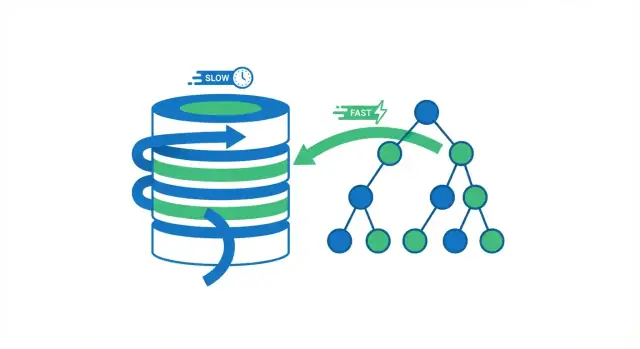
Was Datenbank-Indexierung wirklich bewirkt
Ein Datenbankindex ist eine separate Lookup-Struktur, die der Datenbank hilft, Zeilen schneller zu finden. Er ist keine zweite Kopie deiner Tabelle. Denk daran wie die Indexseiten in einem Buch: du benutzt den Index, um in die richtige Gegend zu springen, und liest dann die genaue Seite (Zeile), die du brauchst.
Ohne Index hat die Datenbank oft nur eine sichere Option: viele Zeilen durchlesen, um zu prüfen, welche zu deiner Abfrage passen. Das kann bei einer Tabelle mit ein paar tausend Zeilen in Ordnung sein. Wenn die Tabelle aber Millionen von Zeilen erreicht, bedeutet „mehr Zeilen prüfen“ mehr Festplattenzugriffe, mehr Speicherbelastung und mehr CPU‑Arbeit — dieselbe Abfrage, die früher instant war, beginnt zu bremsen.
Was ein Index verändert (und was nicht)
Indizes reduzieren die Menge an Daten, die die Datenbank untersuchen muss, um Fragen wie „Finde die Bestellung mit ID 123“ oder „Hole Benutzer mit dieser E‑Mail“ zu beantworten. Anstatt alles zu scannen, folgt die Datenbank einer kompakten Struktur, die die Suche schnell einschränkt.
Indexierung ist jedoch kein Allheilmittel. Manche Abfragen müssen weiterhin viele Zeilen verarbeiten (breite Reports, Filter mit niedriger Selektivität, rechenintensive Aggregationen). Und Indizes haben echte Kosten: zusätzlicher Speicher und langsamere Schreibvorgänge, weil Inserts und Updates auch den Index pflegen müssen.
Was du in diesem Leitfaden lernst
Du wirst sehen:
- warum das Vermeiden von Full Table Scans der große Geschwindigkeitsgewinn ist
- wie gängige Indexstrukturen (wie B‑Bäume) Lookups beschleunigen
- welche Abfragen am meisten profitieren und wann sie es nicht tun
- wie man zusammengesetzte/covering Indizes auswählt und mit einem EXPLAIN‑Plan validiert
- wie man Indizes im Laufe der Zeit pflegt, damit die Performance nicht schleichend abnimmt
Der Kernnutzen: Full Table Scans vermeiden
Wenn eine Datenbank eine Abfrage ausführt, hat sie zwei grobe Optionen: die ganze Tabelle Zeile für Zeile scannen oder direkt zu den passenden Zeilen springen. Die meisten Index‑Gewinne kommen daher, unnötige Lesezugriffe zu vermeiden.
Full Table Scan vs. Index-Lookup
Ein Full Table Scan ist genau das: die Datenbank liest jede Zeile, prüft, ob sie zur WHERE‑Bedingung passt, und gibt dann die Ergebnisse zurück. Das ist bei kleinen Tabellen akzeptabel, wird aber mit wachsender Tabelle in vorhersehbarer Weise langsamer — mehr Zeilen bedeuten mehr Arbeit.
Mit einem Index kann die Datenbank oft das Lesen der meisten Zeilen vermeiden. Stattdessen konsultiert sie zuerst den Index (eine kompakte, zum Suchen gebaute Struktur), findet, wo die passenden Zeilen liegen, und liest dann nur diese spezifischen Zeilen.
Eine einfache Analogie
Denk an ein Buch. Wenn du jede Seite mit dem Wort „Photosynthese“ finden willst, könntest du das ganze Buch von vorne bis hinten lesen (Full Scan). Oder du benutzt das Register, springst zu den aufgelisteten Seiten und liest nur die relevanten Abschnitte (Index Lookup). Die zweite Methode ist schneller, weil du fast alle Seiten überspringst.
Warum weniger Lesezugriffe meist schnellere Abfragen bedeuten
Datenbanken verbringen viel Zeit damit, auf Lesevorgänge zu warten — besonders wenn Daten nicht bereits im Speicher sind. Die Reduktion der zu berührenden Zeilen (und Seiten) reduziert typischerweise:
- Festplatten/SSD‑Leseoperationen
- CPU‑Zeit für das Auswerten von Filtern
- Speicherbelastung durch das Laden unnötiger Daten in den Cache
Wann der Geschwindigkeitsgewinn sichtbar wird
Indexierung hilft am meisten, wenn Daten groß sind und das Abfragemuster selektiv ist (z. B. 20 passende Zeilen von 10 Millionen). Wenn deine Abfrage sowieso die meisten Zeilen zurückliefert oder die Tabelle klein genug ist, um bequem im Speicher zu liegen, kann ein Full Scan genauso schnell — oder sogar schneller — sein.
Wie Indexstrukturen Lookups beschleunigen
Indizes funktionieren, weil sie Werte so organisieren, dass die Datenbank näher an das Gewünschte springen kann, statt jede Zeile zu prüfen.
B‑Baum‑Indizes: der Standard‑Arbeitspferd
Die gebräuchlichste Indexstruktur in SQL‑Datenbanken ist der B‑Baum (oft „B‑tree“ oder „B+tree“ geschrieben). Konzeptuell:
- Werte werden sortiert gehalten
- der Index wird in Seiten (Chunks) geteilt, die auf andere Seiten zeigen und schließlich auf die passenden Tabellenzeilen
Weil er sortiert ist, ist ein B‑Baum großartig für sowohl Gleichheitslookups (WHERE email = ...) als auch Bereichsabfragen (WHERE created_at >= ... AND created_at < ...). Die Datenbank kann zur richtigen Nachbarschaft navigieren und dann vorwärts in Ordnung scannen.
Was „logarithmisch“ praktisch bedeutet
Man sagt, B‑Baum‑Lookups seien „logarithmisch“. Praktisch heißt das: wenn deine Tabelle von Tausenden zu Millionen Zeilen wächst, steigt die Anzahl der Schritte, um einen Wert zu finden, langsam, nicht proportional. Statt „doppelt so viele Daten bedeutet doppelt so viel Arbeit“ ist es eher „viel mehr Daten bedeuten nur ein paar zusätzliche Navigationsschritte“, weil die Datenbank Zeiger durch eine kleine Anzahl Ebenen im Baum folgt.
Hash‑Indizes: schnell für exakte Treffer (mit Einschränkungen)
Manche Engines bieten auch Hash‑Indizes. Diese können für exakte Gleichheitsabfragen sehr schnell sein, weil der Wert in einen Hash umgewandelt wird, der direkt den Eintrag findet.
Der Kompromiss: Hash‑Indizes helfen typischerweise nicht bei Bereichen oder geordneten Scans, und Verfügbarkeit/Verhalten unterscheiden sich zwischen Datenbanken.
Engines unterscheiden sich, die Idee bleibt dieselbe
PostgreSQL, MySQL/InnoDB, SQL Server und andere speichern und nutzen Indizes unterschiedlich (Seitengröße, Clustering, included columns, Sichtbarkeitsprüfungen). Aber das Grundkonzept gilt überall: Indizes schaffen eine kompakte, navigierbare Struktur, die der Datenbank erlaubt, passende Zeilen mit deutlich weniger Arbeit zu finden als beim Durchsuchen der ganzen Tabelle.
Abfragen, die am meisten von Indizes profitieren
Indizes beschleunigen nicht „SQL“ allgemein — sie beschleunigen bestimmte Zugriffsmuster. Wenn ein Index zu Filter-, Join‑ oder Sortierbedingungen deiner Abfrage passt, kann die Datenbank direkt zu relevanten Zeilen springen statt die ganze Tabelle zu lesen.
Die indexfreundlichsten Abfragemuster
1) WHERE‑Filter (besonders auf selektiven Spalten)
Wenn deine Abfrage oft eine große Tabelle auf eine kleine Ergebnismenge reduziert, ist ein Index meist die erste Anlaufstelle. Ein klassisches Beispiel ist die Suche eines Benutzers per Identifier.
Ohne Index auf users.email muss die Datenbank möglicherweise jede Zeile scannen:
SELECT * FROM users WHERE email = '[email protected]';
Mit einem Index auf email kann sie die passende Zeile(n) schnell finden und stoppen.
2) JOIN‑Schlüssel (Fremdschlüssel und referenzierte Schlüssel)
Joins sind Stellen, an denen „kleine Ineffizienzen“ zu großen Kosten werden. Wenn du orders.user_id mit users.id joinst, hilft das Indexieren der Join‑Spalten (typischerweise orders.user_id und der Primärschlüssel users.id), damit die Datenbank Zeilen ohne wiederholte Scans abgleichen kann.
3) ORDER BY (wenn du Ergebnisse bereits sortiert haben willst)
Sortieren ist teuer, wenn die Datenbank viele Zeilen sammeln und danach sortieren muss. Wenn du häufig ausführst:
SELECT * FROM orders WHERE user_id = 42 ORDER BY created_at DESC;
ein Index, der user_id und die Sortierspalte abbildet, kann es der Engine erlauben, Zeilen in der benötigten Reihenfolge zu lesen statt ein großes Zwischenresultat zu sortieren.
4) GROUP BY (wenn Gruppierung zum Index passt)
Gruppierung kann profitieren, wenn die Datenbank in gruppierter Reihenfolge lesen kann. Es ist keine Garantie, aber wenn du oft nach einer Spalte gruppierst, die auch zum Filtern verwendet wird (oder im Index natürlich gruppiert ist), kann die Engine weniger Arbeit haben.
Bereichsfilter: ein typischer B‑Baum‑Gewinn
B‑Baum‑Indizes sind besonders gut für Bereichsbedingungen — denk an Daten, Preise oder BETWEEN‑Abfragen:
SELECT * FROM orders
WHERE created_at >= '2025-01-01' AND created_at < '2025-02-01';
Für Dashboards, Reports und „recent activity“ Bildschirme ist dieses Muster sehr häufig, und ein Index auf der Bereichsspalte bringt oft sofortige Verbesserungen.
Das Thema ist einfach: Indizes helfen am meisten, wenn sie die Art und Weise widerspiegeln, wie du suchst und sortierst. Wenn deine Abfragen zu diesen Zugriffsmustern passen, kann die Datenbank gezielte Lesezugriffe statt breiter Scans durchführen.
Selektivität: Warum manche Indizes nicht helfen
Ein Index hilft vor allem, wenn er die Anzahl der Zeilen, die die Datenbank berühren muss, stark reduziert. Diese Eigenschaft heißt Selektivität.
Was Selektivität in der Praxis bedeutet
Selektivität ist im Grunde: wie viele Zeilen passen zu einem bestimmten Wert? Eine hoch selektive Spalte hat viele unterschiedliche Werte, sodass jede Abfrage wenige Zeilen trifft.
- Hohe Selektivität:
email, user_id, order_number (oft einzigartig oder nahe dran)
- Niedrige Selektivität:
is_active, is_deleted, status mit wenigen gemeinsamen Werten
Bei hoher Selektivität kann ein Index direkt auf eine kleine Menge Zeilen springen. Bei niedriger Selektivität zeigt der Index oft auf einen großen Tabellenteil — die Datenbank muss dann trotzdem viel lesen und filtern.
Warum boolesche (und ähnliche) Indizes enttäuschen
Betrachte eine Tabelle mit 10 Millionen Zeilen und einer Spalte is_deleted, bei der 98% false sind. Ein Index auf is_deleted hilft wenig bei:
SELECT * FROM orders WHERE is_deleted = false;
Die Treffergruppe ist immer noch fast die ganze Tabelle. Die Verwendung des Index kann sogar langsamer sein als ein sequentieller Scan, weil die Engine zusätzlichen Aufwand hat, zwischen Indexeinträgen und Tabellenseiten zu springen.
Warum der Optimierer deinen Index ignorieren kann
Query‑Planner schätzt Kosten. Wenn ein Index die Arbeit nicht genug vermindert — weil zu viele Zeilen passen oder weil die Abfrage auch die meisten Spalten braucht — kann er einen Full Table Scan wählen.
Selektivität ändert sich mit der Zeit
Die Verteilung der Daten ist nicht statisch. Eine status‑Spalte kann anfangs gleichmäßig verteilt sein und dann so driften, dass ein Wert dominiert. Wenn Statistiken nicht aktualisiert werden, trifft der Planner schlechte Entscheidungen, und ein Index, der einst hilfreich war, zahlt sich plötzlich nicht mehr aus.
Zusammengesetzte und Covering‑Indizes (und Spaltenreihenfolge)
Einzelspalten‑Indizes sind ein guter Anfang, aber viele reale Abfragen filtern nach einer Spalte und sortieren oder filtern nach einer anderen. Hier glänzen zusammengesetzte (Multi‑Column) Indizes: ein Index kann mehrere Teile der Abfrage bedienen.
Spaltenreihenfolge: die „left‑to‑right“‑Regel
Die meisten Datenbanken (insbesondere mit B‑Baum‑Indizes) können einen zusammengesetzten Index effizient nur von den linksmotivsten Spalten an nutzen. Denk an den Index als sortiert zuerst nach Spalte A, dann innerhalb dieser nach Spalte B usw.
Das bedeutet:
- Ein Index auf (account_id, created_at) ist großartig für Abfragen, die nach
account_id filtern und dann nach created_at sortieren/filtern
- Derselbe Index hilft in der Regel nicht, wenn nur nach
created_at gefiltert wird (weil es nicht die linksmotivste Spalte ist)
Ein praktisches Muster: Pro‑Account Timelines
Ein häufiges Workload ist „zeige die neuesten Ereignisse für dieses Konto“. Dieses Abfragemuster:
SELECT id, created_at, type
FROM events
WHERE account_id = ?
ORDER BY created_at DESC
LIMIT 50;
profitiert oft enorm von:
CREATE INDEX events_account_created_at
ON events (account_id, created_at);
Die Datenbank kann direkt in den Index‑Bereich dieses Accounts springen und Zeilen in Zeitreihenfolge lesen, statt eine große Menge zu scannen und zu sortieren.
Covering‑Indizes: wenn der Index die Antwort ist
Ein Covering‑Index enthält alle Spalten, die die Abfrage braucht, sodass die Datenbank Ergebnisse aus dem Index liefern kann, ohne die Tabellenzeilen nachzuschlagen (weniger Lesezugriffe, weniger random I/O).
Vorsicht: zusätzliche Spalten machen einen Index groß und teuer.
Baue keine breiten Composite‑Indizes „für alle Fälle"
Breite zusammengesetzte Indizes können Schreibvorgänge verlangsamen und viel Speicher verbrauchen. Füge sie nur für konkrete, wertvolle Abfragen hinzu und verifiziere mit einem EXPLAIN‑Plan und realen Messungen vor und nach der Änderung.
Tradeoffs: langsamere Writes und zusätzlicher Speicher
Indizes werden oft als „kostenlose Beschleuniger“ beschrieben, aber sie sind es nicht. Indexstrukturen müssen bei jeder Änderung der zugrunde liegenden Tabelle gepflegt werden und verbrauchen echte Ressourcen.
Langsamere INSERT/UPDATE/DELETE (weil jeder Index aktualisiert werden muss)
Beim INSERT schreibt die Datenbank nicht nur die neue Zeile — sie fügt auch entsprechende Einträge in jeden Index der Tabelle ein. Dasselbe gilt für DELETE und viele UPDATEs.
Deshalb kann „mehr Indizes“ Schreiblast merklich verlangsamen. Ein UPDATE, das eine indizierte Spalte ändert, kann besonders teuer sein: die Datenbank muss alten Indexeintrag entfernen und einen neuen hinzufügen (und in manchen Engines können Page‑Splits oder interne Rebalancierungen ausgelöst werden). Wenn deine App viele Writes macht — Ereignisse, Sensordaten, Audit‑Logs — kann alles zu indizieren die DB trotz schneller Lesezugriffe träge machen.
Zusätzlicher Speicher- und Memory‑Druck
Jeder Index braucht Festplattenspeicher. Bei großen Tabellen können Indizes die Tabellengröße erreichen oder übersteigen, besonders wenn mehrere sich überschneidende Indizes existieren.
Es wirkt sich auch auf den Arbeitsspeicher aus. Datenbanken sind stark auf Caching angewiesen; wenn dein Working Set mehrere große Indizes umfasst, muss der Cache mehr Seiten halten, um schnell zu bleiben. Andernfalls siehst du mehr Festplatten‑I/O und unvorhersehbarere Performance.
Die praktische Balance
Indexierung heißt: entscheiden, was beschleunigt werden soll. Ist dein Workload read‑lastig, können mehr Indizes sinnvoll sein. Ist er write‑lastig, priorisiere Indizes, die deine wichtigsten Abfragen unterstützen, und vermeide Duplikate. Eine hilfreiche Regel: Füge einen Index nur hinzu, wenn du die konkrete Abfrage benennen kannst, die er verbessert — und verifiziere, dass der Lesegeschwindigkeitsgewinn die Schreib‑ und Wartungskosten überwiegt.
Wie du beweist, dass ein Index hilft: EXPLAIN und Messungen
Ein Index klingt so, als würde er helfen — aber du kannst (und solltest) das verifizieren. Die beiden Werkzeuge dafür sind der Query‑Plan (EXPLAIN) und echte Vorher/Nachher‑Messungen.
Lies den Plan: Wird der Index tatsächlich verwendet?
Führe EXPLAIN (oder EXPLAIN ANALYZE) auf genau der Abfrage aus, die dir wichtig ist.
- Scan‑Typ: Ein Seq Scan / Full Table Scan bedeutet, die DB liest die ganze Tabelle. Ein Index Scan / Index Seek (oder Index Range Scan) deutet darauf hin, dass ein Index zur Eingrenzung genutzt wird.
- Geschätzte vs. tatsächliche Zeilen (besonders in
EXPLAIN ANALYZE): Wenn der Plan geschätzt 100 Zeilen, aber tatsächlich 100.000 berührt hat, hat der Optimierer sich verschätzt — oft wegen veralteter Statistiken oder weil der Filter weniger selektiv ist als gedacht.
- Sort‑Schritte: Wenn du einen expliziten Sort siehst, ordnet die DB Ergebnisse nach dem Abruf. Passt ein neuer Index zum
ORDER BY, kann dieser Sort entfallen — das ist oft ein großer Gewinn.
Richtig messen: vor/nach, gleiche Bedingungen
Benchmark die Abfrage mit den gleichen Parametern, auf repräsentativem Datenvolumen, und erfasse sowohl Latenz als auch gelesene Zeilen.
Achte auf Caching: der erste Lauf kann langsamer sein, weil Daten noch nicht im Speicher sind; wiederholte Läufe können „fixiert“ aussehen, selbst ohne Index. Vergleiche mehrere Läufe und konzentriere dich darauf, ob sich der Plan ändert (Index verwendet, weniger gelesene Zeilen) zusätzlich zur reinen Zeit.
Wenn EXPLAIN ANALYZE weniger berührte Zeilen und weniger teure Schritte (wie Sorts) zeigt, hast du bewiesen, dass der Index hilft — nicht nur gehofft.
Häufige Fehler, die Index‑Vorteile aufheben
Du kannst den „richtigen“ Index hinzufügen und trotzdem keinen Speed‑Up sehen, wenn die Abfrage so geschrieben ist, dass die Datenbank ihn nicht nutzen kann. Diese Probleme sind oft subtil, weil die Abfrage weiterhin korrekte Ergebnisse liefert — sie landet nur in einem langsameren Plan.
Anti‑Pattern, die Indexnutzung blockieren
1) Leading‑Wildcards
Wenn du schreibst:
WHERE name LIKE '%term'
kann die Datenbank einen normalen B‑Baum‑Index nicht verwenden, weil unklar ist, wo in der sortierten Reihenfolge „%term“ beginnt. Sie fällt oft auf einen großen Scan zurück.
Alternativen:
- Wenn möglich, nutze Präfixsuche:
WHERE name LIKE 'term%'.
- Wenn du wirklich „contains“ brauchst, erwäge spezialisierte Indexarten (z. B. Full‑Text/Trigram) statt eines Standardindexes.
2) Funktionen auf indizierten Spalten
Das mag harmlos aussehen:
WHERE LOWER(email) = '[email protected]'
Aber LOWER(email) ändert den Ausdruck, sodass ein Index auf email nicht direkt genutzt werden kann.
Alternativen:
- Speichere normalisierte Daten (z. B. E‑Mails in Kleinbuchstaben) und frage mit
WHERE email = ....
- Oder erstelle einen expression/function‑based Index (datenbankabhängig) speziell für
LOWER(email).
Versteckte Index‑Blocker, die oft übersehen werden
Implizite Typkonvertierungen: Der Vergleich unterschiedlicher Datentypen kann die DB zwingen, eine Seite zu casten, was einen Index deaktivieren kann (z. B. Vergleich einer Integer‑Spalte mit einem String‑Literal).
Nicht übereinstimmende Kollationen/Encodings: Wenn ein Vergleich eine andere Kollation verwendet als der Index, kann der Optimierer den Index meiden.
Schnell‑Checklist: „Warum wird mein Index nicht genutzt?“
- Beginnt die Bedingung mit einem Wildcard (
LIKE '%x')?
- Wendet du Funktionen auf die indizierte Spalte an (
LOWER(col), DATE(col), CAST(col)) ?
- Sind die Typen auf beiden Seiten identisch (keine implizite Konvertierung)?
- Ist Kollation/Locale für den Vergleich konsistent?
- Ist das Prädikat selektiv genug (matcht es nicht einen großen Teil der Tabelle)?
- Filterst/Sortierst du auf den linksmotivsten Spalten eines zusammengesetzten Index?
- Hast du den Plan mit
EXPLAIN geprüft, um zu bestätigen, was die DB tatsächlich gewählt hat?
Index‑Wartung: Statistiken, Bloat und langfristige Gesundheit
Indizes sind nicht „einmal anlegen und vergessen“. Mit der Zeit ändern sich Daten, Abfragemuster verschieben sich, und die physische Form von Tabellen und Indizes driftet. Ein gut gewählter Index kann langsam weniger effektiv — oder gar schädlich — werden, wenn du ihn nicht wartest.
Statistiken: die Karte des Planners kann veraltet sein
Die meisten Datenbanken verlassen sich auf einen Query‑Planner (Optimizer), um zu entscheiden, wie eine Abfrage ausgeführt wird: welchen Index er nutzt, welche Join‑Reihenfolge, und ob ein Index‑Lookup lohnt. Für diese Entscheidungen nutzt der Planner Statistiken — Zusammenfassungen über Wertverteilungen, Zeilenzahlen und Daten‑Skews.
Wenn Statistiken veraltet sind, können die Zeilenschätzungen des Planners stark daneben liegen. Das führt zu schlechten Plänen, z. B. die Wahl eines Index, der viel mehr Zeilen zurückliefert als erwartet, oder das Überspringen eines Index, der schneller wäre.
Routine‑Fix: Plane regelmäßige Statistik‑Updates (oft ANALYZE oder ähnlich). Nach großen Datenladungen, massiven Löschungen oder starker Änderung solltest du Statistiken früher aktualisieren.
Bloat und Fragmentierung: wenn Strukturen unordentlich werden
Beim Einfügen, Aktualisieren und Löschen können Indizes Bloat (leere oder nicht verwendete Seiten) und Fragmentierung ansammeln, was zu größeren Indizes und mehr Lesezugriffen führt — besonders bei Bereichsabfragen.
Routine‑Fix: Baue stark genutzte Indizes periodisch neu auf oder reorganisiere sie, wenn sie unverhältnismäßig gewachsen sind oder die Performance abfällt. Tools und Auswirkungen variieren je nach DB; führe solche Maßnahmen geplant und mit Messungen durch.
Langzeit‑Monitoring
Richte Monitoring ein für:
- langsame Abfragen (Latenz, Häufigkeit, schlimmste Verursacher)
- Indexnutzung (nie verwendete vs. „heiße“ Indizes)
- Index‑Größenwachstum und plötzliche Planwechsel
Dieses Feedback hilft, Wartungsbedarf zu erkennen — oder zu entscheiden, wann ein Index angepasst oder entfernt werden sollte. Mehr zur Validierung von Verbesserungen findest du in /blog/how-to-prove-an-index-helps-explain-and-measurements.
Ein praktischer Workflow, um den richtigen Index hinzuzufügen
Das Hinzufügen eines Index sollte eine bewusste Änderung sein, kein Ratespiel. Ein leichter Workflow hält dich bei messbaren Verbesserungen und verhindert „Index‑Sprawl“.
1) Finde die wirklich problematische Abfrage
Starte mit Beweisen: slow‑query‑Logs, APM‑Traces oder Nutzerberichte. Wähle eine Abfrage, die langsam und häufig ist — ein seltener 10‑Sekunden‑Report ist weniger wichtig als ein häufiger 200‑ms Lookup.
Erfasse die exakte SQL und das Parameter‑Muster (z. B. WHERE user_id = ? AND status = ? ORDER BY created_at DESC LIMIT 50). Kleine Unterschiede ändern, welcher Index hilft.
2) Messe die Ausgangslage
Notiere aktuelle Latenz (p50/p95), gescannte Zeilen und CPU/IO‑Belastung. Speichere den aktuellen Planoutput (z. B. EXPLAIN / EXPLAIN ANALYZE) zum Vergleich.
3) Entwirf den kleinsten nützlichen Index
Wähle Spalten, die zu Filterung und Sortierung deiner Abfrage passen. Bevorzuge den minimalen Index, der den Plan davon abhält, große Bereiche zu scannen.
Teste in Staging mit produktionstypischem Datenvolumen. Indizes sehen bei kleinen Datensätzen oft gut aus, enttäuschen aber im großen Maßstab.
4) Lege ihn sicher an
Bei großen Tabellen nutze Online‑Optionen, falls verfügbar (z. B. PostgreSQL CREATE INDEX CONCURRENTLY). Plane Änderungen in Zeiten mit geringerem Traffic, falls die DB Schreibsperren verursacht.
5) Validieren mit Vorher/Nachher‑Belegen
Führe dieselbe Abfrage erneut aus und vergleiche:
- Planform (hat er von Full Scan auf Indexzugriff gewechselt?)
- Ausführungszeit und gescannte Zeilen
- Auswirkungen auf Writes (Insert/Update Latenz)
6) Habe einen Rollback‑Plan
Wenn der Index Schreibkosten erhöht oder Speicher bloatet, entferne ihn sauber (z. B. DROP INDEX CONCURRENTLY, wo verfügbar). Halte Migrationen umkehrbar.
7) Dokumentiere das „Warum"
Schreibe in der Migration oder Schema‑Notiz, welche Abfrage der Index bedient und welche Metrik sich verbessert hat. Das hilft dir oder Kollegen später zu entscheiden, ob er gelöscht werden kann.
Wo Koder.ai in diesen Workflow passt
Wenn du einen neuen Service baust und früh „Index‑Sprawl“ vermeiden willst, kann Koder.ai helfen, schneller durch den kompletten Loop zu kommen: generiere eine React + Go + PostgreSQL App aus dem Chat, passe Schema‑/Index‑Migrationen während der Anforderungsänderung an und exportiere anschließend den Source Code. Praktisch macht das den Weg kürzer von „dieser Endpoint ist langsam“ zu „hier ist der EXPLAIN‑Plan, der minimale Index und eine reversible Migration“, ohne auf eine traditionelle Pipeline warten zu müssen.
Wenn Indexierung nicht ausreicht (und was dann zu tun ist)
Indizes sind ein starkes Hebelwerkzeug, aber kein magischer Knopf. Manchmal liegt der langsamste Teil einer Anfrage nachdem die DB die richtigen Zeilen gefunden hat — oder dein Abfragemuster macht Indexe zur falschen ersten Wahl.
Fälle, in denen Indexierung nicht die beste Lösung ist
Wenn deine Abfrage bereits einen guten Index nutzt, aber immer noch langsam ist, prüfe folgende Ursachen:
- Fehlende oder falsche Pagination: Seite 1.000 mit
OFFSET 999000 ist selbst mit Indizes langsam. Bevorzuge Keyset‑Pagination (z. B. „gib mir Zeilen nach der zuletzt gesehenen id/timestamp“).
- Zu viele zurückgegebene Daten: Breite Zeilen (
SELECT *) oder das Zurückgeben von Zehntausenden Datensätzen kann auf Netzwerk, JSON‑Serialisierung oder App‑Verarbeitung bottlenecken.
- Schema‑Probleme: Übernormalisierte Joins, durchsuchbare Werte in JSON/Text‑Blobs oder falsche Datentypen zwingen zu teuren Operationen, die Indizes nicht vollständig ausgleichen können.
Komplementäre Optimierungen, die oft wichtiger sind
- Query neu schreiben: Entferne unnötige Joins, vermeide Funktionen auf indizierten Spalten in WHERE‑Klauseln und vereinfache OR‑schwere Prädikate.
- Spalten und Zeilen limitieren: Selektiere nur, was du brauchst, setze sinnvolle
LIMIT‑Werte und paginauliere Ergebnisse bewusst.
- Caching: Cache heiße Reads in der Anwendungsschicht oder nutze einen Read‑Through Cache für teure, wiederkehrende Abfragen.
- Partitionierung: Wenn die meisten Abfragen „aktuelle Daten“ treffen, partitioniere nach Zeit (oder einer natürlichen Grenze), um den Suchraum zu verkleinern.
Wenn du eine tiefere Diagnose willst, kombiniere das mit dem Workflow in /blog/how-to-prove-an-index-helps.
Priorisieren: Behebe zuerst den größten Flaschenhals
Nicht raten. Messe, wo Zeit verbrannt wird (DB‑Ausführung vs. zurückgegebene Zeilen vs. App‑Code). Wenn die DB schnell ist, aber die API langsam, helfen mehr Indizes nicht.
Schnell‑Checklist