21. Sept. 2025·8 Min
Meilisearch für sofortige serverseitige Suche in Ihren Apps
Erfahren Sie, wie Sie Meilisearch in Ihr Backend integrieren für schnelle, fehlertolerante Suche: Einrichtung, Indexierung, Ranking, Filter, Sicherheit und Skalierung.
Was eine sofortige serverseitige Suche liefern sollte
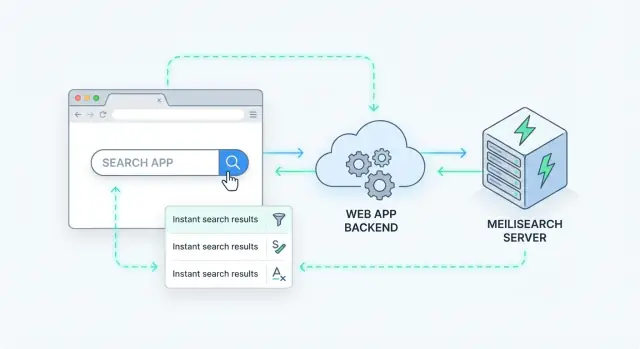
Serverseitige Suche bedeutet, dass die Anfrage auf Ihrem Server (oder einem dedizierten Suchdienst) verarbeitet wird, nicht im Browser. Ihre App sendet eine Suchanfrage, der Server führt sie gegen einen Index aus und gibt gerankte Ergebnisse zurück.
Das ist wichtig, wenn Ihr Dataset zu groß ist, um es an den Client zu schicken, wenn Sie konsistente Relevanz über Plattformen brauchen oder wenn Zugriffskontrolle nicht verhandelbar ist (z. B. interne Tools, bei denen Nutzer nur sehen dürfen, was ihnen erlaubt ist). Es ist außerdem die Standardwahl, wenn Sie Analytics, Logging und vorhersehbare Performance wollen.
Was Nutzer erwarten (und sofort bemerken)
Menschen denken nicht über Suchmaschinen nach—sie bewerten die Erfahrung. Ein guter „sofortiger" Suchablauf bedeutet meist:
- Schnelles Feedback: Ergebnisse aktualisieren sich schnell, während der Nutzer tippt, ohne unangenehme Pausen.
- Tippfehler brechen nichts: Rechtschreibfehler, vertauschte Buchstaben und Teilwörter finden trotzdem die richtigen Einträge.
- Nützliche Steuerungen: Filtern (Kategorie, Status, Preisspanne), Sortierung (neueste, günstigste) und Facetten (Anzahlen pro Filter) fühlen sich natürlich an.
- Relevante Reihenfolge: Die „besten“ Ergebnisse erscheinen zuerst, nicht nur die neuesten oder am stärksten mit Keywords gespickten.
Fehlt eines davon, gleichen Nutzer durch andere Suchanfragen aus, scrollen mehr oder brechen die Suche ganz ab.
Wobei Ihnen dieser Leitfaden hilft
Dieser Artikel ist ein praktischer Durchgang, um diese Erfahrung mit Meilisearch zu bauen. Wir behandeln, wie man es sicher einrichtet, wie man indexierte Daten strukturiert und synchronisiert, wie man Relevanz und Ranking-Regeln abstimmt, wie man Filter/Sortierung/Facetten hinzufügt und wie man über Sicherheit und Skalierung nachdenkt, damit die Suche schnell bleibt, wenn Ihre App wächst.
Wo serverseitige Suche glänzt
Meilisearch passt besonders gut zu:
- Dokumentation und Knowledge Bases (Seiten schnell finden, Tippfehler tolerieren)
- Produktkatalogen und Marktplätzen (Filter und Sortierung sind essenziell)
- Internen Tools (berechtigungsbewusste Suche über Datensätze)
- Content-Seiten (Suche über Artikel, Guides, FAQs)
Ziel ist durchgehend: Ergebnisse, die sich unmittelbar, genau und vertrauenswürdig anfühlen—ohne die Suche zu einem großen Engineering-Projekt zu machen.
Meilisearch-Übersicht in einfachen Worten
Meilisearch ist eine Suchmaschine, die Sie neben Ihrer App betreiben. Sie senden ihr Dokumente (z. B. Produkte, Artikel, Nutzer oder Support-Tickets) und sie baut einen Index auf, der für schnelle Suche optimiert ist. Ihr Backend (oder Frontend) fragt Meilisearch dann über eine einfache HTTP-API ab und erhält in Millisekunden gerankte Ergebnisse.
Was Sie direkt erhalten
Meilisearch konzentriert sich auf die Features, die Nutzer von moderner Suche erwarten:
- Fehlertoleranz, sodass „iphnoe" trotzdem „iPhone" findet.
- Relevanz-Kontrollen (Ranking-Regeln), damit Sie definieren können, was die beste Übereinstimmung für Ihr Business bedeutet.
- Filter, Sortierung und Facetten, damit Nutzer Ergebnisse nach Attributen wie Kategorie, Preisspanne, Verfügbarkeit oder Tags einschränken können.
Es ist so entworfen, dass es sich reaktionsschnell und nachsichtig anfühlt — selbst wenn eine Anfrage kurz, leicht fehlerhaft oder mehrdeutig ist.
Was Meilisearch nicht ist
Meilisearch ist kein Ersatz für Ihre primäre Datenbank. Ihre Datenbank bleibt die Quelle der Wahrheit für Schreibvorgänge, Transaktionen und Constraints. Meilisearch speichert eine Kopie der Felder, die Sie durchsuchbar, filterbar oder anzeigbar machen.
Ein gutes mentales Modell ist: Datenbank zum Speichern und Aktualisieren, Meilisearch zum schnellen Finden.
Performance-Erwartungen (was die Geschwindigkeit beeinflusst)
Meilisearch kann sehr schnell sein, aber die Ergebnisse hängen von einigen praktischen Faktoren ab:
- Datenmenge und Struktur (Anzahl Dokumente, Anzahl Felder und wie viel Text Sie indexieren)
- Hardware (CPU, RAM, Festplatte)
- Konfiguration (welche Attribute durchsuchbar/filterbar/sortierbar sind und wie oft Sie reindexen)
Für kleine bis mittlere Datensätze können Sie es oft auf einer einzigen Maschine betreiben. Wenn Ihr Index wächst, sollten Sie überlegt vorgehen, was Sie indexieren und wie Sie Aktualisierungen handhaben—Themen, die wir in späteren Abschnitten behandeln.
Planung Ihrer Indizes und Datenmodell
Bevor Sie irgendetwas installieren, entscheiden Sie, was Sie tatsächlich durchsuchen wollen. Meilisearch fühlt sich nur dann „sofortig“ an, wenn Ihre Indizes und Dokumente dem entsprechen, wie Menschen Ihre App durchsuchen.
Mappen Sie Entitäten auf Indizes
Beginnen Sie damit, Ihre durchsuchbaren Entitäten aufzulisten—typischerweise Produkte, Artikel, Nutzer, Help-Docs, Orte usw. In vielen Apps ist der sauberste Ansatz ein Index pro Entitätstyp (z. B. products, articles). Das hält Ranking-Regeln und Filter vorhersehbar.
Wenn Ihr UX über mehrere Typen in einer Box sucht („alles durchsuchen“), können Sie trotzdem separate Indizes behalten und Ergebnisse im Backend zusammenführen, oder später einen dedizierten „global"-Index erstellen. Packen Sie nicht alles in einen Index, es sei denn, Felder und Filter sind wirklich kompatibel.
Wählen Sie einen Primärschlüssel und Dokumentform
Jedes Dokument braucht einen stabilen Identifier (Primärschlüssel). Wählen Sie etwas, das:
- nie oder sehr selten geändert wird
- innerhalb des Index eindeutig ist
- bereits in Ihrer Datenbank existiert (z. B.
id,sku,slug)
Für die Dokumentform bevorzugen Sie flache Felder, wenn möglich. Flache Strukturen sind leichter zu filtern und zu sortieren. Verschachtelte Felder sind in Ordnung, wenn sie ein enges, unveränderliches Bündel repräsentieren (z. B. ein author-Objekt), aber vermeiden Sie tiefe Verschachtelung, die Ihrem relationalen Schema entspricht—Suchdokumente sollten read-optimiert sein, nicht datenbankförmig.
Felder klassifizieren: durchsuchbar, filterbar, angezeigt
Ein praktischer Weg, Dokumente zu entwerfen, ist, jedes Feld mit einer Rolle zu versehen:
- Durchsuchbar: Text, den Nutzer tippen (title, name, description)
- Filterbar: Attribute, die als Einschränkungen verwendet werden (category, price range, status, tags)
- Angezeigt: Was Sie der UI zurückgeben (title, Thumbnail-URL, kurzer Auszug)
Das verhindert einen häufigen Fehler: ein Feld „nur für den Fall" zu indexieren und sich später zu wundern, warum Ergebnisse rauschen oder Filter langsam sind.
Planen Sie für mehrsprachige Inhalte
„Sprache" kann in Ihren Daten verschiedene Dinge bedeuten:
- die Dokumentensprache (jedes Article hat z. B.
lang: "en") - die Locale des Nutzers (UI-Sprache)
- gemischte Sprachfelder (Produktnamen in mehreren Sprachen)
Entscheiden Sie früh, ob Sie separate Indizes pro Sprache verwenden (einfach und vorhersehbar) oder einen Index mit Sprachfeldern (weniger Indizes, mehr Logik). Die richtige Antwort hängt davon ab, ob Nutzer üblicherweise innerhalb einer Sprache suchen und wie Sie Übersetzungen speichern.
Meilisearch sicher installieren und betreiben
Meilisearch zu betreiben ist einfach, aber „sicher per Voreinstellung" erfordert ein paar bewusste Entscheidungen: wo Sie es deployen, wie Sie Daten persistieren und wie Sie den Master-Key handhaben.
Deployment-Optionen (wählen Sie das, was Sie betreiben können)
- Docker (am weitesten verbreitet): Schnell zum Starten, einfach zu upgraden, konsistent über Umgebungen. Ergänzen Sie es mit einem persistenten Volume.
- VM oder Bare Metal: Gut, wenn Sie bereits einen Standard-Linux-Deployment-Pipeline haben (systemd, Log-Rotation, Backups).
- Managed Hosting: Wenn Ihr Team keine Server warten möchte, suchen Sie nach einem gemanagten Meilisearch-Anbieter oder einer Plattform, die es als Add-on anbietet. Sie tauschen Flexibilität gegen einfachere Betriebsführung ein.
Grundlegendes zur Umgebung: Storage, Memory, Backups, Monitoring
Storage: Meilisearch schreibt seinen Index auf die Festplatte. Legen Sie das Datenverzeichnis auf zuverlässigen, persistenten Speicher (nicht auf ephemeren Container-Speicher). Planen Sie Kapazität fürs Wachstum: Indizes können mit viel Text und vielen Attributen schnell wachsen.
Memory: Geben Sie genug RAM, damit die Suche unter Last reaktionsschnell bleibt. Wenn Sie Swapping bemerken, leidet die Performance.
Backups: Sichern Sie das Meilisearch-Datenverzeichnis (oder verwenden Sie Snapshots auf Storage-Ebene). Testen Sie die Wiederherstellung mindestens einmal; ein Backup, das Sie nicht wiederherstellen können, ist nur eine Datei.
Monitoring: Überwachen Sie CPU, RAM, Festplattenspeicher und Disk-I/O. Überwachen Sie außerdem Prozessgesundheit und Log-Fehler. Mindestens sollten Sie alarmieren, wenn der Dienst stoppt oder der Speicherplatz knapp wird.
Master-Key setzen und sicher speichern
Führen Sie Meilisearch außerhalb der lokalen Entwicklung immer mit einem Master-Key aus. Bewahren Sie ihn in einem Secret-Manager oder verschlüsselten Umgebungsvariablen-Store auf (nicht in Git, nicht in einer unverschlüsselten .env-Datei im Repo).
Beispiel (Docker):
docker run -d --name meilisearch \\
-p 7700:7700 \\
-v meili_data:/meili_data \\
-e MEILI_MASTER_KEY="$(openssl rand -hex 32)" \\
getmeili/meilisearch:latest
Erwägen Sie außerdem Netzwerkregeln: Binden Sie an eine private Schnittstelle oder beschränken Sie eingehende Verbindungen, sodass nur Ihr Backend Meilisearch erreichen kann.
Erste-Start-Checkliste
- Wählen Sie eine Deployment-Methode (Docker/VM/managed) und stellen Sie sicher, dass persistenter Speicher konfiguriert ist.
- Setzen Sie MEILI_MASTER_KEY über einen sicheren Secret-Store.
- Starten Sie den Dienst und bestätigen Sie, dass er vom richtigen Netzwerk erreichbar ist.
- Prüfen Sie Health-/Version-Response:
curl -s http://localhost:7700/version
- Stellen Sie sicher, dass Logs gesammelt werden und grundlegende Alerts existieren (Prozess down, wenig Festplattenspeicher).
- Machen Sie ein initiales Backup (auch vor echten Daten) und dokumentieren Sie die Wiederherstellungs-Schritte.
Dokumente indexieren und synchron halten
Zuverlässige Indexierung einrichten
Erstelle Batch-Indexierungsjobs mit stabilen IDs, damit Wiederholungen sicher und vorhersehbar bleiben.
Meilisearch-Indexierung ist asynchron: Sie senden Dokumente, Meilisearch legt eine Aufgabe an und erst nach erfolgreichem Abschluss dieser Aufgabe werden Dokumente durchsuchbar. Behandeln Sie Indexierung wie ein Job-System, nicht wie eine einzelne Anfrage.
Ein einfacher Indexierungsablauf (hinzufügen → warten → verifizieren)
- Dokumente hinzufügen (sorgen Sie dafür, dass jedes eine stabile, eindeutige id hat, meist
id).
curl -X POST 'http://localhost:7700/indexes/products/documents?primaryKey=id' \\
-H 'Content-Type: application/json' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY' \\
--data-binary @products.json
- Auf die Aufgabe warten. Die API-Antwort enthält eine
taskUid. Pollen Sie, bis siesucceeded(oderfailed) ist.
curl -X GET 'http://localhost:7700/tasks/123' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY'
- Counts und einfache Suche verifizieren. Bestätigen Sie, dass der Index die erwartete Dokumentanzahl hat und dass eine einfache Abfrage Ergebnisse zurückliefert.
curl -X GET 'http://localhost:7700/indexes/products/stats' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY'
Wenn die Zählungen nicht übereinstimmen, raten Sie nicht—prüfen Sie zuerst die Task-Fehlerdetails.
Batch-Größen, die Sie später nicht überraschen
Batching dient dazu, Aufgaben vorhersehbar und wiederherstellbar zu halten.
- Beginnen Sie mit 1.000–10.000 Dokumenten pro Batch, oder begrenzen Sie die Nutzlastgröße (für viele Apps sind 5–15 MB pro Anfrage komfortabel).
- Bevorzugen Sie viele kleinere Batches gegenüber einem riesigen Upload; das ist einfacher zu retryen und Probleme lassen sich besser isolieren.
- Wenn Sie häufige Änderungen haben, indexen Sie kontinuierlich in Batches (z. B. jede Minute) statt alles neu aufzubauen.
Updates vs. Full-Reindex
addDocuments wirkt wie ein Upsert: Dokumente mit demselben Primärschlüssel werden aktualisiert, neue eingefügt. Verwenden Sie das für normale Updates.
Führen Sie ein Full-Reindex durch, wenn:
- Sie die Form der Dokumente signifikant geändert haben,
- Sie abgeleitete Felder neu berechnen müssen,
- Ihre Synchronisation abgedriftet ist und Sie einen sauberen Reset möchten.
Für Löschungen rufen Sie explizit deleteDocument(s) auf; sonst können alte Einträge bestehen bleiben.
Idempotenz: sichere Retries bei fehlgeschlagenen Jobs
Indexierung sollte wiederholbar sein. Der Schlüssel sind stabile Dokument-IDs.
- Wenn ein Batch-Upload zeitüberschreitet, können Sie denselben Batch erneut senden: Upsert + stabile IDs verhindern Duplikate.
- Speichern Sie die zurückgegebenen
taskUidzusammen mit Ihrer Batch-/Job-ID und wiederholen Sie basierend auf dem Task-Status. - Wenn Sie eine Queue betreiben, machen Sie den Worker „at-least-once" sicher: Duplikate sollten harmlos sein.
Seed-Daten für einen schnellen Pre-Prod-Test
Indexieren Sie vor Produktionsdaten ein kleines Dataset (200–500 Items), das Ihren echten Feldern entspricht. Beispiel: ein products-Set mit id, name, description, category, brand, price, inStock, createdAt. Das ist genug, um Task-Flow, Counts und Update/Delete-Verhalten zu validieren—ohne auf einen massiven Import warten zu müssen.
Relevanz und Ranking-Regeln, die Sie kontrollieren können
„Relevanz" bedeutet schlicht: was zuerst angezeigt wird und warum. Meilisearch macht das anpassbar, ohne dass Sie ein eigenes Scoring-System bauen müssen.
Beginnen Sie mit den richtigen Attributen
Zwei Einstellungen bestimmen, was Meilisearch mit Ihrem Content tun kann:
searchableAttributes: die Felder, in denen Meilisearch sucht, wenn ein Nutzer eine Anfrage tippt (z. B.title,summary,tags). Die Reihenfolge ist wichtig: frühere Felder werden als wichtiger behandelt.displayedAttributes: die Felder, die in der Antwort zurückgegeben werden. Das ist wichtig für Privatsphäre und Payload-Größe—wenn ein Feld nicht angezeigt wird, wird es auch nicht zurückgesendet.
Eine praktische Basis ist, einige wenige hochsignifikante Felder durchsuchbar zu machen (title, Kerntext) und die angezeigten Felder auf das zu beschränken, was die UI braucht.
Wie Ranking-Regeln die Ergebnisreihenfolge beeinflussen
Meilisearch sortiert passende Dokumente mit Hilfe von Ranking-Regeln—einer Pipeline von „Tie-Breakern“. Konzeptionell bevorzugt es:
- Ergebnisse, die gut zur Anfrage passen (inklusive Fehlertoleranz), dann
- Ergebnisse, bei denen die Übereinstimmungen stärker sind (näher stehende Wörter, Treffer in wichtigeren Attributen), dann
- Ergebnisse, die zu Ihrer Business-Logik passen (kundenindividuelle Sortierungen wie Aktualität oder Popularität).
Sie müssen die Interna nicht auswendig kennen, um effektiv zu tunen; im Wesentlichen wählen Sie welche Felder wichtig sind und wann Sie eigenes Sortieren anwenden.
Häufige Tuning-Ziele (mit Beispielen)
Ziel: „Übereinstimmungen im Titel sollen gewinnen." Setzen Sie title an erste Stelle:
{
"searchableAttributes": ["title", "subtitle", "description", "tags"]
}
Ziel: „Neuere Inhalte sollen zuerst erscheinen." Fügen Sie ein Sortierattribut hinzu und sortieren Sie zur Abfragezeit (oder setzen Sie ein Custom Ranking):
{
"sortableAttributes": ["publishedAt"],
"rankingRules": ["sort", "typo", "words", "proximity", "attribute", "exactness"]
}
Dann fragen Sie an:
{ "q": "release notes", "sort": ["publishedAt:desc"] }
Ziel: „Beliebte Items promoten." Machen Sie popularity sortierbar und sortieren Sie bei Bedarf danach.
Änderungen mit einem einfachen Vorher/Nachher-Test bewerten
Wählen Sie 5–10 reale Nutzeranfragen. Speichern Sie die Top-Ergebnisse vor Änderungen und vergleichen Sie nachher.
Beispiel:
- Vorher: Abfrage
"apple"→Apple Watch band,Pineapple slicer,Apple iPhone case - Nachher (Titel zuerst + Exactness): Abfrage
"apple"→Apple iPhone case,Apple Watch band,Pineapple slicer
Wenn die „Nachher"-Liste besser zur Nutzerabsicht passt, übernehmen Sie die Einstellungen. Wenn es Randfälle verschlechtert, passen Sie nacheinander jeweils nur eine Sache an (Attributreihenfolge, dann Ranking/Sortierregeln), damit Sie wissen, was die Verbesserung verursacht hat.
Filter, Sortierung und Facetten für reale Suche
Eine gute Suchbox ist nicht nur „Wörter eintippen, Treffer bekommen." Nutzer wollen oft Ergebnisse einschränken („nur verfügbare Artikel") und ordnen („günstigste zuerst"). In Meilisearch machen Sie das mit Filtern, Sortierung und Facetten.
Filter und Facetten (gleiche Idee, unterschiedliche UI)
Ein Filter ist eine Regel, die Sie auf das Ergebnis-Set anwenden. Eine Fazette ist das, was Sie in der UI zeigen, um Nutzern beim Erstellen dieser Regeln zu helfen (oft Checkboxen oder Anzahlen).
Nicht-technische Beispiele:
- Kategorie: „Shoes", „Jackets", „Accessories"
- Preis: „Unter $50", „$50–$100"
- Status: „In stock", „Backorder", „Archived"
Ein Nutzer könnte also nach „running" suchen und dann filtern auf category = Shoes und status = in_stock. Facetten können Anzahlen anzeigen wie „Shoes (128)" und „Jackets (42)", damit Nutzer wissen, was verfügbar ist.
Filterbare und sortierbare Felder konfigurieren (sonst funktionieren sie nicht)
Meilisearch benötigt, dass Sie Felder explizit erlauben, die Sie für Filter und Sortierung verwenden.
- Markieren Sie Felder als filterable, wenn Sie darauf filtern wollen:
category,status,brand,price,created_at(wenn Sie nach Zeit filtern),tenant_id(wenn Sie Kunden isolieren). - Markieren Sie Felder als sortable, wenn Sie Ergebnisse danach ordnen wollen:
price,rating,created_at,popularity.
Halten Sie diese Liste eng. Alles filterbar/sortierbar zu machen kann Indexgröße und Update-Kosten erhöhen.
Pagination und Limits, um Suche schnell zu halten
Auch wenn Sie 50.000 Treffer haben, sieht der Nutzer nur die erste Seite. Verwenden Sie kleine Seiten (oft 20–50 Ergebnisse), setzen Sie sinnvolle limit-Werte und paginieren Sie mit offset (oder den neueren Paginierungsfeatures, wenn Sie die bevorzugen). Begrenzen Sie außerdem die maximale Seitentiefe in Ihrer App, um teure „Seite 400"-Requests zu vermeiden.
Synonyme und Stoppwörter (optional, mit Bedacht)
- Synonyme helfen, wenn verschiedene Wörter dasselbe bedeuten (z. B. „hoodie" ↔ „sweatshirt"). Fügen Sie sie schrittweise hinzu und prüfen Sie Such-Analytics—zu viele Synonyme können überraschende Treffer erzeugen.
- Stoppwörter entfernen häufige Wörter („the", „and"). Sie können Rauschen reduzieren, aber auch exakte Suchen wie Bandnamen („The Who", „A Team") verschlechtern. Passen Sie Stoppwörter nur an, wenn Sie ein klares Problem haben.
Meilisearch in Ihr Backend integrieren
Filter und Facetten schnell hinzufügen
Erstelle eine Produktsuche mit Facetten, Filtern und Sortierung in nur einem Chat.
Ein sauberer Weg, serverseitige Suche hinzuzufügen, ist, Meilisearch wie einen spezialisierten Datendienst hinter Ihrer API zu behandeln. Ihre App erhält eine Suchanfrage, ruft Meilisearch ab und gibt eine kuratierte Antwort an den Client zurück.
Ein einfaches Backend-Muster
Die meisten Teams landen bei einem Ablauf wie diesem:
- Client ruft Ihren Endpoint auf (z. B.
GET /api/search?q=wireless+headphones&limit=20). - Ihr Backend validiert Eingaben, wendet Business-Regeln an und entscheidet, welchen Index es abfragt.
- Backend ruft Meilisearchs Search-API mit der Nutzeranfrage plus Filtern/Sortierung auf.
- Backend post-prozessiert Ergebnisse (private Felder ausblenden, mit DB-Daten mergen, Berechtigungen anwenden).
- Backend gibt eine stabile Antwortstruktur an den Client zurück.
Dieses Muster hält Meilisearch austauschbar und verhindert, dass Frontend-Code von Index-Interna abhängt.
Wenn Sie eine neue App bauen (oder ein internes Tool neu erstellen) und dieses Muster schnell implementieren wollen, kann eine Vibe-Coding-Plattform wie Koder.ai helfen, den kompletten Flow zu scaffolden—React-UI, ein Go-Backend und PostgreSQL—und Meilisearch hinter einem einzigen /api/search-Endpoint zu integrieren, sodass der Client einfach bleibt und Ihre Berechtigungen serverseitig bleiben.
Frontend- vs Backend-Abfragen (und warum Backend sicherer ist)
Meilisearch unterstützt Client-seitige Abfragen, aber Backend-Abfragen sind meist sicherer, weil:
- Secrets privat bleiben: Sie riskieren nicht, privilegierte API-Keys offenzulegen.
- Autorisierung konsistent ist: Ihr Backend kann durchsetzen, was ein Nutzer sehen darf, bevor Treffer zurückgegeben werden.
- Sie Query-Komplexität kontrollieren: Begrenzen Sie Filter, Sortieroptionen und Paginierung, um die Performance zu schützen.
Client-seitige Abfragen können für öffentliche Daten funktionieren mit eingeschränkten Keys, aber wenn Sie nutzerspezifische Sichtbarkeitsregeln haben, leiten Sie Suche durch Ihren Server.
Caching populärer Anfragen ohne Relevanz zu brechen
Suchverkehr hat oft Wiederholungen („iphone case", „return policy"). Fügen Sie Caching in Ihrer API-Schicht hinzu:
- Cachen Sie die komplette Antwort für kurze Zeiträume (z. B. 10–60 Sekunden) für anonymen Traffic.
- Normalisieren Sie Cache-Keys (Whitespace trimmen, lowercase, Filter/Sort einschließen).
- Invalidieren Sie vorsichtig: Für schnell ändernde Indizes halten Sie TTLs kurz statt aggressiv zu purgen.
Rate Limiting und Abuse-Kontrollen
Behandeln Sie Suche als öffentliches Endpoint:
- Wenden Sie Per-IP- oder Per-User-Rate-Limits an.
- Setzen Sie ein Maximum für
limitund eine maximale Query-Länge. - Erwägen Sie soft-blocking offensichtlicher Bots, während echte Nutzer weiterarbeiten können.
Sicherheitsgrundlagen: Keys, Zugriffskontrolle und Multi-Tenancy
Meilisearch wird oft „hinter“ Ihrer App platziert, weil es schnell vertrauliche Geschäftsdaten zurückgeben kann. Behandeln Sie es wie eine Datenbank: Sperren Sie es ab und geben Sie nur zurück, was jeder Aufrufer sehen darf.
API-Keys: Master vs Scoped (Least Privilege)
Meilisearch hat einen Master-Key, der alles kann: Indizes erstellen/löschen, Einstellungen ändern und Dokumente lesen/schreiben. Bewahren Sie ihn serverseitig auf.
Für Anwendungen erzeugen Sie API-Keys mit begrenzten Aktionen und begrenzten Indizes. Ein gängiges Muster:
- Backend-Jobs: ein Key, der Dokumente schreiben und Einstellungen aktualisieren kann, aber nur auf bestimmten Indizes.
- App-Server: ein schreibgeschützter Key für die Suche.
- Client (falls unumgänglich): ein sehr eng eingeschränkter Search-Only-Key mit strikten Filtern.
Least Privilege bedeutet, dass ein geleakter Key nicht Daten löschen oder aus fremden Indizes lesen kann.
Multi-Tenancy: separate Indizes oder nach tenantId filtern
Wenn Sie mehrere Kunden (Tenants) bedienen, haben Sie zwei Hauptoptionen:
1) Ein Index pro Tenant.
Einfach zu begründen und reduziert das Risiko von Cross-Tenant-Zugriffen. Nachteile: mehr Indizes zu verwalten und Settings-Updates müssen konsistent angewendet werden.
2) Gemeinsamer Index + tenantId-Filter.
Speichern Sie ein tenantId-Feld in jedem Dokument und verlangen Sie einen Filter wie tenantId = "t_123" für alle Suchen. Das kann gut skalieren, aber nur, wenn Sie sicherstellen, dass jede Anfrage immer den Filter anwendet (idealerweise via scoped Key, sodass Aufrufer ihn nicht entfernen können).
Datenlecks verhindern: kontrollieren, was zurückgegeben werden kann
Auch wenn die Suche korrekt arbeitet, können Ergebnisse Felder ausgeben, die Sie nicht zeigen wollten (E-Mails, interne Notizen, Einkaufspreise). Konfigurieren Sie, was zurückgegeben werden darf:
- Begrenzen Sie displayed/retrievable attributes auf eine sichere Allowlist.
- Halten Sie sensible Felder nur indexiert, wenn nötig—und vermeiden Sie deren Rückgabe in Ergebnissen.
Machen Sie einen kurzen „Worst-Case"-Test: Suchen Sie nach einem gebräuchlichen Begriff und bestätigen Sie, dass keine privaten Felder erscheinen.
Operative Basis-Sicherheit
- Beschränken Sie Netzwerkzugriff: Binden Sie an
localhostoder ein privates Netzwerk und erlauben Sie eingehenden Traffic nur von Ihren App-Servern. - Stellen Sie Meilisearch hinter einem Reverse-Proxy, wenn Sie TLS und Rate-Limiting benötigen.
- Speichern Sie Keys in einem Secret-Manager (nicht im Quellcode oder in Frontend-Bundles) und rotieren Sie sie regelmäßig.
Wenn Sie unsicher sind, ob ein Key clientseitig sein sollte, gehen Sie davon aus: „nein" und halten Sie Suche serverseitig.
Performance und Skalierung ohne Rätselraten
Volle Kontrolle über den Code behalten
Behalte die Codebasis – exportiere den Quellcode, wenn du bereit bist, weiterzugehen.
Meilisearch ist schnell, wenn Sie zwei Workloads im Blick behalten: Indexierung (Schreiben) und Suchanfragen (Lesen). Die meisten "mysteriösen" Verlangsamungen sind einfach darauf zurückzuführen, dass eines dieser Workloads CPU, RAM oder Festplatte beansprucht.
Wo Performance üblicherweise zum Flaschenhals wird
Indexierungs-Last kann aufkommen, wenn Sie große Batches importieren, häufige Updates durchführen oder viele durchsuchbare Felder hinzufügen. Indexierung läuft im Hintergrund, verbraucht aber CPU und Festplattenbandbreite. Wenn Ihre Task-Queue wächst, können Suchanfragen langsamer werden, selbst wenn das Anfragevolumen gleich bleibt.
Query-Last wächst mit Traffic, aber auch mit Features: mehr Filter, mehr Facetten, größere Ergebnis-Sets und stärkere Fehlertoleranz erhöhen die Arbeit pro Anfrage.
Disk-I/O ist oft der stille Übeltäter. Langsame Festplatten (oder "noisy neighbors" auf geteilten Volumes) können "sofort" zu "irgendwann" machen. NVMe/SSD-Speicher ist die typische Basis für Production.
Praktische Skalierungsschritte
Starten Sie mit einfacher Dimensionierung: Geben Sie Meilisearch genug RAM, damit Indizes hot bleiben und genug CPU, um Spitzen-QPS zu verarbeiten. Trennen Sie dann die Belange:
- Wenn Indexierung Reads stört, planen Sie Bulk-Imports zu Nebenzeiten und bevorzugen Sie größere Batches über viele winzige Updates.
- Fügen Sie Replikate für hohe Verfügbarkeit und Lese-Kapazität hinzu (Ihre App kann Suchanfragen über Replikate load-balancen).
- Sharding: Meilisearch macht kein automatisches verteiltes Sharding. Wenn Sie eine einzelne Node übersteigen, können Sie Daten auf Anwendungsebene partitionieren (z. B. pro Tenant, Region oder Zeitraum) in mehrere Indizes oder Cluster.
Was Sie überwachen sollten (damit Sie nicht raten)
Verfolgen Sie eine kleine Menge an Signalen:
- Search-Latenz (p50/p95) und Durchsatz
- Task-Queue-Länge / Task-Verarbeitungszeit (eine wachsende Queue bedeutet, Indexierung kommt nicht nach)
- CPU, RAM, Festplattennutzung und Disk I/O Wait
- Fehlerraten (Timeouts, 4xx/5xx, fehlgeschlagene Tasks)
Backups und Upgrade-Planung
Backups sollten Routine sein, nicht heroisch. Verwenden Sie Meilisearchs Snapshot-Funktion nach Zeitplan, speichern Sie Snapshots extern und testen Sie Wiederherstellungen regelmäßig. Für Upgrades lesen Sie die Release Notes, testen Sie das Upgrade in einer Non-Prod-Umgebung und planen Sie Reindexing-Zeit ein, falls eine Version das Indexierungsverhalten ändert.
Wenn Sie bereits Environment-Snapshots und Rollbacks in Ihrer Plattform verwenden (z. B. über Koder.ai’s Snapshots/Rollback-Workflow), stimmen Sie Ihre Such-Rollouts mit derselben Disziplin ab: Snapshot vor Änderungen, Health-Checks verifizieren und einen schnellen Weg zurück in einen bekannten guten Zustand bereithalten.
Fehlerbehebung und praktische Rollout-Checkliste
Auch bei sauberer Integration fallen Suchprobleme meist in einige wiederkehrende Kategorien. Die gute Nachricht: Meilisearch gibt Ihnen genug Sichtbarkeit (Tasks, Logs, deterministische Einstellungen), um schnell zu debuggen—wenn Sie systematisch vorgehen.
Häufige Probleme (und was sie typischerweise bedeuten)
- „Meine Filter funktionieren nicht": Das Feld wurde nicht zu
filterableAttributeshinzugefügt oder die Dokumente speichern es in einer unerwarteten Form (String vs Array vs verschachteltes Objekt). - „Ergebnisse sind seltsam gerankt": Ranking-Regeln, Synonyme, Stoppwörter oder fehlende
sortableAttributes/rankingRules-Anpassungen heben falsche Items hervor. - „Suche zeigt alte Daten": Indexierungs-Tasks laufen noch, Sie schreiben in einen anderen Index als Sie lesen, oder Ihre Sync-Pipeline hat Updates/Löschungen verworfen.
Debugging-Workflow, der überschaubar bleibt
Beginnen Sie damit zu prüfen, ob Meilisearch Ihre letzte Änderung erfolgreich angewendet hat.
- Task-Status prüfen: Jede Settings-Änderung und jedes Dokument-Update erzeugt eine asynchrone Task. Wenn eine Task fehlgeschlagen ist, beheben Sie das zuerst (fehlerhafte Payloads, falsche Feldtypen, übergroße Dokumente).
- Logs mit einer einzigen Frage im Kopf nutzen: „Hat der Server meine Anfrage akzeptiert?“ dann „Hat er die Verarbeitung abgeschlossen?“ Vermeiden Sie, alles auf einmal zu scannen.
- Erschaffen Sie eine minimale reproduzierbare Anfrage:
- Wählen Sie einen Index.
- Nutzen Sie eine Abfrage, die eine kleine, stabile Menge zurückgibt.
- Fügen Sie Einschränkungen schrittweise hinzu:
filter, dannsort, dannfacets.
Wenn Sie ein Ergebnis nicht erklären können, reduzieren Sie temporär Ihre Konfiguration: entfernen Sie Synonyme, verringern Sie Ranking-Regel-Anpassungen und testen Sie mit einem winzigen Dataset. Komplexe Relevanzprobleme sind auf 50 Dokumenten viel einfacher zu sehen als auf 5 Millionen.
Rollout-Strategie: Minimieren Sie die Blast Radius
- Test-Index zuerst: Bauen Sie
your_index_v2parallel auf, wenden Sie Einstellungen an und replayen Sie eine Stichprobe von Produktionsanfragen. - Canary-Rollout: Leiten Sie einen kleinen Prozentsatz des Suchtraffics an den neuen Index oder die neuen Einstellungen und vergleichen Sie Klickrate und "no results"-Raten.
- Fallback-Verhalten: Entscheiden Sie, was Nutzer sehen, wenn Suche langsam oder nicht verfügbar ist—gecachete Ergebnisse, eine vereinfachte Abfrage oder eine freundliche "bitte versuchen Sie es erneut"-Meldung. Lassen Sie nicht zu, dass Suchfehler die ganze Seite brechen.
Nächste Schritte-Checkliste
- Prüfen Sie, ob
filterableAttributesundsortableAttributeszu Ihren UI-Anforderungen passen. - Bestätigen Sie, dass Indexierungs-Tasks nach jedem Deployment erfolgreich abgeschlossen werden.
- Fügen Sie eine kleine "Search-Health"-Überwachung hinzu (Latenz + Task-Fehler).
- Üben Sie einen Rollback: Schalten Sie den Traffic zurück zum vorherigen Index.
Verwandte Guides: /blog (Suchzuverlässigkeit, Indexierungsmuster und Produktions-Rollout-Tipps).
FAQ
Was ist serverseitige Suche und wann sollte ich sie einsetzen?
Serverseitige Suche bedeutet, dass die Anfrage auf Ihrem Backend (oder einem dedizierten Suchdienst) ausgeführt wird, nicht im Browser. Sie ist die richtige Wahl, wenn:
- Ihr Datensatz zu groß ist, um an Clients verteilt zu werden
- Sie konsistente Relevanz über Plattformen hinweg benötigen
- Zugriffskontrollen erforderlich sind (Benutzer dürfen nur berechtigte Datensätze sehen)
- Sie Logging/Analytics und vorhersehbare Performance wollen
Was braucht "sofortige" Suche, damit sie für Nutzer gut wirkt?
Nutzer nehmen vier Dinge sofort wahr:
- Schnelles Feedback beim Tippen (geringe Latenz)
- Fehlertoleranz (Tippfehler funktionieren trotzdem)
- Praktische Steuerungen wie Filter, Sortierung und Facettenzählungen
- Relevante Reihenfolge (beste Treffer zuerst, nicht zufällige Aktualität)
Fehlt eines davon, tippen Nutzer neu, scrollen mehr oder brechen die Suche ab.
Ist Meilisearch ein Ersatz für die Datenbank?
Behandle Meilisearch als Suchindex, nicht als Ihre primäre Datenbank. Ihre Datenbank bleibt die Quelle der Wahrheit für Schreibvorgänge, Transaktionen und Einschränkungen; Meilisearch speichert eine Kopie ausgewählter Felder, optimiert für das schnelle Auffinden.
Ein hilfreiches Modell ist:
- Datenbank: speichern und aktualisieren
- Meilisearch: schnell finden
Wie entscheide ich zwischen einem oder mehreren Indizes?
Eine übliche Standardentscheidung ist ein Index pro Entitätstyp (z. B. products, articles). Das sorgt für:
- kohärente Ranking-Regeln
- vorhersehbare Filter-/Sortierlogik
- konsistente Dokumentfelder
Wenn Sie „alles durchsuchen“ müssen, können Sie mehrere Indizes abfragen und Ergebnisse im Backend zusammenführen oder später einen dedizierten Global-Index anlegen.
Wie wähle ich einen Primärschlüssel und warum ist das wichtig?
Wählen Sie einen Primärschlüssel, der:
- stabil ist (selten/nie ändert)
- eindeutig innerhalb des Index ist
- bereits in Ihrer Datenbank existiert (z. B.
id,sku,slug)
Stabile IDs machen die Indexierung idempotent: Bei einem erneuten Upload entstehen keine Duplikate, da Updates als Upserts wirken.
Wie entscheide ich, welche Felder ich indexiere und der UI zurückgebe?
Klassifizieren Sie jedes Feld nach Zweck, damit Sie nicht zu viel indexieren:
- Durchsuchbar: Text, gegen den Nutzer suchen (title, name, description)
- Filterbar: Einschränkungen (category, status, tags, tenantId)
- Angezeigt: Was die UI zurückbekommt (title, thumbnail, snippet)
Diese Rollen explizit zu halten reduziert Rauschen und verhindert langsame oder aufgeblähte Indizes.
Warum sind meine Dokumente nach der Indexierung nicht sofort sichtbar?
Indexierung ist asynchron: Dokument-Uploads erzeugen eine Aufgabe, und Dokumente werden erst nach erfolgreichem Abschluss dieser Aufgabe durchsuchbar.
Ein verlässlicher Ablauf ist:
- Dokumente hochladen (meist als Upserts)
- Task-Status abfragen, bis
succeededoderfailed - Mit Index-Stats und einer einfachen Suche verifizieren
Wenn Ergebnisse veraltet erscheinen, prüfen Sie zuerst den Task-Status.
Welche Batch-Größe sollte ich beim Indexieren verwenden?
Verwenden Sie mehrere kleinere Batches statt eines riesigen Uploads. Praktische Startpunkte:
- 1.000–10.000 Dokumente pro Batch oder
- ungefähr 5–15 MB Payload pro Anfrage
Kleinere Batches sind leichter neu zu versuchen, einfacher zu debuggen (schlechte Datensätze finden) und seltener zeitbehaftet.
Was sind die einfachsten Wege, die Relevanz in Meilisearch zu verbessern?
Zwei sehr wirkungsvolle Hebel sind:
searchableAttributes: welche Felder durchsucht werden und in welcher Priorität- Ranking-/Sortierverhalten: ob Sie nach Feldern wie
publishedAt,priceoderpopularitysortieren lassen
Praktisches Vorgehen: Nehmen Sie 5–10 reale Nutzeranfragen, speichern Sie die Top-Ergebnisse „vorher“, ändern Sie eine Einstellung und vergleichen Sie „danach“.
Warum funktionieren meine Filter oder die Sortierung nicht?
Die meisten Filter-/Sortierprobleme stammen von fehlender Konfiguration:
- Ein Feld muss in
filterableAttributessein, um darauf zu filtern - Ein Feld muss in
sortableAttributessein, um danach zu sortieren
Prüfen Sie außerdem Form und Typ der Felder in den Dokumenten (String vs Array vs verschachteltes Objekt). Wenn ein Filter fehlschlägt, prüfen Sie den letzten Settings-/Task-Status und bestätigen Sie, dass die indizierten Dokumente die erwarteten Feldwerte enthalten.