Warum Caching hilft — und warum es Systeme verkompliziert
Caching hält eine Kopie von Daten dort, wo sie gebraucht werden, sodass Anfragen schneller beantwortet werden können und weniger Zugriffe auf Kernsysteme nötig sind. Die Vorteile sind meist eine Kombination aus Geschwindigkeit (niedrigere Latenz), Kosten (weniger teure Datenbankzugriffe oder Upstream-Calls) und Stabilität (Origin-Services überstehen Traffic-Spitzen besser).
Der Vorteil: weniger Arbeit für das Origin
Wenn ein Cache eine Anfrage beantworten kann, arbeitet das „Origin“ (App-Server, Datenbanken, Drittanbieter-APIs) weniger. Diese Reduktion kann erheblich sein: weniger Abfragen, weniger CPU-Zeit, weniger Netzwerksprünge und weniger Timeout-Gelegenheiten.
Caching glättet außerdem Spitzen — es hilft Systemen, die für den durchschnittlichen Load dimensioniert sind, Peak-Zeiten zu verkraften, ohne sofort zu skalieren (oder auszufallen).
Die versteckte Kosten: mehr Arbeit für Ingenieure
Caching entfernt Arbeit nicht; es verlagert sie in Design und Betrieb. Es entstehen neue Fragen:
- Was sollte gecached werden?
- Wie lange?
- Was passiert, wenn sich Daten ändern?
- Wie verhindert man veraltete oder falsche Ergebnisse?
- Wie debuggt man Probleme, wenn ein Cache das Origin-Verhalten „versteckt"?
Jede Caching-Schicht bringt Konfiguration, Monitoring und Randfälle mit sich. Ein Cache, der 99 % der Anfragen schneller macht, kann in den verbleibenden 1 % schmerzhafte Vorfälle provozieren: synchronisierte Ausläufe, inkonsistente Nutzererfahrungen oder plötzliche Flut ans Origin.
Caching-Schicht vs. ein einzelner Cache
Ein einzelner Cache ist ein Speicher (z. B. ein In-Memory-Cache neben Ihrer Anwendung). Eine Caching-Schicht ist ein eigener Checkpoint im Request-Pfad — CDN, Browser-Cache, Anwendungs-Cache, Datenbank-Cache — jeder mit eigenen Regeln und Ausfallmodi.
Dieser Beitrag konzentriert sich auf die praktische Komplexität, die durch mehrere Schichten entsteht: Korrektheit, Invalidierung und Betrieb (nicht auf niedrige Ebenen von Cache-Algorithmen oder vendor-spezifisches Tuning).
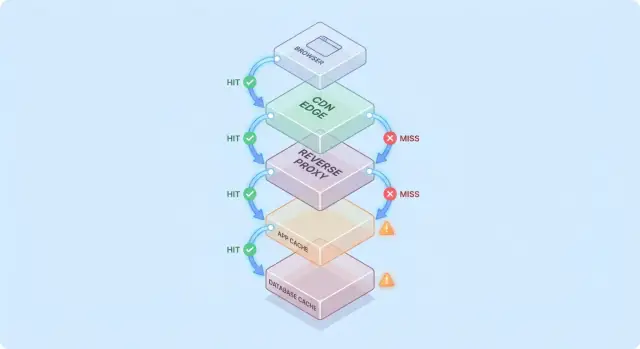
Ein einfaches Modell: Request-Flow durch mehrere Schichten
Caching wird einfacher zu durchdenken, wenn Sie sich eine Anfrage vorstellen, die durch einen Stapel von „vielleicht habe ich es schon“ Checkpoints läuft.
Typischer Request-Pfad
Ein häufiger Pfad sieht so aus:
- Client → Edge (CDN) → App → Datenbank
Bei jedem Hop kann das System entweder eine gecachte Antwort zurückgeben (Hit) oder die Anfrage an die nächste Schicht weiterleiten (Miss). Je früher ein Hit auftritt (z. B. am Edge), desto mehr Last vermeiden Sie tiefer im Stack.
Hits sind schön; Misses sind der wahre Test
Hits sehen in Dashboards gut aus. Misses zeigen die Komplexität: sie lösen echte Arbeit aus (App-Logik, DB-Queries) und fügen Overhead hinzu (Cache-Lookups, Serialisierung, Cache-Schreibvorgänge).
Ein nützliches Modell ist: Jeder Miss zahlt doppelt für den Cache — Sie erledigen trotzdem die ursprüngliche Arbeit plus die Cache-Umgebung darum herum.
Wie Schichten Engpässe verlagern
Eine zusätzliche Cache-Schicht beseitigt selten Engpässe; sie verlagert sie oft:
- Ein CDN verlagert Druck vom App-Tier, erhöht aber die Sensitivität gegenüber Cache-Konfiguration und Purge-Geschwindigkeit.
- Ein Anwendungs-Cache reduziert DB-Last, macht aber App-CPU/Mem zum neuen limitierenden Faktor.
- DB-Caching (Buffer-Pools, Plan-Caches) kann langsame Queries verbergen, bis der Working Set nicht mehr passt.
Einfaches „doppelt gecached“-Beispiel
Angenommen, eine Produktseite ist beim CDN für 5 Minuten gecached und die App cached Produktdetails in Redis für 30 Minuten.
Wenn sich ein Preis ändert, kann das CDN schnell erneuern, während Redis weiterhin den alten Preis ausliefert. Nun hängt die „Wahrheit" davon ab, welche Schicht die Anfrage beantwortet — ein frühes Beispiel dafür, warum Caching Schichten Last reduziert, aber Systemkomplexität erhöht.
Übliche Caching-Schichten und wofür sie gut sind
Caching ist kein Einzelmerkmal — es ist ein Stack von Orten, an denen Daten gespeichert und wiederverwendet werden können. Jede Schicht reduziert Last, hat aber unterschiedliche Regeln für Frische, Invalidierung und Sichtbarkeit.
Browser- und OS-Caches (was Sie steuern vs. was Sie nicht steuern)
Browser cachen Bilder, Skripte, CSS und manchmal API-Antworten basierend auf HTTP-Headern wie Cache-Control und ETag. Das kann wiederholte Downloads komplett eliminieren — gut für Performance und zur Reduktion von CDN/Origin-Traffic.
Der Haken: sobald eine Antwort clientseitig gecached ist, kontrollieren Sie die Revalidierungszeit nicht vollständig. Manche Nutzer behalten ältere Assets länger (oder löschen den Cache unerwartet), daher sind versionierte URLs (z. B. app.3f2c.js) eine übliche Absicherung.
CDN-/Edge-Caching für statische und semi-statische Inhalte
Ein CDN cached Inhalte nahe bei den Nutzern. Es ist ideal für statische Dateien, öffentliche Seiten und „größtenteils konstante" Antworten wie Produktbilder, Dokumentation oder rate-limitierte Endpunkte.
CDNs können auch semi-statisches HTML cachen, wenn Sie mit Variationsregeln (Cookies, Header, Geo, Device) sorgfältig umgehen. Falsch konfigurierte Variationen sind eine häufige Ursache dafür, dass falsche Inhalte an falsche Nutzer ausgespielt werden.
Reverse-Proxy-Caching (Gateway-Level)
Reverse-Proxies (z. B. NGINX oder Varnish) sitzen vor Ihrer Anwendung und können ganze Antworten cachen. Das ist nützlich, wenn Sie zentrale Kontrolle, vorhersehbare Eviction und schnellen Schutz für Origins während Traffic-Spitzen wollen.
Es ist typischerweise weniger global verteilt als ein CDN, aber leichter auf Ihre App-Routen und Header zuzuschneiden.
Anwendungs-Level-Caching (In-Memory, Redis, Memcached)
Dieser Cache zielt auf Objekte, berechnete Ergebnisse und teure Aufrufe ab (z. B. „User-Profil nach ID“ oder „Preise für Region“). Er ist flexibel und kann an Geschäftslogik angepasst werden.
Er bringt jedoch mehr Entscheidungsprozesse: Key-Design, TTL-Wahl, Invalidierungslogik und Betriebsanforderungen wie Sizing und Failover.
Datenbank-Caching und Query/Result-Caching
Die meisten Datenbanken cachen Seiten, Indizes und Query-Pläne automatisch; einige bieten Result-Caching. Das kann häufige Queries beschleunigen, ohne die Anwendung zu ändern.
Betrachten Sie das als Bonus, nicht als Garant: DB-Caches sind unter heterogenen Query-Lasten meist am wenigsten vorhersagbar und sie eliminieren nicht die Kosten von Writes, Locks oder Contention so wie Upstream-Caches.
Wo Caching die größte Lastreduktion bringt
Caching lohnt sich am meisten, wenn es wiederholte, teure Backend-Operationen in einen günstigen Lookup verwandelt. Die Kunst ist, den Cache zu Workloads zu passen, bei denen Anfragen ähnlich genug — und stabil genug — sind, dass Wiederverwendung hoch ist.
Read-lastige Workloads und teure Berechnungen
Wenn Ihr System viel mehr Reads als Writes bedient, kann Caching einen großen Teil der DB- und Anwendungsarbeit entfernen. Produktseiten, öffentliche Profile, Hilfeseiten und Such-/Filterergebnisse werden oft mit gleichen Parametern mehrfach angefragt.
Caching hilft auch bei „aufwändigen" Aufgaben, die nicht strikt DB-gebunden sind: PDF-Generierung, Bild-Resizing, Template-Rendering oder Aggregats-Berechnungen. Selbst ein kurzlebiger Cache (Sekunden bis Minuten) kann wiederholte Berechnung während hoher Last zusammenfassen.
Spitzenverkehr und Burst-Schutz
Caching ist besonders effektiv bei ungleichmäßigem Traffic. Wenn ein Marketing-Mail, ein Medienartikel oder ein Social-Post einen Traffic-Burst auf wenige URLs auslöst, kann ein CDN oder Edge-Cache die meisten Anfragen abfangen.
Das reduziert nicht nur Latenz: es verhindert Autoscaling-Thrashing, vermeidet Erschöpfung von DB-Verbindungen und buyt Zeit für Rate-Limits und Backpressure-Mechanismen.
Hoch-latente Backends und Nutzer über Regionen
Ist Ihr Backend weit von Nutzern entfernt — geografisch oder aufgrund langsamer Abhängigkeiten — reduziert Caching sowohl Last als auch empfundene Langsamkeit. Inhalte vom CDN nahe beim Nutzer zu servieren vermeidet wiederholte Langstrecken-Requests zum Origin.
Internes Caching hilft ebenfalls, wenn ein entfernte DB, ein Drittanbieter-API oder ein shared Service die Latenz-Engstelle ist. Weniger Aufrufe verringern Concurrency-Druck und verbessern Tail-Latenzen.
Wann Caching wenig Sinn macht
Caching bringt weniger Nutzen bei stark personalisierten Antworten (pro Nutzer) oder sehr schnell ändernden Daten (Live-Dashboards, sich rasch ändernde Inventare). Dann sind Hit-Rates niedrig, Invalidierungskosten hoch, und die eingesparte Origin-Arbeit marginal.
Eine praktische Regel: Caching ist am wertvollsten, wenn viele Nutzer innerhalb eines Zeitfensters dasselbe anfragen und „dasselbe" lange genug gültig bleibt. Fehlt diese Überschneidung, erhöht eine zusätzliche Schicht die Komplexität ohne viel Last zu sparen.
Cache-Invalidierung: die Hauptquelle für Komplexität
Caching ist einfach, solange sich Daten nie ändern. Sobald sie sich ändern, übernehmen Sie den schwersten Teil: zu entscheiden, wann gecachte Daten unzuverlässig werden und wie jede Caching-Schicht davon erfährt.
TTL-Expiration: simpel, aber selten „richtig"
Time-to-live (TTL) ist verlockend, weil es keine Koordination erfordert. Das Problem: die „richtige" TTL hängt von der Nutzung ab.
Setzen Sie z. B. eine 5-Minuten-TTL auf einen Produktpreis, sehen einige Nutzer nach einer Preisänderung weiterhin den alten Preis — möglicherweise ein rechtliches oder Support-Problem. Setzen Sie 5 Sekunden, reduziert das kaum die Last. Verschiedene Felder derselben Antwort ändern sich unterschiedlich schnell (Inventar vs. Beschreibung), daher erzwingt eine einzige TTL Kompromisse.
Ereignisgetriebene Invalidierung: genau, aber koordinationsintensiv
Ereignisgetriebene Invalidierung sagt: wenn die Quelle der Wahrheit sich ändert, publiziere ein Event und purge/update alle betroffenen Cache-Keys. Das kann sehr korrekt sein, bringt aber neue Arbeit mit sich:
- Jeder Schreibpfad muss Events zuverlässig ausliefern
- Jede Caching-Schicht muss subscriben, retryen, deduplizieren und mit out-of-order-Zustellung umgehen
- Sie brauchen eine klare Abbildung von „was hat sich geändert" zu „welche Keys invalidiert werden"
Diese Abbildung ist der praktische Knackpunkt: Naming und Invalidierung werden hier greifbar schwierig. Wenn Sie /users/123 cachen und auch „Top Contributors" Lists cachen, betrifft eine Benutzeränderung mehrere Keys. Ohne Beziehungen liefern Sie gemischte Realität.
Muster: cache-aside vs. write-through vs. write-back
Cache-aside (App liest/schreibt DB, füllt Cache bei Bedarf) ist weit verbreitet, aber die Invalidierung liegt bei Ihnen.
Write-through (schreibt Cache und DB zusammen) reduziert Staleness-Risiko, erhöht aber Latenz und Fehlerbehandlungs-Komplexität.
Write-back (erst Cache schreiben, später flushen) erhöht Geschwindigkeit, macht Korrektheit und Recovery jedoch deutlich schwieriger.
Stale-while-revalidate: bewusst „gut genug"
Stale-while-revalidate liefert leicht veraltete Daten, während im Hintergrund aktualisiert wird. Das glättet Peaks und schützt das Origin, ist aber auch eine Produktentscheidung: Sie wählen bewusst „schnell und größtenteils aktuell" über „immer neu".
Konsistenz-Abwägungen und sichtbare Korrektheit für Nutzer
Betrieb erleichtern
Erstelle eine Staging-App, die deinen Stack spiegelt, damit dein Team Cache-Runbooks verfeinern kann.
Caching verändert das Verständnis von „korrekt". Ohne Cache sehen Nutzer meist die zuletzt committeden Daten (abgesehen von normalen DB-Verhalten). Mit Caches können Nutzer leicht veraltete oder inkonsistente Daten sehen — manchmal ohne ersichtlichen Fehler.
Starke vs. eventuale Konsistenz (und was Nutzer wirklich bemerken)
Starke Konsistenz strebt „read-after-write" an: wenn ein Nutzer seine Lieferadresse ändert, sollte die nächste Seite die neue Adresse überall zeigen. Das fühlt sich richtig an, kann aber teuer sein, wenn jeder Write sofort mehrere Caches purge oder refreshen muss.
Eventual Consistency erlaubt kurze Staleness: das Update erscheint bald, aber nicht sofort. Nutzer tolerieren das bei geringwertigem Inhalt (z. B. View-Counts), aber nicht bei Geld, Berechtigungen oder allem, was ihr nächstes Handeln beeinflusst.
Rennbedingungen zwischen Writes und Cache-Refresh
Ein häufiger Fehler ist ein Write, der gleichzeitig mit einer Cache-Repopulation stattfindet:
- Nutzer ändert Profil
- Cache wird invalidiert
- Eine andere Anfrage repopuliert den Cache aus einer Replica, die das Update noch nicht hat
Nun enthält der Cache alte Daten für die volle TTL, obwohl die DB korrekt ist.
Mehrschichtige Inkonsistenz: Edge sagt A, App sagt B
Bei mehreren Schichten können unterschiedliche Systemteile uneinheitlich antworten:
- CDN gibt eine ältere HTML-Seite zurück („Adresse: Alte Str.")
- App-Cache liefert neuere JSON-Daten („Adresse: Neue Str.")
- Die UI wird gemischt
Nutzer interpretieren das als „das System ist kaputt", nicht als „das System ist eventual consistent."
Versionierung reduziert Ambiguität:
- ETags erlauben Clients/CDNs effiziente Revalidierung und vermeiden das Ausliefern veralteter Repräsentationen
- Versionierte Cache-Keys (z. B.
user:123:v7) erlauben ein sicheres Voranschreiten: ein Write erhöht die Version, und Reads wechseln natürlicherweise zum neuen Key ohne perfekt getimte Löschungen
Akzeptable Staleness pro Feature definieren
Die entscheidende Frage ist nicht „sind veraltete Daten schlecht?", sondern wo sie problematisch sind.
Setzen Sie explizite Staleness-Budgets pro Feature (Sekunden/Minuten/Stunden) und richten Sie sie an Nutzererwartungen aus. Suchergebnisse können eine Minute verzögert sein; Kontostände und Zugriffsrechte sollten das nicht sein. So wird „Cache-Korrektheit" zu einer test- und überwachbaren Produktanforderung.
Ausfallmodi: Stampedes, Hot Keys und Cache-Ausfälle
Caching fällt oft auf Arten aus, die sich anfühlen wie „alles war gut, dann war alles auf einmal kaputt." Diese Ausfälle bedeuten nicht, dass Caching schlecht ist — sie zeigen, dass Caches Verkehrsströme konzentrieren, sodass kleine Änderungen große Effekte haben können.
Cold Starts und ungleichmäßige Last nach Deploys
Nach Deploys, Skalierungsereignissen oder einem Cache-Flush ist der Cache meist leer. Die nächste Traffic-Welle zwingt viele Anfragen, direkt die DB oder Upstream-APIs zu treffen.
Besonders schmerzhaft ist das bei schneller Traffic-Rampe, weil der Cache noch keine populären Items vorgeheizt hat. Treffen Deploys auf Spitzenzeiten, erzeugen Sie unbeabsichtigt einen Lasttest.
Cache-Stampedes (Thundering Herd)
Ein Stampede entsteht, wenn viele Nutzer kurz nach Ablauf dasselbe Item anfragen und hunderte oder tausende den Origin überfluten.
Typische Gegenmaßnahmen wurden oben beschrieben: Request-Coalescing, Locks/Single-Flight, Jittered TTLs und stale-while-revalidate.
Hot Keys und ungleichmäßige Verteilung
Manche Keys werden überproportional beliebt (Homepage-Payload, trendendes Produkt, globale Konfiguration). Hot Keys erzeugen ungleiche Last: ein Cache-Node oder Backend-Pfad wird übermäßig belastet, während andere idle sind.
Gegenmaßnahmen: große globale Keys in kleinere aufteilen, Sharding/Partitionierung, oder an einer anderen Schicht cachen (z. B. wirklich öffentliche Inhalte näher an Nutzer mittels CDN).
Wenn der Cache down ist: Ausfallstrategie wählen
Cache-Ausfälle können schlimmer sein als gar kein Cache, weil Anwendungen oft von ihm abhängen. Entscheiden Sie vorab:
- Fail open (Cache umgehen, Origin anfragen): bessere Verfügbarkeit, höheres Last-Risiko
- Fail closed (Fehler zurückgeben): schützt Origin, schlechtere UX
- Graceful degrade (stale/defaults liefern): oft der beste Kompromiss
Egal welche Wahl: Rate-Limits und Circuit-Breaker helfen, dass ein Cache-Fehler nicht zum Origin-Ausfall eskaliert.
Operativer Aufwand: mehr bewegliche Teile zu managen
Schnelle Rollbacks ausprobieren
Nutze Snapshots und Rollbacks, um Caching-Änderungen iterativ umzusetzen, ohne festzustecken.
Caching reduziert zwar Origin-Last, erhöht aber die Anzahl der Services, die Sie täglich betreiben. Selbst „managed" Caches brauchen Planung, Tuning und Incident-Response.
Mehr Komponenten zum Betreiben
Eine neue Caching-Schicht ist oft ein neuer Cluster (oder mindestens eine neue Ebene) mit eigenen Kapazitätsgrenzen. Teams müssen Memory-Sizing, Eviction-Policy und Verhalten unter Druck entscheiden. Ist der Cache zu klein, churnt er: Hit-Rate sinkt, Latenz steigt, und das Origin wird trotzdem geflutet.
Konfigurationsdrift über Schichten hinweg
Caching lebt selten an einem Ort. Sie haben vielleicht CDN-Caching, Anwendungs-Cache und DB-Caching — alle interpretieren Regeln unterschiedlich.
Kleine Abweichungen kumulieren:
- CDN respektiert Header, App-Cache nutzt harte TTLs
- Eine Schicht umgeht bei Cookies, eine andere nicht
- Purge-Regeln existieren nur an einem Ort
Im Laufe der Zeit wird die Frage „Warum ist diese Anfrage gecached?" zu einem Archäologie-Projekt.
Operative Aufgaben, die es vorher nicht gab
Caches erzeugen laufende Arbeit: kritische Keys nach Deploys vorheizen, Purges/Revalidierungen bei Datenänderung, Resharding beim Hinzufügen/Entfernen von Nodes und Proben, was nach einem Full-Flush passiert.
On-Call-Komplexität bei Incidents
Wenn Nutzer veraltete Daten oder plötzliche Langsamkeit melden, haben Responder nun mehrere Verdächtige: CDN, Cache-Cluster, Cache-Client der App und Origin. Debugging bedeutet oft, Hit-Raten, Evictions und Timeouts über Schichten zu prüfen — und zu entscheiden, ob man umgeht, purget oder skaliert.
Observability: nachweisen, dass der Cache tatsächlich hilft
Caching ist nur ein Gewinn, wenn es Origin-Arbeit reduziert und die Nutzerwahrnehmung verbessert. Weil Anfragen von mehreren Schichten bedient werden können (Edge/CDN, App-Cache, DB-Cache), brauchen Sie Observability, die beantwortet:
- Welche Schicht hat diese Anfrage bedient?
- Was hat sich geändert, als sie es nicht tat?
Metriken, die Ergebnisse erklären
Eine hohe Hit-Rate klingt gut, kann aber Probleme verbergen (z. B. langsame Cache-Leses). Tracken Sie pro Schicht eine kleine Menge aussagekräftiger Metriken:
- Hit- und Miss-Rate, aufgeteilt nach Endpoint oder Namespace
- Latenz pro Schicht (Cache-Lesezeit vs Origin-Zeit), ideal p50/p95/p99
- Eviction-Rate und Item-Age (wie lange Einträge überleben)
- Origin-Load-Indikatoren (DB-QPS, CPU, Connection-Pool-Auslastung) korreliert mit Cache-Hits
Wenn die Hit-Rate steigt, die Gesamtlatenz sich aber nicht verbessert, kann der Cache langsam sein, stark serialisiert arbeiten oder zu große Payloads liefern.
Tracing über Schichten hinweg
Distributed Tracing sollte zeigen, ob eine Anfrage am Edge, vom App-Cache oder von der DB bedient wurde. Fügen Sie konsistente Tags wie cache.layer=cdn|app|db und cache.result=hit|miss|stale hinzu, damit Sie Traces filtern und Hit- vs. Miss-Pfade vergleichen können.
Logs und Alerts ohne Datenlecks
Loggen Sie Cache-Keys mit Bedacht: vermeiden Sie rohe Nutzer-IDs, E-Mails, Tokens oder komplette URLs mit Query-Strings. Bevorzugen Sie normalisierte oder gehashte Keys und loggen nur ein kurzes Präfix.
Alarmieren Sie bei abnormen Miss-Rate-Spitzen, plötzlichen Latenzanstiegen bei Misses und Stampede-Signalen (viele gleichzeitige Misses für dasselbe Key-Muster). Trennen Sie Dashboards in Edge, App und DB Views sowie ein End-to-End-Panel, das sie verbindet.
Sicherheits- und Privacy-Risiken bei gecachten Antworten
Caching ist großartig, um Antworten schnell zu wiederholen — kann aber auch die falsche Antwort an die falsche Person wiederholen. Caching-bezogene Sicherheitsvorfälle sind oft still: alles wirkt schnell und gesund, während Daten geleakt werden.
Wie sensible Daten im Cache landen
Ein häufiger Fehler ist das Cachen personalisierter oder vertraulicher Inhalte (Kontodaten, Rechnungen, Support-Tickets, Admin-Seiten). Das kann auf jeder Schicht passieren — CDN, Reverse-Proxy oder Anwendungs-Cache — besonders bei breit angelegten „cache everything"-Regeln.
Ein subtiler Leak: Antworten mit Session-State (z. B. Set-Cookie) cachen und diese gecachte Antwort später anderen Nutzern ausliefern.
Autorisierungsfehler: korrekte Anfrage, falscher Betrachter
Ein klassischer Bug: die Antwort für Nutzer A wird gecached und später Nutzer B serviert, weil der Cache-Key den Nutzerkontext nicht enthielt. In Multi-Tenant-Systemen muss Tenant-Identität Teil des Keys sein.
Faustregel: wenn die Antwort von Authentifizierung, Rollen, Geo, Pricing-Tier, Feature-Flags oder Tenant abhängt, muss Ihr Cache-Key (oder Bypass-Logik) diese Abhängigkeit abbilden.
HTTP-Caching wird stark von Headern gesteuert:
Cache-Control: verhindern Sie versehentliche Speicherung mit private / no-store, wenn nötigVary: sorgen Sie dafür, dass Caches Antworten nach relevanten Request-Headern trennen (z. B. Authorization, Accept-Language)Set-Cookie: ist oft ein Indiz dafür, die Antwort nicht öffentlich zu cachen
Wann man komplett aufs Caching verzichten sollte
Wenn Compliance- oder Risikofaktoren hoch sind — PII, Gesundheits-/Finanzdaten, rechtliche Dokumente — bevorzugen Sie Cache-Control: no-store und optimieren serverseitig. Für gemischte Seiten cachen Sie nur nicht-sensible Fragmente oder statische Assets und halten personalisierte Daten aus geteilten Caches fern.
Kosten und ROI: abwägen, ob eine weitere Schicht sich lohnt
Plane deine Cache-Strategie
Nutze den Planungsmodus, um TTL, Keys und Invalidation‑Regeln festzuhalten, die dein Team prüfen kann.
Caching-Schichten können Origin-Last reduzieren, sind aber selten „kostenlose Performance“. Behandeln Sie jede neue Schicht als Investition: Sie kaufen niedrigere Latenz und weniger Backend-Arbeit gegen Geld, Engineering-Zeit und eine größere Korrektheitsfläche.
Was Sie zahlen vs. was Sie sparen
Extra Infrastrukturkosten vs. reduzierte Origin-Kosten. Ein CDN kann Egress und DB-Reads reduzieren, kostet aber CDN-Requests, Cache-Storage und manchmal Invalidations. Ein Anwendungs-Cache (Redis/Memcached) bringt Cluster-Kosten, Upgrades und On-Call-Belastung. Einsparungen zeigen sich möglicherweise in weniger DB-Replicas, kleineren Instanztypen oder verzögertem Skalieren.
Latenzgewinne vs. Frischekosten. Jeder Cache stellt die Frage „wie stale ist akzeptabel?" Strikte Frische erfordert aufwendigere Invalidierungs-Pipeline (mehr Misses). Zugelassene Staleness spart Rechenzeit, kann aber Nutzervertrauen kosten — besonders bei Preisen, Verfügbarkeit oder Berechtigungen.
Engineering-Zeit: Feature-Velocity vs. Zuverlässigkeitsarbeit. Eine neue Schicht bedeutet meist zusätzliche Codepfade, mehr Tests und neue Incident-Klassen (Stampedes, Hot Keys, partielle Invalidierung). Budgetieren Sie laufende Wartung, nicht nur die initiale Implementierung.
Kleine Experimente fahren, um ROI zu messen
Bevor Sie breit ausrollen, führen Sie ein begrenztes Experiment durch:
- Wählen Sie einen Endpunkt oder eine Seite mit klarer Last (z. B. Top 5 % Traffic)
- Definieren Sie Erfolgsmetriken: p95 Latenz, DB-QPS, Fehlerquote, Cache-Hit-Ratio
- Rampen Sie schrittweise; verfolgen Sie Kosten neben Performance
- Timeboxen Sie das Experiment und behalten Sie einen Rollback-Schalter
Eine einfache Entscheidungs-Checkliste
Fügen Sie eine neue Caching-Schicht nur hinzu, wenn:
- der Flaschenhals bewiesen ist (nicht vermutet) durch Metriken
- ein klares Ziel existiert (z. B. DB-Reads um 40 % reduzieren)
- Staleness- und Invalidierungsregeln explizit akzeptabel sind
- Sie es überwachen können (Hit-Rate, Evictions, Latenz, Fehler)
- die erwarteten Einsparungen die zusätzlichen Betriebs- und Engineering-Kosten über einen realistischen Zeitraum überwiegen
Praktische Richtlinien, um Komplexität beim Cachen zu reduzieren
Caching zahlt sich am schnellsten aus, wenn Sie es wie ein Produktfeature behandeln: es braucht einen Owner, klare Regeln und einen sicheren Deaktivierungsweg.
Klein anfangen, Ownership zuweisen
Fügen Sie eine Schicht nach der anderen hinzu (z. B. zuerst CDN oder Anwendungs-Cache) und benennen Sie ein direkt verantwortliches Team/Person.
Definieren Sie, wer verantwortlich ist für:
- Konfigurationsänderungen (TTL, Bypass-Regeln)
- Kapazität und Eviction-Verhalten
- Incident-Response (was zu tun ist, wenn es falsch läuft)
Machen Sie Cache-Keys langweilig und vorhersehbar
Die meisten Cache-Bugs sind eigentlich „Key-Bugs". Nutzen Sie eine dokumentierte Konvention, die alle Eingaben einschließt, die die Antwort verändern: Tenant/User-Scope, Locale, Device-Klasse und relevante Feature-Flags.
Fügen Sie explizite Key-Versionierung hinzu (z. B. product:v3:...), damit Sie sicher per Versions-Bump invalidieren können, statt Millionen Einträge zu löschen.
Bevorzugen Sie begrenzte Staleness gegenüber perfekter Frische
Perfekte Frische für alles schiebt Komplexität in jeden Schreibpfad.
Stattdessen: entscheiden Sie, was „akzeptabel stale" pro Endpunkt bedeutet (Sekunden/Minuten/„bis zur nächsten Aktualisierung"), und kodieren Sie das mit:
- TTLs, die zu Business-Erwartungen passen
- Hintergrund-Refresh (serve slightly stale while updating)
- Ereignisgetriebener Invalidierung nur für wirklich sensible Daten
Sichere Defaults für Fehler bauen
Gehen Sie davon aus, dass der Cache langsam, falsch oder down sein wird.
Nutzen Sie Timeouts und Circuit Breaker, damit Cache-Aufrufe den Request-Pfad nicht mitreißen. Explizite Graceful-Degradation: wenn Cache ausfällt, auf Origin mit Rate-Limits zurückfallen oder eine minimale Antwort liefern.
Rollout mit Kontrollen und Runbooks
Liefern Sie Caching hinter Canary- oder Prozent-Rollouts aus und behalten Sie einen Bypass-Schalter (pro Route oder Header) für schnelles Troubleshooting.
Dokumentieren Sie Runbooks: wie zu purgen, wie Key-Versionen zu erhöhen sind, wie Caching temporär zu deaktivieren ist und welche Metriken zu prüfen sind. Verlinken Sie diese Runbooks in Ihren internen Handbüchern, damit On-Call schnell handeln kann.
Prototyping von Caching-Änderungen ohne Delivery zu verlangsamen
Caching-Arbeit stoppt oft, weil Änderungen mehrere Schichten berühren (Header, App-Logik, Datenmodell, Rollback-Pläne). Ein Weg, um Iterationskosten zu senken: den vollständigen Request-Pfad in einer kontrollierten Umgebung prototypisch aufbauen.
Mit Koder.ai können Teams schnell einen realistischen App-Stack (React Web, Go Backends mit PostgreSQL, sogar Flutter Mobile) aus einem Chat-getriebenen Workflow hochziehen und Caching-Entscheidungen (TTL, Key-Design, stale-while-revalidate) end-to-end testen. Funktionen wie Planning Mode helfen, das beabsichtigte Cache-Verhalten vor der Implementierung zu dokumentieren; Snapshots/Rollback erleichtern Experimente an Cache-Konfigurationen oder Invalidierungs-Logik. Wenn Sie bereit sind, können Sie Source Code exportieren oder mit Custom Domains deployen — nützlich für Performance-Tests, die Produktionslast nachbilden müssen.
Behandeln Sie solche Plattformen als Ergänzung zur produktionsreifen Observability: Ziel ist schnellere Iteration im Caching-Design bei gleichzeitiger Klarheit über Korrektheitsanforderungen und Rollback-Prozeduren.