30. Dez. 2025·8 Min
Fehler-Triage mit Claude Code: Ein praktischer Ablauf für schnelle Fehlerbehebungen
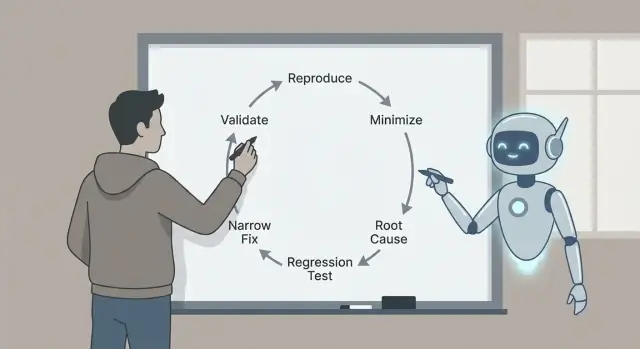
Fehler-Triage mit Claude Code in einem wiederholbaren Ablauf: reproduzieren, minimieren, wahrscheinliche Ursachen identifizieren, einen Regressions-Test hinzufügen und einen engen Fix mit Validierungs-Checks ausliefern.
Was Fehler-Triage ist und warum der Ablauf wichtig ist
Bugs wirken zufällig, wenn jeder Bericht zu einem einmaligen Rätsel wird. Du pikst im Code herum, probierst ein paar Ideen und hoffst, dass das Problem verschwindet. Manchmal klappt es, aber du lernst wenig und das gleiche Problem taucht in anderer Form wieder auf.
Fehler-Triage ist das Gegenteil. Es ist ein schneller Weg, Unsicherheit zu reduzieren. Das Ziel ist nicht, sofort alles zu beheben. Das Ziel ist, eine vage Beschwerde in eine klare, testbare Aussage zu verwandeln und dann die kleinste Änderung zu machen, die beweist, dass diese Aussage falsch ist.
Deshalb ist der Ablauf wichtig: reproduzieren, minimieren, wahrscheinliche Ursachen mit Beweisen identifizieren, einen Regressions-Test hinzufügen, einen engen Fix implementieren und validieren. Jeder Schritt entfernt eine bestimmte Art von Raten. Schritte überspringen zahlt sich später oft mit größeren Fixes, Nebeneffekten oder „behobenen“ Bugs, die nie wirklich weg waren, aus.
Hier ein realistisches Beispiel. Ein Nutzer sagt: „Der Speichern-Button macht manchmal nichts.“ Ohne Ablauf würdest du vielleicht im UI-Code wühlen und Timing, State oder Netzwerkaufrufe ändern. Mit dem Ablauf machst du aus „manchmal“ erst einmal „immer unter diesen genauen Bedingungen“, z. B.: „Nach dem Bearbeiten eines Titels und schnellem Wechseln des Tabs bleibt Speichern deaktiviert.“ Dieser einzelne Satz ist bereits Fortschritt.
Claude Code kann den Denkprozess beschleunigen: Berichte in präzise Hypothesen verwandeln, vorschlagen, wo man nachschauen sollte, und einen minimalen Test vorschlagen, der fehlschlagen sollte. Besonders hilfreich ist das Scannen von Code, Logs und jüngsten Diffs, um schnell plausible Erklärungen zu generieren.
Du musst trotzdem verifizieren, was zählt. Bestätige, dass der Bug in deiner Umgebung echt ist. Ziehe Beweise (Logs, Traces, fehlschlagende Tests) einer gut klingenden Geschichte vor. Halte den Fix so klein wie möglich, beweise ihn mit einem Regressions-Test und validiere ihn mit klaren Checks, damit du keinen Bug gegen einen anderen austauschst.
Der Gewinn ist ein kleiner, sicherer Fix, den du erklären, verteidigen und vor Regression schützen kannst.
Richte den Triage-Arbeitsbereich ein (bevor du am Code arbeitest)
Gute Fixes beginnen mit einem sauberen Workspace und einer einzigen, klaren Problemdefinition. Bevor du Claude fragst, wähle einen Bericht aus und schreibe ihn um als:
„Wenn ich X mache, erwarte ich Y, aber ich bekomme Z.“
Wenn du diesen Satz nicht schreiben kannst, hast du noch keinen Bug. Du hast ein Rätsel.
Sammle die Grundlagen gleich zu Beginn, damit du nicht ständig zurückkehren musst. Diese Details machen Vorschläge testbar statt vage: App-Version oder Commit (und ob lokal, staging oder Produktion), Umgebungsdetails (OS, Browser/Gerät, Feature-Flags, Region), exakte Eingaben (Formfelder, API-Payload, Nutzeraktionen), wer es sieht (alle, eine Rolle, ein einzelner Account/Tenant) und was „erwartet“ bedeutet (Text, UI-State, Statuscode, Geschäftsregel).
Bewahre dann Beweise, solange sie frisch sind. Ein einzelner Zeitstempel kann Stunden sparen. Erfasse Logs rund um das Ereignis (Client und Server, wenn möglich), einen Screenshot oder eine kurze Aufnahme, Request-IDs oder Trace-IDs, exakte Zeitstempel (mit Zeitzone) und das kleinste Daten-Snippet, das das Problem auslöst.
Beispiel: Eine mit Koder.ai generierte React-App zeigt „Payment succeeded“, aber die Bestellung bleibt „Pending“. Notiere die Nutzerrolle, die exakte Bestell-ID, den API-Response-Body und die Server-Log-Zeilen für diese Request-ID. Jetzt kannst du Claude auf einen Flow fokussieren, statt zu schwammig zu bleiben.
Setze schließlich eine Stopp-Regel. Entscheide, was als behoben gilt, bevor du mit dem Coden beginnst: ein bestimmter Test, der besteht, ein UI-State, der sich ändert, ein Fehler, der nicht mehr in Logs erscheint, plus eine kurze Validierungs-Checklist, die du jedes Mal durchläufst. So verhinderst du, dass du nur das Symptom „fixst“ und einen neuen Bug auslieferst.
Verwandle den Bug-Report in eine präzise Frage für Claude
Ein chaotischer Bug-Report mischt meist Fakten, Vermutungen und Frust. Bevor du um Hilfe bittest, verwandle ihn in eine prägnante Frage, die Claude mit Belegen beantworten kann.
Beginne mit einer Ein-Satz-Zusammenfassung, die Feature und Fehler nennt. Gut: „Beim Speichern eines Entwurfs wird auf Mobilgeräten manchmal der Titel gelöscht.“ Nicht gut: „Entwürfe sind kaputt.“ Dieser Satz wird der Anker für den gesamten Triage-Thread.
Trenne dann, was du gesehen hast, von dem, was du erwartet hast. Halte es langweilig und konkret: die exakte Schaltfläche, die du geklickt hast, die Meldung auf dem Bildschirm, die Log-Zeile, der Zeitstempel, das Gerät, der Browser, der Branch, das Commit. Wenn du das noch nicht hast, sag es.
Eine einfache Struktur, die du einfügen kannst:
- Zusammenfassung (ein Satz)
- Beobachtetes Verhalten (was passiert ist, inkl. Fehlermeldungen)
- Erwartetes Verhalten (was passieren sollte)
- Repro-Schritte (nummeriert, kleinstmögliche Menge)
- Umgebung (App-Version, Gerät, OS, Browser, Config-Flags)
Wenn Details fehlen, frag sie als Ja/Nein-Fragen, damit Leute schnell antworten können: Tritt es auf einem frischen Account auf? Nur auf Mobilgeräten? Nur nach einem Refresh? Begann es nach dem letzten Release? Reproduzierbar im Inkognito?
Claude ist auch nützlich als „Report-Cleaner“. Füge den Originalbericht ein (inkl. kopiertem Text aus Screenshots, Logs und Chat-Snippets) und frage:
„Schreibe das als strukturiertes Checkliste um. Markiere Widersprüche. Liste die 5 fehlenden Fakten als Ja/Nein-Fragen. Rate noch nicht die Ursachen.“
Wenn ein Kollege sagt „Es schlägt zufällig fehl“, bringe es in eine testbare Form: „Schlägt 2/10 Mal auf iPhone 14, iOS 17.2 fehl, wenn zwei Mal schnell auf Speichern getippt wird.“ Jetzt kannst du es absichtlich reproduzieren.
Schritt 1 – Den Bug zuverlässig reproduzieren
Wenn du den Bug nicht auf Abruf auslösen kannst, ist jeder nächste Schritt Ratenarbeit.
Fange an, indem du ihn in der kleinstmöglichen Umgebung reproduzierst, die das Problem noch zeigt: ein lokaler Dev-Build, ein minimaler Branch, ein winziger Datensatz und so wenige Dienste wie nötig eingeschaltet.
Schreibe die genauen Schritte auf, damit jemand anderes ohne Rückfragen nachmachen kann. Mache sie copy-paste-freundlich: Befehle, IDs und Beispiel-Payloads sollten genau so enthalten sein wie benutzt.
Eine einfache Capture-Vorlage:
- Setup: Branch/Commit, Config-Flags, Datenbankzustand (leer, seeded, Prod-Kopie)
- Schritte: nummerierte Aktionen mit exakten Eingaben
- Erwartet vs. Tatsächlich: was du erwartet hast, und was stattdessen passierte
- Beweise: Fehlermeldungen, Screenshots, Zeitstempel, Request-IDs
- Häufigkeit: immer, manchmal, nur beim ersten Durchlauf, nur nach Refresh
Die Häufigkeit beeinflusst die Strategie. „Immer“-Bugs sind ideal für schnelles Iterieren. „Manchmal“-Bugs deuten oft auf Timing, Caching, Race-Conditions oder versteckten Zustand hin.
Wenn du Repro-Notizen hast, bitte Claude um schnelle Probes, die Unsicherheit verringern, ohne die App umzuschreiben. Gute Probes sind klein: eine gezielte Log-Zeile an der fehleranfälligen Grenze (Inputs, Outputs, Schlüsselzustand), ein Debug-Flag für eine einzelne Komponente, ein Weg, deterministisches Verhalten zu erzwingen (fester Zufallsseed, feste Zeit, ein Worker), ein kleiner Seed-Datensatz, der den Fehler auslöst, oder eine einzelne fehlschlagende Request/Response-Paarung zum Replayen.
Beispiel: Ein Signup-Flow schlägt „manchmal“ fehl. Claude könnte vorschlagen, die generierte User-ID, das Ergebnis der E-Mail-Normalisierung und die Details eines Unique-Constraint-Errors zu loggen und dann dieselbe Payload 10× auszuführen. Wenn der Fehler nur beim ersten Lauf nach Deploy auftritt, ist das ein starker Hinweis auf Migrations-, Cache-Warmup- oder Seed-Daten-Probleme.
Schritt 2 – Auf einen kleinen, wiederholbaren Testfall minimieren
Plane die Lösung zuerst
Skizziere Hypothesen, Tests und Validierungschecks, bevor du am Code arbeitest.
Eine gute Reproduktion ist nützlich. Eine minimale Reproduktion ist mächtig. Sie macht den Bug schneller verständlich, leichter zu debuggen und weniger anfällig dafür, „versehentlich“ gefixt zu werden.
Streiche alles, was nicht erforderlich ist. Wenn der Bug nach einem langen UI-Flow auftritt, finde den kürzesten Pfad, der ihn weiterhin auslöst. Entferne optionale Bildschirme, Feature-Flags und nicht verwandte Integrationen, bis der Bug entweder verschwindet (du hast etwas Essenzielles entfernt) oder bleibt (du hast Rauschen entfernt).
Verkleinere dann die Daten. Wenn die Fehlfunktion eine große Payload braucht, probiere die kleinste Payload, die noch bricht. Wenn eine Liste von 500 Items nötig ist, teste mit 5, dann mit 2, dann mit 1. Entferne Felder nacheinander. Das Ziel ist: so wenige bewegliche Teile wie nötig, die den Bug noch reproduzieren.
Eine praktische Methode ist „halbieren und erneut testen“:
- Schneide die Schritte in der Hälfte und prüfe, ob der Bug noch auftritt.
- Wenn ja, behalte die Hälfte und kürze erneut.
- Wenn nein, stelle die Hälfte wieder her und kürze anders.
- Wiederhole, bis du nichts mehr entfernen kannst, ohne den Bug zu verlieren.
Beispiel: Eine Checkout-Seite stürzt „manchmal“ ab, wenn ein Gutschein angewendet wird. Du findest, dass es nur passiert, wenn der Warenkorb mindestens einen rabattierten Artikel hat, der Gutschein Kleinbuchstaben enthält und Versand auf "Abholung" gestellt ist. Das ist dein Minimalfall: ein rabattierter Artikel, ein Gutschein in Kleinbuchstaben, Versand auf Abholung.
Wenn der Minimalfall klar ist, bitte Claude, ihn in ein kleines Reproduktionsgerüst zu verwandeln: einen minimalen Test, der die fehlerhafte Funktion mit den kleinsten Eingaben aufruft, ein kurzes Skript, das einen Endpoint mit reduzierter Payload trifft, oder einen kleinen UI-Test, der eine Route besucht und eine Aktion ausführt.
Schritt 3 – Wahrscheinliche Ursachen identifizieren (mit Beweisen)
Wenn du das Problem reproduzieren kannst und einen kleinen Testfall hast, hör auf zu raten. Dein Ziel ist eine kurze Liste plausibler Ursachen und dann jede einzelne zu beweisen oder zu widerlegen.
Eine nützliche Regel ist: beschränke dich auf drei Hypothesen. Wenn du mehr hast, ist dein Testfall wahrscheinlich noch zu groß oder deine Beobachtungen zu vage.
Symptome auf Komponenten abbilden
Übersetze, was du siehst, in mögliche Orte, an denen es passieren kann. Ein UI-Symptom bedeutet nicht zwangsläufig einen UI-Bug.
Beispiel: Eine React-Seite zeigt einen „Gespeichert“-Toast, aber der Datensatz fehlt später. Das kann auf (1) UI-State, (2) API-Verhalten oder (3) die Datenbank-Schreibkette hindeuten.
Für jede Hypothese Beweise sammeln
Bitte Claude, wahrscheinliche Fehlervarianten in einfacher Sprache zu erklären und dann zu sagen, welcher Beweis jede bestätigen würde. Ziel ist, aus „vielleicht“ ein konkretes „prüfe das genau“ zu machen.
Drei gängige Hypothesen und welche Beweise zu sammeln sind:
- UI/State-Mismatch: der Client aktualisiert lokalen State, bevor der Server bestätigt. Beweis: Zustandssnapshots vor und nach der Aktion erfassen und mit der tatsächlichen API-Antwort vergleichen.
- API-Edge-Case: der Handler gibt 200, verwirft aber stillschweigend Arbeit (Validierung, ID-Parsing, Feature-Flag). Beweis: Request/Response-Logs mit Korrelations-IDs hinzufügen und prüfen, ob der Handler den Schreibaufruf mit erwarteten Inputs erreicht.
- Datenbank- oder Timing-Problem: eine Transaktion rollt zurück, ein Konflikt-Error tritt auf oder „read after write“ kommt von einem Cache/Replica. Beweis: DB-Query, betroffene Rows und Error-Codes inspizieren; Transaktionsgrenzen und Retry-Verhalten loggen.
Halte deine Notizen knapp: Symptom, Hypothese, Beweis, Urteil. Wenn eine Hypothese mit den Fakten übereinstimmt, kannst du den Regressions-Test und den gezielten Fix festlegen.
Schritt 4 – Einen Regressions-Test hinzufügen, der aus dem richtigen Grund fehlschlägt
Ein guter Regressions-Test ist dein Sicherheitsgurt. Er beweist, dass der Bug existierte und er zeigt, wann du ihn wirklich behoben hast.
Beginne damit, den kleinsten Test zu wählen, der das reale Fehlverhalten abbildet. Wenn der Bug nur auftritt, wenn mehrere Teile zusammenarbeiten, kann ein Unit-Test das Problem verfehlen.
Wähle die Testebene, die zum Bug passt
Verwende einen Unit-Test, wenn eine einzelne Funktion den falschen Wert zurückgibt. Verwende einen Integrationstest, wenn die Grenze zwischen Teilen das Problem ist (API-Handler plus DB oder UI plus State). Verwende End-to-End nur, wenn der Bug den kompletten User-Flow braucht.
Bevor du Claude bittest, etwas zu schreiben, formuliere den minimierten Fall als strenges erwartetes Verhalten. Beispiel: „Wenn der Nutzer einen leeren Titel speichert, muss die API 400 mit der Nachricht ‚title required‘ zurückgeben.“ Jetzt hat der Test ein klares Ziel.
Lass Claude zuerst einen fehlschlagenden Test entwerfen. Halte das Setup minimal und kopiere nur die Daten, die den Bug auslösen. Benenne den Test nach dem Nutzererlebnis, nicht nach einer internen Funktion.
Den Entwurf überprüfen (vertraue ihm nicht blind)
Mach einen schnellen Check:
- Bestätige, dass er im aktuellen Code aus dem beabsichtigten Grund fehlschlägt (nicht wegen einer fehlenden Fixture oder falschem Import).
- Prüfe, dass Assertions spezifisch sind (genauer Statuscode, Nachricht, gerenderter Text).
- Stelle sicher, dass der Test genau einen Bug abdeckt, nicht ein Bündel von Verhaltensweisen.
- Halte den Namen nutzerfokussiert, z. B. „rejects empty title on save“ statt „handles validation".
Wenn der Test aus dem richtigen Grund fehlschlägt, kannst du selbstbewusst einen engen Fix implementieren.
Schritt 5 – Einen engen Fix implementieren
Bugs schneller triagieren mit Koder.ai
Nutze Chat, um einen Bug von Repro-Schritten bis zur kleinen, testbaren Lösung nachzuverfolgen.
Wenn du eine kleine Repro und einen fehlschlagenden Regressions-Test hast, widerstehe dem Drang nach großem „Aufräumen“. Ziel ist, den Bug mit der kleinsten Änderung zu stoppen, die den Test aus dem richtigen Grund grün macht.
Ein guter enger Fix verändert so wenig Oberfläche wie möglich. Liegt der Fehler in einer Funktion, fixiere diese Funktion und nicht das gesamte Modul. Fehlt eine Grenzprüfung, füge die Prüfung an der Grenze hinzu, nicht über die ganze Aufrufkette.
Wenn du Claude um Hilfe bittest, fordere zwei Fix-Optionen an und vergleiche sie hinsichtlich Umfang und Risiko. Beispiel: Wenn ein React-Form abstürzt, wenn ein Feld leer ist, könntest du bekommen:
- Option A: Eine Guard im Submit-Handler hinzufügen, die leere Eingaben blockiert und einen Fehler anzeigt.
- Option B: Die State-Behandlung refactoren, sodass das Feld nie leer sein kann.
Option A ist in der Triage häufig die Wahl: kleiner, einfacher zu reviewen und weniger riskant.
Um den Fix eng zu halten, ändere so wenige Dateien wie möglich, bevorzuge lokale Fixes gegenüber Refactors, füge Guards/Validierung dort ein, wo der schlechte Wert hereinkommt, und mache die Verhaltensänderung explizit mit einem klaren Vorher/Nachher. Kommentiere nur, wenn der Grund nicht offensichtlich ist.
Konkretes Beispiel: Ein Go-API-Endpoint panict, wenn ein optionaler Query-Param fehlt. Der enge Fix ist, den leeren String an der Handler-Grenze zu behandeln (mit Default parsen oder 400 mit klarer Nachricht zurückgeben). Vermeide Änderungen an gemeinsamen Parsing-Utilities, es sei denn, der Regressions-Test beweist, dass dort das Problem liegt.
Nach der Änderung führe den fehlschlagenden Test und ein oder zwei nahegelegene Tests erneut aus. Wenn dein Fix viele nicht verwandte Tests erfordert, die du anpassen musst, ist das ein Zeichen dafür, dass die Änderung zu breit ist.
Schritt 6 – Den Fix mit klaren Checks validieren
Validierung fängt die kleinen, leicht übersehbaren Probleme: ein Fix, der einen Test bestehen lässt, aber einen nahegelegenen Pfad kaputtmacht, eine Fehlermeldung ändert oder eine langsame Query einführt.
Führe zuerst den Regressions-Test aus, den du hinzugefügt hast. Wenn er besteht, führe die nächsten Nachbarn aus: Tests in derselben Datei, im selben Modul und alles, was dieselben Eingaben abdeckt. Bugs verstecken sich oft in geteilten Helfern, Parsing, Grenzprüfungen oder Caching, daher zeigen sich relevante Fehler meist in der Nähe.
Mache danach eine kurze manuelle Prüfung mit den ursprünglichen Repro-Schritten. Halte sie kurz und spezifisch: dieselbe Umgebung, dieselben Daten, dieselbe Abfolge von Klicks oder API-Calls. War der ursprüngliche Bericht vage, teste die genaue Szene, die du zur Reproduktion verwendet hast.
Eine einfache Validierungs-Checklist
- Regressions-Test besteht, plus verwandte Tests in der Nähe.
- Manuelle Repro-Schritte lösen den Bug nicht mehr aus.
- Fehlerbehandlung bleibt sinnvoll (Nachrichten, Statuscodes, Retries).
- Edge-Cases verhalten sich weiterhin (leere Eingabe, Max-Größen, ungewöhnliche Zeichen).
- Keine offensichtliche Performance-Beeinträchtigung (zusätzliche Schleifen, zusätzliche Calls, langsame Queries).
Wenn du fokussiert bleiben willst, bitte Claude um einen kurzen Validierungsplan basierend auf deiner Änderung und dem fehlschlagenden Szenario. Teile mit, welche Datei du geändert hast, welches Verhalten du beabsichtigt hast und was plausibel betroffen sein könnte. Die besten Pläne sind kurz und ausführbar: 5–8 Checks, die du in Minuten erledigen kannst, jeweils mit klarem Bestehen/Nicht-Bestehen.
Zuletzt dokumentiere, was du validiert hast, in der PR oder in den Notizen: welche Tests du ausgeführt hast, welche manuellen Schritte du probiert hast und welche Grenzen es gab (z. B. „mobil nicht getestet“). Das macht den Fix vertrauenswürdig und später leichter nachzuvollziehen.
Häufige Fehler und Fallen (und wie man sie vermeidet)
Server-seitige Fixes testen
Prototypisiere Go- plus PostgreSQL-Flows und reproduziere API-Edge-Cases mit weniger Reibung.
Der schnellste Weg, Zeit zu verschwenden, ist, einem „Fix“ zuzustimmen, bevor du das Problem zuverlässig reproduzieren kannst. Wenn du es nicht zuverlässig zum Scheitern bringen kannst, weißt du nicht, was sich tatsächlich verbessert hat.
Eine praktische Regel: Fordere keine Fixes an, bis du eine wiederholbare Umgebung beschreiben kannst (exakte Schritte, Eingaben, Umgebung und wie „falsch“ aussieht). Wenn der Bericht vage ist, verwende die ersten Minuten darauf, ihn in eine Checkliste zu verwandeln, die du zweimal ausführen kannst und das gleiche Ergebnis liefert.
Fallen, die dich aufhalten
Fixen ohne reproduzierbaren Fall. Verlange ein minimales Skript oder eine Schrittfolge, die „immer“ fehlschlägt. Wenn es nur „manchmal“ passiert, erfasse Timing, Datenmenge, Flags und Logs, bis es nicht mehr zufällig ist.
Zu früh minimieren. Wenn du den Fall verkleinerst, bevor du die Original-Failure bestätigt hast, verlierst du das Signal. Sperre zuerst die Baseline-Reproduktion ein, und schrumpfe dann schrittweise.
Claude raten lassen. Claude kann wahrscheinliche Ursachen vorschlagen, aber du brauchst trotzdem Beweise. Fordere 2–3 Hypothesen und die genauen Beobachtungen, die jede bestätigen oder widerlegen würden (eine Log-Zeile, ein Breakpoint, ein Query-Result).
Regressions-Tests, die aus dem falschen Grund bestehen. Ein Test kann „grün“ werden, weil er nie den fehlerhaften Pfad trifft. Stelle sicher, dass er vor dem Fix fehlschlägt und mit der erwarteten Nachricht/Assertion.
Symptome behandeln statt des Triggers. Wenn du eine Null-Check hinzufügst, aber das eigentliche Problem ist „dieser Wert sollte nie null sein“, kannst du einen tieferen Bug verstecken. Bevorzuge das Beheben der Ursache, die den schlechten Zustand erzeugt.
Ein schneller Plausibilitäts-Check, bevor du es abschließt
Führe den neuen Regressions-Test und die ursprünglichen Repro-Schritte vor und nach deiner Änderung aus. Wenn ein Checkout-Bug nur auftritt, wenn ein Promo-Code nach dem Ändern des Versands angewendet wird, behalte diese komplette Sequenz als deine „Wahrheit“, auch wenn dein minimierter Test kleiner ist.
Wenn deine Validierung darauf beruht, dass „es jetzt gut aussieht“, füge eine konkrete Prüfung hinzu (ein Log, eine Metrik oder ein spezifisches Output), sodass die nächste Person es schnell überprüfen kann.
Eine kurze Checkliste, Prompt-Templates und nächste Schritte
Wenn es schnell gehen muss, schlägt eine kleine, wiederholbare Schleife heldenhaftes Debugging.
Einseitige Triage-Checkliste
- Reproduzieren: Zuverlässige Repro bekommen und exakte Eingaben, Umgebung und Erwartetes vs. Tatsächliches notieren.
- Minimieren: Auf die kleinsten Schritte oder den Test reduzieren, der noch fehlschlägt.
- Erklären: 2–3 wahrscheinliche Ursachen und die Beweise für jede auflisten.
- Absichern: Einen Regressions-Test hinzufügen, der aus dem richtigen Grund fehlschlägt.
- Fix + Validieren: Die engste Änderung machen und dann eine kurze Validierungs-Checklist abarbeiten.
Schreibe die finale Entscheidung in wenigen Zeilen, damit die nächste Person (oft du selbst später) ihr vertrauen kann. Ein nützliches Format ist: „Root cause: X. Trigger: Y. Fix: Z. Warum sicher: W. Was wir nicht geändert haben: Q.“
Prompt-Templates, die du einfügen kannst
- „Given this bug report and logs, ask me only the missing questions needed to reproduce it reliably."
- „Help me minimize: propose a smaller test case and tell me what to remove first, one change at a time."
- "Rank likely root causes and cite the exact files, functions, or conditions that support each claim."
- „Write a regression test that fails only because of this bug. Explain why it fails for the right reason."
- „Suggest the narrowest fix, plus a validation checklist (unit, integration, and manual checks) that proves we didn’t break nearby behavior."
Nächste Schritte: automatisiere, was du kannst (ein gespeichertes Repro-Skript, ein Standard-Testbefehl, eine Vorlage für Root-Cause-Notes).
Wenn du Apps mit Koder.ai (koder.ai) baust, kann Planning Mode dir helfen, die Änderung zu skizzieren, bevor du den Code anfasst, und Snapshots/Rollback erleichtern das sichere Experimentieren während du an einer kniffligen Repro arbeitest. Sobald der Fix validiert ist, kannst du den Quellcode exportieren oder die aktualisierte App deployen und hosten, einschließlich einer benutzerdefinierten Domain, wenn nötig.
FAQ
Was ist Fehler-Triage, einfach erklärt?
Bug-Triage ist die Gewohnheit, einen vagen Bericht in eine klare, testbare Aussage zu verwandeln und dann die kleinste Änderung zu machen, die beweist, dass die Aussage nicht mehr stimmt.
Es geht weniger darum, sofort alles zu reparieren, und mehr darum, Unsicherheit Schritt für Schritt zu reduzieren: reproduzieren, minimieren, evidenzbasierte Hypothesen bilden, eine Regressions-Test hinzufügen, gezielt fixen und validieren.
Warum ist die Repro → Minimieren → Test → Fix-Schleife so wichtig?
Weil jeder Schritt eine andere Art von Vermutung ausschließt.
- Reproduzieren: beweist, dass es echt und wiederholbar ist
- Minimieren: entfernt Rauschen, damit du nicht nebensächliches Verhalten verfolgst
- Hypothesen mit Beweisen: verhindert, dass du das Falsche reparierst
- Regressions-Test: beweist, dass der Bug existierte und weiterhin behoben bleibt
- Enger Fix + Validierung: reduziert Nebenwirkungen und erneute Fehler
Wie mache ich aus einem unordentlichen Bug-Report etwas Handlungsfähiges?
Schreibe es um als: „Wenn ich X mache, erwarte ich Y, aber ich bekomme Z.“
Sammle dann gerade genug Kontext, damit es testbar ist:
- Version/Commit + wo es passiert (lokal/staging/prod)
- Umgebung (Gerät, OS, Browser, Flags, Region)
- exakte Eingaben/Aktionen
- wer betroffen ist (alle, Rolle, ein Tenant)
- Beweise (Timestamps, Fehlermeldung, Request-/Trace-IDs, Logs)
Was soll ich zuerst tun, wenn ich den Bug nicht reproduzieren kann?
Beginne damit, zu bestätigen, dass du ihn in der kleinstmöglichen Umgebung reproduzieren kannst, die das Problem noch zeigt (oft lokal mit kleinem Datensatz).
Wenn es „manchmal“ passiert, versuche es deterministisch zu machen, indem du Variablen kontrollierst:
- dieselne Payload 10× neu ausführen
- Zeit/Zufall fixieren, wenn möglich
- Concurrency reduzieren (ein Worker/Thread)
- eine gezielte Log-Zeile an der wahrscheinlich fehlschlagenden Grenze hinzufügen
Bewege dich nicht weiter, bis du es auf Abruf reproduzieren kannst, sonst rätst du nur.
Wie minimiere ich einen Bug zu einem kleinen Testfall?
Minimierung heißt: entferne alles, was nicht erforderlich ist, und behalte den Bug.
Eine praktische Methode ist „halbieren und erneut testen“:
- Schritte/Daten halbieren
- wenn es weiterhin fehlschlägt, nochmals halbieren
- wenn es aufhört zu fehlschlagen, stelle die Hälfte wieder her und schneide anders
Verkleinere sowohl Schritte (kürzere Nutzer-Flow) als auch (kleinere Payload, weniger Felder/Elemente), bis du den kleinsten wiederholbaren Trigger hast.
Wie kann Claude Code helfen, ohne dass es zur Rateshow wird?
Nutze Claude Code, um die Analyse zu beschleunigen, aber nicht die Verifikation zu ersetzen.
Gute Anfragen sehen so aus:
- „Hier sind Repro-Schritte + Logs. Nenne 2–3 Hypothesen und welche Beweise jeweils bestätigen würden.“
- „Angesichts dieses Diffs und Stacktraces: wo sind die wahrscheinlichsten Fehlergrenzen?“
- „Entwirf einen minimalen, fehlschlagenden Test für dieses genaue Szenario."
Dann validierst du: lokal reproduzieren, Logs/Traces prüfen und sicherstellen, dass Tests aus gutem Grund fehlschlagen.
Wie viele Root-Cause-Hypothesen sollte ich gleichzeitig betrachten?
Behalte es bei drei Hypothesen. Mehr als das deutet meist darauf hin, dass deine Repro noch zu groß ist oder deine Beobachtungen zu vage sind.
Für jede Hypothese schreibe:
- Symptom (was du beobachtest)
- (was es verursachen könnte)
Was macht einen guten Regressions-Test für einen Bug aus?
Wähle das kleinste Test-Level, das dem Fehler entspricht:
- Unit-Test: eine Funktion liefert den falschen Wert
- Integrationstest: Probleme an der Grenze zwischen Komponenten (Handler + DB, Client + API)
- End-to-End: nur wenn der ganze Flow nötig ist
Ein guter Regressions-Test:
Wie halte ich einen Fix eng und risikoarm?
Mache die kleinste Änderung, die den fehlschlagenden Regressions-Test aus dem richtigen Grund bestehen lässt.
Faustregeln:
- so wenige Dateien wie möglich anfassen
- an der Grenze fixen, an der der schlechte Wert hereinkommt
- während der Triage eine Guard/Validierung einem Refactor vorziehen
- vermeide „Aufräumen“, es sei denn, der Test zeigt, dass es nötig ist
Wenn dein Fix viele nicht verwandte Tests bricht, ist die Änderung wahrscheinlich zu breit.
Wie validiere ich einen Fix, damit der Bug nicht zurückkommt?
Nutze eine kurze Checkliste, die du schnell abarbeiten kannst:
- Regressions-Test besteht
- einige Nachbar-Tests bestehen (gleiches Modul/Inputs)
- die ursprünglichen manuellen Repro-Schritte lösen den Bug nicht mehr aus
- Fehlerbehandlung bleibt sinnvoll (Nachrichten, Statuscodes)
- schnelle Edge-Case-Checks (leere Eingabe, Max-Größe, ungewöhnliche Zeichen)
- keine offensichtlichen Performance-Regressions
Halte fest, was du getestet hast und was nicht, damit das Ergebnis vertrauenswürdig ist.