20. März 2025·8 Min
Wie man eine Kunden‑Support‑Web‑App für Tickets & SLAs baut
Planen, entwerfen und bauen Sie eine Kunden‑Support‑Web‑App mit Ticket‑Workflows, SLA‑Tracking und einer durchsuchbaren Wissensdatenbank – plus Rollen, Analysen und Integrationen.
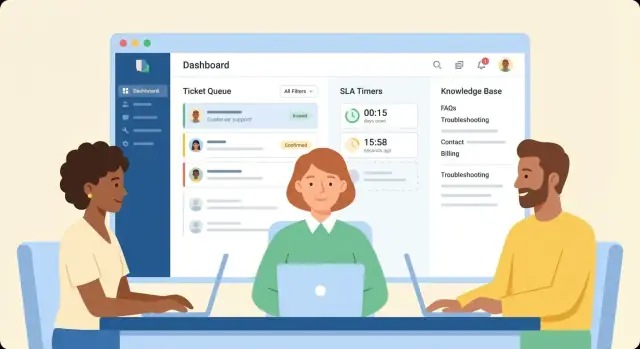
Ziele, Nutzer und Umfang definieren
Ein Ticket-Produkt wird chaotisch, wenn es um Funktionen statt um Ergebnisse aufgebaut wird. Bevor Sie Felder, Queues oder Automatisierungen entwerfen, klären Sie, für wen die App ist, welches Problem sie löst und wie „gut“ aussieht.
Identifizieren Sie Ihre Nutzer (und ihre täglichen Aufgaben)
Beginnen Sie damit, die Rollen zu listen und was jede Rolle in einer normalen Woche erledigen muss:
- Agenten: Tickets priorisieren, antworten, lösen und Lösungen schnell dokumentieren.
- Teamleiter: Arbeitslast ausbalancieren, feststeckende Tickets erkennen, SLAs durchsetzen, Agenten coachen.
- Admins: Kanäle, Kategorien, Automatisierungen, Berechtigungen und Vorlagen konfigurieren.
- Kunden (optional): Anfragen einreichen, Status verfolgen, Details ergänzen, Antworten in einem Portal finden.
Wenn Sie diesen Schritt überspringen, optimieren Sie versehentlich für Admins, während Agenten in der Queue kämpfen.
Notieren Sie die Probleme, die Sie lösen wollen
Halten Sie das konkret und an beobachtbaren Verhaltensweisen fest:
- Verpasste SLAs: Tickets altern stillschweigend; Eskalationen kommen zu spät.
- Chaotische Queues: Unklare Zuständigkeit, doppelte Arbeit und Verwirrung darüber, wohin ein Ticket gehört.
- Wiederkehrende Fragen: Dieselben Antworten werden immer wieder getippt, was die Lösungszeit verlangsamt.
Entscheiden Sie, wo die App genutzt wird
Seien Sie explizit: Ist das ein nur internes Tool, oder liefern Sie auch ein kundenorientiertes Portal aus? Portale ändern Anforderungen (Authentifizierung, Berechtigungen, Inhalte, Branding, Benachrichtigungen).
Wählen Sie Erfolgsmessgrößen früh aus
Wählen Sie eine kleine Menge an Kennzahlen, die Sie vom ersten Tag an verfolgen werden:
- Zeit bis zur ersten Antwort
- Lösungszeit
- Deflection‑Rate (Probleme, die über die Wissensdatenbank statt über Tickets gelöst werden)
Erstellen Sie eine einfache Scope‑Aussage für v1
Schreiben Sie 5–10 Sätze, die beschreiben, was in v1 enthalten ist (unverzichtbare Workflows) und was später kommt (schöne Zusatzfunktionen wie erweitertes Routing, KI‑Vorschläge oder tiefgehende Reports). Das dient als Leitplanke, wenn die Anfragen zunehmen.
Modell und Lebenszyklus eines Tickets entwerfen
Ihr Ticketmodell ist die „Quelle der Wahrheit“ für alles andere: Queues, SLAs, Reporting und das, was Agenten auf dem Bildschirm sehen. Treffen Sie diese Entscheidungen früh, um schmerzhafte Migrationen zu vermeiden.
Abbilden Sie einen Lebenszyklus, den Sie in einem Satz erklären können
Beginnen Sie mit einer klaren Menge von Zuständen und definieren Sie, was jeder operativ bedeutet:
- Neu: erstellt, noch nicht triagiert
- Zugewiesen: in Verantwortung eines Agenten oder Teams
- In Arbeit: wird aktiv bearbeitet
- Warten: blockiert (Kundenantwort, Drittpartei, Engineering)
- Gelöst: Agent hält das Problem für behoben (löst oft eine Benachrichtigung aus)
- Geschlossen: Endzustand (gesperrt oder nur eingeschränkte Bearbeitung)
Fügen Sie Regeln für Zustandsübergänge hinzu. Zum Beispiel dürfen nur Zugewiesen/In Arbeit‑Tickets auf Gelöst gesetzt werden, und ein Geschlossenes Ticket darf nicht wieder geöffnet werden, ohne ein Folge‑Ticket zu erstellen.
Entscheiden Sie, wie Tickets ins System gelangen
Listen Sie jeden Intake‑Pfad auf, den Sie jetzt unterstützen (und was später hinzukommt): Webformular, eingehende E‑Mail, Chat und API. Jeder Kanal sollte dasselbe Ticket‑Objekt erzeugen, mit ein paar kanal‑spezifischen Feldern (z. B. E‑Mail‑Header oder Chat‑Transkript‑IDs). Konsistenz hält Automatisierung und Reporting übersichtlich.
Wählen Sie erforderliche Felder (und halten Sie sie minimal)
Mindestens erforderlich:
- Betreff und Beschreibung
- Anfragender (Kundenidentität)
- Priorität (wie dringend)
- Kategorie (welcher Art das Problem ist)
Alles andere kann optional oder abgeleitet sein. Ein aufgeblähtes Formular reduziert die Qualität der Eingaben und verlangsamt Agenten.
Planen Sie Tags und benutzerdefinierte Felder für reale Teams
Verwenden Sie Tags für leichtes Filtern (z. B. „billing“, „bug“, „vip“) und benutzerdefinierte Felder, wenn Sie strukturiertes Reporting oder Routing benötigen (z. B. „Produktbereich“, „Bestell‑ID“, „Region“). Stellen Sie sicher, dass Felder team‑gescoped sein können, damit eine Abteilung nicht die einer anderen zuspammt.
Definieren Sie Zusammenarbeit innerhalb eines Tickets
Agenten brauchen einen sicheren Ort zur Koordination:
- Interne Notizen (nicht für Kunden sichtbar)
- @Erwähnungen und Follower/CC‑Listen
- Verknüpfte Tickets (Duplikate, Parent/Child‑Incidents)
Ihre Agenten‑UI sollte diese Elemente mit einem Klick vom Haupt‑Timeline erreichbar machen.
Ticket‑Queues und Zuweisungs‑Workflows bauen
Queues und Zuweisungen sind der Punkt, an dem ein Ticket‑System aus einem gemeinsamen Postfach ein Operationstool wird. Ihr Ziel ist einfach: Jedes Ticket sollte eine offensichtliche „nächste beste Aktion“ haben, und jeder Agent sollte wissen, woran er gerade arbeiten soll.
Entwerfen Sie eine Agenten‑Queue, die „Was kommt als Nächstes?“ beantwortet
Erstellen Sie eine Queue‑Ansicht, die standardmäßig die zeitkritischste Arbeit zeigt. Übliche Sortieroptionen, die Agenten tatsächlich nutzen, sind:
- Priorität (z. B. P1–P4)
- SLA‑Fälligkeit (zuerst die bald fälligen)
- Zuletzt aktualisiert (um feststeckende Konversationen zu erkennen)
Fügen Sie Schnellfilter hinzu (Team, Kanal, Produkt, Kundentier) und eine schnelle Suche. Halten Sie die Liste kompakt: Betreff, Anfragender, Priorität, Status, SLA‑Count‑down und zuständiger Agent reichen meist aus.
Zuweisungsregeln: automatisch, wenn möglich; manuell, wenn nötig
Unterstützen Sie einige Zuweisungspfade, damit Teams sich entwickeln können, ohne das Tool zu wechseln:
- Manuelle Zuweisung für Sonderfälle und Trainings
- Round‑Robin, um Last gleichmäßig zu verteilen
- Skills‑basierte Weiterleitung (Sprache, Produktbereich, Billing vs. Technik)
- Team‑basiertes Routing (z. B. „Payments“, „Enterprise“, „Returns")
Machen Sie die Regelentscheidung sichtbar („Zugewiesen von: Skills → Französisch + Billing“), damit Agenten dem System vertrauen.
Status und Vorlagen, die Arbeit voranbringen
Status wie Warten auf Kunde und Warten auf Dritte verhindern, dass Tickets „inaktiv“ aussehen, wenn Aktionen blockiert sind, und machen das Reporting ehrlicher.
Um Antworten zu beschleunigen, fügen Sie Fertige Antworten und Antwortvorlagen mit sicheren Variablen (Name, Bestellnummer, SLA‑Datum) hinzu. Vorlagen sollten durchsuchbar und von autorisierten Leads editierbar sein.
Kollisionen verhindern (zwei Agenten, ein Ticket)
Fügen Sie Kollisions‑Handling hinzu: Wenn ein Agent ein Ticket öffnet, setzen Sie eine kurzlebige „Ansichts-/Edit‑Sperre“ oder ein Banner „wird gerade bearbeitet von“. Wenn jemand anderes versucht zu antworten, warnen Sie und verlangen Sie eine Bestätigung vor dem Senden (oder blockieren Sie das Senden), um doppelte oder widersprüchliche Antworten zu vermeiden.
SLA‑Regeln, Timer und Eskalationen implementieren
SLAs helfen nur, wenn alle sich darauf einigen, was gemessen wird und die App es konsistent durchsetzt. Übersetzen Sie „wir antworten schnell“ in Richtlinien, die Ihr System berechnen kann.
Definieren Sie SLA‑Richtlinien (was gemessen wird)
Die meisten Teams beginnen mit zwei Timern pro Ticket:
- Zeit bis zur ersten Antwort: Zeit von der Erstellung bis zur ersten Agentenantwort (oder der ersten nicht‑automatisierten öffentlichen Antwort).
- Lösungszeit: Zeit von der Erstellung bis „Gelöst/Geschlossen“.
Halten Sie Richtlinien konfigurierbar nach Priorität, Kanal oder Kundentier (z. B. VIP 1 Stunde bis zur ersten Antwort, Standard 8 Geschäfts‑stunden).
Entscheiden Sie, wann SLA‑Uhren starten und stoppen
Schreiben Sie Regeln vor dem Coden auf, denn Randfälle häufen sich schnell:
- Geschäftszeiten vs. 24/7: definieren Sie einen Kalender (Zeitzone, Wochentage, Feiertage).
- Pausen‑Zustände: stoppen Sie die Uhr, wenn das Ticket in „Warten auf Kunde“ oder „Ausstehend Externer Anbieter“ ist.
- Wiederaufnahmebedingungen: starten Sie wieder, wenn der Kunde antwortet oder der Zustand zurück auf „Offen/In Arbeit“ wechselt.
Speichern Sie SLA‑Ereignisse (gestartet, pausiert, fortgesetzt, verletzt), damit Sie später erklären können, warum etwas verletzt wurde.
Machen Sie SLA‑Status in der UI offensichtlich
Agenten sollten ein Ticket nicht öffnen müssen, um zu sehen, dass es bald verletzt wird. Fügen Sie hinzu:
- Einen Countdown‑Timer (verbleibende Zeit)
- Überfällig‑Markierungen mit klarer Schwere (Warnung vs. verletzt)
- Optionale Alerts (in‑App, E‑Mail oder Chat), wenn eine Schwelle naht
Eskalationspfade bauen
Eskalation sollte automatisch und vorhersehbar erfolgen:
- Team‑Lead bei 80% der erlaubten Zeit benachrichtigen
- Bei Bruch an eine diensthabende Queue neu zuweisen
- Priorität erhöhen oder ein „Eskalation“‑Tag hinzufügen
SLA‑Reporting planen
Mindestens sollten Sie Anzahl Verletzungen, Verletzungsrate und Trend über die Zeit verfolgen. Protokollieren Sie auch Verletzungsgründe (zu lange Pause, falsche Priorität, unterbesetzte Queue), damit Reports zu Maßnahmen und nicht zu Beschuldigungen führen.
Eine Wissensdatenbank erstellen, die wiederkehrende Tickets reduziert
Eine gute Wissensdatenbank (KB) ist nicht nur ein Ordner voller FAQs — sie ist ein Produktfeature, das wiederkehrende Fragen messbar reduziert und Lösungen beschleunigt. Gestalten Sie sie als Teil Ihres Ticket‑Flows, nicht als getrennte Dokumentationsseite.
Struktur: machen Sie Inhalte pflegeleicht
Starten Sie mit einem einfachen Informationsmodell, das skaliert:
- Kategorien → Sektionen → Artikel (einfache Navigation für Kunden und Agenten)
- Tags für bereichsübergreifende Themen (Billing, Login, Integrationen) ohne Artikel zu duplizieren
- Klare Zuständigkeiten (wer was reviewed), damit Inhalte aktuell bleiben
Halten Sie Artikelvorlagen konsistent: Problemstellung, Schritt‑für‑Schritt‑Lösung, optional Screenshots, und ein Abschnitt „Wenn das nicht geholfen hat…“ mit Hinweis auf das passende Ticket‑Formular oder den passenden Kanal.
Suche, die wirklich Antworten findet
Die meisten KB‑Fehlschläge sind Suchfehler. Implementieren Sie Suche mit:
- Relevanz‑Tuning (Boosts für Titel/Überschriften, Freshness‑Boosts)
- Synonyme (z. B. „invoice“ ↔ „bill“, „2FA“ ↔ „Authentifizierungs‑Code")
- Toleranz für Tippfehler und Stemming (Plural/Singular)
Indexieren Sie außerdem anonymisierte Ticket‑Betreffzeilen, um reale Kundenformulierungen zu lernen und Ihre Synonymliste zu füttern.
Entwürfe, Reviews und Veröffentlichungsfreigaben
Fügen Sie einen leichten Workflow hinzu: Entwurf → Review → Veröffentlicht, mit optionaler Zeitplanung. Speichern Sie Versionsverlauf und zeigen Sie „zuletzt aktualisiert“ Metadaten an. Kombinieren Sie das mit Rollen (Autor, Reviewer, Publisher), damit nicht jeder Agent öffentliche Inhalte editieren kann.
Messen, was Tickets reduziert
Verfolgen Sie mehr als Seitenaufrufe. Nützliche Kennzahlen sind:
- Hilfreich‑Votes (Ja/Nein) und „was fehlte?“ Feedback
- Deflection‑Signale: Suche → Artikel angesehen → kein Ticket innerhalb von X Stunden
- Top‑Suchen ohne gute Ergebnisse (Content‑Lücken)
Artikel dort verlinken, wo gearbeitet wird
Zeigen Sie im Agenten‑Antwortkomponisten vorgeschlagene Artikel basierend auf Betreff, Tags und erkannter Intention des Tickets. Ein Klick sollte einen öffentlichen Link (z. B. /help/account/reset-password) oder einen internen Snippet einfügen, um Antworten zu beschleunigen.
Gut gemacht wird die KB Ihre erste Support‑Linie: Kunden lösen Probleme selbst, und Agenten bearbeiten weniger wiederkehrende Tickets mit höherer Konsistenz.
Rollen, Berechtigungen und Nachvollziehbarkeit einrichten
Bereitstellen ohne zusätzlichen Aufwand
Stelle deine Support‑App bereit und hoste sie, wenn du bereit bist, live zu gehen.
Berechtigungen sind der Punkt, an dem ein Ticketing‑Tool entweder sicher und vorhersehbar bleibt — oder schnell unordentlich wird. Warten Sie nicht bis nach dem Launch, um „abzusperren“. Modellieren Sie den Zugriff früh, damit Teams schnell arbeiten können, ohne sensible Tickets offenzulegen oder falsche Personen Systemregeln ändern zu lassen.
Rollen trennen (und einfach halten)
Starten Sie mit wenigen klaren Rollen und fügen Sie Nuancen nur bei echtem Bedarf hinzu:
- Agent: bearbeitet Tickets, fügt Notizen hinzu, antwortet, aktualisiert Felder.
- Lead: alles, was ein Agent kann, plus Neu‑Zuweisung, Queue‑Management und Coaching‑Workflows.
- Admin: systemweite Einstellungen wie Kanäle, Benutzerverwaltung und Konfiguration.
- Content‑Editor: erstellt und veröffentlicht KB‑Artikel.
- Nur‑Lesen: für Auditing, Finanzen, Recht oder Stakeholder, die Sichtbarkeit ohne Änderungen benötigen.
Berechtigungen nach Fähigkeiten definieren
Vermeiden Sie „Alles‑oder‑Nichts“‑Zugriff. Behandeln Sie Hauptaktionen als explizite Berechtigungen:
- Anzeigen vs. Bearbeiten von Tickets (einschließlich privater Notizen)
- Makros/Fertige Antworten verwalten
- SLA‑Regeln, Timer und Eskalationsrichtlinien bearbeiten
- Wissensdatenbank publizieren/depublizieren
Das erleichtert Least‑Privilege‑Zugriff und Wachstum (neue Teams, Regionen, Auftragnehmer).
Team‑basierter Zugriff für sensible Queues
Einige Queues sollten standardmäßig eingeschränkt sein — Billing, Security, VIP oder HR‑bezogene Anfragen. Nutzen Sie Team‑Mitgliedschaft, um zu steuern:
- Welche Queues sichtbar sind
- Wer Tickets neu zuweisen oder zusammenführen kann
- Ob Kundendatenfelder maskiert werden
Audit‑Logs, die Sie tatsächlich nutzen werden
Protokollieren Sie wichtige Aktionen mit wer, was, wann und Vorher/Nachher‑Werten: Zuweisungsänderungen, Löschungen, SLA/Policy‑Änderungen, Rollenänderungen und KB‑Publikationen. Machen Sie Logs durchsuchbar und exportierbar, damit Untersuchungen keine DB‑Abfragen erfordern.
Multi‑Brand oder Multi‑Inbox früh planen
Wenn Sie mehrere Marken oder Postfächer unterstützen, entscheiden Sie, ob Nutzer Kontexte wechseln können oder der Zugriff partitioniert ist. Das beeinflusst Berechtigungsprüfungen und Reporting und sollte von Anfang an konsistent sein.
Agenten‑ und Admin‑User‑Experience gestalten
Ein Ticketing‑System gelingt oder scheitert daran, wie schnell Agenten eine Situation erfassen und die nächste Aktion ausführen können. Behandeln Sie den Agenten‑Arbeitsbereich als „Home‑Screen“: Er sollte drei Fragen sofort beantworten—was ist passiert, wer ist dieser Kunde und was soll ich als Nächstes tun?
Layout des Agenten‑Arbeitsbereichs
Beginnen Sie mit einer Split‑Ansicht, die Kontext sichtbar hält, während Agenten arbeiten:
- Konversationsthread (E‑Mail/Chat/Nachrichten) mit klaren Zeitstempeln, Anhängen und Zitaten.
- Kundenpanel mit Identität, Plan/Kundentier, Organisation, vergangenen Tickets und wichtigen Notizen.
- Ticket‑Felder (Status, Priorität, Queue, Zuständiger, Tags, SLA‑Timer) logisch gruppiert, nicht verstreut.
Halten Sie den Thread lesbar: unterscheiden Sie Kunde vs. Agent vs. Systemereignisse und machen Sie interne Notizen visuell anders, damit sie niemals versehentlich gesendet werden.
One‑Click‑Aktionen, die Reibung entfernen
Platzieren Sie häufige Aktionen dort, wo sich bereits der Cursor befindet—nahe der letzten Nachricht und oben im Ticket:
- Zuweisen / neu zuweisen
- Status ändern (inkl. „Warten auf Kunde“)
- Interne Notiz hinzufügen
- Makro anwenden (vorausgefüllte Antwort + Feld‑Updates)
Zielen Sie auf „ein Klick + optionaler Kommentar“‑Abläufe. Wenn eine Aktion ein Modal erfordert, sollte es kurz und keyboard‑freundlich sein.
Geschwindigkeitsfeatures für hochvolumige Teams
High‑throughput Support braucht Shortcuts, die vorhersehbar sind:
- Tastenkürzel für Antwort, Notiz, „Mir zuweisen“, Schließen und nächstes Ticket
- Massenaktionen in Listenansichten (taggen, zuweisen, schließen, mergen)
- Ein schnelles Command‑Palette für Power‑User
Barrierefreiheit und UI‑Sicherheit
Bauen Sie Accessibility von Anfang an ein: ausreichender Kontrast, sichtbare Fokuszustände, vollständige Tab‑Navigation und Screen‑Reader‑Labels für Controls und Timer. Verhindern Sie teure Fehler mit kleinen Schutzmaßnahmen: Bestätigungen bei destruktiven Aktionen, klare Kennzeichnung „öffentliche Antwort“ vs. „interne Notiz“ und Vorschau dessen, was gesendet wird.
Admin‑ und Kundenportal‑UX
Admins brauchen einfache, geführte Bildschirme für Queues, Felder, Automatisierungen und Vorlagen—vermeiden Sie, Essentials hinter verschachtelten Einstellungen zu verstecken.
Wenn Kunden Tickets einreichen und verfolgen können, gestalten Sie ein leichtgewichtiges Portal: Ticket erstellen, Status anzeigen, Updates hinzufügen und vor der Einreichung vorgeschlagene Artikel sehen. Halten Sie es konsistent mit Ihrer Außendarstellung und verlinken Sie es von /help.
Integrationen, APIs und Omnichannel‑Intake planen
Von der Spezifikation zur funktionierenden App
Verwandle dein Ticketmodell und den Lifecycle in funktionierende React‑Screens und eine Go‑API.
Ein Ticketing‑App wird nützlich, wenn sie sich mit den Orten verbindet, an denen Kunden bereits mit Ihnen kommunizieren—und mit den Tools, die Ihr Team zur Problemlösung braucht.
Starten Sie mit Systemen, die Sie verbinden müssen
Listen Sie Ihre „Tag‑eins“ Integrationen und welche Daten Sie von jedem benötigen:
- E‑Mail (Shared Inboxes, Weiterleitungsregeln, ausgehendes SMTP)
- Chat (Website‑Widget, WhatsApp, Intercom‑ähnliche Tools)
- CRM (Account‑Kontext, Owner, Kundentier)
- Billing (Abonnementstatus, Rechnungen, Rückerstattungen)
- Identity Provider (SSO via Google/Microsoft, SCIM‑Provisioning)
Dokumentieren Sie, in welche Richtung Daten fließen (nur lesen vs. write‑back) und wer intern die Integration verantwortet.
Designen Sie Ihre API und Webhooks früh
Auch wenn Sie Integrationen später ausliefern, definieren Sie stabile Primitive jetzt:
- API‑Endpoints für Ticket create, update, search, plus Kommentare/Nachrichten und Statusänderungen.
- Webhooks für Schlüsselereignisse (ticket.created, ticket.updated, message.received, sla.breached), damit externe Systeme reagieren können.
Halten Sie die Authentifizierung vorhersehbar (API‑Keys für Server; OAuth für Benutzerinstallationen) und versionieren Sie die API, um Breaking‑Changes zu vermeiden.
Duplikate vermeiden mit solidem E‑Mail‑Threading
E‑Mail bringt die meisten Edge‑Cases an den Tag. Planen Sie, wie Sie:
- Antworten threaden mit Message‑ID / In‑Reply‑To / References‑Headern
- Weitergeleitete Nachrichten und gängige Signaturen sicher parsen
- Duplikate erkennen, indem Sie wiederholte eingehende Payloads identifizieren (insbesondere von Mail‑Providern)
Eine kleine Investition hier verhindert „jede Antwort erzeugt ein neues Ticket“‑Desaster.
Anhänge sicher handhaben
Unterstützen Sie Anhänge, aber mit Schutzmechanismen: Dateityp/Größenlimits, sichere Speicherung und Hooks für Virus‑Scanning (oder einen Scanning‑Dienst). Ziehen Sie in Betracht, gefährliche Formate zu strippen und niemals untrusted HTML inline zu rendern.
Setup dokumentieren wie ein Produktfeature
Erstellen Sie eine kurze Integrationsanleitung: benötigte Zugangsdaten, Schritt‑für‑Schritt‑Konfiguration, Fehlerbehebung und Testschritte. Wenn Sie Docs pflegen, verlinken Sie zu Ihrem Integrations‑Hub unter /docs, damit Admins keine Entwicklerhilfe brauchen, um Systeme zu verbinden.
Analytics und Reporting für Support‑Performance hinzufügen
Analytics verwandelt Ihr Ticketing‑System von „einem Ort zum Arbeiten“ in „ein Werkzeug zur Verbesserung“. Entscheidend ist, die richtigen Ereignisse zu erfassen, ein paar konsistente Kennzahlen zu berechnen und sie verschiedenen Zielgruppen darzustellen, ohne sensible Daten offenzulegen.
Starten Sie mit einer Ereignis‑Trail (nicht nur dem aktuellen Ticketstatus)
Speichern Sie die Momente, die erklären, warum ein Ticket so aussieht, wie es aussieht. Mindestens sollten Sie tracken: Statuswechsel, Kunden‑ und Agentenantworten, Zuweisungen und Neu‑Zuweisungen, Prioritäts/Kategorie‑Änderungen und SLA‑Timer‑Ereignisse (Start/Stop, Pausen, Verstöße). Das erlaubt Fragen wie „Haben wir verletzt, weil wir unterbesetzt waren oder weil wir auf den Kunden gewartet haben?“ zu beantworten.
Halten Sie Events möglichst append‑only; das macht Audits und Reporting vertrauenswürdiger.
Dashboards für Teamleiter
Leads brauchen in der Regel operationale Ansichten, mit denen sie heute handeln können:
- Backlog nach Queue, Priorität und Kategorie
- Alternde Tickets (z. B. älteste offene, älteste wartend auf Kunde)
- SLA‑Risiko (Tickets, die wahrscheinlich in X Stunden verletzen)
- Agenten‑Workload (zugewiesene Anzahl, aktive Arbeit, Zeit seit letzter Aktualisierung)
Machen Sie Dashboards filterbar nach Zeitraum, Kanal und Team—ohne Manager in Tabellen zu zwingen.
Reports für Führungskräfte
Führungskräfte interessieren sich weniger für einzelne Tickets und mehr für Trends:
- Volumen nach Kategorie/Kanal, einschließlich Spitzenzeiten
- Trends zu Erstantwort‑ und Lösungszeiten (Median und 90. Perzentil)
- CSAT‑Trends (und Antwortrate, damit Scores nicht irreführend sind)
Wenn Sie Ergebnisse Kategorien zuordnen, können Sie Personal, Training oder Produkt‑Fixes begründen.
Filter, Exporte und Zugriffskontrollen
Fügen Sie CSV‑Export für gängige Ansichten hinzu, schränken Sie ihn aber mit Berechtigungen ein (und idealerweise Feld‑level Controls), um E‑Mails, Nachrichteninhalte oder Kundenidentifikatoren nicht versehentlich offenzulegen. Protokollieren Sie, wer was wann exportiert hat.
Datenaufbewahrung ohne riskante Versprechen
Definieren Sie, wie lange Sie Ticket‑Ereignisse, Nachrichteninhalte, Anhänge und Analytics‑Aggregates aufbewahren. Bevorzugen Sie konfigurierbare Aufbewahrungseinstellungen und dokumentieren Sie klar, was tatsächlich gelöscht vs. anonymisiert wird, damit Sie keine Zusagen machen, die Sie nicht verifizieren können.
Eine praktikable Architektur und Tech‑Stack wählen
Ein Ticketing‑Produkt braucht keine komplexe Architektur, um effektiv zu sein. Für die meisten Teams ist ein einfacher Aufbau schneller zu liefern, leichter zu warten und skaliert trotzdem gut.
Beginnen Sie mit einem übersichtlichen Systemdiagramm
Eine praktische Basis sieht so aus:
- Web‑Frontend: Agenten/Admin‑UI plus kundenorientierte Formulare und Portal
- API‑Backend: Geschäftsregeln für Tickets, SLAs, Nutzer und Wissensdatenbank
- Datenbank: Quelle der Wahrheit für Tickets, Nutzer, Ereignisse und Einstellungen
- Background‑Jobs: alles Zeit‑ oder langlaufende
Dieser „modulare Monolith“‑Ansatz (ein Backend, klare Module) hält v1 überschaubar und lässt Raum, Services später zu trennen.
Wenn Sie eine v1 beschleunigen wollen, kann eine Vibe‑Coding‑Plattform wie Koder.ai helfen, das Agenten‑Dashboard, den Ticket‑Lebenszyklus und Admin‑Screens per Chat zu prototypisieren—und den Quellcode zu exportieren, wenn Sie volle Kontrolle übernehmen wollen.
Wissen, was im Hintergrund laufen muss
Ticketing‑Systeme wirken in Echtzeit, aber viel Arbeit ist asynchron. Planen Sie Hintergrundjobs früh für:
- SLA‑Timer und Eskalationen (z. B. „erste Antwort fällig in 30 Minuten“)
- Benachrichtigungen (E‑Mail, In‑App, Webhooks)
- Suchindexierung (Tickets und KB‑Artikel)
- Inbound‑E‑Mail‑Verarbeitung (Parsing, Anhänge, Threading)
Wenn Hintergrundverarbeitung eine Nebensache ist, werden SLAs unzuverlässig und Agenten verlieren Vertrauen.
Daten korrekt speichern, für Geschwindigkeit suchen
Nutzen Sie eine relationale Datenbank (PostgreSQL/MySQL) für Kerndaten: Tickets, Kommentare, Status, Zuweisungen, SLA‑Policies und eine Audit/Ereignis‑Tabelle.
Für schnelle Suche und Relevanz behalten Sie einen separaten Suchindex (Elasticsearch/OpenSearch oder managed Pendant). Versuchen Sie nicht, Ihre relationale DB auf Skala für Full‑Text‑Suche zu nutzen, wenn Ihr Produkt davon abhängt.
Build vs. Buy entscheiden (und warum)
Drei Bereiche sparen oft Monate, wenn sie gekauft werden:
- Authentifizierung: bewährter Anbieter (SSO, MFA, Password‑Policies)
- E‑Mail‑Zustellung: transactional Email Service für Deliverability und Bounce‑Handling
- Suche: managed Search, wenn intern keine Expertise vorliegt
Bauen Sie die Dinge, die Sie differenzieren: Workflow‑Regeln, SLA‑Verhalten, Routing‑Logik und die Agenten‑Erfahrung.
Meilensteine mit klarer v1‑Liste planen
Schätzen Sie Aufwand nach Meilensteinen, nicht nach Features. Eine solide v1‑Meilensteinliste ist: Ticket CRUD + Kommentare, Basiszuweisung, SLA‑Timer (Kern), E‑Mail‑Benachrichtigungen, minimales Reporting. Halten Sie „Nice‑to‑haves“ (erweiterte Automatisierung, komplexe Rollen, tiefgehende Analytics) bewusst außerhalb des Scopes bis v1‑Nutzung zeigt, was wirklich zählt.
Sicherheits‑, Datenschutz‑ und Zuverlässigkeitsgrundlagen abdecken
Plane zuerst den Workflow
Nutze den Planungsmodus, um Zustände, Felder und SLAs zu skizzieren, bevor du Code generierst.
Sicherheits‑ und Zuverlässigkeitsentscheidungen sind am einfachsten (und günstigsten), wenn Sie sie früh integrieren. Eine Support‑App verarbeitet sensible Konversationen, Anhänge und Kontodaten—behandeln Sie sie also wie ein Kernsystem, nicht als Nebenwerkzeug.
Kundendaten standardmäßig schützen
Starten Sie mit Verschlüsselung in Transit überall (HTTPS/TLS), inklusive interner Service‑zu‑Service‑Calls, falls Sie mehrere Services haben. Für ruhende Daten verschlüsseln Sie Datenbanken und Objektspeicher (Anhänge) und lagern Secrets in einem verwalteten Vault.
Nutzen Sie Least‑Privilege‑Zugriff: Agenten sehen nur die Tickets, die sie bearbeiten dürfen, und Admins haben erhöhte Rechte nur bei Bedarf. Fügen Sie Zugrifflogs hinzu, damit Sie „wer hat was wann angesehen/exportiert?“ beantworten können, ohne zu raten.
Authentifizierung passend zur Zielgruppe wählen
Authentifizierung ist nicht One‑Size‑Fits‑All. Für kleine Teams reicht E‑Mail + Passwort. Für größere Kunden kann SSO (SAML/OIDC) erforderlich sein. Für leichte Kundenportale reduzieren Magic‑Links die Reibung.
Egal was Sie wählen, sorgen Sie für sichere Sessions (kurzlebige Tokens, Refresh‑Strategie, Secure Cookies) und fügen Sie MFA für Admin‑Accounts hinzu.
Häufige Angriffe im Vorfeld verhindern
Setzen Sie Rate‑Limiting auf Login, Ticket‑Erstellung und Suche‑Endpoints, um Brute‑Force und Spam zu drosseln. Validieren und sanitizen Sie Eingaben, um Injection‑Issues und unsicheres HTML in Kommentaren zu verhindern.
Bei Cookies: CSRF‑Schutz. Für APIs: strikte CORS‑Regeln. Für File‑Uploads: Malware‑Scan und Einschränkungen bei Dateitypen/-größen.
Backups, Recovery und messbare Ziele
Definieren Sie RPO/RTO‑Ziele (wie viel Datenverlust tolerierbar ist, wie schnell Sie wiederherstellen müssen). Automatisieren Sie Backups für DBs und File‑Storage und—wichtig—testen Sie Wiederherstellungen regelmäßig. Ein Backup, das sich nicht wiederherstellen lässt, ist kein Backup.
Datenschutz‑Basics, die Ihre Nutzer fragen werden
Support‑Apps unterliegen häufig Datenschutzanfragen. Bieten Sie Wege an, Kundendaten zu exportieren und zu löschen, und dokumentieren Sie, was entfernt vs. aus rechtlichen Gründen aufbewahrt wird. Halten Sie Audit‑Trails und Zugrifflogs für Admins bereit (siehe /security), damit Sie Vorfälle schnell untersuchen können.
Testen, starten und mit echten Support‑Teams iterieren
Eine Kunden‑Support‑Web‑App zu liefern ist nicht das Ende—es ist der Beginn, zu lernen, wie echte Agenten unter realem Druck arbeiten. Ziel von Tests und Rollout ist, den täglichen Betrieb zu schützen, während Sie validieren, dass Ihr Ticketing‑System und SLA‑Management korrekt funktionieren.
End‑to‑End‑Testszenarien schreiben, die echte Arbeit abbilden
Neben Unit‑Tests dokumentieren (und automatisieren, wo möglich) Sie eine kleine Menge E2E‑Szenarien, die Ihre riskantesten Flows abbilden:
- Ticket‑Erstellung: E‑Mail/Webformular/API‑Intake erstellt ein Ticket mit richtigen Feldern, Kundenidentität und initialem Status.
- Antworten und Threading: Kundenantworten hängen am richtigen Ticket, Agentenantworten benachrichtigen den Kunden, interne Notizen bleiben intern.
- SLA‑Verstöße: Timer starten/stoppen korrekt (z. B. Pause bei „Warten auf Kunde“), Verstöße triggern die richtige Eskalation und das Audit‑Trail protokolliert alles.
- Wissensdatenbank‑Suche: Agenten finden schnell relevante Artikel aus der Ticket‑Ansicht, und Kunden sehen Vorschläge vor der Einreichung.
Wenn Sie eine Staging‑Umgebung haben, füllen Sie sie mit realistischen Daten (Kunden, Tags, Queues, Geschäftszeiten), damit Tests nicht nur „theoretisch“ bestehen.
Pilot laufen lassen und wöchentlich Feedback sammeln
Starten Sie mit einer kleinen Support‑Gruppe (oder einer Queue) für 2–4 Wochen. Etablieren Sie ein wöchentliches Feedback‑Ritual: 30 Minuten, um zu besprechen, was gebremst hat, was Kunden verwirrt hat und welche Regeln Überraschungen verursacht haben.
Halten Sie Feedback strukturiert: „Welche Aufgabe?“, „Was haben Sie erwartet?“, „Was ist passiert?“ und „Wie oft tritt das auf?“. So priorisieren Sie Fixes, die Durchsatz und SLA‑Einhaltung wirklich verbessern.
Onboarding‑Checklist für Admins und Agenten erstellen
Machen Sie Onboarding reproduzierbar, damit der Rollout nicht von einer einzigen Person abhängt.
Einschließlich Essentials wie: Einloggen, Queue‑Ansichten, Antwort vs. interne Notiz, Zuweisen/Erwähnen, Status ändern, Makros nutzen, SLA‑Indikatoren lesen und KB‑Artikel finden/erstellen. Für Admins: Rollenverwaltung, Geschäftszeiten, Tags, Automatisierungen und Reporting‑Basics.
Gestaffelten Rollout planen (mit Rückroll‑Option)
Rollen Sie nach Team, Kanal oder Ticket‑Typ aus. Definieren Sie einen Rückroll‑Plan im Voraus: Wie stellen Sie Intake temporär zurück, welche Daten müssen eventuell re‑syncen und wer trifft die Entscheidung.
Teams, die auf Koder.ai bauen, nutzen häufig Snapshots und Rollback in frühen Piloten, um Workflows (Queues, SLAs, Portal‑Formulare) sicher zu iterieren, ohne den Live‑Betrieb zu stören.
Iterations‑Roadmap setzen
Wenn der Pilot stabil ist, planen Sie Verbesserungen in Wellen:
- Bessere Automatisierungsregeln (Makros, Trigger, Auto‑Tagging)
- Erweitertes Routing (Skills‑basierte Zuweisung, Load‑Balancing)
- Reichere KB‑Workflows (Artikel‑Reviews, Feedback‑Schleifen, Deflection‑Metriken)
Behandeln Sie jede Welle wie ein kleines Release: testen, pilotieren, messen, dann ausrollen.