15. Sept. 2025·8 Min
David Patterson, RISC‑Denken und der dauerhafte Einfluss von Co‑Design
Erkunden Sie, wie David Pattersons RISC‑Denken und Hardware‑Software‑Co‑Design Leistung pro Watt verbesserten, CPUs prägten und RISC‑V beeinflussen.
Erkunden Sie, wie David Pattersons RISC‑Denken und Hardware‑Software‑Co‑Design Leistung pro Watt verbesserten, CPUs prägten und RISC‑V beeinflussen.
David Patterson wird oft als „RISC‑Pionier“ vorgestellt, doch sein nachhaltiger Einfluss reicht weiter als ein einzelnes CPU‑Design. Er half dabei, eine praktische Denkweise für Computer populär zu machen: Leistung als etwas zu betrachten, das man messen, vereinfachen und Ende‑zu‑Ende verbessern kann — von den Instruktionen, die ein Chip versteht, bis zu den Software‑Tools, die diese Instruktionen erzeugen.
RISC (Reduced Instruction Set Computing) ist die Idee, dass ein Prozessor schneller und vorhersehbarer läuft, wenn er sich auf eine kleinere Menge einfacher Instruktionen konzentriert. Anstatt eine riesige Auswahl komplizierter Operationen in Hardware einzubauen, macht man die häufigen Operationen schnell, regelmäßig und leicht pipelinbar. Die Belohnung ist nicht „weniger Fähigkeit“ — sondern dass einfache Bausteine, die effizient ausgeführt werden, in realen Workloads oft gewinnen.
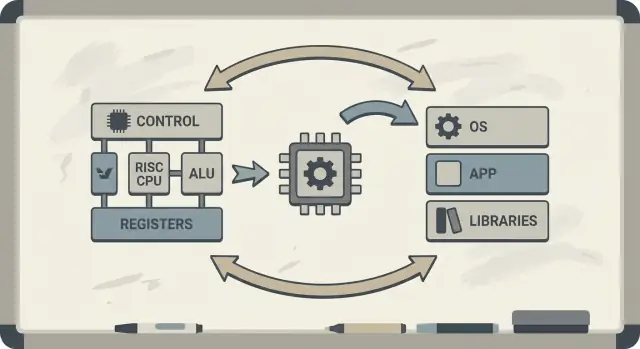
Patterson setzte sich außerdem für Hardware‑Software‑Co‑Design ein: eine Rückkopplungsschleife, in der Chiparchitekten, Compiler‑Autoren und Systemdesigner gemeinsam iterieren.
Wenn ein Prozessor darauf ausgelegt ist, einfache Muster gut auszuführen, können Compiler zuverlässig diese Muster erzeugen. Wenn Compiler zeigen, dass reale Programme Zeit in bestimmten Operationen verbringen (z. B. Speicherzugriffen), kann die Hardware angepasst werden, um diese Fälle besser zu behandeln. Deshalb verbinden sich Diskussionen über eine Befehlssatzarchitektur (ISA) organisch mit Compiler‑Optimierungen, Caching und Pipelining.
Sie erfahren, warum RISC‑Ideen mit Leistung pro Watt zusammenhängen (nicht nur rohe Geschwindigkeit), wie „Vorhersagbarkeit" moderne CPUs und Mobilchips effizienter macht und wie sich diese Prinzipien in heutigen Geräten zeigen — von Laptops bis zu Cloud‑Servern.
Wenn Sie zuerst eine Übersicht der Kernkonzepte möchten, springen Sie zu /blog/key-takeaways-and-next-steps.
Frühe Mikroprozessoren wurden unter engen Randbedingungen gebaut: Chips hatten begrenzten Platz für Schaltungen, Speicher war teuer und Massenspeicher langsam. Entwickler versuchten, erschwingliche und „schnell genug“ Computer auszuliefern, oft mit kleinen (oder keinen) Caches, moderaten Taktraten und sehr begrenztem Hauptspeicher im Vergleich zu dem, was Software wollte.
Eine damals populäre Idee war, dass CPU‑bietet umfassendere, höherstufige Instruktionen — solche, die mehrere Schritte auf einmal erledigen können — Programme schneller und leichter zu schreiben machen würden. Wenn eine Instruktion „die Arbeit von mehreren“ erledigen könnte, so die Überlegung, bräuchte man insgesamt weniger Instruktionen, was Zeit und Speicher spart.
Das ist die Intuition hinter vielen CISC‑Designs: Programmierern und Compilern eine große Werkzeugkiste mit schicken Operationen geben.
Der Haken war, dass reale Programme (und die Compiler, die sie übersetzen) diese Komplexität nicht konsistent nutzten. Viele der aufwändigsten Instruktionen wurden selten gebraucht, während eine kleine Menge einfacher Operationen — Daten laden, Daten speichern, addieren, vergleichen, verzweigen — immer wieder auftauchten.
Gleichzeitig machte die Unterstützung einer riesigen Auswahl komplexer Instruktionen CPUs schwerer zu bauen und langsamer zu optimieren. Komplexität fraß Chipfläche und Entwicklungsaufwand, der hätte dazu verwendet werden können, die häufigen, alltäglichen Pfade vorhersehbar und schnell zu machen.
RISC war eine Antwort auf diese Lücke: Konzentriere die CPU auf das, was Software tatsächlich am meisten tut, und mache diese Pfade schnell — und lass Compiler systematisch mehr „Orchestrierung“ übernehmen.
Eine einfache Art, CISC vs RISC zu betrachten, ist ein Vergleich von Werkzeugkästen.
CISC (Complex Instruction Set Computing) ist wie eine Werkstatt mit vielen spezialisierten, ausgefallenen Werkzeugen — jedes kann in einem Zug viel erledigen. Eine einzelne „Instruktion“ könnte Daten aus dem Speicher laden, eine Berechnung durchführen und das Ergebnis speichern, alles gebündelt.
RISC (Reduced Instruction Set Computing) ist wie ein kleinerer Satz verlässlicher Werkzeuge, die man ständig benutzt — Hammer, Schraubendreher, Maßband — und alles aus wiederholbaren Schritten baut. Jede Instruktion macht in der Regel eine kleine, klare Aufgabe.
Wenn Instruktionen einfacher und einheitlicher sind, kann die CPU sie mit einer saubereren Fertigungsstraße (einer Pipeline) ausführen. Diese Fertigungsstraße ist leichter zu entwerfen, bei höheren Taktraten zu betreiben und besser ausgelastet zu halten.
Bei CISC‑artigen „viel‑machen“-Instruktionen muss die CPU oft eine komplexe Instruktion dekodieren und in kleinere interne Schritte zerlegen. Das kann zusätzliche Komplexität bringen und es schwieriger machen, die Pipeline glatt laufen zu lassen.
RISC zielt auf vorhersagbare Instruktionslaufzeit ab — viele Instruktionen dauern ungefähr gleich lang. Vorhersagbarkeit hilft der CPU, Arbeit effizient zu planen, und hilft Compilern, Code zu generieren, der die Pipeline füllt, statt sie ins Stocken zu bringen.
RISC benötigt meist mehr Instruktionen, um dieselbe Aufgabe zu erledigen. Das kann bedeuten:
Das kann sich dennoch lohnen, wenn jede Instruktion schnell ist, die Pipeline glatt bleibt und das Gesamtentwurf einfacher ist.
In der Praxis können gut optimierende Compiler und guter Cache diese „mehr Instruktionen“-Nachteile ausgleichen — und die CPU verbringt mehr Zeit mit nützlicher Arbeit statt damit, komplizierte Instruktionen aufzulösen.
Berkeley RISC war nicht nur ein neuer Befehlssatz. Es war eine Forschungshaltung: Fang nicht mit dem an, was auf dem Papier elegant erscheint — fang mit dem an, was Programme tatsächlich tun, und forme die CPU um diese Realität.
Konzeptionell strebte das Berkeley‑Team einen CPU‑Kern an, der so einfach ist, dass er sehr schnell und vorhersehbar laufen kann. Anstatt die Hardware mit vielen komplizierten Instruktions‑„Tricks“ vollzustopfen, verließen sie sich darauf, dass der Compiler mehr Arbeit übernimmt: unkomplizierte Instruktionen wählen, sie gut timen und Daten so weit wie möglich in Registern halten.
Diese Arbeitsteilung war entscheidend. Ein kleinerer, sauberer Kern lässt sich besser pipelinen, besser analysieren und ist oft pro Transistor schneller. Der Compiler, der das ganze Programm sieht, kann vorausschauender planen, als es die Hardware zur Laufzeit leicht könnte.
David Patterson betonte Messung, weil Computerkonstruktion voller verführerischer Mythen ist — Features, die nützlich klingen, aber in echtem Code selten auftreten. Berkeley RISC drängte darauf, Benchmarks und Workload‑Traces zu verwenden, um die heißen Pfade zu finden: die Schleifen, Funktionsaufrufe und Speicherzugriffe, die die Laufzeit dominieren.
Das hängt direkt mit dem Prinzip „mach den häufigen Fall schnell“ zusammen. Wenn die meisten Instruktionen einfache Operationen und Loads/Stores sind, zahlt es sich mehr aus, diese häufigen Fälle zu optimieren, als seltene, komplexe Instruktionen zu beschleunigen.
Die dauerhafte Erkenntnis ist, dass RISC sowohl eine Architektur als auch eine Denkweise war: vereinfache das Häufige, validiere mit Daten und betrachte Hardware und Software als ein einziges System, das gemeinsam abgestimmt werden kann.
Hardware–Software‑Co‑Design heißt, dass man eine CPU nicht isoliert entwirft. Man gestaltet den Chip und den Compiler (und manchmal das Betriebssystem) gemeinsam, sodass reale Programme schnell und effizient laufen — nicht nur synthetische „Best‑Case“ Instruktionssequenzen.
Co‑Design funktioniert wie eine Ingenieursschleife:
ISA‑Entscheidungen: Die Befehlssatzarchitektur entscheidet, was die CPU leicht ausdrücken kann (z. B. Load/Store‑Zugriffe, viele Register, einfache Adressierungsarten).
Compiler‑Strategien: Der Compiler passt sich an — hält heiße Variablen in Registern, ordnet Instruktionen um, um Stalls zu vermeiden, und wählt Calling‑Conventions, die Overhead reduzieren.
Workload‑Ergebnisse: Man misst reale Programme (Compiler, Datenbanken, Grafik, OS‑Code) und sieht, wo Zeit und Energie hingehen.
Nächster Entwurf: Man passt ISA und Mikroarchitektur (Pipeline‑Tiefe, Anzahl Register, Cache‑Größen) basierend auf diesen Messungen an.
Hier ist eine kleine Schleife (C), die die Beziehung verdeutlicht:
for (int i = 0; i < n; i++)
sum += a[i];
Auf einer RISC‑artigen ISA hält der Compiler typischerweise sum und i in Registern, nutzt einfache load‑Instruktionen für a[i] und führt Instruktions‑Scheduling durch, damit die CPU beschäftigt bleibt, während ein Load unterwegs ist.
Wenn ein Chip komplexe Instruktionen oder spezielle Hardware hinzufügt, die Compiler kaum verwenden, verbraucht dieser Bereich trotzdem Energie und Entwicklungsaufwand. Unterdessen könnten die „langweiligen“ Dinge, auf die Compiler wirklich angewiesen sind — genügend Register, vorhersehbare Pipelines, effiziente Calling‑Conventions — unterfinanziert bleiben.
Pattersons RISC‑Denken betonte, Silizium dort einzusetzen, wo reale Software tatsächlich Nutzen hat.
Eine zentrale RISC‑Idee war, die CPU‑„Fabrikstraße" leichter ausgelastet zu halten. Diese Fabrikstraße ist die Pipeline: Anstatt eine Instruktion komplett zu beenden, bevor die nächste beginnt, teilt der Prozessor die Arbeit in Stufen (Fetch, Decode, Execute, Write‑Back) und überlappt sie. Wenn alles fließt, beendet man nahe einer Instruktion pro Takt — wie Autos, die durch eine mehrstationige Fertigung fahren.
Pipelines funktionieren am besten, wenn jeder Gegenstand auf der Linie ähnlich ist. RISC‑Instruktionen wurden so entworfen, relativ einheitlich und vorhersehbar zu sein (oft feste Länge, mit einfachen Adressierungsarten). Das reduziert Sonderfälle, in denen eine Instruktion zusätzliche Zeit oder ungewöhnliche Ressourcen benötigt.
Reale Programme laufen nicht perfekt glatt. Manchmal hängt eine Instruktion vom Ergebnis einer vorherigen ab (man kann einen Wert nicht verwenden, bevor er berechnet ist). Manchmal muss die CPU auf Daten aus dem Speicher warten, oder sie weiß noch nicht, welchen Pfad ein Branch nimmt.
Diese Situationen verursachen Stalls — kurze Pausen, in denen ein Teil der Pipeline untätig ist. Die Intuition ist einfach: Stalls entstehen, wenn die nächste Stufe keine nützliche Arbeit leisten kann, weil etwas, das sie braucht, noch nicht angekommen ist.
Hier zeigt sich Hardware‑Software‑Co‑Design besonders deutlich. Wenn die Hardware vorhersehbar ist, kann der Compiler helfen, indem er die Instruktionsreihenfolge umordnet (ohne die Bedeutung des Programms zu ändern), um „Lücken“ zu füllen. Zum Beispiel könnte der Compiler, während er auf ein Ergebnis wartet, eine unabhängige Instruktion einplanen, die nicht von diesem Ergebnis abhängt.
Die Belohnung ist geteilte Verantwortung: Die CPU bleibt einfacher und schnell im normalen Fall, während der Compiler mehr Planung übernimmt. Zusammen reduzieren sie Stalls und erhöhen den Durchsatz — oft mit besseren realen Leistungswerten, ohne die ISA unnötig zu verkomplizieren.
Eine CPU kann einfache Operationen in wenigen Zyklen ausführen, aber das Laden von Daten aus dem Hauptspeicher (DRAM) kann Hunderte von Zyklen dauern. Diese Lücke existiert, weil DRAM physisch weiter entfernt ist, für Kapazität und Kosten optimiert ist und durch Latenz (Dauer einer Anfrage) und Bandbreite (Bytes pro Sekunde) begrenzt wird.
Als CPUs schneller wurden, hielt der Speicher nicht im gleichen Tempo mit — diese wachsende Diskrepanz nennt man oft die Memory‑Wall.
Caches sind kleine, schnelle Speicher nahe der CPU, die verhindern, dass man bei jedem Zugriff das DRAM bezahlen muss. Sie funktionieren, weil reale Programme Lokalität haben:
Moderne Chips stapeln Caches (L1, L2, L3), um das „Working Set“ von Code und Daten nah am Kern zu halten.
Hier zahlt sich Hardware‑Software‑Co‑Design aus. ISA und Compiler formen zusammen, wie viel Cache‑Druck ein Programm erzeugt.
Alltagsgemäß ist die Memory‑Wall der Grund, warum sich eine CPU mit hoher Taktfrequenz dennoch träge anfühlen kann: Eine große App öffnen, eine Datenbankabfrage ausführen, durch einen Feed scrollen oder ein großes Dataset verarbeiten wird oft durch Cache‑Misses und Speicherbandbreite begrenzt — nicht durch rohe Rechenleistung.
Lange Zeit klang die CPU‑Diskussion wie ein Rennen: Welcher Chip eine Aufgabe am schnellsten beendet, „gewinnt“. Aber echte Computer leben in physikalischen Grenzen — Batteriekapazität, Wärme, Lüfterlärm und Stromkosten.
Deshalb wurde Leistung pro Watt zu einer zentralen Kennzahl: wie viel nützliche Arbeit man für die eingesetzte Energie erhält.
Denken Sie daran als Effizienz, nicht als Spitzenleistung. Zwei Prozessoren können sich im Alltag ähnlich schnell anfühlen, aber einer schafft das bei geringerem Energiebedarf, kühlt leichter und läuft länger mit derselben Batterie.
In Laptops und Telefonen wirkt sich das direkt auf Laufzeit und Komfort aus. In Rechenzentren beeinflusst es die Kosten für Strom und Kühlung sowie die Dichte, mit der Server ohne Überhitzung platziert werden können.
RISC‑Denken trieb CPU‑Designs in Richtung, weniger in Hardware zu verbergen und Vorhersagbarkeit zu erhöhen. Ein einfacherer Kern kann Energie auf mehrere Weise sparen:
Damit ist nicht gesagt, dass „einfach immer besser“ ist. Sondern: Komplexität hat einen Energiepreis, und eine gut gewählte ISA und Mikroarchitektur können etwas Cleverness gegen viel Effizienz tauschen.
Handys achten auf Akku und Wärme; Server auf Stromversorgung und Kühlung. Unterschiedliche Umgebungen, dieselbe Lehre: Der schnellste Chip ist nicht immer der beste Computer. Gewinner sind oft Entwürfe, die stetigen Durchsatz liefern und dabei den Energieverbrauch im Griff behalten.
RISC wird oft als „einfachere Instruktionen gewinnen“ zusammengefasst, aber die dauerhaftere Lehre ist subtiler: Der Befehlssatz ist wichtig, doch viele reale Gewinne kamen von der Art, wie Chips implementiert wurden, nicht nur davon, wie die ISA auf dem Papier aussah.
Frühe RISC‑Argumente ließen vermuten, ein sauberer, kleiner ISA mache Computer automatisch schneller. In der Praxis kamen die größten Beschleunigungen oft von Implementationsentscheidungen, die RISC erleichterte: einfachere Dekodierung, tieferes Pipelining, höhere Taktraten und Compiler, die Arbeit vorhersehbar timen konnten.
Deshalb können zwei CPUs mit unterschiedlichen ISAs in Leistung überraschend nah beieinander liegen, wenn Mikroarchitektur, Cache‑Größen, Zweigvorhersage und Fertigungsprozess unterschiedlich sind. Die ISA legt die Regeln fest; die Mikroarchitektur spielt das Spiel.
Eine zentrale Patterson‑Ära‑Verschiebung war, vom Daten getrieben zu entwerfen, nicht von Annahmen. Anstatt Instruktionen hinzuzufügen, weil sie „nützlich erscheinen", maß man, was Programme tatsächlich tun, und optimierte den häufigen Fall.
Diese Haltung schlug oft Feature‑getriebene Designs, bei denen Komplexität schneller wächst als der Nutzen. Sie macht auch Trade‑offs klar: Eine Instruktion, die ein paar Codezeilen spart, kann extra Zyklen, Energie oder Chipfläche kosten — und diese Kosten wirken sich überall aus.
RISC‑Denken formte nicht nur „RISC‑Chips“. Im Laufe der Zeit übernahmen viele CISC‑CPUs RISC‑ähnliche interne Techniken (z. B. Zerlegung komplexer Instruktionen in einfachere interne Operationen) und behielten gleichzeitig ihre kompatible ISA.
Das Ergebnis war also kein „RISC hat CISC geschlagen“. Es war eine Evolution hin zu Entwürfen, die Messung, Vorhersagbarkeit und enge Hardware‑Software‑Koordination schätzten — unabhängig vom ISA‑Logo.
RISC blieb nicht im Labor. Eine der klarsten Linien von früherer Forschung zur modernen Praxis verläuft von MIPS zu RISC‑V — zwei ISAs, die Einfachheit und Klarheit als Feature statt als Einschränkung verstanden.
MIPS wird oft als Lehr‑ISA in Erinnerung behalten — und das zu Recht: Die Regeln sind leicht zu erklären, die Instruktionsformate konsistent und das Load/Store‑Modell macht dem Compiler das Leben leichter.
Diese Sauberkeit war nicht nur akademisch. MIPS‑Prozessoren wurden jahrelang in echten Produkten verbaut (von Workstations bis zu Embedded‑Systemen), teilweise weil ein geradliniger ISA das Bauen schneller Pipelines, vorhersehbarer Compiler und effizienter Toolchains vereinfachte. Wenn Hardwareverhalten regelmäßig ist, kann Software darum herum planen.
RISC‑V belebte das RISC‑Denken neu, indem es einen Schritt ging, den MIPS nie vollständig tat: Es ist eine offene ISA. Das ändert die Anreize. Universitäten, Startups und große Firmen können experimentieren, Silizium ausliefern und Tooling teilen, ohne Zugangsbarrieren zum Befehlssatz.
Für Co‑Design ist diese Offenheit wichtig, weil die „Software‑Seite“ (Compiler, OS, Runtimes) öffentlich zusammen mit der „Hardware‑Seite“ evolvieren kann, mit weniger künstlichen Hürden.
Ein weiterer Grund, warum RISC‑V so gut zu Co‑Design passt, ist sein modularer Ansatz. Man beginnt mit einem kleinen Basis‑ISA und fügt Erweiterungen für spezifische Bedürfnisse hinzu — Vektorrechnen, Embedded‑Beschränkungen oder Sicherheitsfeatures.
Das fördert einen gesünderen Trade‑off: Anstatt alle möglichen Features in ein monolithisches Design zu stopfen, können Teams Hardware‑Funktionen an die Software anpassen, die sie tatsächlich ausführen.
Wenn Sie eine tiefere Einführung möchten, siehe /blog/what-is-risc-v.
Co‑Design ist kein historischer Fußnotenbegriff aus der RISC‑Ära — es ist der Weg, wie moderne Informatik schneller und effizienter wird. Die Kernidee bleibt Patterson‑artig: Man „gewinnt“ nicht allein mit Hardware oder allein mit Software. Man gewinnt, wenn beide ihre Stärken und Beschränkungen aufeinander abstimmen.
Smartphones und viele Embedded‑Geräte orientieren sich stark an RISC‑Prinzipien (oft ARM‑basiert): einfachere Instruktionen, vorhersagbare Ausführung und starker Fokus auf Energieverbrauch.
Diese Vorhersagbarkeit hilft Compilern, effizienten Code zu erzeugen, und Designern, Kerne zu bauen, die beim Scrollen wenig Energie verbrauchen, aber für Kamera‑Pipelines oder Spiele kurzzeitig aufschwingen können.
Laptops und Server verfolgen zunehmend dieselben Ziele — besonders die "Leistung pro Watt". Selbst wenn die ISA nicht traditionell „RISC“ ist, zielen viele interne Designentscheidungen auf RISC‑ähnliche Effizienz: tiefes Pipelining, breite Ausführung und aggressives Energiemanagement, abgestimmt auf reales Softwareverhalten.
GPUs, KI‑Beschleuniger (TPUs/NPUs) und Media‑Engines sind praktische Formen des Co‑Designs: Anstatt alle Last durch eine allgemeine CPU zu pressen, stellt die Plattform Hardware bereit, die zu gängigen Rechenmustern passt.
Was das zu Co‑Design macht (und nicht nur „zusätzliche Hardware“) ist der umgebende Software‑Stack:
Wenn die Software den Beschleuniger nicht anspricht, bleibt die theoretische Geschwindigkeit theoretisch.
Zwei Plattformen mit ähnlichen Spezifikationen können sehr unterschiedlich wirken, weil das „reale Produkt“ Compiler, Bibliotheken und Frameworks umfasst. Eine gut optimierte mathematische Bibliothek (BLAS), ein guter JIT oder ein schlauerer Compiler können ohne Chipänderung große Gewinne bringen.
Deshalb ist modernes CPU‑Design oft benchmarkgetrieben: Hardware‑Teams schauen, was Compiler und Workloads tatsächlich tun, und passen Features (Caches, Branch Prediction, Vektorinstruktionen, Prefetching) so an, dass der häufige Fall schneller wird.
Wenn Sie eine Plattform (Phone, Laptop, Server oder embedded Board) bewerten, suchen Sie nach Co‑Design‑Signalen:
Moderner Fortschritt in der Rechnerwelt dreht sich weniger um eine einzige „schnellere CPU“ und mehr um ein ganzes Hardware‑plus‑Software‑System, das gemessen, dann entworfen, um reale Workloads herum abgestimmt wurde.
RISC‑Denken und Pattersons breitere Botschaft lassen sich auf einige dauerhafte Lektionen reduzieren: Vereinfache, was schnell sein muss; messe, was tatsächlich passiert; und betrachte Hardware und Software als ein System — denn Benutzer erleben das Ganze, nicht die Einzelteile.
Erstens: Einfachheit ist eine Strategie, kein ästhetisches Ziel. Ein sauberer ISA und vorhersehbare Ausführung machen es Compilern leichter, guten Code zu erzeugen, und CPUs leichter, diesen Code effizient auszuführen.
Zweitens: Messen schlägt Intuition. Benchmarken Sie mit repräsentativen Workloads, sammeln Sie Profiling‑Daten und lassen Sie reale Engpässe Design‑Entscheidungen leiten — egal ob Sie Compiler‑Optimierungen tun, eine CPU‑SKU wählen oder einen kritischen Hot‑Path neu entwerfen.
Drittens: Co‑Design ist, wo sich Gewinne kumulieren. Pipeline‑freundlicher Code, cache‑bewusste Datenstrukturen und realistische Leistung‑pro‑Watt‑Ziele liefern oft praktischere Beschleunigung als das Jagen nach theoretischer Spitzenleistung.
Wenn Sie eine Plattform auswählen (x86, ARM oder RISC‑V‑basierte Systeme), bewerten Sie sie so, wie Ihre Nutzer sie erleben:
Wenn ein Teil Ihrer Arbeit daraus besteht, diese Messungen in ausgelieferte Software zu verwandeln, hilft es, die Build‑Measure‑Schleife zu verkürzen. Teams nutzen z. B. Koder.ai, um reale Anwendungen durch einen chatgesteuerten Workflow (Web, Backend, Mobile) zu prototypisieren und weiterzuentwickeln und nach jeder Änderung dieselben Ende‑zu‑Ende‑Benchmarks erneut laufen zu lassen. Features wie Planungsmodus, Snapshots und Rollback unterstützen dieselbe „messen, dann entwerfen“‑Disziplin, die Patterson vorantrieb — angewandt auf moderne Produktentwicklung.
Für eine tiefere Einführung zu Effizienz siehe /blog/performance-per-watt-basics. Wenn Sie Umgebungen vergleichen und eine einfache Abschätzung von Kosten/Leistung brauchen, kann /pricing helfen.
Die dauerhafte Erkenntnis: Die Ideen — Einfachheit, Messung und Co‑Design — zahlen sich weiter aus, während Implementierungen sich von MIPS‑Ära‑Pipelines zu modernen heterogenen Kernen und neuen ISAs wie RISC‑V entwickeln.
RISC (Reduced Instruction Set Computing) setzt auf eine kleinere Menge einfacher, regelmäßiger Instruktionen, die sich gut pipelinen und optimieren lassen. Das Ziel ist nicht „weniger Fähigkeit“, sondern vorhersagbarere, effizientere Ausführung der Operationen, die reale Programme am häufigsten verwenden (Laden/Speichern, Arithmetik, Sprünge).
CISC bietet viele komplexe, spezialisierte Instruktionen, die manchmal mehrere Schritte in einer Anweisung bündeln. RISC arbeitet mit einfacheren Bausteinen (oft Load/Store + ALU-Operationen) und überlässt dem Compiler das effiziente Zusammensetzen dieser Bausteine. Bei modernen Prozessoren ist die Grenze verschwommen, weil viele CISC‑Chips komplexe Instruktionen intern in einfachere Mikro‑Operationen aufspalten.
Einfachere, gleichmäßigere Instruktionen erleichtern den Aufbau einer ruhigen Pipeline (eine „Fließband“-Verarbeitung von Instruktionen). Das kann den Durchsatz verbessern (nah an einer Instruktion pro Takt) und reduziert Zeit, die für Sonderfälle nötig ist — das hilft sowohl der Leistung als auch dem Energieverbrauch.
Ein vorhersehbares ISA- und Ausführungsmodell ermöglicht es Compilern zuverlässig:
load/store darzustellenDas reduziert Pipeline‑Lücken und unnötige Arbeit und verbessert reale Leistung, ohne komplizierte Hardware‑Features einzubauen, die die Software kaum nutzt.
Hardware‑Software‑Co‑Design ist eine iterative Schleife, in der ISA‑Entscheidungen, Compiler‑Strategien und gemessene Workload‑Ergebnisse sich gegenseitig informieren. Anstatt eine CPU isoliert zu entwerfen, stimmen Teams Hardware, Toolchain und manchmal OS/Runtime so ab, dass reale Programme schneller und effizienter laufen.
Stalls treten auf, wenn die Pipeline nicht weiterarbeiten kann, weil etwas fehlt:
RISC‑ähnliche Vorhersagbarkeit hilft Hardware und Compilern, Häufigkeit und Kosten solcher Pausen zu reduzieren.
Die „Memory Wall“ ist die wachsende Lücke zwischen schneller CPU‑Ausführung und langsamen Hauptspeicherzugriffen (DRAM). Caches (L1/L2/L3) mildern das, indem sie Lokalität ausnutzen:
Trotzdem können Cache‑Misses die Laufzeit dominieren und Programme selbst auf schnellen Kernen speichergebunden machen.
„Leistung pro Watt" ist ein Maß für Effizienz: wie viel nutzbare Arbeit man pro Energieeinheit bekommt. Praktisch beeinflusst das Akkulaufzeit, Wärmeentwicklung, Lüfterlauf und die Kosten für Strom/Kühlung in Rechenzentren. Entwürfe, die von RISC‑Gedanken beeinflusst sind, streben oft vorhersagbare Ausführung und weniger verschwendete Schaltaktivität an, was die Leistung pro Watt verbessert.
Viele CISC‑Designs übernahmen intern RISC‑ähnliche Techniken (Pipelining, Zerlegung komplexer Instruktionen in Mikro‑Ops, Fokus auf Caches und Vorhersage), während sie die Abwärtskompatibilität beibehielten. Der langfristige Gewinn war also weniger ein klarer „Sieg“ einer ISA, sondern die Denkweise: echte Workloads messen, den häufigen Fall optimieren und Hardware an Compiler/Software anpassen.
RISC‑V ist eine offene ISA mit einem kleinen Grundkern und modularen Erweiterungen, wodurch sie sich besonders gut für Co‑Design eignet: Teams können Hardware‑Features gezielt an Softwarebedürfnisse koppeln und Toolchains öffentlich weiterentwickeln. Damit setzt RISC‑V die RISC‑Philosophie (simpler Kern + starke Tools + Messen) in die heutige Zeit fort. Mehr dazu: /blog/what-is-risc-v.