18. Aug. 2025·8 Min
Chris Lattners LLVM: Der stille Motor hinter modernen Toolchains
Erfahren Sie, wie Chris Lattners LLVM zur modularen Compiler-Plattform wurde, die Sprachen und Werkzeuge antreibt — für bessere Optimierungen, präzisere Diagnosen und schnelle Builds.
Was LLVM ist — in einfachen Worten
LLVM lässt sich am besten als der „Maschinenraum“ vorstellen, den viele Compiler und Entwicklerwerkzeuge gemeinsam nutzen.
Wenn Sie in einer Sprache wie C, Swift oder Rust schreiben, muss irgendwo dieser Code in Anweisungen übersetzt werden, die Ihre CPU ausführen kann. Ein traditioneller Compiler baute oft jedes Teil dieser Pipeline selbst. LLVM verfolgt einen anderen Ansatz: Es stellt einen hochwertigen, wiederverwendbaren Kern bereit, der die schwierigen, aufwändigen Teile übernimmt — Optimierung, Analyse und die Erzeugung von Maschinencode für viele Prozessorarten.
Eine gemeinsame Grundlage für viele Sprachen
LLVM ist meist nicht der einzelne Compiler, den man „direkt benutzt“. Es ist Compiler-Infrastruktur: Bausteine, die Teams für Programmiersprachen zu einer Toolchain zusammensetzen können. Ein Team kann sich auf Syntax, Semantik und entwicklerorientierte Features konzentrieren und die harte Arbeit an LLVM übergeben.
Diese gemeinsame Basis ist ein großer Grund, warum moderne Sprachen schnell auslieferbare, sichere Toolchains bereitstellen können, ohne Jahrzehnte an Compilerarbeit neu erfinden zu müssen.
Warum es wichtig ist, selbst wenn Sie kein Compiler-Mensch sind
LLVM zeigt sich in der alltäglichen Entwicklererfahrung:
- Geschwindigkeit: Es kann hochsprachlichen Code plattformübergreifend in effizienten Maschinencode verwandeln.
- Bessere Fehlermeldungen und Debugging: Das Ökosystem um LLVM ermöglicht reichhaltigere Diagnosen und bessere Werkzeuge.
- Mehr als „nur Kompilieren“: Statische Analyse, Sanitizer, Code-Coverage und andere Entwicklerhilfen bauen oft auf derselben zugrundeliegenden Repräsentation und Bibliotheken auf.
Was dieser Artikel sein (und nicht sein) wird
Dies ist eine geführte Tour durch die Ideen, die Chris Lattner in Gang gesetzt hat: wie LLVM aufgebaut ist, warum die Mittelschicht wichtig ist und wie sie Optimierungen und Multi-Plattform-Unterstützung ermöglicht. Es ist kein Lehrbuch — wir konzentrieren uns auf Intuition und reale Auswirkungen statt auf formale Theorie.
Chris Lattners ursprüngliche Vision
Chris Lattner ist Informatiker und Ingenieur, der Anfang der 2000er-Jahre als Doktorand LLVM aus einer praktischen Frustration heraus startete: Compiler-Technologie war mächtig, aber schwer wiederzuverwenden. Wenn man eine neue Programmiersprache, bessere Optimierungen oder Unterstützung für eine neue CPU wollte, musste man oft an einem eng gekoppelten „All-in-One“-Compiler herumbasteln, bei dem jede Änderung Nebenwirkungen hatte.
Das Problem, das er lösen wollte
Damals waren viele Compiler wie eine einzige, große Maschine gebaut: Der Teil, der die Sprache verstand, der Teil, der optimierte, und der Teil, der Maschinencode erzeugte, waren tief verwoben. Das machte sie zwar effektiv für ihren ursprünglichen Zweck, aber teuer anzupassen.
Lattners Ziel war nicht „ein Compiler für eine Sprache“. Es war eine gemeinsame Grundlage, die viele Sprachen und viele Werkzeuge antreiben konnte — ohne dass alle die gleichen komplexen Teile immer wieder neu schreiben mussten. Die Wette war: Wenn man die Mitte der Pipeline standardisieren könnte, ließe sich an den Rändern schneller innovieren.
Warum „modulare Infrastruktur“ eine frische Idee war
Der wesentliche Wechsel bestand darin, Kompilierung als eine Reihe separierbarer Bausteine mit klaren Schnittstellen zu betrachten. In einer modularen Welt:
- kann ein Sprache-Team sich auf Parsing und entwicklerorientierte Features konzentrieren,
- kann ein Optimierungs-Team Leistung einmal verbessern und breit teilen,
- kann Hardware-Unterstützung hinzugefügt werden, ohne alles stromaufwärts neu zu entwerfen.
Diese Trennung klingt heute offensichtlich, lief damals aber dem entgegen, wie viele produktive Compiler entstanden waren.
Open Source, gebaut, um von anderen genutzt zu werden
LLVM wurde früh als Open Source freigegeben, was wichtig war, weil eine gemeinsame Infrastruktur nur funktioniert, wenn mehrere Gruppen ihr vertrauen, sie inspizieren und erweitern können. Im Laufe der Zeit formten Universitäten, Unternehmen und unabhängige Beitragende das Projekt, indem sie Ziele hinzufügten, Randfälle beheben, die Performance verbessern und neue Werkzeuge drumherum bauen.
Dieser Community-Aspekt war nicht nur Wohlwollen — er war Teil des Designs: Mach den Kern breit nützlich, und es lohnt sich, ihn gemeinsam zu pflegen.
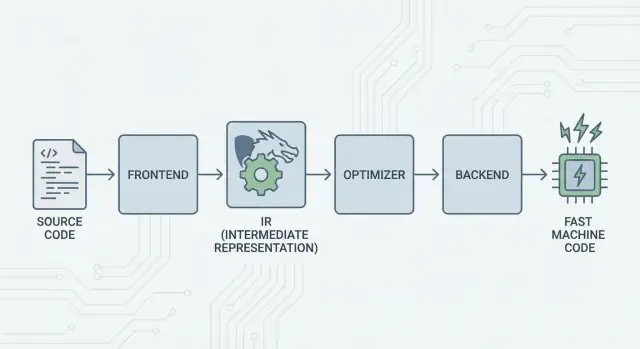
Die große Idee: Frontends, ein gemeinsamer Kern und Backends
Die Kernidee von LLVM ist einfach: Teile einen Compiler in drei Hauptbestandteile, damit viele Sprachen die härteste Arbeit teilen können.
1) Frontends: „Was meinte der Programmierer?“
Ein Frontend versteht eine bestimmte Programmiersprache. Es liest Ihren Quellcode, prüft die Regeln (Syntax und Typen) und wandelt ihn in eine strukturierte Repräsentation um.
Der wichtige Punkt: Frontends müssen nicht jedes CPU-Detail kennen. Ihre Aufgabe ist es, Sprachkonzepte — Funktionen, Schleifen, Variablen — in etwas Universelleres zu übersetzen.
2) Die gemeinsame Mitte: ein gemeinsamer Kern statt N×M Arbeit
Traditionell bedeutete das Erstellen eines Compilers, dieselbe Arbeit immer wieder zu tun:
- Mit N Sprachen und M Chip-Zielen hat man N×M Kombinationen zu unterstützen.
LLVM reduziert das auf:
- N Frontends, die in eine gemeinsame Form übersetzen
- M Backends, die von dieser gemeinsamen Form in Maschinencode übersetzen
Diese „gemeinsame Form“ ist das Zentrum von LLVM: eine gemeinsame Pipeline, in der Optimierungen und Analysen leben. Das ist der große Vereinfacher. Verbesserungen in der Mitte (wie bessere Optimierungen oder bessere Debug-Informationen) kommen vielen Sprachen gleichzeitig zugute, statt in jedem Compiler neu implementiert werden zu müssen.
3) Backends: „Wie bringen wir das auf dieser CPU schnell zum Laufen?“
Ein Backend nimmt die gemeinsame Repräsentation und erzeugt maschinenspezifische Ausgabe: Instruktionen für x86, ARM und so weiter. Hier spielen Details wie Register, Calling Conventions und Instruktionsauswahl eine Rolle.
Ein anschauliches Bild der Pipeline
Man kann Kompilierung als Reiseroute denken:
- Quellcode startet in einem sprachspezifischen Land (Frontend).
- Er überquert eine Grenze in eine gemeinsame, standardisierte „Mittelsprache“ (LLV M’s Kernrepräsentation und Passes).
- Dann nimmt er ein lokales Schienennetz zu einer bestimmten Zielstadt (Backend für Ihre Zielmaschine).
Das Ergebnis ist eine modulare Toolchain: Sprachen können sich darauf konzentrieren, Ideen klar auszudrücken, während der gemeinsame LLVM-Kern daran arbeitet, diese Ideen effizient auf vielen Plattformen auszuführen.
LLVM IR: Die Mittelschicht, die Wiederverwendung ermöglicht
LLVM IR (Zwischenrepräsentation) ist die „gemeinsame Sprache“, die zwischen einer Programmiersprache und dem Maschinencode steht, den Ihre CPU ausführt.
Ein Compiler-Frontend (wie Clang für C/C++) übersetzt Ihren Quellcode in diese gemeinsame Form. Dann arbeiten LLVMs Optimierer und Codegeneratoren auf der IR, nicht auf der Originalsprache. Schließlich wandelt ein Backend die IR in Instruktionen für ein bestimmtes Ziel (x86, ARM usw.) um.
Eine gemeinsame Sprache zwischen Werkzeugen und CPUs
Man kann LLVM IR als sorgfältig gestaltete Brücke betrachten:
- Oben: viele Quellsprachen können sich anschließen (C, C++, Rust, Swift, Julia usw.).
- Unten: viele CPUs können anvisiert werden.
- In der Mitte: dieselben Analyse- und Optimierungswerkzeuge lassen sich wiederverwenden.
Deshalb beschreiben viele Leute LLVM eher als „Compiler-Infrastruktur“ denn als „einen Compiler“. Die IR ist der gemeinsame Vertrag, der diese Infrastruktur wiederverwendbar macht.
Warum IR Wiederverwendung ermöglicht (und Arbeit spart)
Sobald Code in LLVM IR vorliegt, müssen die meisten Optimierungs-Passes nicht wissen, ob er ursprünglich aus C++-Templates, Rust-Iteratoren oder Swift-Generics stammte. Sie interessieren sich hauptsächlich für universelle Ideen wie:
- „Dieser Wert ist konstant.“
- „Diese Berechnung wird wiederholt; können wir das Ergebnis wiederverwenden?“
- „Dieser Speicherzugriff kann sicher verschoben oder entfernt werden.“
Sprachteams müssen also nicht ihren eigenen kompletten Optimierer-Stack aufbauen (und pflegen). Sie können sich aufs Frontend konzentrieren — Parsing, Typprüfung, sprachspezifische Regeln — und LLVM den Großteil der schweren Arbeit übergeben.
Wie es konzeptionell „aussieht"
LLVM IR ist niedrig genug, um sich sauber in Maschinencode abbilden zu lassen, aber immer noch strukturiert genug für Analysen. Konzeptionell besteht es aus einfachen Instruktionen (add, compare, load/store), expliziter Kontrolle des Flusses (Branches) und stark typisierten Werten — eher wie eine aufgeräumte Assembler-Sprache für Compiler als etwas, das Menschen üblicherweise schreiben.
Wie Optimierungen funktionieren (ohne die Mathematik)
Wenn Leute „Compiler-Optimierungen“ hören, stellen sie sich oft mysteriöse Tricks vor. In LLVM sind die meisten Optimierungen besser als sichere, mechanische Umschreibungen des Programms zu verstehen — Transformationen, die die Semantik bewahren, aber versuchen, schneller (oder kleiner) zu werden.
Denken Sie daran wie Bearbeiten, nicht Erfinden
LLVM nimmt Ihren Code (in LLVM IR) und wendet wiederholt kleine Verbesserungen an, ähnlich dem Polieren eines Entwurfs:
- Doppelte Arbeit entfernen: Wenn ein Wert zweimal berechnet wird und sich nichts dazwischen geändert hat, kann LLVM ihn einmal berechnen und das Ergebnis wiederverwenden.
- Offensichtliche Logik vereinfachen: Konstante Ausdrücke können früh gefaltet werden (z. B.
3 * 4zu12), sodass die CPU weniger zur Laufzeit tun muss. - Schleifen straffen: Schleifen-Passes können wiederholte Prüfungen reduzieren, invarianten Code aus der Schleife verschieben oder Muster erkennen, die effizienter ausgeführt werden können.
Diese Änderungen sind bewusst konservativ. Ein Pass führt eine Umschreibung nur durch, wenn er beweisen kann, dass die Umschreibung das Programmverhalten nicht ändert.
Anschauliche Beispiele
Wenn Ihr Programm gedanklich Folgendes tut:
- Liest denselben Konfigurationswert in jeder Iteration einer Schleife
- Führt dieselbe Berechnung an denselben Eingaben an mehreren Stellen aus
- Prüft eine Bedingung, die in einem gegebenen Kontext immer wahr/falsch ist
…versucht LLVM, das in „einmal vorbereiten“, „Ergebnisse wiederverwenden“ und „tote Pfade löschen“ zu verwandeln. Es ist weniger Zauberei und mehr Haushaltsführung.
Der eigentliche Kompromiss: Kompilierzeit vs. Laufzeit
Optimierung ist nicht umsonst: Mehr Analyse und mehr Passes bedeuten in der Regel längere Kompilierzeiten, auch wenn das Endprogramm schneller läuft. Deshalb bieten Toolchains Stufen wie „ein bisschen optimieren“ vs. „aggressiv optimieren“ an.
Profile helfen hier. Mit profile-guided optimization (PGO) führen Sie das Programm aus, sammeln reale Nutzungsdaten und kompilieren dann neu, damit LLVM seine Anstrengungen auf die Pfade richtet, die wirklich zählen — und der Kompromiss vorhersehbarer wird.
Backends: Viele CPUs erreichen, ohne alles neu zu schreiben
Skaliere in deinem Tempo
Wähle Free, Pro, Business oder Enterprise, je nachdem, wie weit du gehen willst.
Ein Compiler hat zwei sehr unterschiedliche Aufgaben. Zuerst muss er Ihren Quellcode verstehen. Dann muss er Maschinencode produzieren, den eine bestimmte CPU ausführen kann. LLVM-Backends konzentrieren sich auf die zweite Aufgabe.
Was ein Backend tatsächlich macht
Man kann sich LLVM IR als „universelles Rezept“ vorstellen, das beschreibt, was das Programm tun soll. Ein Backend wandelt dieses Rezept in die exakten Instruktionen für eine bestimmte Prozessorfamilie um — x86-64 für die meisten Desktops und Server, ARM64 für viele Telefone und neuere Laptops oder spezialisierte Ziele wie WebAssembly.
Konkret ist ein Backend verantwortlich für:
- Instruktionsauswahl: Abbildung von IR-Operationen auf reale CPU-Instruktionen
- Registerallokation: Auswahl, welche Werte in schnellen CPU-Registern vs. im Speicher leben
- Scheduling: Anordnung von Instruktionen, sodass die CPU sie effizient ausführen kann
- Assembly-/Objektausgabe: Erzeugung von Code, den Linker und OS verstehen
Warum gemeinsame Infrastruktur neue Hardwareunterstützung erleichtert
Ohne gemeinsame Mitte müsste jede Sprache all das für jede CPU neu implementieren — enormer Aufwand und ständige Wartungsarbeit.
LLVM dreht das um: Frontends (wie Clang) erzeugen einmal LLVM IR, und Backends erledigen die „letzte Meile“ pro Ziel. Die Unterstützung neuer Hardware bedeutet meist, ein Backend zu schreiben (oder ein bestehendes zu erweitern), statt jeden Compiler neu zu schreiben.
Portabilität für Teams, die auf vielen Plattformen ausliefern
Für Projekte, die auf Windows/macOS/Linux, auf x86 und ARM oder sogar im Browser laufen müssen, ist das Backend-Modell von LLVM ein praktischer Vorteil. Sie können einen Codebase und weitgehend eine Build-Pipeline behalten und dann durch Auswahl eines anderen Backends (oder Cross-Kompilierung) umschalten.
Diese Portabilität ist ein Grund, warum LLVM überall auftaucht: Es geht nicht nur um Geschwindigkeit — es geht auch darum, wiederholte, plattformspezifische Compilerarbeit zu vermeiden, die Teams verlangsamt.
Clang: Wo viele Entwickler LLVM erstmals spüren
Clang ist das C-, C++- und Objective-C-Frontend, das an LLVM anschließt. Wenn LLVM der gemeinsame Motor ist, der optimieren und Maschinencode erzeugen kann, ist Clang der Teil, der Ihre Quelldateien liest, die Sprachregeln versteht und das, was Sie geschrieben haben, in eine Form übersetzt, mit der LLVM arbeiten kann.
Warum Clang aufgefallen ist
Viele Entwickler entdeckten LLVM nicht durch das Lesen von Compiler-Papieren — sie stießen das erste Mal darauf, als sie den Compiler wechselten und das Feedback sich plötzlich verbesserte.
Clangs Diagnosen sind dafür bekannt, lesbarer und spezifischer zu sein. Anstelle vager Fehler weist es oft auf das genaue Token hin, das das Problem ausgelöst hat, zeigt die relevante Zeile und erklärt, was erwartet wurde. Das zählt im täglichen Arbeiten, weil die „kompilieren, fixen, wiederholen“-Schleife weniger frustrierend wird.
Clang stellt auch klare, gut dokumentierte Schnittstellen bereit (insbesondere über libclang und das breitere Clang-Tooling-Ökosystem). Das machte es Editoren, IDEs und anderen Entwicklertools leichter, tiefe Sprachverständnis-Integration zu erreichen, ohne einen C/C++-Parser neu zu schreiben.
Wie es im Alltag auftaucht
Sobald ein Werkzeug zuverlässig Ihren Code parsen und analysieren kann, erhalten Sie Features, die sich weniger wie Textbearbeitung und mehr wie Arbeiten mit einem strukturierten Programm anfühlen:
- Präzise Code-Navigation ("Gehe zur Definition", "Finde Verwendungen") selbst in großen, makrointensiven C++-Projekten
- Refactoring-Unterstützung, die Symbole und Bereiche versteht, nicht nur Suchen-und-Ersetzen
- Inline-Hinweise und Quick-Fixes, die von echter Syntax- und Typinformation getrieben werden
Deshalb ist Clang oft der erste Berührungspunkt mit LLVM: Hier entstehen praktische Verbesserungen der Entwicklererfahrung. Selbst wenn Sie nie an LLVM IR oder Backends denken, profitieren Sie davon, wenn Ihre Editor-Autovervollständigung schlauer ist, Ihre statischen Prüfungen präziser sind und Ihre Build-Fehler leichter zu beheben sind.
Warum viele moderne Sprachen auf LLVM bauen
LLVM reizt Sprache-Teams aus einem einfachen Grund: Es erlaubt ihnen, sich auf die Sprache zu konzentrieren, statt Jahre damit zu verbringen, einen voll optimierenden Compiler neu zu erfinden.
Schnellere Time-to-Market
Eine neue Sprache zu bauen umfasst bereits Parsing, Typprüfung, Diagnosen, Paket-Tooling, Dokumentation und Community-Support. Wenn Sie zusätzlich einen produktionsreifen Optimierer, Codegenerator und Plattformunterstützung von Grund auf neu erstellen müssen, verzögert das die Veröffentlichung — manchmal um Jahre.
LLVM bietet einen sofort nutzbaren Kompilierkern: Registerallokation, Instruktionsauswahl, ausgereifte Optimierungs-Passes und Ziele für gängige CPUs. Teams können ein Frontend anschließen, das ihre Sprache in LLVM IR absenkt, und dann die bestehende Pipeline nutzen, um nativen Code für macOS, Linux und Windows zu erzeugen.
Hohe Performance (ohne „Heldentaten")
LLVMs Optimierer und Backends sind Ergebnis langfristiger Ingenieursarbeit und stetiger Erprobung in der Praxis. Das führt zu einer soliden Basisperformance für Sprachen, die es übernehmen — oft von Anfang an gut genug und verbesserungsfähig, wenn LLVM selbst besser wird.
Deshalb haben mehrere bekannte Sprachen darauf aufgebaut:
- Swift nutzt LLVM, um stark optimierte native Binaries über Apple-Plattformen hinweg zu erzeugen.
- Rust verlässt sich auf LLVM für Codegenerierung und viele Architekturziele.
- Julia verwendet LLVM, um schnelle numerische Codes zu ermöglichen, einschließlich Laufzeitkompilierung für spezialisierte Workloads.
Nicht jede Sprache braucht LLVM
Die Wahl von LLVM ist ein Kompromiss, kein Muss. Manche Sprachen priorisieren winzige Binaries, extrem schnelle Kompilierung oder enge Kontrolle über die gesamte Toolchain. Andere haben bereits etablierte Compiler (z. B. GCC-basierte Ökosysteme) oder bevorzugen einfachere Backends.
LLVM ist populär, weil es ein starker Standardpfad ist — nicht, weil es der einzige richtige Weg wäre.
JIT und Laufzeitkompilierung: Schnelle Feedback-Schleifen
Plane, bevor du codest
Lege zuerst Features und Aufgaben fest, dann lässt du Koder.ai das benötigte Grundgerüst erzeugen.
„Just-in-time“ (JIT)-Kompilierung lässt sich am einfachsten als Kompilieren zur Laufzeit denken. Statt alles im Voraus in ein finales ausführbares Programm zu übersetzen, wartet eine JIT-Engine, bis ein Codeabschnitt tatsächlich benötigt wird, und kompiliert diesen Teil on-the-fly — oft unter Nutzung echter Laufzeitinformationen (wie die genauen Typen und Größen der Daten), um bessere Entscheidungen zu treffen.
Warum JIT sich so schnell anfühlen kann
Weil nicht alles im Voraus kompiliert werden muss, liefern JIT-Systeme schnelles Feedback für interaktive Arbeit. Sie schreiben oder erzeugen einen Code-Schnipsel, führen ihn sofort aus, und das System kompiliert nur das, was gerade nötig ist. Wenn derselbe Code öfter läuft, kann die JIT den kompilierten Code cachen oder „heiße" Abschnitte aggressiver nachoptimieren.
Wo Laufzeitkompilierung praktisch hilft
JIT eignet sich, wenn Workloads dynamisch oder interaktiv sind:
- REPLs und Notebooks: Schnelle Auswertung von Snippets bei dennoch nativer Ausführung für schwere Schleifen.
- Plugins und Erweiterungen: Anwendungen können Benutzer-Code zur Laufzeit laden und für die Host-CPU kompilieren.
- Dynamische Workloads: Wenn Eingaben stark variieren, kann Laufzeit-Profiling zeigen, welche Pfade Optimierung verdienen.
- Wissenschaftliches Rechnen: Generierte Kernel (für eine bestimmte Matrixgröße, Modellform oder Hardwareeigenschaft) können bei Bedarf kompiliert werden.
LLVMs Rolle (ohne Hype)
LLVM macht nicht automatisch jedes Programm schneller und ist kein vollständiger JIT von sich aus. Es stellt einen Werkzeugkasten bereit: eine wohl definierte IR, viele Optimierungs-Passes und Codegenerierung für viele CPUs. Projekte können JIT-Engines auf Basis dieser Bausteine bauen und das richtige Gleichgewicht zwischen Startzeit, Spitzenleistung und Komplexität wählen.
Performance, Vorhersehbarkeit und reale Kompromisse
LLVM-basierte Toolchains können extrem schnellen Code erzeugen — aber „schnell“ ist keine einzige, stabile Eigenschaft. Es hängt von der genauen Compiler-Version, der Ziel-CPU, den Optimierungs-Einstellungen und sogar davon ab, was Sie den Compiler über Ihr Programm annehmen lassen.
Warum „gleicher Quelltext, unterschiedliche Ergebnisse" vorkommt
Zwei Compiler können denselben C/C++- (oder Rust-, Swift-) Quelltext lesen und trotzdem unterschiedlich schnellen Maschinencode erzeugen. Ein Teil davon ist beabsichtigt: Jeder Compiler hat seine eigenen Optimierungs-Passes, Heuristiken und Standardeinstellungen. Selbst innerhalb von LLVM können Clang 15 und Clang 18 unterschiedliche Inlining-Entscheidungen treffen, unterschiedliche Schleifen vektorisieren oder Instruktionen anders schedulen.
Es kann auch an undefiniertem Verhalten und unspezifiziertem Verhalten in der Sprache liegen. Wenn Ihr Programm versehentlich auf etwas vertraut, das der Standard nicht garantiert (z. B. Überlauf bei vorzeichenbehafteten Ganzzahlen in C), können verschiedene Compiler — oder unterschiedliche Flags — „optimieren" und so das Ergebnis ändern.
Determinismus, Debug-Builds und Release-Builds
Menschen erwarten oft, dass Kompilierung deterministisch ist: gleiche Eingaben, gleiche Ausgaben. In der Praxis kommt man nahe heran, aber nicht immer identische Binärartefakte. Build-Pfade, Zeitstempel, Link-Reihenfolge, profilgesteuerte Daten und LTO-Optionen können das Endprodukt beeinflussen.
Der praktischere Unterschied ist Debug vs. Release. Debug-Builds schalten typischerweise viele Optimierungen aus, um schrittweises Debuggen und lesbare Stacktraces zu erhalten. Release-Builds erlauben aggressive Transformationen, die Code umordnen, Funktionen inlinen und Variablen entfernen können — hervorragend für Performance, aber manchmal schwerer zu debuggen.
Praktischer Rat: Messen, nicht raten
Behandle Performance als Messproblem:
- Führe Benchmarks auf repräsentativer Hardware und mit realistischen Datensätzen durch.
- Wärme Caches auf und führe mehrere Iterationen aus.
- Vergleiche Builds mit expliziten Flags (z. B. Änderung von
-O2zu-O3, Aktivierung/Deaktivierung von LTO oder Auswahl eines Targets mit-march).
Kleine Flag-Änderungen können die Performance in beide Richtungen verschieben. Der sicherste Workflow ist: Formuliere eine Hypothese, messe sie und halte Benchmarks nahe an dem, was Ihre Nutzer tatsächlich ausführen.
Tooling jenseits der Kompilierung: Analyse, Debugging und Sicherheit
Eigene Domain nutzen
Setze deine App auf eine eigene Domain, wenn es Zeit ist, sie zu teilen.
LLVM wird oft als Compiler-Werkzeugkasten beschrieben, aber viele Entwickler spüren seine Auswirkungen durch Werkzeuge, die um die Kompilierung herum liegen: Analyzer, Debugger und Sicherheitschecks, die während Builds und Tests eingeschaltet werden.
Analyse und Instrumentierung als "Add-ons"
Weil LLVM eine wohl definierte Zwischenrepräsentation (IR) und eine Pass-Pipeline bereitstellt, ist es naheliegend, zusätzliche Schritte zu bauen, die Code zu anderen Zwecken inspizieren oder umschreiben als nur für Geschwindigkeit. Ein Pass kann Zähler für Profiling einfügen, verdächtige Speicheroperationen markieren oder Coverage-Daten sammeln.
Der Punkt ist, dass sich diese Features integrieren lassen, ohne dass jedes Sprache-Team dieselbe Infrastruktur neu bauen muss.
Sanitizer: Fehler nahe an der Quelle finden
Clang und LLVM popularisierten eine Familie von Laufzeit-"Sanitizern", die Programme instrumentieren, um häufige Bug-Klassen während des Testens zu erkennen — denken Sie an Out-of-Bounds-Speicherzugriffe, Use-After-Free, Data-Races und Muster undefinierten Verhaltens. Sie sind kein magischer Schutz und verlangsamen Programme typischerweise, daher werden sie meist in CI und Pre-Release-Tests eingesetzt. Aber wenn sie auslösen, zeigen sie oft eine präzise Quellstelle und eine gut lesbare Erklärung, was genau passiert ist — genau das, was Teams bei der Jagd nach intermittierenden Abstürzen brauchen.
Bessere Diagnosen = schnelleres Onboarding
Werkzeugqualität bedeutet auch Kommunikation. Klare Warnungen, umsetzbare Fehlermeldungen und konsistente Debug-Informationen reduzieren den "Mystery-Faktor" für Neueinsteiger. Wenn die Toolchain erklärt, was passiert ist und wie man es behebt, verbringen Entwickler weniger Zeit damit, Compiler-Quirks auszuwählen, und mehr Zeit damit, den Code zu lernen.
LLVM garantiert nicht von sich aus perfekte Diagnosen oder Sicherheit, aber es bietet eine gemeinsame Grundlage, die diese entwicklerorientierten Werkzeuge praktisch macht, wartbar zu bauen und über Projekte hinweg zu teilen.
Wann man LLVM verwenden sollte (und wann nicht)
LLVM ist am besten als "Bau-deinen-eigenen-Compiler- und-Tooling-Kit" zu verstehen. Diese Flexibilität treibt viele moderne Toolchains an — aber sie macht es auch nicht immer zur richtigen Antwort.
Wann LLVM gut passt
LLVM glänzt, wenn Sie ernsthafte Compiler-Ingenieursarbeit wiederverwenden möchten, statt sie neu zu erfinden.
Wenn Sie eine neue Programmiersprache bauen, kann LLVM Ihnen eine erprobte Optimierungs-Pipeline, ausgereifte Codegenerierung für viele CPUs und einen Weg zu guten Debug-Informationen geben.
Wenn Sie plattformübergreifende Anwendungen ausliefern, reduziert LLVMs Backend-Ökosystem die Arbeit, die nötig ist, um verschiedene Architekturen zu unterstützen. Sie konzentrieren sich auf Ihre Sprache oder Produktlogik statt auf verschiedene Codegeneratoren.
Wenn Ihr Ziel Entwickler-Tooling ist — Linter, statische Analyse, Code-Navigation, Refactoring —, dann ist LLVM (und das breitere Ökosystem darum) eine starke Grundlage, weil der Compiler bereits Struktur und Typinformation „versteht".
Wann es übertrieben sein kann
LLVM kann schwergewichtig sein, wenn Sie an sehr kleinen Embedded-Systemen arbeiten, bei denen Build-Größe, Speicher und Kompilierzeit strikt begrenzt sind.
Es kann auch ungeeignet sein für sehr spezialisierte Pipelines, in denen Sie keine allgemeingültigen Optimierungen wollen oder Ihre „Sprache" eher ein festes DSL ist mit direkter Abbildung auf Maschinencode.
Eine einfache Checkliste
Stellen Sie sich diese drei Fragen:
- Müssen wir mehrere Plattformen/CPUs jetzt oder bald anvisieren?
- Profitieren wir von bestehenden Optimierungen und Debug-Infos, statt alles selbst zu bauen?
- Wollen wir einen Weg ins Ökosystem (Tooling, Integrationen, Einstellbarkeit) mehr als einen minimalen, maßgeschneiderten Compiler?
Wenn die meisten Antworten „Ja" sind, ist LLVM gewöhnlich eine praktische Wette. Wenn Sie hauptsächlich den kleinsten, einfachsten Compiler wollen, der ein enges Problem löst, kann ein leichterer Ansatz gewinnen.
Eine praktische Anmerkung für Produktteams: LLVM-Vorteile, ohne Compiler-Experten werden zu müssen
Die meisten Teams wollen LLVM nicht als eigenes Projekt „adoptieren". Sie wollen Ergebnisse: plattformübergreifende Builds, schnelle Binaries, gute Diagnosen und verlässliches Tooling.
Deshalb sind Plattformen wie Koder.ai in diesem Zusammenhang interessant. Wenn Ihr Workflow zunehmend von höherer Automatisierung getrieben wird (Planung, Generierung von Gerüstrukturen, iteratives Arbeiten in engem Zyklus), profitieren Sie indirekt von LLVM durch die darunterliegenden Toolchains — egal ob Sie eine React-Web-App, ein Go-Backend mit PostgreSQL oder einen Flutter-Mobil-Client bauen. Koder.ais Chat-getriebener "vibe-coding"-Ansatz fokussiert auf schnelleres Ausliefern von Produktfeatures, während moderne Compiler-Infrastruktur (LLVM/Clang und Co., wo anwendbar) im Hintergrund die unspektakuläre Arbeit von Optimierung, Diagnose und Portabilität übernimmt.