Ein Observability-Tool hilft dabei, konkrete Fragen zu einem System zu beantworten — typischerweise durch Charts, Logs oder Abfrageergebnisse. Es ist etwas, das man „benutzt“, wenn ein Problem auftritt.
Eine Observability-Plattform ist breiter: sie standardisiert, wie Telemetrie gesammelt wird, wie Teams sie explorieren und wie Vorfälle Ende-zu-Ende bearbeitet werden. Sie wird zu etwas, das Ihre Organisation jeden Tag „betreibt“, über viele Services und Teams hinweg.
Von Charts zu Ergebnissen
Die meisten Teams starten mit Dashboards: CPU-Charts, Error-Rate-Graphen, vielleicht ein paar Log-Suchen. Das ist nützlich, aber das eigentliche Ziel sind nicht schönere Charts — sondern schnellere Erkennung und schnellere Behebung.
Ein Plattformwechsel passiert, wenn Sie aufhören zu fragen: „Können wir das grafisch darstellen?“ und stattdessen fragen:
- Findet der On-Call-Ingenieur die Root Cause in Minuten, nicht Stunden?
- Können wir den richtigen Alarm automatisch an das richtige Team routen?
- Können wir wiederkehrende Vorfallsmuster in wiederholbare Playbooks verwandeln?
Das sind ergebnisorientierte Fragen, und sie erfordern mehr als Visualisierung. Sie erfordern gemeinsame Datenstandards, konsistente Integrationen und Workflows, die Telemetrie mit Aktionen verbinden.
Die drei Säulen, die Sie wirklich kaufen
Wenn Plattformen wie die Datadog Observability-Plattform sich entwickeln, ist die „Produktoberfläche“ nicht nur Dashboards. Es sind drei ineinandergreifende Säulen:
- Telemetrie: Logs, Metriken und Traces, die konsistent gesammelt und gut gelabelt werden, damit man ihnen vertraut.
- Integrationen: vorgefertigte Verbindungen, die die Einführung erleichtern und die Abdeckung ohne eigenen Kleber erweitern.
- Workflows: Incident Response, Alert-Routing, Ownership und Nachverfolgung — damit Lernen sich kumuliert.
Ein einzelnes Dashboard hilft einem Team. Eine Plattform wird stärker mit jedem Service, der integriert wird, mit jeder Integration, die hinzugefügt wird, und mit jedem Workflow, der standardisiert wird. Im Laufe der Zeit summiert sich das zu weniger blinden Flecken, weniger duplizierten Tools und kürzeren Incidents — weil jede Verbesserung wiederverwendbar wird, nicht einmalig.
Telemetrie wird zur Produktoberfläche
Wenn Observability von „einem Tool, das wir abfragen“ zu „einer Plattform, auf der wir aufbauen“ wird, hört Telemetrie auf, roher Abgasstrom zu sein, und wird zur Produktoberfläche. Was Sie emittieren — und wie konsistent Sie es emittieren — bestimmt, was Ihre Teams sehen, automatisieren und vertrauen können.
Die zentralen Telemetrie-Typen (und wofür sie da sind)
Die meisten Teams standardisieren sich auf eine kleine Menge Signale:
- Metriken: numerische Trends über Zeit (Latenz, Fehlerrate, Auslastung).
- Logs: detaillierte, menschenlesbare Aufzeichnungen für Investigation und Audit.
- Traces: Request-Pfade über Services, um zu finden, wo Zeit und Fehler passieren.
- Events: diskrete "etwas hat sich geändert"-Einträge (Deploys, Feature Flags, Incidents).
- Profiles: CPU-/Memory-Verhalten, um teure Codepfade zu identifizieren.
Einzeln ist jedes Signal nützlich. Zusammen werden sie zu einer einheitlichen Oberfläche Ihres Systems — das, was Sie in Dashboards, Alerts, Incident-Timelines und Postmortems sehen.
Konsistenz schlägt Volumen
Ein häufiger Fehler ist, „alles“ zu sammeln, aber inkonsistent zu benennen. Wenn ein Service userId verwendet, ein anderer uid und ein dritter gar nichts logged, können Sie Daten nicht zuverlässig slice-en, Signale nicht joinen oder wiederverwendbare Monitore bauen.
Teams erzielen mehr Wert, wenn sie sich auf einige Konventionen einigen — Service-Namen, Environment-Tags, Request-IDs und ein Standardset an Attributen — als durch rein höhere Ingestionsraten.
Was hohe Kardinalität wirklich bedeutet (und warum sie wichtig ist)
Felder mit hoher Kardinalität sind Attribute mit vielen möglichen Werten (wie user_id, order_id oder session_id). Sie sind mächtig, um Probleme zu debuggen, die "nur einen Kunden betreffen", können aber Kosten erhöhen und Abfragen verlangsamen, wenn sie überall verwendet werden.
Der Plattformansatz ist intentional: behalten Sie hohe Kardinalität dort, wo sie klaren investigativen Wert liefert, und vermeiden Sie sie an Stellen, die für globale Aggregationen gedacht sind.
Einheitlicher Kontext reduziert Korrelationsaufwand
Der Gewinn ist Geschwindigkeit. Wenn Metriken, Logs, Traces, Events und Profiles denselben Kontext teilen (Service, Version, Region, Request ID), verbringen Ingenieure weniger Zeit damit, Beweise zusammenzuflicken, und mehr Zeit damit, das eigentliche Problem zu beheben. Anstatt zwischen Tools zu springen und zu raten, folgen Sie einem Faden vom Symptom zur Root Cause.
Von der Datensammlung zur Telemetrie-Strategie
Die meisten Teams starten Observability, indem sie "Daten reinbekommen." Das ist nötig, aber noch keine Strategie. Eine Telemetrie-Strategie sorgt dafür, dass Onboarding schnell bleibt und Ihre Daten konsistent genug sind, um gemeinsame Dashboards, verlässliche Alerts und aussagekräftige SLOs anzutreiben.
Übliche Ingestionspfade (und wofür sie gut sind)
Datadog erhält Telemetrie typischerweise über einige praxistaugliche Wege:
- Agents auf Hosts/VMs: der schnellste Weg, Infrastrukturmetriken, Logs und APM mit minimalen Code-Änderungen zu sammeln.
- Collector und Gateways (z. B. OpenTelemetry Collector): nützlich, wenn Sie zentrale Kontrolle, Multi-Destination-Routing, Redaction oder Standardverarbeitung wollen.
- APIs und direkte SDKs: hilfreich für benutzerdefinierte Events, Business-Metriken oder wenn ein Agent nicht praktikabel ist.
- Serverless-Integrationen: praktisch für managed Runtimes, bei denen Sie den Host nicht kontrollieren, aber Sie sollten bewusst entscheiden, was Sie emittieren.
Geschwindigkeit vs. Standardisierung: Entscheiden, was Sie optimieren
Am Anfang gewinnt Geschwindigkeit: Teams installieren einen Agent, schalten ein paar Integrationen an und sehen sofort Wert. Das Risiko ist, dass jedes Team eigene Tags, Service-Namen und Log-Formate erfindet — was Cross-Service-Views unübersichtlich und Alerts unzuverlässig macht.
Eine einfache Regel: Erlaube „Quick Start“-Onboarding, aber fordere „Standardisierung innerhalb von 30 Tagen“. Das gibt Teams Schwung, ohne Chaos festzuschreiben.
Eine leichte Namens- und Tagging-Konvention
Sie brauchen kein riesiges Taxonomie-Set. Beginnen Sie mit einem kleinen Satz, den jedes Signal (Logs, Metriken, Traces) tragen muss:
service: kurz, stabil, kleingeschrieben (z. B. checkout-api)env: prod, staging, devteam: Identifier des verantwortlichen Teams (z. B. payments)version: Deploy-Version oder Git-SHA
Wenn Sie noch eins wollen, das sich schnell auszahlt, fügen Sie tier (frontend, backend, data) hinzu, um das Filtern zu vereinfachen.
Sampling, Retention und kostenbewusste Defaults
Kostenprobleme entstehen meist durch zu großzügige Defaults:
- Traces: starten Sie mit Head-based Sampling für hochvolumige Endpunkte; behalten Sie 100% für kritische Flows.
- Logs: standardmäßig „Errors + wichtige Business-Events“, dann selektiv Info/Debug mit zeitlich begrenzter Aufbewahrung hinzufügen.
- Retention: behalten Sie hochauflösende Daten kürzer (Tage), rollen Sie Rollups oder Schlüsselaggregationen länger (Wochen/Monate) vor.
Das Ziel ist nicht weniger zu sammeln — sondern konsequent die richtigen Daten zu sammeln, damit Sie die Nutzung skalieren können, ohne überrascht zu werden.
Integrationen als der eigentliche Distributionskanal
Viele denken bei Observability-Tools an „etwas, das man installiert.“ In der Praxis verbreiten sie sich durch eine Organisation wie gute Connectoren: eine Integration nach der anderen.
Was eine „Integration“ tatsächlich bedeutet
Eine Integration ist nicht nur ein Datenrohr. Sie hat in der Regel drei Teile:
- Datenquellen: Metriken, Logs, Traces, Events und Topologie aus Systemen ziehen, die Sie bereits betreiben (Cloud-Services, Kubernetes, Datenbanken, CI/CD, SaaS-Tools).
- Anreicherung: Kontext hinzufügen, damit Telemetrie sofort nutzbar ist — Service-Namen, Environments, Ownership-Tags, Team-Routing, Deploy-Versionen und Cloud-Metadata.
- Aktionen: mit dem, was Sie lernen, etwas tun — Tickets erstellen, On-Call benachrichtigen, Deploys annotieren, Ressourcen skalieren oder Runbooks auslösen.
Der letzte Teil ist es, der Integrationen zur Distribution macht. Wenn das Tool nur liest, ist es ein Dashboard-Ziel. Wenn es auch schreibt, wird es Teil der täglichen Arbeit.
Warum Integrationen die Adoption beschleunigen
Gute Integrationen reduzieren die Setup-Zeit, weil sie sinnvolle Defaults mitliefern: vorgefertigte Dashboards, empfohlene Monitore, Parsing-Regeln und gängige Tags. Anstatt dass jedes Team sein eigenes „CPU-Dashboard“ oder „Postgres-Alerts“ erfindet, erhalten Sie einen standardisierten Ausgangspunkt, der Best Practices widerspiegelt.
Teams passen immer noch an — aber sie passen von einer gemeinsamen Basis aus an. Diese Standardisierung ist wichtig, wenn Sie Tools konsolidieren: Integrationen schaffen wiederholbare Muster, die neue Services kopieren können, was das Wachstum beherrschbar hält.
Priorisieren Sie bidirektionale Integrationen
Bei der Bewertung fragen Sie: Kann es Signale aufnehmen und Aktionen auslösen? Beispiele sind das Öffnen von Incidents im Ticketing-System, das Aktualisieren von Incident-Channels oder das Anhängen eines Trace-Links zurück in einen PR- oder Deploy-View. Bidirektionale Setups sind der Punkt, an dem Workflows sich „nativ“ anfühlen.
Eine einfache Shortlist-Methode
Starten Sie klein und vorhersehbar:
- Kritische Infrastruktur zuerst (Cloud-Provider, Kubernetes, Load Balancer, Kern-Datenbanken).
- Dann die Deploy-Pipeline (CI/CD, Feature Flags, Release-Tracking), damit Telemetrie mit Änderungen übereinstimmt.
- Fügen Sie teamweise SaaS (Queues, Caches, Auth, Payments) hinzu, sobald Tagging- und Ownership-Konventionen stabil sind.
Als Faustregel: priorisieren Sie Integrationen, die sofort die Incident-Response verbessern, nicht die, die nur weitere Charts hinzufügen.
Standardansichten: Services, Dashboards und Monitore
Standardansichten sind der Punkt, an dem eine Observability-Plattform im Alltag brauchbar wird. Wenn Teams dasselbe mentale Modell teilen — was ein „Service“ ist, was „gesund“ bedeutet und wo man zuerst klickt — wird Debugging schneller und Übergaben sauberer.
Beginnen Sie mit Golden Signals (und machen Sie sie sichtbar)
Wählen Sie eine kleine Menge „Golden Signals“ und mapen Sie jedes auf ein konkretes, wiederverwendbares Dashboard. Für die meisten Services sind das:
- Latenz (p95/p99 für Schlüsselendpunkte)
- Traffic (Requests pro Sekunde, verarbeitete Jobs)
- Errors (Rate und Top-Error-Typen)
- Saturation (CPU, Memory, Queue-Depth, DB-Verbindungen)
Das Entscheidende ist Konsistenz: ein Dashboard-Layout, das für alle Services funktioniert, schlägt zehn clevere, maßgeschneiderte Dashboards.
Service-Kataloge schaffen gemeinsame Ownership
Ein Service-Katalog (auch ein leichter) verwandelt „jemand sollte das anschauen“ in „dieses Team ist verantwortlich“. Wenn Services mit Ownern, Environments und Abhängigkeiten getaggt sind, kann die Plattform einfache Fragen sofort beantworten: Welche Monitore gelten für diesen Service? Welche Dashboards sollte ich öffnen? Wer wird paged?
Diese Klarheit reduziert Ping-Pong in Slack während Incidents und hilft neuen Engineers beim Self-Service.
Bausteine, die skalieren
Behandeln Sie diese als Standard-Artefakte, nicht als optionale Extras:
- Dashboards für Golden Signals und Schlüsselabhängigkeiten
- Monitore an SLOs oder nutzerbeeinträchtigenden Symptomen gebunden
- Notebooks für Untersuchungen und Post-Incident-Timelines
- Runbooks (verlinkt von Monitoren) für die ersten 5–10 Minuten der Reaktion
Anti-Pattern, die Sie vermeiden sollten
Vanity-Dashboards (schöne Charts ohne Entscheidungsbasis), One-off-Alerts (schnell erstellt, nie getunt) und undokumentierte Queries (nur eine Person versteht den magischen Filter) erzeugen Plattform-Lärm. Wenn eine Abfrage wichtig ist, speichern Sie sie, benennen Sie sie und hängen Sie sie an einen Service-View, den andere finden können.
Workflows: Wo Observability geschäftlichen Wert liefert
Workflow zuerst entwerfen
Nutzen Sie den Planungsmodus, um Alarm → Verantwortlicher → Runbook abzubilden, bevor Sie Code erzeugen.
Observability wird nur dann „real“ für das Business, wenn sie die Zeit zwischen Problem und sicherer Behebung verkürzt. Das passiert durch Workflows — wiederholbare Pfade, die Sie vom Signal zur Aktion und von der Aktion zum Lernen führen.
Die Incident-Reise: Alert → Triage → Kommunikation → Mitigation → Lernen
Ein skalierbarer Workflow ist mehr als jemanden zu page-en.
Ein Alert sollte eine fokussierte Triage-Schleife eröffnen: Impact bestätigen, betroffenen Service identifizieren und den relevantesten Kontext (aktuelle Deploys, Abhängigkeits-Health, Error-Spikes, Saturation-Signale) ziehen. Von dort macht Kommunikation aus einem technischen Ereignis eine koordinierte Reaktion — wer owns den Incident, was sehen Nutzer und wann kommt das nächste Update?
Mitigation ist der Punkt, an dem Sie „sichere Maßnahmen“ griffbereit haben wollen: Feature Flags, Traffic Shifting, Rollback, Rate Limits oder bekannte Workarounds. Abschließend schließt Lernen den Kreis mit einer leichten Review, die festhält, was sich geändert hat, was funktionierte und was als nächstes automatisiert werden sollte.
Plattformen wie die Datadog Observability-Plattform liefern Mehrwert, wenn sie geteilte Arbeit unterstützen: Incident-Channels, Status-Updates, Handoffs und konsistente Timelines. ChatOps-Integrationen können Alerts in strukturierte Gespräche verwandeln — Incident erstellen, Rollen zuweisen und Schlüsselgraphs/Queries direkt in den Thread posten, sodass alle dieselben Beweise sehen.
Was ein gutes Runbook tatsächlich enthält
Ein nützliches Runbook ist kurz, pointiert und sicher. Es sollte enthalten: das Ziel (Service wiederherstellen), klare Owner/On-Call-Rotationen, Schritt-für-Schritt-Checks, Links zu den richtigen Dashboards/Monitoren und „sichere Aktionen“, die das Risiko reduzieren (mit Rollback-Schritten). Wenn es nicht sicher ist, es um 3 Uhr morgens auszuführen, ist es nicht fertig.
Verknüpfen Sie Incidents mit Deploys und Changes
Die Root Cause findet man schneller, wenn Incidents automatisch mit Deploys, Konfigurationsänderungen und Feature-Flag-Flips korreliert werden. Machen Sie "Was hat sich geändert?" zu einer erstklassigen Ansicht, damit die Triage mit Beweisen und nicht mit Mutmaßungen beginnt.
SLOs und Error Budgets als Betriebssystem für Teams
Was ein SLO ist (und warum es „grüne Dashboards" schlägt)
Ein SLO (Service Level Objective) ist ein einfaches Versprechen über die Benutzererfahrung über ein Zeitfenster — z. B. „99,9% der Requests sind innerhalb von 30 Tagen erfolgreich" oder „p95 Page Loads unter 2 Sekunden".
Das übertrifft ein "grünes Dashboard", weil Dashboards oft Systemgesundheit (CPU, Memory, Queue-Depth) zeigen, statt Kundenimpact. Ein Service kann grün aussehen und dennoch Nutzer enttäuschen (z. B. wenn eine Abhängigkeit timeouts verursacht oder Fehler in einer Region konzentriert sind). SLOs zwingen das Team, das zu messen, was Nutzer tatsächlich spüren.
Error Budgets: eine gemeinsame Sprache für Risiko
Ein Error Budget ist die erlaubte Menge an Unzuverlässigkeit, die Ihr SLO impliziert. Wenn Sie 99,9% Erfolg über 30 Tage versprechen, haben Sie etwa 43 Minuten Fehlerzeit in diesem Fenster.
Das schafft ein praktisches Betriebssystem für Entscheidungen:
- Budget gesund: Features ausliefern, Experimente fahren, moderates Risiko eingehen.
- Budget verbrennt: Releases verlangsamen, Fokus auf Zuverlässigkeitsarbeit, Änderungen reduzieren.
- Budget erschöpft: riskante Deploys pausieren und die Hauptursachen der Fehler beheben.
Statt in einem Release-Meeting über Meinungen zu streiten, diskutieren Sie eine Zahl, die alle sehen können.
Auf Burn Rate alarmieren, nicht auf jeden Spike
SLO-Alerting funktioniert am besten, wenn Sie auf Burn Rate alarmieren (wie schnell Sie das Error Budget verbrauchen), nicht auf rohe Fehlerzahlen. Das reduziert Rauschen:
- Ein kurzer Spike, der sich selbst erholt, muss niemanden page-en.
- Ein anhaltendes Problem, das das Budget bald aufbrauchen würde, löst einen klaren, handlungsfähigen Alarm aus.
Viele Teams nutzen zwei Fenster: ein schnelles Burn (schnell page) und ein langsames Burn (Ticket/Benachrichtigung).
Ein leichtes SLO-Starter-Set für einen typischen Web-Service
Starten Sie klein — zwei bis vier SLOs, die Sie tatsächlich nutzen werden:
- Verfügbarkeit: % erfolgreicher Requests (z. B. HTTP 2xx/3xx) über 30 Tage.
- Latenz: p95 Request-Latenz unter einer Schwelle (getrennt für Read vs Write falls nötig).
- Checkout / kritischer Endpunkt: Erfolgsrate für den Pfad, der dem Business am wichtigsten ist.
- Freshness (falls relevant): Hintergrundjobs schließen innerhalb von X Minuten ab.
Sobald diese stabil sind, können Sie erweitern — ansonsten bauen Sie nur eine weitere Dashboard-Wand. Für mehr siehe /blog/slo-monitoring-basics.
Alerting, das skaliert, ohne Menschen auszubrennen
SLOs in den Mittelpunkt stellen
Prototyp eines SLO‑Dashboards, das die Burn‑Rate hervorhebt und Alerts an Nutzerauswirkung koppelt.
Alerting ist der Punkt, an dem viele Observability-Programme ins Stocken geraten: Die Daten sind da, die Dashboards sehen toll aus, aber die On-Call-Erfahrung wird laut und nicht vertrauenswürdig. Wenn Leute lernen, Alerts zu ignorieren, verliert Ihre Plattform ihre Fähigkeit, das Business zu schützen.
Warum Alert-Fatigue passiert (und warum Signale dupliziert werden)
Die häufigsten Ursachen sind erstaunlich konsistent:
- Zu viele „FYI“-Alerts, die keine Aktion erfordern.
- Schwellenwerte, die über Services kopiert werden ohne Kontext (die gleiche CPU-Regel für sehr unterschiedliche Workloads).
- Mehrere Tools oder Teams alarmieren für dasselbe Symptom — z. B. ein APM-Fehler-Rate-Monitor und ein log-basierter Fehler-Monitor, die beide pagen.
- Rauschende Metriken (spiky Latenz-Perzentile, Autoscaling-Effekte), die Schwankungen statt echte Probleme triggern.
In Datadog-Begriffen erscheinen duplizierte Signale oft, wenn Monitore aus verschiedenen "Surfaces" (Metriken, Logs, Traces) erstellt werden, ohne zu entscheiden, welches das kanonische Page-Signal ist.
Routing: Ownership, Severity und Ruhezeiten
Skalierendes Alerting beginnt mit Routing-Regeln, die für Menschen Sinn ergeben:
- Ownership: Jeder Monitor sollte einen klaren Owner (Service/Team) und einen Eskalationspfad haben.
- Severity: Paging nur für dringende, nutzerbeeinträchtigende Probleme; Tickets oder Chat-Benachrichtigungen für geringere Severity.
- Maintenance Windows: Geplante Deploys, Migrationen und Lasttests sollten keine Pages generieren.
Einfache Regeln, die Alerts handhabbar halten
Ein nützliches Default ist: auf Symptome alarmieren, nicht bei jedem Metrikwechsel. Pagen Sie bei Dingen, die Nutzer spüren (Fehlerrate, fehlgeschlagene Checkouts, anhaltende Latenz, SLO-Burn), nicht bei „Inputs“ (CPU, Pod-Anzahl), außer sie sagen zuverlässig Impact voraus.
Eine Review-Cadence, die wirklich funktioniert
Machen Sie Alert-Hygiene zum Teil des Betriebs: monatliches Pruning und Tuning von Monitoren. Entfernen Sie Monitore, die nie feuern, passen Sie Schwellen an, die zu häufig auslösen, und fassen Sie Duplikate zusammen, sodass jeder Incident eine primäre Page plus kontextuelle Unterstützung hat.
Gut gemacht wird Alerting zu einem Workflow, dem Leute vertrauen — nicht zu einem Hintergrundrauschen.
Observability als "Plattform" zu bezeichnen bedeutet nicht nur, Logs, Metriken, Traces und viele Integrationen an einem Ort zu haben. Es impliziert auch Governance: die Konsistenz und Leitplanken, die das System nutzbar halten, wenn Anzahl der Teams, Services, Dashboards und Alerts multipliziert.
Ohne Governance kann Datadog (oder jede Observability-Plattform) in ein lautes Scrapbook abdriften — hunderte leicht unterschiedliche Dashboards, inkonsistente Tags, unklare Ownership und Alerts, denen niemand vertraut.
Governance ist ein People-and-Process-Problem
Gute Governance klärt, wer was entscheidet und wer verantwortlich ist, wenn die Plattform unordentlich wird:
- Platform-Team: definiert Standards (Tagging, Naming, Dashboard-Patterns), stellt geteilte Komponenten bereit und pflegt Integrationen.
- Service-Owner: sind für die Telemetrie-Qualität ihrer Services verantwortlich und halten Monitore sinnvoll.
- Security & Compliance: legt Regeln für Datenhandling fest (PII, Retention, Zugriffsbeschränkungen) und überprüft risikoreiche Integrationen.
- Leadership: stimmt Governance mit Geschäftsprioritäten ab (Zuverlässigkeitsziele, Incident-Erwartungen) und finanziert die Arbeit.
Praktische Kontrollen, die Observability-Sprawl verhindern
Ein paar leichte Kontrollen bringen mehr als lange Policy-Dokumente:
- Vorlagen per Default: Starter-Dashboards und Monitor-Pakete pro Servicetyp (API, Queue-Worker, DB), damit Teams konsistent beginnen.
- Tagging-Policy: ein kleines Pflicht-Set (z. B.
service, env, team, tier) plus klare Regeln für optionale Tags. Wo möglich in CI erzwingen.
- Zugriff und Ownership: rollenbasierter Zugriff für sensitive Daten und die Forderung, einen Owner für Dashboards und Monitore zu haben.
- Review-Flows für hochwirksame Änderungen: Monitore, die people pagen, Log-Pipelines, die Kosten beeinflussen, und Integrationen, die sensitive Daten ziehen, sollten Prüf-Schritte haben.
Wiederverwenden schlägt Neuerfinden
Der schnellste Weg, Qualität zu skalieren, ist, funktionierende Lösungen zu teilen:
- Geteilte Libraries: interne Pakete oder Snippets, die Logging-Felder, Trace-Attribute und gemeinsame Metriken standardisieren.
- Wiederverwendbare Dashboards und Monitore: ein zentrales Katalog von „goldenen“ Dashboards und Monitor-Vorlagen, die Teams klonen und anpassen können.
- Versionierte Standards: behandeln Sie wichtige Assets wie Code — dokumentieren Sie Änderungen, deprecate alte Patterns und kündigen Updates an einem Ort an.
Wenn Sie wollen, dass das bleibt, machen Sie den geregelten Pfad zum einfachen Pfad — weniger Klicks, schnelleres Setup und klarere Ownership.
Sobald Observability sich wie eine Plattform verhält, folgen meist Plattform-Ökonomien: je mehr Teams sie annehmen, desto mehr Telemetrie wird produziert und desto nützlicher wird sie.
Das erzeugt ein Flywheel:
- Mehr onboardete Services → bessere Cross-Service-Sichtbarkeit und Korrelation
- Bessere Sichtbarkeit → schnellere Diagnose, weniger wiederkehrende Incidents, mehr Vertrauen ins Tool
- Mehr Vertrauen → mehr Teams instrumentieren und integrieren → noch mehr Daten
Der Haken ist, dass dieselbe Schleife auch Kosten erhöht. Mehr Hosts, Container, Logs, Traces, Synthetics und Custom Metrics können schneller wachsen als Ihr Budget, wenn Sie es nicht bewusst managen.
Praktische Kostenhebel (ohne Signale zu töten)
Sie müssen nicht „alles abschalten“. Formen Sie zuerst die Daten:
- Sampling: behalten Sie hochauflösende Traces für kritische Endpunkte, sample aggressiver anderswo.
- Retention-Tiers: kurze Retention für rohe, hochvolumige Logs; längere Retention für kuratierte Security-/Audit-Streams.
- Log-Filtering und Parsing: dropen Sie offensichtlichen Lärm früh (Health-Checks, statische Asset-Requests) und standardisieren Parsing, damit Sie nach Attributen routen können.
- Metrik-Aggregation: bevorzugen Sie Perzentile, Raten und Rollups gegenüber unbeschränkter Kardinalität (z. B. pro-User-IDs).
KPIs, die Kosten mit Ergebnissen verbinden
Verfolgen Sie eine kleine Menge Kennzahlen, die zeigen, ob die Plattform sich auszahlt:
- MTTD (Mean Time To Detect)
- MTTR (Mean Time To Resolve)
- Incident-Anzahl und wiederkehrende Incidents (gleiche Root Cause)
- Deploy-Frequenz (und Change-Failure-Rate, falls verfolgt)
Ein vierteljährlicher „Wert vs. Kosten“-Review (ohne Schuldzuweisung)
Machen Sie es zu einer Produkt-Review, nicht zu einer Prüfung. Bringen Sie Platform-Owner, ein paar Service-Teams und Finance zusammen. Reviewen Sie:
- Top-Kostentreiber nach Datentyp (Logs/Metriken/Traces) und nach Team
- Top-Wins: verkürzte Incidents, vermiedene Ausfälle, entfernte Toil
- 2–3 vereinbarte Aktionen (z. B. Sampling-Regeln anpassen, Retention-Tiering hinzufügen, eine laute Integration fixen)
Das Ziel ist gemeinsame Verantwortung: Kosten werden Input für bessere Instrumentierungs-Entscheidungen, nicht der Grund, das Observing zu stoppen.
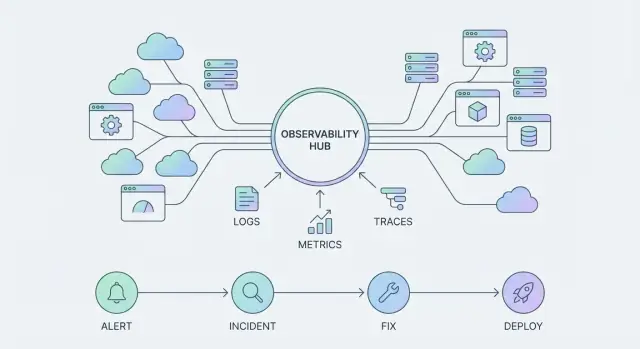
Observability‑Hub bereitstellen
Erstellen Sie einen schlanken Observability‑Hub, der Services mit Verantwortlichen, Dashboards und Runbooks verknüpft.
Wenn Observability zur Plattform wird, hört Ihr "Tool-Stack" auf, eine Sammlung von Punktlösungen zu sein, und wird zu gemeinsam genutzter Infrastruktur. Dieser Wandel macht Tool-Sprawl mehr als nur lästig: er schafft duplizierte Instrumentierung, inkonsistente Definitionen (was zählt als Error?) und höhere On-Call-Last, weil Signale über Logs, Metriken, Traces und Incidents nicht zueinander passen.
Konsolidierung heißt nicht automatisch „ein Vendor für alles“. Es bedeutet weniger Systeme der Wahrheit für Telemetrie und Response, klarere Ownership und eine kleinere Menge Orte, die Menschen bei einem Ausfall durchsuchen müssen.
Was Konsolidierung tatsächlich lösen kann
Tool-Sprawl versteckt Kosten meist an drei Stellen: Zeit, die für das Hüpfen zwischen UIs verloren geht, fragile Integrationen, die man pflegen muss, und fragmentierte Governance (Naming, Tags, Retention, Zugriff). Eine stärker konsolidierte Plattform kann Kontextwechsel reduzieren, Service-Views standardisieren und Incident-Workflows wiederholbar machen.
Eine Entscheidungs-Checkliste (kurz, aber praktisch)
Wenn Sie Ihren Stack (inkl. Datadog oder Alternativen) bewerten, prüfen Sie:
- Must-have-Integrationen: Cloud-Provider, Kubernetes, CI/CD, Incident-Management, Paging und zentrale Datenspeicher — plus alle Business-Systeme, ohne die Sie nicht ausliefern können.
- Workflows: Können Sie von Alert → Owner → Runbook → Timeline → Postmortem ohne Copy/Paste gehen?
- Governance: Tagging-Standards, Zugriffskontrollen, Retention und Leitplanken gegen Dashboard/Monitor-Sprawl.
- Preismodell: Was treibt Kosten (Hosts, Container, ingested Logs, indexierte Traces)? Können Sie Wachstum ohne Überraschungen prognostizieren?
Führen Sie ein Pilotprojekt mit klarem Erfolgs-Metrik durch
Wählen Sie ein oder zwei Services mit echtem Traffic. Definieren Sie eine einzige Erfolgsmetrik wie „Time to identify root cause sinkt von 30 Minuten auf 10“ oder „reduziere laute Alerts um 40%“. Instrumentieren Sie nur das Nötige und reviewen Sie Ergebnisse nach zwei Wochen.
Halten Sie interne Docs zentralisiert, damit Lernen kumuliert — verlinken Sie das Pilot-Runbook, Tagging-Regeln und Dashboards an einem Ort (z. B. /blog/observability-basics als interner Startpunkt).
Ein praktischer Adoptionsplan, den Sie kopieren können
Sie "rollen" Datadog nicht einmal aus. Sie starten klein, setzen Standards früh und skalieren dann, was funktioniert.
30/60/90-Tage-Rollout
Tage 0–30: Onboard (schnell Wert beweisen)
Wählen Sie 1–2 kritische Services und eine kundenorientierte Journey. Instrumentieren Sie Logs, Metriken und Traces konsistent und verbinden Sie die Integrationen, auf die Sie bereits setzen (Cloud, Kubernetes, CI/CD, On-Call).
Tage 31–60: Standardisieren (wiederholbar machen)
Machen Sie aus dem, was Sie gelernt haben, Defaults: Service-Naming, Tagging, Dashboard-Templates, Monitor-Naming und Ownership. Erstellen Sie Golden-Signals-Views (Latenz, Traffic, Errors, Saturation) und ein minimales SLO-Set für die wichtigsten Endpunkte.
Tage 61–90: Skalieren (ohne Chaos auszuweiten)
Onboarden Sie zusätzliche Teams mit denselben Templates. Führen Sie Governance ein (Tag-Regeln, erforderliche Metadaten, Review-Prozess für neue Monitore) und beginnen Sie, Kosten vs. Nutzung zu tracken, damit die Plattform gesund bleibt.
Wo Koder.ai pragmatisch reinpasst
Sobald Sie Observability als Plattform behandeln, wollen Sie meist kleine "Glue"-Apps darum herum: eine Service-Katalog-UI, ein Runbook-Hub, eine Incident-Timeline-Seite oder ein internes Portal, das Owner → Dashboards → SLOs → Playbooks verlinkt.
Das sind leichte interne Tools, die Sie schnell auf Koder.ai bauen können — eine Vibe-Coding-Plattform, mit der Sie Web-Apps per Chat generieren (häufig React im Frontend, Go + PostgreSQL im Backend), mit Source-Export und Deployment/Hosting-Unterstützung. In der Praxis nutzen Teams sie, um operative Oberflächen zu prototypen und zu liefern, die Governance und Workflows erleichtern, ohne ein vollständiges Produktteam vom Roadmap abzuziehen.
Quick Wins, die sich in Woche eins liefern lassen
- Top-10-Monitore für Verfügbarkeit, Fehlerrate, Latenz, Saturation und Schlüsselabhängigkeiten
- Deployment-Marker (aus CI/CD) auf Dashboards und Traces zur sofortigen Change-Korrelation
- Incident-Template: was passiert ist, Impact, Timeline, Owner, Links zu Dashboards/Queries, nächste Schritte
Training, das tatsächlich hängen bleibt
Führen Sie zwei 45-minütige Sessions durch: (1) „Wie wir hier abfragen“ mit gemeinsamen Query-Pattern (nach Service, env, Region, Version) und (2) „Troubleshooting-Playbook“ mit einfachem Ablauf: Impact bestätigen → Deploy-Marker prüfen → auf Service eingrenzen → Traces inspizieren → Abhängigkeits-Health prüfen → Rollback/Mitigation entscheiden.
Copy/Paste-Checklist