„Performance‑kritisch“ heißt nicht „schön, wenn schnell“. Es bedeutet: Das Erlebnis bricht zusammen, wenn die App auch nur leicht langsam, inkonsistent oder verzögert ist. Nutzer bemerken nicht nur das Ruckeln — sie verlieren Vertrauen, verpassen einen Moment oder machen Fehler.
Einige gängige App‑Typen machen das leicht sichtbar:
- Kamera und Video: Tippen auf den Auslöser soll sofort ein Foto erzeugen. Verzögerungen führen zum Verpassen des Moments. Vorschau‑Ruckler, langsamer Fokus oder verlorene Frames machen die App unzuverlässig.\n- Karten und Navigation: Der blaue Punkt muss sich flüssig bewegen, Umleitungen sollen sofort wirken, und die UI muss reaktionsfähig bleiben, während GPS, Datenladung und Rendering parallel laufen.\n- Trading und Finanzen: Ein verspätetes Kursupdate, ein verzögert registrierter Button oder ein eingefrorener Bildschirm während Volatilität können direkt zu Verlusten führen.\n- Spiele: Frame‑Drops und Input‑Verzögerung sind nicht nur unangenehm — sie verändern das Spiel. Konsistentes Frame‑Pacing ist genauso wichtig wie rohe FPS.
In all diesen Fällen ist Performance kein versteckter technischer Messwert. Sie ist sichtbar, fühlbar und wird innerhalb von Sekunden bewertet.
Was „native Frameworks“ bedeutet (ohne Buzzwords)
Wenn wir von nativen Frameworks sprechen, meinen wir den Bau mit den erstklassigen Tools jeder Plattform:
- iOS: Swift/Objective‑C mit Apples iOS‑SDKs (z. B. UIKit oder SwiftUI plus System‑Frameworks)
- Android: Kotlin/Java mit Android‑SDKs (z. B. Jetpack, Views/Compose plus Plattform‑APIs)
Native heißt nicht automatisch „besseres Engineering“. Es heißt, Ihre App spricht direkt die Sprache der Plattform — besonders wichtig, wenn Sie das Gerät stark beanspruchen.
Cross‑Platform‑Frameworks können für viele Produkte großartig sein, insbesondere wenn Entwicklungsgeschwindigkeit und geteilter Code wichtiger sind als jedes Millisekündchen. Dieser Artikel behauptet nicht „native immer“. Er argumentiert, dass bei wirklich performance‑kritischen Apps native Frameworks oft ganze Kategorien von Overhead und Beschränkungen eliminieren.
Die Dimensionen, die meist entscheiden
Wir bewerten Performance‑Anforderungen entlang praktischer Dimensionen:
- Latenz: Touch‑Antwort, Tippen, Echtzeit‑Interaktionen, Audio/Video‑Sync
- Rendering: flüssiges Scrollen, Animationen, Frame‑Pacing, GPU‑getriebene UI
- Batterie und Hitze: nachhaltige Effizienz über lange Sessions
- Hardware/OS‑Zugriff: Kamera‑Pipelines, Sensoren, Bluetooth, Hintergrundausführung, On‑Device‑ML
Das sind die Bereiche, in denen Nutzer den Unterschied spüren — und in denen native Frameworks oft Vorteile haben.
Cross‑Platform‑Frameworks wirken „nah genug“ bei typischen Bildschirmen, Formularen und netzwerkgetriebenen Flows. Der Unterschied tritt meist dort auf, wo eine App empfindlich auf kleine Verzögerungen reagiert, konsistentes Frame‑Pacing benötigt oder das Gerät über längere Zeit stark belastet.
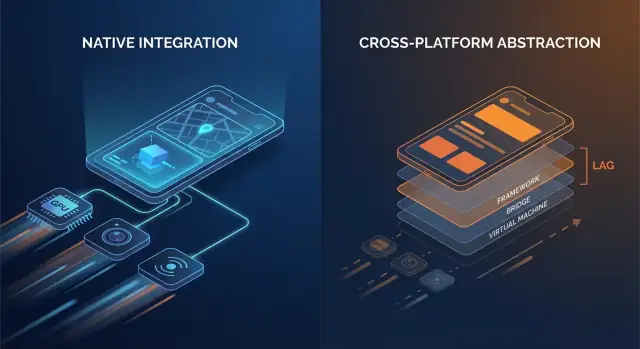
Die zusätzlichen Schichten, die sich summieren
Nativer Code spricht im Allgemeinen direkt mit OS‑APIs. Viele Cross‑Platform‑Stacks fügen eine oder mehrere Übersetzungsschichten zwischen App‑Logik und dem, was das Telefon letztlich rendert, hinzu.
Typische Overhead‑Punkte sind:
- Bridge‑Aufrufe und Kontextwechsel: Wenn UI‑Schicht und Business‑Logik in unterschiedlichen Laufzeiten leben (z. B. eine verwaltete Runtime oder Scripting‑Engine plus native Schicht), kann jede Interaktion einen Hop über eine Grenze erfordern.\n- Serialisierung und Kopien: Daten, die über Grenzen gehen, müssen oft konvertiert werden (JSON‑ähnliche Payloads, typisierte Maps, Byte‑Buffer). Diese Konvertierungsarbeit kann auf heißen Pfaden wie Scrollen oder Tippen sichtbar werden.\n- Zusätzliche View‑Hierarchien: Manche Frameworks bauen einen eigenen UI‑Baum auf und mappen ihn dann auf native Views (oder rendern auf ein Canvas). Reconciliation und Layout können teurer werden als ein direkter nativer View‑Update.
Keiner dieser Kosten ist isoliert riesig. Das Problem ist Wiederholung: Sie können bei jeder Geste, jedem Animationstakt und jedem Listenelement auftreten.
Startzeit und Laufzeit‑„Jank"
Overhead betrifft nicht nur rohe Geschwindigkeit, sondern auch wann Arbeit passiert.
- Startzeit kann sich verlängern, wenn die App eine zusätzliche Runtime initialisieren, gebündelte Assets laden, eine UI‑Engine aufwärmen oder Zustand wiederherstellen muss, bevor der erste Bildschirm interaktiv ist.\n- Laufzeit‑Jank entsteht oft durch unvorhersehbare Pausen: Garbage Collection, Bridge‑Backpressure, teures Diffing oder eine lange Aufgabe, die den Main‑Thread blockiert, genau wenn die UI ihren nächsten Frame liefern muss.
Native Apps können auch diese Probleme haben — aber es gibt weniger bewegliche Teile, also weniger Orte, an denen Überraschungen lauern.
Ein einfaches Mentalmodell
Denken Sie: weniger Schichten = weniger Überraschungen. Jede zusätzliche Schicht kann gut engineered sein, aber sie erhöht trotzdem Scheduling‑Komplexität, Speicherdruck und Übersetzungsarbeit.
Wann Overhead in Ordnung ist — und wann nicht
Für viele Apps ist der Overhead akzeptabel und der Produktivitätsgewinn real. Für performance‑kritische Apps — schnell scrollende Feeds, intensive Animationen, Echtzeit‑Zusammenarbeit, Audio/Video‑Verarbeitung oder alles, was latenzsensitiv ist — können diese „kleinen“ Kosten schnell für Nutzer sichtbar werden.
UI‑Flüssigkeit: Frames, Jank und native Rendering‑Pfade
Eine flüssige UI ist kein „Nice‑to‑have“ — sie signalisiert Qualität. Auf einem 60‑Hz‑Bildschirm hat Ihre App etwa 16,7 ms, um jeden Frame zu produzieren. Auf 120‑Hz‑Geräten sinkt dieses Budget auf 8,3 ms. Wird dieses Zeitfenster verpasst, sehen Nutzer Stottern (Jank): Scrollen, das „hakt“, Übergänge, die ruckeln, oder ein Gesture‑Response, das der Finger voraus ist.
Warum verpasste Frames so leicht auffallen
Menschen zählen Frames nicht bewusst, aber sie bemerken Inkonsistenz. Ein einzelner verlorener Frame bei einem langsamen Fade ist vielleicht tolerierbar; einige verlorene Frames beim schnellen Scrollen sind sofort deutlich. Hochfrequente Bildschirme erhöhen die Erwartung — wer 120 Hz erlebt hat, empfindet inkonsistente Darstellung als deutlich störender als bei 60 Hz.
Der Main‑Thread ist der übliche Engpass
Die meisten UI‑Frameworks verlassen sich weiterhin auf einen primären/UI‑Thread zur Koordination von Input‑Handling, Layout und Zeichnen. Jank entsteht oft, wenn dieser Thread in einem Frame zu viel Arbeit macht:
- Schwere Layout‑Pässe: komplexe View‑Hierarchien, verschachtelte Container oder häufige Relayouts durch Größenänderungen.\n- Teure Animationen: Eigenschaften animieren, die Relayout oder Re‑Rasterisierung erzwingen statt GPU‑freundliche Transforms zu nutzen.\n- Synchrone Arbeit in UI‑Callbacks: JSON‑Parsing, Formatieren großer Textblöcke oder Business‑Logik während Scroll-/Gesture‑Ereignissen.
Native Frameworks haben oft gut optimierte Pipelines und klarere Best Practices, um Arbeit vom Main‑Thread fernzuhalten, Layout‑Invalidierungen zu minimieren und GPU‑freundliche Animationen zu nutzen.
Native Komponenten vs custom‑rendered UI
Ein zentraler Unterschied ist der Rendering‑Pfad:
- Plattform‑native Komponenten mappen normalerweise direkt auf OS‑optimierte Widgets und Compositing‑Systeme.\n- Custom‑rendered UI‑Ansätze (häufig in Cross‑Platform‑Stacks) können einen separaten Render‑Tree, zusätzliche Texture‑Uploads oder Reconciliation‑Arbeit hinzufügen. Das kann gut funktionieren — bis Ihr Bildschirm animation‑ oder listenlastig wird und der Overhead mit dem engen Frame‑Budget konkurriert.
Wo man es spürt: reale Bildschirm‑Beispiele
Komplexe Listen sind der klassische Stresstest: schnelles Scrollen + Bildladen + dynamische Zellhöhen können Layout‑Churn und GC/Memory‑Druck erzeugen.
Transitions können Pipeline‑Ineffizienzen offenbaren: Shared‑Element‑Animationen, unscharfe Hintergründe und geschichtete Schatten sind visuell reich, können aber GPU‑Kosten und Overdraw steigern.
Gesture‑intensive Bildschirme (Drag‑to‑reorder, Swipe‑Cards, Scrubber) sind gnadenlos, weil die UI kontinuierlich reagieren muss. Kommen Frames zu spät, fühlt sich die UI nicht mehr „am Finger“ an — genau das vermeiden Performance‑kritische Apps.
Niedrige Latenz: Touch, Tippen, Audio und Echtzeit‑UX
Latenz ist die Zeit zwischen Nutzeraktion und Reaktion der App. Nicht die allgemeine „Geschwindigkeit“, sondern die Lücke, die Sie fühlen, wenn Sie tippen, ziehen, eine Linie zeichnen oder eine Note spielen.
Nützliche Faust‑Regeln:
- 0–50 ms: wirkt sofort. Taps und Tippen fühlen sich direkt verbunden.\n- 50–100 ms: meist akzeptabel, bei Drag/ Scrub beginnt „Weichheit“ sichtbar zu werden.\n- 100–200 ms: spürbar. Tippen fühlt sich hinterher an; Linien „jagen“ dem Stift hinterher.\n- 200 ms+: frustrierend. Nutzer verlangsamen ihren Input, um Kompensation zu erreichen.
Performance‑kritische Apps — Messaging, Notizen, Trading, Navigation, Kreativ‑Tools — leben und sterben an diesen Latenzen.
Event‑Loops, Scheduling und „Thread‑Hops"
Viele Frameworks behandeln Input in einem Thread, führen App‑Logik in einem anderen aus und fordern dann ein UI‑Update an. Wenn dieser Pfad lang oder inkonsistent ist, entstehen Latenzspitzen.
Cross‑Platform‑Schichten können zusätzliche Schritte hinzufügen:
- Input kommt an → wird in Framework‑Events übersetzt\n- Logik läuft in einer separaten Runtime (mit eigenem Event‑Loop)\n- Zustandsänderungen werden serialisiert und zurückgeschickt\n- UI‑Updates werden später geplant und verpassen womöglich den nächsten Frame
Jeder Hand‑Off (ein „Thread‑Hop“) fügt Overhead und vor allem Jitter hinzu — schwankende Antwortzeiten, die oft schlimmer wirken als eine gleichmäßige Verzögerung.
Native Frameworks haben tendenziell einen kürzeren, vorhersehbareren Pfad von Touch → UI‑Update, weil sie näher am OS‑Scheduler, Input‑System und Rendering‑Pipeline ausgerichtet sind.
Echtzeit‑UX: Audio, Video und Live‑Collaboration
Manche Szenarien haben harte Grenzen:
- Audio‑Monitoring / Instrumente: Round‑Trip‑Latenz sollte grob unter ~20 ms bleiben, damit es spielbar wirkt.\n- Voice/Video‑Calls: Buffering kann Netzprobleme glätten, aber UI‑Steuerungen (Mute, Lautsprecher, Untertitel) müssen sofort reagieren.\n- Live‑Collaboration (Docs, Whiteboards): Lokale Änderungen müssen sofort sichtbar sein, auch wenn Remote‑Sync länger dauert.
Native‑First‑Implementierungen erleichtern es, den „kritischen Pfad“ kurz zu halten — Input und Rendering werden priorisiert gegenüber Hintergrundarbeit, sodass Echtzeit‑Interaktionen tight und vertrauenswürdig bleiben.
Tiefer Hardware‑ und OS‑Zugriff: Native‑First, meist
UX validieren, bevor du optimierst
Baue die wichtigsten Abläufe schnell, sodass du nur das optimierst, was Nutzer wirklich spüren.
Performance ist nicht nur CPU‑Speed oder Framerate. Für viele Apps entscheiden die Momente am Rand — wo Ihr Code die Kamera, Sensoren, Funkmodule und OS‑Services berührt. Diese Fähigkeiten werden zuerst als native APIs entworfen und ausgeliefert, und das prägt, was in Cross‑Platform‑Stacks machbar und stabil ist.
Hardwarezugriff ist selten generisch
Funktionen wie Kamera‑Pipelines, AR, BLE, NFC und Motion‑Sensoren erfordern oft enge Integration mit gerätespezifischen Frameworks. Cross‑Platform‑Wrapper decken die gängigen Fälle ab, aber fortgeschrittene Szenarien zeigen schnell Lücken.
Beispiele, wo native APIs wichtig sind:
- Erweiterte Kamera‑Kontrollen: manueller Fokus und Belichtung, RAW‑Capture, High‑Frame‑Rate‑Video, HDR‑Tuning, Multikamera‑Wechsel, Tiefendaten und Verhalten bei wenig Licht.\n- AR‑Erlebnisse: ARKit/ARCore entwickeln sich schnell (Occlusion, Plane Detection, Scene Reconstruction).\n- BLE und Background‑Modi: Scanning, Reconnect‑Verhalten und „funktioniert zuverlässig im Standby“ hängen oft von Plattform‑Hintergrundregeln ab.\n- NFC: Secure‑Element‑Zugriff, Card‑Emulation‑Limits und Reader‑Sessions sind stark plattformspezifisch.\n- Health‑Daten: HealthKit/Google Fit‑Berechtigungen, Datentypen und Background‑Delivery sind nuanciert und verlangen native Handhabung.
OS‑Updates kommen native‑first
Wenn iOS oder Android neue Features liefert, sind die offiziellen APIs sofort in den nativen SDKs verfügbar. Cross‑Platform‑Layer brauchen oft Wochen oder länger, um Bindings, Plugins und Randfälle zu aktualisieren.
Diese Verzögerung ist nicht nur unbequem — sie kann Zuverlässigkeitsrisiken schaffen. Wenn ein Wrapper nicht für ein neues OS‑Release aktualisiert wurde, können auftreten:
- gebrochene Berechtigungsabläufe,\n- eingeschränkte Hintergrundaufgaben,\n- Crashes durch geändertes Systemverhalten,\n- Regressionen auf bestimmten Geräten.
Für performance‑kritische Apps reduziert Native das Risiko, auf den Wrapper warten zu müssen, und erlaubt Teams, neue OS‑Fähigkeiten sofort zu nutzen — oft der Unterschied zwischen Feature‑Launch in diesem Quartal oder dem nächsten.
Schnelligkeit in einer kurzen Demo ist nur die halbe Wahrheit. Die Performance, an die sich Nutzer erinnern, hält auch nach 20 Minuten Nutzung: das Telefon ist warm, der Akku sinkt und die App war zwischendurch im Hintergrund.
Wo Batterieverbrauch wirklich herkommt
Die meisten „mysteriösen“ Batterie‑Drain‑Fälle sind selbstgemacht:
- Wake Locks und runaway Timers verhindern, dass die CPU schläft, selbst wenn der Bildschirm aus ist.\n- Hintergrundarbeit, die nie richtig stoppt (Polling, häufige Standortabfragen, wiederholte Netzwerk‑Retries) summiert sich schnell.\n- Übermäßiges Redrawen — UI neu aufbauen oder Animationen öfter rendern als nötig — hält CPU/GPU beschäftigt.
Native Frameworks bieten in der Regel klarere, vorhersehbarere Tools zum effizienten Planen von Arbeit (Background Tasks, Job Scheduling, OS‑verwaltete Refreshes), sodass Sie insgesamt weniger Arbeit zu ungünstigen Zeiten durchführen.
Speicherdruck: die versteckte Ursache für Stottern
Speicher beeinflusst nicht nur Abstürze — er beeinflusst Glätte.
Viele Cross‑Platform‑Stacks nutzen eine managed Runtime mit Garbage Collection (GC). Wenn Speicher wächst, kann GC die App kurz anhalten, um aufzuräumen. Sie müssen die Interna nicht kennen, um es zu spüren: gelegentliche Mikro‑Freezes beim Scrollen, Tippen oder bei Übergängen.
Native Apps folgen oft Plattformmustern (z. B. ARC‑artige automatische Referenzzählung auf Apple‑Plattformen), die Aufräumarbeit gleichmäßiger verteilen. Das führt zu weniger überraschenden Pausen — besonders bei enger Speichersituation.
Hitze und nachhaltige Leistung
Hitze ist Performance. Wenn Geräte wärmer werden, drosselt das OS CPU/GPU‑Geschwindigkeiten zum Schutz der Hardware, und Framerates fallen. Das passiert bei anhaltenden Workloads wie Spielen, Navigation, Kamera + Filter oder Echtzeit‑Audio.
Nativer Code kann in diesen Szenarien energieeffizienter sein, weil er hardware‑beschleunigte, OS‑abgestimmte APIs für schwere Aufgaben nutzen kann — native Video‑Pipelines, effiziente Sensorabfrage und Plattform‑Codecs — und so weniger Arbeit in Wärme verwandelt.
Wenn „schnell“ auch „kühl und stabil“ bedeuten soll, hat Native oft die Nase vorn.
Profiling und Debugging: die echten Engpässe sehen
Verdiene Credits für dein Projekt
Teile, was du gebaut hast, und verdiene Credits, die du auf Koder.ai einlösen kannst.
Performance‑Arbeit gelingt oder scheitert an Sichtbarkeit. Native Frameworks liefern meist die tiefsten Hooks ins Betriebssystem, die Runtime und die Rendering‑Pipeline — weil sie vom selben Anbieter stammen, der diese Schichten definiert.
Native Apps können Profiler an den Grenzen anbringen, an denen Verzögerungen entstehen: Main‑Thread, Render‑Thread, System‑Compositor, Audio‑Stack und Netzwerk‑/Storage‑Subsysteme. Wenn Sie einem Stotterer nachjagen, der alle 30 Sekunden auftritt, oder einem Batterie‑Drain, der nur auf bestimmten Geräten auftaucht, sind diese „unterhalb des Frameworks“ Traces oft der einzige Weg zu einer klaren Antwort.
Sie müssen die Tools nicht auswendig kennen, aber es hilft, zu wissen, was existiert:
- Xcode Instruments (Time Profiler, Allocations, Leaks, Core Animation, Energy Log)\n- Xcode Debugger (Thread‑Inspektion, Memory Graph, symbolische Breakpoints)\n- Android Studio Profiler (CPU, Memory, Network, Energy)\n- Perfetto / System Trace (systemweite Tracing‑Tools auf Android)\n- GPU‑Tools wie Xcodes Metal‑Werkzeuge oder herstellerseitige GPU‑Inspektoren (zur Diagnose von Overdraw, Shader‑Kosten, Frame‑Pacing)
Diese Tools beantworten konkrete Fragen: „Welche Funktion ist heiß?“, „Welches Objekt wird nicht freigegeben?“, „Welcher Frame hat seine Deadline verpasst und warum?"
Die letzten 5% Bugs: Freezes, Leaks und Frame‑Drops
Die härtesten Performance‑Probleme verstecken sich oft in Randfällen: eine seltene Synchronisations‑Deadlock, ein langsames JSON‑Parsing im Main‑Thread, eine einzelne View, die teures Layout auslöst, oder ein Speicherleck, das erst nach 20 Minuten auftritt.
Native Profiling erlaubt es, Symptome (Freeze oder Jank) mit Ursachen (konkreter Stack, Allokationsmuster oder GPU‑Spike) zu korrelieren, anstatt auf Trial‑and‑Error angewiesen zu sein.
Schnellere Fixes für hoch‑impact Probleme
Bessere Sichtbarkeit verkürzt die Zeit bis zur Lösung, weil Debatten durch Beweise ersetzt werden. Teams können einen Trace teilen und sich schnell auf den Engpass einigen — oft verwandelt sich Tage langer Spekulation in einen fokussierten Patch und messbares Vorher/Nachher.
Zuverlässigkeit in großem Maßstab: Geräte, OS‑Updates und Edge‑Cases
Performance ist nicht die einzige Sache, die beim Ausliefern an Millionen Geräte bricht — Konsistenz tut es auch. Dieselbe App kann sich auf verschiedenen OS‑Versionen, OEM‑Customizations und sogar GPU‑Treibern unterschiedlich verhalten. Zuverlässigkeit auf großer Skala heißt, Ihre App vorhersehbar zu halten, obwohl das Ökosystem es nicht ist.
Warum „gleiches Android/iOS“ nicht wirklich gleich ist
Bei Android können OEM‑Skins Hintergrundlimits, Benachrichtigungen, Dateiauswahl und Energiemanagement anpassen. Zwei Geräte mit derselben Android‑Version unterscheiden sich womöglich, weil Hersteller unterschiedliche Systemkomponenten und Patches ausliefern.
GPUs stellen eine weitere Variable dar. Vendor‑Treiber (Adreno, Mali, PowerVR) divergieren in Shader‑Präzision, Texture‑Formaten und Optimierungsverhalten. Ein Rendering‑Pfad, der auf einer GPU gut aussieht, kann auf einer anderen Flackern, Banding oder seltene Crashes zeigen — besonders bei Video, Kamera und Custom‑Grafik.
iOS ist enger, aber OS‑Updates verschieben trotzdem Verhalten: Berechtigungsabläufe, Keyboard/Autofill‑Eigenheiten, Audio‑Session‑Regeln und Policies für Hintergrundaufgaben ändern sich mitunter zwischen Minor‑Releases.
Warum native oft Kantenfälle vorhersehbarer handhabt
Native Plattformen liefern die „echten“ APIs zuerst. Wenn das OS sich ändert, spiegeln native SDKs und Dokumentation diese Änderungen schnell wider, und Platform‑Tooling (Xcode/Android Studio, System‑Logs, Crash‑Symbole) stimmt mit dem überein, was auf Geräten läuft.
Cross‑Platform‑Stacks fügen eine Übersetzungsschicht hinzu: Framework, Runtime und Plugins. Wenn ein Edge‑Case auftritt, debuggen Sie sowohl Ihre App als auch die Brücke.
Abhängigkeitsrisiko: Updates, Breaking Changes und Plugin‑Qualität
Framework‑Upgrades können Laufzeitänderungen einführen (Threading, Rendering, Texteingabe, Gesten), die nur auf bestimmten Geräten fehlschlagen. Plugins können schlimmer sein: manche sind dünne Wrapper; andere binden schweren nativen Code mit uneinheitlicher Wartung ein.
Checkliste: Drittbibliotheken in kritischen Pfaden prüfen
- Maintenance: aktuelle Releases, aktives Issue‑Triaging, klare Verantwortlichkeiten.\n- Native Parität: nutzt offizielle Plattform‑APIs (keine privaten/unsupported Hooks).\n- Performance: Benchmarks, vermeidet zusätzliche Kopien/Allokationen, minimale Bridge‑Hops.\n- Fehlermodi: Graceful Fallbacks, Timeouts und Fehlerberichte.\n- Kompatibilität: getestet über OS‑Versionen, OEM‑Geräte und GPU‑Vendors.\n- Observability: Logs, Crash‑Symbole und reproduzierbare Testfälle.\n- Upgrade‑Safety: Semver‑Disziplin, Changelogs, Migrationshinweise.
Auf großer Skala geht Zuverlässigkeit selten um einen Bug — es geht darum, die Anzahl der Schichten zu reduzieren, in denen Überraschungen lauern können.
Kostenlos starten, später hochskalieren
Beginne mit dem Free-Tarif und upgrade, wenn deine Performance-Ziele mehr erfordern.
Manche Workloads bestrafen selbst kleine Mengen Overhead. Wenn Ihre App anhaltend hohe FPS benötigt, schwere GPU‑Arbeit leistet oder enge Kontrolle über Decoding und Buffering verlangt, gewinnt native meist, weil sie die schnellsten Pfade der Plattform direkt ansteuern kann.
Workloads, die stark für Native sprechen
Native passt klar zu 3D‑Szenen, AR‑Erlebnissen, High‑FPS‑Games, Video‑Editing und kamerazentrierten Apps mit Echtzeit‑Filtern. Diese Use‑Cases sind nicht nur „rechenintensiv“ — sie sind Pipeline‑intensiv: große Texturen und Frames wandern Dutzende Male pro Sekunde zwischen CPU, GPU, Kamera und Encodern.
Zusätzliche Kopien, späte Frames oder fehlende Synchronisation zeigen sich sofort als verlorene Frames, Überhitzung oder laggy Controls.
Direkter Zugriff auf GPU‑APIs, Codecs und Beschleunigung
Auf iOS kann nativer Code direkt mit Metal und dem System‑Media‑Stack sprechen. Auf Android ist der Zugriff auf Vulkan/OpenGL sowie Plattform‑Codecs und Hardware‑Beschleunigung über das NDK und Media‑APIs möglich.
Das ist wichtig, weil GPU‑Command‑Submission, Shader‑Kompilierung und Texture‑Management empfindlich darauf reagieren, wie die App Arbeit plant.
Rendering‑Pipelines und Texture‑Uploads (auf hoher Ebene)
Ein typischer Echtzeit‑Pipeline‑Fluss: Frames capturen oder laden → Formate konvertieren → Texturen uploaden → GPU‑Shader laufen lassen → UI compositen → präsentieren.
Nativer Code kann Overhead reduzieren, indem er Daten länger in GPU‑freundlichen Formaten hält, Draw‑Calls batcht und wiederholte Texture‑Uploads vermeidet. Selbst eine unnötige Konvertierung (z. B. RGBA ↔ YUV) pro Frame kann genug Kosten hinzufügen, um flüssige Wiedergabe zu zerstören.
ML‑Inference: Durchsatz, Latenz und Energie
On‑Device‑ML hängt oft von Delegates/Backends ab (Neural Engine, GPU, DSP/NPU). Native Integration bringt diese früher und mit mehr Tuning‑Optionen — wichtig, wenn Ihnen Inferenzlatenz und Akku wichtig sind.
Hybride Strategie: native Module für Hotspots
Sie brauchen nicht immer eine vollständig native App. Viele Teams behalten eine Cross‑Platform‑UI für die meisten Bildschirme und ergänzen native Module für Hotspots: Kamera‑Pipelines, Custom‑Renderer, Audio‑Engines oder ML‑Inference.
Das liefert dort nahezu native Performance, wo es zählt, ohne alles neu zu schreiben.
Die Framework‑Wahl ist weniger Ideologie als Abgleich zwischen Nutzererwartungen und Gerätenotwendigkeiten. Wenn Ihre App instant wirkt, kühl bleibt und unter Last flüssig bleibt, fragt kaum jemand nach der Implementierung.
Praktische Entscheidungs‑Matrix
Beantworten Sie diese Fragen, um schnell einzuschränken:
- Nutzererwartungen: Ist das eine Utility‑App, bei der gelegentliche Hänger tolerierbar sind, oder ein Erlebnis, bei dem Stottern Vertrauen zerstört (Banking, Navigation, Live‑Collab, Creator‑Tools)?\n- Hardware‑Bedarf: Brauchen Sie Kamera‑Pipelines, Bluetooth‑Peripherie, Sensoren, Hintergrundverarbeitung, niedrige Latenz‑Audio, AR oder schwere GPU‑Arbeit? Je näher „close to the metal“, desto mehr zahlt Native.\n- Zeitplan und Iterationsgeschwindigkeit: Cross‑Platform kann Time‑to‑Market für einfache UIs und geteilte Flows reduzieren. Native kann beim Performance‑Tuning schneller sein, weil Sie direkt mit Plattform‑Tooling und APIs arbeiten.\n- Team‑Skills und Hiring: Ein starkes iOS/Android‑Team liefert native höherwertigen Code schneller. Ein kleines Team mit Web‑Background erreicht schneller ein MVP mit Cross‑Platform — wenn Performance‑Constraints moderat sind.
Wenn Sie mehrere Richtungen prototypen, hilft es, Produktflüsse schnell zu validieren, bevor Sie tief in native Optimierung investieren. Beispielsweise nutzen Teams manchmal Koder.ai, um per Chat ein funktionierendes Web‑App‑Prototyp (React + Go + PostgreSQL) aufzusetzen, UX und Datenmodell zu testen und erst dann in eine native oder hybride Mobile‑Build zu investieren.
Was „Hybrid“ wirklich heißt (und warum es oft gewinnt)
Hybrid muss nicht „Web in einer App“ bedeuten. Für performance‑kritische Produkte heißt Hybrid oft:
- Nativer Kern + geteilter Business‑Logic: Networking, State und Domain‑Logik geteilt; UI und performance‑sensible Teile nativ.\n- Native Shell + geteilte UI, wo sicher: Geteilter UI‑Code für statische oder formularlastige Bildschirme; animation‑ oder echtzeitlastige Views nativ.
So begrenzen Sie Risiko: Sie optimieren die heißesten Pfade, ohne alles umzuschreiben.
Erst messen, dann entscheiden
Bevor Sie sich verpflichten, bauen Sie einen kleinen Prototyp des schwierigsten Bildschirms (z. B. Live‑Feed, Editor‑Timeline, Karte + Overlays). Benchmarks: Frame‑Stabilität, Input‑Latenz, Speicher und Akku über 10–15 Minuten. Nutzen Sie diese Daten statt Vermutungen.
Wenn Sie ein KI‑gestütztes Build‑Tool wie Koder.ai für frühe Iterationen nutzen, behandeln Sie es als Beschleuniger für Architektur und UX‑Exploration — nicht als Ersatz für Geräte‑Level‑Profiling. Sobald Sie ein performance‑kritisches Erlebnis anvisieren, gilt: messen auf echten Geräten, Performance‑Budgets setzen und kritische Pfade (Rendering, Input, Media) so nah wie nötig an der nativen Schicht halten.
Vermeiden Sie verfrühte Optimierung
Beginnen Sie damit, die App korrekt und beobachtbar zu machen (Basis‑Profiling, Logging, Performance‑Budgets). Optimieren Sie nur, wenn Sie einen Bottleneck identifizieren, den Nutzer spüren — so verschwenden Teams keine Wochen auf Millisekunden, die nicht im kritischen Pfad liegen.