30. Aug. 2025·8 Min
Nginx vs HAProxy: Den richtigen Reverse-Proxy wählen
Vergleich Nginx vs. HAProxy als Reverse-Proxies: Performance, Load-Balancing, TLS, Observability, Security und typische Setups, um die beste Wahl zu treffen.
Vergleich Nginx vs. HAProxy als Reverse-Proxies: Performance, Load-Balancing, TLS, Observability, Security und typische Setups, um die beste Wahl zu treffen.
Ein Reverse-Proxy ist ein Server, der vor deinen Anwendungen steht und zuerst Client-Anfragen entgegennimmt. Er leitet jede Anfrage an den richtigen Backend-Dienst (deine App-Server) weiter und gibt die Antwort an den Client zurück. Nutzer sprechen mit dem Proxy; der Proxy spricht mit deinen Apps.
Ein Forward-Proxy funktioniert in die andere Richtung: Er steht vor den Clients (z. B. in einem Unternehmensnetzwerk) und leitet deren ausgehende Anfragen ins Internet weiter. Er dient hauptsächlich dazu, Client-Traffic zu kontrollieren, zu filtern oder zu verbergen.
Ein Load Balancer wird oft als Reverse-Proxy implementiert, hat aber einen speziellen Fokus: die Verteilung von Traffic auf mehrere Backend-Instanzen. Viele Produkte (inkl. Nginx und HAProxy) übernehmen sowohl Reverse-Proxying als auch Load-Balancing, weshalb die Begriffe manchmal synonym verwendet werden.
Die meisten Deployments beginnen aus einem oder mehreren dieser Gründe:
/api an einen API-Service, / an eine Web-App).Reverse-Proxies fronten häufig Websites, APIs und Microservices — entweder am Edge (öffentliches Internet) oder intern zwischen Services. In modernen Stacks werden sie außerdem als Bausteine für Ingress-Gateways, Blue/Green-Deployments und Hochverfügbarkeits-Setups verwendet.
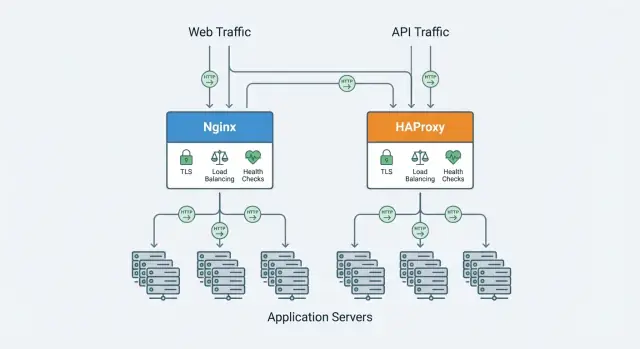
Nginx und HAProxy überschneiden sich, unterscheiden sich aber in der Gewichtung ihrer Stärken. In den nächsten Abschnitten vergleichen wir Entscheidungsfaktoren wie Leistung bei vielen Verbindungen, Load-Balancing und Health-Checks, Protokollunterstützung (HTTP/2, TCP), TLS-Funktionen, Observability und die tägliche Konfiguration und den Betrieb.
Nginx wird weitgehend sowohl als Webserver als auch als Reverse-Proxy eingesetzt. Viele Teams starten damit, eine öffentliche Website zu bedienen, und erweitern seine Rolle später, um vor Anwendungsservern zu sitzen — TLS zu handhaben, Traffic zu routen und Lastspitzen abzufedern.
Nginx spielt seine Stärken aus, wenn dein Traffic überwiegend HTTP(S) ist und du eine einzige „Eingangstür“ willst, die vieles kann. Besonders stark ist es bei:
X-Forwarded-For, Security-Header)Weil es sowohl Inhalte ausliefern als auch zu Apps proxyn kann, ist Nginx eine gängige Wahl für kleine bis mittlere Setups, in denen man weniger Komponenten bevorzugt.
Beliebte Fähigkeiten sind:
Nginx wird oft gewählt, wenn du einen einzigen Zugangspunkt brauchst für:
Wenn dein Fokus reichhaltiges HTTP-Handling ist und du die Kombination aus Web-Serving und Reverse-Proxying magst, ist Nginx häufig die Standard-Auswahl.
HAProxy (High Availability Proxy) wird meist als Reverse-Proxy und Load-Balancer eingesetzt, der vor einer oder mehreren Anwendungsservern steht. Er nimmt eingehenden Traffic an, wendet Routing- und Traffic-Regeln an und leitet Anfragen an gesunde Backends weiter — dabei bleiben die Antwortzeiten oft stabil, selbst bei hoher Konkurrenz.
Teams setzen HAProxy typischerweise für Traffic-Management ein: Verteilung von Anfragen über mehrere Server, Verfügbarkeit bei Ausfällen sicherstellen und Lastspitzen glätten. Es ist eine häufige Wahl am „Edge“ (North–South-Traffic) und auch zwischen internen Services (East–West), besonders wenn vorhersehbares Verhalten und starkes Verbindungsmanagement wichtig sind.
HAProxy ist bekannt für den effizienten Umgang mit großen Mengen gleichzeitiger Verbindungen. Das ist wichtig bei vielen gleichzeitig verbundenen Clients (starke APIs, lang gehaltene Verbindungen, chatty Microservices), wenn der Proxy reaktiv bleiben soll.
Seine Load-Balancing-Fähigkeiten sind ein Hauptgrund für die Wahl. Neben einfachem Round-Robin unterstützt HAProxy mehrere Algorithmen und Routing-Strategien, die helfen:
Health-Checks sind ein weiterer Vorteil. HAProxy kann Backends aktiv überprüfen und automatisch ungesunde Instanzen aus der Rotation nehmen und wieder hinzufügen, wenn sie sich erholt haben. In der Praxis reduziert das Ausfallzeiten und verhindert, dass „halb kaputte“ Deployments alle Nutzer betreffen.
HAProxy kann auf Layer 4 (TCP) und Layer 7 (HTTP) arbeiten.
Der praktische Unterschied: L4 ist generell einfacher und sehr schnell für TCP-Forwarding, während L7 reichhaltigere Routing- und Anfragelogik erlaubt, wenn du sie brauchst.
HAProxy wird oft gewählt, wenn das Hauptziel zuverlässiges, hochperformantes Load-Balancing mit starken Health-Checks ist — z. B. Verteilung von API-Traffic über mehrere App-Server, Failover zwischen Availability-Zonen oder Fronting von Diensten, bei denen Verbindungsvolumen und vorhersehbares Verhalten wichtiger sind als erweiterte Webserver-Funktionen.
Performance-Vergleiche verlaufen oft falsch, weil man auf eine einzelne Zahl (z. B. „max RPS“) schaut und vergisst, was Nutzer tatsächlich spüren.
Ein Proxy kann den Durchsatz erhöhen und gleichzeitig die Tail-Latenz verschlechtern, wenn er zu viel Arbeit bei Last aufstaut.
Denk über die „Form“ deiner Anwendung nach:
Wenn du mit einem Muster benchmarkst, aber ein anderes produktiv verwendest, sind die Ergebnisse nicht übertragbar.
Buffering kann helfen, wenn Clients langsam oder bursty sind, weil der Proxy die komplette Anfrage (oder Antwort) lesen und deiner App gleichmäßiger zuführen kann.
Buffering kann schaden, wenn deine App Streaming braucht (Server-Sent Events, große Downloads, Echtzeit-APIs). Zusätzliches Buffering erhöht den Speicherbedarf und kann Tail-Latenzen verschlechtern.
Miss mehr als nur „max RPS“:
Wenn p95 stark ansteigt, bevor Fehler auftauchen, ist das ein Frühwarnzeichen für Sättigung — nicht „freie Kapazität“.
Sowohl Nginx als auch HAProxy können vor mehreren App-Instanzen sitzen und Traffic verteilen, aber sie unterscheiden sich darin, wie umfangreich ihre Load-Balancing-Funktionen von Haus aus sind.
Round-Robin ist die Standard-, „gut genug“-Wahl, wenn deine Backends ähnlich sind (gleiche CPU/RAM, gleiche Anfragekosten). Einfach, vorhersehbar und funktioniert gut für zustandslose Apps.
Least Connections ist nützlich, wenn Anfragen in der Dauer variieren (Datei-Downloads, lange API-Aufrufe, WebSocket-ähnliche Workloads). Es neigt dazu, langsamere Server zu entlasten, weil Backends mit weniger aktiven Verbindungen bevorzugt werden.
Weighted Balancing (Round-Robin mit Gewichten oder Weighted Least Connections) ist praktisch, wenn Server nicht identisch sind — z. B. gemischte alte/neue Nodes, unterschiedliche Instanzgrößen oder schrittweiser Traffic-Shift während einer Migration.
Generell bietet HAProxy mehr Algorithmus-Optionen und feingranulare Kontrolle auf Layer 4/7, während Nginx die gängigen Fälle sauber abdeckt (und je nach Edition/Modulen erweiterbar ist).
Stickiness hält einen Nutzer auf demselben Backend über mehrere Requests.
Nutze Persistenz nur, wenn nötig (Legacy-Server-seitige Sessions). Zustandslose Apps skalieren und erholen sich in der Regel besser ohne sie.
Aktive Health-Checks prüfen Backends periodisch (HTTP-Endpoint, TCP-Connect, erwarteter Status). Sie erkennen Ausfälle auch bei geringem Traffic.
Passive Health-Checks reagieren auf realen Traffic: Timeouts, Verbindungsfehler oder fehlerhafte Antworten markieren einen Server als ungesund. Sie sind leichtgewichtig, erkennen Probleme aber möglicherweise langsamer.
HAProxy ist bekannt für umfangreiche Health-Check- und Fehlerhandhabungs-Optionen (Schwellenwerte, rise/fall counts, detaillierte Checks). Nginx bietet ebenfalls solide Checks, deren Umfang von Build und Edition abhängt.
Für Rolling-Deploys achte auf:
Kombiniere Draining mit kurzen, definierten Timeouts und einem klaren "ready/unready"-Health-Endpoint, damit Traffic während Deployments sanft verschoben wird.
Reverse-Proxies sitzen am Rand deines Systems, daher beeinflussen Protokoll- und TLS-Entscheidungen alles von Browser-Performance bis hin zur sicheren Kommunikation zwischen Diensten.
Sowohl Nginx als auch HAProxy können TLS „terminieren“: Sie akzeptieren verschlüsselte Verbindungen vom Client, entschlüsseln den Traffic und leiten Anfragen an deine Apps per HTTP oder erneut per TLS weiter.
Betrieblich ist die Zertifikatsverwaltung entscheidend. Du brauchst einen Plan für:
Nginx wird häufig gewählt, wenn TLS-Termination mit Webserver-Funktionen (statische Dateien, Redirects) kombiniert wird. HAProxy wird oft gewählt, wenn TLS vornehmlich Teil einer Traffic-Management-Schicht ist (Load-Balancing, Verbindungssteuerung).
HTTP/2 kann die Ladezeiten im Browser reduzieren, indem mehrere Requests über eine Verbindung multiplexed werden. Beide Tools unterstützen HTTP/2 auf der clientseitigen Seite.
Wichtige Überlegungen:
Wenn du nicht-HTTP-Traffic routen musst (Datenbanken, SMTP, Redis, eigene Protokolle), brauchst du TCP-Proxying statt HTTP-Routing. HAProxy wird oft für hochperformantes TCP-Load-Balancing mit feingranularer Verbindungssteuerung eingesetzt. Nginx kann TCP ebenfalls proxyn (über stream-Funktionalität), was für einfache Pass-Through-Setups ausreichend sein kann.
mTLS verifiziert beide Seiten: Clients präsentieren Zertifikate, nicht nur Server. Das passt gut für Service-to-Service-Kommunikation, Partnerintegrationen oder Zero-Trust-Designs. Beide Proxies können Client-Zertifikatvalidierung am Edge durchsetzen, und viele Teams setzen mTLS auch intern zwischen Proxy und Upstream ein, um Annahmen über ein „vertrauenswürdiges Netzwerk“ zu reduzieren.
Reverse-Proxies stehen in der Mitte jeder Anfrage und sind oft der beste Ort, um die Frage „Was ist passiert?“ zu beantworten. Gute Observability bedeutet konsistente Logs, eine kleine Menge hochrelevanter Metriken und eine wiederholbare Art, Timeouts und Gateway-Fehler zu debuggen.
Schalte mindestens Access-Logs und Error-Logs in Produktion ein. Bei Access-Logs sollten Upstream-Timings enthalten sein, damit du erkennen kannst, ob die Verzögerung vom Proxy oder der Anwendung verursacht wurde.
In Nginx sind gängige Felder request_time und upstream_response_time (z. B. $request_time, $upstream_response_time, $upstream_status). In HAProxy aktiviere den HTTP-Log-Modus und erfasse Timing-Felder (queue/connect/response), damit du zwischen "Warten auf einen Backend-Slot" und "Backend war langsam" unterscheiden kannst.
Halte Logs strukturiert (JSON, wenn möglich) und füge eine Request-ID hinzu (aus einem eingehenden Header oder generiert), um Proxy-Logs mit App-Logs zu korrelieren.
Egal ob Prometheus-Scraping oder anderes Metrics-Pipeline, exportiere einheitlich:
Nginx nutzt oft das Stub-Status-Endpoint oder einen Prometheus-Exporter; HAProxy hat ein eingebautes Stats-Endpoint, das viele Exporter auslesen.
Expose einen leichten /health (Prozess läuft) und /ready (kann Abhängigkeiten erreichen)-Endpoint. Nutze beide in Automatisierung: Load-Balancer-Health-Checks, Deployments und Auto-Scaling-Entscheidungen.
Beim Troubleshooting vergleiche Proxy-Timings (connect/queue) mit Upstream-Response-Time. Wenn connect/queue hoch ist, brauchst du mehr Kapazität oder Anpassungen im Load-Balancing; ist die Upstream-Time hoch, fokussiere dich auf Anwendung und Datenbank.
Ein Reverse-Proxy zu betreiben geht über Peak-Throughput hinaus — es geht auch darum, wie schnell dein Team um 14:00 (oder 02:00) sichere Änderungen ausrollen kann.
Nginx-Konfiguration ist directive-basiert und hierarchisch. Sie liest sich wie „Blöcke in Blöcken“ (http → server → location), was viele als zugänglich empfinden, wenn sie in Begriffen von Sites und Routen denken.
HAProxy-Konfiguration ist eher „Pipeline-artig“: Du definierst frontends (was du akzeptierst), backends (wo du Traffic hinschickst) und hängst dann Regeln (ACLs) an, um die beiden zu verbinden. Sobald man das Modell verinnerlicht hat, wirkt es explizit und vorhersehbar — besonders für Traffic-Routing-Logik.
Nginx macht Config-Reload typischerweise, indem neue Worker gestartet und alte graceful gedraint werden. Das ist freundlich für häufige Routen-Updates und Zertifikats-Erneuerungen.
HAProxy kann ebenfalls nahtlose Reloads durchführen, aber Teams behandeln es oft eher wie ein „Appliance“-System: strengere Change-Kontrolle, versionierte Konfigurationen und sorgfältige Koordination von Reload-Kommandos.
Beide unterstützen Config-Tests vor dem Reload (ein Muss für CI/CD). In der Praxis hältst du Konfigurationen DRY, indem du sie generierst:
Die wichtigste Betriebsgewohnheit: Behandle Proxy-Konfiguration als Code — reviewed, getestet und deployed wie App-Änderungen.
Wenn die Anzahl der Dienste wächst, sind Zertifikat- und Routing-Sprawl die echten Schmerzpunkte. Plane für:
Wenn du hunderte Hosts erwartest, zentralisiere Muster und generiere Konfigurationen aus Service-Metadaten statt Dateien manuell zu bearbeiten.
Wenn du mehrere Services entwickelst und iterierst, ist ein Reverse-Proxy nur ein Teil der Delivery-Pipeline — du brauchst weiterhin reproduzierbare App-Scaffolds, Umgebungskonformität und sichere Rollouts.
Koder.ai kann Teams helfen, schneller von der Idee zur laufenden Anwendung zu gelangen, indem es React-Webapps, Go + PostgreSQL-Backends und Flutter-Mobile-Apps über einen Chat-basierten Workflow generiert, dann Source-Export, Deployment/Hosting, Custom Domains und Snapshots mit Rollback anbietet. Praktisch heißt das: Du kannst API + Web-Frontend prototypen, deployen und erst anhand echten Traffics entscheiden, ob Nginx oder HAProxy die bessere Eingangstür ist — statt zu raten.
Sicherheit ist selten eine einzelne „magische“ Funktion — es geht darum, die Blast-Radius zu reduzieren und Defaults rund um Traffic, den du nicht vollständig kontrollierst, zu verschärfen.
Führe den Proxy mit minimalen Rechten aus: binde privilegierte Ports über Capabilities (Linux) oder einen vorgelagerten Dienst und halte Worker-Prozesse nicht privilegiert. Schütze Konfiguration und Schlüsselmaterial (TLS-Private-Keys, DH-Parameter) mit read-only-Berechtigungen für das Service-Konto.
Auf Netzwerkebene: Erlaube Inbound nur von erwarteten Quellen (Internet → Proxy; Proxy → Backends). Vermeide direkten Backend-Zugriff, wann immer möglich, sodass der Proxy der einzige Kontrollpunkt für Authentifizierung, Rate-Limits und Logging ist.
Nginx hat first-class-Primitives wie limit_req / limit_conn für Anfrage- und Verbindungsbegrenzung. HAProxy nutzt typischerweise Stick-Tables, um Anfrage-Raten, gleichzeitige Verbindungen oder Fehler-Muster zu verfolgen und dann zu blocken, zu drosseln oder zu sperren.
Wähle einen Ansatz passend zu deinem Threat-Model:
X-Forwarded-For, Host)Sei explizit, welche Header du vertraust. Akzeptiere X-Forwarded-For (und Verwandte) nur von bekannten Upstreams; sonst können Angreifer Client-IP fälschen und IP-basierte Kontrollen umgehen. Validierte oder gesetzte Host-Header verhindern Host-Header-Angriffe und Cache-Poisoning.
Faustregel: Der Proxy sollte Weiterleitungs-Header setzen, nicht blind weiterreichen.
Request-Smuggling nutzt oft uneindeutige Parsing-Fälle (konfligierende Content-Length / Transfer-Encoding, ungewöhnliche Whitespace oder ungültige Header). Bevorzuge striktes HTTP-Parsen, lehne malformed Header ab und setze konservative Limits:
Connection, Upgrade und hop-by-hop HeaderDie Syntax unterscheidet sich zwischen Nginx und HAProxy, das Ziel sollte jedoch gleich sein: Im Zweifel geschlossen fehlschlagen und Limits explizit setzen.
Reverse-Proxies werden meist auf zwei Arten eingeführt: als dedizierte Eingangstür für eine einzelne Anwendung oder als gemeinsames Gateway vor vielen Services. Beide — Nginx und HAProxy — können beides. Entscheidend ist, wie viel Routing-Logik du am Edge brauchst und wie du es täglich betreiben willst.
Dieses Muster stellt einen Reverse-Proxy direkt vor eine einzelne Web-App (oder eine kleine Gruppe eng verbundener Services). Es passt, wenn du hauptsächlich TLS-Termination, HTTP/2, Compression, Caching (bei Nginx) oder eine klare Trennung zwischen „öffentlich“ und „privat“ brauchst.
Use when:
Hier routet ein (oder ein kleines Cluster) von Proxies Traffic an mehrere Anwendungen basierend auf Hostname, Pfad, Headern oder anderen Eigenschaften. Das reduziert die Anzahl öffentlicher Einstiegspunkte, erhöht aber die Wichtigkeit sauberer Konfigurationsverwaltung und Change-Control.
Use when:
app1.example.com, app2.example.com) und willst eine zentrale Ingress-Schicht.Proxies können Traffic zwischen „alt“ und „neu“ splitten, ohne DNS oder App-Code zu ändern. Üblicherweise definiert man zwei Upstream-Pools (blue und green) oder Backends (v1 und v2) und verschiebt Traffic schrittweise.
Typische Nutzung:
Das ist besonders praktisch, wenn dein Deployment-Tooling kein gewichtetes Rollout anbietet oder du eine einheitliche Rollout-Mechanik über Teams hinweg willst.
Ein einzelner Proxy ist ein Single Point of Failure. Gängige HA-Pattern sind:
Wähle je nach Umgebung: VRRP ist beliebt auf VMs/Bare-Metal; managed Load-Balancer sind in der Cloud oft am einfachsten.
Eine typische Kette ist: CDN (optional) → WAF (optional) → Reverse-Proxy → Anwendung.
Wenn du bereits ein CDN/WAF nutzt, halte den Proxy auf Anwendungslieferung und Routing fokussiert statt ihn zur einzigen Sicherheits-Schicht zu machen.
Kubernetes verändert, wie du Anwendungen "vorne" stellst: Services sind ephemer, IPs ändern sich und Routing-Entscheidungen passieren oft am Edge des Clusters über einen Ingress-Controller. Sowohl Nginx als auch HAProxy passen hier gut, aber sie glänzen jeweils in leicht unterschiedlichen Rollen.
In der Praxis ist die Entscheidung selten „welches ist besser“, sondern eher „was passt zu deinem Traffic-Muster und wie viel HTTP-Manipulation brauchst du am Edge?".
Wenn du ein Service-Mesh betreibst (z. B. mTLS und Traffic-Policies intern), kannst du Nginx/HAProxy weiterhin am Perimeter für North–South-Traffic (Internet → Cluster) nutzen. Das Mesh übernimmt East–West-Traffic (Service ↔ Service). Diese Trennung hält Edge-Aufgaben — TLS-Termination, WAF/Rate-Limiting, grundlegendes Routing — getrennt von internen Zuverlässigkeitsfunktionen wie Retries und Circuit-Breaking.
gRPC und langlebige Verbindungen belasten Proxies anders als kurze HTTP-Requests. Achte auf:
Teste mit realistischen Dauern (Minuten/Stunden), nicht nur mit kurzen Smoke-Tests.
Behandle Proxy-Konfiguration als Code: im Git halten, Änderungen in CI validieren (Linting, Config-Test) und per CD mit kontrollierten Deployments (Canary oder Blue/Green) ausrollen. Das macht Upgrades sicherer und liefert eine Audit-Spur, wenn Routing- oder TLS-Änderungen Produktion beeinflussen.
Der schnellste Weg ist, von dem auszugehen, was der Proxy täglich tun soll: Inhalte ausliefern, HTTP-Traffic formen oder strikt Verbindungen und Balancing-Logik managen.
Wenn dein Reverse-Proxy auch die Web-„Eingangstür“ ist, ist Nginx oft die bequemere Default-Wahl:
Wenn Präzision in der Traffic-Verteilung und Kontrolle unter Last wichtig ist, glänzt HAProxy:
Die Kombination kommt oft vor, wenn du Webserver-Annehmlichkeiten und spezialisiertes Balancing willst:
Diese Trennung kann auch Verantwortlichkeiten klarer machen: Web-Belange vs. Traffic-Engineering.
Stelle dir folgende Fragen:
Ein Reverse-Proxy steht vor deinen Anwendungen: Clients verbinden sich mit dem Proxy, der die Anfragen an den richtigen Backend-Dienst weiterleitet und die Antwort zurückgibt.
Ein Forward-Proxy steht vor Clients und kontrolliert deren ausgehenden Internetzugriff (häufig in Unternehmensnetzwerken).
Ein Load-Balancer konzentriert sich auf die Verteilung von Traffic über mehrere Backend-Instanzen. Viele Load-Balancer sind als Reverse-Proxies implementiert, weshalb sich die Begriffe überschneiden.
In der Praxis verwendest du oft ein Tool (z. B. Nginx oder HAProxy), das beides übernimmt: Reverse-Proxying + Load-Balancing.
Platziere ihn dort, wo du einen einzigen Kontrollpunkt brauchst:
Wichtig ist, direkte Client-Zugriffe auf Backends zu vermeiden, damit der Proxy der zentrale Punkt für Richtlinien und Sichtbarkeit bleibt.
TLS-Termination bedeutet, dass der Proxy HTTPS übernimmt: Er akzeptiert verschlüsselte Client-Verbindungen, entschlüsselt sie und leitet den Traffic an die Upstreams per HTTP oder rekryptiertem TLS weiter.
Betrieblich solltest du planen für:
Wähle Nginx, wenn dein Proxy auch die Web-„Eingangstür“ ist:
Wähle HAProxy, wenn Traffic-Management und Vorhersagbarkeit unter Last im Vordergrund stehen:
Verwende Round-Robin, wenn Backends ähnlich sind und die Anfragekosten gleichmäßig verteilt sind.
Verwende Least Connections, wenn die Anfragedauer stark variiert (Downloads, lange API-Aufrufe, lange Verbindungen), damit langsamere Instanzen nicht überlastet werden.
Verwende Weighted-Varianten, wenn Backends unterschiedlich sind (verschiedene Instanzgrößen, Stufenmigrationen), damit du Traffic gezielt verschieben kannst.
Stickiness sorgt dafür, dass ein Nutzer über mehrere Anfragen zum gleichen Backend geleitet wird.
Vermeide Sticky Sessions, wenn möglich: stateless-Services skalieren, fallen sauberer aus und lassen sich einfacher ausrollen.
Buffering kann helfen, indem es langsame oder burstige Clients ausgleicht, sodass deine App gleichmäßigere Last sieht.
Es kann schaden, wenn du Streaming-Verhalten brauchst (SSE, WebSockets, große Downloads), denn zusätzliches Buffering erhöht Speicherbedarf und kann Tail-Latenzen verschlechtern.
Wenn deine Anwendung stream-orientiert ist, teste und tune Buffering explizit statt dich auf Defaults zu verlassen.
Trenne Proxy-Verzögerung von Backend-Verzögerung mit Logs/Metriken.
Gängige Bedeutungen:
Nützliche Signale:
Lösungen: Timeouts anpassen, Backend-Kapazität erhöhen oder Health-Checks/Readiness-Endpoints verbessern.