31. Okt. 2025·8 Min
Joe Bedas frühe Kubernetes‑Entscheidungen, die moderne Plattformen prägten
Ein klarer Blick auf Joe Bedas frühe Kubernetes‑Entscheidungen — deklarative APIs, Kontrollschleifen, Pods, Services und Labels — und wie sie moderne Anwendungsplattformen geprägt haben.
Warum Joe Bedas frühe Kubernetes-Entscheidungen noch zählen
Joe Beda gehörte zu den Schlüsselfiguren hinter dem frühen Kubernetes‑Design — zusammen mit anderen Gründern, die Erfahrungen aus Googles internen Systemen in eine offene Plattform einbrachten. Sein Einfluss bestand nicht darin, trendige Features zu jagen, sondern darin, einfache Primitive zu wählen, die echte Produktions‑Chaostests überstehen und für normale Teams verständlich bleiben.
Diese frühen Entscheidungen sind der Grund, warum Kubernetes mehr wurde als „ein Container‑Tool“. Es wurde zu einem wiederverwendbaren Kernel für moderne Anwendungsplattformen.
Container‑Orchestrierung, einfach erklärt
„Container‑Orchestrierung“ ist das Regelwerk und die Automatisierung, die deine App am Laufen hält, wenn Maschinen ausfallen, Traffic ansteigt oder du eine neue Version ausrollst. Anstatt dass ein Mensch Server babysittet, plant das System Container auf Rechnern, startet sie neu, wenn sie abstürzen, verteilt sie für Ausfallsicherheit und vernetzt sie so, dass Nutzer sie erreichen können.
Das Chaos vor Kubernetes
Bevor Kubernetes verbreitet war, bauten Teams oft Scripts und individuelle Tools zusammen, um grundlegende Fragen zu beantworten:
- Wo soll dieser Container jetzt laufen?
- Was passiert, wenn ein Node um 2 Uhr morgens ausfällt?
- Wie deploye ich sicher ohne Downtime?
- Wie finden Dienste einander, wenn sich IPs ständig ändern?
Diese DIY‑Systeme funktionierten — bis sie es nicht mehr taten. Jede neue App oder jedes Team fügte spezielle Logik hinzu, und Betriebs‑Konsistenz war schwer zu erreichen.
Was dieser Beitrag abdeckt
Dieser Artikel führt durch frühe Kubernetes‑Designentscheidungen (die „Form“ von Kubernetes) und warum sie moderne Plattformen immer noch beeinflussen: das deklarative Modell, Controller, Pods, Labels, Services, eine starke API, konsistenter Cluster‑Zustand, pluggbares Scheduling und Erweiterbarkeit. Selbst wenn du Kubernetes nicht direkt betreibst, nutzt du wahrscheinlich eine Plattform, die auf diesen Ideen basiert — oder kämpfst mit denselben Problemen.
Das Problem, das Kubernetes lösen wollte
Vor Kubernetes bedeutete „Container betreiben“ meist, ein paar Container laufen zu lassen. Teams kombinierten Bash‑Skripte, Cron‑Jobs, Goldimages und einige Ad‑hoc‑Tools, um Deployments hinzubekommen. Wenn etwas kaputtging, lebte die Lösung oft im Kopf einer Person — oder in einem README, dem niemand vertraute. Betrieb war eine Abfolge von Einzelmaßnahmen: Prozesse neu starten, Load Balancer umkonfigurieren, Disk aufräumen und raten, welcher Rechner sicher zu berühren ist.
Container in großem Maßstab erzeugen neue Fehlerbilder
Container vereinfachten Packaging, aber beseitigten nicht die unordentlichen Teile der Produktion. Auf Skala versagt das System häufiger und auf mehr Arten: Nodes verschwinden, Netzwerke partitionieren, Images rollen inkonsistent aus und Workloads driften von dem weg, von dem du denkst, dass es läuft. Ein „einfaches“ Deployment kann zur Kaskade werden — einige Instanzen aktualisiert, einige nicht, manche hängen, einige sind gesund, aber unerreichbar.
Das eigentliche Problem war nicht, Container zu starten. Es war, die richtigen Container in der richtigen Form am Laufen zu halten, trotz ständiger Unruhe.
Ein konsistentes Modell über Infrastruktur hinweg
Teams jonglierten auch mit unterschiedlichen Umgebungen: On‑Premises‑Hardware, VMs, frühen Cloud‑Providern und verschiedenen Netzwerk‑ und Storage‑Setups. Jede Plattform hatte ihre eigene Sprache und Ausfallmuster. Ohne ein gemeinsames Modell bedeutete jede Migration, Betriebs‑Tools neu zu schreiben und Leute umzuschulen.
Kubernetes wollte eine einzige, konsistente Art bieten, Anwendungen und ihre betrieblichen Bedürfnisse zu beschreiben — unabhängig davon, wo die Maschinen stehen.
Erwartungen an eine „Plattform"
Entwickler wollten Self‑Service: deployen ohne Tickets, skalieren ohne um Kapazität zu betteln und zurückrollen ohne Drama. Ops‑Teams wollten Vorhersagbarkeit: standardisierte Health‑Checks, wiederholbare Deployments und eine klare Quelle der Wahrheit dafür, was laufen sollte.
Kubernetes wollte nicht ein schicker Scheduler sein. Das Ziel war, die Grundlage für eine verlässliche Anwendungsplattform zu legen — eine, die die unordentliche Realität in ein System verwandelt, über das man nachdenken kann.
Entscheidung 1: Ein deklaratives Desired‑State‑Modell
Eine der einflussreichsten frühen Entscheidungen war, Kubernetes deklarativ zu machen: Du beschreibst, was du willst, und das System bemüht sich, die Realität dieser Beschreibung anzunähern.
Desired State, erklärt am Thermostat
Ein Thermostat ist ein gutes Alltagsbeispiel. Du schaltest die Heizung nicht alle paar Minuten manuell ein und aus. Du stellst eine gewünschte Temperatur ein — sagen wir 21°C — und der Thermostat prüft kontinuierlich den Raum und steuert die Heizung, um nahe diesem Ziel zu bleiben.
Kubernetes funktioniert genauso. Anstatt dem Cluster Schritt für Schritt zu sagen „starte diesen Container auf diesem Rechner, starte ihn neu, wenn er fehlschlägt“, deklarierst du das Ergebnis: „Ich möchte 3 Kopien dieser App laufen haben.“ Kubernetes überprüft kontinuierlich, was tatsächlich läuft, und korrigiert Abweichungen.
Weniger manuelle Schritte, weniger Überraschungen
Deklarative Konfiguration reduziert die versteckte „Ops‑Checkliste“, die oft im Kopf einer Person oder in einem halb aktualisierten Runbook lebt. Du wendest die Konfiguration an und Kubernetes übernimmt Mechanik — Placement, Neustarts und das Reconciliieren von Änderungen.
Es macht Änderungen auch einfacher prüfbar: Eine Änderung ist als Diff in der Konfiguration sichtbar, nicht als Folge von Ad‑hoc‑Befehlen.
Wiederholbarkeit über Umgebungen
Weil der gewünschte Zustand niedergeschrieben ist, kannst du denselben Ansatz in Dev, Staging und Produktion wiederverwenden. Die Umgebung mag sich unterscheiden, aber die Absicht bleibt konsistent, was Deployments vorhersehbarer und auditierbarer macht.
Die Abwägungen
Deklarative Systeme haben eine Lernkurve: Du musst in „was sollte wahr sein“ denken, statt „was mache ich als Nächstes“. Sie sind außerdem stark auf gute Defaults und klare Konventionen angewiesen — ohne diese können Teams Konfigurationen erzeugen, die zwar technisch funktionieren, aber schwer zu verstehen und zu pflegen sind.
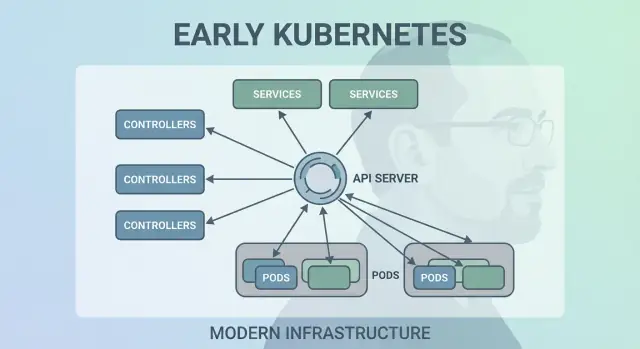
Entscheidung 2: Kontrollschleifen (Controller) als Motor
Kubernetes hat nicht dadurch gesiegt, dass es Container einmal starten konnte — es hat gesiegt, weil es sie über die Zeit korrekt am Laufen halten konnte. Die große Designentscheidung war, Kontrollschleifen (Controller) zum Kernmotor des Systems zu machen.
Was ein Controller ist
Ein Controller ist eine einfache Schleife:
- Sie schaut den aktuellen Zustand an (was tatsächlich läuft)
- Vergleicht ihn mit dem gewünschten Zustand (was du angefragt hast)
- Führt Aktionen aus, bis die beiden übereinstimmen
Es ist weniger eine Einmal‑Aufgabe und mehr Autopilot. Du babysittest Workloads nicht; du deklarierst, was du willst, und Controller steuern den Cluster kontinuierlich zurück zu diesem Ergebnis.
Umgang mit Crashes, Node‑Verlust und Drift
Dieses Muster ist der Grund, warum Kubernetes resilient ist, wenn reale Dinge schiefgehen:
- Container‑Crashes: der Controller bemerkt weniger laufende Instanzen als gewünscht und startet Ersatz.
- Node‑Verlust: wenn ein Node verschwindet, planen Controller die Pods anderswo neu, um die gewünschte Anzahl wiederherzustellen.
- Konfigurationsdrift: ändert oder löscht jemand Ressourcen, reconciliert der Controller die Differenz und korrigiert sie.
Anstatt Fehler als Sonderfälle zu behandeln, sehen Controller sie als routinemäßige „Zustandsunterschiede“ und behandeln sie immer gleich.
Warum das besser skaliert als Skripte
Traditionelle Automatisierungs‑Skripte gehen oft von einer stabilen Umgebung aus: führ Schritt A aus, dann B, dann C. In verteilten Systemen brechen diese Annahmen ständig zusammen. Controller skalieren besser, weil sie idempotent sind (sicher mehrfach ausführbar) und eventually consistent (sie versuchen so lange, bis das Ziel erreicht ist).
Alltägliche Beispiele: Deployments und ReplicaSets
Wenn du ein Deployment benutzt hast, hast du auf Kontrollschleifen vertraut. Unter der Haube verwendet Kubernetes einen ReplicaSet‑Controller, um sicherzustellen, dass die gewünschte Anzahl von Pods existiert — und einen Deployment‑Controller, um Rolling Updates und Rollbacks vorhersehbar zu managen.
Entscheidung 3: Pods als atomare Scheduling‑Einheit
Kubernetes hätte „nur Container“ planen können, aber Joe Bedas Team führte Pods ein, die die kleinste deploybare Einheit darstellen, die das Cluster auf eine Maschine platziert. Die Kernidee: viele reale Anwendungen sind kein einzelner Prozess. Sie sind eine kleine Gruppe eng gekoppelter Prozesse, die zusammen leben müssen.
Warum Pods statt einzelner Container?
Ein Pod ist eine Hülle um einen oder mehrere Container, die dasselbe Schicksal teilen: sie starten zusammen, laufen auf demselben Node und skalieren zusammen. Das macht Muster wie Sidecars natürlich — denk an einen Log‑Shipper, Proxy, Config‑Reloader oder Sicherheitsagent, der immer die Hauptanwendung begleiten sollte.
Statt jede App zu zwingen, diese Helfer zu integrieren, erlaubt Kubernetes, sie als separate Container zu verpacken, die sich dennoch wie eine Einheit verhalten.
Was Pods für Networking und Storage ermöglichten
Pods machten zwei Annahmen praktisch:
- Networking: Container in einem Pod teilen eine Netzwerkkennung (eine IP und Port‑Range). Die Hauptapp kann den Sidecar über
localhosterreichen — einfach und schnell. - Storage: Container in einem Pod können Volumes teilen. Ein Helfer kann Dateien schreiben, die die Hauptapp liest (oder umgekehrt), ohne umständliche externe Schritte.
Diese Entscheidungen verringerten die Notwendigkeit für individuellen Glue‑Code, während Container auf Prozess‑Ebene isoliert bleiben.
Wo Pods Einsteiger verwirren
Neue Nutzer erwarten oft „ein Container = eine App“ und stolpern dann über Pod‑Konzepte: Neustarts, IPs und Skalierung. Viele Plattformen glätten das mit meinungsstarken Templates (z. B. „Web Service“, „Worker“ oder „Job“), die Pods im Hintergrund erzeugen — Teams bekommen so Vorteile von Sidecars und geteilten Ressourcen, ohne täglich über Pod‑Mechanik nachzudenken.
Entscheidung 4: Labels und Selektoren für lose Kopplung
Starte einen Web- und API-Stack
Erstelle eine React-Webapp plus ein Go- und PostgreSQL-Backend per einfachem Chat.
Eine unterschätzte frühe Entscheidung in Kubernetes war, Labels als erstklassige Metadaten zu behandeln und Selektoren als primäre Methode, Dinge zu „finden“. Statt Beziehungen fest zu verdrahten (wie „diese drei spezifischen Maschinen laufen meine App“), ermutigt Kubernetes dazu, Gruppen durch gemeinsame Attribute zu beschreiben.
Labels: flexible Tags auf allem
Ein Label ist ein einfaches Key/Value‑Paar, das du Ressourcen anhängst — Pods, Deployments, Nodes, Namespaces und mehr. Sie fungieren wie konsistente, abfragbare „Tags“:
app=checkoutenv=prodtier=frontend
Weil Labels leichtgewichtig und benutzerdefiniert sind, kannst du die Realität deiner Organisation modellieren: Teams, Kostenstellen, Compliance‑Zonen, Release‑Kanäle oder was immer für deinen Betrieb wichtig ist.
Selektoren: Beziehungen ohne enge Abhängigkeiten
Selektoren sind Abfragen über Labels (zum Beispiel „alle Pods, bei denen app=checkout und env=prod ist“). Das schlägt feste Host‑Listen, weil das System sich anpasst, wenn Pods umplatziert, skaliert oder während Rollouts ersetzt werden. Deine Konfiguration bleibt stabil, selbst wenn die zugrunde liegenden Instanzen sich ständig ändern.
Dynamisches Gruppieren in großem Maßstab
Dieses Design skaliert betrieblich: du verwaltest nicht tausende Instanz‑Identitäten — du verwaltest ein paar sinnvolle Label‑Sätze. Das ist die Essenz loser Kopplung: Komponenten verbinden sich mit Gruppen, deren Mitgliedschaft sicher wechseln kann.
Labels treiben mehr als Gruppierung an
Sobald Labels vorhanden sind, werden sie zur gemeinsamen Sprache über die Plattform hinweg. Sie werden verwendet für Traffic‑Routing (Services), Policy‑Grenzen (NetworkPolicy), Observability‑Filter (Metriken/Logs) und sogar Kostenverfolgung und Chargeback. Eine einfache Idee — Dinge konsequent taggen — entfesselt ein ganzes Ökosystem an Automatisierung.
Entscheidung 5: Services für stabiles Networking
Kubernetes brauchte einen Weg, Networking vorhersehbar zu machen, obwohl Container alles andere als vorhersehbar sind. Pods werden ersetzt, umplatziert und skaliert — daher ändern sich IPs und die spezifischen Maschinen. Die Kernidee eines Service ist simpel: eine stabile „Vorderseite“ zu einer verschieblichen Menge von Pods bieten.
Stabile Zugriffe auf sich verändernde Pods
Ein Service gibt dir eine konsistente virtuelle IP und einen DNS‑Namen (z. B. payments). Dahinter verfolgt Kubernetes ständig, welche Pods zum Selektor des Services passen, und routet den Traffic entsprechend. Wenn ein Pod stirbt und ein neuer erscheint, zeigt der Service weiterhin auf den richtigen Ort, ohne dass du Anwendungseinstellungen anfassen musst.
Service Discovery, die Konfiguration vereinfachte
Dieser Ansatz entfernte viel manuelles Verdrahten. Anstatt IPs in Konfigdateien einzubrennen, können Apps sich auf Namen verlassen. Du deployst die App, deployst den Service und andere Komponenten finden sie über DNS — kein eigener Registry‑Mechanismus nötig, keine hartekodierten Endpunkte.
Eingebaute Lastverteilung für Zuverlässigkeit
Services brachten auch Standard‑Load‑Balancing über gesunde Endpunkte. Das bedeutete, Teams mussten nicht für jeden internen Microservice eigene Load Balancer bauen. Trafficverteilung reduziert die Blast‑Radius eines einzelnen Pod‑Ausfalls und macht Rolling Updates weniger riskant.
Grenzen — und wie Ingress/Gateway erweitern
Ein Service ist großartig für L4 (TCP/UDP) Traffic, modelliert aber keine HTTP‑Routingregeln, TLS‑Termination oder Edge‑Policies. Hier kommen Ingress und zunehmend das Gateway API ins Spiel: sie bauen auf Services auf, um Hostnames, Pfade und externe Einstiegspunkte sauberer zu handhaben.
Entscheidung 6: Eine API als Produktoberfläche
Eine der stillen, radikalen frühen Entscheidungen war, Kubernetes als eine API zu behandeln, gegen die gebaut wird — nicht als monolithisches Tool, das man „benutzt“. Diese API‑erste Haltung machte Kubernetes zu einer Plattform, die sich erweitern, skripten und regeln lässt.
Warum API‑first Plattformbau veränderte
Wenn die API die Oberfläche ist, können Plattformteams standardisieren, wie Anwendungen beschrieben und verwaltet werden, unabhängig davon, welche UI, Pipeline oder internes Portal darüber liegt. „Eine App deployen“ wird zu „API‑Objekte erstellen und aktualisieren“ (wie Deployments, Services und ConfigMaps), was einen viel saubereren Vertrag zwischen App‑Teams und der Plattform darstellt.
Tools, UIs und Automatisierung ohne Sonderzugriff
Weil alles durch dieselbe API geht, brauchen neue Tools keinen privilegierten Backdoor‑Zugang. Dashboards, GitOps‑Controller, Policy‑Engines und CI/CD‑Systeme können alle als normale API‑Clients mit wohl definierten Rechten arbeiten.
Diese Symmetrie ist wichtig: dieselben Regeln, Authentifizierung, Auditing und Admission Controls gelten, egal ob die Anfrage von einer Person, einem Script oder einer internen Plattform‑UI kommt.
Versionierung und Kompatibilität für langlebige Cluster
API‑Versionierung machte es möglich, Kubernetes zu entwickeln, ohne jeden Cluster oder jedes Tool über Nacht zu brechen. Deprecations können gestaffelt werden; Kompatibilität kann getestet werden; Upgrades lassen sich planen. Für Organisationen, die Cluster über Jahre betreiben, ist das der Unterschied zwischen „wir können upgraden“ und „wir stecken fest“.
Was kubectl wirklich repräsentiert
kubectl ist nicht Kubernetes — es ist ein Client. Dieses Mentalmodell bringt Teams dazu, in API‑Workflows zu denken: du kannst kubectl gegen Automatisierung, eine Web‑UI oder ein eigenes Portal austauschen, und das System bleibt konsistent, weil der Vertrag die API ist.
Entscheidung 7: Zentralisierter Cluster‑Zustand (etcd) und Konsistenz
Von der Idee zur lauffähigen App
Baue eine echte App per Chat und sieh, wie schnell du mit Koder.ai iterierst.
Kubernetes brauchte eine einzige „Quelle der Wahrheit“ dafür, wie der Cluster gerade aussehen sollte: welche Pods existieren, welche Nodes gesund sind, wohin Services zeigen und welche Objekte gerade aktualisiert werden. Genau das liefert etcd.
Was etcd tut (einfach erklärt)
etcd ist die Datenbank der Control Plane. Wenn du ein Deployment erstellst, eine ReplicaSet skalierst oder einen Service aktualisierst, wird die gewünschte Konfiguration in etcd geschrieben. Controller und andere Control‑Plane‑Komponenten beobachten diesen gespeicherten Zustand und arbeiten darauf hin, die Realität anzugleichen.
Warum Konsistenz wichtig ist, wenn alle gleichzeitig handeln
Ein Kubernetes‑Cluster ist voll beweglicher Teile: Scheduler, Controller, Kubelets, Autoscaler und Admission Checks können gleichzeitig reagieren. Wenn sie unterschiedliche Versionen der „Wahrheit“ lesen, entstehen Races — zum Beispiel zwei Komponenten, die widersprüchliche Entscheidungen über denselben Pod treffen.
etcds starke Konsistenz stellt sicher, dass, wenn die Control Plane sagt „das ist der aktuelle Zustand“, alle auf derselben Seite sind. Diese Ausrichtung macht Kontrollschleifen vorhersehbar statt chaotisch.
Wie das Backups, Upgrades und Disaster Recovery beeinflusst
Weil etcd die Cluster‑Konfiguration und die Historie von Änderungen hält, schützt du es auch bei:
- Backups: ohne ein etcd‑Snapshot kannst du Cluster‑Objekte nicht zuverlässig wiederherstellen.
- Upgrades: gute etcd‑Gesundheit und Snapshotting reduzieren Upgrade‑Risiken.
- Disaster Recovery: das Wiederherstellen von etcd ist oft der schnellste Weg, die Control Plane mit demselben Intent wiederzubekommen.
Praktische Anleitung
Behandle den Control‑Plane‑Zustand wie kritische Daten. Mache regelmäßige etcd‑Snapshots, teste Wiederherstellungen und lagere Backups außerhalb des Clusters. Wenn du Managed Kubernetes nutzt, kläre, was dein Anbieter sichert — und was du zusätzlich sichern musst (z. B. Persistent Volumes und App‑Daten).
Entscheidung 8: Pluggbares Scheduling und Ressourcenbewusstsein
Kubernetes betrachtete „wo ein Workload läuft“ nicht als Nebensache. Früh war der Scheduler eine eigene Komponente mit klarer Aufgabe: Pods auf Nodes matchen, die sie tatsächlich ausführen können, unter Nutzung des aktuellen Cluster‑Zustands und der Anforderungen des Pods.
Wie der Scheduler Workloads zu Nodes matched
Auf hoher Ebene ist Scheduling eine Zweischritt‑Entscheidung:
- Filtern: entferne Nodes, die harte Constraints nicht erfüllen (nicht genug CPU/Memory, fehlende Labels, inkompatible Taints, Ports belegt usw.).
- Bewerten: ranke die verbleibenden Nodes nach Präferenzen (über Zonen verteilen, fürs Packen optimieren, laute Nachbarn vermeiden, Affinity‑Regeln einhalten).
Diese Struktur machte es möglich, Scheduling zu entwickeln, ohne alles neu schreiben zu müssen.
Trennung der Verantwortlichkeiten: Scheduler vs. Runtime vs. Networking
Eine wichtige Designentscheidung war, Verantwortlichkeiten sauber zu trennen:
- Der Scheduler entscheidet das Placement.
- Die Container Runtime (und der Kubelet) führt die Ausführung auf dem gewählten Node aus.
- Die Netzwerkschicht stellt die Konnektivität her, sobald Dinge laufen.
Weil diese Bereiche separiert sind, erzwingen Verbesserungen in einem Bereich (z. B. ein neues CNI‑Plugin) kein neues Scheduling‑Modell.
Einschränkungen und Prioritäten entwickelten sich natürlich
Ressourcenbewusstsein begann mit Requests und Limits, die dem Scheduler sinnvolle Signale gaben statt Schätzungen. Darauf aufbauend kamen reichere Kontrollen — Node Affinity/Anti‑Affinity, Pod Affinity, Priorities und Preemption, Taints und Tolerations sowie topology‑bewusste Verteilung — alles auf demselben Fundament.
Moderner Einfluss: Multi‑Tenant und kosteneffiziente Platzierung
Dieser Ansatz ermöglicht heutige Shared‑Cluster: Teams können kritische Dienste mit Priorities und Taints isolieren, während alle von höherer Auslastung profitieren. Mit besserem Bin‑Packing und Topologie‑Kontrollen kann die Plattform Workloads kosteneffizienter platzieren, ohne Zuverlässigkeit zu opfern.
Entscheidung 9: Erweiterbarkeit statt „ein eingebauter Weg"
Ohne riskante Deploys ausliefern
Stelle deine App bereit und hoste sie; sichere Änderungen mit Snapshots und Rollback.
Kubernetes hätte mit einer vollständigen, meinungsstarken PaaS‑Erfahrung kommen können — Buildpacks, Routing‑Regeln, Background Jobs, Konventionssätze und mehr. Stattdessen hielt Joe Bedas Team den Kern auf ein kleineres Versprechen fokussiert: Workloads zuverlässig laufen und heilen, sie exponieren und eine konsistente API zum Automatisieren bereitstellen.
Warum Kubernetes nicht versucht hat, eine komplette PaaS zu sein
Eine „komplette PaaS“ hätte einen Workflow und ein Set von Trade‑offs für alle erzwungen. Kubernetes zielte auf ein breiteres Fundament, das viele Plattformstile unterstützen kann — Heroku‑ähnliche Entwicklererfahrung, Enterprise‑Governance, Batch‑ und ML‑Pipelines oder roher Infrastrukturbetrieb — ohne sich auf eine einzige Produktphilosophie festzulegen.
Wie Erweiterungen Features sicher hinzufügen
Die Erweiterungsmechanismen von Kubernetes schufen einen kontrollierten Weg, Fähigkeiten zu erweitern:
- CRDs (CustomResourceDefinitions) erlauben neue API‑Typen (z. B.
CertificateoderDatabase). - Controller/Operatoren reconciliieren diese neuen Ressourcen mit demselben Desired‑State‑Pattern wie die eingebauten Komponenten.
- Admission Controllers/Webhooks erzwingen Policy (Sicherheit, Namenskonventionen, Quotas) und mutieren Defaults an der API‑Schnittstelle.
So können interne Plattformteams und Anbieter Features als Add‑ons liefern und trotzdem Kubernetes‑Primitiven wie RBAC, Namespaces und Audit‑Logs nutzen.
Vorteile — und das Hauptrisiko
Für Anbieter erlaubt es differenzierte Produkte ohne Forking von Kubernetes. Für interne Teams ermöglicht es eine “Plattform auf Kubernetes”, zugeschnitten auf organisatorische Bedürfnisse.
Die Kehrseite ist Ökosystem‑Sprawl: zu viele CRDs, überlappende Tools und inkonsistente Konventionen. Governance — Standards, Ownership, Versionierung und Deprecation‑Regeln — wird Teil der Plattformarbeit.
Wie diese Entscheidungen moderne Anwendungsplattformen prägten
Die frühen Entscheidungen von Kubernetes haben nicht nur einen Container‑Scheduler geschaffen — sie schufen einen wiederverwendbaren Plattform‑Kernel. Deshalb beruhen viele moderne Internal Developer Platforms (IDPs) im Kern auf „Kubernetes plus meinungsstarke Workflows“. Das deklarative Modell, Controller und die konsistente API machten es möglich, höherstufige Produkte zu bauen, ohne Deployment, Reconciliation und Service Discovery jedes Mal neu zu erfinden.
Kubernetes als gemeinsame Control Plane
Weil die API die Produktoberfläche ist, können Anbieter und Plattformteams sich auf eine Control Plane standardisieren und unterschiedliche Erfahrungen darüber bauen: GitOps, Multi‑Cluster‑Management, Policy, Service‑Kataloge und Deployment‑Automatisierung. Das ist ein großer Grund, warum Kubernetes zum gemeinsamen Nenner für cloud‑native Plattformen wurde: Integrationen zielen auf die API, nicht auf ein UI.
Was schwierig bleibt (Day‑2‑Realität)
Selbst mit sauberen Abstraktionen bleibt die härteste Arbeit betrieblich:
- Sicherheit: Identität, NetworkPolicy, Secrets und Supply‑Chain‑Vertrauen
- Upgrades: Kubernetes‑Versionen, CRDs und Add‑ons bewegen sich mit unterschiedlichen Geschwindigkeiten
- Zuverlässigkeit: Debugging von Controllern, Fehlkonfigurationen und laute Nachbarn
Wie man eine Kubernetes‑basierte Plattform bewertet
Stelle Fragen, die operative Reife offenbaren:
- Wie werden Upgrades gehandhabt und wie sieht die Rollback‑Story aus?
- Welche Teile sind Standard‑Kubernetes vs. proprietäre Erweiterungen?
- Welche Guardrails (Policy, Defaults, Templates) verhindern Fußschüsse?
- Wie gut ist das System beobachtbar (Events, Logs, Audit Trails) und wer verantwortet Incidents?
Eine gute Plattform reduziert kognitive Last ohne die zugrunde liegende Control Plane zu verbergen oder Escape‑Hatches schmerzhaft zu machen.
Eine praktische Linse: Hilft die Plattform Teams dabei, von „Idee → laufender Service“ zu kommen, ohne am ersten Tag alle zu Kubernetes‑Experten zu machen? Tools im Bereich der „vibe‑coding“‑Kategorie — wie Koder.ai — setzen hier an, indem sie Teams erlauben, reale Anwendungen aus Chat zu generieren (Web in React, Backends in Go mit PostgreSQL, Mobile in Flutter) und dann schnell mit Features wie Plan‑Modus, Snapshots und Rollback zu iterieren. Ob du so etwas übernimmst oder ein eigenes Portal baust: Das Ziel ist dasselbe — die starken Kubernetes‑Primitiven bewahren und gleichzeitig den Workflow‑Overhead drumherum reduzieren.
Wichtige Erkenntnisse und praktische Lehren
Kubernetes kann kompliziert wirken, aber das meiste davon ist beabsichtigt: es ist eine Sammlung kleiner Primitive, die sich zu vielen Plattformtypen zusammensetzen lassen.
Zwei verbreitete Missverständnisse aufräumen
Erstens: „Kubernetes ist nur Docker‑Orchestrierung.“ Kubernetes geht nicht in erster Linie darum, Container zu starten. Es geht darum, kontinuierlich den Desired State (was du laufen haben willst) mit dem Actual State (was wirklich passiert) abzugleichen — trotz Ausfällen, Rollouts und schwankender Nachfrage.
Zweitens: „Wenn wir Kubernetes nutzen, werden alle zu Microservices.“ Kubernetes unterstützt Microservices, aber auch Monolithen, Batch‑Jobs und interne Plattformen. Die Einheiten (Pods, Services, Labels, Controller und die API) sind neutral; deine Architekturentscheidungen werden nicht vom Tool diktiert.
Wo die Komplexität wirklich herkommt
Die harten Teile sind meistens nicht YAML oder Pods — es sind Netzwerk, Sicherheit und Multi‑Team‑Nutzung: Identität und Zugriff, Secrets‑Management, Policies, Ingress, Observability, Supply‑Chain‑Kontrollen und Guardrails, damit Teams sicher deployen können, ohne einander zu behindern.
Entscheidungen auf hoher Ebene, die du nutzen kannst
Bei der Planung denke an die ursprünglichen Gestaltungsprinzipien:
- Bevorzuge deklarative Workflows und Automatisierung, die Drift reconciliert.
- Nutze Labels/Selektoren, um Kopplung zwischen Teams und Komponenten gering zu halten.
- Betrachte die API als Produkt: Versionierung, Konventionen und klare Ownership sind wichtig.
Ein praktischer nächster Schritt
Mappe deine realen Anforderungen auf Kubernetes‑Primitive und Plattformschichten:
-
Workloads → Pods/Deployments/Jobs
-
Konnektivität → Services/Ingress
-
Betrieb → Controller, Policies und Observability
Wenn du evaluierst oder standardisierst, schreib diese Zuordnung auf und besprich sie mit Stakeholdern — baue deine Plattform inkrementell um die Lücken, nicht um Trends.
Wenn du auch die „Build“-Seite (nicht nur die „Run“-Seite) beschleunigen willst, überlege, wie dein Delivery‑Workflow Intent in deploybare Services übersetzt. Für einige Teams ist das ein kuratiertes Set an Templates; für andere eine KI‑gestützte Erfahrung wie Koder.ai, die einen initialen lauffähigen Service erzeugt und dann Quellcode zur tieferen Anpassung exportiert — während die Plattform weiterhin von den Kernentscheidungen Kubernetes' profitiert.
FAQ
Was bedeutet „Container-Orchestrierung“ einfach erklärt?
Container-Orchestrierung ist die Automatisierung, die Anwendungen am Laufen hält, wenn Maschinen ausfallen, der Traffic sich ändert oder Deployments stattfinden. Praktisch übernimmt sie:
- das Planen von Containern auf Nodes
- das Neustarten fehlgeschlagener Workloads
- das Skalieren nach oben/unten
- das Vernetzen, damit Services sich finden
- Rolling Updates und Rollbacks
Kubernetes hat ein einheitliches Modell populär gemacht, um das über verschiedene Infrastrukturen hinweg zu tun.
Welches Problem wollte Kubernetes ursprünglich lösen?
Das Hauptproblem war nicht das Starten von Containern, sondern das Beibehalten der richtigen Container in der richtigen Form trotz ständigem Wandel. Auf großer Skala treten reguläre Fehler und Drift auf:
- Nodes verschwinden oder werden ungesund
- Deployments werden nur teilweise angewendet
- IPs ändern sich, wenn Pods ersetzt werden
- Menschen „reparieren“ Dinge auf Weisen, die nicht dokumentiert werden
Kubernetes wollte Betrieb wiederholbar und vorhersehbar machen, indem es eine standardisierte Kontroll‑Ebene und ein gemeinsames Vokabular liefert.
Warum ist Kubernetes „deklarativ“ und was bringt der Desired State?
In einem deklarativen System beschreibst du das Ergebnis, das du willst (zum Beispiel „lauf 3 Replikate“), und das System arbeitet kontinuierlich daran, die Realität dem Sollzustand anzugleichen.
Praktischer Ablauf:
- Intent in Konfiguration schreiben (YAML oder generierte Manifeste)
- Anwenden (
kubectl applyoder GitOps) - Controller lassen Fehler und Drift ausgleichen
Das reduziert „versteckte Runbooks“ und macht Änderungen als Diffs prüfbar, statt als Ad-hoc-Befehle.
Was sind Kubernetes-Controller und warum sind sie zentral für Zuverlässigkeit?
Controller sind Kontrollschleifen, die wiederholt:
- den aktuellen Zustand beobachten
- mit dem gewünschten Zustand vergleichen
- Aktionen durchführen, bis sie übereinstimmen
Dieses Muster macht gängige Fehler zur Routine statt zu Spezialfällen. Wenn ein Pod crasht oder ein Node verschwindet, stellt der zuständige Controller einfach fest, „wir haben weniger Replikate als gewünscht“ und erstellt Ersatz.
Warum verwendet Kubernetes Pods statt einzelner Container?
Kubernetes plant Pods (nicht einzelne Container), weil viele reale Workloads eng gekoppelte Hilfsprozesse brauchen.
Pods ermöglichen Muster wie:
- Sidecars (Proxy, Log‑Shipper, Config‑Reloader)
- Gemeinsames Networking (Container kommunizieren über
localhost) - Gemeinsame Speicherung über Volumes
Faustregel: Halte Pods klein und kohärent — gruppiere nur Container, die Lebenszyklus, Netzwerkidentität oder lokale Daten teilen müssen.
Wie reduzieren Labels und Selektoren enge Kopplung in Kubernetes?
Labels sind leichte Key/Value-Tags (zum Beispiel app=checkout, env=prod). Selektoren fragen diese Labels ab, um dynamische Gruppen zu bilden.
Das ist wichtig, weil Instanzen flüchtig sind: Pods kommen und gehen während Reschedules und Rollouts. Mit Labels/Selektoren bleiben Beziehungen stabil („alle Pods mit diesen Labels“), auch wenn sich die Mitglieder ändern.
Betrieblicher Tipp: Standardisiere eine kleine Label-Taxonomie (app, team, env, tier) und erzwinge sie mit Policies, um späteres Chaos zu vermeiden.
Was macht ein Kubernetes Service und wann sollte ich einen verwenden?
Ein Service stellt eine stabile virtuelle IP und einen DNS-Namen bereit, der zu einer sich verändernden Menge von Pods routet, die zu einem Selektor passen.
Verwende einen Service, wenn:
- Backends repliziert sind und Pods ersetzt werden können
- Clients von einem stabilen Namen statt von Pod-IP abhängen sollen
- Du eingebaute Lastverteilung über Endpunkte willst
Für HTTP-Routing, TLS‑Termination und Edge-Regeln schichtest du in der Regel Ingress oder das Gateway API über Services.
Warum ist „API-first" eine so große Designentscheidung bei Kubernetes?
Kubernetes behandelt die API als die primäre Produktschnittstelle: alles ist ein API‑Objekt (Deployments, Services, ConfigMaps usw.). Tools — einschließlich kubectl, CI/CD, GitOps und Dashboards — sind einfach API‑Clients.
Praktische Vorteile:
- Konsistente Authentifizierung, Auditing und Policy via API
- Einfachere Automatisierung (keine „Sonderzugänge“ nötig)
- Versionierung/Kompatibilität für langlebige Cluster
Wenn du eine interne Plattform baust, entwirf Workflows um API‑Verträge, nicht um ein spezifisches UI.
Was ist etcd und was sollten Teams zu Backups und Recovery tun?
etcd ist die Datenbank der Control Plane und die Quelle der Wahrheit für Desired und Current State. Controller und andere Komponenten beobachten etcd und gleichen den Zustand daran aus.
Praktische Hinweise:
- Behandle etcd wie kritische Daten
- Erstelle regelmäßige Snapshots
- Teste Wiederherstellungen (nicht nur Backups)
Bei Managed Kubernetes: Kläre, was dein Anbieter sichert — und was du zusätzlich sichern musst (zum Beispiel Persistent Volumes und Anwendungsdaten).
Wie formt die Erweiterbarkeit von Kubernetes (CRDs/Operatoren) moderne Plattformen und worauf sollte man achten?
Kubernetes bleibt im Kern schlank und erweitert Funktionalität über Erweiterungen:
- CRDs, um neue API‑Typen zu definieren
- Controller/Operatoren, um diese Ressourcen zu reconciliieren
- Admission Webhooks, um Richtlinien durchzusetzen oder Defaults zu setzen
Das ermöglicht eine „Plattform auf Kubernetes“, kann aber zu Tool‑Sprawl führen. Zur Bewertung einer Kubernetes‑basierten Plattform frage: