27. Sept. 2025·8 Min
Blue/Green- und Canary-Deployments: Eine klare Release-Strategie
Erfahre, wann Blue/Green oder Canary sinnvoll sind, wie Traffic-Shifting funktioniert, welche Metriken du beobachten solltest und praktische Schritte für Rollout und Rollback für sicherere Releases.
Was Blue/Green- und Canary-Deployments bedeuten
Neuen Code auszuliefern ist riskant aus einem einfachen Grund: Du weißt erst wirklich, wie er sich verhält, wenn echte Nutzer ihn treffen. Blue/Green und Canary sind zwei gängige Methoden, dieses Risiko zu reduzieren und gleichzeitig die Ausfallzeit nahezu auf null zu halten.
Blue/Green in einfachen Worten
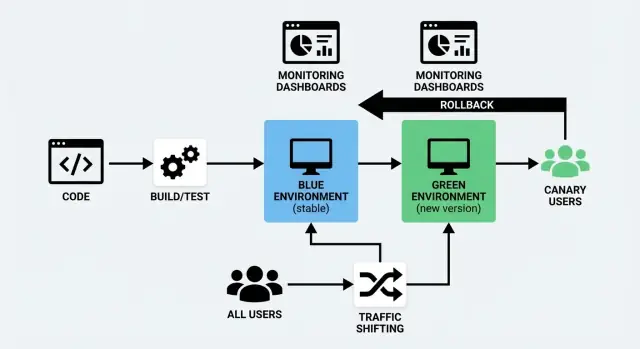
Ein Blue/Green-Deployment nutzt zwei getrennte, aber ähnliche Umgebungen:
- Blue: die Version, die aktuell Nutzer bedient (die „Live“-Umgebung).
- Green: eine zweite, startbereite Umgebung, in die du die neue Version deployst.
Du bereitest die Green-Umgebung im Hintergrund vor — deployst den neuen Build, führst Checks aus, wärmst sie auf — und schaltest den Traffic von Blue auf Green, wenn du dir sicher bist. Wenn etwas schiefgeht, kannst du schnell zurückschalten.
Die Kernidee ist nicht „zwei Farben“, sondern ein sauberer, reversibler Cutover.
Canary in einfachen Worten
Ein Canary-Release ist ein schrittweiser Rollout. Anstatt alle auf einmal zu wechseln, sendest du die neue Version zuerst an einen kleinen Teil der Nutzer (z. B. 1–5%). Wenn alles gesund aussieht, erweiterst du die Verteilung Schritt für Schritt, bis 100% des Traffics auf der neuen Version sind.
Die Kernidee ist aus echtem Traffic zu lernen, bevor du dich vollständig verpflichtest.
Das gemeinsame Ziel: sicherere Releases mit weniger Ausfallzeit
Beide Ansätze sind Bereitstellungsstrategien mit dem Ziel:
- die Nutzerbetroffenheit bei Fehlern zu reduzieren
- ein Zero-Downtime-Deployment zu unterstützen (oder so nah wie dein System es zulässt)
- Rollbacks weniger stressig und besser vorhersehbar zu machen
Sie erreichen das auf unterschiedliche Weise: Blue/Green fokussiert auf einen schnellen Wechsel zwischen Umgebungen, Canary auf kontrollierte Exposition durch Traffic-Shifting.
Keine einzelne „beste“ Option
Keiner der Ansätze ist automatisch überlegen. Die richtige Wahl hängt davon ab, wie dein Produkt genutzt wird, wie sicher du dich in Tests fühlst, wie schnell du Feedback brauchst und welche Arten von Ausfällen du vermeiden willst.
Viele Teams kombinieren beide Ansätze — nutzen Blue/Green für operative Einfachheit und Canary-Techniken für schrittweise Nutzerexposition.
In den folgenden Abschnitten vergleichen wir sie direkt und zeigen, wann welcher Ansatz typischerweise am besten funktioniert.
Blue/Green vs Canary: Kurzer Vergleich
Blue/Green und Canary sind beides Wege, Änderungen auszurollen, ohne Nutzer zu unterbrechen — sie unterscheiden sich jedoch darin, wie der Traffic zur neuen Version bewegt wird.
Wie der Traffic wechselt
Blue/Green betreibt zwei vollständige Umgebungen: „Blue“ (aktuell) und „Green“ (neu). Du verifizierst Green und schaltest dann den gesamten Traffic auf einmal um — wie das Umlegen eines einzelnen, kontrollierten Schalters.
Canary liefert die neue Version zuerst an einen kleinen Teil der Nutzer (z. B. 1–5%) und verschiebt den Traffic dann schrittweise, während du die Performance im Feld beobachtest.
Relevante Vor- und Nachteile
| Faktor | Blue/Green | Canary |
|---|---|---|
| Geschwindigkeit | Sehr schneller Cutover nach Validierung | Von Natur aus langsamer (stufenweiser Rollout) |
| Risiko | Mittel: ein fehlerhaftes Release trifft nach dem Wechsel alle | Niedriger: Probleme zeigen sich oft vor dem Full-Rollout |
| Komplexität | Moderat (zwei Umgebungen, sauberer Wechsel) | Höher (Traffic-Splitting, Analyse, schrittweise Stufen) |
| Kosten | Höher (du hast während des Rollouts effektiv doppelte Kapazität) | Oft niedriger (du kannst mit vorhandener Kapazität rampen) |
| Am besten für | Große, koordinierte Änderungen | Häufige, kleine Verbesserungen |
Eine einfache Entscheidungsrichtlinie
Wähle Blue/Green, wenn du einen sauberen, vorhersehbaren Moment für den Cutover möchtest — besonders bei größeren Änderungen, Migrationen oder Releases, die eine klare Trennung „alt vs neu“ erfordern.
Wähle Canary, wenn du häufig auslieferst, sicher von realer Nutzung lernen willst und den Blast Radius reduzieren möchtest, indem Metriken jeden Schritt steuern.
Wenn du unsicher bist, fang mit Blue/Green für operative Einfachheit an und ergänze Canary für risikoreichere Services, sobald Monitoring und Rollback-Gewohnheiten etabliert sind.
Wann Blue/Green die richtige Wahl ist
Blue/Green eignet sich besonders, wenn Releases sich wie ein „Schalter umlegen“ anfühlen sollen. Du betreibst zwei produktionsähnliche Umgebungen: Blue (aktuell) und Green (neu). Wenn Green verifiziert ist, leitest du die Nutzer dorthin.
Du brauchst nahezu null Ausfallzeit
Wenn dein Produkt keine sichtbaren Wartungsfenster toleriert — Checkout-Flows, Buchungssysteme, eingeloggte Dashboards — hilft Blue/Green, weil die neue Version gestartet, aufgeheizt und geprüft ist, bevor echte Nutzer dorthin geschickt werden. Die meiste „Deploy-Zeit“ passiert nebenbei, nicht vor den Kunden.
Du willst das einfachste Rollback
Rollback ist oft einfach nur das Zurückleiten des Traffics zu Blue. Das ist wertvoll, wenn:
- ein Release innerhalb von Minuten reversibel sein muss
- du Notfall-Hotfixes unter Druck vermeiden willst
- du eine klare, wiederholbare Fehlerreaktion brauchst
Der wesentliche Vorteil: Rollback erfordert oft kein Neubauen oder Re-deployen — es ist ein Traffic-Switch.
Deine Datenbankänderungen können kompatibel gehalten werden
Blue/Green ist am einfachsten, wenn Datenbank-Migrationen rückwärtskompatibel sind, denn für kurze Zeit können Blue und Green gleichzeitig existieren (und je nach Routing/Job-Setup beide lesen/schreiben).
Gute Fälle sind:
- additive Schema-Änderungen (neue nullable Spalten, neue Tabellen)
- Erweiterung von Datenformaten, die alte Logik ignorieren kann
Riskant sind das Entfernen von Spalten, Umbenennen von Feldern oder Bedeutungsänderungen — diese können das „Zurückschalten“-Versprechen brechen, sofern keine mehrstufigen Migrationen geplant sind.
Du kannst doppelte Umgebungen und Routing-Kontrolle leisten
Blue/Green verlangt zusätzliche Kapazität (zwei Stacks) und eine Möglichkeit, Traffic zu steuern (Load Balancer, Ingress oder Plattform-Routing). Wenn du bereits Automatisierung zur Provisionierung von Umgebungen und einen sauberen Routing-Hebel hast, ist Blue/Green ein praktikabler Standard für hochvertrauenswürdige, unaufgeregte Releases.
Wann Canary-Releases sinnvoller sind
Ein Canary-Release ist eine Strategie, bei der du eine Änderung zuerst an einen kleinen Teil echter Nutzer auslieferst, daraus lernst und dann erweiterst. Sie passt, wenn du Risiko reduzieren willst, ohne alles mit einem großen „Alle-auf-einmal“-Release zu verändern.
Du hast viel Traffic — und klare Signale
Canary funktioniert am besten für hoch frequentierte Apps, weil schon 1–5% des Traffics schnell aussagekräftige Daten liefern können. Wenn du bereits klare Metriken verfolgst (Fehlerrate, Latenz, Conversion, Checkout-Abschluss, API-Timeouts), kannst du das Release anhand realer Nutzung validieren statt dich nur auf Testumgebungen zu verlassen.
Du fürchtest Performance- und Edge-Cases
Manche Probleme treten nur unter echtem Load auf: langsame DB-Queries, Cache-Misses, regionale Latenz, ungewöhnliche Geräte oder seltene Nutzerpfade. Mit einem Canary-Release kannst du bestätigen, dass die Änderung Fehler nicht erhöht oder die Performance verschlechtert, bevor alle betroffen sind.
Du brauchst gestaffelte Rollouts, keinen einzigen Cutover
Wenn dein Produkt häufig deployt wird, mehrere Teams beitragen oder Änderungen schrittweise eingeführt werden können (UI-Anpassungen, Preisexperimente, Empfehlungslogik), passen Canary-Rollouts gut. Du kannst von 1% → 10% → 50% → 100% erweitern, abhängig von den Beobachtungen.
Feature Flags sind Teil deiner Werkzeugkiste
Canary passt besonders gut zu Feature Flags: Du kannst Code sicher deployen und dann Funktionalität für eine Nutzergruppe, Region oder Accounts aktivieren. Rollbacks sind weniger dramatisch — oft kannst du einfach das Flag ausschalten statt neu zu deployen.
Wenn du auf Progressive Delivery hinarbeitest, sind Canary-Releases häufig der flexibelste Einstieg.
Siehe auch: /blog/feature-flags-and-progressive-delivery
Traffic-Shifting-Grundlagen (ohne Fachchinesisch)
Traffic-Shifting bedeutet einfach, zu steuern, wer die neue Version deiner App bekommt und wann. Anstatt alle auf einmal umzuschalten, bewegst du Anfragen schrittweise (oder selektiv) von der alten zur neuen Version. Das ist das praktische Herz sowohl eines Blue/Green-Deployments als auch eines Canary-Releases — und es macht ein Zero-Downtime-Deployment realistisch.
Das „Lenkrad“: wo der Traffic geroutet wird
Du kannst Traffic an einigen üblichen Punkten im Stack verschieben. Die richtige Wahl hängt davon ab, was du bereits betreibst und wie fein du steuern musst.
- Load Balancer: teilt eingehende Anfragen zwischen zwei Umgebungen oder Servergruppen auf.
- Ingress-Controller (Kubernetes): routet Traffic zu verschiedenen Services anhand von Regeln.
- Service Mesh: steuert Traffic zwischen Services mit präzisen Regeln und besserer Sichtbarkeit.
- CDN / Edge-Routing: nützlich, wenn Routing-Entscheidungen nah am Nutzer erfolgen sollen, oft für Web-Traffic.
Du brauchst nicht jede Ebene. Wähle eine „Quelle der Wahrheit“ für Routing-Entscheidungen, damit dein Release-Management nicht zur Ratesache wird.
Übliche Arten, Traffic zu teilen
Die meisten Teams nutzen eine (oder eine Mischung) der folgenden Ansätze für Traffic-Shifting:
- Prozentbasiert: 1% → 5% → 25% → 50% → 100%. Das klassische Canary-Muster.
- Header-basiert: Requests mit einem bestimmten Header (z. B. von QA-Tools oder internen Testern) werden zur neuen Version geroutet.
- User-Cohorts: bestimmte Gruppen zuerst — Mitarbeitende, Beta-Nutzer, eine Region oder Kundentier.
Prozentbasiert ist am einfachsten zu erklären, Cohorts sind oft sicherer, weil du kontrollieren kannst, welche Nutzer die Änderung sehen (und so vermeidest, deine wichtigsten Kunden in der ersten Stunde zu überraschen).
Sessions und Caches: die zwei „Fallstricke"
Zwei Dinge sorgen häufig dafür, dass ansonsten solide Deploy-Pläne scheitern:
Sticky Sessions (Session-Affinität). Wenn dein System einen Nutzer an einen Server/eine Version bindet, verhält sich eine 10%-Aufteilung vielleicht nicht wie 10%. Es kann auch zu verwirrenden Bugs führen, wenn Nutzer während einer Sitzung zwischen Versionen hin- und herspringen. Wenn möglich, nutze geteilten Session-Storage oder stelle sicher, dass Routing einen Nutzer konsistent auf einer Version hält.
Cache-Warming. Neue Versionen treffen oft auf kalte Caches (CDN, Anwendungscache, DB-Query-Cache). Das kann wie eine Performance-Regression aussehen, obwohl der Code in Ordnung ist. Plane Zeit zum Aufwärmen der Caches vor dem Hochfahren des Traffics ein, besonders für hochfrequentierte Seiten und teure Endpunkte.
Mach Traffic-Änderungen zu einer kontrollierten Operation
Behandle Routing-Änderungen wie Produktionsänderungen, nicht wie einen zufälligen Button-Klick.
Dokumentiere:
- wer berechtigt ist, Traffic-Splits zu ändern
- wie es genehmigt wird (On-Call? Release-Manager? Change-Ticket?)
- wo es gemacht wird (Load-Balancer-Config, Ingress-Regeln, Mesh-Policy)
- wie ein „Stopp“ aussieht (der Trigger, um das Rollout zu pausieren und den Rollback-Plan zu folgen)
Dieses kleine Maß an Governance verhindert, dass gutmeinende Leute „einfach mal auf 50% schieben“, während du noch prüfst, ob der Canary gesund ist.
Was während eines Rollouts überwacht werden sollte
Sicher deployen
Stelle deine App bereit und hoste sie – mit einfacher Snapshot‑ und Rollback‑Funktion.
Ein Rollout ist nicht nur „ist das Deploy erfolgreich?“ Es ist „bekommen reale Nutzer ein schlechteres Erlebnis?“ Der einfachste Weg, während Blue/Green- oder Canary-Rollouts ruhig zu bleiben, ist das Beobachten einer kleinen Menge von Signalen, die dir sagen: ist das System gesund und schadet die Änderung den Kunden?
Die vier Kernsignale: Fehler, Latenz, Auslastung, Nutzer-Auswirkung
Fehlerrate: Verfolge HTTP-5xx, Request-Failures, Timeouts und Abhängigkeitsfehler (Datenbank, Zahlungen, Drittanbieter-APIs). Ein Canary, das „kleine“ Fehler erhöht, kann trotzdem großen Support-Aufwand erzeugen.
Latenz: Beobachte p50 und p95 (und p99, wenn vorhanden). Eine Änderung, die den Durchschnitt stabil hält, kann trotzdem lange Tail-Verzögerungen schaffen, die Nutzer spüren.
Auslastung: Schau, wie „voll“ dein System ist — CPU, RAM, Disk-IO, DB-Verbindungen, Warteschlangen-Tiefe, Thread-Pools. Sättigungsprobleme zeigen sich oft vor kompletten Ausfällen.
Nutzer-Impact-Signale: Miss, was Nutzer tatsächlich erleben — Checkout-Fehler, Anmeldeerfolg, zurückgegebene Suchergebnisse, App-Absturzrate, Ladezeiten für Schlüsselseiten. Diese sind oft aussagekräftiger als reine Infrastruktur-Stats.
Baue ein „Release-Dashboard“, das jeder lesen kann
Erstelle ein kleines Dashboard, das auf einen Bildschirm passt und im Release-Channel geteilt wird. Halte es konsistent bei jedem Rollout, damit Leute nicht Zeit damit verschwenden, Grafiken zu suchen.
Enthalten sein sollten:
- Fehlerrate (gesamt + Schlüsselendpunkte)
- Latenz (p50/p95 für kritische Pfade)
- Auslastung (Top-3-Engpässe deines Stacks, z. B. App-CPU, DB-Verbindungen, Queue-Tiefe)
- Nutzer-Impact-KPIs (deine 1–3 geschäftskritischen Flows)
Wenn du ein Canary-Release durchführst, segmentiere Metriken nach Version/Instanzgruppe, sodass du Canary vs Baseline direkt vergleichen kannst. Bei Blue/Green vergleiche die neue Umgebung mit der alten während des Cutover-Fensters.
Setze klare Schwellenwerte für Pause-/Rollback-Entscheidungen
Lege die Regeln fest, bevor du Traffic verschiebst. Beispiel-Schwellen könnten sein:
- Fehlerrate steigt um X% gegenüber Baseline für Y Minuten
- p95-Latenz überschreitet einen festen Grenzwert (oder steigt um X% gegenüber Baseline)
- ein Nutzer-Impact-KPI fällt unter einen minimal akzeptablen Wert
Die genauen Zahlen hängen von deinem Service ab, aber wichtig ist die Übereinkunft. Wenn alle den Rollback-Plan und die Trigger kennen, vermeidest du Debatten, während Kunden betroffen sind.
Alerts, die sich auf das Rollout-Fenster fokussieren
Füge Alerts hinzu (oder verschärfe sie temporär) speziell für Rollout-Fenster:
- unerwartete Anstiege von 5xx/Timeouts
- plötzliche Latenzregression auf Schlüsselrouten
- schnelles Wachstum bei Auslastungssignalen (Connection-Pools, Queues)
Halte Alerts handlungsorientiert: „was hat sich geändert, wo und was ist der nächste Schritt.“ Wenn dein Alerting zu laut ist, übersehen Leute das eine Signal, das während des Traffic-Shifts zählt.
Pre-Release-Checks, die Probleme früh abfangen
Die meisten Rollout-Fehler entstehen nicht durch „große Bugs“, sondern durch kleine Diskrepanzen: ein fehlender Konfig-Wert, eine fehlerhafte DB-Migration, ein abgelaufenes Zertifikat oder eine Integration, die sich in der neuen Umgebung anders verhält. Pre-Release-Checks sind deine Chance, diese Probleme zu finden, solange der Blast Radius noch klein ist.
Fang mit Health-Checks und Smoke-Tests an
Bevor du Traffic verschiebst (egal ob Blue/Green-Switch oder kleiner Canary-Prozentsatz), bestätige, dass die neue Version grundsätzlich lebt und Anfragen bedienen kann.
- Stelle sicher, dass Health-Endpunkte OK melden (nicht nur „Prozess läuft“)
- Validere Abhängigkeiten: Datenbank, Cache, Queue, Object Storage, E-Mail/SMS-Provider
- Bestätige, dass Secrets und Environment-Variablen vorhanden und korrekt scoped sind
Führe schnelle End-to-End-Tests gegen die neue Umgebung aus
Unit-Tests sind großartig, aber sie beweisen nicht, dass das deployte System funktioniert. Führe eine kurze, automatisierte End-to-End-Suite gegen die neue Umgebung aus, die in Minuten, nicht Stunden, fertig ist.
Konzentriere dich auf Flows, die Service-Grenzen überschreiten (Web → API → DB → Drittanbieter), und schließe mindestens eine „echte“ Anfrage pro Schlüsselintegration ein.
Verifiziere kritische Nutzer-Journeys (die, die Umsatz bringen)
Automatisierte Tests übersehen manchmal das Offensichtliche. Mach eine gezielte, menschenlesbare Überprüfung deiner Kern-Workflows:
- Login und Passwort-Zurücksetzen
- Checkout- oder Zahlungsfluss (inkl. Fehlerpfade)
- zentrale Create/Update/Delete-Aktionen, die Nutzer täglich durchführen
Wenn du mehrere Rollen unterstützt (Admin vs Kunde), teste mindestens einen Journey pro Rolle.
Halte eine Pre-Release-Readiness-Checkliste bereit
Eine Checkliste macht Tribal Knowledge zu einer wiederholbaren Deployment-Strategie. Halte sie kurz und handhabbar:
- DB-Migrationen angewendet und reversibel (oder eindeutig sicher)
- Observability bereit: Logs, Dashboards, Alerts für Schlüsselmetriken
- Rollback-Plan geprüft (wer, wie und wie sieht „Stopp“ aus)
Wenn diese Checks Routine sind, wird Traffic-Shifting zu einem kontrollierten Schritt — nicht zu einem Sprung ins Ungewisse.
Blue/Green-Rollout: Ein praktisches Playbook
Setze Canary‑Ideen mobil um
Erstelle eine Flutter‑Mobile‑App und iteriere sicher beim Ausrollen von Änderungen.
Ein Blue/Green-Rollout ist am einfachsten, wenn du ihn als Checkliste behandelst: vorbereiten, deployen, validieren, umschalten, beobachten und aufräumen.
1) Auf Green deployen (ohne Nutzer zu berühren)
Shippe die neue Version in die Green-Umgebung, während Blue weiterhin echten Traffic bedient. Halte Konfigurationen und Secrets synchron, sodass Green ein echtes Spiegelbild ist.
2) Green verifizieren, bevor Traffic gewechselt wird
Führe schnelle, signalstarke Checks durch: App startet sauber, Schlüsselseiten laden, Zahlungen/Login funktionieren, und Logs sehen normal aus. Wenn du automatisierte Smoke-Tests hast, führe sie jetzt aus. Das ist auch der Moment, Monitoring-Dashboards und Alerts für Green zu prüfen.
3) DB-Migrationen sicher planen (Expand/Contract)
Blue/Green wird knifflig, wenn die Datenbank geändert wird. Nutze einen Expand/Contract-Ansatz:
- Expand: neue Spalten/Tabellen hinzufügen, rückwärtskompatibel
- Deploy Green so, dass es sowohl mit altem als auch neuem Schema arbeiten kann
- Contract: entferne alte Felder erst, wenn Blue stillgelegt ist und du dir der neuen Version sicher bist
So vermeidest du Situationen, in denen Green funktioniert, Blue aber beim Zurückschalten bricht.
4) Caches aufwärmen und Background-Jobs handhaben
Wärme kritische Caches (Startseite, häufige Queries) auf, bevor du den Traffic schaltest, damit Nutzer nicht den „Cold Start“-Preis zahlen.
Für Background-Jobs/Cron entscheide, wer sie ausführt:
- führe Jobs während des Cutovers nur in einer Umgebung aus, um Doppelverarbeitung zu vermeiden
5) Traffic umschalten und beobachten
Schalte das Routing von Blue auf Green (Load Balancer/DNS/Ingress). Beobachte Fehlerrate, Latenz und Geschäftsmetriken für ein kurzes Fenster.
6) Post-Switch-Validierung und Aufräumen
Mache eine Spot-Check mit echten Nutzer-Szenarien und halte Blue kurz als Fallback verfügbar. Wenn stabil, deaktiviere Blue-Jobs, archiviere Logs und deprovisioniere Blue, um Kosten und Verwirrung zu reduzieren.
Canary-Rollout: Ein praktisches Playbook
Ein Canary-Rollout geht ums sichere Lernen. Anstatt allen Nutzern die neue Version zu geben, exponierst du eine kleine Schnittmenge des echten Traffics, beobachtest genau und erweiterst erst dann. Das Ziel ist nicht „langsam gehen“ — es ist, jeden Schritt mit Belegen zu untermauern.
Ein einfacher Ramp-Plan (1–5% → 25% → 50% → 100%)
- Canary vorbereiten
Deploy die neue Version neben der stabilen Version. Stelle sicher, dass du einen definierten Prozentsatz des Traffics routen kannst und dass beide Versionen im Monitoring sichtbar sind (separate Dashboards oder Tags sind hilfreich).
- Stufe 1: 1–5%
Starte winzig. Hier zeigen sich offensichtliche Probleme schnell: gebrochene Endpunkte, fehlende Konfigurationen, DB-Migrations-Überraschungen oder unerwartete Latenzspitzen.
Halte Notizen für die Stufe:
- was sich in diesem Release geändert hat (inkl. „kleiner“ Config-Änderungen)
- was du erwartet hast
- was du beobachtet hast (Fehler, Latenz, Nutzer-impact)
- Stufe 2: 25%
Wenn die erste Stufe sauber ist, erhöhe auf etwa ein Viertel des Traffics. Du siehst jetzt mehr Real-World-Variation: unterschiedliches Nutzerverhalten, Long-Tail-Geräte, Edge-Cases und höhere Konkurrenz.
- Stufe 3: 50%
Halber Traffic bringt Kapazitäts- und Performance-Themen deutlicher zum Vorschein. Wenn du an eine Skalierungsgrenze stoßen wirst, sieht man früh hier erste Warnsignale.
- Stufe 4: 100% (Promotion)
Wenn Metriken stabil sind und der Nutzer-Impact akzeptabel, wechsle den gesamten Traffic auf die neue Version und erkläre sie zum Standard.
Ramp-Intervalle wählen (wie lange in jeder Stufe warten)
Die Dauer hängt von Risiko und Traffic-Volumen ab:
- Hochrisiko-Änderung oder niedriger Traffic: länger in jeder Stufe warten, um genug Signal zu bekommen (z. B. 30–60 Minuten oder länger). Niedrig-traffic-Services brauchen ggf. Stunden, um Muster zu erkennen.
- Niedrigrisiko-Änderung mit hohem Traffic: kürzere Stufen (z. B. 5–15 Minuten) funktionieren, weil du schnell Daten sammelst.
Berücksichtige außerdem Geschäftsspitzen. Wenn dein Produkt Spitzen hat (Mittagszeit, Wochenenden, Abrechnungsläufe), lass den Canary lang genug laufen, um Bedingungen abzudecken, die typischerweise Probleme verursachen.
Promotion und Rollback automatisieren
Manuelle Rollouts erzeugen Zögern und Inkonsistenz. Automatisiere wenn möglich:
- Promotion, wenn Schlüsselmesswerte innerhalb von Schwellen für ein definiertes Fenster bleiben
- Rollback, wenn Schwellen verletzt werden (z. B. Fehlerrate oder Latenz überschreitet Limits)
Automatisierung ersetzt kein menschliches Urteilsvermögen — sie entfernt Verzögerungen.
Jede Stufe wie ein Experiment behandeln
Für jeden Ramp-Schritt notiere:
- Änderungszusammenfassung (was genau anders ist)
- Erfolgskriterien (welche Metriken stabil bleiben müssen)
- Beobachtete Ergebnisse (was du gesehen hast, auch „nichts Ungewöhnliches")
- Entscheidung (promoten, halten oder rollbacken) und warum
Diese Notizen machen deine Rollout-Historie zur Basis für das nächste Release und erleichtern künftige Incident-Analysen.
Rollback-Pläne und Fehlerbehandlung
Rollbacks sind am einfachsten, wenn du im Voraus entscheidest, was „schlecht“ bedeutet und wer berechtigt ist, den Button zu drücken. Ein Rollback-Plan ist keine pessimistische Haltung — er verhindert, dass kleine Probleme zu langen Ausfällen werden.
Klare Rollback-Trigger definieren
Wähle eine kurze Liste an Signalen und setze explizite Schwellen, damit du nicht während eines Incidents diskutierst. Gängige Trigger sind:
- Fehlerrate: Anstiege von 5xx, fehlgeschlagene Checkouts, Login-Fehler oder API-Timeouts
- Latenz: p95/p99-Latenz über einem vereinbarten Limit über ein anhaltendes Fenster (z. B. 5–10 Minuten)
- Business-KPIs: plötzliche Einbrüche bei Conversion, Zahlungserfolgen, Anmeldungen oder Anstiege bei Kündigungen
Mache den Trigger messbar („p95 > 800ms für 10 Minuten") und verknüpfe ihn mit einem Owner (On-Call, Release-Manager), der befugt ist, sofort zu handeln.
Rollback schnell (und unspektakulär) halten
Geschwindigkeit ist wichtiger als Eleganz. Dein Rollback sollte eine der folgenden Optionen sein:
- Traffic-Shift zurücksetzen (typisch für Blue/Green und Canary): leite den Traffic zurück zur vorher bekannten, guten Version
- Die vorherige Version redeployen: falls sich die Infrastruktur geändert hat, pushe den letzten stabilen Build und führe Health-Checks erneut aus
Vermeide „manuell fixen und Rollout fortsetzen“ als ersten Schritt. Stabilisiere zuerst, untersuche danach.
Plane für partielle Rollouts
Bei Canary-Releases haben einige Nutzer vielleicht Daten mit der neuen Version erzeugt. Entscheide vorher:
- Werden „Canary“-Nutzer sofort zurückgeroutet oder auf der Canary gehalten, während du prüfst?
- Wenn Datenformate geändert wurden, ist die DB rückwärtskompatibel? Falls nicht, erfordert ein Rollback eine eigene Maßnahme.
After-Action-Review, das das nächste Release verbessert
Wenn alles stabil ist, schreibe eine kurze Nachbesprechung: was den Rollback ausgelöst hat, welche Signale gefehlt haben und was du an der Checkliste ändern wirst. Betrachte es als Produktverbesserungszyklus für deinen Release-Prozess, nicht als Schuldzuweisung.
Feature Flags und Progressive Delivery
Plane den Rollout zuerst
Lege Schritte, Prüfungen und Rollback‑Trigger fest, bevor Traffic auf eine neue Version geleitet wird.
Feature Flags trennen „Deploy“ (Code in Produktion bringen) von „Release“ (Funktion für Nutzer aktivieren). Das ist wichtig, weil du dieselbe Deployment-Pipeline — Blue/Green oder Canary — nutzen kannst, während du die Exposition per Schalter kontrollierst.
Deploy ohne Druck, Release mit Absicht
Mit Flags kannst du mergen und deployen, auch wenn ein Feature noch nicht für alle bereit ist. Der Code ist da, aber inaktiv. Wenn du dir sicher bist, aktivierst du das Flag schrittweise — oft schneller als ein neuer Build — und bei Problemen kannst du es ebenso schnell deaktivieren.
Zielgerichtete Aktivierung (nicht alles-oder-nichts)
Progressive Delivery bedeutet, den Zugriff deliberate zu erhöhen. Ein Flag kann aktiviert werden für:
- eine bestimmte Nutzergruppe (internes Personal, Beta-Nutzer, bezahlte Tiers)
- eine Region (beginne in einem Land oder Rechenzentrum)
- einen Prozentsatz der Nutzer (1% → 10% → 50% → 100%)
Das ist besonders nützlich, wenn ein Canary zeigt, dass die neue Version gesund ist, du aber das Feature-Risiko separat steuern willst.
Leitplanken, die „Flag-Debt" verhindern
Feature Flags sind mächtig, aber nur mit Governance nützlich. Einige Regeln halten sie ordentlich:
- Ownership: jedes Flag hat ein verantwortliches Team oder eine Person
- Ablauf: setze ein Entfernungs- oder Überprüfungsdatum, damit alte Flags nicht liegen bleiben
- Dokumentation: beschreibe, was das Flag tut, wen es betrifft und wie es zurückgesetzt wird
Eine praktische Regel: Wenn niemand klar beantworten kann „was passiert, wenn wir das ausschalten?", ist das Flag nicht bereit.
Für tiefere Anleitung zur Nutzung von Flags als Teil einer Release-Strategie, siehe /blog/feature-flags-release-strategy.
Wie du deine Strategie auswählst und loslegst
Die Wahl zwischen Blue/Green und Canary ist keine Frage von „welches ist besser“. Es geht darum, welches Risiko du kontrollieren willst und was du realistisch mit deinem Team und Tooling betreiben kannst.
Eine schnelle Entscheidungsregel
Wenn dein Hauptziel ein sauberer, vorhersehbarer Cutover und eine einfache „Zurück-zur-alten-Version“-Taste ist, ist Blue/Green meist die einfachste Wahl.
Wenn dein Hauptziel ist, den Blast Radius zu reduzieren und vor der breiten Verteilung aus echtem Nutzertraffic zu lernen, ist Canary die sicherere Option — besonders wenn Änderungen häufig sind oder schwer vollständig vorab zu testen.
Eine praktische Regel: Wähle den Ansatz, den dein Team konsistent um 2 Uhr morgens betreiben kann, wenn etwas schiefgeht.
Klein anfangen: pilotiere eine Sache
Wähle einen Service (oder einen Nutzer-Flow) und führe ein Pilotprojekt über einige Releases durch. Nimm etwas, das wichtig, aber nicht so kritisch ist, dass alle zögern. Ziel ist, Routine für Traffic-Shifting, Monitoring und Rollback aufzubauen.
Schreibe ein einfaches Runbook (und weise Verantwortlichkeiten zu)
Kurz ist gut — eine Seite reicht oft:
- wie „gut“ aussieht (Schlüsselmetriken und Schwellen)
- wer während eines Rollouts verantwortlich ist
- wie pausiert, zurückgesetzt und kommuniziert wird
Klare Zuständigkeiten sind notwendig. Eine Strategie ohne Owner bleibt oft nur ein Vorschlag.
Nutze vorhandene Tools zuerst
Bevor du neue Plattformen einführst, prüfe die Tools, auf die du bereits vertraust: Load-Balancer-Einstellungen, Deployment-Skripte, bestehendes Monitoring und euren Incident-Prozess. Ergänze neues Tooling erst, wenn es echte Reibung aus dem Pilot nimmt.
Wenn du schnell neue Services baust und auslieferst, können Plattformen, die App-Generierung mit Deploy-Kontrollen kombinieren, den Betrieb erleichtern. Zum Beispiel ist Koder.ai eine Vibe-Coding-Plattform, die Teams erlaubt, Web-, Backend- und Mobile-Apps aus einem Chat-Interface zu erstellen — und sie dann mit praktischen Sicherheitsfunktionen wie Snapshots und Rollback, Unterstützung für Custom Domains und Source-Code-Export zu deployen und zu hosten. Solche Fähigkeiten passen gut zum Kernziel dieses Artikels: Releases wiederholbar, beobachtbar und reversibel machen.
Vorgeschlagene nächste Schritte
Wenn du Implementierungsoptionen und unterstützte Workflows sehen willst, prüfe /pricing und /docs/deployments. Plane dann dein erstes Pilot-Release, halte fest, was funktioniert hat, und iteriere dein Runbook nach jedem Rollout.