Joe Armstrong und Erlang: „Let‑it‑crash“-Prinzip für zuverlässige Plattformen
Erfahre, wie Joe Armstrong Erlangs Nebenläufigkeit, Supervision und das „let it crash“-Denken geprägt hat — Ideen, die noch immer genutzt werden, um verlässliche Echtzeit‑Dienste zu bauen.
Was dieser Beitrag abdeckt (und warum es noch wichtig ist)
Joe Armstrong hat nicht nur an Erlang mitgearbeitet — er wurde zu seinem klarsten und überzeugendsten Erklärer. Durch Vorträge, Papers und eine pragmatische Sichtweise popularisierte er eine einfache Idee: Wenn Software dauerhaft verfügbar bleiben soll, entwirfst du sie für Ausfälle, anstatt so zu tun, als ließen sich Ausfälle vermeiden.
Dieser Beitrag ist ein geführter Rundgang durch die Erlang‑Denkweise und erklärt, warum sie beim Bau zuverlässiger Echtzeit‑Plattformen weiterhin relevant ist – bei Systemen wie Chat, Call‑Routing, Live‑Benachrichtigungen, Multiplayer‑Koordination und Infrastruktur, die schnell und konsistent reagieren muss, auch wenn Teile davon fehlerhaft sind.
„Echtzeit“ einfach gesagt
Echtzeit heißt nicht immer „Mikrosekunden“ oder harte Deadlines. In vielen Produkten bedeutet es:
- spürbar schnelle Antworten (keine mysteriösen Pausen)
- vorhersehbares Verhalten unter Last (es kann langsamer werden, aber nicht ausufern)
- weiterlaufender Service bei partiellen Ausfällen (eine fehlerhafte Komponente darf nicht alles mitziehen)
Erlang wurde für Telekom‑Systeme gebaut, in denen diese Anforderungen unverhandelbar sind — und genau dieser Druck formte seine einflussreichsten Ideen.
Die drei Säulen, auf die wir uns konzentrieren
Statt in die Syntax zu springen, betrachten wir die Konzepte, die Erlang berühmt machten und die in modernen Systemen immer wieder auftauchen:
- Nebenläufigkeit als Standard: Baue Software aus vielen kleinen, isolierten Arbeitern statt aus einigen wenigen riesigen.
- Fehlertoleranz als Designziel: Gehe davon aus, dass Bugs, Timeouts und Abstürze passieren — und plane, was dann geschehen soll.
- „Let it crash“: Verteidige nicht jede Codezeile übermäßig; versage schnell und stelle mit Struktur wieder her (statt mit Heldentaten).
Auf dem Weg verbinden wir diese Ideen mit dem Actor‑Modell und Message‑Passing, erklären Supervisionsbäume und OTP in zugänglichen Begriffen und zeigen, warum die BEAM‑VM das Ganze praktisch macht.
Selbst wenn du kein Erlang nutzt (und nie nutzen wirst), bleibt der Kern: Armstrongs Denkrahmen liefert eine hilfreiche Checkliste, um Systeme zu bauen, die unter realen Bedingungen reagibel und verfügbar bleiben.
Joe Armstrongs Motivation: Systeme bauen, die laufen
Telekommunikations‑Switches und Call‑Routing‑Plattformen können nicht einfach „für Wartung heruntergefahren“ werden wie viele Websites. Sie sollen rund um die Uhr Anrufe, Billing‑Ereignisse und Signalisierungs‑Traffic verarbeiten — oft mit strengen Verfügbarkeits‑ und Reaktionszeitvorgaben.
Erlang entstand Ende der 1980er bei Ericsson, um genau diese Realität mit Software (statt nur mit Spezialhardware) zu adressieren. Joe Armstrong und seine Kollegen jagten nicht der Eleganz um ihrer selbst willen hinterher; sie versuchten, Systeme zu bauen, denen Betreiber unter konstanter Last, partiellen Ausfällen und unordentlichen Realbedingungen vertrauen konnten.
Was „zuverlässig“ in der Praxis bedeutete
Ein entscheidender Mentalitätswechsel ist: Zuverlässigkeit heißt nicht „nie ausfallen“. In großen, lang laufenden Systemen fällt etwas aus: ein Prozess bekommt unerwartete Eingaben, ein Knoten rebootet, eine Netzverbindung ist instabil oder eine Abhängigkeit hängt.
Das Ziel wird also:
- Nutzer weiter bedienen, auch wenn Teile fehlerhaft sind
- Fehler schnell erkennen
- automatisch und mit minimaler menschlicher Intervention wiederherstellen
- Fehler isolieren, sodass ein Bug nicht alles mitnimmt
Diese Denkweise macht später Ideen wie Supervisionsbäume und „let it crash“ plausibel: Du planst für Ausfälle als normalen Ereignisfall, nicht als katastrophales Sonderereignis.
Weniger Mythos, mehr Problemlösung
Es ist verlockend, die Geschichte als Genie‑Durchbruch eines Einzelnen zu erzählen. Nützlicher ist eine einfachere Lesart: Telekom‑Beschränkungen erzwangen andere Trade‑offs. Erlang priorisierte Nebenläufigkeit, Isolation und Wiederherstellung, weil das die praktischen Werkzeuge waren, um Services am Laufen zu halten, während sich die Welt um sie herum änderte.
Diese Problem‑first‑Perspektive erklärt auch, warum Erlangs Lektionen heute noch übertragbar sind — überall dort, wo Verfügbarkeit und schnelle Erholung wichtiger sind als perfekte Prävention.
Nebenläufigkeit als Standard: Viele kleine Arbeiter
Eine Kernidee in Erlang ist, dass „viele Dinge gleichzeitig tun“ kein Sonderfeature ist, das man später anhängt — sondern die normale Art, ein System zu strukturieren.
Leichte Prozesse, einfach erklärt
In Erlang wird Arbeit in viele winzige „Prozesse“ aufgeteilt. Stell sie dir als kleine Arbeiter vor, die jeweils eine Aufgabe übernehmen: einen Anruf bearbeiten, eine Chatsitzung verfolgen, ein Gerät überwachen, eine Zahlung erneut versuchen oder eine Queue konsumieren.
Sie sind leichtgewichtig, sodass man sehr viele davon haben kann, ohne riesige Hardwareanforderungen. Statt einem schweren Arbeiter, der alles jongliert, hat man eine Menge fokussierter Arbeiter, die schnell starten, schnell stoppen und schnell ersetzt werden können.
Warum ein „großes Programm“ anders versagt
Viele Systeme sind wie ein einzelnes großes Programm mit vielen eng gekoppelten Teilen entworfen. Trifft so ein System ein ernsthaftes Problem, kann der Fehler weitreichend sein — wie das Auslösen einer Sicherung und das Abschalten des ganzen Hauses.
Erlang geht den entgegengesetzten Weg: Verantwortlichkeiten isolieren. Wenn ein kleiner Arbeiter sich falsch verhält, kann man ihn stoppen und ersetzen, ohne unbeteiligte Arbeit zu beeinflussen.
Message Passing wie „Zettelweitergabe"
Wie koordinieren sich diese Arbeiter? Sie wühlen nicht in den internen Zuständen der anderen. Sie schicken Nachrichten — eher wie Zettelweitergabe als das Arbeiten an einem gemeinsamen Whiteboard.
Ein Arbeiter kann sagen: „Neue Anfrage“, „Dieser Nutzer hat die Verbindung getrennt“ oder „Versuch in 5 Sekunden noch einmal“. Der Empfänger liest die Nachricht und entscheidet, was zu tun ist.
Der entscheidende Vorteil ist Eindämmung: Weil Arbeiter isoliert sind und per Nachrichten kommunizieren, breiten sich Fehler seltener systemweit aus.
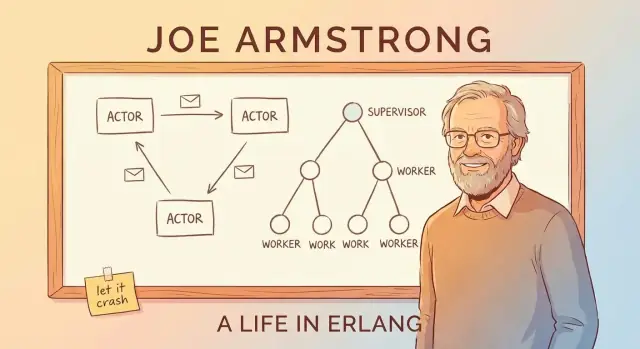
Message Passing und das Actor‑Modell (ohne Fachchinesisch)
Eine einfache Art, Erlangs Actor‑Modell zu verstehen: Stell dir ein System aus vielen kleinen, unabhängigen Arbeitern vor.
Akteure: winzige Arbeiter, die nur über Nachrichten reden
Ein Akteur ist eine in sich geschlossene Einheit mit eigenem privaten Zustand und einem Postfach. Er macht drei grundlegende Dinge:
- empfängt Nachrichten (eine nach der anderen) aus seinem Postfach
- aktualisiert seinen internen Zustand
- sendet Nachrichten an andere Akteure
Das ist alles. Keine versteckten geteilten Variablen, kein „in den Speicher eines anderen hineinpfuschen“. Wenn ein Akteur etwas von einem anderen braucht, fragt er per Nachricht.
Warum vermiedener gemeinsamer Zustand ganze Bugklassen eliminiert
Wenn mehrere Threads dieselben Daten teilen, entstehen Race‑Conditions: Zwei Dinge ändern denselben Wert nahezu gleichzeitig, und das Ergebnis hängt vom Timing ab. Das sind Fehler, die intermittierend und schwer reproduzierbar sind.
Mit Message Passing besitzt jeder Akteur seine Daten. Andere Akteure können sie nicht direkt verändern. Das beseitigt nicht alle Bugs, reduziert aber erheblich Probleme durch gleichzeitigen Zugriff auf dieselbe Zustandsmenge.
Back‑Pressure, wie eine Coffeeshop‑Schlange
Nachrichten kommen nicht „gratis“. Wenn ein Akteur Nachrichten schneller bekommt, als er sie verarbeiten kann, wächst sein Postfach. Das ist Back‑Pressure: Das System sagt dir indirekt, „dieser Teil ist überlastet“.
In der Praxis überwacht man Postfachgrößen und setzt Grenzen: Load shedding, Batchen, Sampling oder Arbeit auf mehr Akteure verteilen, statt Quests unendlich anwachsen zu lassen.
Ein konkretes Beispiel: Chat‑Benachrichtigungen
Stell dir eine Chat‑App vor. Jeder Benutzer könnte einen Akteur haben, der für das Liefern von Benachrichtigungen zuständig ist. Wenn ein Nutzer offline geht, treffen weiterhin Nachrichten ein — das Postfach wächst. Ein gut gestaltetes System könnte die Queue begrenzen, unwichtige Benachrichtigungen fallen lassen oder in einen Digest‑Modus wechseln, statt einen langsamen Nutzer den gesamten Service verschlechtern zu lassen.
„Let It Crash“ erklärt: Schnell fehlschlagen, schneller wiederherstellen
„Let it crash“ ist kein Freibrief für schlampiges Engineering. Es ist eine Zuverlässigkeitsstrategie: Wenn eine Komponente in einen schlechten oder unerwarteten Zustand gerät, soll sie schnell und deutlich stoppen, anstatt mühsam weiterzufunken.
Was es wirklich bedeutet
Statt in jedem Prozess jeden denkbaren Randfall zu behandeln, ermutigt Erlang dazu, jeden Arbeiter klein und fokussiert zu halten. Trifft dieser Arbeiter auf etwas, das er wirklich nicht handhaben kann (korrupter Zustand, verletzte Annahmen, unerwartete Eingabe), beendet er sich. Ein anderer Teil des Systems ist dafür verantwortlich, ihn wieder hochzufahren.
Das verschiebt die zentrale Frage von „Wie verhindern wir Fehler?“ zu „Wie stellen wir sauber wieder her, wenn ein Fehler passiert?"
Der Trade‑off: weniger Defensive Checks, klarere Logik
Überall defensiv programmieren verwandelt einfache Abläufe in ein Labyrinth aus Bedingungen, Retries und Teilszuständen. „Let it crash“ tauscht einen Teil dieser in‑Prozess‑Komplexität gegen:
- einfachere, lesbarere Codepfade
- schnellere Erkennung gebrochener Annahmen
- konsistente Wiederherstellung (weil sie zentralisiert ist)
Die große Idee: Wiederherstellung soll vorhersehbar und wiederholbar sein — nicht improvisiert in jeder Funktion.
Wann es passt — und wann nicht
Es passt am besten, wenn Fehler recoverable und isolierbar sind: ein temporäres Netzwerkproblem, eine schlechte Anfrage, ein festgefahrener Arbeiter oder ein Timeout einer Third‑Party.
Es passt nicht, wenn ein Absturz irreversible Schäden verursachen könnte, etwa:
- Datenverlust ohne durables Quelle der Wahrheit
- sicherheitskritische Operationen, bei denen „nochmal versuchen" nicht akzeptabel ist
Schnelle Neustarts und bekannter guter Zustand
Abstürze helfen nur, wenn das Wiederhochfahren schnell und sicher ist. Praktisch heißt das: Arbeiter müssen in einen bekannten, guten Zustand neu starten — oft durch Neuladen der Konfiguration, Wiederaufbau von In‑Memory‑Caches aus dauerhaftem Speicher und Fortsetzen, ohne so zu tun, als hätte es den fehlerhaften Zustand nie gegeben.
Supervisionsbäume: Für Ausfälle entwerfen
Erlangs „let it crash“ funktioniert nur, weil Abstürze nicht dem Zufall überlassen werden. Das zentrale Muster ist der Supervisionsbaum: Eine Hierarchie, in der Supervisoren wie Manager agieren und Worker die eigentliche Arbeit erledigen (Anrufe bearbeiten, Sitzungen tracken, Queues konsumieren etc.). Wenn ein Worker sich falsch verhält, bemerkt der Manager es und startet ihn neu.
Manager, die Worker neu starten
Ein Supervisor versucht nicht, einen defekten Worker vor Ort zu reparieren. Stattdessen gilt eine einfache, konsistente Regel: stirbt der Worker, starte einen frischen. So wird der Recovery‑Pfad vorhersehbar und die Notwendigkeit für improvisierte Fehlerbehandlung im Code reduziert.
Ebenso wichtig: Supervisoren entscheiden auch, wann nicht neu zu starten ist — wenn etwas zu häufig crasht, deutet das auf ein tieferes Problem hin, und ständiges Neustarten kann die Lage verschlimmern.
Neustartstrategien (oberflächlich)
Supervision ist kein One‑Size‑Fits‑All. Übliche Strategien sind:
- One‑for‑one: nur der fehlerhafte Worker wird neu gestartet. Passt zu unabhängigen Aufgaben.
- Gruppenneustart: wenn ein Worker fällt, werden verwandte Komponenten gemeinsam neu gestartet. Passt zu eng gekoppelten Komponenten.
Abhängigkeiten: der Teil, über den man nachdenken muss
Gute Supervisions‑Designs beginnen mit einer Abhängigkeitskarte: Welche Komponenten sind voneinander abhängig, und was bedeutet „frisch starten" für sie?
Wenn ein Sitzungs‑Handler von einem Cache‑Prozess abhängt, kann es falsch sein, nur den Handler zu starten — er könnte an einen schlechten Zustand des Caches gekoppelt bleiben. Die richtige Gruppierung unter einem Supervisor (oder gemeinsamer Neustart) macht aus chaotischen Fehlerzuständen konsistente, wiederholbare Recovery‑Muster.
OTP: Wiederverwendbare Bausteine für zuverlässige Dienste
Wenn Erlang die Sprache ist, ist OTP (Open Telecom Platform) das Teile‑Set, das „let it crash“ in etwas verwandelt, das du jahrelang produktiv laufen lassen kannst.
OTP als Werkzeugkasten bewährter Muster
OTP ist keine einzelne Bibliothek — es ist eine Sammlung von Konventionen und vorgefertigten Komponenten (genannt behaviours), die die langweiligen, aber kritischen Teile des Servicetreibens lösen:
gen_serverfür lang laufende Worker, die Zustand halten und Anfragen nacheinander bearbeitensupervisorfür automatisches Neustarten fehlgeschlagener Worker nach klaren Regelnapplicationfür das Definieren, wie ein gesamter Dienst startet, stoppt und in ein Release passt
Das sind keine Magie, sondern Templates mit klaren Callbacks, sodass dein Code in bekannte Formen passt statt für jedes Projekt die Form neu zu erfinden.
Warum Standardmuster Eigenbau übertreffen
Teams bauen oft eigene Hintergrund‑Worker, hausgemachte Monitoring‑Haken und einmalige Restart‑Logik. Das funktioniert — bis es nicht mehr funktioniert. OTP reduziert dieses Risiko, indem es alle in dieselbe Sprache und Lifecycle‑Erwartung drängt. Neue Ingenieure müssen nicht zuerst dein Custom‑Framework lernen; sie verlassen sich auf gemeinsame Muster, die in der Erlang‑Community weit verstanden sind.
Wie OTP die Architektur im Alltag leitet
OTP schubst dich dazu, in Prozessrollen und Verantwortlichkeiten zu denken: Was ist ein Worker, was ist ein Koordinator, was soll was neu starten und was darf niemals automatisch neu starten?
Es fördert auch gute Hygiene: klare Benennung, explizite Startreihenfolge, vorhersehbares Herunterfahren und eingebaute Monitoring‑Signale. Das Ergebnis sind Programme, die darauf ausgelegt sind, kontinuierlich zu laufen — Dienste, die von Fehlern genesen, sich weiterentwickeln und ohne ständige menschliche Beaufsichtigung ihren Dienst tun.
BEAM VM: Die Laufzeit, die das Modell praktikabel macht
Erlangs große Ideen — kleine Prozesse, Message Passing und „let it crash“ — wären ohne die BEAM‑VM deutlich schwerer im Betrieb. BEAM ist die Laufzeit, die diese Muster natürlich statt fragil erscheinen lässt.
Scheduling: Fairness statt „ein großer Thread"
BEAM ist darauf ausgelegt, enorme Mengen leichter Prozesse zu betreiben. Anstatt sich auf einige wenige OS‑Threads zu verlassen und zu hoffen, die Anwendung benehme sich, plant BEAM Erlang‑Prozesse selbst.
Der praktische Nutzen ist Reaktionsfähigkeit unter Last: Arbeit wird in kleine Stücke aufgeteilt und fair rotiert, sodass kein einzelner busy‑Arbeiter das System lange dominieren soll. Das passt hervorragend zu einem Service aus vielen unabhängigen Tasks — jeder macht ein bisschen Arbeit und gibt dann wieder frei.
Isolation und „pro‑prozess“ Garbage Collection
Jeder Erlang‑Prozess hat seinen eigenen Heap und seine eigene Garbage Collection. Das ist ein wichtiges Detail: Speicherbereinigung in einem Prozess erfordert nicht das Anhalten des gesamten Programms.
Ebenso wichtig ist die Isolation. Stürzt ein Prozess ab, korruptiert er nicht den Speicher anderer Prozesse, und die VM bleibt am Leben. Diese Isolation ist die Grundlage, die Supervisionsbäume realistisch macht: Fehler werden eingehegt und durch Neustart des gescheiterten Teils behandelt, statt alles abzuschalten.
Distribution: Mehrere Knoten, ein System
BEAM unterstützt auch Distribution auf einfache Weise: Du kannst mehrere Erlang‑Knoten (separate VM‑Instanzen) laufen lassen und sie durch Nachrichtenkommunikation verbinden. Hast du das Prinzip „Prozesse kommunizieren per Nachricht“ verstanden, ist Distribution nur eine Erweiterung derselben Idee — manche Prozesse wohnen eben auf einem anderen Knoten.
BEAM steht nicht für rohe Geschwindigkeitsversprechen. Es macht Nebenläufigkeit, Fehlerisolation und Recovery zur Default‑Erfahrung, sodass die Zuverlässigkeitsstory praktisch statt theoretisch wird.
Upgrades ohne Systemstillstand (Hot Code, mit Vorsicht)
Eine von Erlangs meistdiskutierten Fähigkeiten ist das Hot Code Swapping: Teile eines laufenden Systems mit minimaler Downtime aktualisieren (wenn Laufzeit und Tools das unterstützen). Das Versprechen ist nicht „nie wieder neu starten“, sondern „Fixes ausliefern, ohne einen kleinen Bug in eine lange Outage zu verwandeln."
Was „Hot Code" wirklich bedeutet
In Erlang/OTP kann die Laufzeit zwei Versionen eines Moduls gleichzeitig geladen halten. Bestehende Prozesse können noch mit der alten Version fertigwerden, während neue Aufrufe die neue Version nutzen. Das gibt Raum, einen Bug zu patchen, ein Feature auszurollen oder Verhalten zu ändern, ohne alle Verbindungen zu kicken.
Gut gemacht unterstützt das Zuverlässigkeitsziele direkt: weniger vollständige Neustarts, kürzere Wartungsfenster und schnellere Reaktion, wenn etwas in Produktion schiefgeht.
Die Beschränkungen, die niemand ignorieren sollte
Nicht jede Änderung ist sicher live tauschbar. Beispiele für Änderungen, die besondere Sorgfalt oder einen Neustart erfordern:
- Änderungen an der Zustandsform (ein Prozess erwartet ein Format, neuer Code ein anderes)
- Änderungen an Protokollen oder Nachrichtenformaten, die über Services hinweg übereinstimmen müssen
- Schema‑Migrations, die Zeit oder Koordination benötigen
Erlang bietet Mechanismen für kontrollierte Übergänge, aber man muss den Upgrade‑Pfad entwerfen.
Die Denkweise: Upgrades und Rollbacks sind normal
Hot‑Upgrades funktionieren am besten, wenn Upgrades und Rollbacks alltägliche Operationen sind, nicht seltene Notfälle. Das heißt Versionierung, Kompatibilitätsplanung und ein klarer „Undo"‑Weg von Anfang an. Praktisch koppeln Teams Live‑Upgrade‑Techniken an gestaffelte Rollouts, Healthchecks und Supervision‑basierte Recovery.
Selbst wenn du nie Erlang nutzt: Die Lehre überträgt sich — gestalte Systeme so, dass sich Änderungen sicher durchführen lassen, nicht als zweitrangige Aufgabe.
Wo Erlangs Ideen in Echtzeit‑Plattformen glänzen
Echtzeitplattformen drehen sich weniger um perfekte Timing‑Garantie als darum, reaktionsfähig zu bleiben, während ständig Dinge schiefgehen: Netzwerke schwanken, Abhängigkeiten werden langsam und Nutzertraffic spike‑artig ansteigt. Erlangs Design — von Joe Armstrong vertreten — passt zu dieser Realität, weil es Fehler annimmt und Nebenläufigkeit zur Normalität macht.
Typische „Echtzeit“-Anwendungsfälle
Erlang‑Denkweise zeigt ihre Stärken überall dort, wo viele unabhängige Aktivitäten gleichzeitig stattfinden:
- Messaging und Chat: Millionen kleiner Konversationen, jeweils mit eigenem Zustand und eigenen Retries.
- Echtzeitkommunikation: Voice/Video‑Signalisierung, Presence‑Updates und Sitzungskoordination.
- IoT‑Koordination: Flotten von Geräten, die sporadisch checken, ausfallen und wieder auftauchen.
- Zahlungsworkflows: Mehrstufige Prozesse, bei denen einzelne Schritte langsam sind, ausfallen oder Kompensationsschritte brauchen.
Was „soft real‑time" meist bedeutet
Die meisten Produkte brauchen keine harten Garantien wie „jede Aktion beendet sich in 10 ms“. Sie brauchen soft real‑time: durchweg geringe Latenz für typische Anfragen, schnelle Wiederherstellung bei Teilfehlern und hohe Verfügbarkeit, sodass Nutzer Ausfälle kaum bemerken.
Fehler sind normal: dafür entwerfen
Reale Systeme treffen auf Probleme wie:
- Abgebrochene Verbindungen (mobile Netze, Wi‑Fi‑Wechsel)
- Timeouts, wenn ein Downstream‑Service langsam ist
- Partielle Ausfälle, wenn eine Region oder Abhängigkeit degradiert
Erlangs Modell ermutigt, jede Aktivität zu isolieren (Nutzersitzung, Gerät, Zahlungsversuch), sodass ein Fehler sich nicht ausbreitet. Statt einen großen „Versuch alles zu handhaben“‑Block zu bauen, kann man in kleinen Einheiten denken: Jeder Worker macht eine Aufgabe, kommuniziert per Nachrichten, und wenn er kaputtgeht, wird er sauber neu gestartet.
Dieser Wechsel — von „jede Art von Fehler verhindern“ zu „Fehler schnell eindämmen und wiederherstellen" — macht Echtzeitplattformen oft unter Last stabiler.
Häufige Missverständnisse und reale Grenzen
Erlang hat den Ruf, Systeme immer am Laufen zu halten, weil sie einfach neu starten. Die Realität ist praktischer und nützlicher: „Let it crash“ ist ein Werkzeug, keine Entschuldigung, harte Probleme zu ignorieren.
Neustarts sind kein Pflaster
Ein häufiger Fehler ist, Supervision als Versteck für tiefe Bugs zu missbrauchen. Crasht ein Prozess sofort nach dem Start, kann ein Supervisor ihn immer wieder neu starten und so eine Crash‑Loop erzeugen — CPU‑Verbrauch, Log‑Spam und eventuell ein größerer Ausfall als der ursprüngliche Bug.
Gute Systeme fügen Backoff, Restart‑Intensity‑Limits und klares „aufgeben und eskalieren“ hinzu. Neustarts sollen gesunden Betrieb wiederherstellen, nicht ein gebrochenes Invariant überdecken.
Zustand ist die harte Nuss
Einen Prozess neu zu starten ist oft leicht; korrekten Zustand wiederherzustellen ist es nicht. Lebt Zustand nur im Speicher, musst du klären, was „korrekt“ nach einem Crash heißt:
- Wiederaufbau aus durablem Speicher?
- Events erneut abspielen (Idempotenz)?
- Was passiert mit in‑flight Arbeit oder teilweise angewendeten Updates?
Fehlertoleranz ersetzt kein sorgfältiges Datenmodell. Sie zwingt dich dazu, explizit darüber nachzudenken.
Observability bleibt nötig
Abstürze nützen nur, wenn du sie früh siehst und verstehst. Das heißt Investitionen in Logging, Metriken und Tracing — nicht nur „es wurde neu gestartet, also passt das“. Du willst steigende Neustart‑Raten, wachsende Queues und langsame Dependencies bemerken, bevor Nutzer es spüren.
Operative Grenzen existieren
Trotz BEAM‑Stärken können Systeme auf ganz normale Weise versagen:
- Memory‑Growth durch Leaks, Caches oder große Heaps
- Mailbox‑Backlog, wenn Produzenten schneller sind als Konsumenten (Latenzspitzen und Timeouts)
- Abhängigkeiten, bei denen ein Neustart deines Codes die Ursache nicht behebt (Datenbank, Drittanbieter‑API, DNS)
Erlangs Modell hilft, Fehler einzudämmen und von ihnen zu genesen — es eliminiert sie nicht.
Wie man die Lektionen heute anwendet (auch ohne Erlang)
Erlangs größtes Geschenk ist nicht die Syntax, sondern eine Reihe von Gewohnheiten, um Dienste zu bauen, die weiterlaufen, wenn Teile unvermeidlich scheitern. Diese Gewohnheiten lassen sich in fast jedem Stack anwenden.
Ideen in konkrete Maßnahmen übersetzen
Fange damit an, Fehlergrenzen explizit zu machen. Zerlege dein System in Komponenten, die unabhängig ausfallen können, und gib jeder Komponente einen klaren Vertrag (Inputs, Outputs und was „schlecht" bedeutet).
Automatisiere dann die Wiederherstellung, statt jeden Fehler verhindern zu wollen:
- Isoliere Komponenten: führe riskante Arbeit in separaten Prozessen/Containern/Threads aus, sodass ein Absturz nicht alles verseucht.
- Definiere Grenzen: Timeouts, Retries mit Backoff, Circuit Breaker und Bulkheads, um Kaskadeneffekte zu stoppen.
- Mach Recovery routine: Healthchecks, Auto‑Restarts und sichere Defaults, sodass das System schnell in einen bekannten guten Zustand zurückkehrt.
Eine praktische Art, diese Gewohnheiten zu verankern, ist, sie in Tooling und Lifecycle zu integrieren, nicht nur in den Code. Wenn Teams z. B. Koder.ai nutzen, um Web‑, Backend‑ oder Mobile‑Apps via Chat zu vibe‑coden, fördert der Workflow explizite Planung (Planning Mode), wiederholbare Deploys und sichere Iteration mit Snapshots und Rollback — Konzepte, die zur selben operativen Denkweise passen, die Erlang populär machte: Veränderung und Ausfall sind zu erwarten, mach die Wiederherstellung langweilig.
Startpunkte außerhalb von Erlang
Du kannst Supervision‑ähnliche Muster mit vorhandenen Tools annähern:
- Supervisoren: systemd, Kubernetes Deployments oder Prozessmanager (restart‑on‑failure, Readiness‑Probes).
- Prozessisolation: separate Worker‑Services für CPU‑intensive oder untrusted Tasks.
- Message Passing: Queues/Streams (RabbitMQ, SQS, Kafka) zur Entkopplung von Produzenten und Konsumenten und zum Abpuffern von Spikes.
Kurze Entscheidungs‑Checkliste
Bevor du Patterns kopierst, entscheide, was du wirklich brauchst:
- Erwartete Ausfallmodi: Überlast, partielle Ausfälle, langsame Dependencies, fehlerhafte Inputs, Memory‑Leaks.
- Latenzanforderungen: Brauchst du Echtzeit‑Antworten oder reicht eventual processing?
- Recovery‑Ziel: schneller Neustart, degradierter Betrieb oder manuelle Intervention?
- Team‑Skills und Tooling: Wer ist On‑Call, wer bearbeitet Observability und Incident‑Response?
Wenn du praktische nächste Schritte willst, siehe mehr Guides in /blog oder Implementation Details in /docs (und Pläne in /pricing, falls du Tools evaluierst).
FAQ
Warum ist Joe Armstrongs Erlang-Mentalität heute noch relevant?
Erlang popularisierte eine praktische Zuverlässigkeitsmentalität: gehe davon aus, dass Teile ausfallen werden und gestalte, was danach passiert.
Statt jeden Absturz verhindern zu wollen, betont es Fehlerisolation, schnelle Erkennung und automatische Wiederherstellung, was gut zu Echtzeitplattformen wie Chat, Call-Routing, Benachrichtigungen und Koordinationsdiensten passt.
Was bedeutet „Real‑Time“ im einfachen Sinn dieses Beitrags?
In diesem Kontext bedeutet „Real‑Time“ meist soft real-time:
- Antworten fühlen sich schnell und konsistent an
- Das Verhalten bleibt unter Last vorhersehbar
- Das System läuft weiter bei partiellen Ausfällen
Es geht weniger um Mikrosekunden-Garantien und mehr darum, Staus, Spiralen und Kaskadenausfälle zu vermeiden.
Was bedeutet „Concurrency by default“ im Erlang‑Stil?
„Nebenläufigkeit als Standard“ heißt, das System als viele kleine, isolierte Arbeiter zu strukturieren statt als wenige, große, eng gekoppelte Komponenten.
Jeder Arbeiter übernimmt eine enge Verantwortung (Sitzung, Gerät, Anruf, Retry‑Loop), was Skalierung und Fehlerbegrenzung erleichtert.
Was sind Erlang‑„lightweight processes“ und warum sind sie wichtig?
Lightweight-Prozesse sind kleine, unabhängige Arbeiter, die in großer Zahl erzeugbar sind.
Praktisch helfen sie, weil:
- man pro "Ding" (Nutzer/Sitzung/Gerät) einen Prozess modellieren kann
- Fehler lokal auf einen Arbeiter begrenzt bleiben
- Neustart eines Arbeiters deutlich günstiger ist als ein Reboot eines Monolithen
Warum bevorzugt Erlang Message Passing gegenüber geteiltem Zustand?
Message Passing bedeutet Koordination durch Nachrichten senden statt durch geteilten, veränderbaren Zustand.
Das reduziert ganze Klassen von Nebenläufigkeitsfehlern (z. B. Race‑Conditions), weil jeder Arbeiter seinen internen Zustand besitzt; andere fordern Änderungen nur indirekt über Nachrichten an.
Was ist Back‑Pressure in einem Actor/Message‑System und wie geht man damit um?
Back‑Pressure entsteht, wenn ein Arbeiter Nachrichten schneller erhält, als er verarbeiten kann, sodass sein Postfach wächst.
Praktische Gegenmaßnahmen sind:
- Postfach-/Queue‑Größen überwachen
- Limits setzen (drop, sample, cap)
- Last auf mehr Arbeiter verteilen
- Fallbacks/Degradation (z. B. Digest‑Modus für unwichtige Benachrichtigungen)
Was bedeutet „let it crash“ wirklich (und was nicht)?
„Let it crash“ heißt: erreicht ein Arbeiter einen ungültigen oder unerwarteten Zustand, soll er schnell fehlschlagen, statt halb funktionsfähig weiterzulaufen.
Die Wiederherstellung geschieht strukturiert (via Supervision) — das führt zu klareren Codepfaden und vorhersehbarer Wiederherstellung, vorausgesetzt Neustarts sind sicher und schnell.
Was sind Supervision Trees und warum sind sie zentral für Fehlertoleranz?
Ein Supervisionsbaum ist eine Hierarchie, in der Supervisoren Arbeiter überwachen und sie nach definierten Regeln neu starten.
Statt verstreuter, individueller Recovery‑Logik zentralisierst du:
- was beim Fehler neu startet
- wie man Endlosschleifen mit Backoff/Limit vermeidet
- wann zusammengehörige Komponenten gemeinsam neu gestartet werden müssen
Was ist OTP und wie hilft es beim Bauen zuverlässiger Dienste?
OTP ist die Sammlung standardisierter Muster (Behaviours) und Konventionen, die aus „let it crash“ ein in Produktion brauchbares Konzept machen.
Gängige Bausteine sind:
gen_serverfür zustandsbehaftete, lang laufende Workersupervisorfür Neustart‑Politikenapplicationfür sauberes Starten/Stoppen und Releases
Der Vorteil: gemeinsame, bekannte Lebenszyklen statt eigener Framework‑Silos.
Wie wende ich Erlangs Lektionen an, wenn ich kein Erlang benutze?
Du kannst dieselben Prinzipien in anderen Stacks anwenden, indem du Fehler‑ und Recovery‑Grenzen zur ersten Bürgerpflicht machst:
- risikoreiche Arbeit isolieren (separate Prozesse/Container/Services)
- Timeouts, Backoff‑Retries, Circuit Breaker, Bulkheads einsetzen
- Recovery automatisieren (Healthchecks + Restart‑On‑Failure)
- Message Queues/Streams zur Entkopplung verwenden
Mehr dazu weist der Beitrag auf in /blog und Implementierungsdetails in /docs.