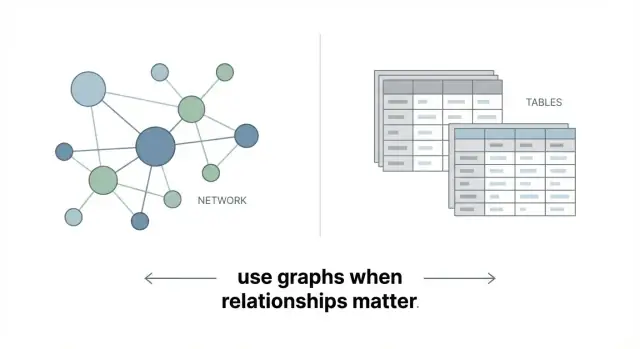
Was eine Graphdatenbank ist (ohne Hype)
Eine Graphdatenbank speichert Daten als Netzwerk statt als Tabellen. Die Grundidee ist simpel:
- Knoten sind die „Dinge“, die dir wichtig sind (ein Kunde, Produkt, Konto, Gerät, Standort).
- Beziehungen verbinden Knoten (Kunde KAUFTE Produkt, Konto ÜBERWIES_AN Konto, Nutzer FOLGT Nutzer).
- Eigenschaften sind Details, die du Knoten und Beziehungen anhängst (Name, Preis, Zeitstempel, Betrag, Status).
Das war’s: Eine Graphdatenbank ist darauf ausgelegt, vernetzte Daten direkt darzustellen.
Beziehungen sind "First-Class"
In einer Graphdatenbank sind Beziehungen kein Nebenprodukt — sie werden als echte, abfragbare Objekte gespeichert. Eine Beziehung kann eigene Eigenschaften haben (zum Beispiel kann eine KAUFTE-Beziehung Datum, Kanal und Rabatt speichern), und du kannst effizient von einem Knoten zum nächsten traversieren.
Das ist wichtig, weil viele Geschäftsfragen natürlich über Pfade und Verbindungen gehen: „Wer ist mit wem verbunden?“, „Wie viele Schritte entfernt ist dieses Objekt?“ oder „Welche gemeinsamen Verknüpfungen gibt es zwischen diesen beiden Dingen?"
Wie sich das von Tabellen und Joins unterscheidet
Relationale Datenbanken sind hervorragend für strukturierte Datensätze: Kunden, Bestellungen, Rechnungen. Beziehungen existieren dort auch, werden aber meist indirekt über Fremdschlüssel dargestellt, und das Verbinden mehrerer Hops bedeutet oft viele Joins über verschiedene Tabellen.
Graphen halten die Verbindungen direkt neben den Daten, sodass das Erkunden mehrstufiger Beziehungen tendenziell einfacher zu modellieren und abzufragen ist.
Erwartungen setzen
Graphdatenbanken sind exzellent, wenn die Beziehungen im Mittelpunkt stehen — Empfehlungen, Betrugsnetzwerke, Abhängigkeitskarten, Wissensgraphen. Sie sind nicht automatisch besser für einfache Reports, Summen oder stark tabellarische Workloads. Das Ziel ist nicht, jede Datenbank zu ersetzen, sondern Graphen dort einzusetzen, wo Vernetzung den Wert treibt.
Warum Beziehungen das Spiel verändern
Die meisten Geschäftsfragen drehen sich nicht um einzelne Datensätze — sie drehen sich darum, wie Dinge verbunden sind.
Ein Kunde ist nicht nur eine Zeile; er ist verknüpft mit Bestellungen, Geräten, Adressen, Support-Tickets, Empfehlungen und manchmal mit anderen Kunden. Eine Transaktion ist nicht nur ein Ereignis; sie ist verbunden mit Händler, Zahlungsmethode, Standort, Zeitfenster und einer Kette verwandter Aktivitäten. Wenn die Frage lautet „wer/was ist mit wem verbunden und wie?“, wird Beziehungsebene zur Hauptrolle.
Traversals: Verbindungen Schritt für Schritt folgen
Graphdatenbanken sind auf Traversals ausgelegt: man startet an einem Knoten und „läuft“ das Netzwerk, indem man Kanten folgt.
Statt Tabellen immer wieder zu joinen, drückst du den Pfad aus, der dich interessiert: Kunde → Gerät → Login → IP-Adresse → Andere Kunden. Dieses Schritt-für-Schritt-Denken passt dazu, wie Menschen Betrug untersuchen, Abhängigkeiten nachverfolgen oder Empfehlungen erklären.
Warum Multi-Hop-Abfragen einfacher werden
Der Unterschied zeigt sich, wenn du mehrere Hops brauchst (zwei, drei, fünf Schritte entfernt) und vorher nicht weißt, wo die interessanten Verbindungen auftauchen.
Im relationalen Modell werden solche Fragen oft zu langen Join-Ketten plus zusätzlicher Logik, um Duplikate zu vermeiden und die Pfadlänge zu kontrollieren. In einem Graphen ist „Finde alle Pfade bis N Hops“ ein normales, lesbares Muster — besonders im Property-Graph-Modell, das viele Graphdatenbanken verwenden.
Beziehungs-Eigenschaften geben Bedeutung
Kanten sind nicht nur Linien; sie können Daten tragen:
- Typ: purchased, referred, works_with
- Zeit: wann die Beziehung begann, endete oder zuletzt auftrat
- Gewichtung: Frequenz, Confidence-Score, Betrag, Risikoniveau
Diese Eigenschaften erlauben bessere Fragen: „verbunden in den letzten 30 Tagen“, „stärkste Verbindungen“ oder „Pfade, die risikoreiche Transaktionen enthalten“ — ohne alles in separate Lookup-Tabellen zu zwingen.
Best-Fit-Anwendungsfälle für Graphdatenbanken
Graphdatenbanken glänzen, wenn deine Fragen von Vernetzung abhängen: „wer ist mit wem verbunden, durch was und wie viele Schritte entfernt?“ Wenn der Wert deiner Daten in den Beziehungen lebt (nicht nur in Attributzeilen), kann ein Graphmodell Modellierung und Abfragen natürlicher machen.
Soziale und berufliche Netzwerke
Alles, was wie ein Netzwerk geformt ist — Freunde, Follower, Kollegen, Teams, Empfehlungen — lässt sich sauber in Knoten und Beziehungen abbilden. Typische Fragen sind „gegenseitige Verbindungen“, „kürzester Weg zu einer Person“ oder „wer verbindet diese beiden Gruppen?“ Solche Abfragen werden bei erzwungenen Join-Tabellen oft umständlich oder langsam.
Empfehlungen (und Discovery)
Empfehlungssysteme hängen oft von mehrstufigen Verbindungen ab: Nutzer → Artikel → Kategorie → ähnliche Artikel → andere Nutzer. Graphdatenbanken sind gut für „Nutzer, die X mochten, mögen auch Y“, „häufig gemeinsam betrachtete Artikel“ oder „Finde Produkte, die über gemeinsame Attribute oder Verhalten verbunden sind“. Das ist besonders nützlich, wenn Signale vielfältig sind und du ständig neue Beziehungstypen ergänzt.
Betrugserkennung und Risikoermittlung
Betrugsdetektion profitiert, weil verdächtiges Verhalten selten isoliert ist. Konten, Geräte, Transaktionen, Telefonnummern, E‑Mails und Adressen bilden Netze geteilter Identifikatoren. Ein Graph erleichtert das Erkennen von Ringen, wiederkehrenden Mustern und indirekten Links (z. B. zwei „unabhängige“ Konten, die über eine Kette von Aktivitäten dasselbe Gerät nutzen).
Netzwerk- und IT-Abhängigkeitskarten
Für Services, Hosts, APIs, Aufrufe und Besitzfragen ist die zentrale Frage Abhängigkeit: „Was fällt aus, wenn das hier geändert wird?“ Graphen unterstützen Impact-Analysen, Root-Cause-Untersuchungen und "Blast-Radius"-Abfragen, wenn Systeme miteinander verknüpft sind.
Wissensgraphen
Wissensgraphen verbinden Entitäten (Personen, Firmen, Produkte, Dokumente) mit Fakten und Referenzen. Das hilft bei Suche, Entitätsauflösung und beim Nachvollziehen, warum eine Aussage bekannt ist (Provenance) über viele verlinkte Quellen.
Häufige Graph-Fragen, die sich leicht beantworten lassen
Graphdatenbanken sind stark, wenn die Frage wirklich Verbindungen betrifft: wer ist mit wem verbunden, durch welche Ketten und welche Muster wiederholen sich. Anstatt Tabellen immer wieder zu joinen, fragst du die Beziehung direkt und hältst die Abfrage lesbar, während das Netzwerk wächst.
1) Pfadfindung: „Wie sind A und B verbunden?“
Typische Fragen:
- „Was ist der kürzeste Weg von diesem Kunden zu jenem Händler?“
- „Welche Kolleg:innen verbinden Alice und Bob und über wie viele Schritte?“
- „Zeige mir alle Routen von diesem Gerät zu jenem Konto innerhalb von 3 Hops.“
Das ist nützlich für Kundensupport („Warum haben wir das empfohlen?“), Compliance („Zeige die Besitzkette“) und Ermittlungen („Wie hat sich das verbreitet?“).
Graphen helfen, natürliche Gruppierungen zu erkennen:
- „Welche Kunden bilden einen Cluster basierend auf geteilten Adressen, Telefonnummern und Geräten?“
- „Wo sind die dichten Communities in unserem Lieferantennetzwerk?“
Das kann zur Segmentierung, zum Auffinden von Betrugsgruppen oder zum Verständnis gemeinsamer Kaufmuster genutzt werden.
3) Zentralität und Einfluss: wichtige Knoten finden
Manchmal geht es nicht nur um „wer ist verbunden“, sondern um „wer ist am wichtigsten“:
- „Welches Konto liegt auf den meisten Pfaden zwischen anderen?“
- „Welches Produkt bildet die stärkste Brücke zwischen zwei Kundensegmenten?“
Solche zentralen Knoten weisen oft auf Influencer, kritische Infrastruktur oder Engpässe hin.
4) Pattern Matching: „Finde Dreiecke“ und „Finde verdächtige Ringe“
Graphen sind gut darin, wiederkehrende Formen zu suchen:
- Dreiecke: „A kennt B, B kennt C, und C kennt A.“
- Ringe: „Konten, die Geld in einer Schleife transferieren.“
In Cypher (einer verbreiteten Graph-Abfragesprache) kann ein Dreiecksmuster so aussehen:
MATCH (a)-[:KNOWS]->(b)-[:KNOWS]->(c)-[:KNOWS]->(a)
RETURN a,b,c
Auch wenn du nie selbst Cypher schreibst, zeigt das, warum Graph-Abfragen zugänglich sind: die Abfrage spiegelt das Bild im Kopf wider.
Graph vs. Relational: Der wirkliche Unterschied
Relationale Datenbanken sind großartig für das, wofür sie entworfen wurden: Transaktionen und gut strukturierte Datensätze. Wenn deine Daten sauber in Tabellen passen (Kunden, Bestellungen, Rechnungen) und du meist nach IDs, Filtern und Aggregaten abfragst, sind relationale Systeme oft die einfachste, sicherste Wahl.
Das Join-Problem ist nicht „Joins sind schlecht“ — es sind tiefe Joins
Joins sind in Ordnung, wenn sie gelegentlich und flach sind. Der Reibungspunkt entsteht, wenn deine wichtigsten Fragen ständig viele Joins über mehrere Tabellen erfordern.
Beispiele:
- „Welche Kunden kauften von Verkäufern, die über zwei Zwischenhändler mit diesem Lieferanten verbunden sind?“
- „Finde alle Geräte, die ein Netzwerk mit Geräten geteilt haben, die von den engen Kontakten dieses Kontos benutzt wurden.“
In SQL werden das lange Queries mit wiederholten Self-Joins und komplexer Logik. Sie lassen sich zudem schwieriger optimieren, je tiefer die Beziehungstiefe wird.
Graphen machen mehrstufige "Walks" zur First-Class-Operation
Graphdatenbanken speichern Beziehungen explizit, sodass Traversals über mehrere Schritte natürliche Operationen sind. Statt Tabellen zur Abfragezeit zusammenzustecken, wanderst du durch verbundene Knoten und Kanten.
Das bedeutet oft:
- Kürzere Abfragen für Multi-Hop-Muster (die Abfrage liest sich mehr wie die Frage)
- Vorhersehbarere Komplexität beim Erkunden variabler Pfadtiefen (z. B. 2–6 Hops)
Eine praktische Faustregel
Wenn dein Team häufig Multi-Hop-Fragen stellt — „verbunden mit“, „durch“, „im selben Netzwerk wie“, „innerhalb von N Schritten“ — lohnt sich das Überlegen eines Graphen. Wenn dein Kern-Workload hochvolumige Transaktionen, strikte Schemata, Reporting und einfache Joins sind, ist relational normalerweise die bessere Default-Entscheidung. Viele Systeme nutzen beides; siehe /blog/practical-architecture-graph-alongside-other-databases.
Wann eine Graphdatenbank das falsche Werkzeug ist
Pilot live schalten
Stelle dein Pilotprojekt bereit, damit Stakeholder echte Durchläufe ausprobieren und schnell Feedback geben können.
Graphen sind toll, wenn Beziehungen die Hauptsache sind. Wenn der Wert deiner App nicht davon abhängt, Verbindungen zu traversieren (wer-kennt-wen, wie Items zusammenhängen, Pfade, Nachbarschaften), kann ein Graph Komplexität ohne großen Nutzen hinzufügen.
Einfache CRUDs mit meist Einzelabrufen
Wenn die meisten Requests „get user by ID“, „update profile“, „create order“ sind und die benötigten Daten in einem Datensatz (oder einem vorhersehbaren, kleinen Satz von Tabellen) leben, ist eine Graphdatenbank oft unnötig. Du investierst Zeit in Modellierung von Knoten/Kanten, das Tunen von Traversals und eine neue Abfragesprache — während eine relationale DB diese Muster effizient mit vertrauten Werkzeugen handhabt.
Reporting/BI, das primär Aggregationen ist
Dashboards auf Basis von Summen, Durchschnitten und gruppierten Kennzahlen (Umsatz pro Monat, Bestellungen pro Region, Conversion nach Kanal) passen typischerweise besser zu SQL und spaltenorientierter Analytik als zu Graph-Abfragen. Graph-Engines können einige Aggregatsfragen beantworten, sind aber selten der einfachste oder schnellste Weg für schwere OLAP-Workloads.
Starke transaktionale Anforderungen und "SQL-native" Features
Wenn du auf ausgereifte SQL-Funktionalität angewiesen bist — komplexe Joins mit strikten Constraints, erweiterte Indexstrategien, Stored Procedures oder etablierte ACID-Pattern — sind relationale Systeme oft die natürliche Wahl. Viele Graph-Datenbanken unterstützen Transaktionen, aber Ökosystem und Betriebsparadigmen entsprechen nicht immer dem, was dein Team braucht.
Weitgehend unabhängige Datensätze mit wenigen Verknüpfungen
Wenn deine Daten größtenteils unabhängige Entitäten sind (Tickets, Rechnungen, Sensormessungen) mit minimalen Querverweisen, wirkt ein Graphmodell häufig erzwungen. In solchen Fällen lieber auf ein sauberes relationales Schema (oder ein Dokumentmodell) setzen und Graph nur dann in Betracht ziehen, wenn Beziehungsschwere Fragen relevant werden.
Eine gute Regel: Wenn du deine Top-Queries ohne Wörter wie „verbunden“, „Pfad“, „Nachbarschaft“ oder „empfehlen“ beschreiben kannst, ist ein Graph oft nicht die erste Wahl.
Trade-Offs, die du kennen solltest, bevor du dich entscheidest
Graphdatenbanken sind stark darin, Verbindungen schnell zu folgen — aber diese Stärke hat ihren Preis. Bevor du dich verpflichtest, ist es hilfreich zu wissen, wo Graphen weniger effizient, teurer oder einfach anders im Betrieb sind.
Graphdatenbanken speichern und indexieren Beziehungen häufig so, dass Hops schnell sind. Der Kompromiss: Sie können mehr Memory und Speicher benötigen als eine vergleichbare relationale Lösung, besonders wenn du Indizes für häufige Lookups hinzufügst und Beziehungdaten schnell verfügbar halten willst.
Nicht jede Abfrage wird schneller
Wenn dein Workload wie eine Tabellenkalkulation aussieht — große Table‑Scans, Reporting-Queries über Millionen von Zeilen oder schwere Aggregationen — kann ein Graph langsamer oder teurer sein. Graphen sind für Traversals optimiert („wer ist mit wem verbunden?“), nicht für das Durchrechnen großer unabhängiger Datensätze.
Operative Unterschiede
Betriebliche Komplexität kann ein echter Faktor sein. Backups, Skalierung und Monitoring unterscheiden sich von dem, was Teams von relationalen Systemen kennen. Manche Graph-Plattformen skalieren am besten durch größere Maschinen (Scale‑Up), andere unterstützen Scale‑Out, erfordern dann aber sorgfältige Planung in Bezug auf Konsistenz, Replikation und Abfragemuster.
Dein Team braucht Zeit, um neue Modellierungs- und Abfragemuster zu lernen (z. B. Property-Graph-Modell und Sprachen wie Cypher). Die Lernkurve ist überschaubar, aber trotzdem ein Kostenfaktor — vor allem, wenn etablierte SQL‑basierte Reporting‑Workflows ersetzt werden sollen.
Ein praktischer Ansatz: Graph dort einsetzen, wo Beziehungen das Produkt sind, und bestehende Systeme für Reporting, Aggregation und tabellarische Analytik behalten.
Grundlagen der Datenmodellierung: Knoten, Kanten und Schemata
Risikoarmen Pilot starten
Verwandle Fragen zu Beziehungen in Screens, APIs und Datenflüsse, die du diese Woche testen kannst.
Ein nützlicher Denkansatz: Knoten sind Dinge, Kanten sind Beziehungen zwischen Dingen. Personen, Konten, Geräte, Bestellungen, Produkte, Standorte — das sind Knoten. „Gekauft“, „eingeloggt von“, „arbeitet mit“, „ist Eltern von“ — das sind Kanten.
Property-Graph vs. RDF-Tripel
Die meisten produktorientierten Graphdatenbanken nutzen das Property-Graph-Modell: sowohl Knoten als auch Kanten können Eigenschaften (Key–Value-Felder) haben. Zum Beispiel kann eine Kante PURCHASED date, amount und channel speichern. Das macht es natürlich, „Beziehungen mit Details“ zu modellieren.
RDF repräsentiert Wissen als Tripel: subject – predicate – object. Es eignet sich gut für interoperable Vokabulare und das Verknüpfen von Daten über Systeme hinweg, verschiebt aber oft „Beziehungsdetails“ in zusätzliche Knoten/Tripel. Praktisch gesehen treibt RDF eher zu Standardontologien und SPARQL-Patterns, während Property-Graphs näher an der Anwendungsdatenmodellierung liegen.
Abfragesprachen in einfachen Worten
- Cypher (beliebt bei Property-Graphen) liest sich wie das Muster, das du finden willst: „(Customer)-[PURCHASED]->(Product).“
- Gremlin ist eher ein Schritt-für-Schritt-Traversal: starte hier, gehe Kanten entlang, filtere, aggregiere.
- SPARQL ist die Abfragesprache der RDF-Welt und matched Muster gegen Tripel oft unter Verwendung gemeinsamer Vokabulare.
Du musst die Syntax nicht gleich auswendig lernen — wichtig ist, dass Graph-Abfragen meist als Pfade und Muster ausgedrückt werden, nicht als Tabellen-Joins.
Was „Schema“ in Graphsystemen bedeutet
Graphen sind oft schemaflexibel, du kannst neue Knoten-Labels oder Eigenschaften hinzufügen, ohne aufwändige Migrationen. Flexibilität braucht trotzdem Disziplin: definiere Namenskonventionen, erforderliche Eigenschaften (z. B. id) und Regeln für Beziehungstypen.
Beziehungstypen, Richtung und Eigenschaften
Wähle Beziehungstypen, die Bedeutung erklären („FRIEND_OF“ vs. „CONNECTED“). Nutze Richtung, um Semantik zu klären (z. B. FOLLOWS vom Follower zum Creator), und füge Kanten-Eigenschaften hinzu, wenn die Beziehung eigene Fakten hat (Zeit, Confidence, Rolle, Gewicht).
Wie du entscheidest, ob dein Problem beziehungsgetrieben ist
Ein Problem ist „beziehungsgetrieben“, wenn das Schwierige nicht das Speichern von Datensätzen ist — sondern zu verstehen, wie Dinge verbunden sind und wie diese Verbindungen ihre Bedeutung anhand des gewählten Pfads ändern.
Fang mit Fragen an, nicht mit Tabellen
Schreibe zuerst deine Top-5–10 Fragen in Klartext — die, die Stakeholder immer wieder stellen und die das aktuelle System langsam oder inkonsistent beantwortet. Gute Graph-Kandidaten enthalten oft Formulierungen wie „verbunden mit“, „durch“, „ähnlich zu“, „innerhalb N Schritte“ oder „wer sonst“.
Beispiele:
- „Welche Kunden sind über gemeinsame Geräte und Adressen mit diesem Betrugsring verbunden?“
- „Welche Produkte werden oft zusammen gekauft von Leuten, die auch X angesehen haben?“
- „Welche Lieferanten sind indirekt betroffen, wenn diese Fabrik ausfällt?“
Übersetze die Frage in Entitäten und Interaktionen
Sobald du Fragen hast, mappe Nomen und Verben:
- Wichtige Entitäten werden Knoten (Customer, Account, Device, Product, Supplier).
- Interaktionen werden Beziehungen (PAID_WITH, LOGGED_IN_FROM, BOUGHT, SUPPLIES).
Entscheide dann, was Beziehung vs. Knoten sein muss. Eine praktische Regel: Wenn etwas eigene Attribute braucht und du mehrere Parteien damit verbinden willst, mach es zum Knoten (z. B. eine Order oder ein Login-Ereignis kann ein Knoten sein).
Filterung und Scoring einfach machen
Füge Eigenschaften hinzu, die es erlauben, Ergebnisse einzugrenzen und Relevanz zu bewerten, ohne zusätzliche Joins oder Nachverarbeitung. Typische Hochwert-Eigenschaften sind Zeit, Betrag, Status, Kanal und Confidence-Score.
Wenn die meisten wichtigen Fragen mehrstufige Verbindungen plus Filterung nach solchen Eigenschaften erfordern, hast du vermutlich ein beziehungsgetriebenes Problem, bei dem Graphen glänzen.
Praktische Architektur: Graph neben anderen Datenbanken
Die meisten Teams ersetzen nicht alles durch einen Graphen. Ein pragmatischer Ansatz ist, die "Source of Truth" dort zu belassen, wo sie gut funktioniert (oft SQL), und eine Graphdatenbank als spezialisierten Motor für verbindungsintensive Fragen zu nutzen.
Behalte das System of Record in SQL (oder deinem Kerndatenspeicher)
Verwende die relationale DB für Transaktionen, Constraints und kanonische Entitäten (Kunden, Bestellungen, Konten). Projiziere dann eine relationale Sicht in einen Graphen — nur die Knoten und Kanten, die du für verknüpfungsbasierte Abfragen brauchst.
So bleibt Auditing und Data Governance überschaubar, während du schnelle Traversal-Abfragen ermöglichst.
Baue den Graphen für ein Feature, nicht für die ganze Firma
Ein Graph eignet sich besonders, wenn du ihn an ein klar abgegrenztes Feature hängst, z. B.:
- Empfehlungen („Leute, die X kauften, kauften auch Y“)
- Risiko-Scoring (Betrugsringe, geteilte Geräte, gemeinsame Zahlungsmittel)
- Identitätsauflösung (Profile über Systeme hinweg verknüpfen)
Starte mit einem Feature, einem Team und einem messbaren Ergebnis. Du kannst später erweitern, wenn sich der Mehrwert bewährt.
Wenn dein Engpass das schnelle Prototyping ist, kann eine vibe-coding Plattform wie Koder.ai helfen, eine einfache graphgestützte App schnell aufzusetzen: du beschreibst das Feature im Chat, generierst eine React-UI und Go/PostgreSQL-Backend und iterierst, während dein Datenteam das Graphschema und die Queries validiert.
Sync-Strategien: Batch vs. Near‑Realtime
Wie aktuell muss der Graph sein?
- Batch-Updates (stündlich/nachts) sind einfacher und oft ausreichend für Analytik, Discovery und viele Empfehlungssysteme.
- Near‑Realtime-Streams (Minuten/Sekunden) passen zu Betrugserkennung und operativen Entscheidungen.
Ein gängiges Muster: schreibe Transaktionen in SQL → publiziere Change-Events → aktualisiere den Graphen.
Konsistente IDs und klare Ownership
Graphen werden unübersichtlich, wenn IDs driftet.
Definiere stabile Identifikatoren (z. B. customer_id, account_id), die in allen Systemen übereinstimmen, und dokumentiere, wer welches Feld und welche Beziehung „besitzt“. Wenn zwei Systeme dieselbe Kante erzeugen können (z. B. „knows“), entscheide, welches System Vorrang hat.
Wenn du ein Pilotprojekt planst, sieh /blog/getting-started-a-low-risk-pilot-plan für einen gestuften Rollout-Ansatz.
Erste Schritte: Ein Pilot mit geringem Risiko
Sicher iterieren
Experimentiere mit stark graphbezogenen Änderungen und rolle sie zurück, falls dein Modell neu gedacht werden muss.
Ein Graph-Pilot sollte sich wie ein Experiment anfühlen, nicht wie ein Rewrite. Ziel ist, zu beweisen (oder zu widerlegen), dass verbindungsintensive Queries einfacher und schneller werden — ohne die gesamte Datenlandschaft zu riskieren.
1) Wähle einen kleinen, wertvollen Ausschnitt
Starte mit einem begrenzten Datenset, das bereits Probleme verursacht: zu viele JOINs, fragile SQL oder langsame „wer ist mit wem verbunden?“-Fragen. Begrenze es auf einen Workflow (z. B. customer ↔ account ↔ device oder user ↔ product ↔ interaction) und definiere eine Handvoll Queries, die Ende-zu-Ende beantwortet werden sollen.
2) Definiere Erfolgsmessungen, bevor du baust
Miss mehr als nur Geschwindigkeit:
- Query-Komplexität: Wie viele Zeilen, Joins oder Zwischentabellen braucht die Abfrage heute vs. im Graph?
- Latenz: Zeit bis zur Ergebnisrückgabe bei realistischen Datenvolumina.
- Developer-Zeit: Wie lange dauert es, Queries zu bauen und bei geänderten Anforderungen anzupassen?
Wenn du die „Vorher“-Zahlen nicht benennst, wirst du dem „Nachher“ nicht vertrauen.
3) Modell bewusst halten (Graph-Sprawl vermeiden)
Es ist verlockend, alles als Knoten und Kante zu modellieren. Widerstehe dem. Achte auf "Graph-Sprawl": zu viele Labels und Beziehungstypen ohne klare Abfragen, die sie benötigen. Jedes neue Label oder jede neue Beziehung sollte sich durch eine echte Frage rechtfertigen.
4) Governance als Teil des Piloten behandeln
Plane Datenschutz, Zugriffskontrolle und Datenlöschung früh. Beziehungdaten können mehr offenbaren als Einzelaufzeichnungen (z. B. Verbindungen, die Verhalten implizieren). Definiere, wer was abfragen darf, wie Ergebnisse geprüft werden und wie Daten bei Bedarf gelöscht werden.
5) Parallel zum bestehenden System betreiben
Nutze eine einfache Synchronisation (Batch oder Streaming), um den Graphen zu füttern, während dein bestehendes System die Quelle der Wahrheit bleibt. Wenn der Pilot Mehrwert zeigt, kannst du den Umfang schrittweise erweitern — vorsichtig, Use Case für Use Case.
Schnell-Entscheidungs-Checkliste: Graph für Beziehungen
Wenn du eine Datenbank wählst, fang nicht mit der Technologie an — fang mit den Fragen an. Graphdatenbanken glänzen, wenn deine schwersten Probleme um Verbindungen und Pfade gehen, nicht nur ums Speichern von Datensätzen.
Kurze „Ist das beziehungsgetrieben?“-Checkliste
Verwende diese Punkte zur Einschätzung, bevor du investierst:
- Beziehungstiefe: Musst du routinemäßig Beziehungen 2+ Hops (A→B→C→D) folgen, um Antworten zu bekommen?
- Query-Muster: Drehen sich die Kernfragen um Muster (z. B. „Leute, die denselben Arbeitgeber und dieselbe Telefonnummer teilen“) statt um Einzel-Tabellen-Filter?
- Update-Frequenz: Ändern sich Beziehungen häufig (neue Verbindungen, Löschungen, Rollenwechsel) und müssen diese Änderungen schnell reflektiert werden?
- Skalierung: Ist das Dataset groß genug, dass viele Joins (oder Stitching in Anwendungscode) langsam, teuer oder fragil werden?
Wenn du bei den meisten Punkten „Ja“ geantwortet hast, ist ein Graph eine starke Option — besonders für Multi-Hop-Pattern-Matching wie:
- „Finde den kürzesten Pfad zwischen zwei Entitäten.“
- „Zeige alle Konten, die mit diesem Gerät innerhalb von 3 Schritten verbunden sind.“
- „Empfehle Artikel basierend auf gemeinsamen Nachbarn, nicht nur Kategorien.“
Wann du bei SQL/NoSQL bleiben solltest
Wenn dein Alltag vorwiegend aus einfachen Lookups (nach ID/Email) oder Aggregationen („Umsatz pro Monat“) besteht, ist eine relationale Datenbank oder ein Key-Value-/Dokumenten-Store normalerweise einfacher und günstiger zu betreiben.
Wie du die Entscheidung entschärfst
Schreib deine Top‑10 Geschäftsfragen als einfache Sätze auf und teste sie an realen Daten in einem kleinen Pilot. Miss die Queries, notiere, was schwer auszudrücken ist, und protokolliere Änderungen am Modell. Wenn dein Pilot hauptsächlich zu „mehr Joins“ oder „mehr Caching“ führt, ist das ein Signal, dass ein Graph lohnen könnte. Wenn es vor allem Zählungen und Filter sind, wahrscheinlich nicht.