26. Aug. 2025·8 Min
KI‑first‑Produkte entwickeln: Modelle in der Anwendungslogik einsetzen
Ein praxisorientierter Leitfaden zum Aufbau von KI‑first‑Produkten, bei denen das Modell Entscheidungen in der Anwendungslogik trifft: Architektur, Prompts, Tools, Daten, Evaluation, Sicherheit und Monitoring.
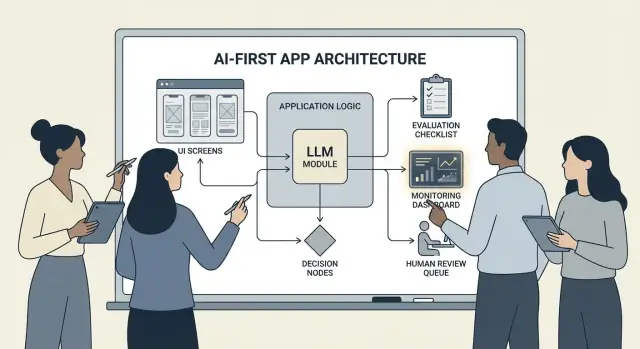
Was es heißt, ein KI‑first‑Produkt zu bauen
Ein KI‑first‑Produkt zu bauen bedeutet nicht einfach, „einen Chatbot hinzuzufügen“. Es bedeutet, dass das Modell ein echter, funktionaler Teil Deiner Anwendungslogik ist — so wie eine Regeln‑Engine, ein Suchindex oder ein Empfehlungsalgorithmus.
Deine App nutzt KI nicht nur; sie ist darauf ausgelegt, dass das Modell Eingaben interpretiert, Aktionen auswählt und strukturierte Ausgaben erzeugt, auf die der Rest des Systems angewiesen ist.
Praktisch heißt das: statt jede Entscheidungsroute hart zu kodieren ("wenn X dann Y"), lässt Du das Modell die unscharfen Teile übernehmen — Sprache, Intention, Mehrdeutigkeit, Priorisierung — während Dein Code das präzise erledigt: Berechtigungen, Zahlungen, Datenbankschreibvorgänge und Richtliniendurchsetzung.
Wann KI‑first passt (und wann nicht)
KI‑first funktioniert am besten, wenn das Problem folgende Eigenschaften hat:
- Viele gültige Eingaben (Freitext, unstrukturierte Dokumente, unterschiedliche Nutzerziele)
- Zu viele Edge‑Cases, um Regeln manuell zu pflegen
- Wert in Urteilsvermögen, Zusammenfassung oder Synthese statt perfekter Determinismus
Regelbasierte Automatisierung ist dagegen meist besser, wenn Anforderungen stabil und exakt sind — Steuerberechnungen, Inventarlogik, Anspruchsprüfungen oder Compliance‑Workflows, bei denen das Ergebnis immer gleich sein muss.
Gängige Produktziele, die KI‑first unterstützt
Teams setzen modellgetriebene Logik typischerweise ein, um:
- Geschwindigkeit zu erhöhen: Entwürfe erstellen, Felder extrahieren, Anfragen schneller routen
- Erlebnisse zu personalisieren: Erklärungen, Pläne oder Empfehlungen anpassen
- Entscheidungen zu unterstützen: Abwägungen hervorheben, Optionen generieren, Belege zusammenfassen
Die Abwägungen, auf die Du Dich einstellen musst
Modelle können unvorhersehbar sein, manchmal selbstbewusst falsch liegen, und ihr Verhalten kann sich ändern, wenn Prompts, Anbieter oder kontextuelle Retrieval‑Daten wechseln. Sie verursachen zudem Kosten pro Anfrage, können Latenz einführen und werfen Sicherheits‑ und Vertrauensfragen auf (Privatsphäre, schädliche Ausgaben, Richtlinienverstöße).
Die richtige Denkweise: ein Modell ist eine Komponente, kein magisches Antwortfeld. Behandle es wie eine Abhängigkeit mit Spezifikationen, Fehlermodi, Tests und Monitoring — so bekommst Du Flexibilität, ohne das Produkt auf Hoffnung zu setzen.
Wähle den richtigen Anwendungsfall und definiere Erfolg
Nicht jede Funktion profitiert davon, das Modell ans Steuer zu setzen. Die besten KI‑first‑Anwendungsfälle beginnen mit einer klaren Aufgabe und enden mit einem messbaren Ergebnis, das Du Woche für Woche verfolgen kannst.
Mit der Aufgabe anfangen, nicht mit dem Modell
Schreibe eine Ein‑Satz‑Job‑Story: „Wenn ___, möchte ich ___, damit ich ___.“ Dann mache das Ergebnis messbar.
Beispiel: „Wenn ich eine lange Kunden‑E‑Mail erhalte, möchte ich einen vorgeschlagenen Antwortentwurf, der unseren Richtlinien entspricht, damit ich in unter 2 Minuten antworten kann.“ Das ist viel konkreter als „füge ein LLM zu E‑Mail hinzu.“
Entscheidungspunkte abbilden
Identifiziere die Momente, an denen das Modell Aktionen auswählt. Diese Entscheidungspunkte sollten explizit sein, damit Du sie testen kannst.
Gängige Entscheidungspunkte sind:
- Intention klassifizieren und an den richtigen Workflow routen
- Entscheiden, ob eine klärende Frage nötig ist oder weitergearbeitet werden kann
- Werkzeuge auswählen (Suche, CRM‑Lookup, Entwurf, Ticket‑Erstellung)
- Entscheiden, wann an einen Menschen eskaliert werden soll
Wenn Du die Entscheidungen nicht benennen kannst, bist Du nicht bereit, modellgetriebene Logik auszuliefern.
Akzeptanzkriterien für Verhalten schreiben
Behandle Modellverhalten wie jede andere Produktanforderung. Definiere, was „gut“ und „schlecht“ in klarem Text bedeutet.
Zum Beispiel:
- Gut: nutzt die aktuelle Richtlinie, nennt die korrekte Bestell‑ID, stellt bei fehlenden Angaben eine klare Frage
- Schlecht: erfindet Rabatte, verweist auf nicht unterstützte Regionen oder antwortet ohne erforderliche Daten zu prüfen
Diese Kriterien werden die Grundlage für Dein Evaluations‑Set später.
Einschränkungen früh benennen
Liste Restriktionen auf, die Deine Design‑Entscheidungen prägen:
- Zeit (Zielwerte für Antwortlatenz)
- Budget (Kosten pro Aufgabe)
- Compliance (Umgang mit PII, Prüfanforderungen)
- Unterstützte Lokalisierungen (Sprachen, Ton, kulturelle Erwartungen)
Erfolgsmessgrößen festlegen, die Du überwachen kannst
Wähle eine kleine Menge an Metriken, die an die Aufgabe gebunden sind:
- Aufgabenerfolgsrate
- Genauigkeit (oder Richtlinien‑Konformität) bei repräsentativen Fällen
- CSAT oder qualitative Nutzerbewertung
- Zeitersparnis pro Aufgabe (oder Time‑to‑Resolution)
Wenn Du Erfolg nicht messen kannst, wirst Du über Eindrücke streiten statt das Produkt zu verbessern.
Entwerfe den KI‑gesteuerten Benutzerfluss und Systemgrenzen
Ein KI‑first‑Flow ist nicht „ein Bildschirm, der ein LLM aufruft“. Es ist eine End‑to‑End‑Reise, bei der das Modell bestimmte Entscheidungen trifft, das Produkt sie sicher ausführt und der Nutzer orientiert bleibt.
Die End‑to‑End‑Schleife abbilden
Beginne damit, die Pipeline als einfache Kette zu zeichnen: Eingaben → Modell → Aktionen → Ausgaben.
- Eingaben: was der Nutzer bereitstellt (Text, Dateien, Auswahlen) plus App‑Kontext (Account‑Tier, Workspace, letzte Aktivitäten).
- Modell‑Schritt: wofür das Modell verantwortlich ist (klassifizieren, entwerfen, zusammenfassen, nächste Aktion wählen).
- Aktionen: was Dein System tun könnte (suchen, Aufgabe erstellen, Datensatz aktualisieren, E‑Mail senden).
- Ausgaben: was der Nutzer sieht (einen Entwurf, eine Erklärung, eine Bestätigungsseite, einen Fehler mit nächsten Schritten).
Diese Karte zwingt zu Klarheit darüber, wo Unsicherheit akzeptabel ist (Entwurf) und wo nicht (Abrechnungsänderungen).
Systemgrenzen ziehen: Modell vs deterministischer Code
Trenne deterministische Pfade (Berechtigungsprüfungen, Geschäftsregeln, Berechnungen, Datenbank‑Schreibvorgänge) von modellgetriebenen Entscheidungen (Interpretation, Priorisierung, natürlichsprachige Generierung).
Eine nützliche Regel: das Modell darf empfehlen, der Code muss prüfen, bevor etwas Unwiderrufliches passiert.
Entscheiden, wo das Modell läuft
Wähle die Laufzeit basierend auf Restriktionen:
- Server: am besten für private Daten, konsistente Tools, Audit‑Logs.
- Client: nützlich für leichte Assistenz und Privacy‑by‑Local‑Processing, aber schwerer zu kontrollieren.
- Edge: schnellere globale Latenz, aber eingeschränkte Abhängigkeiten.
- Hybrid: schnelle Intent‑Erkennung am Edge, schwere Arbeit auf dem Server.
Budgetiere Latenz, Kosten und Datenrechte
Setze ein per‑Request Latenz‑ und Kostenbudget (inklusive Retries und Tool‑Aufrufe) und gestalte die UX danach (Streaming, progressive Ergebnisse, „im Hintergrund fortsetzen“).
Dokumentiere Datenquellen und Berechtigungen, die in jedem Schritt benötigt werden: was das Modell lesen darf, was es schreiben darf und was eine explizite Nutzerbestätigung erfordert. Das wird zum Vertrag für Engineering und Vertrauen.
Architektur‑Muster: Orchestrierung, Zustand und Traces
Wenn ein Modell Teil Deiner App‑Logik ist, umfasst „Architektur“ nicht nur Server und APIs — es geht darum, wie Du zuverlässig eine Kette von Modellentscheidungen betreibst, ohne die Kontrolle zu verlieren.
Orchestrierung: der Dirigent der Modell‑Arbeit
Die Orchestrierung ist die Schicht, die verwaltet, wie eine KI‑Aufgabe End‑to‑End ausgeführt wird: Prompts und Templates, Tool‑Aufrufe, Memory/Kontext, Retries, Timeouts und Fallbacks.
Gute Orchestratoren behandeln das Modell als eine Komponente in einer Pipeline. Sie entscheiden, welchen Prompt sie verwenden, wann ein Tool aufgerufen wird (Suche, DB, E‑Mail, Zahlung), wie Kontext komprimiert oder abgerufen wird und was zu tun ist, wenn das Modell etwas Ungültiges zurückgibt.
Wenn Du schneller von Idee zu funktionierender Orchestrierung kommen willst, kann ein vibe‑coding‑Workflow helfen, diese Pipelines zu prototypisieren, ohne das App‑Gerüst neu zu bauen. Zum Beispiel erlaubt Koder.ai Teams, Web‑Apps (React), Backends (Go + PostgreSQL) und sogar mobile Apps (Flutter) per Chat zu erstellen — und anschließend Flows wie „Eingaben → Modell → Tool‑Aufrufe → Validierungen → UI“ mit Planungsmodus, Snapshots und Rollback zu iterieren, plus Source‑Code‑Export, wenn Du das Repo übernehmen möchtest.
Zustandsautomaten für mehrstufige Aufgaben
Mehrstufige Erfahrungen (Triage → Informationen sammeln → Bestätigen → Ausführen → Zusammenfassen) funktionieren am besten, wenn Du sie als Workflow oder Zustandsautomat modellierst.
Ein einfaches Muster: jeder Schritt hat (1) erlaubte Eingaben, (2) erwartete Ausgaben und (3) Transitionen. Das verhindert abschweifende Konversationen und macht Edge‑Cases explizit — z. B. was passiert, wenn der Nutzer seine Meinung ändert oder nur Teilinformationen liefert.
Single‑Shot vs. mehrstufiges Reasoning
Single‑Shot eignet sich gut für abgegrenzte Aufgaben: eine Nachricht klassifizieren, eine kurze Antwort entwerfen, Felder aus einem Dokument extrahieren. Es ist günstiger, schneller und leichter zu validieren.
Mehrstufiges Reasoning ist besser, wenn das Modell klärende Fragen stellen muss oder Tools iterativ benötigt werden (z. B. planen → suchen → verfeinern → bestätigen). Setze es absichtlich ein und begrenze Schleifen mit Zeit‑/Schrittlimits.
Idempotenz: wiederholte Seiteneffekte vermeiden
Modelle wiederholen. Netze fallen aus. Nutzer klicken doppelt. Wenn ein KI‑Schritt Seiteneffekte auslösen kann — E‑Mails senden, Buchungen, Abbuchungen — mach ihn idempotent.
Gängige Taktiken: einem jeden „Ausführen“‑Action einen Idempotency‑Key anhängen, das Ergebnis speichern und sicherstellen, dass Retries dasselbe Ergebnis zurückliefern, statt es zu wiederholen.
Traces: jeden Schritt debuggbar machen
Führe Nachvollziehbarkeit ein, damit Du beantworten kannst: Was hat das Modell gesehen? Was hat es entschieden? Welche Tools liefen?
Logge für jeden Lauf einen strukturierten Trace: Prompt‑Version, Eingaben, abgerufene Kontext‑IDs, Tool‑Requests/Responses, Validierungsfehler, Retries und das finale Ergebnis. Das verwandelt „die KI hat etwas Seltsames gemacht“ in eine auditierbare, behebbare Timeline.
Prompting als Produktlogik: klare Verträge und Formate
Wenn das Modell Teil Deiner Anwendungslogik ist, werden Prompts von „Copy“ zu ausführbaren Spezifikationen. Behandle sie wie Produktanforderungen: expliziter Umfang, vorhersehbare Ausgaben und Change‑Control.
Mit einem System‑Prompt starten, der den Vertrag definiert
Dein System‑Prompt sollte die Rolle des Modells festlegen, was es darf und nicht darf, und die Sicherheitsregeln, die für Dein Produkt wichtig sind. Halte ihn stabil und wiederverwendbar.
Enthalten sollten sein:
- Rolle und Ziel: wer es ist (z. B. „Support‑Triage‑Assistent“) und wie Erfolg aussieht
- Scope‑Grenzen: welche Anfragen es ablehnen oder eskalieren muss
- Sicherheitsregeln: Umgang mit PII, medizinische/rechtliche Hinweise, kein Raten
- Tool‑Policy: wann Tools aufgerufen werden sollen vs. direkt antworten
Prompts mit klaren Ein‑/Ausgaben strukturieren
Schreibe Prompts wie API‑Definitionen: liste die genauen Eingaben auf, die Du bereitstellst (Nutzertest, Account‑Tier, Locale, Policy‑Auszüge) und die genauen Ausgaben, die Du erwartest. Füge 1–3 Beispiele hinzu, die realen Traffic widerspiegeln, inklusive kniffliger Edge‑Cases.
Ein nützliches Muster ist: Kontext → Aufgabe → Einschränkungen → Ausgabeformat → Beispiele.
Beschränkte Formate für maschinenlesbare Ergebnisse verwenden
Wenn Code die Ausgabe verarbeiten muss, verlasse Dich nicht auf Prosa. Fordere JSON an, das einem Schema entspricht, und lehne alles andere ab.
{
"type": "object",
"properties": {
"intent": {"type": "string"},
"confidence": {"type": "number", "minimum": 0, "maximum": 1},
"actions": {
"type": "array",
"items": {"type": "string"}
},
"user_message": {"type": "string"}
},
"required": ["intent", "confidence", "actions", "user_message"],
"additionalProperties": false
}
Prompts versionieren und sicher ausrollen
Speichere Prompts in der Versionskontrolle, tagge Releases und rolle sie wie Features aus: stufenweise Deployments, A/B‑Tests wo passend und schnelles Rollback. Logge die Prompt‑Version mit jeder Antwort für Debugging.
Baue eine Prompt‑Test‑Suite
Erstelle eine kleine, repräsentative Menge von Fällen (Happy Path, mehrdeutige Anfragen, Richtlinienverstöße, lange Eingaben, verschiedene Locales). Führe sie automatisch bei jeder Prompt‑Änderung aus und lasse den Build fehlschlagen, wenn Ausgaben den Vertrag verletzen.
Tool‑Aufrufe: das Modell entscheiden lassen, der Code ausführen
Über den Prototyp hinaus skalieren
Wechseln Sie vom Solo‑Prototyping zu einem geteilten Workspace, wenn Ihre KI‑Funktion wächst.
Tool‑Calling ist der sauberste Weg, Verantwortlichkeiten zu trennen: das Modell entscheidet was passieren muss und welche Fähigkeit zu nutzen ist, während Dein Anwendungscode die Aktion ausführt und verifizierte Ergebnisse zurückgibt.
Das hält Fakten, Berechnungen und Seiteneffekte (Ticketerstellung, Datensatzänderungen, E‑Mails) in deterministischem, auditierbarem Code — statt auf freiformigen Text zu vertrauen.
Ein kleines, intentional gestaltetes Toolset entwerfen
Beginne mit wenigen Tools, die 80 % der Anfragen abdecken und leicht zu sichern sind:
- Suche (Deine Dokumentation/Help‑Center) um Produktfragen zu beantworten
- DB‑Lookup (zuerst Read‑Only) für Nutzer/Account/Bestellstatus
- Rechner für Preise, Summen, Umrechnungen und regelbasierte Mathematik
- Ticketing um Supportanfragen zu öffnen, wenn menschliches Follow‑up nötig ist
Halte den Zweck jedes Tools eng. Ein Tool, das „alles“ kann, wird schwer testbar und leicht missbräuchlich.
Eingaben validieren, Ausgaben säubern
Behandle das Modell wie einen untrusted Caller.
- Tool‑Eingaben validieren mit strikten Schemata (Typen, Wertebereiche, Enums). Lehne unsichere Argumente ab oder repariere sie (z. B. fehlende IDs, zu weite Abfragen).
- Tool‑Ausgaben säubern bevor Du sie dem Modell zurückgibst: Geheimnisse entfernen, Formate normalisieren und nur die Felder zurückgeben, die das Modell benötigt.
Das reduziert Prompt‑Injection‑Risiko über abgerufene Texte und begrenzt unbeabsichtigte Datenlecks.
Berechtigungen und Rate‑Limits pro Tool hinzufügen
Jedes Tool sollte durchsetzen:
- Berechtigungsprüfungen (wer darf welche Datensätze oder Aktionen nutzen)
- Rate‑Limits (pro Nutzer/Sitzung/Tool) um Missbrauch und runaway‑Loops zu reduzieren
Wenn ein Tool Zustandsänderungen vornimmt (Ticketing, Rückerstattungen), erfordere stärkere Autorisierung und schreibe ein Audit‑Log.
Immer einen „kein Tool“‑Pfad unterstützen
Manchmal ist die beste Aktion keine Aktion: aus vorhandenem Kontext antworten, eine klärende Frage stellen oder Einschränkungen erklären. Mach „kein Tool“ zu einem erstklassigen Ergebnis, damit das Modell Tools nicht nur aufruft, um beschäftigt zu wirken.
Daten und RAG: das Modell in Deiner Realität verankern
Wenn die Antworten Deines Produkts mit Deinen Richtlinien, Inventar, Verträgen oder internem Wissen übereinstimmen müssen, brauchst Du einen Weg, das Modell mit Deinen Daten zu grounds — nicht nur mit seinem allgemeinen Training.
RAG vs. Fine‑Tuning vs. einfacher Kontext
- Einfacher Kontext (ein paar Absätze in den Prompt einfügen) funktioniert, wenn Wissen klein, stabil ist und Du es jedes Mal senden kannst (z. B. eine kurze Preistabelle).
- RAG (Retrieval‑Augmented Generation) ist am besten, wenn Informationen groß, häufig ändernd oder zitierfähig sein müssen (z. B. Help‑Center‑Artikel, Produktdokus, kontospezifische Daten).
- Fine‑Tuning ist sinnvoll, wenn Du konsistenten Stil/Format oder domänenspezifische Muster möchtest — nicht primär, um Fakten zu speichern. Nutze es, um Schreibweise und Regelbefolgung zu verbessern; kombiniere es mit RAG für aktuelle Wahrheiten.
Grundlagen der Ingestion: Chunking, Metadaten, Frische
RAG‑Qualität ist größtenteils ein Ingestionsproblem.
Zerlege Dokumente in Stücke, die zur Modellgröße passen (oft ein paar hundert Tokens), idealerweise entlang natürlicher Grenzen (Überschriften, FAQ‑Einträge). Speichere Metadaten wie Dokumenttitel, Abschnittsüberschrift, Produkt/Version, Zielgruppe, Locale und Berechtigungen.
Plane für Frische: reindizierung planen, „zuletzt aktualisiert“ tracken und alte Chunks ablaufen lassen. Ein veralteter Chunk, der hoch rankt, degradiert stillschweigend das gesamte Feature.
Zitate und kalibrierte Antworten
Lass das Modell Quellen angeben, indem es zurückgibt: (1) Antwort, (2) Liste von Snippet‑IDs/URLs und (3) eine Confidence‑Aussage.
Wenn Retrieval dünn ist, weise das Modell an zu sagen, was es nicht bestätigen kann, und nächste Schritte anzubieten („Ich konnte diese Richtlinie nicht finden; hier ist, wen du kontaktieren kannst“). Vermeide, Lücken zu füllen.
Private Daten: Zugriffskontrolle und Redaktion
Setze Zugriff vor der Retrieval durch (nach Nutzer/Org‑Berechtigungen filtern) und erneut vor der Generierung (sensible Felder redigieren).
Behandle Embeddings und Indizes als sensible Datenspeicher mit Audit‑Logs.
Wenn Retrieval fehlschlägt: elegante Fallbacks
Wenn Top‑Ergebnisse irrelevant oder leer sind, fall zurück auf: eine klärende Frage stellen, an menschlichen Support routen oder in einen Nicht‑RAG‑Modus wechseln, der Grenzen erklärt statt zu raten.
Zuverlässigkeit: Guardrails, Validierung und Caching
Wenn ein Modell in Deine App‑Logik eingebettet ist, reicht „meistens gut“ nicht. Zuverlässigkeit bedeutet, dass Nutzer konsistentes Verhalten sehen, Dein System Ausgaben sicher konsumieren kann und Fehler degradieren, ohne alles zu brechen.
Zuverlässigkeitsziele definieren (bevor Du Fixes hinzufügst)
Schreibe auf, was „zuverlässig“ für das Feature bedeutet:
- Konsistente Ausgaben: ähnliche Eingaben sollten vergleichbare Antworten erzeugen (Ton, Detailtiefe, Einschränkungen).
- Stabile Formate: die Antwort muss jedes Mal parsbar sein (JSON, Liste, spezifische Felder).
- Begrenztes Verhalten: klare Grenzen, was das Modell tun soll (nicht raten, Quellen nennen, bei Unsicherheit fragen).
Diese Ziele werden Akzeptanzkriterien für Prompts und Code.
Guardrails: validieren, filtern und Richtlinien durchsetzen
Behandle Modellausgaben als untrusted Input.
- Schema‑Validierung: erfordere ein striktes Format (z. B. JSON mit erforderlichen Schlüsseln) und lehne alles ab, das nicht parst.
- Content‑Filter: führe Profanity‑Checks, PII‑Detektoren oder Policy‑Validatoren auf Nutzer‑Input und Modell‑Output aus.
- Geschäftsregeln: setze Constraints im Code durch (Preisbereiche, Berechtigungsregeln, erlaubte Aktionen), auch wenn der Prompt sie erwähnt.
Wenn Validierung fehlschlägt, gib einen sicheren Fallback zurück (klären, zu einem einfacheren Template wechseln oder an einen Menschen routen).
Retries, die wirklich helfen
Vermeide blindes Wiederholen. Wiederhole mit einem geänderten Prompt, der den Fehlermodus anspricht:
- „Gib nur gültiges JSON zurück. Kein Markdown.“
- „Wenn unsicher, setze
confidenceniedrig und stelle eine Frage.“
Begrenze Retries und logge den Grund für jeden Fehler.
Deterministische Nachbearbeitung
Nutze Code, um Modellresultate zu normalisieren:
- Einheiten, Daten und Namen kanonisieren
- Duplikate entfernen
- Ranking‑Regeln oder Thresholds anwenden
Das reduziert Varianz und macht Ausgaben testbarer.
Caching ohne Privatsphäre zu gefährden
Cache wiederholbare Ergebnisse (identische Anfragen, geteilte Embeddings, Tool‑Antworten) um Kosten und Latenz zu senken.
Bevorzuge:
- kurze TTLs für nutzerspezifische Daten
- Cache‑Keys, die rohe PII ausschließen (oder sorgfältig hashen)
- „Nicht cachen“‑Flags für sensible Flows
Richtig gemacht erhöht Caching Konsistenz und erhält gleichzeitig Nutzervertrauen.
Sicherheit und Vertrauen: Risiken reduzieren ohne die UX zu zerstören
Volle Code‑Kontrolle behalten
Übernehmen Sie Ihr Repo, wenn Sie bereit sind, indem Sie den Quellcode aus Koder.ai exportieren.
Sicherheit ist keine nachträglich anzubringende Compliance‑Schicht. In KI‑first‑Produkten kann das Modell Aktionen, Formulierungen und Entscheidungen beeinflussen — daher muss Sicherheit Teil Deines Produktvertrags sein: was der Assistent darf, was er ablehnen muss und wann er Hilfe holen soll.
Wichtige Sicherheitsrisiken, für die Du designen solltest
Nenne die Risiken, die Deine App tatsächlich hat, und weise jedem eine Kontrolle zu:
- Sensible Daten: persönliche Identifikatoren, Credentials, private Dokumente, regulatorisch relevante Inhalte
- Schädliche Anleitungen: Anweisungen, die Selbstschädigung, Gewalt, illegale Aktivitäten oder unsichere medizinische/finanzielle Handlungen ermöglichen
- Bias und ungerechte Ergebnisse: inkonsistente Service‑Qualität, Empfehlungen oder Entscheidungen zwischen Gruppen
Erlaubte/gesperrte Themen + Eskalationspfade
Schreibe eine explizite Policy, die Dein Produkt durchsetzen kann. Halte sie konkret: Kategorien, Beispiele und erwartete Antworten.
Nutze drei Stufen:
- Erlaubt: normal antworten.
- Eingeschränkt: mit Einschränkungen antworten (z. B. nur allgemeine Infos, keine Schritt‑für‑Schritt‑Anleitungen).
- Blockiert: ablehnen und an einen Eskalationspfad routen (Support, Ressourcen oder ein menschlicher Agent).
Eskalation sollte ein Produktflow sein, nicht nur eine Ablehnungsmeldung. Biete eine „Mit einer Person sprechen“‑Option und sorge dafür, dass die Übergabe den bereits geteilten Kontext enthält (mit Zustimmung).
Menschliche Überprüfung bei weitreichenden Aktionen
Wenn das Modell reale Konsequenzen auslösen kann — Zahlungen, Rückerstattungen, Kontoänderungen, Kündigungen, Datenlöschung — füge einen Prüfpunkt ein.
Gute Muster: Bestätigungsdialoge, „Entwurf dann Freigabe“, Limits (Betragsgrenzen) und eine menschliche Review‑Queue für Edge‑Cases.
Offenlegungen, Einwilligung und testbare Policies
Informiere Nutzer, wenn sie mit KI interagieren, welche Daten verwendet werden und was gespeichert wird. Hole Einwilligungen ein, wo nötig — besonders beim Speichern von Konversationen oder der Verwendung von Daten zur Systemverbesserung.
Behandle interne Sicherheitsrichtlinien wie Code: versioniere sie, dokumentiere die Begründung und erstelle Tests (Beispiel‑Prompts + erwartete Ergebnisse), damit Sicherheit nicht bei jedem Prompt‑ oder Modellupdate regressiert.
Evaluation: Teste das Modell wie jede andere kritische Komponente
Wenn ein LLM das Produktverhalten verändern kann, brauchst Du eine wiederholbare Methode, um zu beweisen, dass alles noch funktioniert — bevor Nutzer Regressionen entdecken.
Behandle Prompts, Modellversionen, Tool‑Schemata und Retrieval‑Einstellungen als releasefähige Artefakte, die Tests erfordern.
Baue ein Evaluationsset aus der Realität
Sammle reale Nutzer‑Intents aus Support‑Tickets, Suchanfragen, Chat‑Logs (mit Zustimmung) und Sales‑Calls. Verwandle sie in Testfälle, die enthalten:
- Häufige Happy‑Path‑Anfragen
- Mehrdeutige Prompts, die klärende Fragen erfordern
- Edge‑Cases (fehlende Daten, widersprüchliche Einschränkungen, ungewöhnliche Formate)
- Richtlinienrelevante Szenarien (personenbezogene Daten, unzulässige Inhalte)
Jeder Fall sollte erwartetes Verhalten enthalten: die Antwort, die getroffene Entscheidung (z. B. „Rufe Tool A auf“) und jegliche erforderliche Struktur (vorhandene JSON‑Felder, Zitierungen etc.).
Wähle Metriken, die zum Produkt‑Risiko passen
Eine Metrik reicht nicht. Nutze eine kleine Menge an Kennzahlen, die zu Nutzerergebnissen passen:
- Accuracy / Task Success: wurde das Nutzerziel erreicht?
- Groundedness: sind Aussagen durch Kontext oder Quellen belegt?
- Format‑Validität: entspricht die Ausgabe dem Vertrag (JSON, Tabelle, Bullet‑Points)?
- Refusal‑Rate: lehnt es ab, wenn es sollte — und vermeidet unnötiges Ablehnen?
Verfolge Kosten und Latenz zusammen mit Qualität; ein „besseres“ Modell, das die Antwortzeit verdoppelt, kann die Conversion schädigen.
Offline‑Evals bei jeder Änderung
Führe Offline‑Evaluierungen vor dem Release und nach jeder Prompt‑, Modell‑, Tool‑ oder Retrieval‑Änderung aus. Versioniere Ergebnisse, damit Du Runs vergleichen und schnell identifizieren kannst, was gebrochen hat.
Online‑Tests mit Guardrails
Nutze Online‑A/B‑Tests, um reale Outcomes zu messen (Abschlussrate, Edit‑Rate, Nutzerbewertungen), aber ergänze Sicherheitsnetze: Stop‑Bedingungen definieren (z. B. Anstieg ungültiger Ausgaben, Ablehnungen oder Tool‑Fehler) und automatisch zurückrollen, wenn Schwellwerte überschritten werden.
Monitoring in Produktion: Drift, Fehler und Feedback
KI‑Logik schnell prototypen
Baue einen KI‑zentrierten Workflow per Chat und iteriere sicher mit Snapshots und Rollback.
Das Ausliefern eines KI‑first‑Features ist nicht das Ende. Im Live‑Betrieb trifft das Modell neue Formulierungen, Edge‑Cases und sich ändernde Daten. Monitoring macht aus „es funktionierte in Staging“ ein „es funktioniert nächsten Monat noch“.
Logge, was wichtig ist (ohne Geheimnisse zu sammeln)
Erfasse genug Kontext, um Fehler zu reproduzieren: Nutzer‑Intent, Prompt‑Version, Tool‑Aufrufe und die finale Modellausgabe.
Logge Ein‑/Ausgaben mit datenschutzgerechter Redaktion. Behandle Logs als sensible Daten: entferne E‑Mails, Telefonnummern, Tokens und Freitext, der persönliche Details enthalten könnte. Halte einen „Debug‑Modus“ bereit, den Du temporär für bestimmte Sitzungen aktivieren kannst, statt standardmäßig maximal zu loggen.
Die richtigen Signale beobachten
Überwache Fehlerquoten, Tool‑Fehler, Schema‑Verstöße und Drift. Konkret:
- Tool‑Call Erfolgsquote und Timeouts (hat das Modell das richtige Tool gewählt und wurde es ausgeführt?)
- Ausgabeformat/Schema‑Compliance (haben Validatoren abgelehnt?)
- Fallback‑Nutzung (wie oft musstest Du zu einem sichereren oder einfacheren Pfad wechseln?)
- Content‑Safety‑Blocks (wie häufig wurde abgelehnt oder sanitisiert?)
Für Drift vergleiche den aktuellen Traffic mit Deinem Baseline: Änderungen in Thema, Sprache, durchschnittlicher Prompt‑Länge und „unknown“‑Intents. Drift ist nicht immer schlecht — aber immer ein Hinweis zur Neubewertung.
Alerts, Runbooks und Incident‑Response
Setze Alert‑Schwellen und On‑Call‑Runbooks. Alerts sollten mit Aktionen verknüpft sein: Prompt‑Version zurückrollen, ein fehlerhaftes Tool deaktivieren, Validierung verschärfen oder auf einen Fallback wechseln.
Plane Incident‑Response für unsicheres oder falsches Verhalten. Definiere, wer Sicherheitsschalter betätigen darf, wie Nutzer informiert werden und wie Du den Vorfall dokumentierst und daraus lernst.
Den Kreis mit Nutzerfeedback schließen
Nutze Feedback‑Schleifen: Daumen hoch/runter, Grund‑Codes, Bug‑Reports. Frage nach leichtgewichtigen „Warum?“-Optionen (falsche Fakten, Instruktionen nicht befolgt, unsicher, zu langsam), damit Du Probleme richtig zuweist — Prompt, Tools, Daten oder Richtlinie.
UX für modellgetriebene Logik: Transparenz und Kontrolle
Modellgetriebene Features wirken magisch, wenn sie funktionieren — und brüchig, wenn nicht. UX muss Unsicherheit annehmen und trotzdem Nutzern helfen, die Aufgabe zu beenden.
Das „Warum“ zeigen, ohne zu überfordern
Nutzer vertrauen KI‑Ausgaben eher, wenn sie sehen, woher sie stammen — nicht, weil sie eine Vorlesung wollen, sondern weil es bei der Entscheidung hilft.
Nutze progressive Offenlegung:
- Beginne mit dem Ergebnis (Antwort, Entwurf, Empfehlung).
- Biete einen „Warum?“‑ oder „Arbeit zeigen“‑Toggle, der die wichtigsten Eingaben offenlegt: die Nutzeranfrage, verwendete Tools und die konsultierten Quellen oder Datensätze.
- Wenn Du Retrieval nutzt, zeige Zitate, die zur genauen Textstelle springen (z. B. „Basierend auf: Richtlinie §3.2“). Halte es übersichtlich.
Wenn Du eine tiefere Erklärung hast, verlinke intern (z. B. /blog/rag-grounding) statt die UI mit Details zu überfrachten.
Unsicherheit gestalten (ohne beängstigende Warnungen)
Ein Modell ist kein Taschenrechner. Die Oberfläche sollte Vertrauen in AI‑Ausgaben schaffen und zur Überprüfung einladen.
Praktische Muster:
- Vertrauen‑Hinweise in Alltagssprache („Wahrscheinlich korrekt“, „Braucht Überprüfung“) statt falscher Präzision
- Optionen statt einzelner Antworten: „Hier sind 3 mögliche Antworten.“ Das senkt die Kosten eines falschen ersten Vorschlags
- Bestätigungen bei weitreichenden Aktionen (E‑Mails senden, Daten löschen, Zahlungen buchen). Stelle eine einzelne, klare Frage: „Diese Nachricht an 12 Empfänger senden?“
Korrektur und Wiederherstellung mühelos machen
Nutzer sollten das Ergebnis steuern können, ohne neu starten zu müssen:
- Inline‑Editing mit „Änderungen übernehmen“, damit das Modell von den Nutzereingriffen weiterarbeitet
- „Regenerate“ mit Steuerungen (Ton, Länge, Einschränkungen) statt einem blinden Neuwurf
- „Rückgängig“ und sichtbare History, damit Fehler reversibel sind
Eine Notfall‑Option anbieten
Wenn das Modell versagt oder der Nutzer unsicher ist, biete deterministische Flows oder menschliche Hilfe an.
Beispiele: „Auf manuelles Formular wechseln“, „Vorlage verwenden“ oder „Support kontaktieren“ (z. B. /support). Das ist kein Zugeständnis, sondern wie Du Aufgabeabschluss und Vertrauen schützt.
Vom Prototyp zur Produktion (ohne alles neu zu bauen)
Die meisten Teams scheitern nicht, weil LLMs unfähig sind; sie scheitern, weil der Weg vom Prototyp zu einem zuverlässigen, testbaren, monitorbaren Feature länger ist als erwartet.
Ein praktischer Weg, diese Strecke zu verkürzen, ist, das „Produkt‑Skelett“ früh zu standardisieren: Zustandsautomaten, Tool‑Schemata, Validierung, Traces und eine Deploy/Rollback‑Story. Plattformen wie Koder.ai können hier nützlich sein, wenn Du schnell einen KI‑first‑Workflow aufsetzen willst — UI, Backend und Datenbank zusammen — und dann sicher mit Snapshots/Rollback, Custom Domains und Hosting iterierst. Wenn Du bereit bist zu operationalisieren, kannst Du den Source‑Code exportieren und mit Deinem CI/CD‑ und Observability‑Stack weiterarbeiten.