02. Aug. 2025·6 Min
Feature‑Flags für KI‑basierte Apps: riskante Änderungen sicher ausliefern
Lerne Feature‑Flags für KI‑basierte Apps: ein einfaches Modell, Kohorten‑Targeting und sichere Rollouts, damit du riskante Änderungen schnell auslieferst, ohne Nutzer zu beeinträchtigen.
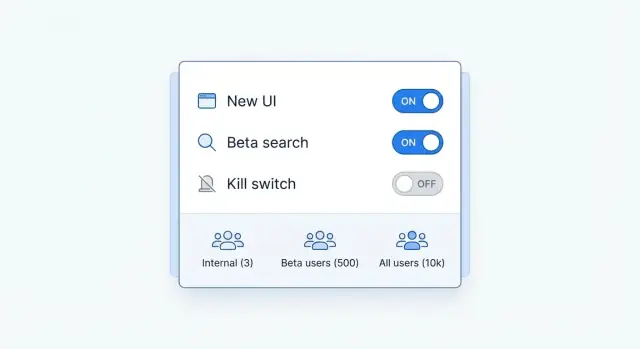
Warum Feature‑Flags wichtig sind, wenn du schnell mit KI baust
Ein Feature‑Flag ist ein einfacher Schalter in deiner App. Ist er an, bekommen Nutzer das neue Verhalten. Ist er aus, nicht. Du kannst den Code mit dem Schalter im Platz ausliefern und später entscheiden, wann (und für wen) du ihn einschaltest.
Diese Trennung ist beim schnellen Bauen mit KI noch wichtiger. KI‑unterstützte Entwicklung kann in Minuten große Änderungen erzeugen: ein neuer Screen, ein anderer API‑Aufruf, ein umgeschriebener Prompt oder ein Modellwechsel. Geschwindigkeit ist toll, aber sie erhöht auch die Wahrscheinlichkeit, etwas „größtenteils richtiges“ auszuliefern, das dennoch einen Kernpfad für echte Nutzer bricht.
Feature‑Flags trennen zwei Aktionen, die oft vermischt werden:
- Code ausliefern: eine neue Version deployen.
- Feature aktivieren: Nutzern erlauben, das Ausgelieferte wirklich zu verwenden.
Die Lücke dazwischen ist dein Sicherheits‑Puffer. Wenn etwas schiefgeht, schaltest du den Flag aus (Not‑Aus), ohne ein vollständiges Release zurückrollen zu müssen.
Flags sparen Zeit und Stress an vorhersehbaren Stellen: neue Nutzerflüsse (Signup, Onboarding, Checkout), Preis‑ und Planänderungen, Prompt‑ und Modellupdates sowie Performance‑Arbeiten wie Caching oder Hintergrundjobs. Der eigentliche Gewinn ist kontrollierte Exposition: teste eine Änderung zuerst mit einer kleinen Gruppe, vergleiche die Ergebnisse und skaliere erst bei guten Metriken.
Wenn du auf einer Vibe‑Coding‑Plattform wie Koder.ai baust, wird diese Geschwindigkeit sicherer, weil jede „schnelle Änderung“ einen Aus‑Schalter und einen klaren Plan dafür hat, wer sie zuerst sieht.
Ein einfaches Flag‑Modell, das du tatsächlich warten kannst
Ein Flag ist ein Laufzeit‑Schalter. Es ändert Verhalten, ohne dass du einen neuen Build ausliefern musst, und gibt dir einen schnellen Weg zurück, falls etwas schiefgeht.
Die einfachste Regel für Wartbarkeit: verteile Flag‑Prüfungen nicht überall. Wähle einen Entscheidungspunkt pro Feature (oft nahe beim Routing, an einer Service‑Grenze oder an einem einzigen UI‑Einstieg) und halte den Rest des Codes sauber. Wenn derselbe Flag in fünf Dateien auftaucht, ist die Feature‑Grenze meist nicht klar.
Hilfreich ist außerdem die Trennung von:
- Kann aktiviert werden (Eligibility): Plan, Region, Gerätetyp, Account‑Alter, interne Tester.
- Soll aktiviert werden (Rollout & Sicherheit): 0%, 10%, 50%, 100% sowie Pause oder Sofort‑Aus‑Kontrollen.
Halte Flags klein und fokussiert: ein Verhalten pro Flag. Brauchst du mehrere Änderungen, nutze mehrere Flags mit klaren Namen oder gruppiere sie hinter einem einzelnen Versions‑Flag (zum Beispiel onboarding_v2), das einen kompletten Pfad auswählt.
Ownership ist wichtiger, als viele Teams erwarten. Entscheide im Vorfeld, wer was umlegen darf und wann. Product sollte Rollout‑Ziele und Timing verantworten, Engineering Defaults und sichere Fallbacks, und Support sollte Zugriff auf einen echten Not‑Aus haben für kundenrelevante Probleme. Mache eine Person verantwortlich für das Aufräumen alter Flags.
Das passt gut, wenn du schnell in Koder.ai baust: Du kannst Änderungen sofort ausliefern, aber trotzdem steuern, wer sie sieht, und schnell zurückrollen, ohne die App umzubauen.
Die Flag‑Typen, die du am häufigsten brauchst
Die meisten Teams brauchen nur ein paar Muster.
Boolean‑Flags sind Standard: an oder aus. Ideal für „zeige das Neue“ oder „benutze den neuen Endpoint“. Wenn du wirklich mehr als zwei Optionen brauchst, nutze ein multivariates Flag (A/B/C) und halte die Werte aussagekräftig (z. B. control, new_copy, short_form), damit Logs lesbar bleiben.
Manche Flags sind temporäre Rollout‑Flags: du nutzt sie, um etwas Riskantes zu liefern, validierst es und entfernst dann das Flag. Andere sind permanente Konfigurations‑Flags, etwa SSO für einen Workspace aktivieren oder eine Storage‑Region wählen. Behandle permanente Konfiguration wie Produkt‑Einstellungen mit klarer Verantwortung und Dokumentation.
Wo du das Flag auswertest, ist wichtig:
- Serverseitige Flags sind sicherer, weil die Entscheidung im Backend (z. B. einer Go‑API) fällt und der Client nur das Ergebnis erhält.
- Clientseitige Flags (React oder Flutter) sind für risikoarme UI‑Änderungen in Ordnung, aber gehe davon aus, dass Nutzer Client‑Inhalte inspizieren und manipulieren können.
Verstecke niemals Geheimnisse, Preisregeln oder Berechtigungsprüfungen hinter client‑only Flags.
Ein Not‑Aus ist ein spezielles Boolean‑Flag für schnelles Rollback. Es sollte einen riskanten Pfad sofort deaktivieren, ohne Redeploy. Füge Not‑Aus‑Schalter für Änderungen hinzu, die Logins, Zahlungen oder Daten‑Schreibvorgänge beeinträchtigen könnten.
Wenn du schnell mit einer Plattform wie Koder.ai baust, sind serverseitige Flags und Not‑Aus‑Schalter besonders nützlich: du kannst schnell handeln und hast trotzdem einen sauberen „Aus“‑Knopf, wenn echte Nutzer an Randfällen hängen bleiben.
Wie du Kohorten zielgerichtet ansteuerst, ohne es zu verkomplizieren
Kohorten‑Targeting begrenzt das Risiko. Der Code ist ausgerollt, aber nur einige Personen sehen ihn. Ziel ist Kontrolle, nicht ein perfektes Segmentierungs‑System.
Beginne damit, eine Einheit der Auswertung zu wählen und dabei zu bleiben. Viele Teams entscheiden sich für Nutzer‑Level (ein Nutzer sieht die Änderung) oder Workspace/Account‑Level (jeder im Team sieht dasselbe). Workspace‑Targeting ist oft sicherer für gemeinsame Features wie Abrechnung, Berechtigungen oder Zusammenarbeit, weil gemischte Erlebnisse im selben Team vermieden werden.
Ein kleiner Satz von Regeln deckt die meisten Bedürfnisse ab: Nutzerattribute (Plan, Region, Gerät, Sprache), Workspace‑Targeting (Workspace‑ID, Org‑Tier, interne Accounts), Prozent‑Rollouts und einfache Allowlists/Blocklists für QA und Support.
Halte Prozent‑Rollouts deterministisch. Wenn ein Nutzer die Seite neu lädt, sollte er nicht zwischen alter und neuer UI hin‑ und herwechseln. Nutze einen stabilen Hash derselben ID überall (Web, Mobile, Backend), damit die Ergebnisse übereinstimmen.
Ein praktischer Default ist „Prozent‑Rollout + Allowlist + Not‑Aus“. Beispiel: in Koder.ai aktivierst du einen neuen Planning Mode‑Prompt‑Flow für 5% der Gratis‑Nutzer und allowlistest einige Pro‑Workspaces, damit Power‑User früh testen können.
Bevor du eine neue Targeting‑Regel hinzufügst, frage: Brauchen wir diesen Slice wirklich, soll er auf Nutzer‑ oder Workspace‑Level sein, wie schalten wir ihn schnell ab, wenn die Metriken fallen, und welche Daten nutzen wir (und ist das angemessen)?
Ein Schritt‑für‑Schritt‑Rollout‑Plan für riskante Änderungen
Rollout mit Compliance abgleichen
Rolle nach Regionen aus, wenn nötig, und deploye Apps im gewählten Land.
Riskante Änderungen sind nicht nur große Features. Ein kleiner Prompt‑Tweak, ein neuer API‑Aufruf oder eine geänderte Validierungsregel können echte Nutzerflüsse brechen.
Die sicherste Gewohnheit ist einfach: liefere den Code aus, aber halte ihn ausgeschaltet.
„Standardmäßig sicher“ bedeutet, der neue Pfad steht hinter einem deaktivierten Flag. Ist der Flag aus, bekommen Nutzer das alte Verhalten. So kannst du mergen und deployen, ohne alle zu zwingen, die Änderung zu nutzen.
Bevor du hochfährst, schreibe auf, wie „gut“ aussieht. Wähle zwei oder drei Signale, die du schnell prüfen kannst, z. B. Abschlussrate des geänderten Flows, Fehlerquote und Support‑Tickets, die dem Feature zugeordnet sind. Lege die Stoppregel im Voraus fest (z. B. „wenn sich Fehler verdoppeln, ausschalten").
Ein Rollout‑Plan, der schnell bleibt ohne Panik‑Releases:
- Mit ausgeschaltetem Flag ausliefern, und verifiziere, dass der alte Pfad in Produktion weiterhin funktioniert.
- Zuerst für das interne Team aktivieren, mit echten Accounts und realen Datenmustern.
- Eine kleine Beta‑Kohorte öffnen (oft 1–5%) und die Erfolgssignale beobachten.
- Schrittweise hochfahren (10%, 25%, 50%, 100%), mit Pausen, um Trends zu erkennen.
- Einen Not‑Aus bereit halten, damit du das Feature sofort deaktivieren kannst, falls etwas schief aussieht.
Mach Rollback langweilig. Das Deaktivieren des Flags sollte Nutzer ohne Redeploy in eine bekannte, funktionierende Erfahrung zurückversetzen. Wenn deine Plattform Snapshots und Rollback unterstützt (Koder.ai tut das), erstelle vor der ersten Exposure eine Momentaufnahme, um schnell wiederherstellen zu können.
Instrumentierung: wissen, was sich geändert hat und wer es gesehen hat
Flags sind nur sicher, wenn du schnell zwei Fragen beantworten kannst: Welches Erlebnis bekam ein Nutzer, und hat es geholfen oder geschadet? Das wird noch wichtiger, wenn kleine Prompt‑ oder UI‑Änderungen große Ausschläge verursachen können.
Beginne damit, Flag‑Auswertungen konsistent zu loggen. Du brauchst am ersten Tag kein komplexes System, aber konsistente Felder, damit du filtern und vergleichen kannst:
- Flag‑Key und Flag‑Version (oder Config‑Hash)
- Variante (an/aus oder A/B‑Wert)
- Kohorten‑Identifier (die Regel, die gematcht hat)
- Nutzer/Workspace‑ID (pseudonymisiert ist ok), plus Umgebung (prod, staging)
- Timestamp und Request‑ID (um Logs zu Fehlern zu joinen)
Verbinde das Flag dann mit einer kleinen Menge an Erfolgs‑ und Sicherheitsmetriken, die du stündlich beobachten kannst. Gute Defaults sind Fehlerquote, p95‑Latenz und eine Produktmetrik, die zur Änderung passt (Signup‑Abschluss, Checkout‑Conversion, Day‑1‑Retention).
Setze Alerts so, dass sie ein Pausieren auslösen, nicht Chaos. Beispiel: Wenn Fehler für die geflaggte Kohorte um 20% steigen, stoppe den Rollout und schalte den Not‑Aus. Wenn die Latenz einen festen Schwellenwert überschreitet, friere das aktuelle Prozentsatz‑Level ein.
Führe schließlich ein einfaches Rollout‑Log. Jedes Mal, wenn du Prozentsatz oder Targeting änderst, notiere wer, was und warum. Diese Gewohnheit hilft, wenn du schnell iterierst und mit Vertrauen zurückrollen musst.
Realistisches Beispiel: ein neues Onboarding‑Flow sicher ausrollen
Du willst ein neues Onboarding‑Flow ausrollen in einer App, die mit einem Chat‑getriebenen Builder wie Koder.ai gebaut wurde. Das neue Flow ändert die First‑Run‑UI, fügt einen „Erstelle dein erstes Projekt“‑Wizard hinzu und aktualisiert den Prompt, der Starter‑Code erzeugt. Es könnte die Aktivierung steigern, ist aber riskant: wenn es kaputt geht, bleiben neue Nutzer stecken.
Pack das gesamte neue Onboarding hinter ein Flag, z. B. onboarding_v2, und halte den alten Flow als Default. Starte mit einer klaren Kohorte: internes Team und eingeladene Beta‑Nutzer (z. B. Accounts mit beta=true).
Wenn das Beta‑Feedback gut aussieht, gehe zu einem Prozent‑Rollout über. Rolle bei 5% der neuen Signups aus, dann 20%, dann 50% und beobachte die Metriken zwischen den Schritten.
Wenn bei 20% etwas schiefgeht (z. B. Support meldet einen unendlichen Lade‑Spinner nach Schritt 2), solltest du das schnell in Dashboards bestätigen können: höhere Abbrüche und erhöhte Fehler beim „create project“‑Endpoint nur für geflaggte Nutzer. Statt eines hektischen Hotfixes, deaktiviere onboarding_v2 global. Neue Nutzer fallen sofort in den alten Flow zurück.
Nachdem du den Fehler gefixt und Stabilität bestätigt hast, fahre in kleinen Schritten wieder hoch: zuerst Beta, dann 5%, dann 25%, dann 100% nach einem vollen Tag ohne Überraschungen. Wenn stabil, entferne das Flag und plane das Löschen toter Code‑Teile zu einem festen Datum.
Häufige Fehler und Fallstricke, die du vermeiden solltest
Vor dem Ramping Snapshot erstellen
Erstelle vor dem Hochfahren eine Momentaufnahme, damit Rollbacks langweilig bleiben, wenn Metriken fallen.
Feature‑Flags machen schnelles Ausliefern sicherer, aber nur, wenn du sie wie echten Produktcode behandelst.
Ein häufiger Fehler ist Flag‑Explosion: Dutzende Flags mit unklaren Namen, ohne Owner und ohne Plan zur Entfernung. Das erzeugt verwirrendes Verhalten und Bugs, die nur für bestimmte Kohorten auftreten.
Eine andere Falle ist, sensible Entscheidungen im Client zu treffen. Kann ein Flag Preise, Berechtigungen, Datenzugriff oder Sicherheit beeinflussen, verlasse dich nicht auf Browser oder Mobile zur Durchsetzung. Halte Enforcement auf dem Server und sende nur das Ergebnis an die UI.
Tote Flags sind ein stilles Risiko. Nach einem 100%‑Rollout bleiben alte Pfade oft „für den Notfall“ bestehen. Monate später weiß niemand mehr, warum sie existieren, und ein Refactor bricht sie. Wenn du Rollback‑Optionen brauchst, nutze Snapshots oder einen klaren Rollback‑Plan, aber plane trotzdem Code‑Aufräumarbeiten, sobald die Änderung stabil ist.
Und zuletzt: Flags ersetzen keine Tests oder Reviews. Ein Flag reduziert den Blast‑Radius. Es verhindert keine Logikfehler, Migrationsprobleme oder Performance‑Engpässe.
Einfache Guardrails verhindern die meisten Probleme: klare Namensgebung (Bereich‑Zweck), Owner und Ablaufdatum zuweisen, ein leichtgewichtiges Flag‑Register führen (experiment, rolling out, fully on, removed) und Flag‑Änderungen wie Releases behandeln (loggen, reviewen, monitoren). Und setze sicherheitskritische Durchsetzungen nicht im Client um.
Kurze Checkliste, bevor du ein Flag aktivierst
Geschwindigkeit ist toll, bis eine kleine Änderung einen Kernpfad für alle bricht. Ein Zwei‑Minuten‑Check kann Stunden an Aufräumarbeit und Support sparen.
Bevor du ein Flag für echte Nutzer aktivierst:
- Klar benennen (z. B.
onboarding_new_ui_weboderpricing_calc_v2_backend). - Einen Owner und ein Ablaufdatum zuweisen, damit temporäre Flags nicht ewig leben.
- Default‑Zustand und sicheren Fallback dokumentieren, damit „aus“ weiterhin funktioniert und getestet wird.
- Rollout‑Regeln in einem Satz definieren (intern, dann 5% neue Signups, dann 25%, dann alle).
- Not‑Aus vorbereiten für hochriskante Pfade und klären, wer ihn umlegen darf.
Ein praktischer Reflex ist ein kurzer „Panik‑Test": Wenn die Fehler direkt nach Aktivierung steigen, können wir schnell ausschalten und landen Nutzer sicher? Wenn die Antwort „vielleicht“ ist, behebe die Rollback‑Pfade, bevor du exponierst.
Wenn du in Koder.ai baust, betrachte Flags als Teil des Builds: plane den Fallback, liefere mit einem sauberen Weg zurück.
Sicherheits‑, Datenschutz‑ und Compliance‑Basics fürs Kohorten‑Targeting
Fürs Bauen belohnt werden
Teile, was du mit Koder.ai gebaut hast, und verdiene Credits, um weiter sicher zu experimentieren.
Kohorten‑Targeting erlaubt sicheres Testen, kann aber auch sensitive Informationen leaken, wenn du unvorsichtig bist. Eine gute Regel: Flags sollten keine personenbezogenen Daten erfordern.
Bevorzuge einfache Targeting‑Eingaben wie Account‑ID, Plan‑Tier, interner Test‑Account, App‑Version oder einen Rollout‑Bucket (0–99). Vermeide rohe E‑Mails, Telefonnummern, genaue Adressen oder alles, was als regulierte Daten gilt.
Wenn du doch nutzerbezogene Dinge targeten musst, speichere sie als grobe Labels wie beta_tester oder employee. Speichere keine sensiblen Gründe als Labels. Achte außerdem darauf, dass Targeting nicht leicht von Nutzern erschlossen werden kann. Wenn ein Toggle plötzlich ein medizinisches Feature oder einen anderen Preis enthüllt, können Leute Rückschlüsse ziehen, welche Kohorten existieren.
Regionale Rollouts sind üblich, können aber Compliance‑Pflichten auslösen. Wenn du ein Feature nur in einem Land aktivierst, weil das Backend dort gehostet ist, stelle sicher, dass die Daten wirklich dort bleiben. Wenn deine Plattform pro Land deployen kann (Koder.ai unterstützt das auf AWS), behandle das als Teil des Rollout‑Plans, nicht als Nachgedanken.
Führe Audit‑Trails. Du willst eine klare Aufzeichnung, wer ein Flag geändert hat, was, wann und warum.
Nächste Schritte: baue einen leichtgewichtigen Flag‑Workflow und beweg dich weiter schnell
Ein leichtgewichtiger Workflow hält dich beweglich, ohne Feature‑Flags zu einem zweiten Produkt zu machen.
Beginne mit einer kleinen Menge an Kern‑Flags, die du wiederverwendest: eins für neue UI, eins für Backend‑Verhalten und ein Not‑Aus. Die gleichen Muster wiederzuverwenden macht es leichter zu überblicken, was live ist und was sicher deaktiviert werden kann.
Bevor du etwas Riskantes baust, mappe, wo es schiefgehen kann. In Koder.ai kann Planning Mode dir helfen, sensible Stellen (Auth, Billing, Onboarding, Daten‑Writes) zu markieren und zu entscheiden, was das Flag schützen soll. Ziel: geht etwas schief, schaltest du das Flag aus und die App verhält sich wie gestern.
Für jede geflaggte Änderung halte eine kleine, wiederholbare Release‑Notiz: Flag‑Name, wer es bekommt (Kohorte und %-Wert), eine Erfolgsmetrik, eine Guardrail‑Metrik, wie man es deaktiviert (Not‑Aus oder Rollout auf 0%), und wer es überwacht.
Wenn die Änderung stabil ist, sichere eine saubere Basis, indem du den Quellcode exportierst, nutze Snapshots vor großen Ramps als extra Sicherheitsnetz und plane anschließend Aufräumen: wenn ein Flag vollständig an (oder aus) ist, setze ein Datum, um es zu entfernen, damit dein System auf einen Blick verständlich bleibt.