Warum Echtzeit‑Apps sich langsam anfühlen, obwohl der Code schnell ist
Geschwindigkeit hat zwei Seiten: Durchsatz und Latenz. Durchsatz ist, wie viel Arbeit Sie pro Sekunde erledigen (Anfragen, Nachrichten, Frames). Latenz ist, wie lange eine einzelne Arbeitseinheit von Anfang bis Ende braucht.
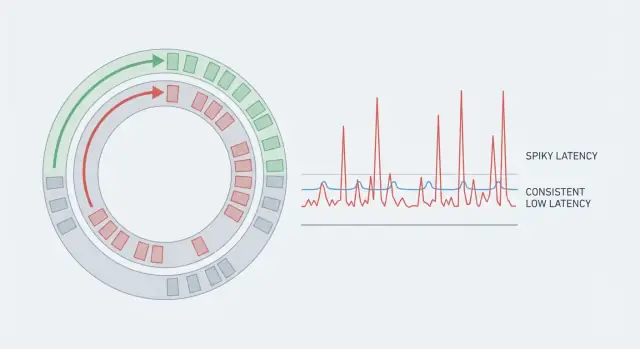
Ein System kann großartigen Durchsatz haben und sich trotzdem langsam anfühlen, wenn manche Anfragen deutlich länger dauern als andere. Deshalb täuschen Durchschnitte. Wenn 99 Aktionen 5 ms brauchen und eine 80 ms, sieht der Durchschnitt gut aus, aber die Person, die den 80‑ms‑Fall trifft, spürt das Stottern. In Echtzeitsystemen sind diese seltenen Spitzen die ganze Geschichte, weil sie den Rhythmus zerstören.
Vorhersehbare Latenz heißt, Sie zielen nicht nur auf einen niedrigen Durchschnitt. Sie zielen auf Konsistenz, sodass die meisten Operationen in einem engen Bereich fertig werden. Deshalb schauen Teams auf die Tail‑Werte (p95, p99). Dort verstecken sich die Pausen.
Ein 50‑ms‑Spike kann wichtig sein bei Sprach‑ und Videoanwendungen (Audio‑Glitches), Multiplayer‑Spielen (Rubber‑Banding), Echtzeit‑Trading (verpasste Preise), industrieller Überwachung (zu späte Alarme) und Live‑Dashboards (zahlen springen, Alerts wirken unzuverlässig).
Ein einfaches Beispiel: Eine Chat‑App liefert meistens schnell Nachrichten. Wenn aber eine Hintergrundpause eine Nachricht um 60 ms verzögert, flackern Tipp‑Indikatoren und die Unterhaltung wirkt träge, obwohl der Server im Durchschnitt „schnell“ aussieht.
Wenn Echtzeit echt wirken soll, brauchen Sie weniger Überraschungen, nicht nur schnelleren Code.
Latenz‑Basics: Wohin die Zeit wirklich geht
Die meisten Echtzeitsysteme sind nicht langsam, weil die CPU kämpft. Sie wirken langsam, weil Arbeit die meiste Zeit wartet: darauf, ausgeführt zu werden, in einer Warteschlange zu stehen, auf das Netzwerk oder auf Storage zu warten.
End‑to‑end‑Latenz ist die gesamte Zeit von „etwas ist passiert“ bis „der Nutzer sieht das Ergebnis“. Selbst wenn Ihr Handler 2 ms läuft, kann die Anfrage 80 ms dauern, wenn sie an fünf verschiedenen Stellen pausiert.
Eine nützliche Zerlegung des Pfads ist:
- Netzwerkzeit (Client zu Edge, Service zu Service, Retries)
- Scheduling‑Zeit (Ihr Thread wartet aufs Ausführen)
- Queue‑Zeit (Arbeit steht hinter anderer Arbeit)
- Storage‑Zeit (Disk, Datenbanksperren, Cache‑Misses)
- Serialisierungszeit (Kodieren und Dekodieren von Daten)
Diese Wartezeiten summieren sich. Ein paar Millisekunden hier und da verwandeln einen „schnellen“ Codepfad in eine langsame Erfahrung.
Tail‑Latenz ist, wo Nutzer anfangen zu klagen. Durchschnittswerte können gut aussehen, aber p95 oder p99 bedeuten die langsamsten 5 % bzw. 1 % der Anfragen. Ausreißer kommen meist von seltenen Pausen: einer GC‑Phase, einem lauten Nachbarn auf dem Host, kurzer Lock‑Contention, einem Cache‑Refill oder einem Ansturm, der eine Warteschlange erzeugt.
Konkretes Beispiel: Ein Preisupdate kommt in 5 ms über das Netzwerk an, wartet 10 ms auf einen beschäftigten Worker, steht 15 ms hinter anderen Events und trifft dann auf einen Datenbank‑Stall für 30 ms. Ihr Code lief immer noch in 2 ms, aber der Nutzer wartete 62 ms. Das Ziel ist, jeden Schritt vorhersehbar zu machen, nicht nur die Berechnung schnell.
Die üblichen Quellen für Jitter jenseits der Codegeschwindigkeit
Ein schneller Algorithmus kann sich trotzdem langsam anfühlen, wenn die Zeit pro Anfrage schwankt. Nutzer bemerken Spitzen, nicht Durchschnitte. Diese Schwankung ist Jitter und kommt oft von Dingen, die Ihr Code nicht vollständig kontrolliert.
CPU‑Caches und Speicherverhalten sind versteckte Kosten. Wenn Hot‑Daten nicht in den Cache passen, stagniert die CPU, während sie auf RAM wartet. Objekt‑reiche Strukturen, verstreuter Speicher und „nur noch ein Lookup“ können zu wiederholten Cache‑Misses werden.
Speicherallokation bringt eigene Zufälligkeit. Viele kurzlebige Objekte belasten den Heap und führen später zu Pausen (Garbage Collection) oder Allokator‑Contention. Selbst ohne GC können häufige Allokationen den Speicher fragmentieren und Lokalität verschlechtern.
Thread‑Scheduling ist eine weitere häufige Quelle. Wenn ein Thread descheduled wird, zahlen Sie Kontextwechsel‑Overhead und verlieren Cache‑Wärme. Auf einer vollen Maschine kann Ihr „Echtzeit‑Thread“ hinter fremder Arbeit warten.
Lock‑Contention ist ein Punkt, an dem vorhersehbare Systeme oft scheitern. Ein Lock, das „meist frei“ ist, kann in einen Konvoi verwandelt werden: Threads wachen auf, kämpfen um das Lock und bringen einander wieder zum Schlafen. Die Arbeit wird erledigt, aber die Tail‑Latenz dehnt sich.
I/O‑Warten können alles übertreffen. Ein einzelner Systemaufruf, ein voller Netzwerkpuffer, ein TLS‑Handshake, ein Disk‑Flush oder ein langsamer DNS‑Lookup können eine scharfe Spitze erzeugen, die keine Mikro‑Optimierung behebt.
Wenn Sie Jitter jagen, schauen Sie nach Cache‑Misses (oft verursacht durch pointer‑reiche Strukturen und zufälligen Zugriff), häufigen Allokationen, Kontextwechseln durch zu viele Threads oder laute Nachbarn, Lock‑Contention und jedem blockierenden I/O (Netzwerk, Disk, Logging, synchrone Aufrufe).
Beispiel: Ein Price‑Ticker‑Service rechnet Updates in Mikrosekunden, aber ein synchroner Logger‑Aufruf oder ein contended Metrics‑Lock kann sporadisch zehnende Millisekunden hinzufügen.
Martin Thompson und was das Disruptor‑Muster ist
Martin Thompson ist in der Low‑Latency‑Ingenieurswelt bekannt dafür, Systeme unter Last zu betrachten: nicht nur Durchschnittsgeschwindigkeit, sondern vorhersehbare Geschwindigkeit. Zusammen mit dem LMAX‑Team half er, das Disruptor‑Pattern zu popularisieren, einen Referenzansatz, um Ereignisse mit kleinen und konsistenten Verzögerungen durch ein System zu bewegen.
Der Disruptor‑Ansatz ist eine Reaktion auf das, was viele „schnelle“ Apps unvorhersehbar macht: Contention und Koordination. Typische Queues verlassen sich oft auf Locks oder schwere Atomics, wecken Threads rauf und runter und erzeugen Warte‑Burst, wenn Producer und Consumer um gemeinsame Strukturen kämpfen.
Statt einer Queue nutzt Disruptor einen Ringpuffer: ein festgrößiges zirkuläres Array mit Slots für Events. Producer beanspruchen den nächsten Slot, schreiben Daten und publizieren dann eine Sequenznummer. Consumer lesen in Reihenfolge, indem sie dieser Sequenz folgen. Da der Puffer vorallokiert ist, vermeiden Sie häufige Allokationen und reduzieren Druck auf die Garbage Collection.
Eine Schlüsselidee ist das Single‑Writer‑Prinzip: Halten Sie eine Komponente für ein bestimmtes geteiltes Stück Zustand verantwortlich (zum Beispiel den Cursor, der durch den Ring läuft). Weniger Schreiber bedeuten weniger „Wer ist als Nächstes dran?“-Momente.
Backpressure ist explizit. Wenn Consumer zurückfallen, erreichen Producer irgendwann einen noch genutzten Slot. An diesem Punkt muss das System warten, verwerfen oder langsamer werden — aber es passiert kontrolliert und sichtbar, statt das Problem in einer unendlich wachsenden Queue zu verstecken.
Kernideen im Design, die Latenz konsistent halten
Was Disruptor‑ähnliche Designs schnell macht, ist keine clevere Mikro‑Optimierung. Es ist das Entfernen unvorhersehbarer Pausen, die auftreten, wenn ein System gegen seine eigenen beweglichen Teile kämpft: Allokationen, Cache‑Misses, Lock‑Contention und langsame Arbeit im Hot‑Path.
Ein nützliches Modell ist eine Fertigungsstraße. Ereignisse bewegen sich entlang einer festen Route mit klaren Übergaben. Das reduziert geteilten Zustand und macht jeden Schritt einfacher beobachtbar und messbar.
Speicher und Daten vorhersehbar halten
Schnelle Systeme vermeiden überraschende Allokationen. Wenn Sie Puffer vorallokieren und Nachrichtenobjekte wiederverwenden, reduzieren Sie „manchmal“‑Spitzen, die durch Garbage Collection, Heap‑Wachstum und Allokator‑Locks verursacht werden.
Es hilft auch, Nachrichten klein und stabil zu halten. Wenn die Daten, die Sie pro Event berühren, in den CPU‑Cache passen, verbringen Sie weniger Zeit mit Warten auf Speicher.
Praktisch sind die Gewohnheiten, die meist am meisten zählen: Objekte wiederverwenden statt pro Event neu anzulegen, Ereignisdaten kompakt halten, einen einzelnen Writer für geteilten Zustand bevorzugen und sorgfältig batchen, sodass Sie Koordinationskosten seltener zahlen.
Langsame Pfade offensichtlich machen
Echtzeit‑Apps brauchen oft Extras wie Logging, Metriken, Retries oder Datenbank‑Writes. Die Disruptor‑Denkweise isoliert diese vom Kernloop, sodass sie ihn nicht blockieren können.
Bei einem Live‑Pricing‑Feed könnte der Hot‑Path nur ein Tick validieren und die nächste Preissnapshot publizieren. Alles, was stallern kann (Disk, Netzwerkaufrufe, schwere Serialisierung), wird zu einem separaten Consumer oder Side‑Channel verschoben, sodass der vorhersehbare Pfad vorhersehbar bleibt.
Architekturentscheidungen für vorhersehbare Latenz
Den kritischen Pfad inspizieren
Öffnen Sie den Quellcode und prüfen Sie Hot-Paths, Allokationen und blockierende Aufrufe.
Vorhersehbare Latenz ist vor allem ein Architekturproblem. Sie können schnellen Code haben und trotzdem Spitzen bekommen, wenn zu viele Threads um dieselben Daten kämpfen oder Nachrichten unnötig übers Netzwerk springen.
Beginnen Sie damit, zu entscheiden, wie viele Writer und Reader dieselbe Queue oder denselben Buffer berühren. Ein einzelner Producer ist einfacher glatt zu halten, weil er Koordination vermeidet. Multi‑Producer‑Setups erhöhen oft Durchsatz, bringen aber Contention und machen Worst‑Case‑Timing weniger vorhersehbar. Wenn Sie mehrere Producer brauchen, reduzieren Sie geteilte Writes durch Sharding nach Schlüssel (z. B. userId oder instrumentId), sodass jede Partition ihren eigenen Hot‑Path hat.
Auf der Consumer‑Seite sorgt ein einzelner Consumer für stabilere Timing‑Werte, wenn Reihenfolge wichtig ist, weil Zustand lokal in einem Thread bleibt. Worker‑Pools helfen, wenn Aufgaben wirklich unabhängig sind, aber sie fügen Scheduling‑Verzögerungen hinzu und können Arbeit neu ordnen, wenn Sie nicht aufpassen.
Batching ist ein weiterer Trade‑off. Kleine Batches senken Overhead (weniger Wakeups, weniger Cache‑Misses), können aber Wartezeit addieren, wenn Sie Events zurückhalten, um eine Batch zu füllen. Falls Sie in einem Echtzeitsystem batchen, begrenzen Sie die Wartezeit strikt (z. B. „bis zu 16 Events oder 200 Mikrosekunden, je nachdem, was zuerst eintritt").
Service‑Grenzen sind ebenfalls wichtig. In‑Process‑Messaging ist normalerweise am besten, wenn Sie enge Latenz benötigen. Netzwerk‑Hops lohnen sich fürs Skalieren, aber jeder Hop fügt Queues, Retries und variable Verzögerung hinzu. Wenn Sie einen Hop brauchen, halten Sie das Protokoll einfach und vermeiden Fan‑Out im Hot‑Path.
Praktische Regeln: Behalten Sie nach Möglichkeit einen Single‑Writer‑Pfad pro Shard, skalieren Sie durch Sharding von Schlüsseln statt eine Hot‑Queue zu teilen, batchen Sie nur mit striktem Zeitlimit, fügen Sie Worker‑Pools nur für parallele und unabhängige Arbeit hinzu und behandeln Sie jeden Netzwerk‑Hop als potenzielle Jitter‑Quelle, bis Sie sie gemessen haben.
Schritt für Schritt: Entwurf einer Low‑Jitter‑Pipeline
Beginnen Sie mit einem schriftlichen Latenzbudget, bevor Sie Code anfassen. Wählen Sie ein Ziel (wie „gut“ sich anfühlt) und ein p99 (worunter Sie bleiben müssen). Teilen Sie diese Zahl über Stufen wie Input, Validierung, Matching, Persistenz und Outbound‑Updates auf. Hat eine Stufe kein Budget, hat sie keine Grenze.
Zeichnen Sie dann den vollständigen Datenfluss und markieren Sie jede Übergabe: Thread‑Grenzen, Queues, Netzwerkhops und Storage‑Aufrufe. Jede Übergabe ist ein Ort, an dem Jitter lauert. Wenn Sie sie sehen, können Sie sie reduzieren.
Ein Workflow, der Designs ehrlich hält:
- Schreiben Sie ein pro‑Stufen‑Budget (Ziel und p99) plus einen kleinen Puffer für Unbekanntes.
- Kartieren Sie die Pipeline und kennzeichnen Sie Queues, Locks, Allokationen und blockierende Aufrufe.
- Wählen Sie ein Concurrency‑Modell, das Sie durchdenken können (Single Writer, partitionierte Worker nach Schlüssel oder ein dedizierter I/O‑Thread).
- Definieren Sie früh das Nachrichtenformat: stabile Schemata, kompakte Payloads und minimales Kopieren.
- Legen Sie Backpressure‑Regeln vorab fest: verwerfen, verzögern, degradieren oder Last abwerfen. Machen Sie das sichtbar und messbar.
Entscheiden Sie dann, was asynchron sein kann, ohne die Nutzererfahrung zu brechen. Eine einfache Regel: Alles, was das sieht, was der Nutzer „jetzt“ sieht, bleibt auf dem kritischen Pfad. Alles andere wird herausgenommen.
Analytics, Audit‑Logs und sekundäre Indexe können oft vom Hot‑Path weggeschoben werden. Validierung, Ordering und Schritte, die den nächsten Zustand erzeugen, können meist nicht verschoben werden.
Laufzeit‑ und OS‑Entscheidungen, die Tail‑Latenz beeinflussen
Schneller Code kann sich trotzdem langsam anfühlen, wenn Laufzeit oder OS Ihre Arbeit im falschen Moment pausieren. Das Ziel ist nicht nur hoher Durchsatz. Es ist weniger Überraschungen in den langsamsten 1 % der Anfragen.
Garbage‑collected Runtimes (JVM, Go, .NET) sind produktivitätsstark, können aber Pausen einführen, wenn Speicher bereinigt werden muss. Moderne Sammler sind besser geworden, doch Tail‑Latenz kann springen, wenn unter Last viele kurzlebige Objekte entstehen. Nicht‑GC‑Sprachen (Rust, C, C++) vermeiden GC‑Pauses, schieben aber die Kosten in manuelle Ownership und Allokationsdisziplin.
Die praktische Gewohnheit ist einfach: Finden Sie, wo Allokationen passieren, und machen Sie sie langweilig. Objekte wiederverwenden, Puffer vorgrößen und vermeiden, Hot‑Path‑Daten in temporäre Strings oder Maps zu verwandeln.
Thread‑Entscheidungen zeigen sich ebenfalls als Jitter. Jede zusätzliche Queue, jeder async‑Hop oder Thread‑Pool‑Handoff fügt Wartezeit und Varianz hinzu. Bevorzugen Sie wenige, langlebige Threads, halten Sie Producer‑Consumer‑Grenzen klar und vermeiden Sie blockierende Aufrufe auf dem Hot‑Path.
Einige OS‑ und Container‑Einstellungen entscheiden oft, ob Ihr Tail sauber oder stotternd ist. CPU‑Throttling durch enge Limits, laute Nachbarn auf geteilten Hosts und schlecht platziertes Logging oder Metriken können plötzliche Verlangsamungen auslösen. Wenn Sie nur eine Sache ändern, messen Sie Allokationsrate und Context‑Switches während Latenzspitzen.
Daten, Storage und Service‑Grenzen ohne Überraschungspausen
Ohne Angst iterieren
Führen Sie riskante Latenz-Experimente durch und rollen Sie zurück, wenn sich p99 verschlechtert.
Viele Latenzspitzen sind kein „langsamer Code“. Es sind ungeplante Wartezeiten: eine Datenbanksperre, ein Retry‑Sturm, ein blockierter Cross‑Service‑Call oder ein Cache‑Miss, das eine volle Rundetrip erzeugt.
Halten Sie den kritischen Pfad kurz. Jeder zusätzliche Hop fügt Scheduling, Serialisierung, Netzwerk‑Queues und mehr Blockierstellen hinzu. Wenn Sie eine Antwort in einem Prozess und einem Datenspeicher geben können, tun Sie das zuerst. Teilen Sie in mehr Services nur, wenn jeder Call optional oder strikt begrenzt ist.
Begrenztes Warten ist der Unterschied zwischen schnellen Durchschnitten und vorhersehbarer Latenz. Setzen Sie harte Timeouts auf Remote‑Aufrufe und schlagen Sie schnell fehl, wenn eine Abhängigkeit ungesund ist. Circuit Breaker dienen nicht nur dem Serversparen — sie begrenzen, wie lange Nutzer hängen bleiben können.
Wenn Datenzugriff blockiert, trennen Sie die Pfade. Reads wollen oft indexierte, denormalisierte, cache‑freundliche Formen. Writes wollen Durability und Ordering. Trennung kann Contention eliminieren und Sperrzeiten reduzieren. Falls Ihre Konsistenzanforderungen es erlauben, verhalten sich append‑only Records (Event‑Log) oft vorhersehbarer als In‑Place‑Updates, die Hot‑Row‑Locking oder Hintergrundwartung auslösen.
Eine einfache Regel für Echtzeit‑Apps: Persistenz sollte nicht auf dem kritischen Pfad liegen, es sei denn, Sie brauchen sie für Korrektheit. Häufiger ist die bessere Form: im Speicher aktualisieren, antworten und dann asynchron persistieren mit Replay‑Mechanismus (Outbox oder Write‑Ahead‑Log).
In vielen Ringpuffer‑Pipelines endet das so: in einen In‑Memory‑Buffer publizieren, Zustand aktualisieren, antworten, dann ein separater Consumer batcht Writes in PostgreSQL.
Ein realistisches Beispiel: Echtzeit‑Updates mit vorhersehbarer Latenz
Stellen Sie sich eine Live‑Kollaborations‑App (oder ein kleines Multiplayer‑Spiel) vor, das Updates alle 16 ms pusht (ca. 60 Hz). Das Ziel ist nicht „schnell im Durchschnitt“. Es ist „meist unter 16 ms“, selbst wenn die Verbindung eines Nutzers schlecht ist.
Ein einfacher Disruptor‑ähnlicher Ablauf könnte so aussehen: Nutzerinput wird zu einem kleinen Event, das in einen vorallokierten Ringpuffer publiziert wird, dann von einer festen Folge von Handlern in Ordnung verarbeitet wird (validate -> apply -> prepare outbound messages) und schließlich an Clients gesendet wird.
Batching hilft an den Rändern. Zum Beispiel outbound pro Client einmal pro Tick batchen, damit Sie die Netzwerkschicht seltener aufrufen. Aber batchen Sie nicht im Hot‑Path so, dass Sie „nur ein bisschen länger“ auf mehr Events warten. Warten ist, wie Sie den Tick verpassen.
Wenn etwas langsam wird, behandeln Sie es als Containment‑Problem. Wenn ein Handler langsamer wird, isolieren Sie ihn hinter seinem eigenen Buffer und publizieren Sie stattdessen ein leichtgewichtiges Work‑Item, statt die Hauptschleife zu blockieren. Wenn ein Client langsam ist, lassen Sie ihn nicht den Broadcaster blockieren; geben Sie jedem Client eine kleine Send‑Queue und verwerfen oder coalescen Sie alte Updates, sodass der aktuelle Zustand bleibt. Wenn die Buffer‑Tiefe wächst, üben Sie Backpressure am Rand (stoppen Sie zusätzliche Inputs für diesen Tick oder degradieren Sie Features).
Sie wissen, dass es funktioniert, wenn die Zahlen langweilig bleiben: Backlog‑Tiefe schwebt nahe null, verworfene/coalescierte Events sind selten und erklärbar, und p99 bleibt während realistischer Last unter Ihrem Tick‑Budget.
Häufige Fehler, die Latenz‑Spitzen erzeugen
Eine reale App bereitstellen
Bringen Sie die App auf einer eigenen Domain unter für realistisches Client-Routing und Caching.
Die meisten Latenzspitzen sind selbstverschuldet. Der Code kann schnell sein, aber das System pausiert, wenn es auf andere Threads, das OS oder alles außerhalb des CPU‑Caches wartet.
Einige wiederkehrende Fehler:
- Überall Shared‑Locks verwenden, weil es sich einfach anfühlt. Ein contended Lock kann viele Requests aufhalten.
- Langsame I/O in den Hot‑Path mischen, wie synchrones Logging, Datenbank‑Writes oder Remote‑Calls.
- Unbegrenzte Warteschlangen behalten. Sie verbergen Überlast, bis Sie Sekundenlangen Rückstau haben.
- Auf Durchschnitte schauen statt auf p95 und p99.
- Zu früh überoptimieren. Threads zu pinnen hilft nicht, wenn Verzögerungen von GC, Contention oder Socket‑Warten kommen.
Ein schneller Weg, Spitzen zu reduzieren, ist Wartezeiten sichtbar und begrenzt zu machen. Legen Sie langsame Arbeit auf einen separaten Pfad, begrenzen Sie Queues und entscheiden Sie, was passiert, wenn Sie voll sind (verwerfen, Last abwerfen oder degradieren).
Schnelle Checkliste für vorhersehbare Latenz
Behandeln Sie vorhersehbare Latenz wie ein Produktmerkmal, nicht als Zufall. Bevor Sie Code tunen, stellen Sie sicher, dass das System klare Ziele und Schutzmechanismen hat.
- Setzen Sie ein explizites p99‑Ziel (und p99.9, wenn nötig) und schreiben Sie ein Latenzbudget pro Stufe.
- Halten Sie den Hot‑Path frei von blockierender I/O. Muss I/O passieren, verschieben Sie es auf einen Nebenpfad und entscheiden Sie, was passiert, wenn es nachhinkt.
- Verwenden Sie begrenzte Warteschlangen und definieren Sie Überlastverhalten (verwerfen, shed, coalesce oder Backpressure).
- Messen Sie kontinuierlich: Backlog‑Tiefe, pro‑Stufe‑Zeit und Tail‑Latenz.
- Minimieren Sie Allokation in der Hot‑Loop und machen Sie sie leicht im Profil ersichtlich.
Ein einfacher Test: simulieren Sie einen Burst (10× normale Last für 30 Sekunden). Wenn p99 explodiert, fragen Sie, wo das Warten passiert: wachsende Queues, ein langsamer Consumer, eine GC‑Pause oder eine geteilte Ressource.
Nächste Schritte: Wie Sie das in Ihrer App anwenden
Behandeln Sie das Disruptor‑Pattern als Workflow, nicht nur als Bibliothekswahl. Beweisen Sie vorhersehbare Latenz mit einem dünnen Slice, bevor Sie Features hinzufügen.
Wählen Sie eine Nutzeraktion, die sich sofort anfühlen muss (z. B. „neuer Preis kommt an, UI aktualisiert sich“). Schreiben Sie das End‑to‑End‑Budget und messen Sie von Tag eins p50, p95 und p99.
Eine Abfolge, die oft funktioniert:
- Bauen Sie eine dünne Pipeline mit einem Input, einem Kernloop und einem Output. Validieren Sie p99 früh unter Last.
- Machen Sie Verantwortlichkeiten explizit (wer besitzt Zustand, wer publiziert, wer konsumiert) und halten Sie geteilten Zustand klein.
- Fügen Sie Nebenläufigkeit und Buffering schrittweise hinzu und machen Sie Änderungen rückgängig machbar.
- Deployen Sie nahe bei Nutzern, wenn das Budget eng ist, und messen Sie dann erneut unter realistischer Last (gleiche Payload‑Größen, gleiche Burst‑Muster).
Wenn Sie auf Koder.ai (koder.ai) prototypen, hilft es, den Event‑Flow zuerst im Planning Mode zu skizzieren, damit Queues, Locks und Service‑Grenzen nicht versehentlich auftauchen. Snapshots und Rollback erleichtern wiederholte Latenzexperimente und das Zurücknehmen von Änderungen, die Durchsatz verbessern, aber p99 verschlechtern.
Bleiben Sie bei den Messungen ehrlich. Verwenden Sie ein festes Testskript, wärmen Sie das System auf und protokollieren Sie sowohl Durchsatz als auch Latenz. Wenn p99 mit Last steigt, fangen Sie nicht sofort mit „Code‑Optimierung“ an. Suchen Sie nach Pausen durch GC, laute Nachbarn, Logging‑Bursts, Thread‑Scheduling oder versteckte blockierende Aufrufe.