21. Sept. 2025·8 Min
Eric Brewers CAP‑Denken: Warum verteilte Systeme Kompromisse eingehen
Erlernen Sie Eric Brewers CAP‑Theorem als praktisches Denkmodell: wie Konsistenz, Verfügbarkeit und Partitionen Entscheidungen in verteilten Systemen prägen.
Warum CAP zum bevorzugten Denkmodell wurde
Wenn Sie dieselben Daten auf mehr als einer Maschine speichern, gewinnen Sie Geschwindigkeit und Fehlertoleranz — aber Sie bekommen auch ein neues Problem: Uneinigkeit. Zwei Server können unterschiedliche Updates erhalten, Nachrichten können verspätet eintreffen oder ganz verloren gehen, und Nutzer sehen je nach Replik unterschiedliche Antworten. CAP wurde beliebt, weil es Ingenieur*innen eine klare Sprache für diese unordentliche Realität gibt, ohne Nebelkerzen.
Eric Brewer, Informatiker und Mitgründer von Inktomi, formulierte die Kernidee im Jahr 2000 als praktische Aussage über replizierte Systeme unter Fehlern. Sie verbreitete sich schnell, weil sie dem entsprach, was Teams bereits in Produktion erlebten: verteilte Systeme fallen nicht nur dadurch aus, dass sie komplett abschalten; sie fallen dadurch aus, dass sie sich teilen.
CAP ist eine Fehler‑Linse, kein Feature‑Checklist
CAP ist am nützlichsten, wenn etwas schiefläuft — besonders wenn das Netzwerk sich merkwürdig verhält. An einem gesunden Tag können viele Systeme sowohl konsistent als auch verfügbar genug erscheinen. Der wahre Test ist, wenn Maschinen nicht mehr zuverlässig kommunizieren und Sie entscheiden müssen, wie Sie mit Reads und Writes umgehen, während das System geteilt ist.
Dieses Framing ist der Grund, warum CAP zu einem bevorzugten Denkmodell wurde: Es diskutiert nicht darüber, was „best practices“ sind; es zwingt zu einer konkreten Frage—was opfern wir während einer Partition?
Was Sie am Ende entscheiden können sollten
Am Ende dieses Artikels sollten Sie in der Lage sein:
- zu erkennen, wann Sie es mit einem echten CAP‑Szenario zu tun haben (Replikation + mögliche Kommunikationsunterbrechungen).
- bewusst zu wählen, ob Ihr System Konsistenz (alle sehen dieselbe Wahrheit) oder Verfügbarkeit (das System antwortet weiter) priorisieren soll, wenn Repliken nicht übereinstimmen können.
- diese Wahl an Produkt‑Auswirkungen zu koppeln: was Nutzer erleben, welche Fehlermeldungen Sie anzeigen und welche Nacharbeiten nötig sind, nachdem die Partition verheilt ist.
CAP überdauert, weil es vagen „verteilte Systeme sind schwer“‑Diskussionen eine verteidigbare Entscheidung entzieht.
Die Ausgangslage: Replikation und das Problem der Uneinigkeit
Ein verteiltes System ist schlicht gesagt viele Computer, die versuchen wie ein einziger zu wirken. Sie haben mehrere Server in verschiedenen Racks, Regionen oder Cloud‑Zonen, aber für den Nutzer ist es „die App“ oder „die Datenbank“.
Warum wir Daten replizieren
Damit dieses gemeinsame System in realer Größe funktioniert, replizieren wir normalerweise: wir halten mehrere Kopien derselben Daten auf verschiedenen Maschinen.
Replikation ist aus drei praktischen Gründen beliebt:
- Skalierung: mehr Maschinen können mehr Traffic verarbeiten.
- Performance: Nutzer können von einer nahegelegenen Kopie bedient werden, was Latenz reduziert.
- Zuverlässigkeit: wenn eine Maschine ausfällt, kann eine andere Kopie den Dienst aufrechterhalten.
Bisher klingt Replikation nach einem klaren Gewinn. Der Haken ist, dass Replikation eine neue Aufgabe schafft: alle Kopien in Übereinstimmung zu halten.
Die Kernspannung: Kopien können uneinig sein
Wenn jede Replik sich jederzeit sofort mit jeder anderen Replik verständigen könnte, könnten sie Updates koordinieren und synchron bleiben. Aber reale Netzwerke sind nicht perfekt. Nachrichten können verzögert, verworfen oder umgeleitet werden.
Wenn die Kommunikation gesund ist, können Repliken meist Updates austauschen und auf denselben Zustand konvergieren. Wenn die Kommunikation jedoch unterbrochen ist (auch nur temporär), können Sie mit zwei gültig aussehenden Versionen der „Wahrheit“ dastehen.
Beispiel: ein Nutzer ändert seine Lieferadresse. Replik A erhält das Update, Replik B nicht. Nun muss das System eine scheinbar einfache Frage beantworten: Was ist die aktuelle Adresse?
Normalbetrieb vs. Fehlerbetrieb
Das ist der Unterschied zwischen:
- Normalbetrieb: Repliken können koordinieren; Uneinigkeit ist meist ein Timing‑Problem.
- Fehlerbetrieb: einige Repliken können nicht kommunizieren; Uneinigkeit wird unvermeidbar.
CAP‑Denken beginnt genau hier: sobald Replikation existiert, ist Uneinigkeit bei Kommunikationsausfall kein Randfall mehr — es ist das zentrale Designproblem.
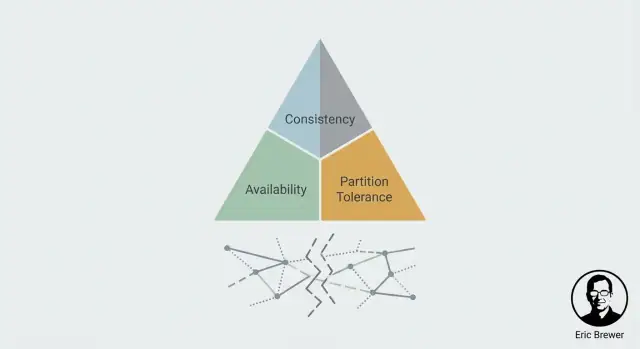
CAP in einfachen Worten: C, A und P
CAP ist ein Denkmodell dafür, was Nutzer tatsächlich spüren, wenn ein System über mehrere Maschinen (oft an mehreren Standorten) verteilt ist. Es beschreibt nicht „gute“ oder „schlechte“ Systeme — nur die Spannung, die Sie managen müssen.
Konsistenz (C): sehe ich den letzten Schreibvorgang?
Konsistenz dreht sich um Übereinstimmung. Wenn Sie etwas aktualisieren, wird der nächste Lesezugriff (von überall) diese Änderung widerspiegeln?
Aus Sicht eines Nutzers ist es der Unterschied zwischen „Ich habe es gerade geändert, und alle sehen denselben neuen Wert“ und „Manche sehen noch eine Weile den alten Wert“.
Verfügbarkeit (A): bekomme ich überhaupt eine Antwort?
Verfügbarkeit bedeutet, dass das System auf Anfragen — Lese‑ und Schreibzugriffe — mit einem Erfolgsergebnis antwortet. Nicht „so schnell wie möglich“, aber „es verweigert nicht die Bedienung“.
Bei Problemen (ein Server ist down, ein Netzwerkstörer) akzeptiert ein verfügbares System weiterhin Anfragen, selbst wenn es mit leicht veralteten Daten antworten muss.
Partitionstoleranz (P): was passiert, wenn Knoten nicht sprechen können?
Eine Partition ist, wenn das Netzwerk sich spaltet: Maschinen laufen zwar, aber Nachrichten zwischen einigen von ihnen kommen nicht durch (oder kommen zu spät, um nützlich zu sein). In verteilten Systemen können Sie dies nicht als unmöglich behandeln — Sie müssen Verhalten definieren, wenn es passiert.
Eine einfache Geschichte: zwei Geschäfte, ein Lagerbestand
Stellen Sie sich zwei Einzelhandelsgeschäfte vor, die dasselbe Produkt verkaufen und einen gemeinsamen „Lagerbestand = 1“ teilen. Ein Kunde kauft den letzten Artikel in Geschäft A, also schreibt Geschäft A inventory = 0. Zur gleichen Zeit verhindert eine Netzwerkpartition, dass Geschäft B davon erfährt.
Bleibt Geschäft B verfügbar, kann es einen Artikel verkaufen, den es nicht mehr hat (die Bestellung akzeptieren, während es partitioniert ist). Erzwingt Geschäft B Konsistenz, verweigert es den Verkauf, bis es die neueste Bestandsinformation bestätigen kann (während der Spaltung Dienst verweigern).
Was Partitionen wirklich sind (und warum Sie sie nicht ignorieren können)
Eine „Partition“ ist nicht nur „das Internet ist weg“. Es ist jede Situation, in der Teile Ihres Systems nicht zuverlässig miteinander reden können — selbst wenn jeder Teil weiterhin läuft.
In einem replizierten System tauschen Knoten ständig Nachrichten aus: Schreibvorgänge, Bestätigungen, Heartbeats, Leader‑Elections, Leseanfragen. Eine Partition passiert, wenn diese Nachrichten nicht mehr ankommen (oder zu spät ankommen), wodurch Uneinigkeit über die Realität entsteht: „Hat der Schreibvorgang stattgefunden?“ „Wer ist der Leader?“ „Ist Knoten B noch da?“
Partitionen sind Kommunikationsfehler
Kommunikation kann auf viele, unordentliche Arten scheitern:
- Paketverlust, der Retries und Timeouts auslöst
- Routing‑Probleme, bei denen Traffic lange Umwege nimmt oder im Leeren landet
- Überlastete Leitungen (oder saturierte NICs), die starke Verzögerungen verursachen
- Fehlkonfigurierte Firewalls / Security‑Gruppen, die nur bestimmte Ports oder Richtungen blockieren
- DNS‑ oder Service‑Discovery‑Störungen, die verhindern, dass Knoten sich finden
Wichtig ist: Partitionen sind oft Degradierung, nicht ein sauberer An/Aus‑Ausfall. Aus Sicht der Anwendung kann „langsam genug“ nicht von „down“ unterschieden werden.
Warum Partitionen in großem Maßstab unvermeidlich sind
Je mehr Maschinen, Netzwerke, Regionen und bewegliche Teile Sie hinzufügen, desto mehr Gelegenheiten entstehen, dass Kommunikation zeitweilig bricht. Selbst wenn einzelne Komponenten zuverlässig sind, erlebt das Gesamtsystem Fehler, weil es mehr Abhängigkeiten und mehr Koordination zwischen Knoten hat.
Sie müssen keine exakte Ausfallrate annehmen, um die Realität zu akzeptieren: Läuft Ihr System lange genug und spannt es genug Infrastruktur, werden Partitionen passieren.
Was „Partitionen tolerieren“ in der Praxis bedeutet
Partitionstoleranz heißt, Ihr System ist so entworfen, dass es während einer Spaltung weiterarbeitet — selbst wenn Knoten nicht übereinstimmen oder nicht bestätigen können, was die andere Seite gesehen hat. Das erzwingt eine Wahl: entweder Anfragen weiter bedienen (mit Inkonsistenzen) oder einige Anfragen stoppen/ablehnen (Konsistenz bewahren).
Der entscheidende Moment: Konsistenz oder Verfügbarkeit während einer Spaltung wählen
Sobald Sie Replikation haben, ist eine Partition einfach ein Kommunikationsausfall: zwei Teile Ihres Systems können für eine Weile nicht zuverlässig miteinander reden. Repliken laufen weiter, Nutzer klicken weiter, und Ihr Dienst erhält weiterhin Anfragen — aber die Repliken können sich nicht auf die neueste Wahrheit einigen.
Das ist die CAP‑Spannung in einem Satz: während einer Partition müssen Sie entscheiden, ob Sie Konsistenz (C) oder Verfügbarkeit (A) priorisieren. Beides gleichzeitig bekommen Sie nicht.
Wenn Sie Konsistenz wählen (C)
Sie sagen damit: „Ich bin lieber korrekt als reaktionsschnell.“ Wenn das System nicht bestätigen kann, dass eine Anfrage alle Repliken synchron hält, muss es fehlschlagen oder warten.
Praktische Auswirkungen: einige Nutzer sehen Fehler, Timeouts oder „bitte erneut versuchen“‑Meldungen — besonders bei Operationen, die Daten verändern. Das ist üblich, wenn Sie lieber eine Zahlung ablehnen, als zweimal abzubuchen, oder einen Sitzplatz blockieren, statt zu überverkaufen.
Wenn Sie Verfügbarkeit wählen (A)
Sie sagen damit: „Ich antworte lieber, als zu blockieren.“ Jede Seite der Partition nimmt weiterhin Anfragen an, auch wenn sie nicht koordinieren kann.
Praktische Auswirkungen: Nutzer erhalten erfolgreiche Antworten, aber die Daten können veraltet sein und parallele Updates können konfligieren. Danach sind Sie auf Rekonsiliation angewiesen (Merge‑Regeln, Last‑Write‑Wins, manuelle Überprüfung usw.).
Die Wahl kann je nach Operation variieren
Das ist nicht immer eine einzige globale Einstellung. Viele Produkte mischen Strategien:
- Reads vs. Writes: Reads verfügbar halten, Writes strenger machen.
- Kritische vs. nicht‑kritische Aktionen: Konsistenz für Geld, Identität und Inventar; Verfügbarkeit für Feeds, Analytics, „Likes“ oder gecachte Profile.
Der Schlüsselmoment ist die Entscheidung — pro Operation — was schlimmer ist: jetzt einen Nutzer blockieren oder später eine widersprüchliche Wahrheit bereinigen.
Häufige Missverständnisse: Mehr als nur „Wähle zwei"
CAP-Abwägungen schnell prototypen
Verwandle deine CAP‑Entscheidungen in einen funktionierenden Go‑ und Postgres‑Prototyp – in einem einzigen Chat.
Der Slogan „Wähle zwei“ ist eingängig, führt aber oft in die Irre, weil Leute denken, CAP sei ein Menü aus drei Features, von denen man zwei behalten darf. CAP beschreibt, was passiert, wenn das Netzwerk nicht mehr mitspielt: während einer Partition muss ein verteiltes System zwischen konsistenten Antworten und vollständiger Verfügbarkeit für jede Anfrage wählen.
Missverständnis 1: „Ich wähle C und A und vermeide Partitionen"
In realen verteilten Systemen sind Partitionen keine Einstellung, die Sie abschalten können. Wenn Ihr System über Maschinen, Racks, Zonen oder Regionen verteilt ist, können Nachrichten verzögert, verworfen, neu geordnet oder merkwürdig geroutet werden. Das ist aus Sicht der Software eine Partition: Knoten können nicht mehr gut genug koordinieren.
Selbst wenn das physische Netzwerk in Ordnung ist, erzeugen Fehler anderswo denselben Effekt — Garbage Collection‑Pauses, laute Nachbarn, DNS‑Hiccups, fehlerhafte Load Balancer. Das Ergebnis ist dasselbe: Teile des Systems können nicht mehr gut genug reden, um zu koordinieren.
Missverständnis 2: „Partitionen sind seltene Randfälle"
Anwendungen erleben „Partition“ nicht als sauberes binäres Ereignis. Sie erleben Latenzspitzen und Timeouts. Wenn eine Anfrage nach 200 ms timeoutet, ist es egal, ob das Paket nach 201 ms ankam oder nie ankam: die App muss entscheiden, wie weiter verfahren wird. Aus Sicht der App ist langsame Kommunikation oft nicht von gebrochener zu unterscheiden.
Missverständnis 3: „Systeme sind entweder CP oder AP"
Viele reale Systeme sind meistens konsistent oder meistens verfügbar, abhängig von Konfiguration und Betriebsbedingungen. Timeouts, Retry‑Politiken, Quorum‑Größen und ‚read‑your‑writes‘‑Optionen können das Verhalten verschieben.
Unter normalen Bedingungen wirkt eine Datenbank stark konsistent; unter Belastung oder Cross‑Region‑Störungen beginnt sie eventuell, Anfragen abzulehnen (Konsistenz priorisieren) oder veraltete Daten zu liefern (Verfügbarkeit priorisieren).
CAP geht weniger darum, Produkte zu etikettieren, als darum zu verstehen, welchen Kompromiss Sie eingehen, wenn Uneinigkeit auftritt — besonders wenn diese Uneinigkeit durch einfache Langsamkeit verursacht wird.
Konsistenz‑Optionen, die Sie tatsächlich wählen können
CAP‑Debatten machen Konsistenz oft binär erscheinen: entweder „perfekt“ oder „alles ist erlaubt“. Reale Systeme bieten ein Menü an Garantien, jede mit unterschiedlichem Nutzererlebnis, wenn Repliken uneinig sind oder ein Link bricht.
Starke Konsistenz (und ihr Preis bei Ausfall)
Starke Konsistenz (oft „linearizable“) bedeutet: sobald ein Schreibvorgang bestätigt wurde, liefert jede spätere Leseoperation — egal welche Replik — diesen Schreibvorgang.
Kosten: während einer Partition oder wenn eine Minderheit der Repliken unerreichbar ist, kann das System lesen/schreiben verzögern oder ablehnen, um widersprüchliche Zustände zu vermeiden. Nutzer merken das als Timeouts, „bitte erneut versuchen“ oder temporäre Nur‑Lesen‑Verfügbarkeit.
Eventuelle Konsistenz (und was Nutzer merken können)
Eventuelle Konsistenz verspricht, dass bei ausbleibenden Updates alle Repliken konvergieren. Sie garantiert nicht, dass zwei Nutzer, die gerade jetzt lesen, dasselbe sehen.
Was Nutzer merken könnten: ein gerade aktualisiertes Profilbild „springt zurück“, Zähler hinken hinterher oder eine gerade gesendete Nachricht ist auf einem anderen Gerät kurzfristig nicht sichtbar.
Nützliche Zwischen‑Garantien
Oft bekommt man eine bessere Erfahrung, ohne volle starke Konsistenz zu verlangen:
- Read‑your‑writes: nachdem Sie etwas geändert haben, lesen Sie nicht eine ältere Version Ihrer eigenen Daten.
- Monotone Reads: sobald Sie Version N gesehen haben, sehen Sie später nicht wieder Version N‑1.
- Kausale Konsistenz: wenn Ereignis B von A abhängt (Antwort nach dem Lesen einer Nachricht), sehen alle A vor B.
Diese Garantien passen gut zur menschlichen Erwartung („zeige nicht meine eigene Änderung verschwinden“) und sind unter teilweisen Ausfällen oft leichter einzuhalten.
Konsistenzlevel nach Erwartungen wählen
Beginnen Sie mit Nutzerzusagen, nicht mit Fachbegriffen:
- Wenn falsche Reads irreparable Schäden verursachen (Geldbewegungen, Inventarreservierung, Berechtigungsänderungen), tendieren Sie zu stärkerer Konsistenz und akzeptieren temporäre Nichtverfügbarkeit.
- Wenn das Feature kurze Uneinigkeiten toleriert (Likes, View‑Counts, Feed‑Ranking), passt meist eventuelle oder kausale Konsistenz.
- Wenn das Hauptproblem persönliche Verwirrung ist („Ich habe gespeichert — warum sehe ich es nicht?“), priorisieren Sie read‑your‑writes und monotone reads.
Konsistenz ist eine Produktentscheidung: definieren Sie, wie „falsch“ für den Nutzer aussieht, und wählen Sie die schwächste Garantie, die diese falsche Situation verhindert.
Verfügbarkeit als Produktentscheidung, nicht nur als Uptime‑Zahl
Verhalten in produktionsähnlichen Durchläufen sehen
Setze einen Prototypen ein und beobachte, wie Timeouts und Fallbacks die wahrgenommene Verfügbarkeit beeinflussen.
Verfügbarkeit in CAP ist kein Werbe‑Metrik („five nines“) — es ist ein Versprechen gegenüber Nutzer*innen, wie sich das System verhält, wenn es sich nicht sicher sein kann.
Schneller Erfolg vs. genauer Erfolg
Wenn Repliken nicht übereinstimmen können, wählen Sie oft zwischen:
- Schneller Erfolg: geben Sie etwas schnell zurück (auch wenn es veraltet ist).
- Genaue Antwort: geben Sie nur zurück, wenn Sie beweisen können, dass die Antwort aktuell ist.
Nutzer empfinden das als „die App funktioniert“ vs. „die App ist korrekt“. Keines ist universell besser; die richtige Wahl hängt davon ab, was „falsch“ im Produkt bedeutet. Ein leicht veralteter Social‑Feed ist ärgerlich; ein veralteter Kontostand kann schädlich sein.
„Fail closed“ vs. „fail open"
Zwei häufige Verhaltensweisen in Unsicherheitssituationen:
- Fail closed: die Anfrage wird abgelehnt (Fehler, Timeouts, Nur‑Lesen‑Modus). Sie schützen Korrektheit, blockieren aber Nutzer.
- Fail open: liefern Sie eine Best‑Effort‑Antwort (Cache, lokale Replik, queued write). Sie schützen den Fluss, riskieren aber Inkonsistenzen.
Das ist keine rein technische Entscheidung; es ist eine Policy‑Erwägung. Das Produkt muss definieren, was akzeptabel angezeigt werden darf und was niemals geraten werden darf.
Teilweise Verfügbarkeit ist trotzdem Verfügbarkeit
Verfügbarkeit ist selten alles‑oder‑nichts. Während einer Spaltung sehen Sie möglicherweise partielle Verfügbarkeit: einige Regionen, Netze oder Nutzergruppen haben Erfolg, andere nicht. Das kann absichtlich so gewollt sein (lokale Repliken bedienen weiter) oder ein unbeabsichtigter Nebeneffekt (Routing‑Ungleichgewicht, ungleicher Quorum‑Zugriff).
Degraded Mode: Kernfunktionen halten, Risiko begrenzen
Eine praktische Zwischenlösung ist der Degraded Mode: erlauben Sie weiterhin sichere Aktionen, beschränken Sie riskante. Zum Beispiel: Browsen und Suchen erlauben, aber vorübergehend „Geld überweisen“, „Passwort ändern“ oder andere Operationen deaktivieren, bei denen Korrektheit und Einzigartigkeit zentral sind.
Konkrete Beispiele: CAP‑Wahl an Use Cases anpassen
CAP wirkt abstrakt, bis Sie es auf das abbilden, was Nutzer während einer Netzwerkspaltung erleben: Bevorzugen Sie, dass das System weiter antwortet, oder dass es stoppt und widersprüchliche Daten vermeidet?
Inventar und Bestellungen: Oversell‑Risiko vs. Checkout‑Ausfälle
Stellen Sie zwei Rechenzentren vor, die Bestellungen akzeptieren, während sie nicht miteinander reden können.
Wenn Sie den Checkout verfügbar halten, könnte jede Seite den „letzten Artikel“ verkaufen und Sie oversellen. Das ist bei niedrigen Werten akzeptabel (Backorder, Entschuldigung), aber bei limitierten Drops schmerzhaft.
Wenn Sie Konsistenz priorisieren, blockieren Sie möglicherweise neue Bestellungen, wenn Sie den globalen Bestand nicht bestätigen können. Nutzer sehen „bitte später versuchen“, aber Sie vermeiden Verkäufe, die Sie nicht erfüllen können.
Zahlungen und Kontostände: Korrektheits‑first Muster (und warum)
Geld ist das klassische Beispiel, bei dem Fehler teuer sind. Wenn zwei Repliken unabhängig Abbuchungen annehmen, kann ein Konto ins Minus geraten.
Systeme bevorzugen oft Konsistenz bei kritischen Writes: Aktionen ablehnen oder verzögern, wenn der aktuelle Kontostand nicht bestätigt werden kann. Sie tauschen Verfügbarkeit (temporäre Zahlungsfehler) gegen Korrektheit, Prüf‑ und Vertrauensfähigkeit ein.
Chat, Feeds, Analytics: „verfügbar mit leicht veralteten Daten“ ist OK
In Chat und Social‑Feeds tolerieren Nutzer meist kleine Inkonsistenzen: eine Nachricht kommt einige Sekunden später an, eine Like‑Anzahl weicht ab, Metriken aktualisieren verspätet.
Hier ist Verfügbarkeit oft eine gute Produktwahl, solange klar ist, welche Elemente „schließlich korrekt“ werden und wie Updates zusammengeführt werden.
Der Punkt: Ihr Tradeoff ist eine Geschäftsentscheidung
Die „richtige“ CAP‑Wahl hängt von den Kosten eines Fehlers ab: Rückerstattungen, rechtliche Risiken, Vertrauensverlust der Nutzer oder operativer Chaosaufwand. Entscheiden Sie, wo temporäre Staleness akzeptabel ist — und wo geschlossen werden muss.
Designmuster, die Ihren Kompromiss umsetzen
Wenn Sie entschieden haben, wie das System sich bei einer Netzwerkspaltung verhalten soll, brauchen Sie Mechanismen, die diese Entscheidung real machen. Diese Muster tauchen in Datenbanken, Nachrichtensystemen und APIs auf — auch wenn das Produkt nie „CAP“ sagt.
Quorums: Mehrheitsvereinbarung
Ein Quorum ist einfach „die Mehrheit der Repliken stimmt zu“. Bei 5 Kopien ist eine Mehrheit 3.
Wenn Sie Lese‑ und/oder Schreibvorgänge an die Mehrheit knüpfen, reduzieren Sie die Chance, veraltete oder konfligierende Daten zurückzugeben. Beispiel: wenn ein Write von 3 Repliken bestätigt werden muss, ist es unwahrscheinlicher, dass zwei isolierte Gruppen jeweils unterschiedliche Wahrheiten akzeptieren.
Der Nachteil ist bei Erreichbarkeit und Geschwindigkeit: wenn Sie keine Mehrheit erreichen (wegen Partition oder Ausfall), verweigert das System die Operation — Sie wählen Konsistenz über Verfügbarkeit.
Timeouts, Retries und Backoff formen die gefühlte Verfügbarkeit
Viele „Verfügbarkeits“‑Probleme sind nicht harte Fehler, sondern langsame Antworten. Kurze Timeouts machen das System flink, erhöhen aber die Wahrscheinlichkeit, langsame Erfolge als Fehler zu behandeln.
Retries können transienten Störungen begegnen, aber aggressive Retries können einen schon belasteten Dienst überfordern. Backoff (längere Wartezeiten zwischen Retries) und Jitter (Zufall) verhindern, dass Retries zu Traffic‑Spitzen werden.
Der Schlüssel ist, diese Einstellungen an Ihr Versprechen anzupassen: „immer antworten“ heißt meist mehr Retries und Fallbacks; „niemals lügen“ heißt engere Limits und klarere Fehler.
Konflikthandhabung, wenn Sie Divergenz erlauben
Wenn Sie während Partitionen verfügbar bleiben, können Repliken unterschiedliche Updates annehmen und Sie müssen später reconciliieren. Übliche Ansätze:
- Last‑Write‑Wins (LWW): das Update mit dem neuesten Zeitstempel gewinnt. Einfach, kann aber gültige Änderungen verwerfen, wenn Uhren nicht synchron sind.
- Versionsvektoren: fügen eine kleine „Historie“ hinzu, die hilft zu erkennen, ob Updates gleichzeitig sind oder eines das andere superseded.
- Merge‑Regeln: definieren, wie Änderungen kombiniert werden (z. B. Warenkorbeinträge vereinigen; Zähler addieren; Profile bevorzugen nicht‑leere Felder). Funktioniert am besten, wenn es im Datenmodell berücksichtigt ist.
Idempotenz: Retries sicher machen
Retries können Duplikate erzeugen: doppelte Belastungen oder doppelte Aufträge. Idempotenz verhindert das.
Ein übliches Muster ist ein Idempotency‑Key (Request‑ID) bei jeder Anfrage. Der Server speichert das erste Ergebnis und liefert bei Wiederholungen dasselbe Ergebnis zurück — so verbessern Retries die Verfügbarkeit, ohne Daten zu korruptieren.
Wie Sie CAP‑Annahmen im echten Leben validieren
Bauen und Credits verdienen
Teile, was du mit Koder.ai gebaut hast, und verdiene Credits, um weiter zu experimentieren.
Die meisten Teams „wählen“ eine CAP‑Haltung am Whiteboard — und stellen in Produktion fest, dass das System sich unter Last anders verhält. Validierung heißt, gezielt die Bedingungen zu erzeugen, in denen CAP‑Kompromisse sichtbar werden, und zu prüfen, ob Ihr System wie geplant reagiert.
Partitionen absichtlich (sicher) testen
Sie brauchen keinen echten Kabelschnitt, um zu lernen. Nutzen Sie kontrollierte Fault‑Injection in Staging (und vorsichtig in Produktion), um Partitionen zu simulieren:
- Blackhole Traffic zwischen bestimmten Diensten oder Knoten (Pakete fallen, Verbindungen bleiben offen) um eine stille Trennung zu imitieren.
- Links killen durch Blockieren von Ports oder Security‑Gruppen zwischen Repliken/Regionen.
- Extreme Latenz und Paketverlust hinzufügen, sodass Timeouts und Retries sich wie eine Partition verhalten.
- Leader‑Isolation erzwingen (z. B. den Primary von einem Quorum isolieren), um zu sehen, ob Sie „konsistent“ oder „verfügbar“ reagieren.
Das Ziel ist, konkrete Fragen zu beantworten: Werden Writes abgelehnt oder akzeptiert? Liefern Reads veraltete Daten? Erholt sich das System automatisch und wie lange dauert die Rekonsiliation?
Wenn Sie Verhalten früh prüfen wollen (bevor Sie Wochen in das Zusammenspiel der Dienste investieren), hilft ein realistisches Prototyping. Teams erstellen oft einen kleinen Service‑Prototyp (z. B. Go‑Backend mit PostgreSQL und React‑UI) und iterieren dort an Retries, Idempotency‑Keys und Degraded‑Mode‑Flows in einer Sandbox.
Signale überwachen, die CAP‑Schmerz anzeigen
Traditionelle Uptime‑Checks erfassen nicht „verfügbar aber falsch“. Beobachten Sie:
- Fehlerraten nach Operationstyp (Read vs Write vs Conditional Update)
- Stale‑Read‑Indikatoren (Read‑your‑writes‑Verletzungen, Version/ETag‑Mismatch, Lag‑Metriken)
- Replik‑Divergenz (Replikationsverzögerung, fehlgeschlagene Apply‑Counts, Konfliktraten)
- Timeouts/Retries (oft das erste Anzeichen einer sich entwickelnden Spaltung)
Runbooks und Nutzerkommunikation
Operatoren brauchen vorgefertigte Aktionen für den Partition‑Fall: wann Writes einfrieren, wann Failover stattfinden, wann Features einschränken und wie man die Re‑Merge‑Sicherheit überprüft.
Planen Sie auch die Nutzer‑sicht. Wenn Sie Konsistenz wählen, könnte die Meldung lauten: „Wir können Ihr Update gerade nicht bestätigen — bitte versuchen Sie es später.“ Wenn Sie Verfügbarkeit wählen, seien Sie explizit: „Ihre Änderung kann ein paar Minuten dauern, bis sie überall sichtbar ist.“ Klare Formulierungen reduzieren Support‑Aufwand und erhalten Vertrauen.
Eine praktische CAP‑Checkliste für Alltagsentscheidungen
Wenn Sie eine Systementscheidung treffen, ist CAP am nützlichsten als schneller „was bricht bei einer Spaltung?“‑Audit — nicht als theoretische Debatte. Nutzen Sie diese Checkliste, bevor Sie ein Datenbankfeature, eine Cache‑Strategie oder einen Replikationsmodus wählen.
1) Kurze CAP‑Checkliste
Fragen Sie in dieser Reihenfolge:
- Was muss korrekt sein? (z. B. „ein Kontostand darf nie negativ werden“, „Inventar darf nicht überverkauft werden“, „Berechtigungen müssen akkurat sein“)
- Was muss erreichbar bleiben? (z. B. Checkout‑Endpoint, Login, readonly Katalog)
- Was kann temporär degradiert werden? (z. B. Analytics, Empfehlungen, Profil‑Avatare, „zuletzt online“)
Wenn eine Partition passiert, entscheiden Sie, welche dieser Dinge Sie zuerst schützen.
2) Pro Datentyp und pro Endpoint entscheiden
Vermeiden Sie eine einzige globale Einstellung wie „wir sind ein AP‑System“. Entscheiden Sie pro:
- Datentyp: Geld vs Likes vs Logs
- Endpoint: „Bestellung aufgeben“ vs „Bestellung ansehen“ vs „Sendung verfolgen"
Beispiel: Während einer Spaltung blockieren Sie Writes an payments (Konsistenz bevorzugen), halten Reads des product_catalog aber mit gecachten Daten verfügbar.
3) Definieren Sie „akzeptable Inkonsistenz“ konkret
Formulieren Sie, was Sie tolerieren, mit Beispielen:
- Zeitlich: „Zähler können 5–10 Minuten hinterherhinken"
- Betragsmäßig: „Inventar kann bei wenig nachgefragten Artikeln ±1 abweichen"
- Feldbezogen: „Versand‑ETA kann veraltet sein; Bestellsumme darf es nicht"
- User‑sichtbar: „zeige ‚pending‘ statt eines definitiven Status"
Wenn Sie Inkonsistenz nicht in einfachen Beispielen beschreiben können, werden Sie Schwierigkeiten beim Testen und bei der Incident‑Erklärung haben.
4) Fazit + weiterführende Lektüre
- Partitionen machen aus „nice‑to‑have“ Garantien erzwungene Entscheidungen.\n- Treffen Sie diese Entscheidungen explizit pro Endpoint und dokumentieren Sie akzeptable Inkonsistenz.
Weiterführende Themen, die gut zu dieser Checkliste passen: Konsensus (/blog/consensus-vs-cap), Konsistenzmodelle (/blog/consistency-models-explained) und SLOs/Error‑Budgets (/blog/sre-slos-error-budgets).
FAQ
Welches Problem hilft CAP Ingenieur*innen zu durchdenken?
CAP ist ein Denkmodell für replizierte Systeme unter Kommunikationsausfall. Es ist besonders nützlich, wenn das Netzwerk langsam, verlustbehaftet oder geteilt ist, denn dann können Repliken nicht zuverlässig übereinstimmen und man muss zwischen folgenden Optionen wählen:
- Konsistenz: alle sehen denselben neuesten Wert
- Verfügbarkeit: das System liefert weiterhin erfolgreiche Antworten
Es hilft, das vage „Verteilte Systeme sind schwierig“ in eine konkrete Produkt‑ und Ingenieursentscheidung zu verwandeln.
Wann befinde ich mich tatsächlich in einer CAP‑Situation?
Ein echtes CAP‑Szenario braucht beides:
- Replikation (mehr als ein Knoten kann dieselben Daten bedienen bzw. annehmen)
- eine realistische Chance für Kommunikationsausfälle (Partitionen, Timeouts, lange Verzögerungen)
Wenn Ihr System nur auf einem Knoten läuft oder Zustand nicht repliziert wird, sind CAP‑Tradeoffs nicht das zentrale Problem.
Was zählt in realen Systemen als Netzwerkpartition?
Eine Partition ist jede Situation, in der Teile Ihres Systems nicht mehr zuverlässig oder innerhalb der erforderlichen Zeitlimits kommunizieren können — selbst wenn jede Maschine noch läuft.
Praktisch zeigt sich eine Partition oft als:
- Latenzspitzen, die Timeouts auslösen
- verlorene/blackholed Pakete
- Firewall‑ oder Routing‑Fehlkonfigurationen
- überlastete Knoten, die nicht mehr rechtzeitig antworten
Aus Sicht der Anwendung kann „zu langsam“ dasselbe sein wie „ausgefallen“.
Was ist der Unterschied zwischen Konsistenz und Verfügbarkeit in User‑Begriffen?
Konsistenz (C) bedeutet, dass Lesevorgänge den zuletzt bestätigten Schreibvorgang anzeigen — egal an welche Replik man sich wendet. Nutzer*innen erleben das als: „Ich habe es geändert und alle sehen dieselbe Änderung."
Verfügbarkeit (A) bedeutet, dass jede Anfrage eine erfolgreiche Antwort erhält (nicht unbedingt die aktuellste). Nutzer*innen erleben das als: „Die App funktioniert weiter“, möglicherweise mit veralteten Ergebnissen.
Während einer Partition kann man in der Regel nicht beides für alle Operationen garantieren.
Warum kann ich nicht einfach Konsistenz und Verfügbarkeit wählen und Partitionen ignorieren?
Weil Partitionen in verteilten Systemen, die sich über Maschinen, Racks, Zonen oder Regionen erstrecken, nicht optional sind. Wenn Sie replizieren, müssen Sie Verhalten definieren, wenn Knoten nicht koordinieren können.
„Partitionen tolerieren“ bedeutet in der Praxis: wenn die Kommunikation ausfällt, hat das System ein definiertes Verhalten — entweder lehnt es einige Aktionen ab/pausiert sie (Konsistenz bevorzugen) oder es liefert best‑effort Ergebnisse (Verfügbarkeit bevorzugen).
Wie sieht eine Konsistenz‑first (CP) Entscheidung während einer Partition aus?
Wenn Sie Konsistenz priorisieren, tun Sie in der Regel Folgendes:
- lehnen Operationen ab oder verzögern sie, wenn Sie keine bestätigte Übereinstimmung herstellen können
- verlangen Mehrheits‑Quorums für Lese‑/Schreibvorgänge
- zeigen Fehler wie Timeouts, „bitte erneut versuchen“ oder einen Nur‑Lesen‑Modus an
Das ist verbreitet bei Geldbewegungen, Inventarreservierungen und Berechtigungsänderungen — dort ist falsch zu sein schlimmer als kurzzeitig nicht verfügbar zu sein.
Wie sieht eine Verfügbarkeits‑first (AP) Entscheidung während einer Partition aus?
Wenn Sie Verfügbarkeit priorisieren, tun Sie typischerweise:
- auf jeder Seite der Partition weiterhin Lese‑ und Schreibvorgänge annehmen
- zulassen, dass Repliken vorübergehend divergieren
- später reconciliieren (Merge‑Regeln, Konfliktlösung, manuelle Überprüfung)
Nutzer sehen weniger harte Fehler, können aber veraltete Daten, doppelte Effekte ohne Idempotenz oder konfligierende Updates erleben, die aufgeräumt werden müssen.
Kann ich Konsistenz‑ und Verfügbarkeits‑Entscheidungen nach Operation mischen?
Ja. Häufig wählt man unterschiedlich pro Endpunkt oder Datentyp. Übliche gemischte Strategien sind:
- Reads bleiben verfügbar, Writes werden strenger (Durchsuchen funktioniert; riskante Updates können fehlschlagen)
- Kritische Aktionen fallen geschlossen aus (Zahlungen, Inventar, Auth), während niederwertige Features offen bleiben (Feeds, Analytics)
- Degraded Mode: sichere Operationen erlaubt, riskante vorübergehend deaktiviert
Das vermeidet ein globales Label „wir sind AP/CP“, das selten zu den Produktanforderungen passt.
Welche Konsistenzgarantien kann ich neben „stark“ und „eventuell“ wählen?
Nützliche Optionen neben „stark“ vs. „eventuell“ sind:
Wie teste und überwache ich das CAP‑Verhalten meines Systems praktisch?
Validieren Sie durch das Herbeiführen von Bedingungen, bei denen Divergenz sichtbar wird:
- simulieren Sie Partitionen/Latenz in Staging (und vorsichtig in Prod): blackhole Traffic, Ports blockieren, Verzögerung/Verlust hinzufügen
- prüfen Sie das Verhalten: werden Writes abgewiesen oder akzeptiert? werden Reads veraltet? wie läuft die Wiederherstellung/Reconciliation?
- überwachen Sie Signale jenseits der Uptime:
- fehlerquoten nach Operationstyp (read vs write)