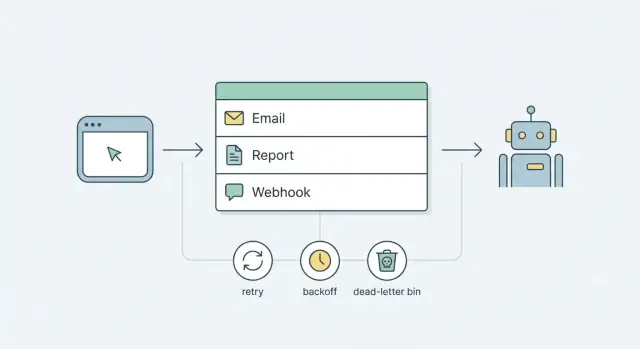
Warum du Hintergrund-Jobs brauchst (und warum es schnell unordentlich wird)
Arbeit, die länger als eine oder zwei Sekunden dauern kann, sollte nicht in einer Benutzeranfrage laufen. E-Mails versenden, Berichte erstellen und Webhooks liefern hängen alle von Netzwerken, Drittanbietern oder langsamen Abfragen ab. Manchmal pausieren sie, schlagen fehl oder dauern länger als erwartet.
Wenn du diese Arbeit im laufenden Request machst, merken Benutzer das sofort. Seiten hängen, "Speichern"-Buttons drehen sich und Anfragen laufen in Timeouts. Retries können auch am falschen Ort passieren: Ein Benutzer aktualisiert die Seite, dein Load Balancer wiederholt, oder dein Frontend sendet erneut — und am Ende hast du doppelte E-Mails, doppelte Webhook-Aufrufe oder zwei konkurrierende Reportläufe.
Hintergrund-Jobs lösen das, indem sie Anfragen klein und vorhersehbar halten: Akzeptiere die Aktion, lege einen Job zum späteren Ausführen an und antworte schnell. Der Job läuft außerhalb des Requests mit Regeln, die du kontrollierst.
Der schwierige Teil ist Zuverlässigkeit. Sobald Arbeit aus dem Request-Pfad verschoben ist, musst du trotzdem Fragen beantworten wie:
- Was, wenn der E-Mail-Provider drei Minuten ausfällt?
- Was, wenn ein Webhook-Endpunkt 500 zurückgibt oder ein Timeout hat?
- Was, wenn der Job zweimal läuft?
- Wie bemerkst du feststeckende Jobs, bevor Nutzer sich beschweren?
Viele Teams reagieren mit „schwerer Infrastruktur": Message-Broker, separate Worker-Fleets, Dashboards, Alerting und Playbooks. Diese Tools sind nützlich, wenn du sie wirklich brauchst, aber sie fügen auch neue bewegliche Teile und Fehlerfälle hinzu.
Ein besseres Einstiegsziel ist einfacher: zuverlässige Jobs mit Bausteinen, die du bereits hast. Für die meisten Produkte bedeutet das eine datenbankgestützte Queue plus einen kleinen Worker-Prozess. Füge eine klare Retry- und Backoff-Strategie und ein Dead-Letter-Pattern für Jobs hinzu, die wiederholt fehlschlagen. So erhältst du vorhersehbares Verhalten, ohne gleich auf eine komplexe Plattform setzen zu müssen.
Selbst wenn du schnell mit einem chatgesteuerten Tool wie Koder.ai entwickelst, bleibt diese Trennung wichtig. Nutzer sollten jetzt eine schnelle Antwort bekommen, und dein System sollte langsame, fehleranfällige Arbeit sicher im Hintergrund erledigen.
Was eine Queue einfach gesagt ist
Eine Queue ist eine Warteschlange für Arbeit. Anstatt langsame oder unzuverlässige Aufgaben während einer Benutzeranfrage auszuführen (E-Mail senden, Bericht erstellen, Webhook aufrufen), legst du einen kleinen Eintrag in eine Queue und antwortest schnell. Später holt ein separater Prozess diesen Eintrag und führt die Arbeit aus.
Ein paar Begriffe, die du oft siehst:
- Job: eine Arbeitseinheit, z. B. „Willkommens-E-Mail an Benutzer 123 senden".
- Worker: der Code, der Jobs zieht und ausführt.
- Attempt: ein Versuch, einen Job auszuführen.
- Schedule: wann der Job laufen soll (jetzt oder später).
- Queue: wo Jobs warten, bis ein Worker sie nimmt.
Der einfachste Ablauf sieht so aus:
-
Enqueue: deine App speichert einen Job-Datensatz (Typ, Payload, Laufzeit).
-
Claim: ein Worker findet den nächsten verfügbaren Job und "sperrt" ihn, sodass nur ein Worker ihn ausführt.
-
Run: der Worker führt die Aufgabe aus (senden, erzeugen, zustellen).
-
Finish: markiere ihn als erledigt oder vermerke einen Fehler und setze die nächste Laufzeit.
Wenn dein Job-Volumen moderat ist und du schon eine Datenbank hast, reicht oft eine datenbankgestützte Queue. Sie ist leicht zu verstehen, einfach zu debuggen und deckt gängige Bedürfnisse wie E-Mail-Job-Verarbeitung und zuverlässige Webhook-Zustellung ab.
Streaming-Plattformen machen erst Sinn, wenn du sehr hohen Durchsatz, viele unabhängige Consumer oder die Fähigkeit zum Replay riesiger Ereignis-Historien über viele Systeme brauchst. Wenn du Dutzende Services mit Millionen Events pro Stunde betreibst, helfen Tools wie Kafka. Bis dahin deckt eine Tabelle plus Worker-Loop viele reale Fälle ab.
Die minimalen Daten, die du für jeden Job verfolgen solltest
Eine datenbankbasierte Queue bleibt nur dann handhabbar, wenn jeder Job-Datensatz drei Fragen schnell beantwortet: was zu tun ist, wann erneut versucht wird und was beim letzten Mal passiert ist. Wenn das stimmt, wird der Betrieb langweilig (das ist gut).
Was du in der Payload speichern solltest (und was nicht)
Speichere die kleinsten Eingaben, die nötig sind, um die Arbeit zu erledigen, nicht das vollständig gerenderte Ergebnis. Gute Payloads sind IDs und ein paar Parameter, z. B. { "user_id": 42, "template": "welcome" }.
Vermeide das Speichern großer Blobs (vollständige HTML-E-Mails, große Report-Daten, riesige Webhook-Bodies). Das lässt die Datenbank schnell wachsen und erschwert das Debugging. Wenn der Job ein großes Dokument braucht, speichere stattdessen eine Referenz: report_id, export_id oder einen Dateischlüssel. Der Worker kann die vollständigen Daten beim Lauf holen.
Die Felder, die sich auszahlen
Mindestens solltest du Platz für folgende Felder vorsehen:
- job_type + payload:
job_type wählt den Handler (send_email, generate_report, deliver_webhook). payload enthält kleine Eingaben wie IDs und Optionen.
- status: halte ihn explizit (z. B.
queued, running, succeeded, failed, dead).
- attempt tracking:
attempt_count und max_attempts, damit du aufhörst zu wiederholen, wenn es klar nicht funktioniert.
- Zeitfelder:
created_at und next_run_at (wann der Job fällig ist). started_at und finished_at kannst du hinzufügen für bessere Sichtbarkeit langsamer Jobs.
- Idempotency + last error: ein
idempotency_key, um doppelte Effekte zu verhindern, und last_error, damit du ohne lange Logsuche siehst, warum es schiefging.
Idempotenz klingt fancy, die Idee ist aber einfach: Wenn derselbe Job zweimal läuft, sollte der zweite Durchlauf nichts Gefährliches tun. Ein Webhook-Delivery-Job kann z. B. einen Idempotency-Key wie webhook:order:123:event:paid nutzen, sodass du dasselbe Event nicht noch einmal zustellst, falls ein Retry mit Timeout überlappt.
Sammle außerdem ein paar Basiszahlen. Du brauchst kein großes Dashboard zum Start, nur Abfragen, die dir sagen: wie viele Jobs sind queued, wie viele fehlschlagen und wie alt ist der älteste wartende Job.
Schritt für Schritt: eine einfache datenbankgestützte Queue, die du heute bauen kannst
Wenn du bereits eine Datenbank hast, kannst du eine Hintergrund-Queue starten, ohne neue Infrastruktur hinzuzufügen. Jobs sind Zeilen, und ein Worker ist ein Prozess, der fällige Zeilen nimmt und die Arbeit erledigt.
1) Erstelle eine jobs-Tabelle
Halte die Tabelle klein und langweilig. Du brauchst genügend Felder, um später Jobs zu betreiben, zu retryen und zu debuggen.
CREATE TABLE jobs (
id bigserial PRIMARY KEY,
job_type text NOT NULL,
payload jsonb NOT NULL,
status text NOT NULL DEFAULT 'queued',
attempts int NOT NULL DEFAULT 0,
next_run_at timestamptz NOT NULL DEFAULT now(),
locked_at timestamptz,
locked_by text,
last_error text,
created_at timestamptz NOT NULL DEFAULT now(),
updated_at timestamptz NOT NULL DEFAULT now()
);
CREATE INDEX jobs_due_idx ON jobs (status, next_run_at);
Wenn du auf Postgres (häufig bei Go-Backends) aufbaust, ist jsonb praktisch, um Job-Daten wie { "user_id":123,"template":"welcome" } zu speichern.
2) Sicheres Enqueueing (besonders bei Benutzeraktionen)
Wenn eine Benutzeraktion einen Job auslösen soll (E-Mail senden, Webhook feuern), schreibe die Job-Zeile möglichst in derselben Datenbank-Transaktion wie die Hauptänderung. Das verhindert "Benutzer erstellt, aber Job fehlt", falls nach dem Hauptschreiben ein Absturz passiert.
Beispiel: Wenn sich ein Benutzer registriert, füge die User-Zeile und einen send_welcome_email-Job in einer Transaktion ein.
3) Führe einen skalierbaren Worker-Loop aus
Ein Worker wiederholt denselben Zyklus: finde einen fälligen Job, claim ihn atomar, verarbeite ihn und markiere ihn als erledigt oder plane einen Retry.
In der Praxis bedeutet das:
- Wähle einen Job, bei dem
status='queued' und next_run_at <= now().
- Claim ihn atomar (in Postgres ist
SELECT ... FOR UPDATE SKIP LOCKED ein gängiger Ansatz).
- Setze
status='running', locked_at=now(), locked_by='worker-1'.
- Verarbeite den Job.
- Markiere ihn als fertig (
done/succeeded) oder speichere last_error und plane den nächsten Versuch.
Mehrere Worker können gleichzeitig laufen. Der Claim-Schritt verhindert das doppelte Abholen.
4) Shutdown behandeln, ohne Jobs zu zerstören
Beim Herunterfahren: nimm keine neuen Jobs mehr an, beende den aktuellen und beende dann den Prozess. Wenn ein Prozess mitten in einem Job abstirbt, verwende eine einfache Regel: behandle Jobs, die zu lange im Zustand running sind, als wieder anzuzeigen und lasse ein periodisches "Reaper"-Task sie neu einreihen.
Wenn du in Koder.ai baust, ist dieses datenbankbasierte Pattern ein solider Default für E-Mails, Reports und Webhooks, bevor du spezialisierte Queue-Services einführst.
Retries und Backoff, die keinen Chaos erzeugen
Über einen Worker hinaus wachsen
Skaliere von einer einfachen Datenbank-Warteschlange zu mehreren Workern, wenn dein Durchsatz wächst.
Retries sind das Mittel, mit dem eine Queue ruhig bleibt, wenn die reale Welt unordentlich ist. Ohne klare Regeln werden Retries zu einer lauten Schleife, die Benutzer zuspammt, APIs bombardiert und echte Fehler verschleiert.
Entscheide zuerst, was du erneut versuchen solltest und was sofort scheitern kann.
Wiederhole temporäre Probleme: Netzwerk-Timeouts, 502/503-Fehler, Rate-Limits oder ein kurzzeitig verlorener DB-Connection.
Breche schnell ab, wenn der Job nicht erfolgreich sein wird: fehlende E-Mail-Adresse, 400-Antwort von einem Webhook weil das Payload ungültig ist, oder ein Report-Request für ein gelöschtes Konto.
Backoff ist die Pause zwischen Versuchen. Lineares Backoff (5s, 10s, 15s) ist einfach, kann aber noch Verkehrswellen erzeugen. Exponentielles Backoff (5s, 10s, 20s, 40s) verteilt die Last besser und ist gewöhnlich sicherer für Webhooks und Drittanbieter. Füge Jitter (eine kleine zufällige Verzögerung) hinzu, damit tausend Jobs nicht exakt zur selben Sekunde erneut versuchen.
Regeln, die sich in Produktion bewähren:
- Wiederhole nur bei klar temporären Fehlern (Timeouts, 429, 5xx).
- Verwende exponentielles Backoff mit Jitter.
- Begrenze Versuche und markiere den Job danach als fehlgeschlagen.
- Setze ein Timeout pro Versuch, damit Worker nicht hängen bleiben.
- Mache jeden Job idempotent, damit Retries keine Duplikate erzeugen.
Die maximale Anzahl an Versuchen limitiert Schaden. Für viele Teams reichen 5 bis 8 Versuche. Danach stoppe und parke den Job zur Überprüfung (Dead-Letter) anstatt ewig zu schleifen.
Timeouts verhindern "Zombie"-Jobs. E-Mails können 10–20 Sekunden pro Versuch erlauben. Webhooks brauchen oft ein kürzeres Limit (5–10 Sekunden), weil der Empfänger down sein kann und du weiterziehen willst. Report-Generierung kann Minuten erlauben, sollte aber trotzdem ein hartes Cutoff haben.
Wenn du das in Koder.ai baust, behandle should_retry, next_run_at und einen Idempotency-Key als erstklassige Felder. Diese kleinen Details halten das System ruhig, wenn etwas schiefläuft.
Dead-Letter-Handling und einfache Betriebsabläufe
Ein Dead-Letter-Status ist der Ort, an den Jobs wandern, wenn weitere Versuche nicht mehr sicher oder nützlich sind. So wird stilles Scheitern zu etwas, das du sehen, durchsuchen und bearbeiten kannst.
Was bei einem Dead-Letter-Job zu speichern ist
Speichere genug, um zu verstehen, was passiert ist und um den Job bei Bedarf nachzuspielen, aber sei vorsichtig mit Geheimnissen.
Behalte:
- Die Job-Inputs (Payload) genau so, wie sie verwendet wurden, plus Job-Typ und Version
- Die letzte Fehlermeldung und einen kurzen Stacktrace (oder einen Fehlercode, falls keine Stacks vorliegen)
- Attempt-Count, erste Laufzeit, letzte Laufzeit und next_run_time (falls geplant)
- Die Worker-Identität (Service-Name, Host) und eine Korrelation-ID für Logs
- Einen Dead-Letter-Grund (Timeout, Validierungsfehler, 4xx vom Vendor etc.)
Wenn die Payload Tokens oder persönliche Daten enthält, redigiere oder verschlüssele sie vor dem Speichern.
Ein einfacher Triage-Workflow
Wenn ein Job in den Dead-Letter geht, triff eine schnelle Entscheidung: erneut versuchen, fixen oder ignorieren.
Retry ist für externe Ausfälle und Timeouts. Fix ist für falsche Daten (fehlende E-Mail, falsche Webhook-URL) oder einen Bug im Code. Ignorieren sollte selten sein, ist aber gültig, wenn der Job nicht mehr relevant ist (z. B. weil der Kunde sein Konto gelöscht hat). Wenn du ignorierst, dokumentiere den Grund, damit der Job nicht einfach verschwindet.
Manuelles Requeue ist am sichersten, wenn es einen neuen Job erstellt und den alten unverändert lässt. Markiere den Dead-Letter-Job mit wer ihn neu eingereiht hat, wann und warum, und enqueue eine frische Kopie mit neuer ID.
Für Alerts achte auf Signale, die echten Schmerz bedeuten: schnell steigende Dead-Letter-Zahlen, derselbe Fehler bei vielen Jobs und alte wartende Jobs, die nicht übernommen werden.
Wenn du Koder.ai nutzt, helfen Snapshots und Rollback, wenn ein fehlerhaftes Release plötzlich Fehler spiket — so kannst du schnell zurückrollen und untersuchen.
Füge schließlich Sicherheitsventile für Vendor-Ausfälle hinzu. Rate-limit pro Provider und verwende einen Circuit-Breaker: Wenn ein Webhook-Endpunkt stark fehlschlägt, pause neue Versuche für ein kurzes Fenster, damit du deren Server (und deine) nicht flutest.
Muster für E-Mails, Reports und Webhooks
Warteschlange und Worker deployen
Deploye deine App und Worker zusammen und iteriere sicher, wenn die Last wächst.
Eine Queue funktioniert am besten, wenn jeder Job-Typ klare Regeln hat: was Erfolg ist, was wiederholt werden sollte und was niemals zweimal passieren darf.
E-Mails. Die meisten E-Mail-Fehler sind temporär: Provider-Timeouts, Rate-Limits oder kurze Ausfälle. Behandle diese als retrybar mit Backoff. Das größere Risiko sind doppelte Sends — mache E-Mail-Jobs idempotent. Speichere einen stabilen Dedupe-Key wie user_id + template + event_id und weigere dich zu senden, wenn dieser Key bereits als gesendet markiert ist.
Es lohnt sich auch, Template-Name und -Version (oder einen Hash des gerenderten Betreffs/Körpers) zu speichern. Bei einem erneuten Lauf kannst du wählen, ob du denselben Inhalt erneut sendest oder aus dem aktuellen Template neu renderst. Wenn der Provider eine Message-ID zurückgibt, speichere sie, damit Support nachverfolgen kann, was geschehen ist.
Reports. Reports versagen anders: Sie können Minuten laufen, an Pagination-Grenzen stoßen oder wegen zu großer Verarbeitung im Speicher scheitern. Teile die Arbeit in kleinere Stücke. Ein gängiges Muster ist: ein "report request"-Job erstellt viele "page"- oder "chunk"-Jobs, die jeweils einen Datenabschnitt verarbeiten.
Speichere Ergebnisse zur späteren Abholung, statt den Benutzer warten zu lassen. Das kann eine Tabelle sein, keyed nach report_run_id, oder eine Datei-Referenz plus Metadaten (Status, Row-Count, created_at). Füge Fortschrittsfelder hinzu, damit die UI "processing" vs. "ready" anzeigen kann.
Webhooks. Webhooks drehen sich um Zustellzuverlässigkeit, nicht um Geschwindigkeit. Signiere jede Anfrage (z. B. HMAC mit einem gemeinsamen Secret) und füge einen Zeitstempel hinzu, um Replay zu verhindern. Retry nur, wenn der Empfänger später Erfolg haben könnte.
Eine einfache Regel:
- Wiederhole bei Timeouts und 5xx-Antworten, mit Backoff und maximaler Attempt-Zahl.
- Behandle die meisten 4xx-Antworten als permanente Fehler und höre auf zu retryen.
- Protokolliere den letzten Statuscode und einen kurzen Response-Body zum Debuggen.
- Verwende einen Idempotency-Key, damit Empfänger Duplikate sicher ignorieren können.
- Begrenze die Payload-Größe und logge, was du tatsächlich gesendet hast.
Reihenfolge und Priorität. Die meisten Jobs brauchen keine strikte globale Reihenfolge. Wenn Reihenfolge wichtig ist, dann meist pro Key (pro Nutzer, pro Rechnung, pro Webhook-Endpunkt). Füge einen group_key hinzu und lasse nur einen in-flight Job pro Key laufen.
Für Priorität trenne dringende Arbeit von langsamer Arbeit. Ein großer Report-Rückstau darf z. B. Passwort-Reset-E-Mails nicht verzögern.
Beispiel: Nach einem Kauf enqueuest du (1) eine Bestätigungs-E-Mail, (2) einen Partner-WebHook und (3) einen Report-Update-Job. Die E-Mail retryt schnell, der Webhook versucht länger mit Backoff, und der Report läuft später mit niedriger Priorität.
Ein realistisches Beispiel: Signup-Flow plus Webhook plus nächtlicher Report
Ein Benutzer registriert sich. Drei Dinge sollen passieren, aber keines davon darf die Signup-Seite verlangsamen: Willkommens-E-Mail senden, dein CRM per Webhook informieren und den Benutzer in den nächtlichen Aktivitätsreport aufnehmen.
Was beim Signup in die Queue kommt
Direkt nachdem du die User-Zeile erstellt hast, schreibst du drei Job-Zeilen in deine Datenbank-Queue. Jede Zeile hat einen Typ, eine Payload (z. B. user_id), einen Status, einen Attempt-Count und einen next_run_at-Zeitstempel.
Ein typischer Lebenszyklus sieht so aus:
queued: erstellt und wartet auf einen Workerrunning: ein Worker hat ihn übernommensucceeded: erledigt, keine weitere Arbeitfailed: fehlgeschlagen, für später geplant oder aus den Versuchen rausdead: zu oft fehlgeschlagen und braucht menschliche Sicht
Der Willkommens-Mail-Job enthält einen Idempotency-Key wie welcome_email:user:123. Bevor gesendet wird, prüft der Worker eine Tabelle abgeschlossener Idempotency-Keys (oder erzwingt einen Unique-Constraint). Läuft der Job zweimal wegen eines Absturzes, sieht der zweite Durchlauf den Key und überspringt das Senden. Keine doppelten Willkommens-Mails.
Ein Fehlerfall und wie er sich erholt
Nun ist der CRM-WebHook-Endpunkt down. Der Webhook-Job schlägt mit einem Timeout fehl. Dein Worker plant einen Retry mit Backoff (z. B. 1 Minute, 5 Minuten, 30 Minuten, 2 Stunden) plus ein bisschen Jitter, damit nicht viele Jobs exakt gleichzeitig erneut versuchen.
Nach den maximalen Versuchen wird der Job dead. Der Benutzer ist trotzdem registriert, hat die Willkommens-Mail bekommen, und der nächtliche Report-Job kann normal laufen. Nur die CRM-Benachrichtigung steckt fest und ist sichtbar.
Am nächsten Morgen kann Support (oder die zuständige Person) das ohne lange Logsuche bearbeiten:
- Filtere Dead-Jobs nach Typ (z. B.
webhook.crm).
- Lies die letzte Fehlermeldung und prüfe, ob die Payload korrekt aussieht.
- Verifiziere, dass das CRM wieder erreichbar ist.
- Requeue den Job (dead -> queued, Attempts zurücksetzen) oder deaktiviere das Ziel vorübergehend.
Wenn du Apps auf einer Plattform wie Koder.ai baust, gilt dasselbe Muster: halte den Nutzerfluss schnell, schiebe Side-Effects in Jobs und mache Fehler leicht sichtbar und neu startbar.
Häufige Fehler, die Queues unzuverlässig machen
Die Trennung Request ⇢ Job ausliefern
Generiere eine React- und Go-App, die Anfragen schnell hält und langsame Arbeiten an Worker auslagert.
Der schnellste Weg, eine Queue zu ruinieren, ist sie als optional zu behandeln. Teams beginnen oft mit "schick die E-Mail diesmal direkt im Request", weil es einfacher wirkt. Das breitet sich aus: Passwort-Resets, Belege, Webhooks, Report-Exporte. Bald fühlt sich die App langsam an, Timeouts steigen und jeder Drittanbieter-Zwicker wird zu deinem Ausfall.
Ein weiterer häufiger Fehler ist das Überspringen von Idempotenz. Läuft ein Job zweimal, darf er nicht zwei Ergebnisse erzeugen. Ohne Idempotenz führen Retries zu doppelten E-Mails, wiederholten Webhook-Events oder schlimmer.
Ein dritter Punkt ist Sichtbarkeit. Wenn du Fehler nur durch Support-Tickets erfährst, schadet die Queue bereits den Nutzern. Schon eine grundlegende interne Ansicht mit Job-Zahlen nach Status und durchsuchbarem last_error spart Zeit.
Zuverlässigkeits-Killer, auf die du achten solltest
Einige Probleme tauchen früh auf, selbst in einfachen Queues:
- Sofortiges Wiederholen nach Fehlern. Wenn ein Provider down ist, erzeugen schnelle Retries deinen eigenen Traffic-Peak.
- Vermischung von langsamen und dringenden Jobs. Ein 10-Minuten-Report kann eine "E-Mail bestätigen"-Nachricht blockieren.
- Fehler immer als temporär behandeln. Jobs, die nie erfolgreich werden, zyklisieren und verbergen echte Probleme.
- Keine Verantwortung für Payload-Versionen. Wenn du die Form der Jobs änderst, können alte Jobs plötzlich fehlschlagen.
- Ignorieren von Rate-Limits. Queues können Anbieter überfluten, die dich drosseln.
Backoff verhindert selbstgemachte Ausfälle. Schon ein einfaches Schema wie 1 Minute, 5 Minuten, 30 Minuten, 2 Stunden macht Fehler sicherer. Setze außerdem ein Maximum an Versuchen, damit ein defekter Job stoppt und sichtbar wird.
Wenn du auf einer Plattform wie Koder.ai baust, ist es hilfreich, diese Basics zusammen mit dem Feature auszuliefern und nicht erst Wochen später als Aufräumprojekt.
Kurze Checkliste und nächste Schritte
Bevor du mehr Tools hinzufügst, stell sicher, dass die Basics stimmen. Eine datenbankgestützte Queue funktioniert gut, wenn jeder Job leicht zu claimen, leicht zu retryen und leicht zu inspizieren ist.
Eine schnelle Zuverlässigkeits-Checkliste:
- Jeder Job hat: id, type, payload, status, attempts, max_attempts, run_at/next_run_at und last_error.
- Worker claimen Jobs sicher (jeweils ein Worker pro Job) und erholen sich nach Abstürzen (Lock-Timeout + Reaper).
- Jeder Job hat ein klares Timeout, damit hängende Arbeit retrybar wird statt ewig zu blockieren.
- Retries sind begrenzt und die Verzögerung wächst (Backoff), um Thundering-Herds zu vermeiden.
- Es gibt einen Dead-Letter-Status (oder eine Tabelle) und einen klaren Weg, Jobs neu zu starten oder zu verwerfen.
Als nächstes wähle deine ersten drei Job-Typen und schreibe ihre Regeln auf. Zum Beispiel: Passwort-Reset-E-Mail (schnelle Retries, kurze Maximalzahl), nächtlicher Report (wenige Retries, längere Timeouts), Webhook-Zustellung (mehr Retries, längeres Backoff, bei permanenten 4xx stoppen).
Wenn du unsicher bist, wann eine datenbankbasierte Queue nicht mehr reicht, achte auf Signale wie Row-Level-Contention durch viele Worker, strikte Ordering-Anforderungen über viele Job-Typen, großes Fan-Out (ein Ereignis erzeugt tausende Jobs) oder Cross-Service-Consumption, bei dem verschiedene Teams unterschiedliche Worker betreiben.
Wenn du schnell prototypen willst, kannst du den Ablauf in Koder.ai (koder.ai) im Planungsmodus skizzieren, die Jobs-Tabelle und den Worker-Loop generieren und mit Snapshots und Rollback iterieren, bevor du ausrollst.