03. Nov. 2025·8 Min
Multi-Tenant-SaaS-Muster: Isolation, Skalierung und KI-gestaltetes Design
Lerne gängige Multi-Tenant-SaaS-Muster, die Abwägungen bei Mandantenisolation und Skalierungsstrategien. Erfahre, wie KI-generierte Architekturen Design und Reviews beschleunigen.
Was Multi-Tenancy bedeutet (ohne Fachchinesisch)
Multi-Tenancy bedeutet, dass ein Softwareprodukt mehrere Kunden (Mandanten) aus demselben laufenden System bedient. Jeder Mandant hat das Gefühl, „seine eigene App“ zu nutzen, aber hinter den Kulissen werden Teile der Infrastruktur geteilt — etwa dieselben Webserver, derselbe Codebase und oft dieselbe Datenbank.
Ein hilfreiches Bild ist ein Wohnhaus mit Apartments. Jeder hat seine eigene verschlossene Einheit (Daten und Einstellungen), teilt aber Fahrstuhl, Sanitär und Wartungsteam (Compute, Storage und Betrieb der App).
Warum Teams Multi-Tenancy wählen
Die meisten Teams entscheiden sich nicht aus Modegründen für Multi-Tenant-SaaS, sondern weil es effizient ist:
- Geringere Kosten pro Kunde: Geteilte Infrastruktur ist in der Regel günstiger als für jeden Kunden einen vollständigen Stack zu starten.
- Einfacherer Betrieb: Eine Plattform zu überwachen, zu patchen und zu sichern ist einfacher als Hunderte kleiner Deployments.
- Schnellere Auslieferung: Verbesserungen kommen allen gleichzeitig zugute und verhindern Versionsabweichungen zwischen Kunden.
Wo es schiefgehen kann
Die klassischen Fehlerquellen sind Sicherheit und Performance.
Bei der Sicherheit: Wenn Mandantengrenzen nicht überall durchgesetzt werden, kann ein Fehler Daten über Kunden hinweg leaken. Solche Lecks sind selten dramatische „Hacks“ — meist sind es alltägliche Fehler wie ein fehlender Filter, eine falsch konfigurierte Berechtigungsprüfung oder ein Hintergrundjob ohne Mandantenkontext.
Bei der Performance: Geteilte Ressourcen bedeuten, dass ein ausgelasteter Mandant andere verlangsamen kann. Der sogenannte "noisy neighbor" zeigt sich in langsamen Abfragen, bursty Workloads oder wenn ein einzelner Kunde überproportional viele API-Ressourcen verbraucht.
Kurzer Überblick der behandelten Muster
Dieser Artikel beschreibt die Bausteine, mit denen Teams diese Risiken managen: Datenisolation (Datenbank, Schema oder Zeilen), mandantenbewusste Identität und Berechtigungen, Maßnahmen gegen noisy neighbors und operative Muster für Skalierung und Änderungsmanagement.
Der Kerntrade-off: Isolation vs. Effizienz
Multi-Tenancy ist eine Entscheidung darüber, wo man auf einem Spektrum sitzt: wie viel geteilt wird vs. wie viel pro Mandant dediziert ist. Jedes unten beschriebene Architekturpattern ist ein anderer Punkt auf dieser Linie.
Geteilte vs. dedizierte Ressourcen: das Kernspektrum
An einem Ende teilen Mandanten fast alles: dieselben App-Instanzen, dieselben Datenbanken, dieselben Queues und Caches — logisch getrennt durch Tenant-IDs und Zugriffsregeln. Das ist meist am günstigsten und am einfachsten zu betreiben, weil Kapazität gepoolt wird.
Am anderen Ende bekommt jeder Mandant seinen eigenen "Slice" des Systems: separate Datenbanken, eigene Compute-Ressourcen, manchmal sogar eigene Deployments. Das erhöht Sicherheit und Kontrolle, steigert aber Aufwand und Kosten.
Warum Isolation und Kosten in entgegengesetzte Richtungen ziehen
Isolation reduziert die Wahrscheinlichkeit, dass ein Mandant auf die Daten eines anderen zugreift, dessen Performance-Budget aufbraucht oder durch ungewöhnliche Nutzungsmuster beeinträchtigt wird. Sie erleichtert außerdem bestimmte Audits und Compliance-Anforderungen.
Effizienz steigt, wenn Leerlaufkapazität über viele Mandanten amortisiert wird. Geteilte Infrastruktur erlaubt weniger Server, einfachere Deployment-Pipelines und Skalierung nach aggregierter Nachfrage statt nach dem schlimmsten Einzelfall.
Häufige Entscheidungstreiber
Dein „richtiger“ Punkt auf dem Spektrum ist selten philosophisch — er wird von Rahmenbedingungen getrieben:
- SLA und Kundenerwartungen: strenge Verfügbarkeits- oder Latenzziele treiben zu mehr Isolation.
- Compliance und Datenlokation: Vorgaben können dedizierten Storage oder dedizierte Umgebungen erzwingen.
- Wachstumsphase: Frühe Produkte starten oft geteilter, um schneller zu werden; später führt man dedizierte Optionen für große Kunden ein.
- Betriebliche Reife: Mehr Isolation bedeutet in der Regel mehr Dinge zu überwachen, zu patchen und zu migrieren.
Einfaches Entscheidungsmodell
Stelle zwei Fragen:
-
Wie groß ist die Blast-Radius, wenn ein Mandant sich schlecht verhält oder kompromittiert wird?
-
Welche Geschäftskosten entstehen, um diesen Blast-Radius zu verkleinern?
Muss der Blast-Radius minimal sein, wähle mehr dedizierte Komponenten. Sind Kosten und Geschwindigkeit zentral, teile mehr — und investiere in starke Zugriffskontrollen, Ratenbegrenzungen und mandantenbezogenes Monitoring, damit Sharing sicher bleibt.
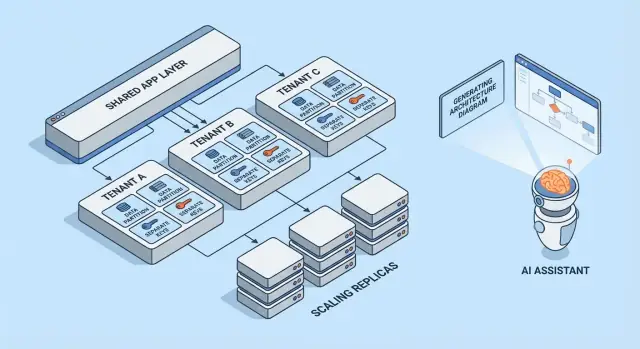
Multi-Tenant-Modelle im Überblick
Multi-Tenancy ist keine einzelne Architektur — es sind mehrere Wege, Infrastruktur zwischen Kunden zu teilen (oder nicht). Das beste Modell hängt davon ab, wie viel Isolation benötigt wird, wie viele Mandanten erwartet werden und wie viel betrieblicher Overhead das Team tragen kann.
1) Single-Tenant (dediziert) — die Basis
Jeder Kunde erhält seinen eigenen App-Stack (oder zumindest eine isolierte Laufzeit und Datenbank). Das ist am einfachsten hinsichtlich Sicherheit und Performance, aber meist am teuersten pro Mandant und kann den Betriebsskalierungsprozess verlangsamen.
2) Gemeinsame App + gemeinsame DB — geringste Kosten, höchster Sorgfaltsbedarf
Alle Mandanten nutzen dieselbe Anwendung und Datenbank. Die Kosten sind meist am niedrigsten, weil Wiederverwendung maximiert wird, aber man muss konsequent Mandantenkontext überall durchsetzen (Abfragen, Caching, Hintergrundjobs, Analytics-Exporte). Ein einziger Fehler kann zu einem Cross-Mandant-Datenleck führen.
3) Gemeinsame App + separate DB — stärkere Isolation, mehr Betrieb
Die Anwendung wird geteilt, aber jeder Mandant hat eine eigene Datenbank (oder DB-Instanz). Das verbessert die Blast-Radius-Kontrolle bei Vorfällen, erleichtert Mandanten-Backups/Restores und kann Compliance-Gespräche vereinfachen. Der Trade-off ist Betrieb: mehr Datenbanken zu provisionieren, zu überwachen, zu migrieren und zu sichern.
4) Hybride Modelle für "große Mandanten"
Viele SaaS-Produkte mischen Ansätze: die meisten Kunden leben in geteilter Infrastruktur, während große oder regulierte Mandanten dedizierte Datenbanken oder dedizierten Compute bekommen. Hybride Modelle sind oft der praktische Zielzustand, benötigen aber klare Regeln: wer qualifiziert sich, was kostet es und wie laufen Upgrades?
Wenn du tiefer in Isolationstechniken innerhalb der Modelle einsteigen willst, siehe /blog/data-isolation-patterns.
Datenisolation-Muster (DB, Schema, Zeile)
Datenisolation beantwortet die Frage: „Kann ein Kunde jemals die Daten eines anderen sehen oder beeinflussen?“ Es gibt drei gängige Muster mit unterschiedlichen Sicherheits- und Betriebsimplikationen.
Zeilenbasierte Isolation (gemeinsame Tabellen + tenant_id)
Alle Mandanten teilen dieselben Tabellen; jede Zeile enthält eine tenant_id-Spalte. Das ist das effizienteste Modell für kleine bis mittlere Mandanten, da es Infrastruktur minimiert und Reporting/Analytics unkompliziert hält.
Das Risiko ist klar: vergisst eine Abfrage den Filter tenant_id, können Daten ausgegeben werden. Schon ein einziger Admin-Endpunkt oder ein Hintergrundjob kann zur Schwachstelle werden. Milderungsmaßnahmen sind:
- Durchsetzung von Mandantenfiltern in einer gemeinsamen Data-Access-Schicht (entwickler schreiben nicht selbst Filter)
- Nutzung von DB-Features wie Row-Level Security (RLS), wo verfügbar
- Automatisierte Tests, die bewusst Cross-Tenant-Zugriff versuchen
- Indexierung für gängige Zugriffspfade (z. B.
(tenant_id, created_at)oder(tenant_id, id)), damit tenant-skopierte Abfragen schnell bleiben
Schema-pro-Mandant (gleiche DB, separate Schemas)
Jeder Mandant erhält sein eigenes Schema (Namensräume wie tenant_123.users, tenant_456.users). Das verbessert die Isolation gegenüber Zeilen-Sharing und macht Mandantenexporte oder mandantenspezifisches Tuning einfacher.
Der Nachteil ist betrieblicher Aufwand. Migrationen müssen über viele Schemas ausgeführt werden, und Fehler werden komplexer: du könntest 9.900 Mandanten erfolgreich migrieren und bei 100 stecken bleiben. Monitoring und Tooling sind hier entscheidend — der Migrationsprozess braucht klare Retry- und Reporting-Mechanismen.
Datenbank-pro-Mandant (separate Datenbanken)
Jeder Mandant erhält eine separate Datenbank. Die Isolation ist stark: Zugriffsgrenzen sind klarer, laute Abfragen eines Mandanten beeinflussen andere weniger und das Wiederherstellen eines einzelnen Mandanten aus Backup ist sauberer.
Kosten und Skalierung sind die Hauptnachteile: mehr Datenbanken zu managen, mehr Connection-Pools und potentiell mehr Upgrade-/Migrationsarbeit. Viele Teams reservieren dieses Modell für hochpreisige oder regulierte Mandanten, während kleinere Mandanten auf geteilter Infrastruktur bleiben.
Sharding- und Platzierungsstrategien beim Wachstum
Reale Systeme mischen oft diese Muster. Ein üblicher Weg ist Zeilen-Isolation für frühes Wachstum und später das „Hochstufen“ großer Mandanten in eigene Schemas oder DBs.
Sharding fügt eine Platzierungsebene hinzu: Entscheiden, in welchem DB-Cluster ein Mandant lebt (nach Region, Größe oder Hashing). Wichtig ist, die Mandantenplatzierung explizit und änderbar zu machen — so kannst du einen Mandanten verschieben, ohne die App umzuschreiben, und durch Hinzufügen von Shards skalieren, statt alles neu zu designen.
Identität, Zugriff und Mandantenkontext
Multi-Tenancy scheitert auf überraschend gewöhnliche Weise: ein fehlender Filter, ein gecachter Objekt, das zwischen Mandanten geteilt wird, oder ein Admin-Feature, das „vergisst“, für welchen Mandanten die Anfrage ist. Die Lösung ist kein einzelnes Sicherheitsfeature — es ist ein konsistenter Mandantenkontext vom ersten Byte einer Anfrage bis zur letzten DB-Abfrage.
Mandantenerkennung (wie man weiß, "wer")
Die meisten SaaS-Produkte wählen eine primäre Kennung und behandeln andere Signale als Convenience:
- Subdomain:
acme.yourapp.comist benutzerfreundlich und eignet sich gut für mandantenbranded Erlebnisse. - Header: nützlich für API-Clients und interne Services (muss aber authentifiziert werden).
- Token-Claim: ein signiertes JWT (oder Session) enthält
tenant_id, was Manipulation erschwert.
Wähle eine Quelle der Wahrheit und logge sie überall. Unterstützt du mehrere Signale (Subdomain + Token), definiere Vorrangregeln und lehne mehrdeutige Anfragen ab.
Request-Scoping (wie jede Abfrage mandantensicher bleibt)
Eine gute Regel: Sobald du tenant_id aufgelöst hast, sollte alles Downstream es aus einer einzigen Quelle (Request-Context) lesen, nicht erneut ableiten.
Gängige Schutzmaßnahmen:
- Middleware, die
tenant_idan den Request-Context hängt - Data-Access-Helper, die
tenant_idals Parameter verlangen - Datenbankdurchsetzung (wie zeilenbasierte Policies), sodass Fehler geschlossen fehlschlagen
handleRequest(req):
tenantId = resolveTenant(req) // subdomain/header/token
req.context.tenantId = tenantId
return next(req)
Autorisierungsgrundlagen (Rollen innerhalb eines Mandanten)
Trenne Authentifizierung (wer der User ist) von Autorisierung (was er tun darf).
Typische SaaS-Rollen sind Owner / Admin / Member / Read-only, aber wichtig ist der Scope: Ein Nutzer kann Admin in Mandant A und Member in Mandant B sein. Berechtigungen sollten mandantenbezogen gespeichert werden, nicht global.
Cross-Mandant-Leaks verhindern (Tests und Guardrails)
Behandle Cross-Mandant-Zugriff wie einen Top-Tier-Vorfall und verhindere ihn proaktiv:
- Füge automatisierte Tests hinzu, die versuchen, Tenant-B-Daten als Tenant-A-User zu lesen
- Erschwere das Versenden von fehlenden Mandantenfiltern (Linter, Query-Builder, verpflichtende Mandantenparameter)
- Logge und alarmiere bei verdächtigen Mustern (z. B. Mandantenmismatch zwischen Token und Subdomain)
Für eine tiefere operative Checkliste verlinke diese Regeln in deinen Engineering-Runbooks unter /security und versioniere sie zusammen mit deinem Code.
Isolation über die Datenbank hinaus
Multi‑Tenancy schnell prototypen
Erzeuge ein Gerüst mit React, Go und PostgreSQL, um die Mandantenzuordnung früh zu testen.
Datenbankisolation ist nur die halbe Miete. Viele echte Multi-Tenant-Vorfälle passieren in der geteilten Peripherie: Caches, Queues und Storage. Diese Schichten sind schnell, bequem und leicht versehentlich global.
Geteilte Caches: Key-Kollisionen und Datenlecks verhindern
Wenn mehrere Mandanten Redis oder Memcached teilen, gilt die Hauptregel: niemals tenant-agnostische Keys speichern.
Ein praktisches Muster ist, jeden Key mit einer stabilen Mandantenkennung zu prefixen (nicht mit einer E-Mail-Domain oder einem Anzeigenamen). Beispiel: t:{tenant_id}:user:{user_id}. Das bewirkt zweierlei:
- Verhindert Kollisionen, wenn zwei Mandanten dieselben internen IDs haben
- Ermöglicht Bulk-Invalidierung (Löschen per Prefix) bei Supportvorfällen oder Migrationen
Entscheide außerdem, was global geteilt werden darf (z. B. öffentliche Feature-Flags, statische Metadaten) und dokumentiere es — versehentliche Globals sind eine häufige Quelle für Cross-Mandant-Exposition.
Mandantenbewusste Ratenlimits und Quotas
Selbst wenn Daten isoliert sind, können Mandanten gegenseitig durch geteilten Compute beeinträchtigen. Setze mandantenbewusste Limits an den Rändern:
- API-Rate-Limits pro Mandant (und oft pro Benutzer innerhalb eines Mandanten)
- Quotas für teure Operationen (Exporte, Report-Generierung, KI-Anfragen)
Mach die Limits sichtbar (Header, UI-Hinweise), damit Kunden verstehen, dass Throttling Policy und kein Systemfehler ist.
Hintergrundjobs: Queues pro Mandant partitionieren
Eine einzige gemeinsame Queue kann einen beschäftigten Mandanten die Worker dominieren lassen.
Gängige Lösungen:
- Separate Queues nach Tarif/Stufe (z. B.
free,pro,enterprise) - Partitionierte Queues nach Mandantenbucket (Hash von tenant_id in N Queues)
- Mandantenbewusste Scheduling-Strategien, sodass jeder Mandant fairen Anteil bekommt
Propagiere immer den Mandantenkontext in Job-Payloads und Logs, um Nebenwirkungen auf falsche Mandanten zu vermeiden.
Datei-/Objektspeicher: separate Pfade, Richtlinien und Keys
Bei S3-/GCS-ähnlichem Storage erfolgt Isolation meist per Pfad und Policy:
- Bucket-pro-Mandant für strenge Trennung (stärkere Grenzen, mehr Overhead)
- Gemeinsamer Bucket mit Mandanten-Prefixes (einfacher, erfordert sorgfältiges IAM und signierte URLs)
Was auch immer du wählst: validiere Uploads/Downloads auf Mandantenbesitz bei jeder Anfrage, nicht nur in der UI.
Umgang mit Noisy Neighbors und faire Ressourcennutzung
Multi-Tenant-Systeme teilen Infrastruktur; ein Mandant kann versehentlich (oder absichtlich) mehr als seinen fairen Anteil verbrauchen. Das ist das Noisy-Neighbor-Problem: eine einzelne laute Workload verschlechtert die Leistung für alle anderen.
Wie sich "noisy neighbor" zeigt
Stell dir ein Reporting-Feature vor, das ein Jahr Daten in CSV exportiert. Mandant A plant 20 Exporte um 9:00 Uhr. Diese Exporte sättigen CPU und DB-I/O, sodass die normalen Bildschirme von Mandant B anfangen zu timen — obwohl B nichts Ungewöhnliches tut.
Ressourcensteuerung: Limits, Quotas und Workload-Shaping
Vorbeugung beginnt mit expliziten Ressourcen-Grenzen:
- Ratenlimits (Requests pro Sekunde) pro Mandant und Endpoint, damit teure APIs nicht gespammt werden.
- Quotas (täglich/monatlich) für Exporte, E-Mails, KI-Aufrufe oder Hintergrundjobs.
- Workload-Shaping: schiebe schwere Aufgaben (Exporte, Importe, Re-Indexing) in Queues mit mandantenbezogenen Concurrency-Limits und Prioritätsregeln.
Ein praktisches Muster ist, interaktive Last von Batch-Workloads zu trennen: Benutzeranfragen auf eine schnelle Spur, alles andere in kontrollierte Queues.
Per-Mandant Circuit-Breaker und Bulkheads
Füge Sicherheitsventile hinzu, die anspringen, wenn ein Mandant Schwellenwerte überschreitet:
- Circuit-Breaker: teure Operationen temporär ablehnen oder verzögern, wenn Fehlerquoten, Latenz oder Queue-Depth für diesen Mandanten Grenzwerte überschreiten.
- Bulkheads: geteilte Pools (DB-Verbindungen, Worker-Threads, Cache) isolieren, sodass ein Mandant die globale Kapazität nicht erschöpft.
Gut umgesetzt kann Mandant A seine Exportgeschwindigkeit selbst schädigen, ohne Mandant B mitzureißen.
Wann einen Mandanten auf dedizierte Kapazität umziehen
Verschiebe einen Mandanten auf dedizierte Ressourcen, wenn er dauerhaft geteilte Annahmen sprengt: anhaltend hohe Durchsatzraten, unvorhersehbare Peaks, geschäftskritische Events, strenge Compliance-Anforderungen oder wenn sein Workload spezielles Tuning braucht. Eine einfache Regel: Wenn zum Schutz anderer Mandanten ständiges Drosseln eines zahlenden Kunden nötig wäre, ist es Zeit für dedizierte Kapazität (oder ein höherer Tarif), statt permanentem Firefighting.
Skalierungsmuster, die in Multi-Tenant-SaaS funktionieren
Mandanten‑Sicherheitsrisiken prüfen
Erhalte eine Bedrohungsmodell‑Checkliste für Lecks zwischen Mandanten, Hintergrundjobs und Caches.
Skalierung in Multi-Tenant-Umgebungen ist weniger "mehr Server" und mehr darum, dass das Wachstum eines Mandanten nicht alle anderen überrascht. Gute Muster machen Skalierung vorhersehbar, messbar und umkehrbar.
Horizontale Skalierung für zustandslose Dienste
Beginne damit, deine Web-/API-Schicht zustandslos zu gestalten: Sessions im Shared Cache speichern (oder tokenbasierte Auth nutzen), Uploads in Object Storage ablegen und lang laufende Arbeit in Hintergrundjobs verschieben. Wenn Requests nicht von lokalem Speicher abhängen, kannst du Instanzen hinter einen Load Balancer setzen und schnell horizontal skalieren.
Praktischer Tipp: Behalte den Mandantenkontext am Rand (aus Subdomain oder Headern abgeleitet) und übergebe ihn an jeden Request-Handler. Zustandslos heißt nicht mandantenlos — es heißt mandantenbewusst ohne Sticky-Server.
Per-Mandant-Hotspots: erkennen und glätten
Die meisten Skalierungsprobleme entstehen, weil "ein Mandant anders ist". Achte auf Hotspots wie:
- Ein Mandant erzeugt übermäßigen Traffic
- Einige Mandanten mit sehr großen Datensätzen
- Batchy Nutzung (End-of-Month-Reports, nächtliche Importe)
Glättungsmaßnahmen: per-Mandant-Ratenlimits, Queue-basierte Ingestion, Caching mandantenspezifischer Lesewege und Sharding großer Mandanten in separate Worker-Pools.
Read-Replicas, Partitionierung und asynchrone Workloads
Nutze Read-Replicas für leseintensive Workloads (Dashboards, Suche, Analytics) und halte Writes auf dem Primary. Partitionierung (nach Mandant, Zeit oder beidem) hilft, Indizes klein zu halten und Abfragen schnell. Für teure Aufgaben — Exporte, ML-Scoring, Webhooks — bevorzuge asynchrone Jobs mit Idempotenz, damit Retries die Last nicht multiplizieren.
Kapazitätsplanungssignale und einfache Schwellenwerte
Behalte einfache, mandantenbewusste Signale: p95-Latenz, Fehlerquote, Queue-Depth, DB-CPU und per-Mandant-Request-Rate. Setze einfache Schwellen (z. B. „Queue-Depth > N für 10 Minuten“ oder „p95 > X ms“), die Autoscaling oder temporäre Mandantenlimits triggern — bevor andere Mandanten es merken.
Observability und Betrieb nach Mandant
Multi-Tenant-Systeme fallen meist nicht global aus — sie versagen für einen Mandanten, ein Tarifniveau oder eine laute Workload. Wenn Logs und Dashboards nicht in Sekunden beantworten können, "welcher Mandant ist betroffen?", wird On-Call-Routine zu Ratespiel.
Mandantenbewusste Logs, Metriken und Traces
Beginne mit einem konsistenten Mandantenkontext über Telemetrie hinweg:
- Logs: Füge
tenant_id,request_idund eine stabileactor_id(User/Service) in jede Anfrage und jeden Hintergrundjob ein. - Metriken: Emitte Counter und Latenzhistogramme nach Mandanten-Tier zumindest (z. B.
tier=basic|premium) und nach hochleveligen Endpoints (nicht rohe URLs). - Traces: Propagiere Mandantenkontext als Trace-Attribute, sodass du einen langsamen Trace auf einen bestimmten Mandanten filtern und sehen kannst, wo Zeit verbracht wird (DB, Cache, Drittanbieter).
Halte die Kardinalität in Schach: Per-Mandant-Metriken für alle Mandanten können teuer werden. Ein gängiger Kompromiss ist Tier-Level-Metriken standardmäßig und Per-Mandant-Drilldown bei Bedarf (Sampling von Traces für „Top 20 Mandanten nach Traffic“ oder „Mandanten, die gerade SLOs brechen").
Sensible Daten in Telemetrie vermeiden
Telemetrie ist ein Datenexport-Kanal. Behandle sie wie Produktionsdaten.
Bevorzuge IDs statt Inhalte: logge customer_id=123 statt Namen, E-Mails, Tokens oder Query-Payloads. Führe Redaction in der Logger-/SDK-Schicht ein und blocklist übliche Secrets (Authorization-Header, API-Keys). Für Support-Workflows speichere Debug-Payloads in einem separaten, zugriffs-kontrollierten System — nicht in geteilten Logs.
SLOs nach Mandanten-Tier (ohne Überversprechen)
Definiere SLOs, die du tatsächlich durchsetzen kannst. Premium-Mandanten können engere Latenz-/Fehlerbudgets bekommen, aber nur, wenn du auch Kontrollen hast (Ratenlimits, Workload-Isolation, Prioritätsqueues). Veröffentliche Tier-SLOs als Targets und tracke sie pro Tier und für eine kuratierte Menge wichtiger Mandanten.
On-Call-Runbooks: häufige Vorfälle in Multi-Tenant-SaaS
Deine Runbooks sollten mit „betroffene Mandanten identifizieren“ beginnen und dann die schnellste isolierende Aktion:
- Noisy neighbor: Mandanten drosseln, schwere Jobs pausieren oder sie in eine niedrigere Prioritätsqueue verschieben.
- DB-Hotspots/runaway queries: Query-Timeouts aktivieren, Top-Queries nach Mandant inspizieren, Index anwenden oder Endpoint limitieren.
- Mandantenkontext-Bugs (Datenvermischung): Feature-Flag oder Endpoint sofort deaktivieren und Mandanten-Scoping in Zugriffskontrollen prüfen.
- Hintergrundjob-Überlastungen: Per-Mandanten-Queues entleeren, Concurrency begrenzen und mit Idempotenz-Schutz wiederholen.
Operativ ist das Ziel einfach: per Mandant detektieren, per Mandant enthalten und wiederherstellen, ohne alle anderen zu beeinträchtigen.
Deployments, Migrationen und mandantenweise Releases
Multi-Tenant-SaaS verändert den Rhythmus des Shippings. Du deployst nicht nur "eine App"; du deployst eine geteilte Laufzeit und geteilte Datenpfade, von denen viele Kunden gleichzeitig abhängen. Ziel ist, neue Features zu liefern, ohne alle Mandanten in einen synchronen Big-Bang-Upgrade zu zwingen.
Rolling-Deploys und migrationsarme Änderungen
Bevorzuge Deployment-Pattern, die gemischte Versionen kurz tolerieren (Blue/Green, Canary, Rolling). Das funktioniert nur, wenn deine DB-Änderungen ebenfalls gestaffelt sind.
Eine praktische Regel ist expand → migrate → contract:
- Expand: Neue Spalten/Tabellen/Indizes hinzufügen, ohne alten Code zu breaken.
- Migrate: Daten in Batches nachfüllen (oft pro Mandant) und verifizieren.
- Contract: Alte Felder entfernen, erst nachdem alle App-Instanzen sie nicht mehr nutzen.
Bei stark genutzten Tabellen mach Backfills inkrementell (und throttle), sonst erzeugst du während einer Migration selbst ein Noisy-Neighbor-Ereignis.
Tenant-spezifische Feature-Flags für sichere Rollouts
Mandantenbezogene Feature-Flags ermöglichen, Code global zu deployen, Verhalten aber selektiv zu aktivieren.
Das unterstützt:
- Early-Access-Programme für wenige Mandanten
- Schnelles Rollback, indem man ein Feature nur für betroffene Mandanten deaktiviert
- A/B-Tests ohne Forking der Deployments
Halte das Flag-System auditierbar: Wer hat was für welchen Mandanten wann aktiviert.
Versionierung und Erwartungen an Abwärtskompatibilität
Geh davon aus, dass manche Mandanten in Konfiguration, Integrationen oder Nutzungsverhalten hinterherhinken. Entwerfe APIs und Events mit klarer Versionierung, damit neue Producer alte Consumer nicht brechen.
Gängige interne Erwartungen:
- Neue Releases sollten alte und neue Shapes während der Migrationsfenster lesen können.
- Deprecations brauchen einen veröffentlichten Zeitplan (auch wenn es nur interne Notizen plus Email-Template ist).
Mandantenspezifisches Konfigurationsmanagement
Behandle Mandanten-Konfiguration als Produktfläche: sie braucht Validierung, Defaults und Änderungshistorie.
Speichere Konfiguration getrennt vom Code (idealerweise getrennt von Laufzeit-Secrets) und unterstütze einen Safe-Mode-Fallback, wenn Konfiguration ungültig ist. Eine einfache interne Seite wie /settings/tenants kann während Incident-Response und gestaffelten Rollouts Stunden sparen.
Wie KI-generierte Architekturen helfen (und ihre Grenzen)
Bauen und Credits verdienen
Teile, was du gebaut hast, mit Koder.ai und verdiene Credits über das Content‑Programm.
KI kann frühes Architekturdenken für Multi-Tenant-SaaS beschleunigen, ersetzt aber kein Engineering-Urteil, Tests oder Security-Reviews. Behandle sie als hochwertigen Brainstorming-Partner, der Entwürfe liefert — prüfe dann jede Annahme.
Was KI-Architektur leisten sollte (und nicht)
KI ist nützlich, um Optionen zu generieren und typische Fehlerquellen hervorzuheben (z. B. wo Mandantenkontext verloren gehen kann oder geteilte Ressourcen Überraschungen erzeugen). Sie darf dein Modell nicht entscheiden, Compliance nicht garantieren und Performance nicht validieren. Sie kann deine reale Traffic-Situation, Teamstärke oder Edge-Cases in Legacy-Integrationen nicht kennen.
Relevante Eingaben: Anforderungen, Einschränkungen, Risiken, Wachstum
Die Qualität der Ausgabe hängt von deinen Eingaben ab. Hilfreiche Inputs sind:
- Mandantenzahl heute vs. in 12–24 Monaten und erwartetes Datenvolumen pro Mandant
- Isolationserfordernisse (vertraglich, regulatorisch, Kundenerwartungen)
- Budget und operative Kapazität (On-Call-Reife, SRE-Unterstützung, Tooling)
- Latenzziele, Peak-Pattern und Burstiness pro Mandant
- Risikotoleranz: Was passiert, wenn ein Mandant einen anderen beeinträchtigt?
KI nutzen, um Musteroptionen mit Trade-offs vorzuschlagen
Fordere 2–4 Designkandidaten an (z. B. DB-pro-Mandant vs. Schema-pro-Mandant vs. Zeilen-Isolation) und bitte um eine klare Tabelle der Trade-offs: Kosten, betriebliche Komplexität, Blast-Radius, Migrationsaufwand und Skalierungsgrenzen. KI ist gut darin, Gotchas aufzulisten, die du in Designfragen für dein Team umwandeln kannst.
Wenn du vom "Draft-Architektur"-Status schneller zu einem Prototypen willst, können Vibe-Coding-Plattformen wie Koder.ai helfen, diese Entscheidungen mit Chat-Unterstützung in ein App-Skelett zu überführen — oft mit React-Frontend und Go + PostgreSQL Backend — damit du Mandantenkontext-Propagation, Ratenlimits und Migrationsworkflows früher validieren kannst. Features wie Planungsmodus sowie Snapshots/Rollback sind beim Iterieren an Multi-Tenant-Datenmodellen besonders nützlich.
KI zur Generierung von Threat-Models und Checklisten nutzen
KI kann ein einfaches Threat-Model entwerfen: Entry-Points, Trust-Boundaries, Mandantenkontext-Propagation und typische Fehler (z. B. fehlende Authorization-Checks in Hintergrundjobs). Nutze es, um Review-Checklisten für PRs und Runbooks zu erstellen — aber validiere mit echter Security-Expertise und eurer eigenen Vorfallhistorie.
Praktische Auswahl-Checkliste für dein Team
Die Wahl eines Multi-Tenant-Ansatzes ist weniger eine Frage der "Best Practice" als der Passung: Datensensitivität, Wachstumsrate und wie viel operative Komplexität ihr tragen könnt.
Schritt-für-Schritt-Checkliste (30-Minuten-Workshop)
-
Daten: Welche Daten werden über Mandanten geteilt (falls überhaupt)? Was darf niemals ko-lokalisiert werden?
-
Identität: Wo lebt die Mandantenidentität (Einladungslinks, Domains, SSO-Claims)? Wie wird Mandantenkontext bei jeder Anfrage etabliert?
-
Isolation: Entscheide die Standard-Isolationsebene (Zeile/Schema/DB) und identifiziere Ausnahmen (z. B. Enterprise-Kunden mit stärkerer Separation).
-
Skalierung: Identifiziere den ersten Skalierungsdruck, den du erwartest (Storage, Lese-Traffic, Hintergrundjobs, Analytics) und wähle das einfachste Muster, das ihn adressiert.
Fragen für Ingenieure und Security-Reviewer
- Wie verhindern wir Cross-Mandant-Zugriff, wenn ein Entwickler einen Filter vergisst?
- Wie ist unsere Audit-Story pro Mandant (wer hat was wann gemacht)?
- Wie handhaben wir Datenlöschung und -aufbewahrung pro Mandant?
- Wie groß ist der Blast-Radius einer fehlerhaften Migration oder einer runaway query?
- Können wir pro Mandant drosseln, ratenlimitieren und Ressourcen budgetieren?
Warnsignale, die tieferes Design erfordern
- „Wir fügen Mandantenchecks später hinzu.“
- Geteilte Admin-Tools, die ohne strikte Kontrollen alles sehen können.
- Keine Planung für Mandanten-Backups/Restore oder Incident-Response.
- Eine einzige Queue/Worker-Pool ohne Mandantenfairness.
Beispiel-"empfohlene nächste Schritte"-Zusammenfassung
Empfehlung: Starte mit zeilenbasierter Isolation + strenger Mandantenkontext-Durchsetzung, füge per-Mandant-Throttles hinzu und definiere einen Upgrade-Pfad zu Schema-/DB-Isolation für Hochrisiko-Mandanten.
Nächste Aktionen (2 Wochen): Threat-Model der Mandantengrenzen erstellen, Enforcement in einem Endpoint prototypisch implementieren und eine Migrationsprobe auf einer Staging-Kopie durchführen. Für Rollout-Anleitungen siehe /blog/tenant-release-strategies.