28. Dez. 2025·7 Min
Claude Code für Performance-Untersuchungen: ein gemessener Workflow
Nutze Claude Code für Performance-Untersuchungen mit einer wiederholbaren Schleife: messen, Hypothese bilden, wenig ändern und vor dem Ausrollen erneut messen.
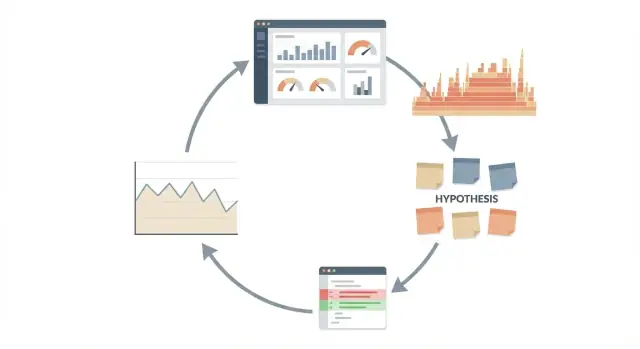
Nutze Claude Code für Performance-Untersuchungen mit einer wiederholbaren Schleife: messen, Hypothese bilden, wenig ändern und vor dem Ausrollen erneut messen.
Performance-Bugs laden zum Raten ein. Jemand merkt, dass eine Seite sich langsam anfühlt oder eine API timeouts hat, und der schnellste Reflex ist, Code zu „bereinigen“, Caching hinzuzufügen oder eine Schleife umzuschreiben. Das Problem: „fühlt sich langsam an" ist keine Metrik, und „sauberer" ist nicht gleich schneller.
Ohne Messung verbrauchen Teams Stunden, um am falschen Ort Änderungen vorzunehmen. Der heiße Pfad kann in der Datenbank, im Netzwerk oder in einer unerwarteten Allokation liegen, während das Team Code poliert, der kaum zur Laufzeit beiträgt. Schlimmer noch: eine Änderung, die schlau aussieht, kann die Performance verschlechtern — extra Logging in einer engen Schleife, ein Cache, der den Speicherdruck erhöht, oder Parallelisierung, die Lock-Contention erzeugt.
Raten gefährdet auch die Korrektheit. Wenn du Code änderst, um ihn zu beschleunigen, kannst du Ergebnisse, Fehlerbehandlung, Reihenfolge oder Retries verändern. Wenn du Korrektheit und Geschwindigkeit nicht zusammen erneut prüfst, kannst du in einem Benchmark „gewinnen“ und gleichzeitig einen Bug ausliefern.
Behandle Performance wie ein Experiment, nicht wie eine Debatte. Die Schleife ist einfach und wiederholbar:
Viele Verbesserungen sind moderat: 8 % p95-Latenz sparen, 50 MB Peak-Speicher reduzieren oder eine Datenbankabfrage entfernen. Diese Gewinne zählen — aber nur, wenn sie gemessen, verifiziert und reproduzierbar sind.
Das funktioniert am besten als Schleife, nicht als einmalige „mach schneller“-Anfrage. Die Schleife hält dich ehrlich, weil jede Aktion zu einem Beweis und einer Zahl zurückführt, die du beobachten kannst.
Eine klare Reihenfolge:
Jeder Schritt schützt vor einer anderen Art Selbsttäuschung. Erst messen verhindert, dass du etwas „behebst“, das kein echtes Problem war. Eine geschriebene Hypothese hindert dich daran, fünf Dinge auf einmal zu ändern und dann zu raten, was geholfen hat. Minimale Änderungen reduzieren das Risiko, Verhalten zu brechen oder neue Engpässe einzuführen. Neu messen fängt Placebo-Effekte ein (z. B. schnellerer Lauf wegen warmem Cache) und deckt Regressionsprobleme auf.
„Fertig" ist kein Gefühl. Es ist ein Ergebnis: die Zielmetrik hat sich in die richtige Richtung bewegt, und die Änderung hat keine offensichtlichen Regressionen verursacht (Fehler, mehr Speicher, schlechteres p95, langsamere nahegelegene Endpoints).
Zu wissen, wann man aufhört, gehört zum Workflow. Hör auf, wenn die Gewinne abflachen, die Metrik für Nutzer gut genug ist oder die nächste Idee großen Refactor-Aufwand für wenig Nutzen verlangt. Performance-Arbeit hat immer Opportunitätskosten; die Schleife hilft dir, Zeit dort auszugeben, wo es sich lohnt.
Wenn du fünf Dinge gleichzeitig misst, weißt du am Ende nicht, was sich verbessert hat. Wähle eine primäre Metrik für die Untersuchung und behandle alles andere als unterstützende Signale. Für viele nutzerorientierte Probleme ist das die Latenz. Für Batch-Arbeit kann es Durchsatz, CPU-Zeit, Speicher oder sogar Kosten pro Lauf sein.
Sei spezifisch beim Szenario. "Die API ist langsam" ist zu vage. "POST /checkout mit einem typischen Warenkorb von 3 Artikeln" ist messbar. Halte die Inputs stabil, damit die Zahlen etwas bedeuten.
Schreibe die Basislinie und Umgebungsdetails auf, bevor du Code änderst: Datensatzgröße, Maschinentyp, Build-Modus, Feature-Flags, Konkurrenz und Aufwärmzustand. Diese Basislinie ist dein Anker. Ohne sie kann jede Änderung wie Fortschritt aussehen.
Bei Latenz verlasse dich auf Perzentile, nicht nur auf den Mittelwert. p50 zeigt das typische Erlebnis, während p95 und p99 die schmerzhaften Ausreißer offenbaren, über die Nutzer klagen. Eine Änderung, die p50 verbessert, aber p99 verschlechtert, kann sich trotzdem langsamer anfühlen.
Entscheide vorab, was „bedeutend" bedeutet, damit du kein Rauschen feierst:
Sind diese Regeln festgelegt, kannst du Ideen testen, ohne die Zielpfosten zu verschieben.
Fange mit dem einfachsten Signal an, dem du vertraust. Ein einzelnes Timing um eine Anfrage herum kann dir sagen, ob du ein echtes Problem hast und wie groß es ungefähr ist. Tieferes Profiling nutzt du, wenn du erklären musst, warum etwas langsam ist.
Gute Beweise kommen oft aus einer Mischung von Quellen:
Nutze einfache Metriken, wenn die Frage lautet „ist es langsamer und um wie viel?" Profiling ist sinnvoll, wenn die Frage lautet „wo geht die Zeit hin?" Wenn die p95-Latenz nach einem Deploy verdoppelt, beginne mit Timings und Logs, um die Regression zu bestätigen und einzugrenzen. Wenn Timings zeigen, dass der Großteil der Verzögerung in deinem App-Code liegt (nicht in der DB), kann ein CPU-Profiler oder ein Flame-Graph die genaue Funktion zeigen, die gewachsen ist.
Halte Messungen sicher. Sammle, was du zum Debuggen brauchst, nicht Nutzerinhalte. Bevorzuge Aggregate (Dauern, Zählungen, Größen) statt roher Payloads und redactiere IDs standardmäßig.
Rauschen ist real — nimm mehrere Samples und notiere Ausreißer. Führe dieselbe Anfrage 10–30 Mal aus und zeichne Median und p95 statt eines einzelnen besten Laufs auf.
Schreibe das genaue Testrezept auf, damit du es nach Änderungen wiederholen kannst: Umgebung, Datensatz, Endpoint, Request-Body-Größe, Konkurrenzlevel und wie du die Ergebnisse erfasst hast.
Beginne mit einem benennbaren Symptom: "p95-Latenz springt von 220 ms auf 900 ms bei Traffic-Spitzen", "CPU liegt bei 95 % auf zwei Kernen" oder "Speicher wächst um 200 MB pro Stunde." Vage Symptome wie "es fühlt sich langsam an" führen zu zufälligen Änderungen.
Übersetze dann das Gemessene in einen verdächtigen Bereich. Ein Flame-Graph kann zeigen, dass viel Zeit im JSON-Encoding liegt, ein Trace kann einen langsamen Call-Path zeigen, oder DB-Statistiken können eine Query offenbaren, die die Gesamtzeit dominiert. Wähle den kleinsten Bereich, der den Großteil der Kosten erklärt: eine Funktion, eine einzelne SQL-Abfrage oder einen externen Call.
Eine gute Hypothese ist ein Satz, testbar und mit einer Vorhersage verknüpft. Du bittest um Hilfe, eine Idee zu testen — nicht darum, dass ein Tool alles magisch schneller macht.
Verwende dieses Format:
Beispiel: "Weil das Profil zeigt, dass 38 % der CPU in SerializeResponse liegen, verursacht das Anlegen eines neuen Puffers pro Request CPU-Spitzen. Wenn wir einen Puffer wiederverwenden, sollte die p95-Latenz um etwa 10–20 % sinken und die CPU unter gleicher Last um ~15 % fallen."
Halte dich ehrlich, indem du Alternativen benennst, bevor du Code änderst. Vielleicht liegt das Problem tatsächlich upstream, an Lock-Contention, einer Änderung der Cache-Miss-Rate oder an einem Rollout, das die Payload-Größe erhöht hat.
Schreibe 2–3 alternative Erklärungen auf und wähle dann diejenige, die deine Beweise am besten stützt. Wenn deine Änderung die Metrik nicht bewegt, hast du bereits die nächste Hypothese parat.
Claude ist bei Performance-Arbeit am nützlichsten, wenn du ihn wie einen sorgfältigen Analysten behandelst, nicht wie ein Orakel. Halte jede Empfehlung an das Gebot gebunden, was du gemessen hast, und sorge dafür, dass jeder Schritt widerlegbar ist.
Gib ihm echte Inputs, keine vage Beschreibung. Füge kleine, fokussierte Beweise ein: eine Profil-Zusammenfassung, ein paar Log-Zeilen um die langsame Anfrage, einen Query-Plan und den konkreten Code-Pfad. Beilagen sollten auch "Vorher"-Zahlen enthalten (p95-Latenz, CPU-Zeit, DB-Zeit), damit die Ausgangslage klar ist.
Bitte es, zu erklären, was die Daten nahelegen und was nicht. Fordere konkurrierende Erklärungen. Ein hilfreicher Prompt endet mit: "Gib mir 2–3 Hypothesen, und für jede nenne, wie man sie falsifizieren kann." Das verhindert, dass man sich an die erstbeste plausible Erklärung klammert.
Bevor du irgendetwas änderst, bitte um das kleinste Experiment, das die führende Hypothese validiert. Halte es schnell und umkehrbar: eine Timer-Messung um eine Funktion, eine Profiler-Flag setzen oder eine DB-Abfrage mit EXPLAIN laufen lassen.
Wenn du eine strikte Struktur für die Ausgabe willst, fordere:
Wenn es keine spezifische Metrik, keinen Ort und kein erwartetes Ergebnis benennt, bist du wieder beim Raten.
Hast du Beweise und eine Hypothese, widerstehe dem Drang, "alles aufzuräumen." Performance-Arbeit ist am einfachsten vertrauenswürdig, wenn die Codeänderung klein und leicht rückgängig zu machen ist.
Ändere eine Sache auf einmal. Wenn du eine Query anpasst, Caching hinzufügst und eine Schleife refaktorierst, weißt du nicht, was geholfen hat (oder geschadet). Einfaktor-Änderungen machen die nächste Messung aussagekräftig.
Schreibe vor der Änderung auf, was du in Zahlen erwartest. Beispiel: "p95-Latenz sollte von 420 ms auf unter 300 ms fallen, und DB-Zeit sollte um ~100 ms sinken." Wenn das Ziel verfehlt wird, lernst du schnell, dass die Hypothese schwach oder unvollständig war.
Halt die Änderungen reversibel:
"Minimal" heißt nicht „trivially“. Es bedeutet fokussiert: cachiere ein teures Funktionsresultat, entferne eine wiederholte Allokation in einer engen Schleife oder unterlasse Arbeit für Requests, die sie nicht brauchen.
Füge leichte Timings um den vermuteten Engpass hinzu, damit du siehst, was sich bewegt hat. Ein Timestamp vor und nach einem Aufruf (geloggt oder als Metrik erfasst) kann bestätigen, ob deine Änderung das langsame Stück getroffen hat oder die Zeit nur verschoben wurde.
Nach einer Änderung führe exakt dasselbe Szenario aus, das du für die Basislinie verwendet hast: gleiche Inputs, gleiche Umgebung und gleiche Lastform. Wenn dein Test Caches oder Aufwärmen benötigt, mache das explizit (z. B.: "erster Lauf kalt, nächste 5 Läufe warm"). Sonst „entdeckst“ du Verbesserungen, die nur Glück waren.
Vergleiche Ergebnisse mit derselben Metrik und denselben Perzentilen. Mittelwerte können Schmerzen verbergen — beobachte p95 und p99, plus Durchsatz und CPU-Zeit. Führe genug Wiederholungen durch, um zu sehen, ob sich die Zahlen einpendeln.
Bevor du feierst, prüfe auf Regressionsarten, die nicht in der Schlagzeile stehen:
Dann entscheide auf Basis der Beweise, nicht der Hoffnung. Wenn die Verbesserung echt ist und du keine Regressionen eingeführt hast, behalte die Änderung. Wenn die Ergebnisse gemischt oder verrauscht sind, revertiere und formuliere eine neue Hypothese oder isoliert die Änderung weiter.
Wenn du auf einer Plattform wie Koder.ai arbeitest, kann ein Snapshot vor dem Experiment die Rücksetzung zu einem Schritt machen, was mutigere Tests sicherer macht.
Schreibe schließlich auf, was du gelernt hast: Basislinie, Änderung, neue Zahlen und Fazit. Diese kurze Aufzeichnung verhindert, dass die nächste Runde dieselben Sackgassen wiederholt.
Performance-Arbeit gerät meist aus dem Ruder, wenn die Verbindung zwischen dem, was du gemessen hast, und dem, was du geändert hast, verloren geht. Halte eine saubere Beweiskette, damit du mit Gewissheit sagen kannst, was Dinge besser oder schlechter gemacht hat.
Die üblichen Fehler:
Ein kleines Beispiel: Ein Endpoint wirkt langsam, also optimierst du den Serializer, weil er im Profil heiß aussieht. Beim Retest benutzt du jedoch einen kleineren Datensatz — es sieht schneller aus. In Produktion verschlechtert sich p99, weil die Datenbank weiter der Engpass ist und deine Änderung die Payload-Größe erhöht hat.
Wenn du Claude Code um Vorschläge bittest, halte die Zügel kurz. Fordere 1–2 minimale Änderungen, die zu den bereits gesammelten Beweisen passen, und bestehe auf einem Re-Measure-Plan, bevor du einen Patch akzeptierst.
Geschwindigkeitsansprüche zerfallen, wenn der Test verschwommen ist. Bevor du feierst, stelle sicher, dass du erklären kannst, was du gemessen hast, wie du es gemessen hast und was du geändert hast.
Beginne damit, eine Metrik zu benennen und die Basislinie mit Umgebungsangaben aufzuschreiben (Hardware, Konfiguration, Daten, Build-Modus, Feature-Flags, Cache-Status, Konkurrenz). Wenn du das Setup morgen nicht reproduzieren kannst, hast du keine Basislinie.
Checkliste:
Wenn die Zahlen besser aussehen, mache einen schnellen Regressions-Check. Prüfe Korrektheit (gleiche Outputs), Fehlerrate und Timeouts. Achte auf Nebeneffekte wie höheren Speicher, CPU-Spitzen, langsameren Startup oder mehr DB-Last. Eine Änderung, die p95 verbessert, aber den Speicher verdoppelt, ist vielleicht das falsche Tauschverhältnis.
Ein Team meldet, dass GET /orders in Dev okay wirkt, aber in Staging bei moderater Last langsamer wird. Nutzer klagen über Timeouts, während die durchschnittliche Latenz noch „ok" aussieht — eine klassische Falle.
Zuerst die Basislinie: Unter einem stabilen Lasttest (gleicher Datensatz, gleiche Konkurrenz, gleiche Dauer) misst du:
Sammle Beweise. Ein schneller Trace zeigt, dass der Endpoint eine Hauptquery für Bestellungen ausführt und dann pro Bestellung verwandte Items einzeln abfragt. Die JSON-Antwort ist groß, aber die DB-Zeit dominiert.
Formuliere eine prüfbare Hypothesenliste:
Bitte um eine minimale Änderung, die zur stärksten Evidenz passt: entferne eine offensichtliche N+1-Call-Quelle, indem du Items in einer einzigen Query per Order-IDs holst (oder füge den fehlenden Index hinzu, wenn der Query-Plan einen Full-Scan zeigt). Halte es revertierbar und in einem fokussierten Commit.
Messe mit demselben Lasttest neu. Ergebnisse:
Entscheidung: Fix ausliefern (klarer Gewinn), dann eine zweite Runde starten, die sich auf die verbleibende Lücke und die CPU-Spitzen konzentriert, da DB nicht mehr der Hauptlimitierer ist.
Der schnellste Weg, besser bei Performance-Untersuchungen zu werden, ist, jeden Durchlauf wie ein kleines, wiederholbares Experiment zu behandeln. Wenn der Prozess konsistent ist, werden Ergebnisse leichter vertrauenswürdig, vergleichbar und teilbar.
Eine einfache einseitige Vorlage hilft:
Entscheide, wo diese Notizen leben, damit sie nicht verschwinden. Ein gemeinsamer Ort ist wichtiger als das perfekte Tool: ein Repo-Ordner neben dem Service, ein Team-Dokument oder Ticket-Notizen. Wichtig ist Auffindbarkeit. Jemand sollte "p95-Latenz-Anstieg nach Caching-Änderung" noch Monate später finden können.
Mache sichere Experimente zur Gewohnheit. Nutze Snapshots und einfache Rollbacks, damit du Ideen ohne Angst testen kannst. Wenn du mit Koder.ai baust, kann Planning Mode ein praktischer Ort sein, um den Messplan zu skizzieren, die Hypothese zu definieren und die Änderung zu begrenzen, bevor du einen engen Diff generierst und neu misst.
Setze eine Cadenz. Warte nicht auf Vorfälle. Füge nach Änderungen wie neuen Queries, Endpoints, größeren Payloads oder Dependency-Upgrades kleine Performance-Checks hinzu. Ein 10-minütiger Baseline-Check jetzt kann einen Tag Rätselraten später sparen.
Beginne mit einer Zahl, die zur Beschwerde passt — meist p95-Latenz für einen konkreten Endpoint und Eingabetyp. Lege eine Baseline unter identischen Bedingungen fest (Datengröße, Konkurrenz, warm/kalter Cache), ändere dann nur eine Sache und messe erneut.
Wenn du die Baseline nicht reproduzieren kannst, misst du noch nicht — du rätst nur.
Eine nützliche Baseline enthält:
Schreibe das auf, bevor du Code anfässt, damit du das Ziel nicht verschiebst.
Percentile zeigen die Nutzererfahrung besser als ein Mittelwert. p50 ist das „typische“ Erlebnis, aber Nutzer beschweren sich über die langsame Spitze — also p95/p99.
Wenn p50 besser wird, aber p99 schlechter, kann sich das System trotzdem langsamer anfühlen, obwohl der Durchschnitt gut aussieht.
Nutze einfache Timings/Logs, wenn du wissen willst: „Ist es langsamer und um wie viel?“ Profiling nutzt du, wenn du fragen musst: „Wohin geht die Zeit?“
Ein praktischer Ablauf: bestätige die Regression mit Timings, und profile erst, wenn die Verlangsamung echt und eingegrenzt ist.
Wähle eine primäre Metrik und behandle den Rest als Absicherung. Ein übliches Set ist:
So vermeidest du, dass du auf einem Chart „gewinnst“, während du heimlich Timeouts, Speicherwachstum oder schlechtere Tail-Latenz verursachst.
Formuliere eine ein-Satz-Hypothese, die an Beweise gebunden ist und eine Vorhersage macht:
Wenn du weder den Beweis noch die erwartete Metrikbewegung benennen kannst, ist die Hypothese noch nicht testbar.
Mach es klein, fokussiert und einfach rückgängig zu machen:
Kleine Diffs machen die Messung aussagekräftig und verringern die Gefahr, beim Optimieren Verhalten zu brechen.
Führe exakt dasselbe Testrezept aus (gleiche Inputs, Umgebung, Load-Form). Dann prüfe auf Regressionsarten, die nicht in der Schlagzeile stehen:
Wenn die Ergebnisse rauschen, nimm mehr Stichproben oder setze zurück und verfeinere das Experiment.
Gib Claude Code konkrete Beweise und zwinge es, testgetrieben zu bleiben:
Wenn die Ausgabe keine spezifische Metrik und keinen Re-Test-Plan enthält, landest du wieder beim Raten.
Hör auf, wenn:
Performance-Arbeit hat Opportunitätskosten. Die Schleife (messen → hypothesieren → ändern → neu messen) hilft dir, Zeit dort zu investieren, wo Zahlen es rechtfertigen.