19. Apr. 2025·8 Min
Kelsey Hightowers Cloud‑Native‑Klarheit: Kubernetes erklärt
Wie Kelsey Hightowers klare Lehrweise Teams half, Kubernetes und Betriebs‑konzepte zu verstehen — und so Vertrauen, gemeinsame Sprache und breitere Adoption zu fördern.
Warum Klarheit in Cloud‑Native‑Umgebungen wichtig ist
Cloud‑native Tools versprechen Geschwindigkeit und Flexibilität, bringen aber auch neue Begriffe, neue Bausteine und neue Denkweisen für den Betrieb mit sich. Wenn die Erklärung verschwommen ist, verlangsamt das die Einführung aus einem einfachen Grund: Menschen können das Werkzeug nicht sicher mit ihren tatsächlichen Problemen verbinden. Teams zögern, Führungskräfte verschieben Entscheidungen, und frühe Experimente bleiben halbfertige Piloten.
Klarheit verändert diese Dynamik. Eine eindeutige Erklärung macht aus „Kubernetes erklärt“ keine Marketingfloskel, sondern ein geteiltes Verständnis: was Kubernetes tut, was es nicht tut und wofür Ihr Team im Alltag verantwortlich ist. Sobald dieses mentale Modell steht, werden Gespräche praktisch — über Workloads, Zuverlässigkeit, Skalierung, Sicherheit und die betrieblichen Gewohnheiten, die nötig sind, um produktive Systeme zu betreiben.
Warum gute Erklärungen die Einführung beschleunigen
Wenn Konzepte in klarer Sprache erklärt werden, können Teams:
- Trade‑offs schneller bewerten (und aufhören, jedes Feature als Pflicht zu betrachten).
- Voraussetzungen früh erkennen (Skills, Ownership, On‑Call‑Erwartungen).
- Die Angst vor „Produktion kaputtmachen“ reduzieren, weil das System handhabbar erscheint.
- Eine gemeinsame Basis zwischen Entwicklern, Ops, SRE und Führung herstellen.
Mit anderen Worten: Kommunikation ist kein nettes Extra; sie gehört zum Rollout‑Plan.
Was Sie in diesem Artikel lernen
Dieser Beitrag konzentriert sich darauf, wie Kelsey Hightowers Lehrstil zentrale DevOps‑Konzepte und Kubernetes‑Grundlagen zugänglich gemacht hat — und wie dieser Ansatz die breitere Cloud‑Native‑Adoption beeinflusst hat. Sie nehmen Praxislektionen mit, die Sie in Ihrer Organisation anwenden können:
- Wie man Entscheidungen im Plattform‑Engineering ohne Fachjargon erklärt.
- Wie man das „Warum“ hinter operativer Exzellenz vermittelt, nicht nur das „Wie“.
- Wie gemeinschaftsgetriebener Wissensaustausch die reale Nutzung beschleunigt.
Ziel ist nicht, über Tools zu streiten. Es geht darum zu zeigen, wie klare Kommunikation — wiederholt, geteilt und von einer Community verbessert — eine Branche von Neugier zu selbstbewusstem Einsatz führt.
Wer ist Kelsey Hightower (und warum hört man auf ihn)
Kelsey Hightower ist eine bekannte Stimme in der Kubernetes‑Bildung und Community, deren Arbeit vielen Teams geholfen hat zu verstehen, was Containerorchestrierung tatsächlich bedeutet — besonders die operativen Teile, die man oft auf die harte Tour lernt.
Er ist sichtbar in praktischen, öffentlichen Rollen: Vorträge auf Konferenzen, Tutorials, Talks und aktive Teilnahme an der Cloud‑Native‑Community, in der Praktiker Muster, Fehler und Korrekturen teilen. Anstatt Kubernetes als magisches Produkt darzustellen, behandelt seine Arbeit das System als etwas, das man betreibt — mit beweglichen Teilen, Trade‑offs und realen Ausfallmodi.
Eine Stimme, die bei Operatoren (und Einsteigern) ankommt
Was beständig auffällt, ist Empathie für die Menschen, die beim Ausfall die Verantwortung tragen: On‑Call‑Ingenieure, Plattformteams, SREs und Entwickler, die liefern wollen und gleichzeitig neue Infrastruktur lernen.
Diese Empathie zeigt sich darin, wie er erklärt:
- wofür Kubernetes verantwortlich ist (und wofür nicht),
- woher Komplexität kommt (verteilte Systeme, Netzwerk, Identität, Upgrades),
- wie man Intuition aufbaut, statt Befehle auswendig zu lernen.
Ebenso spricht er Anfänger an, ohne herablassend zu sein. Der Ton ist direkt, bodenständig und zurückhaltend bei absoluten Behauptungen — eher „so läuft es unter der Haube“ als „das ist der einzig richtige Weg“.
Beobachtbare Arbeit statt Persönlichkeit
Man muss niemanden zum Maskottchen erklären, um den Einfluss zu sehen. Die Beweise stehen in den Materialien selbst: häufig zitierte Vorträge, praxisnahe Lernressourcen und Erklärungen, die von anderen Lehrenden und internen Plattformteams übernommen werden. Wenn Leute sagen, sie hätten endlich ein Konzept wie Controlplanes, Zertifikate oder Cluster‑Bootstrapping „verstanden“, dann oft, weil jemand es schlicht erklärt hat — und viele dieser einfachen Erklärungen lassen sich auf seinen Stil zurückführen.
Wenn Kubernetes‑Adoption teilweise ein Kommunikationsproblem ist, erinnert sein Einfluss daran, dass klare Lehre ebenfalls eine Form von Infrastruktur ist.
Kubernetes, bevor es zugänglich wirkte
Bevor Kubernetes die Standardantwort auf „wie betreiben wir Container in Produktion?“ wurde, wirkte es oft wie eine dichte Wand aus neuer Terminologie und Annahmen. Selbst Teams, die mit Linux, CI/CD und Cloud‑Services vertraut waren, stellten grundlegende Fragen — und fühlten sich dann, als sollten sie diese Fragen gar nicht erst haben.
Frühe Verwirrung: neue Begriffe, neue mentale Modelle
Kubernetes brachte eine andere Art des Denkens über Anwendungen mit sich. Statt „ein Server läuft meine App“ gab es plötzlich Pods, Deployments, Services, Ingresses, Controller und Cluster. Jeder Begriff klang für sich simpel, aber seine Bedeutung hing davon ab, wie er mit dem Rest verbunden war.
Ein gängiger Stolperstein war das Auseinanderklaffen der mentalen Modelle:
- „Wohin SSH ich?“ (Oft: gar nicht.)
- „Auf welcher Maschine läuft meine App?“ (Das kann sich ändern.)
- „Warum wurde sie neu gestartet?“ (Weil es so vorgesehen ist.)
Es ging dabei nicht nur um das Lernen eines Werkzeugs, sondern um ein System, das Infrastruktur als beweglich behandelt.
Häufige Ängste: Zuverlässigkeit, Sicherheit und Day‑2‑Betrieb
Die erste Demo zeigt vielleicht das reibungslose Skalieren eines Containers. Die Angst setzt später ein, wenn sich die realen betrieblichen Fragen vorstellen:
- Was passiert bei Node‑Ausfall?
- Wie verwalten wir Secrets sicher?
- Wer bekommt welche Zugriffsrechte im Cluster?
- Wie patchen, upgraden und rollen wir zurück, ohne Produktion zu beschädigen?
Viele Teams hatten keine Angst vor YAML — sie fürchteten versteckte Komplexität, bei der Fehler still bleiben, bis ein Ausfall eintritt.
Die Lücke zwischen Marketingversprechen und realer Einrichtung
Kubernetes wurde oft als sauberer Plattform‑Flow präsentiert, bei dem man „einfach deployt“ und alles automatisiert läuft. In der Praxis erfordert das Erreichen dieses Zustands Entscheidungen: Netzwerk, Storage, Identität, Policies, Monitoring, Logging und Upgrade‑Strategie.
Diese Lücke erzeugte Frust. Menschen lehnten Kubernetes nicht per se ab; sie reagierten darauf, wie schwer es war, das Versprechen („einfach, portabel, selbstheilend“) mit den notwendigen Schritten für ihre Umgebung zu verbinden.
Ein Lehrstil, gebaut für arbeitende Ingenieure
Kelsey Hightower unterrichtet wie jemand, der On‑Call war, ein Deploy schiefging und trotzdem am nächsten Tag liefern musste. Das Ziel ist nicht, mit Vokabular zu beeindrucken — es ist, ein mentales Modell zu bauen, das Sie um 2 Uhr morgens bei einem Pager nutzen können.
Klare Sprache, genau dann, wenn sie gebraucht wird
Eine zentrale Gewohnheit ist, Begriffe genau in dem Moment zu definieren, in dem sie relevant sind. Statt ein Vokabel‑Feuerwerk gleich zu Beginn loszulassen, erklärt er ein Konzept im Kontext: was ein Pod ist, während er gleichzeitig sagt, warum man Container gruppiert, oder was ein Service tut, wenn die Frage lautet: „Wie finden Anfragen meine App?“
Dieser Ansatz reduziert das „Ich bin hinterher“-Gefühl, das viele Ingenieure bei Cloud‑Native‑Themen haben. Man muss kein Glossar auswendig lernen; man lernt, indem man einem Problem zur Lösung folgt.
Konkrete Beispiele statt abstrakter Diagramme
Seine Erklärungen beginnen häufig mit etwas Greifbarem:
- „Wenn dieser Prozess stirbt, was startet ihn neu?“
- „Wenn der Node verschwindet, was passiert mit dem Traffic?“
- „Wenn wir von 2 auf 20 Instanzen skalieren, wie bleiben Clients verbunden?“
Diese Fragen führen natürlich zu Kubernetes‑Primitiven, sind aber in Szenarien verankert, die Ingenieure aus realen Systemen kennen. Diagramme helfen zwar, sind aber nicht die ganze Lektion — das Beispiel trägt die Hauptlast.
Respekt vor der operativen Realität
Wichtig ist, dass die Lehre die unschönen Teile einschließt: Upgrades, Incidents und Trade‑offs. Es heißt nicht „Kubernetes macht alles einfach“, sondern „Kubernetes liefert Mechanismen — jetzt müsst ihr sie betreiben“.
Das bedeutet auch, Einschränkungen offen anzusprechen:
- Version‑Skew und Upgrade‑Planung sind nicht optional.
- Observability ist kein Häkchen; sie ist die Art, wie man verteilte Fehler debuggt.
- On‑Call‑Last gehört zur Systemgestaltung, nicht als Nachgedanke.
Deshalb spricht seine Arbeit besonders Praktiker an: Produktion ist das Klassenzimmer, und Klarheit ist eine Form von Respekt.
„Kubernetes the Hard Way“: die Grundlagen lernen
Ein Referenz-Backend aufsetzen
Erstelle schnell eine Go-API mit PostgreSQL, damit Ops-Gespräche konkret bleiben.
„Kubernetes the Hard Way“ ist deshalb einprägsam, weil es einen berührt, was die meisten Tutorials verbergen. Statt durch einen Managed‑Service‑Wizard zu klicken, setzt man ein funktionierendes Cluster Baustein für Baustein zusammen. Dieser „learning by doing“‑Ansatz verwandelt Infrastruktur aus einer Blackbox in ein System, über das man schließen kann.
Wie „learning by doing“ aussieht
Der Walkthrough lässt dich die Bausteine selbst erstellen: Zertifikate, kubeconfigs, Controlplane‑Komponenten, Netzwerk und Worker‑Setup. Selbst wenn du nicht vorhast, Kubernetes so in Produktion zu betreiben, lehrt die Übung, wofür jede Komponente verantwortlich ist und was passieren kann, wenn sie falsch konfiguriert ist.
Du hörst nicht bloß „etcd ist wichtig“ — du siehst, warum, was es speichert und was passiert, wenn es nicht verfügbar ist. Du merkst, dass die API‑Server „die Haustür“ sind, indem du sie konfigurierst und verstehst, welche Schlüssel vor einer Anfrage geprüft werden.
Warum Grundlagen Vertrauen schaffen
Viele Teams zögern, weil sie nicht sehen können, was unter der Haube passiert. Vom Grundlegenden auszugehen kehrt dieses Gefühl um. Wenn man die Vertrauenskette (Zertifikate), die Quelle der Wahrheit (etcd) und die Idee der Control‑Loop (Controller, die fortlaufend gewünschten vs. aktuellen Zustand abgleichen) versteht, wirkt das System weniger mysteriös.
Dieses Vertrauen ist praktisch: Es hilft, Anbieterfeatures zu bewerten, Incidents zu interpretieren und sinnvolle Defaults zu wählen. Man kann sagen: „Wir wissen, was dieser managed Service abstrahiert“, statt nur zu hoffen, dass er korrekt ist.
Schritt‑für‑Schritt reduziert die Angst vor Komplexität
Ein guter Walkthrough zerlegt „Kubernetes“ in kleine, testbare Schritte. Jeder Schritt hat ein klares erwartetes Ergebnis — Service startet, Healthcheck besteht, Node tritt bei. Fortschritt ist messbar, und Fehler sind lokal.
Diese Struktur senkt die Angst: Komplexität wird zu einer Reihe verständlicher Entscheidungen, nicht zu einem einzigen Sprung ins Unbekannte.
Kernkonzepte von Kubernetes verständlich machen
Viel Verwirrung entsteht, wenn man Kubernetes als Funktionshäufung statt als einfaches Versprechen behandelt: Du beschreibst, was du willst, und das System bemüht sich, die Realität daran anzupassen.
Gewünschter Zustand (was du willst)
„Desired state“ ist einfach das, was dein Team als Ergebnis festlegt: Führe drei Kopien dieser App aus, mache sie unter einer stabilen Adresse erreichbar, begrenze die CPU‑Nutzung. Es ist kein Schritt‑für‑Schritt‑Runbook.
Diese Unterscheidung spiegelt alltägliche Ops‑Arbeit wider. Statt „SSH zu Server A, starte Prozess, kopiere Konfig“ deklarierst du das Ziel, und die Plattform übernimmt repetitive Aufgaben.
Rekonziliation (wie es erhalten bleibt)
Reconciliation ist die konstante Prüf‑und‑Korrektur‑Schleife. Kubernetes vergleicht, was jetzt läuft, mit dem, was du verlangt hast, und wenn etwas abweicht — ein Pod abgestürzt, ein Node verschwunden, eine Konfiguration geändert — ergreift es Maßnahmen, um die Lücke zu schließen.
In menschlichen Worten: Es ist ein nie schlafender On‑Call‑Ingenieur, der kontinuierlich den vereinbarten Standard wiederherstellt.
Hier hilft es, Konzepte von Implementierungsdetails zu trennen. Das Konzept lautet „das System korrigiert Drift“. Die Umsetzung kann Controller, ReplicaSets oder Rollout‑Strategien beinhalten — diese Details kann man später lernen, ohne das Kernverständnis zu verlieren.
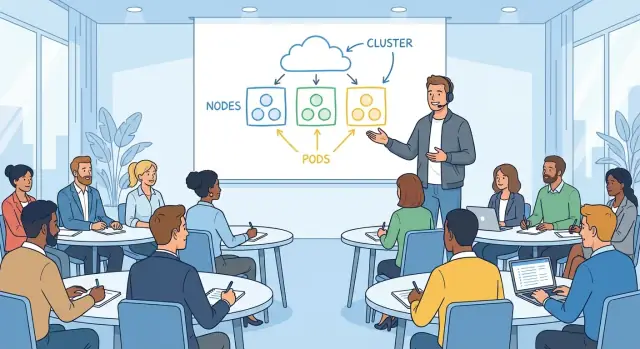
Scheduling (wo es läuft)
Scheduling beantwortet eine praktische Frage, die jeder Operator kennt: Auf welcher Maschine soll diese Workload laufen? Kubernetes betrachtet verfügbare Kapazität, Einschränkungen und Richtlinien und platziert die Workloads entsprechend.
Das Verbinden von Primitiven mit vertrauten Aufgaben macht es verständlich:
- Pods sind eine „ausführbare Einheit“ (ähnlich einer Prozessgruppe).
- Deployments sorgen dafür, dass N Kopien laufen und Updates sicher erfolgen.
- Services bieten eine stabile Erreichbarkeit, auch wenn Instanzen wechseln.
Wenn Sie Kubernetes als „deklarieren, rekonziliieren, platzieren“ rahmen, wird der Rest Wortschatz — nützlich, aber nicht mehr mysteriös.
Betrieb erklären, ohne einzuschüchtern
Operations‑Talk kann wie eine Geheimsprache klingen: SLIs, Error Budgets, „Blast Radius“, Kapazitätsplanung. Fühlt sich jemand ausgeschlossen, nickt er nur mit oder meidet das Thema — beides führt zu fragilen Systemen.
Kelseys Stil macht Ops zu normaler Ingenieursarbeit: praktische Fragen, die man lernen kann, auch als Neuling.
Ops in alltägliche Entscheidungen übersetzen
Statt Operations als abstrakte „Best Practices“ zu behandeln, übersetze sie in das, was dein Service unter Last tun muss.
Zuverlässigkeit wird zu: Was bricht zuerst, und wie bemerken wir es? Kapazität wird zu: Was passiert bei Montagmorgen‑Traffic? Fehlermodi werden zu: Welcher Dienst wird lügen, timeouts verursachen oder partielle Daten liefern? Observability wird zu: Wenn ein Kunde sich beschwert, können wir in fünf Minuten sagen, was sich geändert hat?
Wenn Ops‑Konzepte so formuliert werden, klingen sie nicht mehr wie Trivia, sondern wie gesunder Menschenverstand.
Mache Trade‑offs explizit (und akzeptabel)
Große Erklärungen behaupten nicht, es gäbe nur einen richtigen Weg — sie zeigen die Kosten jeder Wahl.
Einfachheit vs. Kontrolle: Ein verwalteter Dienst reduziert Toil, kann aber tiefergehende Anpassungen erschweren.
Geschwindigkeit vs. Sicherheit: Schnell zu liefern kann heute weniger Prüfungen bedeuten, erhöht aber die Wahrscheinlichkeit, morgen in Produktion debuggen zu müssen.
Indem man Trade‑offs offen benennt, können Teams produktiv streiten, ohne jemanden für Unwissenheit zu beschämen.
Normalisiere Fragen, Fehler und Iteration
Operations lernt man durch Beobachten realer Incidents und Beinahefehler, nicht durch Auswendiglernen von Begriffen. Eine gesunde Ops‑Kultur behandelt Fragen als Arbeit, nicht als Schwäche.
Eine praktische Gewohnheit: Nach einem Ausfall drei Dinge notieren — was Sie erwarteten, was tatsächlich passierte und welches Signal früher gewarnt hätte. Diese kleine Schleife verwandelt Verwirrung in bessere Runbooks, klarere Dashboards und ruhigere On‑Call‑Dienste.
Wenn Sie diese Denkweise verbreiten wollen, lehren Sie sie genauso: klare Worte, ehrliche Trade‑offs und Erlaubnis, laut zu lernen.
Wie klare Erklärungen sich in einer Community verbreiten
Demo-Umgebung hosten
Stelle deinen Prototypen bereit und hoste ihn, damit das Team ihn gemeinsam testen kann.
Kluge Erklärungen helfen nicht nur einer Person. Sie verbreiten sich. Wenn ein Sprecher oder Autor Kubernetes greifbar macht — zeigt, was jedes Teil tut, warum es existiert und wo es in der Praxis versagt — dann wiederholen andere diese Ideen in Flurgesprächen, übernehmen sie in interne Docs und lehren sie auf Meetups neu.
Ein gemeinsamer Wortschatz reduziert Reibung
Kubernetes hat viele Begriffe, die vertraut klingen, aber spezifische Bedeutungen tragen: Cluster, Node, Controlplane, Pod, Service, Deployment. Präzise Erklärungen verhindern, dass Teams aneinander vorbeireden.
Ein paar Beispiele, wie ein geteilter Wortschatz wirkt:
- Ein Entwickler sagt „der Service ist kaputt“ — und alle wissen, ob damit DNS, Load‑Balancing oder Selector‑Probleme gemeint sind.
- Ein SRE sagt „die Controlplane ist degraded“ — das unterscheidet sich klar davon, „die App ist down“.
- Produktverantwortliche hören „Deployment“ und lernen, dass das ein Kubernetes‑Objekt ist — nicht nur „wir haben Code ausgeliefert“.
Diese Ausrichtung beschleunigt Debugging, Planung und Onboarding, weil weniger Zeit fürs Übersetzen verloren geht.
Vertrauen ersetzt Angst
Viele Ingenieure meiden Kubernetes anfangs nicht, weil sie es nicht lernen könnten, sondern weil es wie eine Blackbox wirkt. Klare Lehre ersetzt Geheimnis durch ein mentales Modell: „So spricht A mit B, hier lebt Zustand, so wird Traffic geroutet.“
Wenn dieses Modell passt, fühlt sich Experimentieren sicherer an. Menschen sind eher bereit:
- ein kleines Cluster für Tests aufzusetzen,
- Logs und Events zu lesen, ohne zu raten,
- bessere Fragen in Code‑Reviews und Incident‑Kanälen zu stellen.
Der Welleneffekt: Vorträge, Meetups und Docs
Wenn Erklärungen einprägsam sind, wiederholt die Community sie. Ein einfaches Diagramm oder eine Analogie wird zur Standardart zu lehren und beeinflusst:
- Meetup‑Präsentationen und Konferenzvorträge (neue Sprecher übernehmen die Einordnung),
- Open‑Source‑Dokumentationen (mehr „Warum“ neben „Wie“),
- Interne Runbooks und Onboarding‑Guides (klarere Schritte, klarere Erwartungen).
Mit der Zeit wird Klarheit zu einem kulturellen Artefakt: Die Community lernt nicht nur Kubernetes, sondern, wie man darüber spricht.
Wie Kommunikation die Branchen‑Adoption beeinflusste
Klare Kommunikation machte Kubernetes nicht nur leichter zu lernen — sie veränderte, wie Organisationen entschieden, es zu übernehmen. Wenn komplexe Systeme in einfachen Worten erklärt werden, sinkt das wahrgenommene Risiko, und Teams können über Ergebnisse statt Jargon sprechen.
Warum Entscheidungsträger aufmerksam wurden
Führungskräfte benötigen nicht jede Implementierungs‑Einzelheit, wohl aber eine glaubwürdige Darstellung der Trade‑offs. Einfache Erklärungen, was Kubernetes ist (und nicht ist), halfen bei Gesprächen über:
- Risiko: was ausfallen kann, was stabil ist und was vorsichtig ausgerollt werden muss
- Kosten und ROI: wo Automatisierung Toil reduziert, wo Personalbedarf steigt und wann Standardisierung sich auszahlt
- Verantwortung: wer Cluster‑Betrieb, Sicherheit und Verfügbarkeit übernimmt
Wenn Kubernetes als verständliche Bausteine präsentiert wurde, wurden Budget‑ und Zeitplangespräche weniger spekulativ. Das erleichterte Piloten und das Messen echter Ergebnisse.
Wie Bildung die Adoption unterstützte
Die Branchen‑Adoption verbreitete sich nicht nur durch Vendor‑Pitches, sondern durch Lehre. Hochwertige Talks, Demos und praxisnahe Anleitungen schufen einen gemeinsamen Wortschatz über Unternehmen und Rollen hinweg.
Diese Bildung führte typischerweise zu drei Beschleunigern der Adoption:
- Schulungsprogramme, die Einarbeitungszeit für Entwickler und Betreiber verkürzten
- Interne Enablement‑Maßnahmen (Docs, Brown‑Bags, Templates), die Tribal Knowledge wiederverwendbar machten
- Champions, die „Warum“ und „Wie“ ihren Kollegen erklären konnten, nicht nur das „Was“ implementierten
Sobald Teams Konzepte wie Desired State, Controller und Rollout‑Strategien erklären konnten, wurde Kubernetes diskutierbar — und damit adopierbar.
Wo Klarheit nicht alles löst
Auch die besten Erklärungen ersetzen keinen organisatorischen Wandel. Kubernetes‑Adoption erfordert weiterhin:
- neue operative Fähigkeiten (Zuverlässigkeit, Incident Response, Security‑Hygiene)
- klare Plattform‑Verantwortung und Servicegrenzen
- Zeit, Lieferprozesse zu überarbeiten, nicht nur „ein Cluster zu installieren"
Kommunikation machte Kubernetes zugänglich; erfolgreiche Einführung verlangte weiterhin Commitment, Übung und abgestimmte Anreize.
Praktische Lektionen für Teams, die Kubernetes einführen
Sichere Änderungen üben
Nutze Snapshots und Rollbacks, um Releases zu proben, ohne deine Sandbox zu gefährden.
Kubernetes‑Adoption scheitert meist aus normalen Gründen: Leute können Day‑2‑Betrieb nicht vorhersagen, wissen nicht, was zuerst zu lernen ist, und Dokumentation nimmt an, alle sprächen bereits „Cluster“. Die praktische Lösung ist, Klarheit als Teil des Rollout‑Plans zu behandeln — nicht als Nachgedanken.
Baue zwei Lernpfade (und sag, welchen ihr verfolgt)
Die meisten Teams vermischen „wie nutzt man Kubernetes“ mit „wie betreibt man Kubernetes“. Teile dein Enablement in zwei explizite Pfade:
- Einsteigerpfad: Kernkonzepte, wie deployen, wie eine einfache Workload debuggen, wie „gut“ aussieht.
- Operatorpfad: Cluster‑Lifecycle, Upgrades, Networking, Sicherheitsgrenzen, Backup/Restore und Incident Response.
Platziere die Trennung direkt oben in deinen Docs, damit neue Mitarbeitende nicht aus Versehen ins tiefe Ende springen.
Demo, als würdest du eine Gewohnheit lehren, nicht ein Produkt zeigen
Demos sollten mit dem kleinsten funktionierenden System starten und Komplexität nur hinzufügen, wenn sie nötig ist, um eine reale Frage zu beantworten.
Beginne mit einem einzelnen Deployment und Service. Füge dann Konfiguration, Healthchecks und Autoscaling hinzu. Erst wenn die Grundlagen stabil sind, solltest du Ingress‑Controller, Service‑Meshes oder Custom Operators einführen. Ziel ist, Ursache und Wirkung zu verbinden, nicht YAML auswendig zu lernen.
Schreibe Runbooks, die „Warum“ erklären, nicht nur „mach das"
Runbooks, die nur Checklisten sind, führen zu Cargo‑Kult‑Betrieb. Jeder große Schritt sollte einen Ein‑Satz‑Rational enthalten: welches Symptom adressiert wird, woran Erfolg zu erkennen ist und was schiefgehen kann.
Beispiel: „Pod neu starten behebt einen hängenden Connection‑Pool; wenn es innerhalb von 10 Minuten wieder passiert, prüfe Latenzen downstream und HPA‑Events.“ Dieses „Warum“ erlaubt Improvisation, wenn der Vorfall nicht exakt dem Skript entspricht.
Messe Verständnis, nicht Anwesenheit
Du wirst wissen, dass dein Kubernetes‑Training wirkt, wenn:
- dieselben Fragen nicht mehr ständig in Slack auftauchen.
- die Incident‑Triage schneller wird, weil alle ein gemeinsames mentales Modell teilen.
- Postmortems weniger „wir wussten nicht, wo wir suchen sollten“-Momente enthalten.
Verfolge diese Ergebnisse und passe Docs und Workshops entsprechend an. Klarheit ist ein Deliverable — behandle sie auch so.
Nutze schnelle Prototypen, um die Plattform zu lehren (ohne Produktion zu riskieren)
Eine unterschätzte Methode, Kubernetes und Plattformkonzepte „greifbar“ zu machen, ist, Teams realistische Dienste ausprobieren zu lassen, bevor sie kritische Umgebungen berühren. Das kann bedeuten, eine kleine interne Referenz‑App (API + UI + Datenbank) zu bauen und sie als konstantes Beispiel in Docs, Demos und Troubleshooting‑Drills zu verwenden.
Plattformen wie Koder.ai können hier helfen, weil man daraus per Chat‑gestützter Spezifikation schnell eine Web‑App, Backend‑Service und ein Datenmodell generieren kann und dann im „Planungsmodus“ iteriert, bevor jemand über perfektes YAML nachdenkt. Ziel ist nicht, Kubernetes‑Lernen zu ersetzen, sondern die Zeit von Idee → laufender Dienst zu verkürzen, sodass das Training sich auf das operative mentale Modell konzentrieren kann (Desired State, Rollouts, Observability, sichere Änderungen).
Wie man komplexe Plattformkonzepte in der eigenen Organisation lehrt
Der schnellste Weg, Plattformarbeit intern funktionieren zu lassen, ist, sie verständlich zu machen. Nicht jeder Ingenieur muss Kubernetes‑Experte werden, aber man braucht gemeinsame Begriffe und das Vertrauen, grundlegende Probleme ohne Panik zu debuggen.
Ein wiederholbares Framework: definieren, zeigen, üben, troubleshooten
Definieren: Starte mit einem klaren Satz. Beispiel: „Ein Service ist eine stabile Adresse für eine wechselnde Menge von Pods.“ Vermeide, fünf Definitionen auf einmal zu liefern.
Zeigen: Demonstriere das Konzept im kleinstmöglichen Beispiel. Eine YAML‑Datei, ein Befehl, ein erwartetes Ergebnis. Wenn du es nicht schnell zeigen kannst, ist der Umfang zu groß.
Üben: Gib eine kurze Aufgabe, die jeder selbst ausführen kann (auch in einer Sandbox). „Skaliere dieses Deployment und schau, was mit dem Service‑Endpoint passiert.“ Lernen bleibt hängen, wenn Hände die Tools berühren.
Troubleshooten: Beende die Session, indem du es absichtlich kaputtmachst und durchdenkst, wie man vorgeht. „Was würdest du zuerst prüfen: Events, Logs, Endpoints oder NetworkPolicy?“ Hier wächst operative Sicherheit.
Analogien, die helfen (und wie man irreführende vermeidet)
Analogien orientieren, ersetzen aber keine Präzision. „Pods sind wie Vieh, nicht wie Haustiere“ erklärt Austauschbarkeit, kann aber Details verschleiern (Stateful Workloads, Persistent Volumes, Disruption Budgets).
Gute Regel: benutze die Analogie, um die Idee einzuführen, und wechsle dann schnell zu den realen Begriffen. Sag: „In dieser Hinsicht ist es wie X; hier hört die Ähnlichkeit auf.“ Dieser Satz verhindert teure Missverständnisse später.
Checkliste für interne Talks, die tatsächlich genutzt werden
Vor einem Vortrag validiere vier Dinge:
- Zielpublikum: Für wen ist das—App‑Entwickler, On‑Call‑Ingenieure, Neueinstellungen?
- Ziel: Was sollen sie nach 30 Minuten können?
- Demo: Eine funktionierende Demo, geprobt, mit Fallback‑Plan.
- Nächste Schritte: Ein Doc, ein Runbook oder ein geführtes Lab, dem sie morgen folgen können.
Baue eine Lehrkultur, kein Gatekeeping
Konsistenz schlägt gelegentliche Großtrainings. Probiere leichte Rituale:
- wöchentliche Office Hours für „Bring dein Cluster‑Problem“,
- monatliche Brown Bags mit einem Konzept und einem Live‑Beispiel,
- Pairing‑Rotationen zwischen Plattform‑ und Produktteams bei Incidents.
Wenn Lehren normal wird, wird Adoption ruhiger — und eure Plattform hört auf, wie eine Blackbox zu wirken.
FAQ
Warum ist Klarheit beim Einsatz von Cloud‑Native‑Tools wie Kubernetes so wichtig?
Cloud-native-Stacks bringen neue Primitive (Pods, Services, Controlplanes) und neue Betriebspflichten (Upgrades, Identität, Networking) mit sich. Wenn Teams kein gemeinsames, klares mentales Modell haben, stocken Entscheidungen und Pilotprojekte bleiben halbfertig, weil niemand das Werkzeug mit den wirklichen Risiken und Arbeitsabläufen verbindet.
Wie beschleunigen gute Erklärungen tatsächlich die Kubernetes‑Adoption?
Klare, einfache Erklärungen machen Trade‑offs und Voraussetzungen früh sichtbar:
- Man entscheidet schneller, was wirklich notwendig ist vs. was „nice to have“ ist.
- Zuständigkeiten (wer betreibt was) werden eindeutig.
- Teams können den Day‑2‑Aufwand vorhersagen (On‑Call, Upgrades, Debugging), was Angst und Verzögerungen reduziert.
Wer ist Kelsey Hightower und warum hören Praktiker auf ihn?
Er ist deshalb ein viel beachteter Sprecher, weil er Kubernetes konsequent als ein System erklärt, das man betreibt — nicht als magisches Produkt. Seine Lehre betont, was kaputtgehen kann, wofür man verantwortlich ist und wie man über Controlplane, Netzwerk und Sicherheit nachdenkt — Themen, die Teams oft erst während Incidents lernen, wenn sie nicht vorher vermittelt wurden.
Warum wirkte Kubernetes früher so verwirrend, bevor es zugänglicher wurde?
Verwirrung entsteht oft durch einen Wechsel im mentalen Modell:
- Man denkt nicht mehr „dieser Server läuft meine App“, sondern „die Plattform hält N Repliken am Laufen“.
- Instanzen verschieben sich, starten neu und skalieren absichtlich.
- Debugging verlagert sich von SSH‑Gewohnheiten zu Events, Logs, Controllern und Konfiguration.
Wenn Teams akzeptieren, dass Infrastruktur flüssig ist, lassen sich die Begriffe leichter einordnen.
Was ist die größte Diskrepanz zwischen Kubernetes‑Marketing und realer Einrichtung?
Die Differenz liegt zwischen Demo‑Versprechen und Produktionsrealität. Demos zeigen „deploy und scale“, aber Produktion verlangt Entscheidungen zu:
- Netzwerk und Ingress
- Storage und Stateful Workloads
- Identität, RBAC und Secrets
- Observability und Incident Response
- Upgrade‑Strategien
Ohne diesen Kontext wirkt Kubernetes wie ein Versprechen ohne Karte.
Was ist „Kubernetes the Hard Way“ und warum wird es empfohlen?
Das Konzept lehrt die Grundlagen, indem du ein Cluster Schritt für Schritt zusammenbaust (Zertifikate, kubeconfigs, Controlplane‑Komponenten, Netzwerk, Worker‑Setup). Selbst wenn du später einen managed Service nutzt, hilft das Durcharbeiten des „Hard Way“, zu verstehen, was abstrahiert wird und wo Fehlkonfigurationen auftreten können.
Was bedeutet „desired state“ in Kubernetes in einfachen Worten?
„Desired state“ bedeutet, dass du Ergebnisse beschreibst, nicht Schritt‑für‑Schritt‑Anweisungen. Beispiele:
- „Führe drei Repliken dieser App aus.“
- „Stelle sie unter einer stabilen Adresse bereit.“
- „Begrenze CPU und Speicher.“
Kubernetes arbeitet kontinuierlich daran, die Realität mit dieser Beschreibung in Einklang zu bringen, auch wenn Pods abstürzen oder Nodes ausfallen.
Was ist „Reconciliation“ und warum ist es zentral für das Verständnis von Kubernetes?
Reconciliation ist die ständige Prüf‑und‑Korrektur‑Schleife: Kubernetes vergleicht, was du gefordert hast, mit dem, was tatsächlich läuft, und unternimmt Maßnahmen, um Abweichungen zu schließen.
Praktisch erklärt: Deshalb kommt ein abgestürzter Pod zurück und deshalb werden Skalierungsregeln im Zeitverlauf durchgesetzt — sogar wenn sich das System darunter ändert.
Wie können Teams Ops‑Konzepte (SLIs, Error Budgets, Zuverlässigkeit) erklären, ohne Neueinsteiger einzuschüchtern?
Erläutere Ops‑Begriffe als alltägliche Fragen unter Druck:
- Zuverlässigkeit: „Was bricht zuerst und wie merken wir es?“
- Kapazität: „Was passiert, wenn am Montagmorgen der Traffic hochgeht?“
- Observability: „Können wir in fünf Minuten sagen, was sich geändert hat?“
So klingen SLIs, Error Budgets und Co. weniger wie Fachjargon und mehr wie normale Ingenieursfragen.
Was sind praktische erste Schritte, um Kubernetes intern zu vermitteln und gescheiterte Piloten zu vermeiden?
Teile das Enablement in zwei explizite Pfade:
- User‑Track: deployen, skalieren und eine Arbeitslast debuggen; Kernobjekte und sinnvolle Defaults lernen.
- Operator‑Track: Cluster‑Lifecycle, Upgrades, Networking, RBAC, Backup/Restore und Incident Response.
Validiere das Lernen über Ergebnisse (schnellere Incident‑Triage, weniger wiederkehrende Fragen), nicht nur über Teilnahme an Trainings.