19. Mai 2025·8 Min
Web‑App zur Analyse von Kündigungen erstellen und Retention testen
Lernen Sie, wie Sie eine Web‑App planen, bauen und starten, die Abonnementkündigungen erfasst, Treiber analysiert und Retentions‑Experimente sicher durchführt.
Was Sie bauen und warum es wichtig ist
Kündigungen sind einer der aussagekräftigsten Momente in einem Abonnementgeschäft. Ein Kunde sagt Ihnen explizit: „das ist das nicht mehr wert“, oft direkt nachdem er auf Reibung, Enttäuschung oder ein Preis/Wert‑Missverhältnis gestoßen ist. Wenn Sie Kündigung nur als einfachen Statuswechsel behandeln, verlieren Sie eine seltene Chance zu lernen, was schiefläuft — und es zu beheben.
Das Problem, das Sie lösen
Die meisten Teams sehen Churn nur als monatliche Zahl. Das verschleiert die Geschichte:
- Wer kündigt (neue Nutzer vs. Langzeitkunden, Tariftyp, Segment)
- Wann sie kündigen (Tag 1, nach der Probezeit, nach einer Preiserhöhung, nach fehlgeschlagener Zahlung)
- Warum sie kündigen (zu teuer, fehlende Funktionen, Bugs, Wechsel zu Konkurrenz, „nutze es nicht“)
Das ist es, was Analyse von Abonnementkündigungen in der Praxis bedeutet: einen Klick auf „Kündigen“ in strukturierte Daten zu verwandeln, denen Sie vertrauen und die Sie aufschlüsseln können.
Was „Retention‑Experimente“ bedeuten
Sobald Sie Muster sehen, können Sie Änderungen testen, die den Churn reduzieren — ohne zu raten. Retention‑Experimente können Produkt‑, Preis‑ oder Messaging‑Änderungen sein, zum Beispiel:
- Verbesserung des Kündigungsflusses (klarere Optionen, bessere Downgrade‑Pfad)
- Angebot einer Pause oder eines Rabatts für das richtige Segment
- Beheben von Onboarding‑Lücken, die mit frühen Kündigungen korrelieren
Der Schlüssel ist die Messung des Impacts mit sauberen, vergleichbaren Daten (z. B. ein A/B‑Test).
Was Sie in diesem Leitfaden bauen
Sie bauen ein kleines System mit drei verbundenen Teilen:
- Tracking: Ereignisse rund um den Abonnement‑Lebenszyklus und den Kündigungsfluss, einschließlich Gründe.
- Ein Dashboard: Funnels, Kohorten und Segmente, die zeigen, wo der Churn herkommt.
- Eine Experiment‑Schleife: die Fähigkeit, gezielte Tests durchzuführen und zu sehen, ob der Churn tatsächlich sinkt.
Am Ende haben Sie einen Workflow, der von „wir hatten mehr Kündigungen“ zu „dieses spezifische Segment kündigt nach Woche 2 wegen X — und diese Änderung reduzierte den Churn um Y%“ führt.
Woran Erfolg zu erkennen ist
Erfolg ist nicht nur ein hübscheres Diagramm — es sind Geschwindigkeit und Sicherheit:
- Schnellere Erkenntnisse (Tage, nicht Monate)
- Messbare Churn‑Reduktion, die an spezifische Änderungen gebunden ist
- Wiederholbares Lernen: jede Kündigung lehrt Sie etwas, worauf Sie reagieren können
Ziele, Metriken und Scope für das MVP festlegen
Bevor Sie Bildschirme, Tracking oder Dashboards bauen, klären Sie schmerzhaft genau, welche Entscheidungen dieses MVP ermöglichen soll. Eine App für Kündigungsanalyse ist dann erfolgreich, wenn sie ein paar handlungsrelevante Fragen schnell beantwortet — nicht wenn sie versucht, alles zu messen.
Starten Sie mit den Fragen, die zu Maßnahmen führen
Schreiben Sie die Fragen auf, die Sie in der ersten Version beantworten möchten. Gute MVP‑Fragen sind spezifisch und führen zu offensichtlichen nächsten Schritten, z. B.:
- Was sind die wichtigsten Kündigungsgründe und wie unterscheiden sie sich nach Tarif, Region oder Anmeldekanal?
- Wie lange dauert es, bis Kunden kündigen (time‑to‑cancel) und welche Muster zeigen sich in den ersten 7/30/90 Tagen?
- Welche Tarife (oder Abrechnungszyklen) haben die höchste Kündigungsrate, und downgraden Benutzer vor der Kündigung?
Wenn eine Frage keine Produktänderung, Support‑Playbook oder Experiment beeinflusst, parken Sie sie für später.
Wählen Sie 3–5 „North‑Star“‑MVP‑Metriken
Wählen Sie eine kurze Liste, die Sie wöchentlich überprüfen. Halten Sie Definitionen eindeutig, damit Produkt, Support und Führung dieselben Zahlen meinen.
Typische Anfangsmetriken:
- Kündigungsrate (über einen definierten Zeitraum, z. B. wöchentlich/monatlich)
- Save‑Rate (Anteil der Kündigungsversuche, die zu einem erhaltenen Outcome führen)
- Reaktivierungsrate (Kunden, die nach der Kündigung zurückkehren)
- Time‑to‑cancel (medianer Tageabstand vom Start bis zur Kündigung)
- Verteilung der Gründe (Top‑Gründe nach Volumen und nach Umsatz‑Impact)
Dokumentieren Sie für jede Metrik die genaue Formel, das Zeitfenster und Ausschlüsse (Proben, Rückerstattungen, fehlgeschlagene Zahlungen).
Benennen Sie Verantwortliche und Grenzen
Identifizieren Sie, wer das System nutzen und pflegen wird: Produkt (Entscheidungen), Support/Success (Qualität der Gründe und Nachverfolgung), Data (Definitionen und Validierung) und Engineering (Instrumentation und Zuverlässigkeit).
Stimmen Sie dann die Grenzen ab: Datenschutzanforderungen (Minimierung von PII, Aufbewahrungsfristen), erforderliche Integrationen (Billing‑Provider, CRM, Support‑Tool), Zeitplan und Budget.
Schreiben Sie einen einseitigen Scope, um Feature Creep zu stoppen
Halten Sie es kurz: Ziele, Hauptnutzer, die 3–5 Metriken, „Must‑have“‑Integrationen und eine klare Non‑Goals‑Liste (z. B. „kein vollständiges BI‑Suite“, „keine Multi‑Touch‑Attribution in v1“). Diese Seite wird Ihr MVP‑Vertrag, wenn neue Anfragen auftauchen.
Modellieren Sie Abonnements und Lifecycle‑Ereignisse
Bevor Sie Kündigungen analysieren können, brauchen Sie ein Abonnementmodell, das widerspiegelt, wie Kunden tatsächlich durch Ihr Produkt wandern. Wenn Ihre Daten nur den aktuellen Abo‑Status speichern, werden Sie Schwierigkeiten haben, grundlegende Fragen zu beantworten wie „Wie lange waren sie aktiv bevor sie kündigten?“ oder „Sagten Downgrades den Churn voraus?"
Kartieren Sie den Lifecycle, den Sie messen wollen
Starten Sie mit einer einfachen, expliziten Lifecycle‑Karte, auf die sich Ihr ganzes Team einigt:
Trial → Active → Downgrade → Cancel → Win‑back
Sie können später weitere Zustände hinzufügen, aber diese Grundkette zwingt zur Klarheit darüber, was als „aktiv“ zählt (bezahlt? innerhalb einer Nachfrist?) und was als „Win‑back“ zählt (reaktiviert innerhalb von 30 Tagen? jederzeit?).
Definieren Sie die Kernelemente
Modellieren Sie mindestens diese Entitäten, damit Ereignisse und Geld konsistent zugeordnet werden können:
- User: die Person, die die App nutzt (kann sich im Laufe der Zeit ändern)
- Account: der Billing/Customer‑Container (oft die richtige Einheit für Churn)
- Subscription: die Vereinbarung, die starten, erneuern, wechseln oder enden kann
- Plan: die Produktstufe (Name, Preis, Abrechnungsintervall)
- Invoice: was berechnet wurde, wann, und ob es bezahlt/erstattet wurde
- Cancel event: wann die Kündigung angefragt wurde und wann sie wirksam wurde
Wählen Sie stabile Identifier (account_id vs user_id)
Für Churn‑Analytics ist account_id in der Regel der sicherste primäre Identifier, weil Nutzer wechseln können (Mitarbeiter gehen, Admins wechseln). Sie können Aktionen weiterhin auf user_id attribuieren, aber aggregieren Sie Retention und Kündigungen auf Account‑Ebene, es sei denn, Sie verkaufen wirklich persönliche Abonnements.
Speichern Sie Status‑Historie, nicht nur einen Status
Implementieren Sie eine Status‑Historie (effective_from/effective_to), damit Sie vergangene Zustände zuverlässig abfragen können. Das macht Kohortenanalyse und Analyse von Verhalten vor der Kündigung möglich.
Planen Sie Edge‑Cases im Voraus
Modellieren Sie diese explizit, damit sie die Churn‑Zahlen nicht verschmutzen:
- Pausen (vorübergehendes Stoppen ohne Kündigung)
- Rückerstattungen/Chargebacks (Zahlungsrücknahme vs. freiwilliger Churn)
- Planwechsel (Upgrade/Downgrade als Ereignisse, nicht als „neues Abonnement“)
- Grace‑Periods (fehlgeschlagene Zahlung vs. echte Kündigung)
Instrumentieren Sie den Kündigungsfluss (Ereignisse und Gründe)
Wenn Sie Churn verstehen (und Retention verbessern) wollen, ist der Kündigungsfluss Ihr wertvollster „Moment der Wahrheit“. Instrumentieren Sie ihn wie eine Produkt‑Surface, nicht wie ein Formular — jeder Schritt sollte klare, vergleichbare Ereignisse erzeugen.
Verfolgen Sie die wichtigsten Schritte (und machen Sie sie unverzichtbar)
Erfassen Sie mindestens eine saubere Sequenz, damit Sie später einen Funnel bauen können:
cancel_started— Nutzer öffnet das Kündigungserlebnisoffer_shown— ein Save‑Angebot, Pause‑Option, Downgrade‑Pfad oder „Kontakt zum Support“ CTA wird angezeigtoffer_accepted— Nutzer nimmt ein Angebot an (Pause, Rabatt, Downgrade)cancel_submitted— Kündigung bestätigt
Diese Ereignisnamen sollten über Web/Mobile hinweg konsistent und langfristig stabil sein. Wenn Sie die Payload weiterentwickeln, erhöhen Sie die Schema‑Version (z. B. schema_version: 2) statt Bedeutungen stillschweigend zu ändern.
Erfassen Sie Kontext, der erklärt warum es passiert ist
Jedes kündigungsbezogene Ereignis sollte dieselben Kernkontextfelder enthalten, damit Sie ohne Rätselraten segmentieren können:
- Plan, Laufzeit, Preis
- Land, Gerät
- Akquisitionskanal
Speichern Sie diese als Eigenschaften auf dem Ereignis (nicht später abgeleitet), um gebrochene Attribution zu vermeiden, wenn andere Systeme sich ändern.
Sammeln Sie Kündigungsgründe, die Sie analysieren und lesen können
Verwenden Sie eine vordefinierte Grundliste (für Charts) plus optional Freitext (für Nuancen).
cancel_reason_code(z. B.too_expensive,missing_feature,switched_competitor)cancel_reason_text(optional)
Speichern Sie den Grund auf cancel_submitted und erwägen Sie, ihn auch zu loggen, wenn er zuerst ausgewählt wird (hilft, Unentschlossenheit oder Hin‑und‑Her‑Verhalten zu erkennen).
Hören Sie nicht bei der Kündigung auf: verfolgen Sie Outcomes
Um Retention‑Interventionen zu messen, loggen Sie nachgelagerte Outcomes:
reactivateddowngradedsupport_ticket_opened
Mit diesen Ereignissen können Sie Kündigungsintentionen mit Ergebnissen verbinden — und Experimente durchführen, ohne über die wahre Bedeutung der Daten zu streiten.
Entwerfen Sie Ihre Datenpipeline und Speicherung
Gute Churn‑Analytics beginnt mit langweiligen Entscheidungen, die gut getroffen wurden: wo Ereignisse leben, wie sie bereinigt werden und wie alle vereinbaren, was „eine Kündigung“ bedeutet.
Wählen Sie Speicherung: OLTP + (optional) Warehouse
Für die meisten MVPs speichern Sie Roh‑Tracking‑Ereignisse zuerst in Ihrer primären App‑Datenbank (OLTP). Das ist einfach, transaktional und leicht für Debugging abzufragen.
Wenn Sie hohes Volumen oder schwere Reports erwarten, fügen Sie später ein Analytics‑Warehouse hinzu (Postgres Read Replica, BigQuery, Snowflake, ClickHouse). Ein übliches Muster ist: OLTP als „Source of Truth“ + Warehouse für schnelle Dashboards.
Kern‑Tabellen, die Sie brauchen werden
Entwerfen Sie Tabellen um „was passiert ist“ statt um „was Sie denken, dass Sie brauchen“. Eine minimale Menge:
events: eine Zeile pro getracktem Ereignis (z. B.cancel_started,offer_shown,cancel_submitted) mituser_id,subscription_id, Zeitstempeln und JSON‑Eigenschaften.cancellation_reasons: normalisierte Zeilen für Grundauswahlen, inklusive optionaler Freitext‑Feedbacks.experiment_exposures: wer welche Variante wann und in welchem Kontext gesehen hat (Feature Flag / Testname).
Diese Trennung hält Ihre Analytics flexibel: Sie können Gründe und Experimente an Kündigungen joinen, ohne Daten zu duplizieren.
Späte Ereignisse, Duplikate und Idempotenz
Kündigungsflüsse erzeugen Retries (Zurück‑Button, Netzprobleme, Refresh). Fügen Sie einen idempotency_key (oder event_id) hinzu und erzwingen Sie Einzigartigkeit, damit dasselbe Ereignis nicht doppelt gezählt wird.
Entscheiden Sie außerdem eine Policy für späte Ereignisse (Mobile/Offline): in der Regel akzeptieren, aber verwenden Sie den ursprünglichen Event‑Timestamp für Analysen und die Ingestionszeit für Debugging.
ETL/ELT für Reporting‑Performance
Auch ohne komplettes Warehouse bauen Sie einen leichten Job, der „Reporting‑Tabellen“ (tägliche Aggregate, Funnel‑Steps, Kohorten‑Snapshots) erstellt. Das hält Dashboards schnell und reduziert teure Joins auf Roh‑Ereignissen.
Dokumentieren Sie Definitionen, damit Metriken übereinstimmen
Schreiben Sie ein kurzes Data‑Dictionary: Ereignisnamen, erforderliche Eigenschaften und Metrikformeln (z. B. „Churn‑Rate verwendet cancel_effective_at“). Legen Sie es in Ihr Repo oder interne Docs, damit Produkt, Data und Engineering Charts gleich interpretieren.
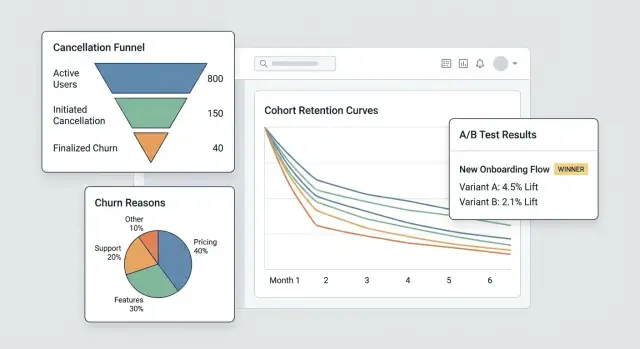
Bauen Sie das Dashboard: Funnels, Kohorten und Segmente
Auf deiner Domain veröffentlichen
Stelle das interne Dashboard auf einer eigenen Domain bereit, um es leichter mit Teams zu teilen.
Ein gutes Dashboard versucht nicht, alle Fragen auf einmal zu beantworten. Es sollte Ihnen erlauben, von „etwas sieht falsch aus“ zu „hier ist die genaue Gruppe und der Schritt, der es verursacht“ in ein paar Klicks zu kommen.
Kernansichten, die Sie jede Woche nutzen werden
Starten Sie mit drei Ansichten, die widerspiegeln, wie Menschen tatsächlich Churn untersuchen:
- Kündigungs‑Funnel: von
cancel_started→ Grund ausgewählt →offer_shown→offer_acceptedodercancel_submitted. Das zeigt, wo Leute aussteigen und wo Ihr Save‑Flow (nicht) wirkt. - Verteilung der Gründe: Aufschlüsselung der ausgewählten Kündigungsgründe mit einem „Andere (Freitext)“‑Bucket, der gesampelt werden kann. Zeigen Sie sowohl Counts als auch %‑Anteile, damit Spitzen auffallen.
- Kohorten nach Startmonat: Retention‑ oder Kündigungsrate nach Monat des Abonnementstarts. Kohorten machen es schwerer, sich mit Saisonalität oder Akquisitionsmix zu täuschen.
Segmente, die Erkenntnisse handlungsfähig machen
Jedes Diagramm sollte nach Attributen filterbar sein, die Churn und Save‑Akzeptanz beeinflussen:
- Tarif oder Stufe
- Laufzeit (z. B. 0–7 Tage, 8–30, 31–90, 90+)
- Region / Land
- Akquisitionsquelle (organic, paid, partner, sales)
- Zahlungsmethode (Karte, Rechnung, PayPal usw.)
Halten Sie die Standardansicht „Alle Kunden“, aber denken Sie daran: Ziel ist es, welches Segment sich verändert zu finden, nicht nur ob Churn sich bewegt.
Zeitsteuerung und Performance des Save‑Flows
Fügen Sie schnelle Datums‑Presets (letzte 7/30/90 Tage) sowie einen Custom‑Range hinzu. Verwenden Sie dieselbe Zeitsteuerung über alle Ansichten, um unpassende Vergleiche zu vermeiden.
Für Retention‑Arbeit verfolgen Sie den Save‑Flow als Mini‑Funnel mit Business‑Impact:
- Offer‑Views
- Offer‑Akzeptanzrate
- Net retained MRR (MRR, das nach Rabatten, Gutschriften oder Downgrades erhalten bleibt)
Drill‑Down ohne Vertrauen zu brechen
Jedes aggregierte Diagramm sollte einen Drill‑Down auf eine Liste betroffener Accounts ermöglichen (z. B. „Kunden, die ‚Zu teuer‘ auswählten und innerhalb von 14 Tagen kündigten“). Fügen Sie Spalten wie Tarif, Laufzeit und letzte Rechnung hinzu.
Sperren Sie Drill‑Down hinter Berechtigungen (rollenbasierter Zugriff) und erwägen Sie, sensible Felder standardmäßig zu maskieren. Das Dashboard soll Investigieren ermöglichen und gleichzeitig Privatsphäre und interne Zugriffsregeln respektieren.
Fügen Sie ein Experiment‑Framework hinzu (A/B‑Tests und Targeting)
Wenn Sie Kündigungen reduzieren wollen, brauchen Sie eine verlässliche Methode, Änderungen (Copy, Angebote, Timing, UI) zu testen, ohne aus Meinungen argumentieren zu müssen. Ein Experiment‑Framework ist die „Verkehrsregel“, die entscheidet, wer was sieht, es aufzeichnet und Outcomes einer Variante zuordnet.
1) Definieren Sie die Experiment‑Einheit (Cross‑Kontamination vermeiden)
Entscheiden Sie, ob die Zuordnung auf Account‑ oder User‑Ebene passiert.
- Account‑Level ist für SaaS in der Regel am sichersten: Jeder im gleichen Workspace sieht dieselbe Variante und verhindert gemischte Botschaften und kontaminierte Ergebnisse.
- User‑Level kann für Consumer‑Apps funktionieren, aber achten Sie auf geteilte Geräte, mehrere Logins oder Team‑Accounts.
Schreiben Sie diese Wahl für jedes Experiment auf, damit Ihre Analyse konsistent ist.
2) Wählen Sie eine Zuweisungsmethode
Unterstützen Sie ein paar Targeting‑Modi:
- Random (klassisches A/B): guter Default.
- Weighted (z. B. 90/10): nützlich für vorsichtige Rollouts.
- Rules‑based Targeting: zeigt eine Variante nur bestimmten Segmenten (Tarif, Land, Laufzeit, „kurz vor Kündigung“). Halten Sie Regeln einfach und versioniert.
3) Loggen Sie Exposure, wenn sie tatsächlich passiert
Zählen Sie nicht „assigned“ als „exposed“. Loggen Sie Exposure, wenn der Nutzer die Variante wirklich sieht (z. B. Kündigungsseite gerendert, Angebotsmodal geöffnet). Speichern Sie: experiment_id, variant_id, Unit‑ID (Account/User), Timestamp und relevanten Kontext (Plan, Sitzanzahl).
4) Definieren Sie Metriken: Primär + Guardrails
Wählen Sie eine primäre Erfolgsmetrik, z. B. Save‑Rate (cancel_started → retained outcome). Fügen Sie Guardrails hinzu, um schädliche Wins zu verhindern: Support‑Kontakte, Rückerstattungsanfragen, Beschwerderate, Time‑to‑cancel oder Downgrade‑Churn.
5) Planen Sie Dauer und Stichprobengröße
Entscheiden Sie vor dem Launch:
- Mindestlaufzeit (oft 1–2 Abrechnungszyklen für Abonnementverhalten)
- Minimale Stichprobengröße basierend auf aktueller Save‑Rate und der kleinsten Verbesserung, die Ihnen wichtig ist
Das verhindert frühes Abbrechen bei verrauschten Daten und hilft dem Dashboard zu zeigen, ob „noch gelernt wird“ oder ob Daten statistisch aussagekräftig sind.
Entwerfen Sie Retention‑Interventionen zum Testen
Auf Mobile erweitern
Erstelle eine Flutter-Begleit-App, damit Support- oder Success-Teams den Kündigungskontext einsehen können.
Retention‑Interventionen sind die Dinge, die Sie während der Kündigung zeigen oder anbieten, die die Entscheidung eines Nutzers ändern könnten — ohne dass er sich manipuliert fühlt. Ziel ist es herauszufinden, welche Optionen Churn reduzieren und gleichzeitig Vertrauen erhalten.
Übliche Interventionsvarianten zum Ausprobieren
Starten Sie mit einem kleinen Musterkatalog, den Sie kombinieren können:
- Alternative Angebote: zeitlich begrenzter Rabatt, ein freier Monat oder verlängerte Trial
- Pause‑Option: Nutzer für 1–3 Monate von der Abrechnung aussetzen (mit klaren Erwartungen zur Reaktivierung)
- Tarif‑Downgrade: Wechsel zu einer günstigeren Stufe oder weniger Sitzen statt kompletter Kündigung
- Message‑Copy: kurze, spezifische Copy, die an den Wert erinnert („Exportieren Sie Ihre Daten jederzeit“) vs. generische Copy („Schade, dass Sie gehen“)
Angebote gestalten, die Nutzer nicht fangen
Machen Sie jede Wahl klar und reversibel, wenn möglich. Der „Kündigen“‑Pfad sollte sichtbar sein und keine Schatzsuche erfordern. Wenn Sie einen Rabatt anbieten, sagen Sie genau, wie lange er gültig ist und wie der Preis danach wieder aussieht. Wenn Sie Pause anbieten, zeigen Sie, was mit Zugang und Abrechnungsdaten passiert.
Eine gute Regel: Ein Nutzer sollte in einem Satz erklären können, was er ausgewählt hat.
Progressive Disclosure verwenden
Halten Sie den Flow leicht:
-
Nach einem Grund fragen (ein Tap)
-
Eine zugeschnittene Antwort zeigen (Pause bei „zu teuer“, Downgrade bei „nutze zu wenig“, Support bei „Bugs“)
-
Endgültiges Ergebnis bestätigen (Pause/Downgrade/Kündigung)
Das reduziert Reibung und hält das Erlebnis relevant.
Ergebnisseite und Changelog hinzufügen
Erstellen Sie eine interne Experiment‑Ergebnisseite, die zeigt: Konversion zum „gespeicherten“ Outcome, Churn‑Rate, Lift vs. Control und entweder ein Konfidenzintervall oder einfache Entscheidungsregeln (z. B. „shippen, wenn Lift ≥ 3% und Sample ≥ 500").
Führen Sie ein Changelog der getesteten und live geschalteten Änderungen, damit zukünftige Tests nicht alte Ideen wiederholen und Sie Retention‑Verschiebungen mit konkreten Änderungen verbinden können.
Datenschutz, Sicherheit und Zugriffskontrolle
Kündigungsdaten gehören zu den sensibelsten Produktdaten: sie enthalten oft Billing‑Kontext, Identifikatoren und Freitext, der persönliche Informationen enthalten kann. Behandeln Sie Datenschutz und Sicherheit als Produktanforderungen, nicht als Nachgedanken.
Authentifizierung und Rollen
Starten Sie mit authentifiziertem Zugriff (idealerweise SSO). Fügen Sie dann einfache, explizite Rollen hinzu:
- Admin: Einstellungen, Datenaufbewahrung, Benutzerzugriff und Exporte verwalten.
- Analyst: Dashboards ansehen, Segmente erstellen, Experimente durchführen.
- Support: Kundenhistorie sehen, die zur Hilfe nötig ist (eingeschränkte Felder).
- Read‑only: aggregierte Dashboards ansehen ohne Drill‑Down.
Machen Sie Roll‑Checks serverseitig, nicht nur in der UI.
Minimieren Sie die Exposition sensibler Daten
Begrenzen Sie, wer Kunden‑Level‑Datensätze sehen kann. Bevorzugen Sie Aggregationen standardmäßig und setzten Sie Drill‑Down hinter stärkere Berechtigungen.
- Maskieren Sie Identifikatoren (E‑Mail, Kunden‑ID) in der UI, wo möglich.
- Hashen Sie Identifier für Joins und Deduplizierung (z. B. SHA‑256 mit geheimem Salt), damit Analysten segmentieren können, ohne rohe PII zu sehen.
- Trennen Sie „Billing/Identity“‑Tabellen von Event‑Analytics‑Tabellen, verbunden über einen gehashten Schlüssel.
Regeln zur Datenaufbewahrung
Definieren Sie Aufbewahrung im Voraus:
- Behalten Sie Ereignisdaten nur so lange, wie es für Kohortenanalyse nötig ist (z. B. 13–18 Monate).
- Wenden Sie kürzere Aufbewahrung oder Redaktion für Freitext‑Kündigungsgründe an, die versehentlich persönliche Infos enthalten können.
- Bieten Sie Lösch‑Workflows an, um Benutzeranfragen und interne Richtlinien zu erfüllen.
Audit‑Logs
Protokollieren Sie Dashboard‑Zugriffe und Exporte:
- Wer Kunden‑Level‑Seiten angesehen hat
- Wer Daten exportiert hat, wann und welche Filter verwendet wurden
- Admin‑Änderungen an Aufbewahrung und Berechtigungen
Sicherheits‑Checklist zum Launch
Decken Sie die Basics vor dem Shipping ab: OWASP‑Toprisiken (XSS/CSRF/Injection), TLS überall, Least‑Privilege DB‑Accounts, Secrets‑Management (keine Keys im Code), Rate‑Limiting auf Auth‑Endpunkten und getestete Backup/Restore‑Prozeduren.
Implementierungsplan (Frontend, Backend und Testing)
Dieser Abschnitt ordnet den Build in drei Teile — Backend, Frontend und Qualität — damit Sie ein MVP ausliefern, das konsistent, schnell genug für echten Gebrauch und sicher zu erweitern ist.
Backend: Abonnements, Ereignisse und Experimente
Starten Sie mit einer kleinen API, die CRUD für Subscriptions unterstützt (erstellen, Status updaten, pausieren/resumieren, kündigen) und wichtige Lifecycle‑Daten speichert. Halten Sie Write‑Paths einfach und validiert.
Fügen Sie als Nächstes einen Event‑Ingest‑Endpoint für Tracking von Aktionen wie „Kündigungsseite geöffnet“, „Grund ausgewählt“ und „Kündigung bestätigt“ hinzu. Bevorzugen Sie serverseitige Ingests (aus Ihrem Backend), um Ad‑Blocker und Manipulation zu reduzieren. Falls Sie Client‑Events akzeptieren müssen, signieren Sie Requests und setzen Sie Rate‑Limits.
Für Retention‑Experimente implementieren Sie die Experiment‑Zuweisung serverseitig, damit dasselbe Account immer dieselbe Variante erhält. Ein typisches Muster: eligible experiments abrufen → hash (account_id, experiment_id) → Variante zuweisen → Zuweisung persistieren.
Wenn Sie das schnell prototypen wollen, kann eine Plattform wie Koder.ai das Fundament (React‑Dashboard, Go‑Backend, PostgreSQL‑Schema) aus einer kurzen Spezifikation im Chat generieren — dann können Sie den Quellcode exportieren und Datenmodell, Event‑Contracts und Berechtigungen anpassen.
Frontend: Dashboard, Filter und Exporte
Bauen Sie eine Handvoll Dashboard‑Seiten: Funnels (cancel_started → offer_shown → cancel_submitted), Kohorten (nach Signup‑Monat) und Segmente (Tarif, Land, Akquisitionskanal). Halten Sie Filter auf allen Seiten konsistent.
Für kontrolliertes Teilen bieten Sie CSV‑Exporte mit Schutzmechanismen an: standardmäßig nur aggregierte Ergebnisse exportieren, zeilenweise Exporte nur mit erhöhten Rechten erlauben und Exporte für Auditing protokollieren.
Performance‑Basics
Nutzen Sie Paginierung für Ereignislisten, indexieren Sie gängige Filter (Datum, subscription_id, Plan) und fügen Sie Pre‑Aggregationen für schwere Charts hinzu (tägliche Counts, Kohorten‑Tabellen). Cachen Sie „letzte 30 Tage“‑Zusammenfassungen mit kurzer TTL.
Testing und Zuverlässigkeit
Schreiben Sie Unit‑Tests für Metrikdefinitionen (z. B. was als „Kündigung gestartet“ zählt) und für Zuweisungskonsistenz (dasselbe Konto landet immer in derselben Variante).
Für Ingestionsfehler implementieren Sie Retries und eine Dead‑Letter‑Queue, um stillen Datenverlust zu verhindern. Machen Sie Fehler in Logs und auf einer Admin‑Seite sichtbar, damit Sie Probleme beheben können, bevor sie Entscheidungen verzerren.
Deployen, überwachen und Daten vertrauenswürdig halten
MVP klar definieren
Nutze den Planungsmodus, um Metriken, Schemata und Verantwortliche festzulegen, bevor du Code schreibst.
Das Ausliefern Ihrer Kündigungsanalyse‑App ist nur die halbe Arbeit. Die andere Hälfte ist, sie akkurat zu halten, während Ihr Produkt und Ihre Experimente sich wöchentlich ändern.
Wählen Sie einen Deploy‑Ansatz
Wählen Sie die einfachste Option, die zum Betriebsteam passt:
- Managed Hosting (PaaS): schnellster Weg, wenn Sie eingebaute Deploys, Logs und Skalierung wollen.
- Container (Docker + Orchestrator): gut, wenn Sie reproduzierbare Builds und mehr Kontrolle über Abhängigkeiten brauchen.
- Serverless: gut für spitze Workloads (Event‑Ingestion, geplante Validierungsjobs), aber Achtung bei Cold‑Starts und Anbieterlimits.
Behandeln Sie die Analytics‑App wie ein Produktionssystem: versionieren Sie sie, automatisieren Sie Deploys und halten Sie Config in Umgebungsvariablen.
Wenn Sie die Pipeline nicht sofort vollständig betreiben wollen, kann Koder.ai auch Deployment und Hosting übernehmen (inkl. Custom Domains) und Snapshots/Rollbacks unterstützen — nützlich beim schnellen Iterieren an einem sensiblen Flow wie Kündigungen.
Getrennte Umgebungen (und Daten)
Richten Sie dev, staging und production mit klarer Isolation ein:
- Getrennte Datenbanken und Storage‑Buckets, damit Test‑Ereignisse Metriken nicht verunreinigen.
- Eine dedizierte Staging‑Umgebung, die Produktion in Schema und Routing spiegelt.
- Unterschiedliche Experiment‑Namespaces (z. B. Prefix der Experiment‑IDs in Non‑Prod), um „Phantom‑Varianten“ im Dashboard zu verhindern.
Monitoring, das Entscheidungen schützt
Sie überwachen nicht nur Uptime — Sie überwachen Wahrheit:
- Uptime/Health der API, Background‑Worker und des Dashboards.
- Ingestions‑Lag (Event‑Time vs. Processed‑Time) mit Alerts bei Drift.
- Experiment‑Zuweisungsfehler: plötzliche Anstiege in „unassigned units“, Varianten‑Imbalance oder sich ändernde Zuweisungen für dasselbe Konto.
Automatisierte Datenvalidierungsjobs
Planen Sie leichte Checks, die laut fehlschlagen:
- Fehlende Schlüssel‑Ereignisse (z. B.
cancel_startedohnecancel_submitted, wo erwartet). - Schema‑Änderungen (neue/entfernte Eigenschaften, Typänderungen, unerwartete Enums).
- Volumen‑Anomalien (Ereignisse fallen nach Release auf nahezu Null).
Rollback‑Plan für Experiment‑UI‑Änderungen
Für jedes Experiment, das den Kündigungsfluss berührt, planen Sie im Voraus einen Rollback:
- Feature‑Flags, um Varianten sofort zu deaktivieren.
- Schnellen Weg, das letzte bekannte gute Build neu zu deployen.
- Eine Notiz im Dashboard, die das Rollback‑Fenster markiert, damit Analysten die Daten nicht falsch interpretieren.
Den Betrieb: Von Erkenntnis zu fortlaufenden Experimenten
Eine Kündigungsanalyse‑App lohnt sich nur, wenn sie zur Gewohnheit wird, nicht zu einem einmaligen Report. Ziel ist, „wir haben Churn bemerkt“ in eine stetige Schleife aus Insight → Hypothese → Test → Entscheidung zu verwandeln.
Führen Sie einen einfachen wöchentlichen Rhythmus ein
Wählen Sie eine feste Zeit jede Woche (30–45 Minuten) und halten Sie das Ritual leicht:
- Dashboard auf Key‑Metriken prüfen (Gesamtchurn, Churn nach Tarif, Churn nach Laufzeit, Top‑Kündigungsgründe).
- Eine Anomalie benennen, die es lohnt zu untersuchen (z. B. Churn‑Spike bei jährlichen Renewals oder ein Grund, der plötzlich #1 wird).
- Genau eine Hypothese für die nächste Woche auswählen.
Eine Hypothese zwingt zur Klarheit: Was glauben wir, passiert, wer ist betroffen und welche Aktion könnte das Ergebnis ändern?
Priorisieren Sie Experimente (Impact × Aufwand)
Vermeiden Sie zu viele gleichzeitige Tests — besonders im Kündigungsfluss — weil überlappende Änderungen Ergebnisse schwer interpretierbar machen.
Verwenden Sie ein einfaches Raster:
- Hoher Impact / niedriger Aufwand: zuerst (Copy‑Änderungen, Routing zum Support, Angebot für Jahreswechsel).
- Hoher Impact / hoher Aufwand: planen (Abrechnungsflexibilität, Produktfixes).
- Niedriger Impact: parken.
Wenn Sie neu im Experimentieren sind, stimmen Sie Basics und Entscheidungsregeln vor dem Shipping ab: /blog/ab-testing-basics.
Schließen Sie den Kreis mit qualitativen Inputs
Zahlen sagen, was passiert; Support‑Notizen und Kündigungskommentare oft, warum. Sample jede Woche ein paar aktuelle Kündigungen pro Segment und fassen Sie Themen zusammen. Ordnen Sie dann Themen testbaren Interventionen zu.
Bauen Sie ein „Winning Interventions“‑Playbook
Tracken Sie Erkenntnisse über die Zeit: was funktionierte, für wen und unter welchen Bedingungen. Speichern Sie kurze Einträge wie:
- Segmentdefinition (Tarif, Laufzeit, Nutzung)
- Hypothese und Änderung, die veröffentlicht wurde
- Ergebnis und Vertrauen
- Folgeaktion (ausrollen, iterieren oder zurückziehen)
Wenn Sie Angebote standardisieren wollen (und ad‑hoc Rabatte vermeiden), verbinden Sie Ihr Playbook mit Packaging und Limits: /pricing.