Warum Kubernetes den Alltag im Betrieb veränderte
Kubernetes brachte nicht nur ein neues Werkzeug—es veränderte, wie „täglicher Betrieb“ aussieht, wenn man Dutzende (oder Hunderte) von Services betreibt. Vor Orchestrierung setzten Teams oft Skripte, manuelle Runbooks und implizites Wissen zusammen, um immer wiederkehrende Fragen zu beantworten: Wo soll dieser Service laufen? Wie rollen wir eine Änderung sicher aus? Was passiert, wenn ein Node um 2 Uhr morgens ausfällt?
Was „Orchestrierung“ eigentlich löst
Im Kern ist Orchestrierung die Koordinationsschicht zwischen deiner Absicht („führe diesen Service so aus“) und der unordentlichen Realität von Maschinen, die ausfallen, Traffic-Verschiebungen und kontinuierlichen Deployments. Anstatt jeden Server als Einzelstück zu behandeln, betrachtet Orchestrierung Compute als Pool und Workloads als planbare Einheiten, die sich bewegen können.
Kubernetes popularisierte ein Modell, in dem Teams beschreiben, was sie wollen, und das System fortlaufend daran arbeitet, die Realität dieser Beschreibung anzupassen. Dieser Wandel ist wichtig, weil Betrieb weniger von Heldentaten und mehr von wiederholbaren Prozessen abhängt.
Drei Ergebnisse, die Teams sofort spürten
Kubernetes standardisierte operative Ergebnisse, die die meisten Service-Teams brauchen:
- Bereitstellung: ein konsistenter Weg, zu deklarieren, was laufen soll, es zu aktualisieren und auf seine Gesundheit zu überprüfen.
- Skalierung: ein praktischer Pfad von einer Instanz zu vielen, ohne die Anwendung neu zu entwerfen oder Maschinen manuell bereitzustellen.
- Service-Betrieb: stabile Wege, damit Services einander finden, Traffic routen und bei wechselnden Instanzen weiterlaufen.
Ein Hinweis zu Umfang und Quellen
Dieser Artikel konzentriert sich auf die Ideen und Muster, die mit Kubernetes (und Führungspersonen wie Brendan Burns) verbunden sind, nicht auf eine persönliche Biographie. Wenn wir darüber sprechen, „wie es begann“ oder „warum es so entworfen wurde“, sollten diese Aussagen auf öffentlichen Quellen beruhen—Konferenzvorträgen, Design-Dokumenten und Upstream-Dokumentation—damit die Geschichte überprüfbar bleibt und keine Mythenbildung entsteht.
Brendan Burns in der Kubernetes-Entstehungsgeschichte (Überblick)
Brendan Burns wird weithin als einer der drei ursprünglichen Mitbegründer von Kubernetes anerkannt, neben Joe Beda und Craig McLuckie. In der frühen Kubernetes-Arbeit bei Google half Burns, sowohl die technische Ausrichtung als auch die Art und Weise zu formen, wie das Projekt gegenüber Nutzern erklärt wurde—insbesondere mit Blick auf „wie man Software betreibt“ statt nur „wie man Container ausführt“. (Quellen: Kubernetes: Up & Running, O’Reilly; Kubernetes-Projekt-Repository AUTHORS/Maintainers-Auflistungen)
Open-Source-Zusammenarbeit prägte das Design
Kubernetes wurde nicht einfach als fertiges internes System „veröffentlicht“; es wurde öffentlich mit einer wachsenden Anzahl von Mitwirkenden, Anwendungsfällen und Randbedingungen aufgebaut. Diese Offenheit drängte das Projekt zu Schnittstellen, die in verschiedenen Umgebungen bestehen können:
- klare, versionierte APIs statt versteckter Implementierungsdetails
- portierbares Verhalten über Cloud-Anbieter und On-Prem-Setups hinweg
- Erweiterungspunkte, damit der Kern relativ klein bleiben kann, während viele Bedürfnisse unterstützt werden
Dieser kollaborative Druck ist wichtig, weil er beeinflusste, worauf Kubernetes optimierte: gemeinsame Primitive und wiederholbare Muster, denen viele Teams zustimmen konnten, selbst wenn sie sich bei Werkzeugen unterschieden.
Was „standardisiert“ hier wirklich bedeutet
Wenn Leute sagen, Kubernetes habe Bereitstellung und Betrieb „standardisiert“, meinen sie normalerweise nicht, dass es jedes System identisch machte. Sie meinen, es stellte ein gemeinsames Vokabular und eine Reihe von Workflows bereit, die sich zwischen Teams wiederholen lassen:
- „Deployment“, „Service“, „Ingress“, „Job“, „Namespace“ als gemeinsame Begriffe
- ein konsistentes Modell, um zu deklarieren, was man will (und das System arbeiten zu lassen, um es zu erreichen)
- vorhersehbare Wege, Änderungen auszurollen, zu skalieren und sich von Fehlern zu erholen
Dieses gemeinsame Modell machte es leichter, Dokumentation, Tools und Teampraktiken von einer Firma zur nächsten zu übertragen.
Das Projekt Kubernetes vs. das Ökosystem
Es ist hilfreich, Kubernetes (das Open-Source-Projekt) vom Kubernetes-Ökosystem zu unterscheiden.
Das Projekt ist die Kern-API und die Kontrollbereichskomponenten, die die Plattform implementieren. Das Ökosystem ist alles, was darum gewachsen ist—Distributionen, Managed-Services, Add‑ons und angrenzende CNCF-Projekte. Viele reale „Kubernetes-Funktionen“, auf die Leute bauen (Observability-Stacks, Policy-Engines, GitOps-Tools), leben im Ökosystem, nicht im Kernprojekt selbst.
Die Kernidee: Deklarierter Sollzustand
Deklarative Konfiguration ist ein einfacher Wechsel in der Art, wie man Systeme beschreibt: anstatt die auszuführenden Schritte aufzulisten, gibst du an, welches Endergebnis du möchtest.
In Kubernetes-Sprache sagst du nicht „starte einen Container, öffne dann einen Port, starte ihn neu, wenn er abstürzt.“ Du deklarierst „es sollen drei Kopien dieser App laufen, erreichbar auf diesem Port, mit diesem Container-Image.“ Kubernetes übernimmt die Verantwortung, die Realität mit dieser Beschreibung in Einklang zu bringen.
Sollzustand vs. imperative Skripte
Imperative Operationen sind wie ein Runbook: eine Folge von Befehlen, die beim letzten Mal funktioniert haben und erneut ausgeführt werden, wenn sich etwas ändert.
Der deklarierte Sollzustand ist eher ein Vertrag. Du hältst das beabsichtigte Ergebnis in einer Konfigurationsdatei fest, und das System arbeitet kontinuierlich daran, dieses Ergebnis zu erreichen. Wenn sich etwas entfernt—eine Instanz stirbt, ein Node verschwindet, eine manuelle Änderung eingeschmuggelt wird—erkennt die Plattform die Abweichung und korrigiert sie.
Vorher/Nachher: Runbook-Befehle vs. YAML
Vorher (imperatives Runbook-Denken):
- SSH auf einen Server
- ziehe das neue Container-Image
- stoppe den alten Prozess
- starte den neuen Prozess
- aktualisiere eine Load-Balancer-Regel
- wenn der Traffic steigt, wiederhole das auf weiteren Servern
Dieser Ansatz funktioniert, aber es ist einfach, „Schneeflocken“-Server zu erzeugen und eine lange Checkliste zu hinterlassen, der nur wenige vertrauen.
Danach (deklarierter Sollzustand):
apiVersion: apps/v1
kind: Deployment
metadata:
name: checkout
spec:
replicas: 3
selector:
matchLabels:
app: checkout
template:
metadata:
labels:
app: checkout
spec:
containers:
- name: app
image: example/checkout:1.2.3
ports:
- containerPort: 8080
Du änderst die Datei (z. B. image oder replicas), wendest sie an, und die Kubernetes-Controller arbeiten daran, das Ausgeführte mit dem Deklarierten in Einklang zu bringen.
Warum das Aufwand und Drift reduziert
Deklarativer Sollzustand senkt den betrieblichen Aufwand, indem er „mache diese 17 Schritte“ in „halte es so“ verwandelt. Er reduziert auch Konfigurationsdrift, weil die Quelle der Wahrheit explizit und überprüfbar ist—oft in der Versionskontrolle—so dass Überraschungen leichter zu erkennen, zu prüfen und konsistent zurückzusetzen sind.
Controller und Reconciliation: Das System, das Dinge am Laufen hält
Kubernetes wirkt „selbstverwaltend“, weil es um ein einfaches Muster herum aufgebaut ist: du beschreibst, was du willst, und das System arbeitet kontinuierlich daran, die Realität an diese Beschreibung anzupassen. Der Motor dieses Musters ist der Controller.
Was ein Controller ist (einfach erklärt)
Ein Controller ist eine Schleife, die den aktuellen Zustand des Clusters beobachtet und ihn mit dem in YAML (oder über eine API) deklarierten Sollzustand vergleicht. Wenn er eine Lücke erkennt, ergreift er Maßnahmen, um diese Lücke zu schließen.
Er ist kein einmaliges Skript und wartet nicht auf einen Menschen, der einen Knopf drückt. Er läuft wiederholt—beobachten, entscheiden, handeln—und kann so jederzeit auf Änderungen reagieren.
Reconciliation: wie Kubernetes „Dinge wahr hält"
Dieses wiederholte Vergleichen-und-Korrigieren-Verhalten heißt Reconciliation. Es ist der Mechanismus hinter dem Versprechen „self-healing“. Das System verhindert Ausfälle nicht magisch; es erkennt Drift und korrigiert sie.
Drift kann aus banalen Gründen auftreten:
- ein Prozess stürzt ab
- ein Node verschwindet
- jemand skaliert etwas hoch oder runter
- ein Deployment wird aktualisiert
Reconciliation bedeutet, dass Kubernetes diese Ereignisse als Signale sieht, um deine Absicht erneut zu prüfen und sie wiederherzustellen.
Die Ergebnisse, die Menschen wirklich interessieren
Controller führen zu vertrauten operativen Ergebnissen:
- Ersetze ausgefallene Pods: stirbt ein Pod, bemerkt ein Controller, dass du ihn noch willst, und plant einen neuen.
- Halte Replikazahlen konstant: wenn du 5 Replikate angefordert hast und nur 4 laufen, versucht Kubernetes, das fehlende zu erzeugen.
- Erhalte Rollout-Fortschritt: während Updates treibt der Controller das System zur neuen Version, ohne die gewünschte Verfügbarkeit übermäßig zu gefährden.
Der Kern ist: Du rennst nicht manuell Symptomen hinterher. Du deklarierst das Ziel, und die Kontrollschleifen leisten die kontinuierliche Arbeit des „am Laufen Haltens“.
Warum das über eine einzelne Funktion hinaus skaliert
Dieses Vorgehen beschränkt sich nicht auf einen Ressourcentyp. Kubernetes nutzt dasselbe Controller‑und‑Reconciliation‑Prinzip über viele Objekte hinweg—Deployments, ReplicaSets, Jobs, Nodes, Endpoints und mehr. Diese Konsistenz ist ein großer Grund, warum Kubernetes zur Plattform wurde: sobald man das Muster verstanden hat, kann man vorhersagen, wie sich das System verhält, wenn man neue Fähigkeiten hinzufügt (inklusive Custom Resources, die derselben Schleife folgen).
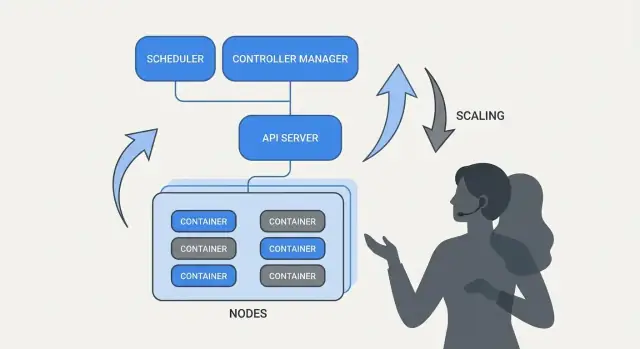
Scheduling als Produktfunktion, nicht als manuelle Aufgabe
Plane zuerst den Rollout
Nutze den Planungsmodus, um Services, APIs und Rollouts zu planen, bevor du Code änderst.
Wenn Kubernetes nur Container „ausführen“ würde, bliebe die schwerste Frage bestehen: wo sollte jede Arbeitslast laufen. Scheduling ist das eingebaute System, das Pods automatisch auf die richtigen Nodes platziert, basierend auf Ressourcenbedarf und von dir definierten Regeln.
Das ist wichtig, weil Platzierungsentscheidungen direkt Verfügbarkeit und Kosten beeinflussen. Eine Web-API auf einem überlasteten Node kann langsam werden oder abstürzen. Ein Batch-Job neben latenzsensitiven Diensten kann noisy-neighbor-Probleme verursachen. Kubernetes macht dies zu einer wiederholbaren Produktfunktion anstelle einer Spreadsheet‑und‑SSH‑Routine.
Wofür der Scheduler optimiert
Grundsätzlich sucht der Scheduler nach Nodes, die die Anforderungen deines Pods erfüllen können.
- CPU/Memory-Requests: Requests reservieren Kapazität für Platzierungsentscheidungen. Wenn du 500m CPU und 1Gi Memory anforderst, betrachtet Kubernetes nur Nodes mit ausreichender verfügbarer Kapazität.
Diese eine Gewohnheit—realistische Requests setzen—verringert oft zufällige Instabilität, weil kritische Dienste nicht mehr mit allem konkurrieren.
Gängige Constraints, die Teams tatsächlich einsetzen
Über Ressourcen hinaus verlassen sich die meisten Produktions-Cluster auf ein paar praktische Regeln:
- Affinity / Anti-Affinity: „Platziere diese zusammen“ (für Caching‑Lokalität) oder „halte diese auseinander“ (um zu vermeiden, dass ein Node-Ausfall alle Replikate trifft).
- Taints und Tolerations: markiere bestimmte Nodes als Spezialzweck (GPU‑Nodes, System‑Nodes, Compliance‑Nodes) und erlaube nur freigegebenen Workloads, dort zu landen.
Wie das Ausfälle reduziert
Scheduling‑Funktionen helfen Teams, operative Absicht zu kodifizieren:
- Replikate über Nodes verteilen, um Node-Ausfälle zu überstehen.
- „Spiky“ Jobs von kundenorientierten Services isolieren.
- teure Nodes (z. B. GPU) davor schützen, von falschen Workloads verdrängt zu werden.
Die praktische Kernbotschaft: behandle Scheduling‑Regeln wie Produktanforderungen—schreibe sie auf, prüfe sie und wende sie konsistent an—damit Zuverlässigkeit nicht davon abhängt, dass sich um 2 Uhr morgens jemand erinnert, welcher Node „der richtige“ ist.
Skalierung: Von einer Instanz zu Tausenden ohne Neuimplementierung
Eine der praktischsten Ideen von Kubernetes ist, dass Skalierung nicht erfordern sollte, deine Anwendung zu ändern oder einen neuen Bereitstellungsansatz zu erfinden. Wenn die App als ein Container laufen kann, kann dieselbe Workload-Definition üblicherweise zu hunderten oder tausenden Kopien wachsen.
Skalierung hat zwei Ebenen
Kubernetes trennt Skalierung in zwei verwandte Entscheidungen:
- Wie viele Pods laufen sollen (mehr Kopien deiner App für höheren Durchsatz oder Redundanz).
- Wie viel Cluster-Kapazität du hast (genug Nodes—und die richtige Größe der Nodes—um diese Pods zu platzieren).
Diese Trennung ist wichtig: du kannst 200 Pods anfordern, aber wenn der Cluster nur Platz für 50 hat, wird „Skalierung“ zu einer Warteschlange von Pending-Pods.
Autoscaling, konzeptionell (HPA, VPA, Cluster Autoscaler)
Kubernetes verwendet üblicherweise drei Autoscaler, die jeweils auf einem anderen Hebel arbeiten:
- Horizontal Pod Autoscaler (HPA): ändert die Anzahl der Pods basierend auf Signalen wie CPU‑Nutzung, Memory oder benutzerdefinierten Anwendungsmetriken.
- Vertical Pod Autoscaler (VPA): passt Pod-Resource-Requests/Limits an, sodass jeder Pod mehr (oder weniger) CPU/Memory erhält.
- Cluster Autoscaler: fügt Nodes hinzu oder entfernt sie, damit der Scheduler Platz hat, die angeforderten Pods zu platzieren.
Zusammen verwandeln sie Skalierung in Politik: „halte Latenz stabil“ oder „halte CPU bei ~X%“, anstatt in ein manuelles Paging‑Ritual.
Wovon „gute Skalierung" abhängt
Skalierung funktioniert nur so gut wie die Eingaben:
- Metriken: CPU ist einfach, aber nicht immer aussagekräftig; Request‑Rate, Queue‑Tiefe und Latenz passen oft besser zum realen Load.
- Resource Requests/Limits: sie sagen dem Scheduler, was ein Pod braucht. Ohne sie wird Platzierung und Autoscaling zum Ratespiel.
- Lastmuster: sprunghafte Traffic‑Anstiege, langsame Warm‑ups und schwere Hintergrundjobs verändern, wie schnell Skalierung reagieren sollte.
Übliche Fallstricke
Zwei Fehler treten immer wieder auf: Skalierung auf die falsche Metrik (CPU bleibt niedrig, während Requests timeouts bekommen) und fehlende Resource-Requests (Autoscaler kann Kapazität nicht vorhersagen, Pods werden zu dicht gepackt und Leistung wird inkonsistent).
Sichere Deployments: Rollouts, Health Checks und Rollbacks
Eine große Veränderung, die Kubernetes verbreitete, ist, Deployments als ein fortlaufendes Steuerungsproblem zu behandeln, nicht als ein einmaliges Skript, das man am Freitag um 17 Uhr ausführt. Rollouts und Rollbacks sind erstklassige Verhaltensweisen: du deklarierst, welche Version du willst, und Kubernetes bewegt das System dahin, während es kontinuierlich prüft, ob die Änderung wirklich sicher ist.
Rollouts als kontrollierter Übergang
Mit einem Deployment ist ein Rollout ein schrittweiser Ersatz alter Pods durch neue. Anstatt alles zu stoppen und neu zu starten, kann Kubernetes in Schritten aktualisieren—die Kapazität verfügbar halten, während die neue Version im echten Traffic bewiesen wird.
Wenn die neue Version zu fehlern beginnt, ist Rollback keine Notfallaktion. Es ist ein normaler Vorgang: du kannst auf ein vorheriges ReplicaSet (die letzte bekannte gute Version) zurücksetzen und den Controller das alte Verhalten wiederherstellen lassen.
Probes: verhindern, dass Releases „laufend, aber fehlerhaft" sind
Health Checks verwandeln Rollouts von Hoffnung in messbare Vorgänge.
- Readiness-Probes bestimmen, ob ein Pod Traffic erhalten soll. Ein Container kann laufen, aber noch nicht bereit sein (Caches werden aufgebaut, Abhängigkeiten werden geladen). Readiness verhindert, dass Nutzer an Instanzen geleitet werden, die nicht korrekt antworten können.
- Liveness-Probes erkennen, ob ein Container festhängt oder defekt ist und neu gestartet werden muss. Das vermeidet langsame Fehlerzustände, in denen ein Prozess zwar lebt, aber Anfragen nicht bearbeitet.
Bei sinnvoller Nutzung minimieren Probes falsche Erfolge—Deployments, die so aussehen, als liefen sie, weil Pods gestartet sind, obwohl sie tatsächlich Anfragen fehlschlagen.
Bereitstellungsstrategien: rolling, blue/green, canary
Kubernetes unterstützt rolling updates standardmäßig, aber Teams bauen oft zusätzliche Muster darüber:
- Blue/Green: zwei vollständige Umgebungen; der Traffic wird von alt (blue) auf neu (green) umgeschaltet, sobald green verifiziert ist.
- Canary: ein kleiner Prozentsatz des Traffics geht zur neuen Version; nach Beobachtung der Metriken wird schrittweise ausgeweitet.
Messbare (und automatisierbare) Sicherheit
Sichere Deployments beruhen auf Signalen: Fehlerquoten, Latenz, Auslastung und Nutzerwirkung. Viele Teams verbinden Rollout‑Entscheidungen mit SLOs und Error Budgets—verbrennt ein Canary zu viel Budget, stoppt die Promotion.
Das Ziel sind automatisierte Rollback-Trigger basierend auf realen Indikatoren (fehlgeschlagene Readiness, steigende 5xx, Latenzspitzen), sodass „Rollback“ zu einer vorhersehbaren Systemantwort wird—nicht zu einer nächtlichen Heldentat.
Service-Betrieb: Discovery, Routing und stabiles Networking
Wähle den passenden Plan
Wechsle vom Solo-Prototypen zur teamfähigen Arbeit mit dem passenden Plan für dich.
Eine Containerplattform wirkt nur dann „automatisch“, wenn andere Teile des Systems deine App nach Bewegungen noch finden. In Produktions-Clustern werden Pods ständig erstellt, gelöscht, neu geplant und skaliert. Wenn jede Änderung das Aktualisieren von IP-Adressen in Konfigurationen erfordert, würde Betrieb in ständige Arbeit ausarten—und Ausfälle wären an der Tagesordnung.
Warum Service-Discovery wichtig ist
Service-Discovery bedeutet, Clients eine verlässliche Möglichkeit zu geben, eine sich ändernde Menge von Backends zu erreichen. In Kubernetes besteht der zentrale Wandel darin, dass man aufhört, einzelne Instanzen anzuzielen („ruf 10.2.3.4 an“) und stattdessen einen benannten Service anspricht („ruf checkout an“). Die Plattform regelt, welche Pods aktuell diesen Namen bedienen.
Services, Selector und Endpoints (einfach erklärt)
Ein Service ist eine stabile Haustür für eine Gruppe von Pods. Er hat einen konstanten Namen und eine virtuelle Adresse im Cluster, auch wenn die zugrundeliegenden Pods wechseln.
Ein Selector legt fest, welche Pods „hinter“ dieser Tür stehen—meistens über Labels wie app=checkout.
Endpoints (oder EndpointSlices) sind die lebende Liste der tatsächlichen Pod-IP‑Adressen, die aktuell dem Selector entsprechen. Wenn Pods skalieren, gerollt oder neu geplant werden, aktualisiert sich diese Liste automatisch—Clients nutzen weiter denselben Service-Namen.
Stabile Adressen, Load-Balancing und Routing
Operativ bietet das:
- Stabile Adressen: Apps sprechen einen Service-DNS-Namen an statt Pod-IP‑Adressen.
- Load-Balancing: Verkehr verteilt sich auf gesunde Pods hinter dem Service.
- Vorhersehbares Routing: du trennst „wer Traffic erhalten soll“ (Labels/Selector) von „wo die Pods gerade laufen".
Für North–South‑Traffic (außerhalb des Clusters) verwendet Kubernetes typischerweise ein Ingress oder den neueren Gateway-Ansatz. Beide bieten einen kontrollierten Einstiegspunkt, an dem du anhand von Hostname oder Pfad routen kannst und oft zentrale Aufgaben wie TLS‑Termination bündelst. Die zugrundeliegende Idee bleibt: externe Zugänge stabil halten, während die Backends darunter wechseln.
Self‑Healing: Was es in Produktion wirklich bedeutet
„Self‑healing“ in Kubernetes ist kein Zauber. Es sind automatisierte Reaktionen auf Fehler: restart, reschedule und replace. Die Plattform überwacht, was du angegeben hast (dein gewünschter Zustand), und schubst die Realität laufend zurück in Einklang.
Restart: wenn ein Container abstürzt
Wenn ein Prozess beendet oder ein Container ungesund wird, kann Kubernetes ihn auf demselben Node neu starten. Das wird typischerweise ausgelöst durch:
- Liveness-Probes: „Funktioniert dieser Container noch?“ Wenn nicht, starte ihn neu.
- Restart-Policies: Regeln, wann Neustarts erfolgen sollen.
Ein gängiges Produktionsmuster ist: ein Container crasht → Kubernetes startet ihn neu → dein Service routet nur zu gesunden Pods.
Reschedule und Replace: wenn ein Node ausfällt
Fällt ein kompletter Node aus (Hardware-Fehler, Kernel-Panic, Netzwerkverlust), erkennt Kubernetes den Node als nicht erreichbar und beginnt, Arbeit anderswo zu platzieren. Grob:
- Der Node wird als unhealthy/not ready markiert.
- Pods, die dort liefen, gelten als verloren.
- Controller erstellen Ersatz-Pods auf anderen gesunden Nodes, um die gewünschte Replikazahl wiederherzustellen.
Das ist Self‑Healing auf Cluster‑Ebene: das System ersetzt Kapazität, anstatt auf manuelle Eingriffe zu warten.
Observability: wie du siehst, dass es heilt
Self‑Healing zählt nur, wenn du es verifizieren kannst. Teams beobachten typischerweise:
- Logs (App-Logs und Plattform-Events), um zu sehen, was neu gestartet wurde und warum
- Metriken wie Restart-Anzahlen, fehlgeschlagene Probes und Node‑Readiness
- Alerts, wenn Healing nicht funktioniert (z. B. wiederholte CrashLoopBackOff, Replikakürze, zu viele Evictions)
Fehlkonfigurationen, die Self‑Healing brechen
Selbst mit Kubernetes kann „Healing“ scheitern, wenn Guardrails fehlen:
- fehlerhafte oder fehlende Liveness/Readiness‑Probes (falsche Positiv/Negativ-Erkennungen)
- keine Resource Requests/Limits, was zu unvorhersehbarer Planung oder OOMs führt
- zu wenige Replikate (ein einzelner Pod bietet keine Kontinuität)
- zu aggressive Probe-Timings, die Restart‑Stürme auslösen
- Workloads, die auf node‑lokalem Zustand beruhen, ohne dauerhafte Speicherstrategie
Ist Self‑Healing gut eingerichtet, werden Ausfallzeiten kürzer und messbarer.
In Minuten ein App-Gerüst erhalten
Beschreibe deinen Service im Chat und generiere ein Basisgerüst mit React, Go und PostgreSQL.
Kubernetes gewann nicht nur, weil es Container ausführen konnte. Es gewann, weil es standardisierte APIs für die häufigsten betrieblichen Bedürfnisse anbot—Bereitstellung, Skalierung, Networking und Observability. Wenn Teams sich auf dieselbe Objektform (z. B. Deployments, Services, Jobs) einigen, können Tools organisationsübergreifend geteilt werden, Schulungen werden einfacher und Übergaben zwischen Entwicklern und Betrieb basieren nicht mehr auf impliziertem Wissen.
Warum standardisierte APIs Team-Workflows verändern
Eine konsistente API bedeutet, dass deine Deployment-Pipeline nicht die Eigenheiten jeder App kennen muss. Sie kann dieselben Aktionen ausführen—create, update, rollback, health‑check—mit denselben Kubernetes-Konzepten.
Sie verbessert auch die Ausrichtung: Sicherheitsteams können Guardrails als Policies ausdrücken; SREs können Runbooks um gemeinsame Gesundheits‑Signale standardisieren; Entwickler können Releases in einer gemeinsamen Sprache betrachten.
Kubernetes erweitern: CRDs und Operatoren
Der Plattform‑Charakter wird mit Custom Resource Definitions (CRDs) offensichtlich. Eine CRD erlaubt es, einen neuen Objekttyp in den Cluster einzuführen (z. B. Database, Cache oder Queue) und ihn mit denselben API‑Mustern wie eingebaute Ressourcen zu verwalten.
Ein Operator koppelt solche Custom Objects an einen Controller, der kontinuierlich Realität und gewünschten Zustand abgleicht—und so Aufgaben automatisiert, die früher manuell waren, wie Backups, Failover oder Upgrades. Der wirkliche Gewinn ist nicht magische Automatisierung, sondern die Wiederverwendung desselben Control‑Loop‑Ansatzes, den Kubernetes für alles andere anwendet.
Passung zu GitOps, CI/CD und Policy‑Checks
Weil Kubernetes API‑getrieben ist, lässt es sich gut in moderne Workflows integrieren:
- GitOps: der gewünschte Zustand lebt in Git; Änderungen werden wie Code geprüft.
- CI/CD: Pipelines können Manifeste anwenden, auf Readiness warten und Versionen promoten.
- Policy-Checks: Admission‑Controller können riskante Konfigurationen blocken, bevor sie Produktion erreichen.
Wenn du praxisnahe Deployment- und Betriebsleitfäden zu diesen Ideen suchst, durchsuche /blog.
Was Teams heute anwenden können (auch ohne Kubernetes)
Die größten Kubernetes‑Ideen—viele, die mit Brendan Burns’ früher Darstellung verbunden sind—lassen sich gut übertragen, selbst wenn du VMs, Serverless oder eine kleinere Container-Umgebung betreibst.
Muster, die den Alltag verbessern
Schreibe den „gewünschten Zustand“ auf und lass die Automatisierung ihn durchsetzen. Ob Terraform, Ansible oder eine CI-Pipeline: behandle Konfiguration als Quelle der Wahrheit. Das Ergebnis sind weniger manuelle Deploy‑Schritte und deutlich weniger „auf meinem Rechner lief es“-Überraschungen.
Nutze Reconciliation statt einmaliger Skripte. Statt Skripten, die einmal laufen und hoffen, baue Schleifen, die wichtige Eigenschaften fortlaufend prüfen (Version, Konfiguration, Instanzanzahl, Gesundheit). So bekommst du wiederholbaren Betrieb und vorhersehbare Wiederherstellung nach Fehlern.
Mache Scheduling und Skalierung zu Produktfunktionen. Definiere, wann und warum du Kapazität hinzufügst (CPU, Queue‑Tiefe, Latenz‑SLOs). Auch ohne Kubernetes‑Autoscaling können Teams Skalierungsregeln standardisieren, sodass Wachstum kein Rewrite der Applikation erfordert oder niemand geweckt werden muss.
Standardisiere Rollouts. Rolling Updates, Health Checks und schnelle Rollbacks reduzieren Änderungsrisiken. Das lässt sich mit Load Balancern, Feature Flags und Deployment‑Pipelines umsetzen, die Releases an realen Signalen ausrichten.
Checkliste für eine sichere Einführung
- Definiere den gewünschten Zustand eines Services: Version, Konfiguration, Abhängigkeiten und minimale Instanzanzahl
- Füge Health‑Endpoints (Liveness/Readiness‑Äquivalente) hinzu und integriere sie in Load Balancer oder Deployment‑Pipeline
- Automatisiere Rollout-Schritte: deployen, verifizieren, Traffic verschieben und bei Fehlern zurückrollen
- Erstelle einen kleinen „Reconciler": geplante Prüfungen, die Drift korrigieren (falsche Konfiguration, fehlende Instanzen)
- Füge Skalierungs‑Trigger mit klaren Grenzen hinzu (max. Instanzen, Cooldowns, Genehmigungsregeln)
Was das allein nicht löst
Diese Muster beheben nicht automatisch schlechtes App‑Design, unsichere Datenmigrationen oder Kostenkontrolle. Du brauchst weiterhin versionierte APIs, Migrationspläne, Budgetlimits und Observability, die Deploys mit Kundenauswirkung verknüpft.
Nächste Schritte
Wähle einen kundenorientierten Service und implementiere die Checkliste Ende‑zu‑Ende, dann skaliere aus.
Wenn du neue Services baust und schneller zu „etwas Deploybarem“ kommen willst, kann Koder.ai dir helfen, aus einer Chat‑Spezifikation eine komplette Web/Backend/Mobile‑App zu generieren—typischerweise React im Frontend, Go mit PostgreSQL im Backend und Flutter für Mobile—und anschließend den Quellcode zu exportieren, sodass du dieselben Kubernetes‑Muster anwenden kannst (deklarative Konfigurationen, wiederholbare Rollouts und rollback‑freundliche Abläufe). Für Teams, die Kosten und Governance evaluieren, schaue /pricing.