Warum Teams mit traditionellen Integrationen an eine Wand laufen
Die meisten Produkte starten mit einfachen Punkt-zu-Punkt-Integrationen: System A ruft System B auf, oder ein kleines Skript kopiert Daten von einem Ort zum anderen. Das funktioniert, bis das Produkt wächst, Teams sich aufteilen und die Zahl der Verbindungen sich vervielfacht. Bald erfordert jede Änderung Koordination über mehrere Services hinweg, weil ein kleines Feld oder eine Statusänderung Kettenreaktionen auslösen kann.
Geschwindigkeit ist meist das Erste, das bricht. Ein neues Feature zu ergänzen bedeutet, mehrere Integrationen zu aktualisieren, mehrere Services neu zu deployen und zu hoffen, dass niemand vom alten Verhalten abhängig war.
Dann wird Debugging schmerzhaft. Wenn etwas in der UI falsch aussieht, ist es schwer, einfache Fragen zu beantworten: Was ist passiert, in welcher Reihenfolge und welches System hat den Wert geschrieben, den Sie sehen?
Oft fehlt eine Audit-Spur. Wenn Daten direkt von einer Datenbank in eine andere geschoben werden (oder unterwegs transformiert werden), geht die Historie verloren. Man sieht vielleicht den Endzustand, aber nicht die Abfolge von Ereignissen, die dazu geführt hat. Incident-Reviews und Kundensupport leiden, weil Sie die Vergangenheit nicht abspielen können, um zu bestätigen, was sich wann und warum geändert hat.
Hier beginnt auch das „wer besitzt die Wahrheit"-Argument. Ein Team sagt: „Der Billing-Service ist die Quelle der Wahrheit.“ Ein anderes sagt: „Der Order-Service ist es.“ In Wahrheit hat jedes System nur eine Teilansicht, und Punkt-zu-Punkt-Integrationen verwandeln diese Uneinigkeit in täglichen Reibungsverlust.
Ein einfaches Beispiel: Eine Bestellung wird erstellt, dann bezahlt, dann erstattet. Wenn drei Systeme sich gegenseitig direkt aktualisieren, kann jedes eine andere Geschichte haben, wenn Retries, Timeouts oder manuelle Korrekturen auftreten.
Das führt zur Kernfrage hinter Kafka Event-Streaming: Brauchen Sie nur, dass Arbeit von A nach B verschoben wird (eine Queue), oder brauchen Sie ein gemeinsames, dauerhaftes Protokoll dessen, was passiert ist, das viele Systeme lesen, zurückspulen und vertrauen können (ein Log)? Die Antwort verändert, wie Sie Ihr System bauen, debuggen und weiterentwickeln.
Jay Kreps, Kafka und die Idee des Logs
Jay Kreps hat Kafka mitgeprägt und wichtiger noch die Art, wie viele Teams über Datenbewegung denken. Die nützliche Verschiebung ist eine Denkweise: Beenden Sie das Denken in einmaligen Nachrichtenlieferungen und beginnen Sie, Systemaktivität als Aufzeichnung zu betrachten.
Die Kernidee ist einfach. Modellieren Sie wichtige Änderungen als Strom unveränderlicher Fakten:
- Eine Bestellung wurde erstellt.
- Eine Zahlung wurde autorisiert.
- Ein Benutzer hat seine E-Mail geändert.
Jedes Ereignis ist eine Tatsache, die nachträglich nicht verändert werden sollte. Wenn sich später etwas ändert, fügen Sie ein neues Ereignis hinzu, das die neue Wahrheit aussagt. Im Laufe der Zeit formen diese Fakten ein Log: eine append-only-Historie Ihres Systems.
Hier unterscheidet sich Kafka Event-Streaming von vielen einfachen Messaging-Setups. Viele Queues sind so gebaut: „senden, verarbeiten, löschen.“ Das ist in Ordnung, wenn Arbeit rein eine Übergabe ist. Die Log-Sicht sagt: „behalte die Historie, damit viele Konsumenten sie jetzt und später nutzen können."
History replayen ist die praktische Superkraft.
Wenn ein Report falsch ist, können Sie dieselbe Ereignishistorie durch einen korrigierten Analytics-Job laufen lassen und sehen, wo sich die Zahlen verändert haben. Wenn ein Bug falsche E-Mails ausgelöst hat, können Sie Ereignisse in einer Testumgebung erneut abspielen und die genaue Timeline reproduzieren. Wenn ein neues Feature historische Daten braucht, können Sie einen neuen Konsumenten bauen, der von Anfang an liest und in seinem eigenen Tempo aufholt.
Ein konkretes Beispiel: Sie fügen Fraud-Checks hinzu, nachdem Sie bereits Monate an Zahlungen verarbeitet haben. Mit einem Log aus Zahlungs- und Konto-Ereignissen können Sie die Vergangenheit erneut abspielen, Regeln an echten Sequenzen trainieren oder kalibrieren, Risiko-Scores für alte Transaktionen berechnen und „fraud_review_requested"-Ereignisse nachträglich erzeugen, ohne die Datenbank umzuschreiben.
Beachten Sie, was das von Ihnen verlangt. Ein log-basierter Ansatz zwingt Sie, Ereignisse klar zu benennen, stabil zu halten und zu akzeptieren, dass mehrere Teams und Services von ihnen abhängig sein werden. Er stellt auch nützliche Fragen: Was ist die Quelle der Wahrheit? Was bedeutet dieses Ereignis langfristig? Was tun wir, wenn wir einen Fehler gemacht haben?
Der Wert liegt nicht in der Persönlichkeit. Er liegt darin, dass ein gemeinsames Log zum Gedächtnis Ihres Systems werden kann — und Gedächtnis lässt Systeme wachsen, ohne bei jedem neuen Konsumenten auseinanderzufallen.
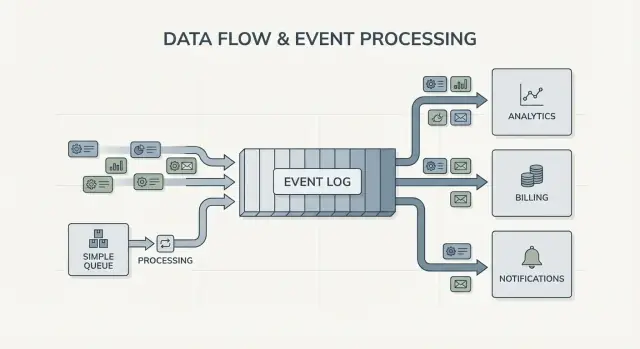
Queue vs Log: das einfachste Denkmodell
Eine Message Queue ist wie eine To-Do-Liste für Ihre Software. Producer legen Arbeit in die Reihe, Konsumenten nehmen das nächste Element, erledigen die Arbeit und das Element ist weg. Das System kümmert sich hauptsächlich darum, dass jede Aufgabe einmal so schnell wie möglich erledigt wird.
Ein Log ist anders. Es ist eine geordnete Aufzeichnung von Fakten, die passiert sind, in einer dauerhaften Reihenfolge. Konsumenten „nehmen" Ereignisse nicht weg. Sie lesen das Log in ihrem eigenen Tempo und können es später erneut lesen. Im Kafka Event-Streaming ist dieses Log die Kernidee.
Ein praktischer Merksatz:
- Queue = Arbeit, die erledigt werden muss. Sobald ein Worker bestätigt hat, verschwindet sie.
- Log = Historie dessen, was passiert ist. Ereignisse bleiben für eine Retention-Periode erhalten.
Retention verändert das Design. Bei einer Queue, wenn Sie später ein neues Feature brauchen, das alte Nachrichten benötigt (Analytics, Fraud-Checks, Replays nach einem Bug), müssen Sie oft eine separate Datenbank ergänzen oder Kopien ablegen. Bei einem Log ist Replay normal: Sie können eine abgeleitete Sicht neu aufbauen, indem Sie von Anfang an lesen (oder von einem bekannten Checkpoint).
Fan-out ist ein weiterer großer Unterschied. Stellen Sie sich vor, der Checkout-Service erzeugt OrderPlaced. Mit einer Queue wählen Sie normalerweise eine Worker-Gruppe, die das verarbeitet, oder duplizieren die Arbeit über mehrere Queues. Mit einem Log können Billing, E-Mail, Inventory, Search-Indexing und Analytics denselben Event-Stream unabhängig voneinander lesen. Jedes Team kann in seinem eigenen Tempo arbeiten und einen neuen Konsumenten hinzuzufügen erfordert keine Änderung beim Produzenten.
Das Denkmodell ist einfach: Verwenden Sie eine Queue, wenn Sie Aufgaben verschieben; verwenden Sie ein Log, wenn Sie Ereignisse aufzeichnen, die viele Teile der Firma jetzt oder später lesen werden.
Was Event-Streaming im Systemdesign ändert
Event-Streaming dreht die Ausgangsfrage um. Statt zu fragen „Wem soll ich diese Nachricht schicken?" beginnen Sie mit „Was ist gerade passiert?" Das klingt klein, verändert aber, wie Sie Ihr System modellieren.
Sie publizieren Fakten wie OrderPlaced oder PaymentFailed und andere Teile des Systems entscheiden, ob, wann und wie sie reagieren.
Mit Kafka Event-Streaming brauchen Produzenten keine Liste direkter Integrationen mehr. Ein Checkout-Service kann ein einziges Ereignis veröffentlichen, ohne wissen zu müssen, ob Analytics, E-Mail, Fraud-Checks oder ein zukünftiger Recommendation-Service es verwenden werden. Neue Konsumenten können später erscheinen, alte können pausiert werden, und der Produzent verhält sich gleich.
Das ändert auch, wie Sie von Fehlern wiederherstellen. In einer reinen Nachrichtenwelt geht vieles verloren, wenn ein Konsument etwas verpasst oder einen Bug hatte — sofern Sie nicht eigene Backups gebaut haben. Mit einem Log können Sie den Code reparieren und die Historie erneut abspielen, um den korrekten Zustand wiederherzustellen. Das schlägt oft manuelle Datenbank-Änderungen oder einmalige Skripte, denen niemand vertraut.
In der Praxis zeigt sich der Wandel so: Sie behandeln Ereignisse als dauerhaftes Protokoll, fügen Features durch Subscriben statt durch Ändern von Produzenten hinzu, Sie können Read-Modelle (Search-Indizes, Dashboards) neu aufbauen und erhalten klarere Zeitlinien darüber, was zwischen Services passiert ist.
Observability verbessert sich, weil das Ereignislog zur gemeinsamen Referenz wird. Wenn etwas schiefgeht, können Sie einer Geschäftssequenz folgen: Bestellung erstellt, Inventar reserviert, Zahlung erneut versucht, Versand geplant. Diese Timeline ist oft leichter zu verstehen als verstreute Applikationslogs, weil sie sich auf Geschäftsereignisse konzentriert.
Ein konkretes Beispiel: Wenn ein Rabatt-Bug Bestellungen zwei Stunden lang falsch bepreist hat, können Sie einen Fix deployen und die betroffenen Ereignisse erneut abspielen, um Summen neu zu berechnen, Rechnungen zu aktualisieren und Analytics zu korrigieren. Sie korrigieren Ergebnisse durch Neableiten, nicht durch Raten, welche Tabellen manuell gepatcht werden müssen.
Wann eine einfache Queue ausreicht
Eine einfache Queue ist das richtige Werkzeug, wenn Sie Arbeit verschieben, nicht eine langfristige Aufzeichnung aufbauen. Das Ziel ist, eine Aufgabe an einen Worker zu übergeben, auszuführen und dann zu vergessen. Wenn niemand die Vergangenheit erneut abspielen, alte Ereignisse inspizieren oder später neue Konsumenten hinzufügen muss, hält eine Queue die Dinge einfacher.
Queues sind ideal für Background-Jobs: Willkommens-E-Mails senden, Bilder nach dem Upload skalieren, nächtliche Reports generieren oder langsame externe APIs aufrufen. In diesen Fällen ist die Nachricht nur ein Arbeitsticket. Hat ein Worker den Job erledigt, hat auch das Ticket seinen Zweck erfüllt.
Eine Queue passt auch zum üblichen Ownership-Modell: Eine Consumer-Gruppe ist für die Arbeit verantwortlich, und andere Services sollen dieselbe Nachricht nicht unabhängig lesen.
Eine Queue reicht in der Regel, wenn überwiegend Folgendes zutrifft:
- Die Daten haben einen kurzlebigen Wert.
- Ein Team oder Service besitzt den Job End-to-End.
- Replays und lange Retention sind keine Anforderungen.
- Debugging hängt nicht vom erneuten Abspielen der Historie ab.
Beispiel: Ein Produkt lädt Nutzerfotos hoch. Die App schreibt eine „resize image“-Aufgabe in eine Queue. Worker A nimmt sie, erzeugt Thumbnails, speichert sie und markiert die Aufgabe als erledigt. Wenn die Aufgabe zweimal läuft, ist das Ergebnis gleich (idempotent), sodass at-least-once-Delivery in Ordnung ist. Kein anderer Service muss diese Aufgabe später lesen.
Wenn Ihre Bedürfnisse in Richtung geteilter Fakten (viele Konsumenten), Replay, Audit oder „Was glaubte das System letzte Woche?“ wandern, lohnt sich Kafka Event-Streaming und ein log-basierter Ansatz.
Wann ein log-basierter Ansatz sich lohnt
Ein log-basierter Ansatz zahlt sich aus, wenn Ereignisse aufhören, Einmalnachrichten zu sein, und zu geteilter Historie werden. Statt „senden und vergessen" behalten Sie eine geordnete Aufzeichnung, die viele Teams jetzt oder später in ihrem eigenen Tempo lesen können.
Das deutlichste Zeichen sind mehrere Konsumenten. Ein Ereignis wie OrderPlaced kann Billing, E-Mail, Fraud-Checks, Suchindexierung und Analytics speisen. Mit einem Log liest jeder Konsument denselben Stream unabhängig. Sie müssen keine eigene Fan-Out-Pipeline bauen oder koordinieren, wer die Nachricht zuerst bekommt.
Ein weiterer Vorteil ist die Frage „Was wussten wir damals?" Wenn ein Kunde eine Charge bestreitet oder eine Empfehlung falsch war, macht ein append-only-Protokoll es möglich, die Fakten so abzuspielen, wie sie damals ankamen. Eine solche Audit-Spur lässt sich später nur schwer an eine einfache Queue anheften.
Sie gewinnen auch eine praktische Möglichkeit, neue Features hinzuzufügen, ohne alte umzuschreiben. Wenn Sie später eine „Shipping Status"-Seite brauchen, kann ein neuer Service abonnieren und die Historie nachholen, um seinen Zustand aufzubauen, statt Upstreams um Exporte zu bitten.
Ein log-basierter Ansatz lohnt sich häufig, wenn eines oder mehrere dieser Bedürfnisse auftreten:
- Dieselben Ereignisse müssen mehrere Systeme versorgen (Analytics, Search, Billing, Support-Tools).
- Sie benötigen Replay, Audit oder Untersuchungen basierend auf vergangenen Fakten.
- Neue Services müssen aus der Historie backfillen, ohne einmalige Jobs.
- Reihenfolge ist pro Entität wichtig (pro Bestellung, pro Nutzer).
- Event-Formate werden sich entwickeln und Sie brauchen eine kontrollierte Versionierung.
Ein häufiges Muster: Ein Produkt startet mit Bestellungen und E-Mails. Später will Finance Umsatzreports, Product Funnel-Analysen und Ops ein Live-Dashboard. Wenn jedes neue Bedürfnis Sie zwingt, Daten durch neue Pipelines zu kopieren, steigen die Kosten schnell. Ein gemeinsames Event-Log erlaubt Teams, auf derselben Quelle der Wahrheit aufzubauen, während das System wächst und sich Event-Shapes ändern.
Wie man entscheidet — Schritt für Schritt
Die Wahl zwischen einer einfachen Queue und einem log-basierten Ansatz wird leichter, wenn Sie sie wie eine Produktentscheidung behandeln. Starten Sie damit, was in einem Jahr wahr sein muss, nicht nur was diese Woche funktioniert.
Ein praktischer 5-Schritte-Entscheidungsweg
-
Kartieren Sie Producer und Reader. Schreiben Sie auf, wer heute Ereignisse erzeugt und wer sie liest, und fügen Sie wahrscheinliche zukünftige Konsumenten hinzu (Analytics, Suchindex, Fraud-Checks, Notifications). Erwarten Sie viele unabhängige Leser, macht ein Log Sinn.
-
Fragen Sie, ob Sie die Historie erneut lesen müssen. Seien Sie konkret: Replay nach Bugfix, Backfills oder Konsumenten, die unterschiedlich schnell lesen. Queues sind großartig für einmalige Übergaben. Logs sind besser, wenn Sie ein Protokoll zum Replay brauchen.
-
Definieren Sie, was „done" bedeutet. Bei einigen Workflows heißt done: „Der Job lief“ (E-Mail gesendet, Bild skaliert). Bei anderen heißt done: „Das Ereignis ist ein dauerhafter Fakt" (eine Bestellung wurde platziert, eine Zahlung autorisiert). Dauerhafte Fakten schieben Sie Richtung Log.
-
Wählen Sie Delivery-Erwartungen und wie Sie Duplikate behandeln. At-least-once-Delivery ist üblich, also können Duplikate auftreten. Wenn ein Duplikat schaden kann (doppelte Abbuchung), planen Sie Idempotenz: speichern Sie verarbeitete Event-IDs, nutzen Sie Unique-Constraints oder machen Sie Updates wiederholsicher.
-
Starten Sie mit einer dünnen Scheibe. Wählen Sie einen Event-Stream, der leicht verständlich ist, und wachsen Sie von dort. Wenn Sie Kafka Event-Streaming wählen, halten Sie das erste Topic fokussiert, benennen Sie Events klar und mischen Sie keine unzusammenhängenden Event-Typen.
Ein konkretes Beispiel: Wenn OrderPlaced später Shipping, Invoicing, Support und Analytics speisen wird, erlaubt ein Log jedem Team, in seinem Tempo zu lesen und bei Fehlern zurückzuspulen. Wenn Sie nur einen Background-Worker brauchen, der eine Quittungs-E-Mail sendet, reicht meistens eine einfache Queue.
Beispiel: Order-Ereignisse in einem wachsenden Produkt
Stellen Sie sich einen kleinen Online-Shop vor. Zuerst muss er nur Bestellungen annehmen, eine Karte belasten und eine Versand-Anfrage erstellen. Die einfachste Version ist ein Hintergrundjob nach dem Checkout: „process order." Er ruft die Payment-API auf, aktualisiert die Order-Zeile in der Datenbank und ruft dann Shipping auf.
Dieses Queue-Muster funktioniert gut, wenn es einen klaren Workflow gibt, nur ein Consumer nötig ist und Retries sowie Dead Letters die meisten Fehlerfälle abdecken.
Es wird problematisch, wenn der Shop wächst. Support will automatische „Wo ist meine Bestellung?"-Updates. Finance braucht tägliche Umsatzzahlen. Product will Kunden-E-Mails. Fraud-Checks sollten vor dem Versand stattfinden. Mit einem einzelnen „process order"-Job bearbeiten Sie denselben Worker immer wieder, fügen Verzweigungen hinzu und riskieren neue Bugs im Kernfluss.
Mit einem log-basierten Ansatz erzeugt der Checkout kleine Fakten als Events, und jedes Team kann daraus seinen Zustand bauen. Typische Events könnten sein:
OrderPlacedPaymentConfirmedItemShippedRefundIssued
Der entscheidende Wandel ist Ownership. Der Checkout-Service besitzt OrderPlaced. Der Payments-Service besitzt PaymentConfirmed. Shipping besitzt ItemShipped. Später können neue Konsumenten ohne Änderung des Produzenten auftauchen: Ein Fraud-Service liest OrderPlaced und PaymentConfirmed zur Risikobewertung, ein E-Mail-Service sendet Quittungen, Analytics baut Funnels und Support-Tools halten eine Timeline dessen, was passiert ist.
Hier zahlt sich Kafka Event-Streaming aus: das Log behält die Historie, sodass neue Konsumenten von Anfang an oder ab einem bekannten Punkt aufholen können, anstatt jeden Upstream-Service um einen weiteren Webhook zu bitten.
Das Log ersetzt nicht Ihre Datenbank. Sie brauchen weiterhin eine Datenbank für den aktuellen Zustand: den letzten Bestellstatus, Kunden-Datensätze, Inventarzahlen und transaktionale Regeln (z. B. „nicht versenden, solange die Zahlung nicht bestätigt ist"). Denken Sie an das Log als Aufzeichnung der Änderungen und die Datenbank als Ort, an dem Sie „was jetzt wahr ist" abfragen.
Häufige Fehler und Fallen
Event-Streaming kann Systeme sauberer wirken lassen, aber einige häufige Fehler können den Nutzen schnell zunichtemachen. Die meisten entstehen, wenn man ein Ereignislog wie eine Fernbedienung statt wie ein Protokoll behandelt.
Eine häufige Falle ist, Ereignisse als Commands zu schreiben, z. B. „SendWelcomeEmail" oder „ChargeCardNow." Das koppelt Konsumenten stark an Ihre Absicht. Ereignisse funktionieren besser als Fakten: „UserSignedUp" oder „PaymentAuthorized." Fakten altern gut. Neue Teams können sie später wiederverwenden, ohne raten zu müssen, was gemeint war.
Duplikate und Retries sind die nächste große Schmerzquelle. In realen Systemen retryen Produzenten und Konsumenten verarbeiten neu. Wenn Sie das nicht einplanen, entstehen doppelte Abbuchungen, doppelte E-Mails und verärgerte Supportfälle. Die Lösung ist nicht exotisch, muss aber bewusst sein: idempotente Handler, stabile Event-IDs und Geschäftsregeln, die „bereits angewendet" erkennen.
Gängige Fallstricke:
- Events im Command-Stil, die Dienste anweisen, was zu tun ist, statt aufzuzeichnen, was passiert ist.
- Konsumenten, die brechen, wenn sie dasselbe Event zweimal sehen.
- Streams zu früh aufteilen, sodass ein Geschäftsfluss über zu viele Topics verstreut ist.
- Schema-Regeln ignorieren, bis eine kleine Änderung ältere Konsumenten bricht.
- Streaming als Ersatz für gutes Datenbankdesign behandeln.
Schemata und Versionierung verdienen besondere Aufmerksamkeit. Selbst mit JSON brauchen Sie einen klaren Vertrag: Pflichtfelder, optionale Felder und wie Änderungen ausgerollt werden. Eine kleine Änderung wie ein Feldumbenennung kann Analytics, Billing oder mobile Apps, die langsamer aktualisieren, stillschweigend brechen.
Eine andere Falle ist Über-Segmentierung. Teams erstellen manchmal für jedes Feature einen neuen Stream. Einen Monat später kann niemand mehr sagen: „Was ist der aktuelle Zustand einer Bestellung?", weil die Geschichte über zu viele Orte verteilt ist.
Event-Streaming ersetzt nicht die Notwendigkeit solider Datenmodelle. Sie brauchen weiterhin eine Datenbank, die die aktuelle Wahrheit repräsentiert. Das Log ist die Historie, nicht Ihre ganze Anwendung.
Kurze Checkliste und nächste Schritte
Wenn Sie unsicher sind zwischen Queue und Kafka Event-Streaming, starten Sie mit ein paar schnellen Checks. Sie zeigen, ob Sie eine einfache Übergabe zwischen Workern brauchen oder ein Log, das Sie jahrelang wiederverwenden können.
Kurze Checks
- Brauchen Sie Replay (für Backfills, Bugfixes oder neue Features) und wie weit zurück?
- Werden mehr als ein Konsument dieselben Events jetzt oder bald brauchen (Analytics, Suche, E-Mails, Fraud, Billing)?
- Brauchen Sie Retention, damit Teams die Historie ohne erneutes Senden durch den Produzenten lesen können?
- Wie wichtig ist Reihenfolge und auf welcher Ebene: pro Entität (pro Bestellung, pro Nutzer) oder global?
- Können Konsumenten idempotent sein (sicher, dasselbe Event erneut zu verarbeiten ohne doppelte Abbuchungen, doppelte E-Mails oder doppelte Updates)?
Wenn Sie bei Replay „nein", „nur ein Konsument" und „kurzlebige Nachrichten" antworten, reicht meist eine einfache Queue. Wenn Sie bei Replay, mehreren Konsumenten oder längerer Retention mit „ja" antworten, zahlt sich ein log-basierter Ansatz aus, weil er einen Event-Stream in eine gemeinsame Quelle der Wahrheit verwandelt, auf der andere Systeme aufbauen können.
Nächste Schritte
Setzen Sie die Antworten in einen kleinen, testbaren Plan um.
- Listen Sie 5–10 Kernereignisse in einfacher Sprache auf (z. B.
OrderPlaced, PaymentAuthorized, OrderShipped) und notieren Sie, wer jedes publiziert und wer es konsumiert.
- Entscheiden Sie den Ordering-Key (oft pro Entität, z. B. orderId) und dokumentieren Sie, was „korrekte Reihenfolge" bedeutet.
- Definieren Sie eine Idempotenz-Regel pro Konsument (z. B. den zuletzt verarbeiteten Event-ID pro Bestellung speichern).
- Wählen Sie eine Retention, die zu Ihren Bedürfnissen passt (Tage für queue-ähnliche Workflows, Wochen/Monate wenn Replay wichtig ist).
- Führen Sie eine End-to-End-Scheibe in einer Sandbox durch, bevor Sie das ganze System festlegen.
Wenn Sie schnell prototypen, können Sie den Event-Flow im Koder.ai Planungsmodus skizzieren und das Design iterieren, bevor Sie Event-Namen und Retry-Regeln festschreiben. Da Koder.ai Source-Code-Export, Snapshots und Rollback unterstützt, ist es auch praktisch, um eine einzelne Producer-Consumer-Scheibe zu testen und Event-Formen ohne frühen Produktions-Technical-Debt anzupassen.