05. Mai 2025·8 Min
Web-App erstellen, um Kunden-Eskalations-Timelines zu verwalten
Schritt-für-Schritt-Plan zum Aufbau einer Web-App, die Kunden-Eskalationen, Fristen, SLAs, Zuständigkeiten und Alerts nachverfolgt — plus Reporting und Integrationen.
Schritt-für-Schritt-Plan zum Aufbau einer Web-App, die Kunden-Eskalationen, Fristen, SLAs, Zuständigkeiten und Alerts nachverfolgt — plus Reporting und Integrationen.
Bevor Sie Bildschirme entwerfen oder einen Tech-Stack auswählen, legen Sie konkret fest, was „Eskalation" in Ihrer Organisation bedeutet. Ist es ein Support-Fall, der altert, ein Incident, der die Verfügbarkeit bedroht, eine Beschwerde eines Schlüsselkunden oder jede Anfrage, die eine Schweregrenze überschreitet? Wenn unterschiedliche Teams das Wort verschieden verwenden, wird Ihre App Verwirrung kodieren.
Schreiben Sie eine Ein-Satz-Definition, der Ihr gesamtes Team zustimmen kann, und fügen Sie ein paar Beispiele hinzu. Zum Beispiel: „Eine Eskalation ist jedes Kundenproblem, das eine höhere Supportstufe oder Management-Einbindung erfordert und eine zeitlich begrenzte Verpflichtung hat."
Definieren Sie auch, was nicht zählt (z. B. Routine-Tickets, interne Aufgaben), damit v1 nicht aufbläht.
Erfolgskriterien sollten widerspiegeln, was Sie verbessern wollen — nicht nur, was Sie bauen möchten. Typische Kernoutcomes sind:
Wählen Sie 2–4 Metriken, die Sie von Tag eins an verfolgen können (z. B. Verletzungsrate, Zeit in jeder Eskalationsphase, Anzahl der Reassignments).
Listen Sie primäre Nutzer (Agenten, Team-Leads, Manager) und sekundäre Stakeholder (Account Manager, Engineering On-Call) auf. Notieren Sie für jede Rolle, was sie schnell erledigen müssen: Verantwortung übernehmen, eine Frist mit Begründung verlängern, den nächsten Schritt sehen oder den Status für einen Kunden zusammenfassen.
Erfassen Sie aktuelle Fehlerfälle mit konkreten Geschichten: verpasste Übergaben zwischen Stufen, unklare Fälligkeiten nach Reassignment, „Wer hat die Verlängerung genehmigt?“ Debatten.
Nutzen Sie diese Stories, um Muss-Funktionen (Timeline + Ownership + Auditierbarkeit) von späteren Ergänzungen (fortgeschrittene Dashboards, komplexe Automatisierung) zu trennen.
Mit klaren Zielen schreiben Sie auf, wie eine Eskalation durch Ihr Team fließt. Ein geteilter Workflow verhindert, dass „Sonderfälle" zu inkonsistentem Handling und verpassten SLAs führen.
Starten Sie mit einer einfachen Menge an Stufen und erlaubten Übergängen:
Dokumentieren Sie, was jede Stufe bedeutet (Entry-Kriterien) und was wahr sein muss, um sie zu verlassen (Exit-Kriterien). So vermeiden Sie Ambivalenzen wie „Resolved, aber wartet noch auf Kunde".
Eskalationen sollten durch Regeln entstehen, die Sie in einem Satz erklären können. Häufige Trigger sind:
Entscheiden Sie, ob Trigger automatisch eine Eskalation erstellen, dem Agenten vorschlagen oder eine Genehmigung erfordern.
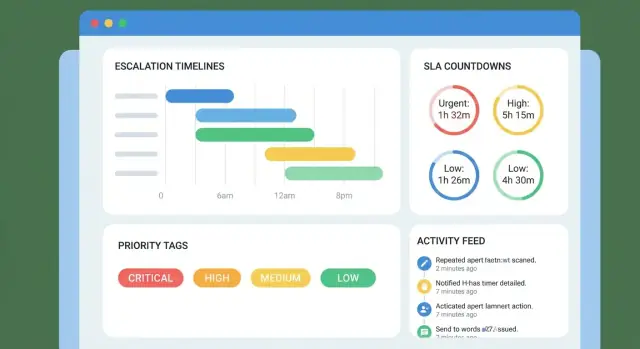
Ihre Timeline ist nur so gut wie ihre Ereignisse. Erfassen Sie mindestens:
Schreiben Sie Regeln für Ownership-Änderungen: wer kann neu zuweisen, wann sind Genehmigungen nötig (z. B. Cross-Team oder Vendor-Handoff) und was passiert, wenn ein Owner nicht mehr verfügbar ist.
Abschließend kartieren Sie Abhängigkeiten, die das Timing beeinflussen: On-Call-Pläne, Tier-Level (T1/T2/T3) und externe Vendoren (inkl. deren Reaktionsfenster). Das steuert später Ihre Timeline-Berechnungen und die Eskalationsmatrix.
Eine verlässliche Eskalations-App ist größtenteils ein Datenproblem. Wenn Timelines, SLAs und Historie nicht klar modelliert sind, wirkt die UI und Benachrichtigung immer „falsch“. Beginnen Sie damit, die Kern-Entities und ihre Beziehungen zu benennen.
Mindestens planen für:
Behandeln Sie jeden Meilenstein als Timer mit:
start_at (wann die Uhr beginnt)due_at (berechnete Frist)paused_at / pause_reason (optional)completed_at (wann erfüllt)Speichern Sie warum ein Fälligkeitsdatum existiert (die Regel), nicht nur den berechneten Zeitstempel. Das erleichtert spätere Streitfälle.
SLAs bedeuten selten „immer“. Modellieren Sie einen Kalender pro SLA-Policy: Geschäftszeiten vs 24/7, Feiertage und regionsspezifische Zeitpläne.
Berechnen Sie Deadlines in einer konsistenten Server-Zeit (UTC), speichern Sie jedoch stets die Case-Zeitzone (oder Kundenzeitzone), damit die UI Fristen korrekt anzeigen und Nutzer sie einordnen können.
Entscheiden Sie früh zwischen:
CASE_CREATED, STATUS_CHANGED, MILESTONE_PAUSED), oderFür Compliance und Verantwortlichkeit ist ein Event-Log vorzuziehen (auch wenn Sie zusätzlich „aktuellen Zustand" für Performance vorhalten). Jede Änderung sollte aufzeichnen wer, was sich geändert hat, wann und Quelle (UI, API, Automation), plus eine Korrelations-ID zum Nachverfolgen zusammenhängender Aktionen.
Berechtigungen sind der Punkt, an dem Eskalations-Tools entweder Vertrauen verdienen — oder mit Neben-Tabellenkalkulationen umgangen werden. Definieren Sie früh, wer was darf, und erzwingen Sie es konsistent über UI, API und Exporte.
Halten Sie v1 einfach mit Rollen, die den Support-Teams entsprechen:
Machen Sie Rollenprüfungen sichtbar im Produkt: Controls deaktivieren statt Nutzer auf Fehler klicken zu lassen.
Eskalationen überschneiden oft mehrere Gruppen (Tier 1, Tier 2, CSM, Incident Response). Planen Sie Multi-Team-Unterstützung durch Sichtbarkeits-Scoping über eine oder mehrere Dimensionen:
Ein guter Default: Nutzer sehen Fälle, bei denen sie Assignee, Watcher oder Mitglied des owning-Teams sind — plus Accounts, die explizit mit ihrer Rolle geteilt sind.
Nicht alle Daten sollten für jeden sichtbar sein. Häufig sensible Felder sind Kunden-PII, Vertragsdetails und interne Notizen. Implementieren Sie feldbezogene Berechtigungen wie:
Für v1 reicht meist E-Mail/Passwort mit optionaler MFA. Gestalten Sie das Nutzer-Modell so, dass SSO (SAML/OIDC) später ohne komplette Neuimplementierung hinzufügbar ist (z. B. Rollen/Teams intern speichern, SSO-Gruppen beim Login mappen).
Behandeln Sie Berechtigungsänderungen als auditierbare Aktionen. Zeichnen Sie Events wie Rollen-Updates, Team-Reassignments, Export-Downloads und Konfig-Edits auf — wer, wann und was sich geändert hat. Das schützt bei Incidents und erleichtert Access-Reviews.
Ihre Eskalations-App gewinnt oder verliert am täglichen Interface: was ein Support-Lead zuerst sieht, wie schnell er einen Fall versteht und ob die nächste Frist leichter übersehen wird.
Beginnen Sie mit wenigen Seiten, die 90% der Arbeit abdecken:
Halten Sie die Navigation vorhersehbar: linke Sidebar oder Top-Tabs mit „Queue“, „My Cases“, „Reports“. Setzen Sie die Queue als Default-Landing-Page.
In der Fallliste zeigen Sie nur Felder, die helfen, schnell zu entscheiden, was als Nächstes zu tun ist. Eine gute Default-Zeile enthält: Kunde, Priorität, aktueller Owner, Status, nächstes Fälligkeitsdatum und ein Warnindikator (z. B. „Fällig in 2h" oder „Überfällig um 1d").
Fügen Sie schnelle, praktische Filter und Suche hinzu:
Gestalten Sie die Ansicht scanbar: konsistente Spaltenbreiten, klare Status-Chips und eine einzige Highlight-Farbe, die nur für Dringlichkeit verwendet wird.
Die Fallansicht sollte auf einen Blick beantworten:
Platzieren Sie schnelle Aktionen oben (nicht in verschachtelten Menüs): Reassign, Escalate, Add milestone, Add note, Set next deadline. Jede Aktion sollte bestätigen, was sich geändert hat und die Timeline sofort aktualisieren.
Ihre Timeline sollte wie eine klare Abfolge von Verpflichtungen lesbar sein. Enthalten Sie:
Nutzen Sie progressive Offenlegung: zeigen Sie neueste Events zuerst, mit Option, ältere Historie aufzuklappen. Wenn Sie einen Audit-Trail haben, verlinken Sie ihn aus der Timeline (z. B. „Change Log anzeigen").
Verwenden Sie ausreichend Kontrast, koppeln Sie Farbe mit Text („Overdue"), sorgen Sie dafür, dass alle Aktionen per Tastatur erreichbar sind, und schreiben Sie Labels in der Nutzersprache („Set next customer update deadline", nicht „Update SLA"). Das reduziert Fehlklicks unter Druck.
Alerts sind der „Herzschlag" einer Eskalations-Timeline: sie halten Fälle in Bewegung, ohne dass Menschen dauerhaft ein Dashboard beobachten müssen. Das Ziel ist simpel — die richtige Person zur richtigen Zeit mit minimalem Rauschen informieren.
Starten Sie mit einer kleinen Menge an Events, die direkt zu Aktionen führen:
Für v1 wählen Sie Kanäle, die Sie zuverlässig liefern und messen können:
SMS oder Chat-Integrationen kommen später, wenn Regeln und Volumen stabil sind.
Stellen Sie Eskalation als zeitbasierte Schwellen dar, die an die Timeline des Falls gebunden sind:
Halten Sie die Matrix pro Priorität/Queue konfigurierbar, sodass „P1 Incidents" nicht dieselben Regeln wie „Billing-Fragen" folgen.
Implementieren Sie Dedupe („nicht dieselbe Benachrichtigung zweimal senden"), Batching (ähnliche Alerts zusammenfassen) und Quiet Hours, die nicht-kritische Erinnerungen verzögern, diese aber weiterhin protokollieren.
Jeder Alert sollte unterstützen:
Speichern Sie diese Aktionen im Audit-Trail, damit Reports unterscheiden können zwischen „niemand hat es gesehen" und „jemand hat es gesehen und verschoben".
Die meisten Eskalations-Apps scheitern, wenn Leute Daten neu eintippen müssen, die schon anderswo existieren. Für v1 integrieren Sie nur, was nötig ist, um Timelines akkurat und Benachrichtigungen rechtzeitig zu halten.
Entscheiden Sie, welche Kanäle Fälle erstellen/aktualisieren dürfen:
Halten Sie Inbound-Payloads klein: Case-ID, Customer-ID, aktueller Status, Priorität, Zeitstempel und eine kurze Zusammenfassung.
Ihre App sollte andere Systeme informieren, wenn etwas Wichtiges passiert:
Verwenden Sie Webhooks mit signierten Requests und einer Event-ID zur Dedupe.
Wenn Sie in beide Richtungen synchronisieren, deklarieren Sie pro Feld eine Quelle der Wahrheit (z. B. Ticketing-Tool owns Status; Ihre App owns SLA-Timer). Definieren Sie Konfliktregeln ("last write wins" ist selten korrekt) und fügen Sie Retry-Logik mit Backoff plus eine Dead-Letter-Queue für Fehler hinzu.
Für v1: importieren Sie Kunden und Kontakte über stabile externe IDs und ein minimales Schema: Account-Name, Tier, Key-Contacts und Eskalationspräferenzen. Vermeiden Sie tiefes CRM-Mirroring.
Dokumentieren Sie eine kurze Checkliste (Auth-Methode, benötigte Felder, Rate-Limits, Retries, Test-Umgebung). Veröffentlichen Sie einen minimalen API-Vertrag (selbst eine einseitige Spezifikation) und versionieren Sie ihn, damit Integrationen nicht unerwartet brechen.
Ihr Backend muss zwei Dinge gut können: Eskalations-Timing akkurat halten und bei wachsendem Fallvolumen performant bleiben.
Wählen Sie die einfachste Architektur, die Ihr Team warten kann. Ein klassisches MVC mit REST API reicht oft für v1. Wenn Sie bereits GraphQL erfolgreich nutzen, kann es passen — vermeiden Sie es jedoch „nur weil". Kombinieren Sie es mit einer managed DB (z. B. Postgres), damit Sie Zeit in Eskalationslogik statt DB-Betrieb investieren.
Wenn Sie den Workflow Ende-zu-Ende validieren wollen, bevor Wochen Entwicklungsarbeit beginnen, kann eine Vibe-Coding-Plattform wie Koder.ai helfen, den Kern-Loop (Queue → Falldetail → Timeline → Notifications) aus einer Chat-Schnittstelle zu prototypen und später Quellcode zu exportieren. Ihr Default-Stack (React Web, Go + PostgreSQL Backend) passt gut zu audit-sensitiven Apps.
Eskalationen hängen von zeitgesteuerter Arbeit ab, daher benötigen Sie Background-Processing für:
Implementieren Sie Jobs idempotent (sicher mehrfach auszuführen) und retryable. Speichern Sie ein last evaluated at pro Fall/Timeline, um doppelte Aktionen zu vermeiden.
Speichern Sie alle Timestamps in UTC. Konvertieren Sie in die Zeitzone des Nutzers nur an UI-/API-Grenzen. Fügen Sie Tests für Randfälle hinzu: DST-Änderungen, Schaltjahre und „gepaarte" Pausen (z. B. SLA pausiert beim Warten auf den Kunden).
Nutzen Sie Pagination für Queues und Audit-Trail-Views. Fügen Sie Indizes hinzu, die Ihren Filtern/Sorts entsprechen — übliche Indexe: (due_at), (status), (owner_id) und Komposit-Index wie (status, due_at).
Planen Sie Dateispeicher getrennt von der DB: Größen-/Typ-Limits erzwingen, Uploads scannen (oder Provider-Integration nutzen) und Aufbewahrungsregeln definieren (z. B. Löschen nach 12 Monaten außer bei Legal Hold). Metadaten in Case-Tabellen halten; Datei in Object Storage ablegen.
Reporting macht Ihre Eskalations-App vom gemeinsamen Posteingang zum Management-Tool. Für v1 zielen Sie auf eine einzige Reporting-Seite, die zwei Fragen beantwortet: „Erfüllen wir SLAs?" und „Wo bleiben Eskalationen hängen?" Halten Sie es einfach, schnell und in übereinstimmenden Definitionen.
Ein Report ist nur so vertrauenswürdig wie seine zugrunde liegenden Definitionen. Schreiben Sie diese in klarer Sprache und spiegeln Sie sie im Datenmodell wider:
Entscheiden Sie außerdem, welche SLA-Uhr Sie reporten: First Response, Next Update oder Resolution (oder alle drei).
Ihr Dashboard kann leichtgewichtig, aber handlungsfähig sein:
Fügen Sie operative Views für tägliche Arbeitsverteilung hinzu:
CSV-Export reicht meist für v1. Binden Sie Exporte an Berechtigungen (Team-basiert, Rollenchecks) und schreiben Sie einen Audit-Log-Eintrag für jeden Export (wer, wann, Filter, Anzahl Zeilen). Das verhindert „mysteriöse Tabellen" und unterstützt Compliance.
Liefern Sie die erste Reporting-Seite schnell und reviewen Sie sie wöchentlich mit Support-Leads für einen Monat. Sammeln Sie Feedback zu fehlenden Filtern, verwirrenden Definitionen und „Ich kann X nicht beantworten"-Momenten — das sind die besten Inputs für v2.
Testen einer Eskalations-Timeline-App geht über „funktioniert es?" hinaus. Es geht darum, „verhält sie sich wie Support-Teams es erwarten, wenn Druck da ist?" Fokus auf realistische Szenarien, die Timeline-Regeln, Benachrichtigungen und Handoffs stressen.
Konzentrieren Sie die Testarbeit auf Timeline-Berechnungen — kleine Fehler hier führen zu großen SLA-Streitigkeiten.
Decken Sie Fälle wie Geschäftszeiten-Zählung, Feiertage und Zeitzonen ab. Fügen Sie Tests für Pausen (Warten auf Kunde, Engineering pending), Priority-Änderungen im Verlauf und Eskalationen, die Zielzeiten verschieben. Testen Sie auch Randbedingungen: ein Fall, der eine Minute vor Geschäftsschluss erstellt wurde, oder eine Pause, die genau an einer SLA-Grenze startet.
Benachrichtigungen scheitern oft in den Lücken zwischen Systemen. Schreiben Sie Integrationstests, die verifizieren:
Wenn Sie E-Mail, Chat oder Webhooks nutzen, prüfen Sie Payloads und Timing — nicht nur, dass „etwas gesendet wurde".
Erstellen Sie realistische Beispieldaten, die UX-Probleme früh aufdecken: VIP-Kunden, langlaufende Fälle, häufige Reassignments, wiedereröffnete Incidents und Peak-Perioden mit Queue-Spikes. So validieren Sie, dass Queues, Falldetail und Timeline ohne Erklärung lesbar sind.
Führen Sie einen Pilot mit einem Team für 1–2 Wochen durch. Sammeln Sie täglich Issues: fehlende Felder, verwirrende Labels, Benachrichtigungsrauschen und Ausnahmen Ihrer Timeline-Regeln.
Verfolgen Sie, was Nutzer außerhalb der App tun (Tabellen, Nebenkanäle), um Lücken zu erkennen.
Formulieren Sie vor der breiten Einführung, was „done" bedeutet: Kern-SLA-Metriken stimmen mit erwarteten Ergebnissen überein, kritische Benachrichtigungen sind zuverlässig, Audit-Trails vollständig und das Pilot-Team kann Eskalationen Ende-zu-Ende ohne Workarounds durchführen.
Das Ausliefern der ersten Version ist nicht das Ende. Eine Eskalations-Timeline-App wird „real" erst, wenn sie Alltagsfehler überlebt: verpasste Jobs, langsame Queries, falsch konfigurierte Benachrichtigungen und unvermeidliche SLA-Änderungen. Behandeln Sie Deployment und Betrieb als Produktaufgabe.
Halten Sie Ihren Release-Prozess langweilig und wiederholbar. Dokumentieren und automatisieren Sie mindestens:
Wenn Sie eine Staging-Umgebung haben, seeden Sie sie mit realistischen (sanitized) Daten, damit Timeline-Verhalten und Benachrichtigungen vor Prod verifiziert werden können.
Traditionelle Uptime-Checks fangen nicht die schlimmsten Probleme. Ergänzen Sie Monitoring dort, wo Eskalationen stillschweigend scheitern:
Erstellen Sie ein kleines On-Call-Playbook: „Wenn Eskalations-Reminders nicht senden, prüfe A → B → C." Das reduziert Ausfallzeiten in Hochdruck-Situationen.
Eskalationsdaten enthalten oft Kundennamen, E-Mails und sensible Notizen. Definieren Sie Richtlinien früh:
Machen Sie Retention konfigurierbar, damit Policy-Änderungen keinen Code-Change erfordern.
Auch in v1 benötigen Admins Mittel, um das System gesund zu halten:
Schreiben Sie kurze, aufgabenbasierte Docs: „Eine Eskalation erstellen", „Eine Timeline pausieren", „SLA überschreiben", „Wer hat was geändert?".
Fügen Sie einen leichten Onboarding-Flow in der App hinzu, der Nutzer zu Queues, Falldetail und Timeline-Aktionen führt, plus einen Link zu einer /help-Seite.
Version 1 sollte den Kern-Loop beweisen: Ein Fall hat eine klare Timeline, die SLA-Uhr verhält sich vorhersehbar und die richtigen Personen werden benachrichtigt. Version 2 kann Leistung hinzufügen, ohne v1 in ein aufgeblähtes System zu verwandeln. Die Kunst ist, eine kurze, explizite Backlog-Liste zu behalten, die Sie erst nach echtem Nutzungs-Feedback abarbeiten.
Ein gutes v2-Item reduziert (a) manuelle Arbeit in großem Maßstab, oder (b) verhindert kostspielige Fehler. Wenn es hauptsächlich mehr Konfigurationsoptionen hinzufügt, parken Sie es, bis mehrere Teams tatsächlich Bedarf zeigen.
SLA-Kalender pro Kunde sind oft die erste sinnvolle Erweiterung: unterschiedliche Geschäftszeiten, Feiertage oder vertraglich vereinbarte Reaktionszeiten.
Danach Playbooks und Templates: vorgefertigte Eskalationsschritte, empfohlene Stakeholder und Nachrichtenvorlagen, die Antworten konsistent machen.
Wenn Assignment zum Flaschenhals wird, überlegen Sie Skills-basiertes Routing und On-Call-Pläne. Halten Sie die erste Iteration einfach: wenige Skills, Default-Fallback-Owner und klare Override-Kontrollen.
Auto-Eskalation kann bei bestimmten Signalen triggern (Severity-Änderungen, Keywords, Sentiment, wiederholte Kontakte). Beginnen Sie mit „Vorgeschlagener Eskalation" (Prompt) bevor Sie automatische Eskalation aktivieren, und protokollieren Sie jeden Trigger-Grund für Vertrauen und Auditierbarkeit.
Fügen Sie erforderliche Felder vor Eskalation hinzu (Impact, Severity, Customer Tier) und Genehmigungsschritte für hochkritische Eskalationen. Das reduziert Rauschen und hält Reporting akkurat.
Wenn Sie Automationsmuster erkunden wollen, sehen Sie /blog/workflow-automation-basics. Beim Abgleichen von Scope mit Packaging prüfen Sie /pricing.
Beginnen Sie mit einer Ein-Satz-Definition, der alle zustimmen (plus ein paar Beispiele). Führen Sie explizit Non-Beispiele auf (Routine-Tickets, interne Aufgaben), damit v1 nicht zu einem allgemeinen Ticketing-System wird.
Schreiben Sie dann 2–4 Erfolgsmetriken, die Sie sofort messen können, z. B. SLA-Verletzungsrate, Zeit in jeder Phase oder Anzahl der Reassignments.
Wählen Sie Ergebnisse, die operative Verbesserungen abbilden, nicht nur Feature-Fertigkeiten. Praktische v1-Metriken sind:
Wählen Sie eine kleine Menge, die Sie aus den Day-One-Timestamps berechnen können.
Verwenden Sie eine kleine gemeinsame Menge von Phasen mit klaren Ein-/Austrittskriterien, zum Beispiel:
Schreiben Sie fest, was zutreffen muss, um eine Phase zu betreten bzw. zu verlassen. Das verhindert Mehrdeutigkeiten wie „Resolved, aber wartet noch auf den Kunden”.
Erfassen Sie die Mindestereignisse, die nötig sind, um die Timeline zu rekonstruieren und SLA-Entscheidungen zu begründen:
Wenn Sie nicht erklären können, wie ein Timestamp verwendet wird, sammeln Sie ihn in v1 nicht.
Modellieren Sie jeden Meilenstein als Timer mit:
start_atdue_at (berechnet)paused_at und pause_reason (optional)completed_atSpeichern Sie außerdem die Regel, die erzeugt hat (Policy + Kalender + Grund). Das macht Audits und Streitfälle deutlich einfacher, als nur die endgültige Deadline zu speichern.
Speichern Sie alle Zeitstempel in UTC, halten Sie jedoch eine Fall-/Kunden-Zeitzone für die Anzeige und das Nutzerverständnis. Modellieren Sie SLA-Kalender explizit (24/7 vs. Geschäftszeiten, Feiertage, regionsspezifische Zeitpläne).
Testen Sie Randfälle wie Sommer-/Winterzeitwechsel, Fälle, die kurz vor Geschäftsschluss erstellt werden, und „Pause beginnt genau an der Grenze”.
Halten Sie v1-Rollen einfach und an realen Arbeitsabläufen orientiert:
Fügen Sie Scoping-Regeln (Team/Region/Account) und feldbezogene Kontrollen für sensible Daten wie interne Notizen und PII hinzu.
Konzentrieren Sie sich zuerst auf die „täglichen" Bildschirme:
Optimieren Sie für schnelles Scannen und reduzieren Sie Kontextwechsel—schnelle Aktionen dürfen nicht in Menüs versteckt sein.
Starten Sie mit einer kleinen Menge hochsignalisierender Benachrichtigungen:
Wählen Sie 1–2 Kanäle für v1 (meist In-App + E-Mail) und fügen Sie eine Eskalationsmatrix mit klaren Schwellenwerten hinzu (T–2h, T–0h, T+1h). Verhindern Sie Fatigue durch Dedupe, Batching und Quiet Hours und machen Sie Acknowledge/Snooze auditierbar.
Integrieren Sie nur das, was Timelines akkurat hält:
Wenn Sie bidirektional synchronisieren, legen Sie pro Feld eine Quelle der Wahrheit und Konfliktregeln fest (vermeiden Sie „last write wins“). Veröffentlichen Sie einen minimalen, versionierten API-Vertrag, damit Integrationen stabil bleiben. Für mehr zu Automationsmustern siehe /blog/workflow-automation-basics; für Packaging-Überlegungen siehe /pricing.
due_at