Was diese Web‑App lösen sollte
Die meisten Teams scheitern beim Experimentieren nicht an fehlenden Ideen, sondern daran, dass Ergebnisse verstreut sind. Ein Produkt hat Diagramme im Analytics‑Tool, ein anderes eine Tabelle, ein drittes eine Präsentation mit Screenshots. Einige Monate später kann niemand einfache Fragen wie „Haben wir das schon getestet?“ oder „Welche Version hat gewonnen — nach welcher Metrikdefinition?“ beantworten.
Das Kernproblem: fragmentierte Ergebnisse und inkonsistente Wahrheit
Eine Experiment‑Tracking‑Web‑App sollte zentralisieren, was getestet wurde, warum, wie gemessen wurde und was passiert ist — über mehrere Produkte und Teams hinweg. Ohne das verschwenden Teams Zeit mit dem Nachbauen von Reports, streiten über Zahlen und wiederholen alte Tests, weil Learnings nicht durchsuchbar sind.
Für wen das gedacht ist (und was jede Gruppe braucht)
Das ist nicht nur ein Analysten‑Tool.
- Product Manager brauchen einen schnellen Überblick zu Ergebnissen, Confidence und Entscheidungsstatus.
- Analysten brauchen einen verlässlichen Ort, um Annahmen, Metrikdefinitionen und Caveats zu dokumentieren.
- Engineer brauchen Klarheit, welche Feature‑Flags, Varianten und Rollout‑Bedingungen galten.
- Führung braucht eine konsistente Sicht auf den Impact über Produkte hinweg, ohne maßgeschneiderte Decks.
Optimale Outcomes
Ein guter Tracker schafft Geschäftswert durch:
- schnellere Entscheidungen (weniger Zeit beim Suchen von Links und Genehmigungen)
- weniger Reporting‑Fehler (eine Quelle der Wahrheit für „die finalen Zahlen“)
- geteilte Learnings (durchsuchbare Historie von Erfolgen, Misserfolgen und neutralen Tests)
Klare Abgrenzung des Scopes
Seien Sie explizit: Diese App dient primär dem Tracking und Reporting von Experimentergebnissen — nicht dem vollständigen Ausführen von Experimenten. Sie kann zu bestehenden Tools verlinken (Feature‑Flagging, Analytics, Data Warehouse), während sie das strukturierte Protokoll des Experiments und dessen finale, abgestimmte Interpretation verwaltet.
Anforderungen: der minimale brauchbare Experiment‑Tracker
Ein MVP‑Tracker sollte zwei Fragen ohne Suchen beantworten: was testen wir und was haben wir gelernt. Beginnen Sie mit einer kleinen Menge an Entitäten und Feldern, die produktübergreifend funktionieren, und erweitern Sie nur, wenn Teams echten Schmerz spüren.
Kern‑Entitäten
Halten Sie das Datenmodell so einfach, dass es von allen Teams gleich genutzt wird:
- Product: die Oberfläche (App/Website/API), auf der die Änderung ausgerollt wird.
- Experiment: eine Hypothese und eine Entscheidung.
- Variant: Control und eine oder mehrere Treatments.
- Metric: benannte Messgröße mit Owner und Definition.
- Segment: optionale Audiences (New Users, Paid Users, Region) für Reports.
Experiment‑Typen (klein anfangen, flexibel bleiben)
Unterstützen Sie die häufigsten Muster ab Tag eins:
- A/B‑Tests (Control vs Treatment)
- Multivariate Tests (mehrere Varianten)
- Feature‑Flag‑Rollouts (prozentuale Exposure)
Selbst wenn Rollouts anfangs keine formalen Statistiken nutzen, hilft das gemeinsame Tracking, dass Teams nicht dieselben „Tests“ ohne Dokumentation wiederholen.
Minimale Felder für jedes Experiment
Bei der Erstellung fordern Sie nur, was nötig ist, um den Test später zu interpretieren:
- Hypothese (Welche Änderung, für wen, warum)
- Owner (eine verantwortliche Person)
- Start/End‑Daten (geplant und tatsächlich)
- Targeting (Eligibility‑Regeln) und Allocation (Traffic‑Split)
- Links zu Rollout/Flag, Ticket oder Spec (relative URLs wie /projects/123)
Erfolgskriterien und Entscheidungsstatus
Machen Sie Ergebnisse vergleichbar, indem Sie Struktur erzwingen:
- Primäre Metrik (Hauptmaß für Erfolg)
- Guardrails (Metriken, die nicht verschlechtern dürfen)
- Entscheidungsstatus: proposed → running → analyzed → shipped/rolled back → archived
Wenn Sie nur dies bauen, können Teams Experimente zuverlässig finden, Setup verstehen und Ergebnisse protokollieren — noch bevor Sie erweiterte Analytics oder Automatisierung hinzufügen.
Datenmodell, das über Produkte hinweg funktioniert
Ein produktübergreifender Tracker lebt oder stirbt am Datenmodell. Wenn IDs kollidieren, Metriken driftet oder Segmente inkonsistent sind, kann Ihr Dashboard „richtig“ aussehen und trotzdem eine falsche Geschichte erzählen.
Wählen Sie stabile Identifikatoren (und halten Sie sich daran)
Starten Sie mit einer klaren ID‑Strategie:
- product_id: stabil bei Umbenennungen (verwenden Sie keine Anzeigenamen als Keys)
- experiment_key: menschenlesbarer Slug (z. B.
checkout_free_shipping_banner) plus eine unveränderliche experiment_id
- variant_key: stabile Labels wie
control, treatment_a
So können Sie Ergebnisse produktübergreifend vergleichen, ohne zu raten, ob „Web Checkout“ und „Checkout Web" dasselbe sind.
Kern‑Collections/Tabellen
Halten Sie die Kern‑Entities klein und explizit:
- experiments: product_id, hypothesis, primary_metric_def_id, start/end, status
- variants: experiment_id, variant_key, traffic_split
- assignments: experiment_id, user_id (oder anonymous_id), variant_key, assigned_at
- metric_defs: Metrikname, Zähler/Nenner‑Logik, Einheit (user/session/order), Owner
- results: experiment_id, metric_def_id, time_window_id, segment_id, computed_at, effect, uncertainty
Auch wenn die Berechnung extern stattfindet, ermöglicht das Speichern der Outputs schnelle Dashboards und eine verlässliche Historie.
Zeitfenster und Versionierung
Metriken und Experimente sind nicht statisch. Modellieren Sie:
- time windows (z. B. „erste 7 Tage nach Zuweisung“, „Kalenderwochen")
- versionierte Metrikdefinitionen: Wenn sich die Berechnung einer Metrik ändert, erstellen Sie eine neue Version statt die alte zu editieren
Das verhindert, dass letzte Monats‑Experimente sich ändern, wenn jemand KPI‑Logik aktualisiert.
Segmente und Audit‑Trail
Planen Sie für konsistente Segmente über Produkte hinweg: Land, Gerät, Tarif, Neu vs. Wiederkehrend.
Fügen Sie schließlich einen Audit‑Trail hinzu, der festhält, wer was wann geändert hat (Statusänderungen, Traffic‑Splits, Metrikdefinitionen). Das ist essenziell für Vertrauen, Reviews und Governance.
Metrikdefinitionen und konsistente Berechnungen
Wenn Ihr Tracker die Metrik‑Mathematik falsch (oder inkonsistent) handhabt, ist das „Ergebnis“ nur eine Meinung mit Chart. Der schnellste Weg, das zu verhindern, ist, Metriken als gemeinsame Produkt‑Assets zu behandeln — nicht als Ad‑hoc‑Query‑Schnipsel.
Bauen Sie einen kanonischen Metrik‑Katalog
Erstellen Sie einen Metrik‑Katalog als einzige Quelle der Wahrheit für Definitionen, Berechnungslogik und Ownership. Jeder Eintrag sollte beinhalten:
- Eine Plain‑English‑(bzw. Plain‑German)‑Definition (welche Entscheidung sie unterstützt)
- Einen Owner (Person/Team verantwortlich für Änderungen)
- Die exakte Formel und benötigte Events/Felder
- Inklusions/Exklusionsregeln (z. B. interne Nutzer, Bots, erstattete Bestellungen)
- Gültige Aggregationslevel und unterstützte Produkte
Halten Sie den Katalog dort, wo Leute arbeiten (z. B. verlinkt aus dem Experiment‑Erstellungsfluss) und versionieren Sie ihn, damit Sie historische Ergebnisse erklären können.
Standardisieren Sie Aggregationslevel
Entscheiden Sie vorher, welche „Analyse‑Einheit“ jede Metrik nutzt: pro Nutzer, pro Session, pro Account oder pro Bestellung. Eine Conversion‑Rate „pro Nutzer“ kann sich von „pro Session“ unterscheiden, obwohl beide korrekt sind.
Speichern Sie die Aggregationswahl mit der Metrikdefinition und verlangen Sie sie bei der Experiment‑Einrichtung. Lassen Sie nicht zu, dass jedes Team willkürlich eine Einheit wählt.
Verzögerte Conversions und Attribution behandeln
Viele Produkte haben Conversion‑Fenster (z. B. Anmeldung heute, Kauf innerhalb von 14 Tagen). Definieren Sie Attribution‑Regeln konsistent:
- Wann startet die Uhr (Exposure‑Zeit, erster Besuch, Zuweisungszeit)?
- Was zählt als Conversion, wenn ein Nutzer mehrfach exponiert wird?
- Wie handhaben Sie geräteübergreifende oder produktübergreifende Journeys?
Machen Sie diese Regeln im Dashboard sichtbar, damit Leser wissen, was sie sehen.
Rohzählungen und berechnete Statistiken speichern
Für schnelle Dashboards und Auditierbarkeit speichern Sie beides:
- Rohzählungen (Exposures, Converters, Revenue‑Summen, Varianz‑Inputs)
- Berechnete Statistiken (Lift, Konfidenzintervalle, p‑Werte)
Das ermöglicht schnelle Darstellung und gleichzeitig das Nachrechnen, wenn Definitionen sich ändern.
Namenskonventionen vermeiden Metrik‑Sprawl
Führen Sie eine Namenskonvention ein, die Bedeutung kodiert (z. B. activation_rate_user_7d, revenue_per_account_30d). Erzwingen Sie eindeutige IDs, erlauben Sie Aliase und markieren Sie near‑duplicates beim Anlegen einer Metrik, um den Katalog sauber zu halten.
Datenerfassung: Events, Pipelines und Qualitätsprüfungen
Ihr Experiment‑Tracker ist nur so glaubwürdig wie die Daten, die er einliest. Das Ziel ist, für jedes Produkt zuverlässig zwei Fragen beantworten zu können: Wer wurde welcher Variante ausgesetzt, und was hat er anschließend getan? Alles Weitere — Metriken, Statistik, Dashboards — baut darauf auf.
Wählen Sie einen Ingestionsansatz
Die meisten Teams wählen eines der Muster:
- Event‑Stream (near real‑time): Gut für schnelle Einsichten und schnelles Debugging. Erfordert mehr Engineering‑Reife.
- Täglicher Batch: Einfacher zu betreiben und günstiger. Am besten, wenn Entscheidungen nicht stündlich getroffen werden.
- Hybrid: Streamen Sie Exposures und kritische Events (so validieren Sie Zuweisungen schnell), batchen Sie den Rest für Vollständigkeit und Kostenkontrolle.
Egal was Sie wählen, standardisieren Sie das minimale Event‑Set produktübergreifend: exposure/assignment, zentrale Conversion‑Events und genug Kontext zum Joinen (user_id/device_id, timestamp, experiment_id, variant).
Produkt‑Events auf Metriken abbilden (und Vollständigkeit validieren)
Definieren Sie eine klare Abbildung von Roh‑Events zu den Metriken, die Ihr Tracker berichtet (z. B. purchase_completed → Revenue, signup_completed → Activation). Pflegen Sie diese Abbildung pro Produkt, aber halten Sie die Namen über Produkte hinweg konsistent, damit Ihr A/B‑Dashboard „wie‑mit‑wie“ vergleicht.
Validieren Sie Vollständigkeit früh:
- Bestätigen Sie, dass jede Exposure eine Experiment‑ID und Variant enthält.
- Stellen Sie sicher, dass Conversion‑Events die gleichen Identitätsfelder wie Exposures für Joins enthalten.
- Achten Sie auf Event‑Dropoffs zwischen Client, Server und Warehouse (Mobile‑SDKs sind häufige Schuldige).
Automatisierte Data‑Quality‑Checks
Bauen Sie Prüfungen, die bei jedem Load laufen und laut Fehler melden:
- Missing exposure events: Conversions ohne vorhergehende Exposure (häufig Instrumentationslücken oder Identitätsmismatches).
- Skewed allocations: Varianten erhalten 70/30 statt erwarteter 50/50 (kann Targeting‑Bugs anzeigen).
- Timestamp‑Sanity: Exposures nach Conversions oder große Verzögerungen durch Clock‑Issues.
Zeigen Sie diese Warnungen im App‑UI als Hinweise am Experiment an, nicht nur in Logs.
Backfills und Reprocessing
Pipelines ändern sich. Wenn Sie ein Instrumentationsproblem oder Dedupe‑Bug fixen, müssen historische Daten reprocessed werden, damit Metriken konsistent bleiben.
Planen Sie für:
- Versionierte Transformationen (damit klar ist, welche Logik welches Ergebnis erzeugte)
- Sichere Backfills (Scope begrenzt nach Datum/Produkt/Experiment)
- Einen Audit‑Trail der Neukalkulation
Integrationen dokumentieren
Behandeln Sie Integrationen als Produktfeature: dokumentieren Sie unterstützte SDKs, Event‑Schemas und Troubleshooting‑Schritte. Wenn Sie einen Docs‑Bereich haben, verlinken Sie ihn als relative Pfade wie /docs/integrations.
Statistik und Ergebnisberechnung, der man trauen kann
Mehr Build-Zeit erhalten
Verdienen Sie Credits, indem Sie teilen, was Sie bauen, oder Teammitglieder an Koder.ai verweisen.
Wenn Leute den Zahlen nicht vertrauen, nutzen sie den Tracker nicht. Das Ziel ist nicht, mit Mathematik zu beeindrucken, sondern Entscheidungen wiederholbar und verteidigbar zu machen.
Wählen Sie ein statistisches „Dialekt" und bleiben Sie dabei
Entscheiden Sie, ob Ihre App frequentistische Ergebnisse (p‑Werte, Konfidenzintervalle) oder bayessche Ergebnisse (Wahrscheinlichkeit der Verbesserung, glaubwürdige Intervalle) anzeigen wird. Beides funktioniert, aber ein Mischen führt zu Verwirrung.
Eine praktische Regel: Wählen Sie den Ansatz, den Ihre Organisation bereits versteht, und standardisieren Sie Terminologie, Defaults und Schwellen.
Definieren Sie genau, was die UI zeigt
Mindestens sollte die Ergebnisseansicht unmissverständlich folgende Punkte zeigen:
- Lift (absolut und/oder relativ) gegenüber Control
- Intervall (Konfidenz‑ oder Credible Interval) als Bereich, nicht nur Punktwert
- Beweisstärke (p‑Wert für frequentistische, Wahrscheinlichkeit des Übertreffens für bayessche)
Zeigen Sie außerdem das Analysefenster, die gezählten Einheiten (Users, Sessions, Orders) und die verwendete Metrikversionsnummer. Diese Details machen den Unterschied zwischen konsistentem Reporting und endlosen Debatten.
Multiple Comparisons und „Peeking"‑Policies
Wenn Teams viele Varianten, viele Metriken oder tägliche Checks haben, steigen False‑Positives. Ihre App sollte eine Policy kodieren, statt es jedem Team freizulassen:
- Multiple Comparisons: entscheiden Sie, ob Sie adjustieren (z. B. FDR) oder Ergebnisse klar als „unadjusted exploratory" markieren.
- Repeated Peeking: entweder (1) entmutigen Sie es durch ein fixes Enddatum und „finalized“ Status oder (2) unterstützen Sie sequenzielle Methoden und zeigen „safe‑to‑stop“ Hinweise.
Guardrails, die häufige Fehler fangen
Fügen Sie automatisierte Flags direkt neben Ergebnissen hinzu:
- Sample Ratio Mismatch (SRM): Warnung bei Abweichung der Traffic‑Split‑Erwartung
- Anomaly‑Detection: markiert plötzliche Einbrüche/Spitzen in Traffic, Conversions oder Revenue, die auf Tracking‑Brüche, Ausfälle oder Bot‑Traffic hinweisen können
Neben den Zahlen sollte eine kurze Erklärung für nicht‑technische Leser stehen, z. B.: „Der beste Schätzer ist +2,1% Lift, aber der wahre Effekt könnte plausibel zwischen -0,4% und +4,6% liegen. Wir haben noch nicht genügend Evidenz, um einen Gewinner zu deklarieren."
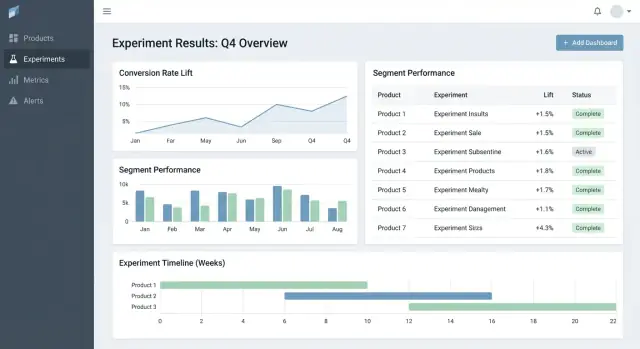
UX und Dashboards für schnelle Entscheidungen
Gute Experiment‑Tools helfen Menschen zwei Fragen schnell zu beantworten: Worauf sollte ich als Nächstes schauen? und Was sollen wir tun? Die UI sollte Kontext nicht verstecken und den Entscheidungsstatus klar machen.
Schlüssel‑Seiten zur Verankerung des Workflows
Starten Sie mit drei Seiten, die die meiste Nutzung abdecken:
- Experiments list: eine sortierbare Queue für die ganze Organisation (oder pro Produkt).
- Experiment detail: die Single Source of Truth für Setup, Ergebnisse und Entscheidung.
- Product overview: Rollup aktiver Tests, jüngster Entscheidungen und Metrik‑Health für ein Produkt.
Auf List‑ und Product‑Seiten sollten Filter schnell und persistent sein: Product, Owner, Datumsbereich, Status, Primärmetrik und Segment. Nutzer sollten in Sekunden zu „Checkout‑Experimente, Owner = Maya, laufend diesen Monat, primäre Metrik = Conversion, Segment = New Users“ filtern können.
Entscheidungsstatus, dem man vertrauen kann
Behandeln Sie Status als kontrolliertes Vokabular, nicht als Freitext:
Draft → Running → Stopped → Shipped / Rolled back
Zeigen Sie den Status überall (Listenzeilen, Detail‑Header, Share‑Links) und protokollieren Sie, wer ihn warum geändert hat. So verhindern Sie „stille Launches“ und unklare Outcomes.
Eine Ergebnis‑Tabelle, die die Entscheidung deutlich macht
Im Experiment‑Detail führen Sie mit einer kompakten Ergebnistabelle pro Metrik:
- Baseline
- Variante
- Lift
- Unsicherheit (Konfidenz‑ oder Credible Interval)
- Notizen (z. B. Instrumentation Caveats, Segment‑Eigenheiten)
Halten Sie fortgeschrittene Charts hinter „Mehr Details“, damit Entscheider nicht überfordert werden.
Teilen und Exportieren ohne Kontrollverlust
Bieten Sie CSV‑Export für Analysten und teilbare Links für Stakeholder, aber erzwingen Sie Zugriffskontrolle: Links müssen Rollen‑ und Produktberechtigungen respektieren. Eine einfache „Link kopieren"‑Taste plus „CSV exportieren" deckt die meisten Kollaborationsfälle ab.
Berechtigungen, Datenschutz und Governance
Mobile Ansicht hinzufügen
Erstellen Sie eine Flutter-Begleitapp für schnelle Auswertungen und Statusprüfungen.
Wenn Ihr Tracker mehrere Produkte umfasst, sind Zugriffskontrolle und Auditierbarkeit keine Option — sie sind Voraussetzung. Sie machen das Tool sicher über Teams hinweg und glaubwürdig bei Reviews.
Rollenbasierte Zugriffskontrolle (RBAC)
Starten Sie mit einem einfachen Rollensatz und halten Sie ihn app‑weit konsistent:
- Viewer: Nur‑Lesen für Experimente, Ergebnisse und Dashboards
- Editor: Erstellen/Bearbeiten von Experimenten, Uploads von Dokumenten, Statusänderungen
- Admin: Nutzer, Permissions, Metrikdefinitionen, Retention‑Regeln und Integrationen verwalten
Centralisieren Sie RBAC‑Entscheidungen (eine Policy‑Ebene), damit UI und API die gleichen Regeln durchsetzen.
Produkt‑level und Zeilen‑level Berechtigungen
Viele Organisationen brauchen produktgebundene Sichtbarkeit: Team A sieht Produkt A, nicht Produkt B. Modellieren Sie das explizit (z. B. user ↔ product Memberships) und sorgen Sie dafür, dass jede Abfrage nach Produkt gefiltert wird.
Für sensible Fälle (Partnerdaten, regulierte Segmente) fügen Sie row‑level restrictions zu Produkt‑Scoping hinzu. Ein pragmatischer Ansatz ist, Experimente oder Ergebnis‑Slices mit einer Sensitivitätsstufe zu taggen und zusätzliche Berechtigungen für die Ansicht zu verlangen.
Audit‑Trail: Änderungen + Zugriffe
Protokollieren Sie getrennt:
- Change logs: Wer hat ein Experiment, eine Metrikdefinition oder eine Entscheidung editiert — was wurde wann geändert
- Access logs: Wer hat Ergebnisse angesehen oder exportiert (wichtig für sensible Experimente)
Stellen Sie die Änderungs‑Historie im UI dar und halten Sie tiefere Logs für Untersuchungen vor.
Aufbewahrungs‑ und Löschregeln
Definieren Sie Retentionsregeln für:
- Experiment‑Metadaten (Hypothese, Owner, Daten, Entscheidungsnotizen)
- Berechnete Ergebnisse (Effektgrößen, Intervalle, Signifikanzflags)
Machen Sie Retention pro Produkt und Sensitivität konfigurierbar. Wenn Daten gelöscht werden müssen, behalten Sie einen minimalen Tombstone‑Datensatz (ID, Löschzeit, Grund), um Reporting‑Integrität zu wahren, ohne sensible Inhalte zu behalten.
Workflow‑Funktionen: von Idee zur Lernbibliothek
Ein Tracker wird wirklich nützlich, wenn er den kompletten Experiment‑Lifecycle abdeckt, nicht nur den finalen p‑Wert. Workflow‑Funktionen verwandeln verstreute Docs, Tickets und Charts in einen wiederholbaren Prozess und erleichtern das Wiederverwenden von Learnings.
Lifecycle: Idee → Review → Run → Post‑Mortem
Modellieren Sie Experimente als Sequenz von Zuständen (Draft, In Review, Approved, Running, Ended, Readout Published, Archived). Jeder Zustand braucht klare Exit‑Kriterien, damit Experimente nicht live gehen ohne Essentials wie Hypothese, Primärmetrik und Guardrails.
Genehmigungen müssen nicht schwerfällig sein. Ein einfacher Reviewer‑Step (z. B. Produkt + Data) plus Audit‑Trail, wer was wann genehmigt hat, kann vermeidbare Fehler verhindern. Nach Abschluss verlangen Sie ein kurzes Post‑Mortem, bevor ein Experiment als „Published" markiert werden kann, um Ergebnisse und Kontext zu erfassen.
Templates, die das Denken standardisieren
Bieten Sie Templates für:
- Experiment‑Brief (Ziel, Hypothese, Zielgruppe, Erfolgsmessung, Guardrails, Rollout‑Plan)
- Analyse‑Notizen (Datenquellen, Ausschlüsse, Sanity‑Checks, Interpretation, Risiken)
Templates reduzieren das „Blank‑Page“‑Problem und beschleunigen Reviews, weil jeder weiß, wo zu schauen ist. Halten Sie sie pro Produkt editierbar, behalten Sie aber einen gemeinsamen Kern bei.
Learnings: alles verlinken, durchsuchbar halten
Experimente leben selten isoliert — Nutzer brauchen Kontext. Erlauben Sie Anhänge zu Tickets/Specs und zugehörigen Writeups (z. B. /blog/how-we-define-guardrails, /blog/experiment-analysis-checklist). Speichern Sie strukturierte „Learning“‑Felder wie:
- Was geändert wurde (Entscheidung)
- Was wir gelernt haben (Insight)
- Nächste Schritte (Follow‑up)
Alerts für Guardrails und veränderte Ergebnisse
Unterstützen Sie Benachrichtigungen, wenn Guardrails regressieren (z. B. Error‑Rate, Stornierungen) oder wenn sich Ergebnisse nach späten Daten oder Metrik‑Neuberechnung signifikant ändern. Machen Sie Alerts handlungsorientiert: zeigen Sie Metrik, Threshold, Zeitraum und einen Owner zum Bestätigen/Eskalieren.
Bibliothek‑Ansicht zum Wiederverwenden
Bieten Sie eine Bibliothek, die nach Produkt, Feature‑Area, Audience, Metrik, Outcome und Tags filtert (z. B. „pricing“, „onboarding“, „mobile"). Fügen Sie „ähnliche Experimente“‑Vorschläge basierend auf geteilten Tags/Metriken hinzu, damit Teams nicht denselben Test wiederholen, sondern auf früheren Learnings aufbauen.
Architektur und Tech‑Stack‑Optionen
Sie brauchen keinen „perfekten" Stack, aber klare Grenzen: wo die Daten leben, wo Berechnungen laufen und wie Teams Ergebnisse konsistent abrufen.
Praktischer Baseline‑Stack
Für viele Teams ist ein einfaches, skalierbares Setup:
- Frontend: React (oder Vue) für Dashboards und Workflows
- Backend API: Node.js/Express, Python/FastAPI oder Java/Spring — wählen Sie, was Ihr Team pflegen kann
- Datenbank: Postgres für App‑Daten (Experimente, Metrikdefinitionen, Berechtigungen)
- Analytics‑Warehouse: BigQuery/Snowflake/Redshift für Event‑Daten und schwere Aggregationen
Diese Aufteilung hält transaktionale Workflows schnell, während das Warehouse großskalige Berechnungen übernimmt.
Wenn Sie die UI‑Workflow‑Prototypen schnell testen wollen (Experiments‑Liste → Detail → Readout), kann eine Low‑Code/assisted‑development Plattform wie Koder.ai helfen, eine funktionierende React+Backend‑Basis aus einer Chat‑Spezifikation zu generieren. Das ist nützlich, um Entities, Formulare, RBAC‑Gerüst und auditfähige CRUD‑Aktionen schnell bereitzustellen und dann die Datenverträge mit dem Analytics‑Team zu verfeinern.
Wo sollten Metrikberechnungen leben?
Drei Optionen:
- Warehouse‑first: SQL‑Modelle erzeugen Metriken und Experiment‑Result‑Tables. Die App liest primär.
- Backend‑Jobs: Worker berechnen Ergebnisse zeitgesteuert oder bei Änderungen.
- Hybrid: Canonical Aggregationen im Warehouse, Backend für Post‑Processing (Formatierung, Guardrails, Caching).
Warehouse‑first ist oft am einfachsten, wenn Ihr Data‑Team schon vertrauenswürdige SQL‑Modelle besitzt. Backend‑schwer eignet sich bei niedriger Latenz oder spezieller Logik, erhöht aber die Komplexität.
Experiment‑Dashboards wiederholen oft dieselben Queries. Planen Sie:
- Precompute Rollups (tägliche Metrik‑Aggregates pro Experiment/Variante/Segment)
- Cache teure Reads auf API‑Ebene (z. B. Redis) mit klaren Invalidation‑Regeln
- Verwenden Sie materialized views oder geplante Tabellen im Warehouse für gängige Dashboards
Multi‑Tenant vs Single‑Tenant
Wenn Sie viele Produkte/BU unterstützen, entscheiden Sie früh:
- Single‑tenant (geteiltes Schema): Leichter zu betreiben, erfordert aber strikte Permission‑Filterung
- Multi‑tenant: Separate Schemas/Projects pro Produkt für stärkere Isolation, mehr Overhead
Ein gängiger Kompromiss ist geteilte Infrastruktur mit starkem tenant_id‑Modell und erzwungener Row‑Level‑Access.
Definieren Sie die Kern‑APIs
Halten Sie die API‑Oberfläche klein: Endpoints für experiments, metrics, results, segments und permissions (plus audit‑freundliche Reads). So können Sie neue Produkte hinzufügen, ohne die Infrastruktur neu zu schreiben.
Testing, Monitoring und zuverlässiger Betrieb
Metrikkatalog einrichten
Erstellen Sie versionierte Metrikdefinitionen, damit Ergebnisse über die Zeit vergleichbar bleiben.
Ein Tracker ist nur nützlich, wenn Leute ihm vertrauen. Vertrauen entsteht durch diszipliniertes Testen, klares Monitoring und vorhersagbaren Betrieb — besonders wenn mehrere Produkte und Pipelines in dieselben Dashboards fließen.
Observability, wie Nutzer die App verwenden
Starten Sie mit strukturiertem Logging für jeden kritischen Schritt: Event‑Ingest, Assignment, Metrik‑Rollups, Ergebnisberechnung. Fügen Sie Identifikatoren wie product, experiment_id, metric_id und pipeline_run_id hinzu, damit Support ein Ergebnis zu seinen Inputs zurückverfolgen kann.
Ergänzen Sie mit System‑Metriken (API‑Latenz, Job‑Runtimes, Queue‑Depth) und Daten‑Metriken (Events verarbeitet, % späte Events, % durch Validierung gedroppt). Tracing über Services hilft bei Fragen wie „Warum fehlen in diesem Experiment die Daten von gestern?"
Daten‑Freshness‑Checks verhindern stille Fehler am schnellsten. Wenn ein SLA „täglich bis 9 Uhr" ist, überwachen Sie Freshness pro Produkt/Quelle und alarmieren bei:
- fehlender Partition
- stark abweichendem Event‑Volumen
- Rollup‑Jobs, die zwar laufen, aber 0 Zeilen produzieren
Automatisierte Tests: schützen Sie Daten und Mathematik
Erstellen Sie Tests auf drei Ebenen:
- Schema und Constraints: Pflichtfelder, Uniqueness (z. B. eine Zuweisung pro User/Experiment), Foreign Keys, valide Datumsbereiche
- Permissions: RBAC‑Tests (Viewer/Editor/Admin) und Produkt‑Scoping
- Result‑Math: Unit‑Tests für Lift, Konfidenzintervalle, Signifikanzflags und Edge‑Cases (kleine Samples, Null‑Nenner, mehrere Varianten)
Halten Sie ein kleines „golden dataset“ mit bekannten Outputs, um Regressionen zu fangen.
Deployments, Migrationen und historische Sicherheit
Behandeln Sie Migrationen als Teil des Betriebs: versionieren Sie Metrikdefinitionen und Ergebnis‑Logik, und vermeiden Sie das Überschreiben historischer Experimente, außer auf ausdrückliche Anforderung. Bieten Sie für notwendige Änderungen einen kontrollierten Backfill‑Pfad und dokumentieren Sie die Änderungen im Audit‑Trail.
Stellen Sie eine Admin‑Ansicht bereit, um eine Pipeline für ein spezifisches Experiment/Datum neu zu starten, Validierungsfehler zu inspizieren und Vorfälle mit Statusnotizen zu markieren. Verlinken Sie Incident‑Notizen direkt aus betroffenen Experimenten, damit Nutzer Verzögerungen verstehen und nicht auf unvollständigen Daten basieren.
Rollout‑Plan und typische Fallen
Das Ausrollen eines Experiment‑Trackers über Produkte ist weniger ein „Launch‑Tag“ als ein schrittweises Reduzieren von Ambiguität: was getrackt wird, wer es besitzt und ob die Zahlen mit der Realität übereinstimmen.
Praktische Rollout‑Abfolge
Starten Sie mit einem Produkt und einer kleinen, vertrauenswürdigen Metrikmenge (z. B. Conversion, Activation, Revenue). Ziel ist es, den End‑to‑End‑Workflow zu validieren — Experiment anlegen, Exposure erfassen, Outcomes joinen, Ergebnisse berechnen und Entscheidung dokumentieren — bevor Sie Komplexität hinzufügen.
Wenn das erste Produkt stabil ist, erweitern Sie produktweise mit einer vorhersehbaren Onboarding‑Cadence. Jedes neue Produkt sollte wie ein wiederholbarer Setup‑Schritt wirken, nicht wie ein individuelles Projekt.
Wenn Ihre Organisation dazu neigt, in langen „Platform Build“‑Zyklen stecken zu bleiben, erwägen Sie einen Zwei‑Spuren‑Ansatz: bauen Sie durable Data Contracts (Events, IDs, Metrikdefinitionen) parallel zu einer dünnen Applikationsschicht. Teams nutzen manchmal Koder.ai, um diese dünne Schicht schnell bereitzustellen — Formulare, Dashboards, Berechtigungen und Export — und härten die Lösung dann mit wachsender Adoption aus (inkl. Source‑Code‑Export und iterativen Rollbacks via Snapshots bei sich ändernden Anforderungen).
Onboarding‑Checkliste für jedes neue Produkt
Verwenden Sie eine leichte Checkliste, um Produkte und Event‑Schemas konsistent einzubinden:
- Event‑Taxonomie und Namenskonventionen bestätigen (und wer sie ändern darf)
- Sicherstellen, dass Exposure‑Events existieren und eindeutig einem Nutzer zugeordnet werden können
- Metriken auf das Produkt‑Event‑Schema abbilden (inkl. Edge‑Cases wie Refunds)
- Backfill oder Parallel‑Run durchführen, um mit bestehender Analytics zu vergleichen
- Ownership für Experiment‑Setup, Datenvalidierung und finale Entscheidungsnotizen zuweisen
Zum Fördern der Adoption verlinken Sie „Next Steps“ aus Experiment‑Ergebnissen zu relevanten Produktbereichen (z. B. Pricing‑Experimente → /pricing). Halten Sie Links informativ und neutral — ohne implizite Schlussfolgerungen.
Adoption messen, um Reibung früh zu beheben
Messen Sie, ob das Tool der Standardort für Entscheidungen wird:
- Wöchentliche aktive Nutzer nach Rolle (PM, Analyst, Engineer)
- Erstellte und abgeschlossene Experimente
- Anteil mit ausgefüllten Entscheidungsnotizen
- Zeit vom Experiment‑Ende bis zur Entscheidungsdokumentation
Häufige Fallen
In der Praxis stolpern Rollouts oft über:
- inkonsistente Metrikdefinitionen über Produkte hinweg (gleicher Name, andere Berechnung)
- fehlende oder fehlerhafte Exposure‑Erfassung → verzerrte Ergebnisse
- unklare Ownership bei Validierung und Sign‑off → "Zombie"‑Experimente
- stille Schemaänderungen, die Trends brechen, ohne dass jemand es bemerkt
- zu frühes Skalieren auf viele Metriken, bevor der Kernworkflow vertraut ist