03. Okt. 2025·7 Min
Daten außen vs. innen – Pat Hellands Lektionen für Apps
Pat Hellands Konzept „Daten außen vs. innen“: Setze klare Grenzen, entwerfe idempotente Aufrufe und gleiche Zustände bei Netzwerkfehlern ab.
Pat Hellands Konzept „Daten außen vs. innen“: Setze klare Grenzen, entwerfe idempotente Aufrufe und gleiche Zustände bei Netzwerkfehlern ab.
Wenn du eine App baust, ist es leicht, sich vorzustellen, dass Anfragen ordentlich nacheinander und in der richtigen Reihenfolge eintreffen. Reale Netze verhalten sich nicht so. Ein Nutzer tippt „Bezahlen“ zweimal, weil der Bildschirm eingefroren ist. Eine mobile Verbindung bricht direkt nach dem Tastendruck ab. Ein Webhook kommt verspätet oder doppelt an. Manchmal kommt er gar nicht.
Pat Hellands Idee von Daten außen vs. innen ist eine klare Art, mit diesem Durcheinander zu denken.
„Außen" ist alles, was dein System nicht kontrolliert. Dort kommunizierst du mit anderen Personen und Systemen, und die Zustellung ist unsicher: HTTP‑Requests von Browsern und mobilen Apps, Nachrichten aus Queues, Drittanbieter‑Webhooks (Zahlungen, E‑Mails, Versand) und Retries, die von Clients, Proxies oder Hintergrundjobs angestoßen werden.
Außen: gehe davon aus, dass Nachrichten verzögert, dupliziert oder in falscher Reihenfolge ankommen können. Selbst wenn etwas „meist zuverlässig“ ist, entwerfe für den Tag, an dem es das nicht ist.
„Innen" ist das, was dein System verlässlich machen kann. Es ist der dauerhafte Zustand, den du speicherst, die Regeln, die du durchsetzt, und die Fakten, die du später beweisen kannst:
Innen schützt Invarianten. Wenn du „eine Zahlung pro Bestellung“ versprichst, muss dieses Versprechen innen durchgesetzt werden, weil dem Außen nicht vertraut werden kann.
Die Denkweise ist einfach: erwarte keine perfekte Zustellung oder perfekte Zeitsteuerung. Behandle jede Außen‑Interaktion wie einen unzuverlässigen Vorschlag, der wiederholt werden kann, und lass das Innen sicher darauf reagieren.
Das gilt selbst für kleine Teams und einfache Apps. Beim ersten Netzwerkfehler, der zu einer doppelten Abbuchung oder einer festhängenden Bestellung führt, wird Theorie zu Rückerstattung, Supportticket und Vertrauensverlust.
Ein konkretes Beispiel: ein Nutzer tippt „Bestellung abschicken“, die App sendet eine Anfrage, und die Verbindung bricht ab. Der Nutzer versucht es erneut. Wenn dein Innen nicht erkennen kann „das ist derselbe Versuch“, erzeugst du möglicherweise zwei Bestellungen, reservierst Inventar zweimal oder versendest zwei Bestätigungs‑E‑Mails.
Hellands Aussage ist klar: die Außenwelt ist unsicher, aber das Innere deines Systems muss konsistent bleiben. Netzwerke verlieren Pakete, Handys verlieren Signal, Uhren driften und Nutzer drücken Refresh. Das liegt außerhalb deiner Kontrolle. Was du kontrollieren kannst, ist, was du als „wahr“ akzeptierst, sobald Daten eine klare Grenze überqueren.
Stell dir vor, jemand bestellt Kaffee per Handy in einem Gebäude mit schlechtem WLAN. Er tippt „Bezahlen“. Der Spinner dreht. Das Netzwerk bricht ab. Er tippt nochmal.
Vielleicht hat die erste Anfrage deinen Server erreicht, aber die Antwort kam nie zurück. Oder vielleicht ist gar keine der beiden Anfragen angekommen. Aus Sicht des Nutzers sehen beide Möglichkeiten gleich aus.
Das ist Zeit und Unsicherheit: du weißt noch nicht, was passiert ist, und könntest es später erfahren. Dein System muss sich sinnvoll verhalten, während es wartet.
Wenn du akzeptierst, dass das Außen unzuverlässig ist, werden einige „komische" Verhaltensweisen normal:
Außendaten sind eine Behauptung, keine Tatsache. „Ich habe bezahlt“ ist nur eine Aussage über einen unzuverlässigen Kanal. Es wird erst zur Tatsache, wenn du es innen dauerhaft und konsistent aufzeichnest.
Das treibt dich zu drei praktischen Gewohnheiten: ziehe klare Grenzen, mache Retries sicher durch Idempotenz und plane Reconciliation, wenn Realität und System auseinanderdriften.
Die Idee „außen vs. innen" beginnt mit einer praktischen Frage: wo beginnt und endet die Wahrheit deines Systems?
Innerhalb der Grenze kannst du starke Zusagen machen, weil du die Daten und Regeln kontrollierst. Außerhalb machst du Best‑Effort‑Versuche und gehst davon aus, dass Nachrichten verloren gehen, dupliziert, verzögert oder falsch geordnet ankommen.
In echten Apps erscheint die Grenze oft an Stellen wie:
Wenn du diese Linie ziehst, entscheide, welche Invarianten darin unverhandelbar sind. Beispiele:
Die Grenze braucht auch eine klare Sprache dafür, „wo wir stehen“. Viele Fehler leben in der Lücke zwischen „wir haben dich gehört" und „wir sind fertig". Ein hilfreiches Muster ist, drei Bedeutungen zu trennen:
Wenn Teams das überspringen, entstehen Bugs, die nur unter Last oder bei Teil‑Ausfällen auftreten. Ein System verwendet „paid“, um Geldabbuchung zu bedeuten; ein anderes meint damit den Beginn eines Zahlungsversuchs. Diese Inkongruenz erzeugt Duplikate, festhängende Bestellungen und Supporttickets, die sich niemand reproduzieren kann.
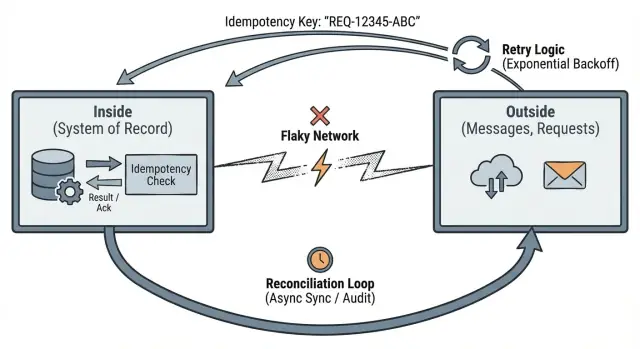
Idempotenz bedeutet: wenn dieselbe Anfrage zweimal gesendet wird, behandelt das System sie wie eine Anfrage und liefert dasselbe Ergebnis zurück.
Retries sind normal. Timeouts passieren. Clients wiederholen sich. Wenn das Außen wiederholen kann, muss dein Innen das in stabile Zustandsänderungen verwandeln.
Ein einfaches Beispiel: eine mobile App sendet „bezahle $20" und die Verbindung bricht. Die App versucht es erneut. Ohne Idempotenz könnte der Kunde zweimal belastet werden. Mit Idempotenz liefert die zweite Anfrage das Ergebnis der ersten zurück.
Die meisten Teams nutzen eines der folgenden Muster (oder eine Mischung):
Idempotency-Key: ...). Der Server speichert den Key und die finale Antwort.Wenn ein Duplikat ankommt, ist das beste Verhalten meist nicht „409 Conflict" oder ein generischer Fehler. Es ist, dasselbe Ergebnis zurückzugeben, das du beim ersten Mal zurückgegeben hast — inklusive derselben Ressourcen‑ID und desselben Status. Das macht Retries für Clients und Hintergrundjobs sicher.
Der Idempotency‑Eintrag muss innerhalb deiner Grenze in dauerhafter Speicherung leben, nicht nur im Speicher. Wenn deine API neu startet und das vergisst, verschwindet die Sicherheitsgarantie.
Bewahre Einträge lange genug, um realistische Retries und verzögerte Zustellungen abzudecken. Das Zeitfenster hängt vom Geschäftsrisiko ab: Minuten bis Stunden für risikoarme Erstellungen, Tage für Zahlungen/E‑Mails/Sendungen, bei denen Duplikate teuer sind, und länger, wenn Partner über längere Zeiträume erneut versuchen können.
Verteilte Transaktionen klingen beruhigend: ein großer Commit über Dienste, Queues und Datenbanken. In der Praxis sind sie oft nicht verfügbar, langsam oder zu zerbrechlich, um sich darauf zu verlassen. Sobald ein Netzwerk‑Hop involviert ist, kannst du nicht annehmen, dass alles zusammen committet.
Eine übliche Falle ist ein Workflow, der nur funktioniert, wenn jeder Schritt jetzt sofort erfolgreich ist: Bestellung speichern, Karte belasten, Inventar reservieren, Bestätigung senden. Wenn Schritt 3 time‑outet, ist unklar, ob er fehlgeschlagen oder erfolgreich war. Wenn du erneut versuchst, doppelt zu belasten oder doppelt zu reservieren?
Zwei pragmatische Ansätze vermeiden das:
Wähle pro Workflow einen Stil und bleibe dabei. Das Vermischen von „manchmal Outbox, manchmal synchroner Erfolg“ erzeugt Edge‑Cases, die schwer zu testen sind.
Eine einfache Regel hilft: wenn du nicht atomar über Grenzen committen kannst, entwerfe für Retries, Duplikate und Verzögerungen.
Reconciliation ist die Eingeständnis einer einfachen Wahrheit: wenn deine App über ein Netzwerk mit anderen Systemen spricht, werdet ihr manchmal unterschiedlicher Meinung darüber sein, was passiert ist. Requests timen‑out, Callbacks kommen spät, und Menschen wiederholen Aktionen. Reconciliation ist, wie du Abweichungen erkennst und über die Zeit reparierst.
Behandle externe Systeme als unabhängige Wahrheitsquellen. Deine App führt ihr eigenes internes Register, aber sie braucht einen Weg, dieses Register mit dem abzugleichen, was Partner, Provider und Nutzer tatsächlich getan haben.
Die meisten Teams benutzen ein kleines Set langweiliger Werkzeuge (langweilig ist gut): ein Worker, der ausstehende Aktionen erneut probiert und externen Status nachprüft, ein geplanter Scan nach Inkonsistenzen und eine kleine Admin‑Reparaturaktion, mit der der Support retryen, stornieren oder als geprüft markieren kann.
Reconciliation funktioniert nur, wenn du weißt, was zu vergleichen ist: internes Ledger vs. Provider‑Ledger (Zahlungen), Bestellstatus vs. Versandstatus (Fulfillment), Subscription‑Status vs. Billing‑Status.
Mache Zustände reparierbar. Statt direkt von „created" zu „completed" zu springen, verwende Zwischenzustände wie pending, on hold oder needs review. Das erlaubt zu sagen „wir sind uns nicht sicher" und gibt der Reconciliation einen klaren Ort für die Landung.
Erfasse eine kleine Audit‑Spur bei wichtigen Änderungen:
Beispiel: wenn deine App ein Versandlabel anfordert und das Netzwerk abbricht, kannst du intern „kein Label“ haben, während der Carrier tatsächlich eines erstellt hat. Ein Recon‑Worker kann per Korrelation‑ID suchen, das Label finden und die Bestellung voranbringen (oder sie zur Prüfung markieren, wenn Details nicht übereinstimmen).
Sobald du annimmst, dass das Netzwerk ausfällt, ändert sich das Ziel. Du versuchst nicht mehr, jeden Schritt in einem Durchlauf erfolgreich zu machen. Du versuchst, jeden Schritt so zu gestalten, dass er sicher wiederholt werden kann und leicht zu reparieren ist.
Schreibe einen ein‑satzigen Boundary‑Statement. Sei explizit darüber, was dein System besitzt (Quelle der Wahrheit), was es spiegelt und was es nur bei anderen anfragt.
Liste Ausfallmodi auf, bevor du den Happy‑Path definierst. Mindestens: Timeouts (du weißt nicht, ob es funktioniert hat), doppelte Anfragen, partielle Erfolge (ein Schritt passierte, der nächste nicht) und out‑of‑order‑Events.
Wähle eine Idempotency‑Strategie für jeden Input. Bei synchronen APIs ist das oft ein Idempotency‑Key plus ein gespeichertes Ergebnis. Bei Nachrichten/Events ist es normalerweise eine eindeutige Message‑ID und eine „habe ich das schon verarbeitet?“‑Aufzeichnung.
Persistiere die Absicht, dann handle. Speichere zuerst etwas Dauerhaftes wie „PaymentAttempt: pending“ oder „ShipmentRequest: queued“, rufe dann den externen Dienst auf und speichere danach das Ergebnis. Gib eine stabile Referenz‑ID zurück, damit Retries auf dieselbe Absicht zeigen statt eine neue zu erzeugen.
Baue Reconciliation und einen Reparaturweg und mache beides sichtbar. Reconciliation kann ein Job sein, der „zu lange pending“ Einträge scannt und externen Status erneut abruft. Der Reparaturweg kann eine sichere Admin‑Aktion wie „retry", „cancel" oder „mark resolved" sein, mit einem Audit‑Note. Füge grundlegende Observability hinzu: Korrelation‑IDs, klare Statusfelder und einige Zähler (pending, retries, failures).
Beispiel: wenn der Checkout kurz nachdem du den Zahlungsprovider aufgerufen hast time‑outet, rate nicht. Speichere den Versuch, gib die Attempt‑ID zurück und lass den Nutzer mit demselben Idempotency‑Key erneut versuchen. Später kann Reconciliation bestätigen, ob der Provider belastet hat oder nicht, und den Versuch aktualisieren, ohne doppelt zu belasten.
Ein Kunde tippt „Bestellung abschicken“. Dein Service sendet eine Zahlungsanfrage an einen Provider, aber das Netzwerk ist labil. Der Provider hat seine eigene Wahrheit, und deine Datenbank hat deine. Sie werden auseinanderdriften, wenn du nicht dafür sorgst.
Aus deiner Sicht ist das Außen ein Strom von Nachrichten, die verspätet, wiederholt oder fehlend sein können:
Keiner dieser Schritte garantiert „exactly once". Sie garantieren nur „maybe".
Innerhalb deiner Grenze speichere dauerhafte Fakten und das Minimum, das nötig ist, um Außen‑Ereignisse mit diesen Fakten zu verbinden.
Wenn der Kunde die Bestellung zuerst absendet, erstelle einen order‑Datensatz in einem klaren Zustand wie pending_payment. Erstelle auch einen payment_attempt‑Datensatz mit einer eindeutigen Provider‑Referenz sowie einem idempotency_key, der zur Kundenaktion gehört.
Wenn der Client timet out und erneut versucht, sollte deine API keine zweite Bestellung erzeugen. Sie sollte den idempotency_key nachschlagen und dieselbe order_id und den aktuellen Status zurückgeben. Diese einzelne Entscheidung verhindert Duplikate bei Netzwerkfehlern.
Nun kommt der Webhook zweimal an. Der erste Callback aktualisiert payment_attempt zu authorized und setzt die Bestellung auf paid. Der zweite Callback trifft denselben Handler, aber du erkennst, dass du dieses Provider‑Event bereits verarbeitet hast (durch Speichern der Provider‑Event‑ID oder durch Kontrolle des aktuellen Zustands) und tust nichts. Du kannst trotzdem 200 OK zurückgeben, weil das Ergebnis bereits stimmt.
Schließlich erledigt Reconciliation die komplizierten Fälle. Wenn die Bestellung nach einer Verzögerung noch pending_payment ist, fragt ein Hintergrundjob den Provider anhand der gespeicherten Referenz erneut ab. Wenn der Provider „authorized" meldet, du aber den Webhook verpasst hast, aktualisierst du deine Aufzeichnungen. Wenn der Provider „failed" sagt, du aber als bezahlt markiert hast, markierst du es zur Überprüfung oder löst eine Kompensation wie Rückerstattung aus.
Die meisten doppelten Datensätze und festhängenden Workflows entstehen, weil Außen‑Ereignisse (eine Anfrage kam an, eine Nachricht wurde empfangen) mit dem, was du sicher innen committet hast, verwechselt werden.
Ein klassischer Fehler: ein Client sendet „Bestellung platzieren", dein Server beginnt die Arbeit, das Netz bricht ab und der Client wiederholt. Wenn du jeden Retry als völlig neue Wahrheit behandelst, bekommst du Doppellasten, doppelte Bestellungen oder mehrere E‑Mails.
Häufige Ursachen sind:
Ein Problem verschlimmert alles: kein Audit‑Trail. Wenn du Felder überschreibst und nur den letzten Zustand behältst, verlierst du die Beweise, die du zur späteren Reconciliation brauchst.
Eine gute Kontrollfrage ist: „Wenn ich diesen Handler zweimal ausführe, bekomme ich dasselbe Ergebnis?" Wenn die Antwort nein ist, sind Duplikate keine seltene Randbedingung. Sie sind garantiert.
Wenn du dir eins merkst: deine App muss korrekt bleiben, auch wenn Nachrichten verspätet, doppelt oder gar nicht ankommen.
Verwende diese Checkliste, um Schwachstellen zu finden, bevor sie zu doppelten Datensätzen, fehlenden Updates oder festhängenden Workflows werden:
Wenn du eine dieser Fragen nicht schnell beantworten kannst, ist das nützlich. Meist bedeutet es, dass eine Grenze unscharf ist oder eine Zustandsübergang fehlt.
Praktische nächste Schritte:
Skizziere zuerst Grenzen und Zustände. Definiere pro Workflow eine kleine Menge an Zuständen (z. B.: Created, PaymentPending, Paid, FulfillmentPending, Completed, Failed).
Füge Idempotenz dort hinzu, wo es am meisten zählt. Beginne mit den risikoreichsten Schreibvorgängen: Bestellung erstellen, Zahlung einziehen, Rückerstattung ausstellen. Speichere Idempotency‑Keys in PostgreSQL mit einem Unique‑Constraint, sodass Duplikate sicher abgewiesen werden.
Behandle Reconciliation als normales Feature. Plane einen Job, der „zu lange pending" Einträge findet, externe Systeme erneut prüft und lokalen Zustand repariert.
Iteriere sicher. Passe Übergänge und Retry‑Regeln an und teste, indem du dieselbe Anfrage absichtlich erneut sendest und dasselbe Event mehrfach verarbeitest.
Wenn du schnell auf einer Chat‑gesteuerten Plattform wie Koder.ai (koder.ai) aufbaust, lohnt es sich trotzdem, diese Regeln früh in die generierten Dienste einzubetten: Geschwindigkeit kommt durch Automatisierung, Zuverlässigkeit durch klare Grenzen, idempotente Handler und Reconciliation.
"Außen" ist alles, was du nicht kontrollierst: Browser, mobile Netze, Queues, Drittanbieter‑Webhooks, Retries und Timeouts. Gehe davon aus, dass Nachrichten verzögert, dupliziert, verloren gehen oder in falscher Reihenfolge ankommen können.
"Innen" ist das, was du kontrollierst: dein persistenter Zustand, deine Regeln und die Fakten, die du später beweisen kannst (in der Regel in deiner Datenbank).
Weil das Netz dir nicht die ganze Wahrheit sagt.
Ein Client‑Timeout bedeutet nicht, dass dein Server die Anfrage nicht verarbeitet hat. Ein Webhook, das zweimal ankommt, bedeutet nicht, dass der Provider die Aktion zweimal ausgeführt hat. Wenn du jede Nachricht als „neue Wahrheit“ behandelst, erzeugst du doppelte Bestellungen, doppelte Abbuchungen und festhängende Workflows.
Eine klare Grenze ist der Punkt, an dem eine unzuverlässige Nachricht zur dauerhaften Tatsache wird.
Gängige Grenzen sind:
Sobald die Daten die Grenze überschreiten, setzt du Invarianten durch (z. B. „eine Bestellung kann nur einmal bezahlt werden“).
Nutze Idempotenz. Die Grundregel: dasselbe Intent soll dasselbe Ergebnis liefern, selbst wenn es mehrfach gesendet wird.
Praktische Muster:
Nicht nur im Arbeitsspeicher. Speichere den Idempotency‑Eintrag innerhalb deiner Grenze (z. B. PostgreSQL), damit ein Neustart die Garantie nicht zerstört.
Faustregeln zur Aufbewahrung:
Bewahre ihn lange genug auf, um realistische Retries und verzögerte Callbacks abzudecken.
Nutze Zustände, die Unsicherheit zulassen.
Ein einfaches, praktisches Set:
pending_* (Intent akzeptiert, Ergebnis noch offen)succeeded / failed (finales Ergebnis aufgezeichnet)needs_review (Abgleich hat eine Abweichung gefunden, menschliche Prüfung nötig)Weil du nicht atomar über Netzgrenzen hinweg committen kannst.
Wenn du synchron „Bestellung speichern → Karte belasten → Inventar reservieren“ machst und Schritt 2 time‑outet, weißt du nicht, ob erneut versucht werden soll. Wiederholen kann Duplikate erzeugen; nicht wiederholen kann Arbeit unvollständig lassen.
Entwirf für partielle Erfolge: zuerst Intent persistieren, dann externe Aktionen ausführen, danach Ergebnisse speichern.
Das Outbox/Inbox‑Muster macht Cross‑System‑Messaging zuverlässig, ohne das Netzwerk zu verhehlen.
Reconciliation ist, wie du wieder in Einklang kommst, wenn deine Aufzeichnungen und ein externes System auseinanderlaufen.
Gute Defaults:
needs_reviewFür Zahlungen, Fulfillment, Subscriptions oder alles mit Webhooks ist das keine Option, sondern Pflicht.
Ja. Schnell bauen entfernt nicht das Netzproblem — es macht dich nur schneller damit konfrontiert.
Wenn du Dienste mit Koder.ai generierst, baue diese Defaults früh ein:
So werden Retries und doppelte Callbacks langweilig statt teuer.
Das vermeidet Raten während Timeouts und erleichtert die Reconciliation.