ist, weil sie noch existiert. Halte die neue Spalte zunächst optional und verschiebe strikte Constraints, bis alle Writer aktualisiert sind.
Lesende Zugriffe werden oft vorsichtiger umgestellt als Schreibvorgänge. Lass eine Zeit lang die alten Spalten lesen (die vollständig gefüllt sind). Nach Backfill und Verifikation stellst du die Leselogik so um, dass sie das neue Feld bevorzugt und bei fehlendem Wert auf das alte zurückfällt.
Halte auch die API-Ausgabe stabil, während sich die Datenbank darunter ändert. Selbst wenn du ein neues internes Feld einführst, vermeide Änderungen an Response-Formaten, bis alle Konsumenten (Web, Mobile, Integrationen) bereit sind.
Ein rollback-freundlicher Ablauf könnte so aussehen:
- Release 1: Neue Spalte hinzufügen und Code ausrollen, der alte Daten lesen und in beide Spalten schreiben kann.
- Release 2: Bestehende Zeilen backfillen und Code ausrollen, der das neue Feld bevorzugt, aber zurückfällt.
- Release 3: Aufhören, die alte Spalte zu schreiben (sie bleibt aber bestehen).
- Release 4: Alte Lesewege entfernen und dann die alte Spalte löschen.
Die zentrale Idee ist, dass der erste irreversible Schritt das Löschen der alten Struktur ist — den verschiebst du ans Ende.
Daten sicher backfillen (ohne die DB zu überlasten)
Sichere Schema-Änderungen planen
Setze deinen Expand-/Contract-Plan in konkrete Aufgaben und Checkpoints um, bevor du in Produktion eingreifst.
Backfilling ist der Punkt, an dem viele „ausfallfreie" Schema-Änderungen schiefgehen. Du willst die neue Spalte für bestehende Zeilen füllen, ohne lange Locks, langsame Queries oder unerwartete Lastspitzen.
Batching ist entscheidend. Ziel sind Batches, die schnell fertig werden (Sekunden, nicht Minuten). Sind die Batches klein, kannst du pausieren, fortsetzen und den Job anpassen, ohne Releases zu blockieren.
Zur Fortschrittsverfolgung nutze einen stabilen Cursor — in PostgreSQL oft der Primärschlüssel. Verarbeite Zeilen in Reihenfolge und speichere die zuletzt verarbeitete id oder arbeite in id-Bereichen. So vermeidest du teure Full-Table-Scans beim Neustart des Jobs.
Ein einfaches Muster ist:
UPDATE my_table
SET new_col = ...
WHERE new_col IS NULL
AND id > $last_id
ORDER BY id
LIMIT 1000;
Mache das Update bedingt (z. B. WHERE new_col IS NULL), sodass der Job idempotent ist. Wiederholte Läufe berühren nur Zeilen, die noch Arbeit brauchen, und reduzieren unnötige Writes.
Plane für neue Daten, die während des Backfills ankommen. Übliche Reihenfolge ist:
- App-Code zuerst aktualisieren, damit neue Writes auch das neue Feld befüllen.
- Historische Zeilen in Batches backfillen.
- Eine kurze Catch-up-Schleife laufen lassen, die neuere Zeilen erneut prüft.
- Falls nötig, ein Guardrail (Trigger oder Default) hinzufügen, um neue NULLs zu verhindern.
Ein guter Backfill ist langweilig: stetig, messbar und einfach zu pausieren, falls die DB heiß läuft.
Verifizieren, dass die Migration wirklich abgeschlossen ist
Der riskanteste Moment ist nicht das Hinzufügen der neuen Spalte — es ist die Entscheidung, ihr zu vertrauen.
Bevor du zu Contract übergehst, beweise zwei Dinge: die neuen Daten sind vollständig, und Produktion liest sie sicher.
Beginne mit schnellen, wiederholbaren Vollständigkeitsprüfungen:
- Bestätige, dass die neue Spalte keine unerwarteten NULLs enthält.
- Vergleiche, wie viele Zeilen in Frage kommen vs. wie viele gefüllt wurden.
- Prüfe stichprobenartig einige IDs und vergleiche alte vs. neue Werte.
- Teste Randfälle (leere Strings, Null, sehr alte Datensätze).
- Führe dieselben Checks später nochmals aus, um Drift auszuschließen.
Wenn du dual-schreibst, füge eine Konsistenzprüfung hinzu, um stille Fehler zu finden. Zum Beispiel eine stündliche Abfrage, die Zeilen findet, in denen old_value \u003c\u003e new_value, und alarmiere, wenn das Resultat nicht Null ist. Das ist oft der schnellste Weg, zu entdecken, dass ein Writer nur das alte Feld aktualisiert.
Beobachte grundlegende Produktionssignale, während die Migration läuft. Wenn Query-Zeiten oder Lock-Waits ansteigen, können selbst deine „sicheren" Verifizierungsabfragen Last hinzufügen. Überwache Fehlerraten für Codepfade, die das neue Feld lesen, besonders direkt nach Deploys.
Wie lange beide Pfade laufen sollten? Länger als ein Release-Zyklus und mindestens solange, bis ein Backfill-Neustart durchgelaufen ist. Viele Teams halten 1–2 Wochen oder bis sie sicher sind, dass keine alte App-Version mehr läuft.
Contract-Phase: den alten Pfad entfernen
Contract ist der Moment, vor dem Teams oft Nervosität haben, weil es sich wie der point of no return anfühlt. Wenn Expand korrekt gemacht wurde, ist Contract größtenteils Aufräumen und lässt sich in kleinen, risikoarmen Schritten durchführen.
Wähle den Zeitpunkt sorgfältig. Lösche nichts sofort nach einem Backfill-Finish. Warte mindestens einen Release-Zyklus, damit verzögerte Jobs und Randfälle sich zeigen können.
Eine sichere Contract-Reihenfolge sieht meist so aus:
- Beende Dual-Write und bestätige, dass neue Writes nur noch in die neuen Spalte(n) gehen.
- Entferne alte Lesewege in der Anwendung, sodass der Fallback wegfällt.
- Lösche toten Code, Feature-Flags und Background-Jobs, die das alte Schema referenzieren.
- Entferne temporäre Trigger, Sync-Jobs oder Kompatibilitäts-Views.
- Drope alte Indizes und Constraints, dann die alte Spalte.
Wenn möglich, teile Contract in zwei Releases: eins, das Code-Referenzen entfernt (mit zusätzlichem Logging), und ein späteres, das Datenbankobjekte löscht. Diese Trennung macht Rollback und Troubleshooting erheblich leichter.
PostgreSQL-spezifika sind hier wichtig. Das Löschen einer Spalte ist meist eine Metadaten-Änderung, kann aber kurzzeitig einen ACCESS EXCLUSIVE-Lock benötigen. Plane ein ruhiges Fenster und halte die Migration kurz. Falls du zusätzliche Indizes erstellt hast, ziehe in Betracht, sie mit DROP INDEX CONCURRENTLY zu entfernen, um Schreibvorgänge nicht zu blockieren (dies kann nicht in einem Transaktionsblock laufen, also muss dein Migrationstool das unterstützen).
Häufige Fehler und Fallen
Backfill in kleinen Batches
Erstelle einen einfachen Backfill-Job und passe Batch-Größen an, ohne das Team zu verlangsamen.
Ausfallfreie Migrationen scheitern, wenn Datenbank und App aufhören, sich einig zu sein, was erlaubt ist. Das Muster funktioniert nur, wenn jeder Zwischenzustand für alten und neuen Code sicher ist.
Fallen, die Produktion brechen
Diese Fehler treten oft auf:
- NOT NULL zu früh setzen, während eine ältere App-Version noch Zeilen ohne neues Feld schreiben kann.
- Einen riesigen Table in einer Transaktion backfillen, was Locks, Table-Bloat und Timeouts verursacht.
- Denken, ein Default sei kostenlos. In PostgreSQL können manche Defaults einen Table-Rewrite auslösen.
- Reads auf die neue Spalte umstellen, bevor Writes sie zuverlässig füllen.
- Andere Writer und Reader vergessen (Cron-Jobs, Worker, Exporte, Reporting-Queries).
Ein realistisches Szenario: Du beginnst, full_name über die API zu setzen, aber ein Hintergrundjob, der Nutzer anlegt, setzt weiterhin nur first_name und last_name. Er läuft nachts, legt Zeilen mit full_name = NULL an, und späterer Code geht davon aus, dass full_name immer vorhanden ist.
Wie du vermeidest, in der Mitte der Migration festzustecken
Behandle jeden Schritt wie ein Release, das Tage laufen kann:
- Halte die neue Spalte während der Transition nullable und erzwinge „erforderlich" zuerst im Code.
- Backfille in kleinen, pausierbaren Batches und überwache die DB-Last.
- Mache den Code tolerant: lese beide Pfade, schreibe beide Pfade bei Bedarf, und handhabe fehlende Werte.
- Prüfe jeden Ort, der die Tabelle berührt, inklusive Worker und Reporting.
Kurze Checkliste vor jedem Release
Eine wiederholbare Checkliste verhindert, dass du Code auslieferst, der nur in einem Datenbankzustand funktioniert.
Vor dem Deploy bestätige, dass die Datenbank bereits die erweiterten Teile hat (neue Spalten/Tabellen, Indizes low-lock angelegt). Dann stelle sicher, dass die App tolerant ist: sie muss mit altem, erweitertem und halb-backfilltem Zustand funktionieren.
Halte die Checkliste kurz:
- Expansion vorhanden: neue Schema-Objekte existieren und wurden low-lock hinzugefügt.
- Kompatibilität echt: die App funktioniert mit altem und erweitertem Schema, inklusive Worker und Admin-Pfade.
- Backfill kontrolliert: kleine Batches, pausierbar, mit Basis-Fortschrittsmetriken.
- Read-Switch geplant: du weißt genau, wann Reads umgestellt werden und wie du rollbackst, falls Ergebnisse falsch aussehen.
- Contract verzögert: warte mindestens ein oder zwei Release-Zyklen, bevor du alte Objekte entfernst.
Eine Migration ist erst dann erledigt, wenn Reads die neuen Daten nutzen, Writes das Alte nicht mehr pflegen und du den Backfill mit mindestens einer einfachen Prüfung (Counts oder Sampling) verifiziert hast.
Ein realistisches Beispiel: eine Spalte ohne Downtime ersetzen
Dual-Write sicher hinzufügen
Baue von Anfang an die Dual-Write- und Fallback-Logik in deine App ein.
Angenommen, du hast eine PostgreSQL-Tabelle customers mit einer Spalte phone, die uneinheitliche Werte speichert. Du willst sie durch phone_e164 ersetzen, kannst aber Releases nicht blockieren oder die App herunterfahren.
Eine saubere Expand/Contract-Abfolge könnte so aussehen:
- Expand:
phone_e164 nullable und ohne Default hinzufügen, noch keine strengen Constraints.
- Kompatibler Deploy: Code aktualisieren, der sowohl
phone als auch phone_e164 schreibt, aber Lesungen weiterhin phone nutzen, damit sich für Nutzer nichts ändert.
- Backfill: bestehende Zeilen in kleinen Batches konvertieren (z. B. 1.000 pro Batch).
- Read-Switch: Code deployen, der zuerst
phone_e164 liest und bei NULL auf phone zurückfällt.
- Contract: Sobald alles
phone_e164 nutzt, den Fallback entfernen, phone löschen und bei Bedarf strengere Constraints hinzufügen.
Rollbacks bleiben einfach, wenn jeder Schritt rückwärtskompatibel ist. Führt der Read-Switch zu Problemen, rollst du die App zurück und die DB hat weiterhin beide Spalten. Verursacht der Backfill Lastspitzen, pausierst du den Job, verringerst die Batch-Größe und setzt später fort.
Wenn das Team auf Kurs bleiben soll, dokumentiere den Plan an einem Ort: das genaue SQL, welches Release die Reads flippt, wie du Fertigstellung misst (z. B. Prozent non-NULL phone_e164) und wer welche Schritte verantwortet.
Nächste Schritte: Wiederholbarkeit schaffen
Expand/Contract funktioniert am besten, wenn es Routine ist. Schreibe ein kurzes Runbook, das dein Team für jede Schema-Änderung wiederverwenden kann — idealerweise eine Seite und spezifisch genug, dass auch ein neues Teammitglied folgen kann.
Eine praktische Vorlage umfasst:
- Expand (exakte Migrationen)
- Code-Änderungen (was rückwärtskompatibel bleiben muss und wo Dual-Read oder Dual-Write eingesetzt wird)
- Backfill (Batch-Größe, Rate-Limits, Pause/Resume)
- Verifizieren (Abfragen und Metriken, die Korrektheit beweisen)
- Contract (was entfernt wird und wann)
Bestimme Verantwortlichkeiten im Voraus. „Jeder dachte, jemand anderes würde Contract machen“ ist der Grund, warum alte Spalten und Feature-Flags monatelang leben.
Auch bei online laufendem Backfill plane ihn während geringerer Last. Dann sind Batches einfacher klein zu halten, DB-Last leichter zu beobachten und ein Stopp rasch möglich.
Wenn du mit Koder.ai (koder.ai) buildest und deployst, kann Planning Mode nützlich sein, um Phasen und Checkpoints zu skizzieren, bevor du Produktion anfasst. Dieselben Kompatibilitätsregeln gelten, aber niedergeschriebene Schritte machen es schwerer, die langweiligen Teile zu überspringen, die Ausfälle verhindern.