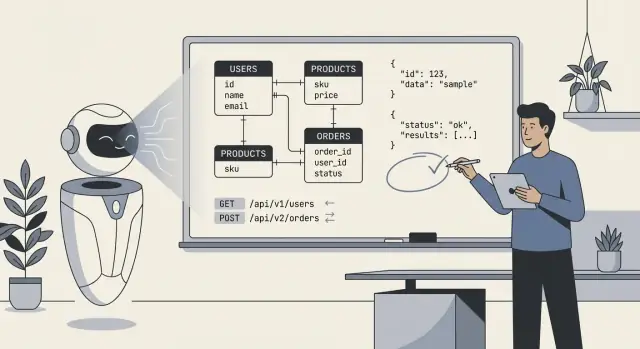
Was „KI entwirft dein Backend“ tatsächlich bedeutet
Wenn Leute sagen „KI hat unser Backend entworfen“, meinen sie meist, dass das Modell einen ersten Entwurf der technischen Blaupause erzeugt hat: Datenbanktabellen (oder Collections), wie diese Teile zusammenhängen, und die APIs, die Daten lesen und schreiben. In der Praxis ist es weniger „die KI hat alles gebaut“ und mehr „die KI hat eine Struktur vorgeschlagen, die wir implementieren und verfeinern können.“
Was ein KI-entworfenes Backend typischerweise enthält
Mindestens kann die KI erzeugen:
- Schemata und Entitäten: Tabellen/Collections wie
users, orders, subscriptions sowie Felder und Grundtypen.
- Beziehungen: 1‑zu‑n und n‑zu‑n Verknüpfungen (z. B. eine Bestellung hat viele Positionen; ein Produkt gehört zu vielen Kategorien).
- Constraints und Validierungen: Pflichtfelder, Unique-Keys, einfache Bereiche, enum‑ähnliche Status und einfache referentielle Integritätsregeln.
- API-Oberfläche: CRUD-Endpunkte, Request-/Response‑Shapes, Paginierungs‑Muster, Fehlerformate und manchmal Versionierungs‑Vorschläge.
Was sie ohne euren Business-Kontext nicht entscheiden kann
Die KI kann „typische“ Muster ableiten, aber nicht zuverlässig das richtige Modell wählen, wenn Anforderungen mehrdeutig oder domänenspezifisch sind. Sie kennt nicht eure tatsächlichen Richtlinien für:
- Was als „User“ zählt (Rollen? Organisationen? Gastkonten?).
- Welche Felder rechtlich erforderlich, sensibel oder Aufbewahrungsregeln unterworfen sind.
- Welche Aktionen auditierbar, reversibel oder genehmigungspflichtig sein sollten.
- Die genaue Bedeutung von Statuswerten (z. B.
cancelled vs refunded vs voided).
Die richtige Erwartung: Co‑pilot, nicht finale Autorität
Behandle KI-Ausgaben als schnellen, strukturierten Ausgangspunkt—nützlich, um Optionen zu erkunden und Auslassungen zu finden—aber nicht als Spezifikation, die du unverändert shippen kannst. Deine Aufgabe ist es, präzise Regeln und Edge‑Cases zu liefern und das, was die KI produziert hat, so zu prüfen, wie du den ersten Entwurf eines Junior Engineers prüfen würdest: nützlich, manchmal beeindruckend, gelegentlich subtil falsch.
Eingaben, die die Qualität der KI-Ergebnisse bestimmen
Die KI kann schnell ein Schema oder eine API entwerfen, aber sie kann die fehlenden Fakten nicht erfinden, die ein Backend „passend“ für euer Produkt machen. Die besten Ergebnisse gibt es, wenn du die KI wie einen schnellen Junior-Designer behandelst: du gibst klare Vorgaben und sie schlägt Optionen vor.
Die Eingaben, die die KI wirklich braucht
Bevor du Tabellen, Endpunkte oder Modelle anforderst, schreibe die Essentials auf:
- Kernentitäten und Definitionen: Welche Objekte existieren (z. B. User, Subscription, Order) und was jedes davon bedeutet für euer Business.
- Wichtige Workflows: Die Haupt-Journeys (Signup, Checkout, Refunds, Approvals) und die Zustände, durch die sie laufen.
- Rollen und Berechtigungen: Wer darf was (Admin, Staff, Customer, Auditor) und was muss eingeschränkt werden.
- Reporting- und Analyse-Anforderungen: Fragen, die ihr später beantworten müsst (monatlicher Umsatz, Kohorten-Retention, SLA‑Metriken), einschließlich Gruppierungsdimensionen.
- Integrationen und externe IDs: Zahlungsprovider, CRMs, Identity-Systeme—und welche IDs gespeichert werden müssen.
- Skalierungs‑ und Performance‑Erwartungen: Grobe Größenordnung (Hunderte vs Millionen Datensätze) und Latenzerwartungen.
- Compliance und Aufbewahrung: GDPR/CCPA, Audit-Logs, Datenlöschregeln, Datenlokalität, Aufbewahrungsfristen.
- Operative Realitäten: Backfills, Importe, manuelle Überschreibungen und „Support-Team muss X editieren“-Szenarien.
Warum unklare Anforderungen brüchige Modelle erzeugen
Bei vagen Anforderungen neigt die KI dazu, Defaults zu „raten“: überall optionale Felder, generische Statusspalten, unklare Ownership und inkonsistente Benennung. Das führt oft zu Schemata, die zwar plausibel aussehen, aber beim echten Einsatz — insbesondere hinsichtlich Berechtigungen, Reporting und Edge‑Cases (Refunds, Stornierungen, Teillieferungen, mehrstufige Genehmigungen) — versagen. Später zahlt man das mit Migrationen, Workarounds und verwirrenden APIs.
Kopierbare Requirements‑Vorlage
Nutze das als Ausgangspunkt und füge es in deinen Prompt ein:
Product summary (2–3 sentences):
Entities (name → definition):
-
Workflows (steps + states):
-
Roles & permissions:
- Role:
- Can:
- Cannot:
Reporting questions we must answer:
-
Integrations (system → data we store):
-
Constraints:
- Compliance/retention:
- Expected scale:
- Latency/availability:
Non-goals (what we won’t support yet):
-
Wobei KI am meisten hilft: Geschwindigkeit, Konsistenz, Abdeckung
KI ist am besten, wenn du sie wie eine schnelle Entwurfsmaschine einsetzt: Sie kann in Minuten ein sinnvolles erstes Datenmodell und passende Endpunkte skizzieren. Diese Geschwindigkeit verändert die Arbeitsweise — nicht weil das Ergebnis automatisch „korrekt“ ist, sondern weil du sofort etwas Konkretes iterieren kannst.
Geschwindigkeit: von leerer Seite zu einem funktionalen Skelett
Der größte Gewinn ist das Eliminieren des Cold‑Starts. Gib der KI eine kurze Beschreibung der Entitäten, Hauptflüsse und Constraints, und sie kann Tabellen/Collections, Beziehungen und eine Basis‑API‑Oberfläche vorschlagen. Besonders wertvoll für Demos oder wenn Anforderungen noch nicht stabil sind.
Speed zahlt sich aus bei:
- Prototypen, bei denen du ein Konzept mit echten Datenflüssen validieren willst
- Internen Tools, wo „gut genug“ wichtiger als perfekte Modellierung ist
- Frühen Produktiterationen, die du ohnehin teilweise neu schreiben wirst
Konsistenz: langweilige Entscheidungen einheitlich getroffen
Menschen ermüden und driftet — KI nicht. Daher ist sie gut darin, Konventionen über das ganze Backend hinweg zu wiederholen:
- konsistente Benennungsmuster (z. B.
createdAt, updatedAt, customerId)
- vorhersehbare Endpoint‑Shapes (
/resources, /resources/:id)
- standardisierte Pagination und Filter-Parameter
Diese Konsistenz macht das Backend leichter dokumentier‑, test‑ und übergabefähig.
Abdeckung: „Haben wir einen Endpunkt vergessen?“
KI ist außerdem gut in Vollständigkeit. Wenn du ein komplettes CRUD‑Set plus gängige Operationen (Search, List, Bulk‑Updates) anforderst, generiert sie meist eine umfassendere Start‑Oberfläche als ein gehetzter Mensch. Ein schneller Gewinn ist standardisierte Fehlerbehandlung: eine einheitliche Fehler‑Hülle (code, message, details) über alle Endpunkte. Selbst wenn du sie später verfeinerst, verhindert eine einheitliche Ausgangsform von Anfang an ein Durcheinander.
Mindset: Lass die KI die ersten 80% schnell liefern, und investiere deine Zeit in die 20%, die Urteilskraft verlangt — Geschäftsregeln, Edge‑Cases und das „Warum“ hinter dem Modell.
Typische Failure‑Modes bei KI‑generierten Schemata
KI‑Schemata sehen oft auf den ersten Blick „sauber“ aus: ordentliche Tabellen, sinnvolle Namen und Beziehungen, die den Happy Path abbilden. Probleme tauchen meist auf, wenn echte Daten, reale Benutzer und reale Workflows das System treffen.
Normalisierung: zu viel oder zu wenig
Die KI kann in beide Extreme ausschlagen:
- Über‑Normalisierung: alles in viele Tabellen aufspalten (z. B. separate Tabellen für jedes Attribut), was häufige Queries teuer macht und Join‑Komplexität erhöht.
- Unter‑Normalisierung: wiederholte Felder in eine Tabelle stopfen (z. B. mehrere Adress‑Spalten, denormalisierte Statusflags), die schwer zu validieren und zu aktualisieren ist.
Schneller Geruchstest: Wenn deine häufigsten Seiten 6+ Joins brauchen, bist du möglicherweise über‑normalisiert; wenn Updates denselben Wert in vielen Reihen ändern müssen, bist du vielleicht unter‑normalisiert.
Fehlende Edge‑Cases, die in Produktion wichtig sind
Die KI lässt oft „langweilige“ Anforderungen weg, die das Backend‑Design bestimmen:
- Multi‑Tenant‑Daten:
tenant_id vergessen oder keine Service‑seitige Mandantentrennung in Unique‑Constraints.
- Soft Deletes:
deleted_at hinzufügen, aber Unique‑Regeln oder Query‑Patterns nicht anpassen.
- Auditing: fehlende
created_by/updated_by, Änderungshistorie oder unveränderliche Event‑Logs.
- Zeitzonen: Vermischung von
date und timestamp ohne klare Regel (UTC‑Speicherung vs lokale Anzeige), was zu Off‑by‑One‑Day Bugs führt.
Falsche Annahmen zu Einzigartigkeit und Lifecycle
Die KI könnte raten:
- ein Feld sei global eindeutig, obwohl es nur pro Mandant eindeutig ist (z. B.
invoice_number),
- ein Feld sei erforderlich, obwohl es beim Onboarding optional ist,
- ein einzelner Status reiche, obwohl ein Lifecycle nötig ist (draft → active → suspended → archived).
Solche Fehler zeigen sich meist in unbequemen Migrationen und App‑Workarounds.
Die meisten generierten Schemata reflektieren nicht, wie ihr abfragen werdet:
- fehlende zusammengesetzte Indexe für häufige Filter (tenant_id + created_at),
- kein Plan für „Hot Paths“ (neuste Items, Unread Counts),
- starke Nutzung von JSON‑Feldern ohne Indexierungsstrategie.
Wenn das Modell nicht die Top‑5‑Queries beschreiben kann, kann es das Schema für sie nicht zuverlässig auslegen.
API‑Design: Was die KI richtig und falsch macht
Die KI ist oft überraschend gut darin, eine API zu erzeugen, die „standardmäßig“ aussieht. Sie spiegelt vertraute Muster aus populären Frameworks und öffentlichen APIs wider, was viel Zeit sparen kann. Das Risiko: Sie optimiert für Plausibilität statt für Richtigkeit in eurem Produkt‑Kontext und für zukünftige Änderungen.
Was die KI meist richtig macht
Ressourcenmodellierung: Bei klarem Domain‑Input wählt die KI meist sinnvolle Nomen und URL‑Strukturen (z. B. /customers, /orders/{id}, /orders/{id}/items). Sie wiederholt Namenskonventionen konsistent.
Grundlegendes Endpoint‑Scaffolding: Meist sind List vs Detail, Create/Update/Delete und vorhersehbare Request/Response‑Shapes enthalten.
Basis‑Konventionen: Auf Anfrage standardisiert sie Pagination, Filtering und Sorting, z. B. ?limit=50&cursor=... (Cursor‑Pagination) oder ?page=2&pageSize=25 (Seitenbasiert), plus ?sort=-createdAt und Filter wie ?status=active.
Wo die KI oft danebenliegt
Leaky abstractions. Ein klassischer Fehler ist, interne Tabellen direkt als „Ressourcen“ zu exponieren, besonders wenn das Schema Join‑Tabellen, denormalisierte Felder oder Audit‑Spalten enthält. Dann entstehen Endpunkte wie /user_role_assignments, die Implementierungsdetails zeigen statt eines benutzerzentrierten Konzepts („Rollen für einen Benutzer“).
Inkonsistente Fehlerbehandlung. Die KI kann Stile mischen: manchmal 200 mit Fehlerkörper, manchmal 4xx/5xx. Du willst einen klaren Vertrag:
- Richtige HTTP‑Statuscodes (
400, 401, 403, 404, 409, 422)
- Eine konsistente Fehler‑Hülle (z. B.
{ "error": { "code": "...", "message": "...", "details": [...] } })
Versionierung als Nachgedanke. Viele Designs überspringen eine Versionierungsstrategie, bis es weh tut. Entscheide am ersten Tag, ob du Pfadversionierung (/v1/...) oder Header‑Versionierung nutzt und was einen Breaking Change auslöst.
Faustregel
Nutze KI für Geschwindigkeit und Konsistenz, aber behandle API‑Design als Produktinterface. Wenn ein Endpunkt deine DB widerspiegelt statt das mentale Modell des Nutzers, ist das ein Hinweis, dass die KI für einfache Generierung optimiert hat—nicht für langfristige Benutzbarkeit.
Ein praktischer Workflow, um KI zu nutzen ohne die Kontrolle zu verlieren
Für Nutzer greifbar machen
Stelle dein Backend unter einer eigenen Domain bereit, wenn du es teilen möchtest.
Behandle die KI wie einen schnellen Junior‑Designer: großartig bei Entwürfen, nicht verantwortlich für das finale System. Ziel ist, ihre Geschwindigkeit zu nutzen und gleichzeitig Architektur bewusst, prüfbar und testgetrieben zu halten.
Wenn du ein „vibe‑coding“-Tool wie Koder.ai benutzt, wird diese Trennung noch wichtiger: Die Plattform kann schnell ein Backend (z. B. Go‑Services mit PostgreSQL) entwerfen und implementieren, aber du musst weiterhin Invarianten, Autorisierungsgrenzen und Migrationsregeln definieren, mit denen du leben kannst.
Eine wiederholbare Schleife: prompt → draft → review → tests → revise
Beginne mit einem präzisen Prompt, der Domain, Constraints und „was Erfolg bedeutet“ beschreibt. Fordere zuerst ein konzeptionelles Modell (Entitäten, Beziehungen, Invarianten), nicht sofort Tabellen.
Dann iteriere in einer festen Schleife:
- Prompt: Anforderungen, Non‑Goals, Skalierungsannahmen und Namenskonventionen nennen.
- Draft: KI um konzeptionelles Modell + ersten Schemaentwurf + API‑Verträge bitten.
- Review: Prüfen auf Domänenkorrektheit, Edge‑Cases und Übereinstimmung mit Produktentscheidungen.
- Tests: Tests schreiben oder generieren, die die Entscheidungen kodifizieren (Validierungsregeln, Autorisierung, Idempotenz, Migrationsicherheit).
- Revise: Feedback und Testfehler an die KI zurückgeben und um Korrekturen bitten.
Diese Schleife funktioniert, weil sie „KI‑Vorschläge“ in überprüfbare Artefakte verwandelt.
Konzeptionelles Modell, physisches Schema und API‑Verträge trennen
Halte drei Ebenen getrennt:
- Konzeptionelles Modell: Was das Business interessiert (z. B. „Subscription kann pausiert werden“, „Invoice muss sich auf eine Abrechnungsperiode beziehen“).
- Physisches Schema: Wie es gespeichert wird (Tabellen/Collections, Indexe, Constraints, Partitionierung).
- API‑Verträge: Wie Clients damit interagieren (Ressourcen, Request/Response‑Shapes, Fehlercodes, Versionierungsstrategie).
Fordere die KI auf, diese Ebenen als separate Abschnitte auszugeben. Wenn sich etwas ändert (z. B. ein neuer Status), aktualisierst du zuerst das konzeptionelle Layer und stimmst Schema und API danach ab. Das reduziert versehentliche Kopplungen und erleichtert Refactors.
Entscheidungen nachverfolgbar machen mit leichten Design‑Notes
Jede Iteration sollte eine Spur hinterlassen. Nutze kurze ADR‑ähnliche Zusammenfassungen (eine Seite oder weniger), die erfassen:
- Entscheidung: was gewählt wurde (z. B. „Soft Delete via
deleted_at“).
- Begründung: warum (Audit‑Anforderungen, Restore‑Flow).
- Alternativen: und warum verworfen.
- Konsequenzen: Migrations‑Impact, Query‑Komplexität, API‑Verhalten.
Wenn du Feedback in die KI zurückcopy‑pastest, füge die relevanten Entscheidungsnotizen wörtlich bei. So „vergisst“ das Modell frühere Entscheidungen nicht und dein Team versteht in Monaten noch den Kontext.
Prompts, die bessere Schemata und APIs erzeugen
KI lässt sich steuern, wenn du Prompting wie Spezifikation‑Schreiben behandelst: Domain definieren, Constraints nennen und konkrete Outputs fordern (DDL, Endpunkt‑Tabellen, Beispiele). Ziel ist nicht „sei kreativ“, sondern „sei präzise“.
Prompts für Entitäten und Beziehungen (mit Constraints)
Fordere ein Datenmodell und die Regeln, die es konsistent halten.
- „Entwirf ein relationales Schema für Subscriptions mit Entitäten: User, Plan, Subscription, Invoice. Füge Kardinalitäten, Unique‑Constraints und Soft‑Delete‑Strategie hinzu. Regeln: pro User max. eine aktive Subscription; Invoices müssen den zum Kaufzeitpunkt fixierten Plan‑Preis referenzieren; Währung als ISO‑Code speichern; Zeitstempel in UTC.“
Wenn du Konventionen hast, sag das: Benennungsstil, ID‑Typ (UUID vs bigint), Nullable‑Policy und Index‑Erwartungen.
Prompts für Endpunkte und Verträge (mit Beispielen)
Fordere eine API‑Tabelle mit expliziten Verträgen, nicht nur eine Routeliste.
- „Schlage REST‑Endpunkte für Subscription‑Management vor. Für jeden Endpunkt: Methode, Pfad, Auth, Query‑Params, Request‑JSON, Response‑JSON, Fehlercodes und Idempotenz‑Hinweise. Füge Beispiele für Erfolg und zwei Fehlerfälle bei.“
Füge Geschäftsverhalten hinzu: Pagination‑Style, Sort‑Felder und wie Filter funktionieren.
Prompts für Migrationen und Rückwärtskompatibilität
Lass das Modell in Releases denken.
- „Wir fügen
billing_address zur Customer‑Tabelle hinzu. Gib einen sicheren Migrationsplan: Forward‑Migration SQL, Backfill‑Schritte, Feature‑Flag‑Rollout und Rollback‑Strategie. API muss 30 Tage kompatibel bleiben; alte Clients dürfen das Feld weglassen.“
Anti‑Pattern Prompts, die du vermeiden solltest
Vage Prompts erzeugen vage Systeme.
- „Design the database for an e‑commerce app“ (zu breit)
- „Make it scalable and secure“ (fehlende messbare Constraints)
- „Generate the best schema“ (keine Domänenregeln)
- „Create APIs for everything“ (keine Abgrenzung oder Priorisierung)
Wenn du bessere Ergebnisse willst, schärfe den Prompt: spezifizier die Regeln, die Edge‑Cases und das Format der Deliverables.
Human‑Review‑Checkliste bevor du shippst
Ein lauffähiges Grundgerüst liefern
Erzeuge ein Go + PostgreSQL-Backend und iteriere schnell, wenn sich Anforderungen ändern.
KI kann ein brauchbares Backend entwerfen, aber produktiv setzen sollte ein Mensch. Betrachte diese Checkliste als Release‑Gate: Wenn du ein Item nicht sicher beantworten kannst, stoppe und behebe es, bevor du produktive Daten erzeugst.
Schema‑Checkliste (Tabellen, Collections und Spalten)
- Primärschlüssel: Jede Tabelle hat einen klaren PK. Wenn UUIDs verwendet werden, bestätige die Erzeugungsstrategie (DB vs App) und das Indexieren.
- Foreign Keys & Constraints: Füge FK‑Constraints hinzu, wo Beziehungen echt sind. Überprüfe ON DELETE/ON UPDATE Regeln bewusst (restrict vs cascade vs set null).
- Eindeutigkeit: Erzwinge Uniqueness in der DB (nicht nur im Code): E‑Mails, externe IDs, zusammengesetzte Constraints (z. B.
(tenant_id, slug)).
- Nullability: Prüfe jedes nullable Feld. Wenn „unknown“ sich von „empty“ unterscheidet, modellier das explizit.
- Indexe: Füge Indexe für häufige Filter/Sorts/Joins hinzu. Entferne versehentliche Indexe auf Low‑Cardinality Feldern.
- Benennungs‑Konsistenz: Wähle Konventionen (Singular vs Plural,
_id‑Suffixe, Timestamps) und wende sie einheitlich an.
Entscheidungen zur Datenintegrität (teuer zu ändern später)
Schreibe Systemregeln nieder:
- Referentielle Integrität: Welche Beziehungen dürfen nie brechen? Welche sind „best‑effort“?
- Cascading‑Regeln: Wenn ein Parent gelöscht wird, sollen Kinder gelöscht, verwaist oder blockiert werden?
- Soft‑Delete‑Strategie: Bei Soft Deletes sicherstellen, dass Queries gelöschte Datensätze nicht „wiederbeleben“. Entscheide, ob Unique‑Constraints Soft‑Deleted‑Zeilen ignorieren sollen.
API‑Checkliste (Verhalten und Sicherheit)
- Auth & Authorization: Wer darf welchen Endpunkt aufrufen und was darf er sehen (insbesondere bei Multi‑Tenant)?
- Validierung: Typen, Bereiche, Formate und Cross‑Field‑Regeln validieren. Verlass dich nicht auf DB‑Errors als Validierung.
- Rate Limits & Abuse Controls: Sinnvolle Defaults, nach User/Token/IP, wo passend.
- Idempotenz: Für Create/Payment‑ähnliche Operationen Idempotenz‑Keys oder deterministische Request‑IDs unterstützen.
- Konsistente Fehler: Standardisiere Fehlerform und HTTP‑Codes. Achte darauf, dass Fehlermeldungen keine sensiblen Interna verraten.
Vor dem Merge: ein kurzer „Happy Path + Worst Path“ Check: ein normaler Request, ein ungültiger Request, ein unauthorized Request, ein High‑Volume‑Szenario. Wenn das API‑Verhalten Überraschungen liefert, wird es auch Nutzer überraschen.
Teststrategie für KI‑entworfene Backends
Die KI kann schnell ein plausibles Schema und API‑Surface liefern, aber nicht beweisen, dass das Backend unter realem Traffic, realen Daten und zukünftigen Änderungen korrekt funktioniert. Behandle KI‑Output als Entwurf und verankere ihn mit Tests.
Contract‑Tests für APIs
Beginne mit Contract‑Tests, die Requests, Responses und Fehler‑Semantik validieren — nicht nur Happy Paths. Baue eine kleine Suite, die gegen eine echte Instanz (oder Container) läuft.
Fokus auf:
- Statuscodes und Fehlerkörper (z. B. 400 vs 404 vs 409)
- Validierungs‑Edge‑Cases (leere Strings, übergroße Payloads, unerwartete Felder)
- Paginierungs‑ und Sortier‑Stabilität (konsequente Reihenfolge, Cursor‑Korrektheit)
- Idempotenz bei Create/Update (sichere Retries, Idempotency‑Keys wenn verwendet)
Wenn du ein OpenAPI‑Spec veröffentlichst, generiere Tests daraus — und ergänze handgeschriebene Fälle für die kniffligen Teile, die das Spec nicht abbilden kann (Autorisierungsregeln, Geschäftsconstraints).
Migrations‑Tests und Rollback‑Pläne
KI‑Schemata übersehen oft operative Details: sichere Defaults, Backfills, Reversibilität. Füge Migrationstests hinzu, die:
- Migrationen aus einer leeren DB und aus einem „dirty“ älteren Snapshot anwenden
- Constraints (Unique, FKs) nach Backfill verifizieren
- Rollback‑Pläne oder zumindest forward‑fix‑Pläne für jede Migration prüfen
Halte einen skriptbaren Rollback‑Plan für Produktion bereit: Was tun, wenn eine Migration langsam ist, Tabellen sperrt oder Kompatibilität bricht.
Benchmarke nicht generische Endpunkte. Erfasse repräsentative Query‑Muster (Top‑List‑Views, Suche, Joins, Aggregationen) und loadteste genau diese.
Miss:
- p95/p99 Latenz pro Endpunkt
- DB‑Query‑Counts und langsame Queries
- Index‑Nutzung (fehlende Indexe identifizieren)
Hier scheitern KI‑Designs oft: „vernünftige“ Tabellen produzieren teure Joins unter Last.
Security‑Tests (Grundlagen)
Automatisiere Checks für:
- Autorisierungsregeln (User A darf nicht auf Ressourcen von User B zugreifen)
- Injection (SQL/NoSQL, Pfad‑Traversal, JSON‑Injection)
- Umgang mit sensitiven Daten (keine Secrets in Logs, Feld‑Redaction, Verschlüsselung wo nötig)
Selbst einfache Security‑Tests verhindern die kostspieligste Klasse von KI‑Fehlern: Endpunkte, die funktionieren, aber zu viel offenlegen.
Migrationen, Refactors und langfristige Wartbarkeit
Die KI kann einen guten „Version 0“ Entwurf liefern, aber dein Backend wird Version 50 erleben. Der Unterschied zwischen gut alterndem Backend und einem, das zusammenbricht, ist, wie du es weiterentwickelst: Migrationen, kontrollierte Refactors und klare Dokumentation der Intention.
Sichere Weiterentwicklung KI‑generierter Schemata
Behandle jede Schema‑Änderung als Migration, auch wenn die KI „einfach die Tabelle ändert“ vorschlägt. Nutze explizite, reversierbare Schritte: neue Spalten zuerst, backfill, dann Constraints verschärfen. Bevorzuge additive Änderungen (neue Felder, neue Tabellen) gegenüber destruktiven (rename/drop), bis bewiesen ist, dass nichts vom alten Shape abhängt.
Wenn du die KI um Schema‑Updates bittest, füge das aktuelle Schema und eure Migrationsregeln hinzu (z. B. „keine Spalten löschen; expand/contract“). So verringerst du die Chance, dass sie eine theoretisch korrekte, aber in Produktion riskante Änderung vorschlägt.
Breaking Changes ohne Chaos handhaben
Breaking Changes sind meist ein Übergang, kein einzelner Moment.
- Deprecations: Alte Felder/Endpunkte weiter unterstützen und Nutzung loggen.
- Dual‑Write: Während der Übergangszeit sowohl auf alt als auch neu schreiben.
- Backfills: einmalige oder inkrementelle Jobs zum Befüllen neuer Strukturen.
Die KI hilft beim Schritt‑für‑Schritt‑Plan (inkl. SQL‑Snippets und Rollout‑Reihenfolge), aber du musst Runtime‑Auswirkungen validieren: Locks, langlaufende Transaktionen, Resume‑Fähigkeit des Backfills.
Datenmodell refactoren ohne alles neu zu schreiben
Refactors sollten Änderungen isolieren. Wenn du normalisieren, eine Tabelle splitten oder ein Event‑Log einführen musst, bewahre Kompatibilitätslayer: Views, Übersetzungscode oder „Shadow“‑Tabellen. Bitte die KI um einen Refactor‑Vorschlag, der bestehende API‑Verträge erhält, und eine Liste der nötigen Änderungen in Queries, Indexen und Constraints.
Annahmen dokumentieren, damit zukünftige Prompts konsistent bleiben
Langfristige Drift entsteht oft, weil der nächste Prompt die ursprüngliche Absicht vergisst. Halte ein kurzes „Data Model Contract“ Dokument: Benennungsregeln, ID‑Strategie, Timestamp‑Semantik, Soft‑Delete‑Policy und Invarianten („Order Total ist abgeleitet, nicht gespeichert“). Verlinke es in internen Docs (z. B. /docs/data-model) und wiederverwende es in künftigen KI‑Prompts, damit Designs innerhalb derselben Grenzen bleiben.
Sicherheits‑ und Datenschutzaspekte
Prompts in ein Backend verwandeln
Erstelle ein Schema, APIs und Services aus nur einem Chat-Prompt in Koder.ai.
KI kann schnell Tabellen und Endpunkte entwerfen, aber sie „besitzt“ das Risiko nicht. Behandle Sicherheit und Privacy als erstklassige Anforderungen im Prompt und verifiziere sie in Reviews—besonders bei sensiblen Daten.
Mit Datenklassifikation anfangen
Bevor du ein Schema akzeptierst, klassifiziere Felder nach Sensitivität (public, internal, confidential, regulated). Diese Klassifikation bestimmt, was verschlüsselt, maskiert oder minimalisiert werden muss.
Beispiel: Passwörter dürfen nie gespeichert werden (nur gesalzene Hashes), Tokens sollten kurzlebig und im Ruhezustand verschlüsselt sein, und PII wie Email/Telefon sollten in Admin‑Views/Exports maskiert werden. Wenn ein Feld keinen Produktwert bringt, speichere es nicht—die KI fügt oft „nice to have“ Attribute hinzu, die die Angriffsfläche vergrößern.
Access Control: RBAC vs ABAC
KI‑APIs defaulten oft zu einfachen Rollenprüfungen. RBAC ist leicht verständlich, aber limitiert bei Ownership‑Regeln („Users dürfen nur ihre Rechnungen sehen“) oder kontextabhängigen Regeln („Support darf Daten nur während eines aktiven Tickets sehen“). ABAC handhabt solche Fälle besser, erfordert aber explizite Policies.
Sei klar, welche Muster du nutzt, und stelle sicher, dass jeder Endpunkt sie konsistent durchsetzt—besonders List/Search‑Endpunkte, die häufig Datenlecks verursachen.
Verhindere versehentliches Loggen sensibler Felder
Generierter Code loggt oft komplette Request‑Bodies, Header oder DB‑Rows bei Fehlern. Das kann Passwörter, Auth‑Tokens und PII in Logs/APM‑Tools leaken.
Setze Defaults: strukturierte Logs, Allowlist von Feldern zum Loggen, Redaction von Secrets (Authorization, Cookies, Reset‑Tokens) und vermeide rohes Payload‑Logging bei Validierungsfehlern.
Privacy, Aufbewahrung und Löschung
Entwirf Löschmechanismen von Anfang an: Nutzerinitiierte Löschungen, Kontoabschluss und „Right to be forgotten“. Definiere Aufbewahrungsfenster pro Datenklasse (z. B. Audit‑Events vs Marketing‑Events) und stelle sicher, dass du beweisen kannst, was wann gelöscht wurde.
Wenn Audit‑Logs behalten werden, speichere minimale Identifikatoren, schütze sie stärker und dokumentiere, wie Daten exportiert oder gelöscht werden können.
Wann KI nutzen (und wann nicht)
KI ist am besten, wenn du sie wie einen schnellen Junior‑Architekten behandelst: großartig für einen ersten Entwurf, schwächer bei domänenkritischen Trade‑offs. Die richtige Frage ist weniger „Kann KI mein Backend designen?“ als „Welche Teile kann die KI sicher entwerfen, und welche erfordern Expertenverantwortung?“
Gute Anwendungsfälle: Entwürfe, Prototypen und bekannte Muster
KI spart Zeit, wenn du baust:
- Kleine Prototypen, interne Tools und MVPs zum schnellen Lernen
- CRUD‑schwere Systeme mit vertrauten Entitäten (Users, Orders, Subscriptions)
- „Blank page“ Situationen: initiales Schema, API‑Oberfläche und Naming‑Konventionen generieren
Hier ist KI wertvoll wegen Geschwindigkeit, Konsistenz und Coverage—vor allem wenn du bereits weißt, wie das Produkt sich verhalten soll und Fehler leicht erkennst.
Schlechte Anwendungsfälle: regulierte, risiko‑ oder domänenintensive Systeme
Sei vorsichtig (oder nutze KI nur als Inspiration), wenn du in Bereichen arbeitest wie:
- Finanzen: Ledger, Reconciliation, Audit‑Trails und Idempotenz‑Regeln, die exakt sein müssen
- Gesundheitswesen: Patientendaten, Consent‑Modelle, Aufbewahrung, Interoperabilitätsanforderungen
- Sicherheitskritische Domänen: wo eine „vernünftige Annahme“ kostspielig werden kann
In diesen Bereichen überwiegt Domänenexpertise die KI‑Geschwindigkeit. Subtile Anforderungen (rechtlich, klinisch, buchhalterisch, operativ) fehlen oft im Prompt, die KI füllt Lücken selbstbewusst auf.
Entscheidungsleitfaden: KI für Entwürfe, menschliche Freigabe fordern
Praktische Regel: Lass die KI Optionen vorschlagen, verlange aber eine Endabnahme für Datenmodell‑Invarianten, Autorisierungsgrenzen und Migrationsstrategie. Wenn du nicht benennen kannst, wer für Schema und API‑Verträge verantwortlich ist, rolle kein KI‑entworfenes Backend aus.
Nächste Schritte
Wenn du Workflows und Guardrails evaluierst, siehe verwandte Guides in /blog. Wenn du Unterstützung bei der Anwendung dieser Praktiken in deinem Team brauchst, schau /pricing an.
Wenn du einen End‑to‑End‑Workflow bevorzugst, bei dem du per Chat iterieren, eine funktionierende App generieren und weiterhin Kontrolle via Source‑Code‑Export und rollback‑freundlichen Snapshots behalten möchtest, ist Koder.ai genau für diesen Build‑and‑Review‑Loop ausgelegt.