26. Dez. 2025·7 Min
Interne Entwickler-Tools mit Claude Code: sichere CLI-Dashboards
Bauen Sie interne Entwickler-Tools mit Claude Code, um Log-Suche, Feature-Toggles und Datenprüfungen zu lösen – und dabei Prinzip der geringsten Rechte sowie klare Schutzvorkehrungen durchzusetzen.
Welches Problem Ihr internes Tool tatsächlich lösen sollte
Interne Tools entstehen oft als Abkürzung: ein Befehl oder eine Seite, die dem Team während eines Vorfalls 20 Minuten spart. Das Risiko ist, dass dieselbe Abkürzung unbemerkt zu einer privilegierten Hintertür wird, wenn Sie das Problem und die Grenzen nicht von Anfang an definieren.
Teams greifen normalerweise dann zu einem Tool, wenn der gleiche Schmerz jeden Tag wiederkehrt, zum Beispiel:
- Langsame, inkonsistente oder über Systeme verteilte Log-Suche
- Feature-Toggles, die eine riskante manuelle Änderung oder ein direktes Schreiben in die Datenbank erfordern
- Datenprüfungen, die davon abhängen, dass eine Person ein Skript von ihrem Laptop ausführt
- On-Call-Aufgaben, die einfach sind, bei 2 Uhr nachts aber leicht schiefgehen können
Diese Probleme wirken klein, bis das Tool Produktionslogs lesen, Kundendaten abfragen oder einen Schalter umlegen kann. Dann geht es um Zugriffskontrolle, Audit-Trails und versehentliche Schreibvorgänge. Ein Tool, das „nur für Entwickler“ gedacht ist, kann trotzdem einen Ausfall verursachen, wenn es eine breite Abfrage fährt, die falsche Umgebung trifft oder den Zustand ohne klare Bestätigung ändert.
Definieren Sie Erfolg eng und messbar: schnellere Abläufe, ohne Berechtigungen zu erweitern. Ein gutes internes Tool entfernt Schritte, nicht Schutzmaßnahmen. Anstatt allen breiten Datenbankzugriff zu geben, damit sie ein vermutetes Abrechnungsproblem prüfen, bauen Sie ein Tool, das eine Frage beantwortet: „Zeige mir die fehlgeschlagenen Abrechnungsereignisse von heute für Konto X“ – mit ausschließlich lesenden, eingeschränkten Zugangsdaten.
Bevor Sie eine Schnittstelle wählen, entscheiden Sie, was die Leute im Moment brauchen. Eine CLI ist großartig für wiederholbare Aufgaben während des On-Calls. Ein Web-Dashboard ist besser, wenn Ergebnisse Kontext und gemeinsame Sichtbarkeit brauchen. Manchmal liefern Sie beides aus, aber nur, wenn sie dünne Ansichten über dieselben geschützten Operationen sind. Das Ziel ist eine klar definierte Fähigkeit, nicht eine neue Admin-Oberfläche.
Wählen Sie einen einzelnen Schmerzpunkt und halten Sie den Umfang klein
Der schnellste Weg, ein internes Tool nützlich (und sicher) zu machen, ist, eine klare Aufgabe zu wählen und sie gut zu erledigen. Wenn es von Tag eins Logs, Feature-Flags, Datenreparaturen und Benutzerverwaltung abdecken soll, bekommt es versteckte Verhaltensweisen und überrascht Leute.
Starten Sie mit einer einzigen Frage, die ein Benutzer während der tatsächlichen Arbeit stellt. Zum Beispiel: „Zeige mir zu einer Request-ID den Fehler und die umgebenden Zeilen über Services hinweg.“ Das ist eng, testbar und leicht zu erklären.
Seien Sie explizit, für wen das Tool gedacht ist. Ein Entwickler, der lokal debuggt, braucht andere Optionen als jemand auf Schicht, und beide unterscheiden sich von Support oder Analysten. Wenn Sie Zielgruppen mischen, fügen Sie am Ende „mächtige“ Befehle hinzu, die die meisten Benutzer nie anfassen sollten.
Schreiben Sie Eingaben und Ausgaben wie einen kleinen Vertrag auf.
Eingaben sollten explizit sein: Request-ID, Zeitbereich, Umgebung. Ausgaben sollten vorhersehbar sein: gefundene Zeilen, Service-Name, Timestamp, Zähler. Vermeiden Sie versteckte Nebenwirkungen wie „löscht auch Cache“ oder „versucht den Job erneut“. Genau das sind die Funktionen, die Unfälle verursachen.
Standardmäßig nur lesen. Sie können dem Tool mit Suche, Diff, Validierung und Report dennoch Wert geben. Fügen Sie Schreibaktionen nur hinzu, wenn Sie ein reales Szenario benennen können, das sie benötigt, und Sie es eng einschränken können.
Eine einfache Umfangsregel, die Teams auf Kurs hält:
- Eine Hauptaufgabe, ein Hauptbildschirm oder -befehl
- Eine Datenquelle (oder eine logische Sicht), nicht „alles“
- Explizite Flags für Umgebung und Zeitbereich
- Zuerst nur lesen, keine Hintergrundaktionen
- Falls Schreibvorgänge existieren: Bestätigung erforderlich und jede Änderung protokollieren
Datenquellen und sensible Operationen früh kartieren
Bevor Claude Code irgendetwas schreibt, notieren Sie, was das Tool berühren wird. Die meisten Sicherheits- und Zuverlässigkeitsprobleme tauchen hier auf, nicht in der UI. Behandeln Sie diese Karte als Vertrag: Sie sagt den Prüfern, was im Umfang ist und was tabu bleibt.
Beginnen Sie mit einem konkreten Inventar der Datenquellen und Owner. Zum Beispiel: Logs (App, Gateway, Auth) und wo sie liegen; die genauen Datenbanktabellen oder Views, die das Tool abfragen darf; Ihr Feature-Flag-Store und Namensregeln; Metriken und Traces und welche Labels sicher sind; und ob Sie planen, Notizen an Ticket- oder Incident-Systeme zu schreiben.
Benennen Sie dann die zulässigen Operationen. Vermeiden Sie „Admin“ als Permission. Definieren Sie stattdessen auditierbare Verben. Übliche Beispiele sind: read-only search und export (mit Limits), annotate (Note hinzufügen ohne History zu ändern), bestimmte Flags umschalten mit TTL, begrenzte Backfills (Datumsspanne und Anzahl Datensätze) und Dry-Run-Modi, die die Auswirkungen zeigen ohne Daten zu ändern.
Sensible Felder brauchen explizite Behandlung. Entscheiden Sie, was maskiert werden muss (E-Mails, Tokens, Session-IDs, API-Keys, Kundenkennungen) und was nur abgeschnitten gezeigt werden darf. Zum Beispiel: nur die letzten 4 Zeichen einer ID zeigen oder sie konsistent hashen, damit Ereignisse korreliert werden können, ohne den Rohwert zu sehen.
Stimmen Sie schließlich Aufbewahrungs- und Audit-Regeln ab. Wenn ein Benutzer eine Abfrage ausführt oder einen Flag umlegt, protokollieren Sie wer es tat, wann, welche Filter benutzt wurden und die Ergebnisanzahl. Bewahren Sie Audit-Logs länger als App-Logs auf. Selbst eine einfache Regel wie „Abfragen 30 Tage, Audit-Records 1 Jahr“ verhindert schmerzhafte Debatten während eines Vorfalls.
Prinzip der geringsten Rechte – einfach halten
Das Prinzip der geringsten Rechte ist am einfachsten, wenn Sie das Modell langweilig halten. Listen Sie zunächst auf, was das Tool tun kann, und kennzeichnen Sie jede Aktion als read-only oder write. Die meisten internen Tools brauchen für die meisten Personen nur Lesezugriff.
Für ein Web-Dashboard verwenden Sie Ihr bestehendes Identity-System (SSO mit OAuth). Vermeiden Sie lokale Passwörter. Für eine CLI bevorzugen Sie kurzlebige Tokens, die schnell verfallen und nur auf die Aktionen beschränkt sind, die der Benutzer braucht. Lang lebende, geteilte Tokens landen oft in Tickets, Shell-History oder auf persönlichen Rechnern.
Halten Sie RBAC klein. Wenn Sie mehr als ein paar Rollen brauchen, tut das Tool wahrscheinlich zu viel. Viele Teams kommen mit drei Rollen gut zurecht:
- Viewer: nur lesen, sichere Defaults
- Operator: lesen plus eine kleine Menge risikoarmer Aktionen
- Admin: risikoreiche Aktionen, selten genutzt
Trennen Sie Umgebungen früh, auch wenn die UI gleich aussieht. Machen Sie es schwer, „versehentlich in prod zu handeln“. Verwenden Sie unterschiedliche Zugangsdaten pro Umgebung, unterschiedliche Konfigurationsdateien und unterschiedliche API-Endpunkte. Wenn ein Benutzer nur staging unterstützt, sollte er sich gar nicht gegen production authentifizieren können.
Risikoarme Aktionen verdienen einen Freigabeschritt. Denken Sie an Löschen von Daten, Flag-Änderungen, Neustarts von Services oder schwere Abfragen. Fügen Sie eine zweite Person hinzu, wenn die Blast-Region groß ist. Praktische Muster sind getippte Bestätigungen, die das Ziel enthalten (Service-Name und Umgebung), protokollieren wer angefragt und wer genehmigt hat, und eine kurze Verzögerung oder geplante Fenster für sehr gefährliche Operationen.
Wenn Sie das Tool mit Claude Code generieren, machen Sie es zur Regel, dass jeder Endpoint und Befehl seine erforderliche Rolle von Anfang an deklariert. Diese Gewohnheit hält Berechtigungsprüfungen überschaubar, während das Tool wächst.
Schutzvorkehrungen, die Unfälle und schlechte Abfragen verhindern
Schnell ein kleines CLI ausliefern
Prototypen Sie einen engen On-Call-Workflow und behalten Sie das Verhalten leicht überprüfbar.
Der häufigste Fehlermodus für interne Tools ist kein Angreifer. Es ist ein müder Kollege, der den „richtigen“ Befehl mit falschen Eingaben ausführt. Behandeln Sie Guardrails als Produktfunktion, nicht als Feinschliff.
Sicherheitsvorgaben
Starten Sie mit einer sicheren Grundhaltung: standardmäßig nur lesen. Selbst wenn der Benutzer Admin ist, sollte das Tool in einem Modus öffnen, der nur Daten abruft. Schreibaktionen sollten opt-in und offensichtlich sein.
Für jede Operation, die den Zustand ändert (Flag umlegen, Backfill, Datensatz löschen), verlangen Sie eine explizite Type-to-confirm. „Sind Sie sicher? y/N“ ist zu leicht durch Muskelgedächtnis zu bestätigen. Bitten Sie den Benutzer, etwas Spezifisches einzugeben, wie den Umgebungsnamen plus die Ziel-ID.
Strenge Eingabevalidierung verhindert die meisten Katastrophen. Akzeptieren Sie nur die Formen, die Sie wirklich unterstützen (IDs, Daten, Umgebungen) und lehnen Sie alles andere früh ab. Bei Suchen begrenzen Sie die Macht: begrenzen Sie Ergebnisgrößen, erzwingen Sie sinnvolle Zeitspannen und verwenden Sie eine Allow-List statt beliebiger Patterns gegen Ihren Log-Store.
Um Ausreißer-Abfragen zu vermeiden, fügen Sie Timeouts und Ratenbegrenzungen hinzu. Ein sicheres Tool schlägt schnell fehl und erklärt warum, anstatt zu hängen und die Datenbank zu überlasten.
Ein Satz von Guardrails, der sich gut bewährt hat:
- Standardmäßig read-only, mit einem klaren „Write-Mode“-Schalter
- Type-to-confirm für Schreibvorgänge (inkl. env + Ziel)
- Strikte Validierung für IDs, Daten, Limits und erlaubte Patterns
- Abfrage-Timeouts plus per-User-Rate-Limits
- Maskierung von Secrets in Ausgabe und in internen Logs
Ausgabepflege
Gehen Sie davon aus, dass die Ausgabe des Tools in Tickets und Chats kopiert wird. Maskieren Sie Secrets standardmäßig (Tokens, Cookies, API-Keys und bei Bedarf E-Mails). Säubern Sie auch, was Sie speichern: Audit-Logs sollten dokumentieren, was versucht wurde, nicht die rohen zurückgegebenen Daten.
Für ein Log-Such-Dashboard geben Sie zuerst eine kurze Vorschau und eine Anzahl zurück, nicht die vollständigen Payloads. Wenn jemand wirklich das komplette Event braucht, machen Sie daraus eine separate, deutlich gegated Aktion mit eigener Bestätigung.
Wie Sie mit Claude Code arbeiten, ohne die Kontrolle zu verlieren
Behandeln Sie Claude Code wie einen schnellen Junior-Kollegen: hilfreich, aber kein Gedankenleser. Ihre Aufgabe ist es, die Arbeit begrenzt, prüfbar und leicht rückgängig zu machen. Das ist der Unterschied zwischen Tools, die sicher wirken, und Tools, die Sie um 2 Uhr nachts überraschen.
Beginnen Sie mit einer Spezifikation, der das Modell folgen kann
Bevor Sie nach Code fragen, schreiben Sie eine kleine Spezifikation, die die Benutzeraktion und das erwartete Ergebnis benennt. Beschränken Sie sich auf Verhalten, nicht auf Framework-Details. Eine gute Spezifikation passt meist auf eine halbe Seite und deckt ab:
- Befehle oder Bildschirme (exakte Namen)
- Eingaben (Flags, Felder, Formate, Limits)
- Ausgaben (was angezeigt wird, was gespeichert wird)
- Fehlerfälle (ungültige Eingabe, Timeouts, leere Ergebnisse)
- Berechtigungsprüfungen (was passiert, wenn Zugriff verweigert wird)
Zum Beispiel: Wenn Sie eine Log-Search-CLI bauen, definieren Sie einen Befehl von Anfang bis Ende: logs search --service api --since 30m --text \"timeout\", mit einer harten Begrenzung der Ergebnisse und einer klaren „Kein Zugriff“-Meldung.
Fordern Sie kleine Inkremente zur Verifikation an
Bitten Sie zuerst um ein Gerüst: CLI-Wiring, Config-Laden und einen gestubten Datenaufruf. Dann fordern Sie genau eine Funktion vollständig umgesetzt an (inklusive Validierung und Fehlern). Kleine Diffs machen Reviews real.
Nach jeder Änderung verlangen Sie eine einfache, klare Erklärung in Alltagssprache, was sich geändert hat und warum. Wenn die Erklärung nicht zum Diff passt, stoppen Sie und formulieren Verhalten und Sicherheitsgrenzen neu.
Generieren Sie Tests früh, bevor Sie mehr Features hinzufügen. Mindestens sollten Happy Path, ungültige Eingaben (schlechte Daten, fehlende Flags), Permission Denied, leere Ergebnisse und Rate-Limit- oder Backend-Timeouts abgedeckt sein.
CLI vs. Web-Dashboard: die richtige Schnittstelle wählen
CLI und internes Web-Dashboard können dasselbe Problem lösen, sie fallen aber auf unterschiedliche Weise. Wählen Sie die Oberfläche, die den sicheren Pfad zum einfachsten Pfad macht.
Eine CLI ist meist am besten, wenn Geschwindigkeit zählt und der Benutzer schon weiß, was er will. Sie passt auch gut zu read-only-Workflows, weil Sie Berechtigungen eng halten und Buttons vermeiden können, die unbeabsichtigt Schreibaktionen auslösen.
Eine CLI ist eine starke Wahl für schnelle On-Call-Abfragen, Skripting und Automatisierung, explizite Audit-Trails (jeder Befehl ist dokumentiert) und einfachen Rollout (ein Binary, eine Config).
Ein Web-Dashboard ist besser, wenn gemeinsame Sichtbarkeit oder geführte Schritte nötig sind. Es reduziert Fehler, indem es Menschen zu sicheren Defaults wie Zeitbereichen, Umgebungen und vorab genehmigten Aktionen lenkt. Dashboards eignen sich außerdem für teamweite Übersichten, geschützte Aktionen mit Bestätigung und eingebaute Erklärungen, was ein Button bewirkt.
Wenn möglich, verwenden Sie dasselbe Backend-API für beides. Legen Sie Auth, Rate-Limits, Abfrage-Limits und Audit-Logging in dieses API, nicht in die UI. Dann werden CLI und Dashboard zu unterschiedlichen Clients mit unterschiedlichen Ergonomien.
Entscheiden Sie auch, wo das Tool läuft, denn das ändert Ihr Risiko. Eine CLI auf einem Laptop kann Tokens leaken. Sie auf einer Bastion oder in einem internen Cluster laufen zu lassen, kann die Exposition verringern und Logs sowie Policy-Enforcement vereinfachen.
Beispiel: Für Log-Suche ist eine CLI großartig für eine On-Call-Ingenieurin, die die letzten 10 Minuten für einen Service holt. Ein Dashboard ist besser für einen gemeinsamen Incident-Raum, in dem alle dieselbe gefilterte Ansicht brauchen, plus eine geführte „Export für Postmortem“-Aktion, die permission-checked ist.
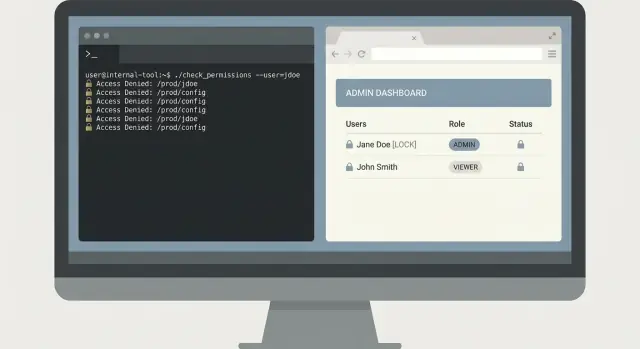
Ein realistisches Beispiel: Log-Search-Tool für On-Call
Wählen Sie Dashboard statt Skripten
Erstellen Sie ein React-Dashboard mit einem Go-Backend, wenn eine Web-Oberfläche die sicherere Wahl ist.
Es ist 02:10 und der On-Call erhält die Meldung: „Beim Klick auf Bezahlen tritt manchmal ein Fehler für einen Kunden auf.“ Support hat einen Screenshot mit einer Request-ID, aber niemand möchte zufällige Abfragen in ein Log-System mit Admin-Rechten einfügen.
Ein kleines CLI kann das sicher lösen. Entscheidend ist, es eng zu halten: den Fehler schnell finden, nur das Notwendige zeigen und Produktionsdaten unangetastet lassen.
Ein minimaler CLI-Fluss
Starten Sie mit einem Befehl, der Zeitgrenzen und eine spezifische Kennung erzwingt. Fordern Sie eine Request-ID und ein Zeitfenster an und setzen Sie standardmäßig ein kurzes Fenster.
oncall-logs search --request-id req_123 --since 30m --until now
Geben Sie zuerst eine Zusammenfassung zurück: Service-Name, Error-Klasse, Anzahl und die Top-3 passenden Meldungen. Erlauben Sie dann einen expliziten Expand-Schritt, der vollständige Log-Zeilen nur druckt, wenn der Benutzer danach fragt.
oncall-logs show --request-id req_123 --limit 20
Dieses Zwei-Schritt-Design verhindert versehentliche Datenlecks. Es erleichtert auch Reviews, weil das Tool einen klaren Safe-by-Default-Pfad hat.
Optionale Folgeaktion (kein Schreiben)
On-Call muss oft eine Spur für die nächste Person hinterlassen. Statt in die Datenbank zu schreiben, fügen Sie eine optionale Aktion hinzu, die eine Ticket-Note erzeugt oder einen Tag im Incident-System anlegt, aber niemals Kundendaten berührt.
Um Least Privilege zu wahren, sollte die CLI ein read-only Log-Token verwenden und ein separates, eingeschränktes Token für die Ticket- oder Tag-Aktion.
Speichern Sie für jeden Lauf einen Audit-Eintrag: wer es ausgeführt hat, welche Request-ID, welche Zeitgrenzen verwendet wurden und ob Details expandiert wurden. Dieses Audit-Log ist Ihr Sicherheitsnetz, wenn etwas schiefgeht oder Zugriff überprüft werden muss.
Häufige Fehler, die Sicherheits- und Zuverlässigkeitsprobleme erzeugen
Kleine interne Tools beginnen oft als „schnelle Helfer“. Genau deshalb enden sie mit riskanten Defaults. Der schnellste Weg, Vertrauen zu verlieren, ist ein schlechter Vorfall, etwa ein Tool, das Daten löscht, obwohl es nur lesen sollte.
Die Fehler, die am häufigsten auftreten:
- Dem Tool Produktionsdatenbank-Schreibzugriff geben, obwohl es nur Lesezugriff braucht, und dann auf „wir sind vorsichtig“ vertrauen
- Auf Audit-Trails verzichten, sodass später niemand beantworten kann, wer einen Befehl ausführte, welche Eingaben benutzt wurden und was sich änderte
- Freiform-SQL, Regex oder Ad-hoc-Filter erlauben, die versehentlich riesige Tabellen oder Logs scannen und Systeme zum Absturz bringen
- Umgebungen mischen, sodass Staging-Aktionen Prod erreichen, weil Konfigurationen, Tokens oder Basis-URLs geteilt werden
- Secrets im Terminal, Browser-Console oder Logs ausgeben und vergessen, dass diese Ausgaben in Tickets und Chats kopiert werden
Ein realistisches Versagen sieht so aus: Eine On-Call-Ingenieurin nutzt eine Log-Search-CLI während eines Vorfalls. Das Tool akzeptiert beliebige Regex und schickt sie an das Log-Backend. Ein teures Pattern läuft über Stunden hochvolumige Logs, treibt Kosten und verlangsamt Suchen für alle. In derselben Sitzung druckt die CLI ein API-Token im Debug-Output, das später in ein öffentliches Incident-Dokument eingefügt wird.
Sicherere Defaults, die die meisten Vorfälle verhindern
Behandeln Sie read-only als echte Sicherheitsgrenze, nicht als Gewohnheit. Verwenden Sie unterschiedliche Zugangsdaten pro Umgebung und unterschiedliche Service-Accounts pro Tool.
Ein paar Guardrails erledigen den Großteil der Arbeit:
- Erlaubte Abfragen (oder Templates) statt rohem SQL nutzen und Zeitspannen sowie Zeilenanzahl begrenzen
- Jede Aktion protokollieren mit Request-ID, Benutzeridentität, Zielumgebung und genauen Parametern
- Explizite Umgebungswahl verlangen, mit lauter Bestätigung für Produktion
- Secrets standardmäßig redigieren und Debug-Output deaktivieren, außer bei einem privilegierten Flag
Wenn das Tool von vornherein nichts Gefährliches tun kann, muss Ihr Team nicht auf perfekte Aufmerksamkeit in einem 3-Uhr-Nacht-Vorfall bauen.
Kurze Checkliste bevor Sie das Tool ausliefern
Iterieren ohne Überraschungen
Halten Sie Experimente getrennt, während Sie an Umfang, Validierung und sicheren Defaults iterieren.
Bevor Ihr internes Tool echte Benutzer erreicht (insbesondere On-Call), behandeln Sie es wie ein Produktionssystem. Bestätigen Sie, dass Zugriff, Berechtigungen und Sicherheitsgrenzen echt sind, nicht implizit.
Beginnen Sie mit Zugriff und Berechtigungen. Viele Unfälle passieren, weil „temporärer“ Zugriff permanent wird oder ein Tool stillschweigend Schreibrechte gewinnt.
- Auth und Offboarding: Bestätigen Sie, wer sich anmelden kann, wie Zugriff gewährt wird und wie er am selben Tag entzogen wird, wenn jemand das Team verlässt
- Rollen klein halten: 2–3 Rollen maximal (Viewer, Operator, Admin) und niederschreiben, was jede Rolle darf
- Standardmäßig nur lesen: Anzeigen ist der Standardpfad; für alles, was Daten ändert, ist eine explizite Rolle erforderlich
- Umgang mit Secrets: Tokens und Keys außerhalb des Repos speichern und sicherstellen, dass das Tool sie nicht in Logs oder Fehlermeldungen ausgibt
- Break-glass-Flow: Wenn Sie Notfallzugang brauchen, machen Sie ihn zeitlich begrenzt und protokolliert
Validieren Sie dann Guardrails, die gängige Fehler verhindern:
- Bestätigungen für riskante Aktionen: Getippte Bestätigungen für Deletes, Backfills oder Config-Änderungen
- Limits und Timeouts: Ergebnismengen begrenzen, Zeitfenster erzwingen und Abfragen zeitlich begrenzen, damit eine fehlerhafte Anfrage nicht ewig läuft
- Eingabevalidierung: IDs, Daten und Umgebungsnamen validieren; alles ablehnen, was wie „run everywhere“ aussieht
- Audit-Logs: Dokumentieren, wer was wann und von wo aus getan hat; Logs leicht durchsuchbar machen für Vorfälle
- Basis-Metriken und Fehler: Erfolgsrate, Latenz und Top-Fehlertypen messen, damit Sie Ausfälle früh bemerken
Führen Sie Change Control wie für jeden Service durch: Peer Review, ein paar fokussierte Tests für gefährliche Pfade und einen Rollback-Plan (inklusive Möglichkeit, das Tool schnell zu deaktivieren, wenn es sich falsch verhält).
Nächste Schritte: Sicher ausrollen und kontinuierlich verbessern
Behandeln Sie die erste Veröffentlichung wie ein kontrolliertes Experiment. Starten Sie mit einem Team, einem Workflow und einer kleinen Menge realer Aufgaben. Ein Log-Search-Tool für On-Call ist ein guter Pilot, weil Sie die eingesparte Zeit messen und risikoreiche Abfragen schnell erkennen können.
Halten Sie den Rollout planbar: Pilot mit 3–10 Nutzern, anfangen in Staging, Zugriff mit Least-Privilege-Rollen (nicht geteilte Tokens) gateen, klare Nutzungsgrenzen setzen und Audit-Logs für jeden Befehl oder Button-Click aufzeichnen. Stellen Sie sicher, dass Sie Konfigurationen und Berechtigungen schnell zurücksetzen können.
Schreiben Sie den Vertrag des Tools in klarer Sprache auf. Listen Sie jeden Befehl (oder Dashboard-Aktion), die erlaubten Parameter, was Erfolg bedeutet und was Fehler heißen. Menschen verlieren das Vertrauen in interne Tools, wenn Ausgaben mehrdeutig wirken, selbst wenn der Code korrekt ist.
Fügen Sie eine Feedback-Schleife hinzu, die Sie wirklich prüfen. Verfolgen Sie, welche Abfragen langsam sind, welche Filter häufig genutzt werden und welche Optionen Leute verwirren. Wenn Sie wiederkehrende Workarounds sehen, fehlt dem Interface meist ein sicheres Default.
Wartung braucht einen Owner und einen Plan. Entscheiden Sie, wer Dependencies aktualisiert, wer Credentials rotiert und wer gerufen wird, wenn das Tool während eines Vorfalls ausfällt. Überprüfen Sie KI-generierte Änderungen genauso wie jede Produktionsänderung: Berechtigungs-Diffs, Abfrage-Sicherheit und Logging.
Wenn Ihr Team lieber chatgetrieben iteriert, kann Koder.ai (koder.ai) ein praktischer Weg sein, aus einer Unterhaltung ein kleines CLI oder Dashboard zu generieren, Snapshots bekannter guter Zustände zu speichern und schnell zurückzusetzen, wenn eine Änderung Risiko einführt.