Ein Transformer ist eine Methode, Computern zu helfen, Sequenzen zu verstehen—Dinge, bei denen Reihenfolge und Kontext zählen, wie Sätze, Code oder eine Folge von Suchanfragen. Anstatt ein Token nach dem anderen zu lesen und ein fragiles Gedächtnis vorzutragen, schaut ein Transformer über die ganze Sequenz hinweg und entscheidet, worauf beim Interpretieren jedes Teils geachtet werden soll.
Dieser einfache Wechsel war ein großer Schritt. Er ist ein wesentlicher Grund dafür, dass moderne große Sprachmodelle (LLMs) Kontext halten können, Anweisungen folgen, zusammenhängende Absätze schreiben und Code erzeugen, der sich auf frühere Funktionen und Variablen bezieht.
Wenn Sie einen Chatbot, eine "dies zusammenfassen"-Funktion, semantische Suche oder einen Coding-Assistenten genutzt haben, sind Sie wahrscheinlich mit Transformer-basierten Systemen in Kontakt gekommen. Dieselbe Kernarchitektur unterstützt:
- Chat- und Kundensupport-Tools, die verfolgen, was Sie zuvor gesagt haben
- Such- und Empfehlungssysteme, die Bedeutung statt nur Schlüsselwörter abgleichen
- Zusammenfassungen, die abwägen, was zentral vs. Nebensache ist
- Coding-Tools, die Definitionen, Verwendung und Absicht über Dateien hinweg verbinden
Was Sie in diesem Artikel lernen werden
Wir zerlegen die Schlüsselbestandteile—Selbstaufmerksamkeit, Multi-Head-Attention, Positionskodierung und den grundlegenden Transformer-Block—und erklären, warum dieses Design so gut skaliert, wenn Modelle größer werden.
Wir gehen auch auf moderne Varianten ein, die dieselbe Kernidee behalten, aber für mehr Geschwindigkeit, geringere Kosten oder längere Kontextfenster optimiert werden.
Was Sie erwarten (und was nicht)
Dies ist eine hochrangige Tour mit verständlichen Erklärungen und minimaler Mathematik. Ziel ist Intuition: was die Teile tun, warum sie zusammen funktionieren und wie sich das in echten Produktfähigkeiten übersetzt.
Noam Shazeer ist ein KI-Forscher und -Ingenieur, bekannt als einer der Koautoren des 2017er Papers „Attention Is All You Need.“ Dieses Papier stellte die Transformer-Architektur vor, die später die Grundlage vieler moderner großer Sprachmodelle (LLMs) wurde. Shazeers Arbeit ist Teil eines Teamaufwands: Der Transformer wurde von einer Gruppe von Forschenden bei Google entwickelt, und das sollte entsprechend anerkannt werden.
Was das Paper von 2017 veränderte
Vor dem Transformer setzten viele NLP-Systeme auf rekurrente Modelle, die Text Schritt für Schritt verarbeiteten. Der Transformer schlug vor, Sequenzen effektiv ohne Rekurrenz zu modellieren, indem Aufmerksamkeit als zentrales Mechanismus zur Kombination von Informationen über einen Satz hinweg genutzt wird.
Dieser Wechsel war wichtig, weil das Training leichter parallelisierbar wurde (man kann viele Token gleichzeitig verarbeiten) und weil er es ermöglichte, Modelle und Datensätze so zu skalieren, dass sie schnell praktisch für reale Produkte wurden.
Von der Forschungsidee zum Baustein für Produkte
Shazeers Beitrag—neben den anderen Autoren—blieb nicht auf akademische Benchmarks beschränkt. Der Transformer wurde zu einem wiederverwendbaren Modul, das Teams anpassen konnten: Komponenten austauschen, die Größe ändern, für Aufgaben abstimmen und später großflächig vortrainieren.
So reisen viele Durchbrüche: Ein Paper stellt ein klares, allgemeines Rezept vor; Ingenieure verfeinern es; Firmen operationalisieren es; und schließlich wird es zur Standardwahl beim Aufbau von Sprachfunktionen.
Genauigkeit bei der Zuschreibung
Es ist korrekt zu sagen, dass Shazeer ein wichtiger Mitwirkender und Koautor des Transformer-Papers war. Es wäre jedoch nicht zutreffend, ihn als alleinigen Erfinder darzustellen. Die Wirkung ergibt sich aus dem kollektiven Design—und aus den vielen Nachfolgeverbesserungen, die die Community auf dieses ursprüngliche Grundgerüst aufgebaut hat.
Was davor kam: RNNs, LSTMs und ihre Grenzen
Vor den Transformern dominierten in vielen Sequenzproblemen (Übersetzung, Sprache, Textgenerierung) Recurrent Neural Networks (RNNs) und später LSTMs (Long Short-Term Memory-Netze). Die Grundidee war einfach: Text Token für Token lesen, einen laufenden "Speicher" (Hidden State) führen und diesen verwenden, um das Nächste vorherzusagen.
Ein schnelles Bild, wie sie arbeiteten
Ein RNN verarbeitet einen Satz wie eine Kette. Jeder Schritt aktualisiert den Hidden State basierend auf dem aktuellen Wort und dem vorherigen Hidden State. LSTMs verbesserten das durch Gates, die entscheiden, was behalten, vergessen oder ausgegeben wird—so lassen sich nützliche Signale länger halten.
Warum langfristige Abhängigkeiten schwer waren
In der Praxis hat sequentieller Speicher einen Engpass: Viele Informationen müssen durch einen einzigen State gepresst werden, je länger der Satz wird. Selbst mit LSTMs können Signale von weit früheren Wörtern verblassen oder überschrieben werden.
Das machte bestimmte Beziehungen schwer zuverlässig zu lernen—z. B. ein Pronomen korrekt einem Nomen zuzuordnen, das viele Wörter zurückliegt, oder ein Thema über mehrere Klauseln hinweg zu verfolgen.
Trainings- und Skalierungsprobleme
RNNs und LSTMs sind auch langsam im Training, weil sie nicht vollständig über die Zeit parallelisieren können. Man kann zwar über verschiedene Sätze batchen, aber innerhalb eines Satzes hängt Schritt 50 von Schritt 49 ab, der von Schritt 48 abhängt, usw.
Diese schrittweise Berechnung wird zu einer ernsthaften Einschränkung, wenn man größere Modelle, mehr Daten und schnellere Iteration will.
Motivation für einen parallelfreundlicheren Ansatz
Forschende brauchten ein Design, das Wörter miteinander in Beziehung setzen kann, ohne strikt links-nach-rechts beim Training vorzugehen—einen Weg, Langstreckenbeziehungen direkt zu modellieren und moderne Hardware besser zu nutzen. Dieser Druck bereitete das Feld für den auf Aufmerksamkeit basierenden Ansatz in Attention Is All You Need.
Attention, ohne Mathematik erklärt
Attention ist die Art und Weise, wie das Modell fragt: „Welche anderen Wörter sollte ich mir gerade ansehen, um dieses Wort zu verstehen?“ Anstatt einen Satz strikt von links nach rechts zu lesen und darauf zu hoffen, dass das Gedächtnis hält, lässt Attention das Modell in dem Moment auf die relevantesten Satzteile blicken.
Die Idee „suchen und abrufen"
Ein hilfreiches mentales Modell ist eine kleine Suchmaschine, die innerhalb des Satzes läuft.
- Query: wonach das aktuelle Wort sucht (die Frage)
- Keys: was jedes andere Wort anbietet (die Labels möglicher Treffer)
- Values: die tatsächliche Information, die bei einem Treffer abgerufen wird (der Inhalt)
Das Modell bildet also eine Query für die aktuelle Position, vergleicht sie mit den Keys aller Positionen und holt eine Mischung von Values.
Relevanz-Scores → Attention-Gewichte
Diese Vergleiche erzeugen Relevanz-Scores: grobe "wie zusammenhängend ist das?"-Signale. Das Modell wandelt sie dann in Attention-Gewichte um, Verhältnisse, die zusammen 1 ergeben.
Wenn ein Wort sehr relevant ist, erhält es einen größeren Anteil der Aufmerksamkeit. Sind mehrere Wörter wichtig, kann die Aufmerksamkeit auf sie verteilt werden.
Ein einfaches Beispiel (Pronomen und Grammatik)
Nehmen Sie: „Maria sagte Jenna, dass sie später anrufen würde.“
Um sie zu interpretieren, sollte das Modell Kandidaten wie „Maria“ und „Jenna“ anschauen. Attention weist dem Namen, der am besten in den Kontext passt, ein höheres Gewicht zu.
Oder: „Die Schlüssel zum Schrank sind verschwunden.“ Attention hilft, „sind“ mit „Schlüssel“ (das tatsächliche Subjekt) zu verbinden, nicht mit „Schrank“, obwohl „Schrank“ näher steht. Das ist der Kernvorteil: Attention verknüpft Bedeutung über Distanz, bei Bedarf.
Selbstaufmerksamkeit: Der Kernmechanismus
Selbstaufmerksamkeit bedeutet, dass jedes Token in einer Sequenz andere Token derselben Sequenz anschauen kann, um zu entscheiden, was gerade wichtig ist. Anstatt Wörter strikt links-nach-rechts zu verarbeiten (wie ältere rekurrente Modelle), lässt der Transformer jedes Token Hinweise aus der gesamten Eingabe sammeln.
Tokens, die auf Tokens achten
Stellen Sie sich den Satz vor: „Ich goss das Wasser in die Tasse, weil sie leer war.“ Das Wort „sie“ sollte mit „Tasse“ verbunden werden, nicht mit „Wasser“. Bei Selbstaufmerksamkeit weist das Token für „sie“ höheren Stellenwert Tokens zu, die helfen, seine Bedeutung aufzulösen („Tasse“, „leer“) und weniger auf irrelevante.
Wie Kontext aufgebaut wird
Nach Selbstaufmerksamkeit ist ein Token nicht mehr nur sich selbst. Es wird eine kontextbewusste Variante—eine gewichtete Mischung aus Informationen anderer Token. Man kann sich vorstellen, dass jedes Token eine personalisierte Zusammenfassung des ganzen Satzes erstellt, abgestimmt auf das, was dieses Token braucht.
In der Praxis bedeutet das, dass die Repräsentation von „Tasse“ Signale von „goss“, „Wasser“ und „leer“ tragen kann, während „leer“ Informationen dessen aufnimmt, was es beschreibt.
Warum Training parallel möglich ist
Weil jedes Token gleichzeitig seine Attention über die ganze Sequenz berechnen kann, muss das Training nicht auf die schrittweise Verarbeitung vorheriger Token warten. Diese parallele Verarbeitung ist einer der Hauptgründe, warum Transformer effizient auf großen Datensätzen trainieren und zu riesigen Modellen skaliert werden.
Warum es bei Langstreckenbeziehungen stark ist
Selbstaufmerksamkeit erleichtert das Verbinden weit entfernter Textteile. Ein Token kann direkt auf ein relevantes, weit entferntes Wort fokussieren—ohne Information durch eine lange Kette von Zwischenschritten zu schicken.
Dieser direkte Pfad hilft bei Aufgaben wie Koreferenz ("sie", "es", "sie"), dem Verfolgen von Themen über Absätze hinweg und beim Umgang mit Anweisungen, die von früheren Details abhängen.
Multi-Head-Attention: Viele Blickwinkel auf denselben Satz
Bereitstellen, während du iterierst
Stelle deine App bereit und hoste sie, während du Prompts und Bewertungen verfeinerst.
Eine einzelne Attention ist mächtig, aber es ist so, als würde man eine Unterhaltung nur aus einer Kamera-Perspektive beobachten. Sätze enthalten oft mehrere gleichzeitige Beziehungen: wer was tat, worauf sich "sie" bezieht, welche Wörter den Ton setzen und welches das übergeordnete Thema ist.
Warum eine Attention-Ansicht nicht ausreicht
Wenn Sie lesen „Die Trophäe passte nicht in den Koffer, weil er zu klein war“, müssen Sie vielleicht mehrere Hinweise gleichzeitig verfolgen (Grammatik, Bedeutung, realweltlicher Kontext). Eine Attention-Ansicht könnte sich auf das nächstgelegene Nomen fixieren; eine andere könnte die Verbphrase nutzen, um zu entscheiden, worauf „er“ sich bezieht.
Was mehrere Köpfe tun
Multi-Head-Attention führt mehrere Attention-Berechnungen parallel aus. Jeder "Head" betrachtet den Satz durch eine andere Linse—oft beschrieben als andere Subräume. Praktisch können Köpfe sich auf Muster spezialisieren, z. B.:
- Lokale Syntax (z. B. Adjektiv → Nomen)
- Langreichweite-Verbindungen (z. B. Subjekt ↔ Verb über eine Klausel)
- Koreferenz (z. B. Pronomen → Entität)
- Thematische Signale (Wörter, die das Thema oder die Stimmung setzen)
Wie die Köpfe kombiniert werden
Nachdem jeder Kopf seine Einsichten produziert hat, wählt das Modell nicht nur eine davon aus. Es konkateniert die Kopf-Ausgaben (nebeneinander stapeln) und projiziert sie dann mit einer gelernten linearen Schicht zurück in den Hauptarbeitsraum des Modells.
Denken Sie daran wie das Zusammenführen mehrerer Teilnotizen zu einer sauberen Zusammenfassung, die die nächste Schicht verwenden kann. Das Ergebnis ist eine Repräsentation, die viele Beziehungen zugleich erfassen kann—ein Grund, warum Transformer so gut bei Skalierung funktionieren.
Positionskodierung: Dem Modell Wortreihenfolge beibringen
Selbstaufmerksamkeit ist großartig darin, Beziehungen zu erkennen—aber allein weiß sie nicht, wer zuerst kam. Wenn man die Wörter in einem Satz mischt, kann eine einfache Selbstaufmerksamkeit die gemischte Version als ähnlich behandeln, weil sie Token ohne eingebaute Positionssicht vergleicht.
Positionskodierung löst das, indem sie "wo bin ich in der Sequenz?"-Informationen in die Token-Repräsentationen injiziert. Sobald Positionen angehängt sind, kann Attention Muster lernen wie "das Wort direkt nach ‹nicht› ist wichtig" oder "Subjekt steht normalerweise vor dem Verb", ohne die Reihenfolge neu erfinden zu müssen.
Wie Positionskodierungen Ordnung hinzufügen
Die Kernidee ist einfach: Jede Token-Einbettung wird vor dem Eintritt in den Transformer-Block mit einem Positionssignal kombiniert. Dieses Positionssignal kann als zusätzlicher Merkmalsvektor verstanden werden, der ein Token als 1., 2., 3.... in der Eingabe kennzeichnet.
Es gibt einige gängige Ansätze:
- Absolute (feste) Positionen: Klassische Transformer nutzten deterministische, sinusförmige Muster. Diese fügen keine neuen Parameter hinzu und können bis zu einem gewissen Punkt auf Längen über den Trainingsbereich hinaus generalisieren.
- Gelernte absolute Positionen: Das Modell lernt einen Vektor für „Position 1“, „Position 2“ usw. Das kann sehr gut funktionieren, bindet das Modell aber oft an ein maximales Kontextfenster, mit dem es trainiert wurde.
- Relative Positionen: Statt „dies ist Token 57“ kodiert das Modell Distanzen wie „dieses Token ist 3 Schritte vor jenem“. Moderne Varianten (einschließlich rotary-artiger Methoden) fallen oft in diese Familie.
Warum es für Langkontextaufgaben wichtig ist
Positionsentscheidungen beeinflussen merklich das Langkontextmodellieren—z. B. beim Zusammenfassen langer Berichte, Verfolgen von Entitäten über viele Absätze oder Abrufen von Details, die tausende Token zurückliegen.
Bei langen Eingaben lernt das Modell nicht nur Sprache; es lernt, wo es hinschauen muss. Relative und rotary-artige Schemata erleichtern oft den Vergleich weit auseinanderliegender Token und das Bewahren von Mustern, während einige absolute Schemata bei Überschreitung des Trainingsfensters schneller degradieren.
In der Praxis ist die Positionskodierung eine dieser stillen Designentscheidungen, die darüber bestimmt, ob ein LLM bei 2.000 Token scharf wirkt—und bei 100.000 noch kohärent bleibt.
Verdiene Credits für Inhalte
Verdiene Credits, indem du Inhalte über deinen Build auf Koder.ai teilst.
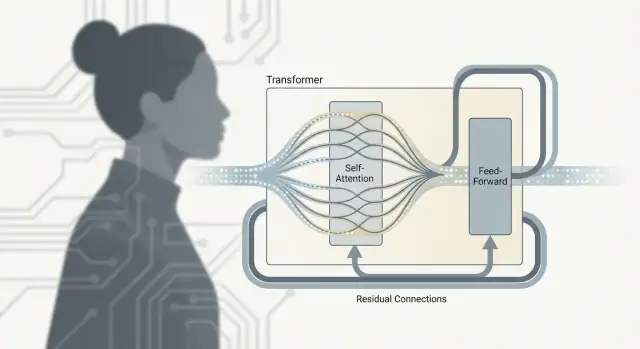
Ein Transformer ist nicht nur „Attention“. Die eigentliche Arbeit passiert in einer wiederholten Einheit—oft Transformer-Block genannt—die Informationen über Token mischt und sie dann verfeinert. Stapeln Sie viele dieser Blöcke, und Sie erhalten die Tiefe, die große Sprachmodelle so leistungsfähig macht.
Nach der Attention: Was das FFN/MLP macht
Selbstaufmerksamkeit ist der Kommunikationsschritt: Jedes Token sammelt Kontext von anderen Token.
Das Feed-Forward-Netz (FFN), auch MLP genannt, ist der Denk-Schritt: Es nimmt die aktualisierte Repräsentation jedes Tokens und führt dasselbe kleine neuronale Netz unabhängig darauf aus.
Einfach gesagt transformiert das FFN, was jedes Token nun weiß, und formt reichere Merkmale (wie Syntaxmuster, Fakten oder Stilhinweise), nachdem Kontext gesammelt wurde.
Warum Blöcke Attention und FFN abwechseln
Die Abwechslung ist wichtig, weil die beiden Teile unterschiedliche Aufgaben erfüllen:
- Attention bewegt Informationen zwischen Token (wer sollte wen beeinflussen)
- FFN verarbeitet Informationen innerhalb jedes Tokens (wie man den Kontext in nützliche Merkmale umwandelt)
Dieses Muster zu wiederholen erlaubt dem Modell, schrittweise höherwertige Bedeutung aufzubauen: kommunizieren, rechnen, wieder kommunizieren, wieder rechnen.
Residual-Verbindungen: die "Überholspuren"
Jede Sublayer (Attention oder FFN) ist mit einer Residual-Verbindung umgeben: Die Eingabe wird zur Ausgabe addiert. Das hilft tiefen Modellen beim Training, weil Gradienten durch die "Überholspur" fließen können, selbst wenn eine bestimmte Schicht noch lernt. Es erlaubt einer Schicht auch, kleine Anpassungen vorzunehmen, anstatt alles neu lernen zu müssen.
Layer-Normalisierung: Signale stabil halten
Layer-Normalisierung ist ein Stabilisator, der verhindert, dass Aktivierungen über viele Schichten zu groß oder zu klein werden. Man kann es sich vorstellen wie das Konstanthalten der Lautstärke, damit spätere Schichten nicht überfordert oder unterversorgt werden—das macht das Training glatter und zuverlässiger, besonders im LLM-Maßstab.
Encoder–Decoder vs. Decoder-Only: Was treibt LLMs an?
Der originale Transformer in Attention Is All You Need war für Maschinenübersetzung gebaut, wo man eine Sequenz (z. B. Französisch) in eine andere (Englisch) übersetzt. Diese Aufgabe lässt sich natürlich in zwei Rollen teilen: lesen und dann schreiben.
Encoder–Decoder: „Lesen, dann Schreiben"
In einem Encoder–Decoder-Transformer verarbeitet der Encoder die gesamte Eingabe auf einmal und erzeugt reichhaltige Repräsentationen. Der Decoder generiert dann die Ausgabe Token für Token.
Wesentlich ist: Der Decoder stützt sich nicht nur auf seine eigenen bisherigen Token. Er verwendet auch Cross-Attention, um auf die Encoder-Ausgabe zurückzublicken und so im Quelltext verankert zu bleiben.
Dieses Setup ist exzellent, wenn man stark auf eine Eingabe konditioniert sein muss—Übersetzung, Zusammenfassung oder Fragebeantwortung mit einem bestimmten Textabschnitt.
Decoder-Only: Ein Modell, das einfach weiter vorhersagt
Die meisten modernen großen Sprachmodelle sind decoder-only. Sie werden mit einer einfachen, leistungsfähigen Aufgabe trainiert: das nächste Token vorhersagen.
Dazu nutzen sie maskierte Selbstaufmerksamkeit (kausale Attention). Jede Position darf nur frühere Token beachten, nicht zukünftige, sodass die Generierung konsistent left-to-right bleibt: das Modell schreibt und verlängert die Sequenz Schritt für Schritt.
Das ist dominant für LLMs, weil es einfach ist, auf massiven Textkorpora zu trainieren, die Generierungsaufgabe direkt abbildet und effizient mit Daten und Rechenleistung skaliert.
Wo Encoder-Only-Modelle passen
Encoder-only Transformer (wie BERT-ähnliche Modelle) erzeugen keinen Text; sie lesen die ganze Eingabe bidirektional. Sie sind ideal für Klassifikation, Suche und Embeddings—alles, bei dem das Verstehen eines Textstücks wichtiger ist als das Erzeugen einer langen Fortsetzung.
Transformer erwiesen sich als ungewöhnlich skalierfreundlich: Wenn man ihnen mehr Text, mehr Rechenleistung und größere Modelle gibt, verbessern sie sich häufig auf vorhersehbare Weise.
Ein großer Grund ist strukturelle Einfachheit. Ein Transformer besteht aus wiederholten Blöcken (Selbstaufmerksamkeit + kleines Feed-Forward-Netz plus Normalisierung), und diese Blöcke verhalten sich ähnlich, egal ob man mit einer Million Wörtern oder einer Billion trainiert.
Paralleles Training ist die versteckte Superkraft
Frühere Sequenzmodelle (wie RNNs) mussten Token eins nach dem anderen verarbeiten, was die parallele Auslastung begrenzt. Transformer hingegen können während des Trainings alle Token einer Sequenz parallel verarbeiten.
Das macht sie zu einer hervorragenden Wahl für GPUs/TPUs und große verteilte Setups—genau das, was man beim Training moderner LLMs braucht.
Das "Kontextfenster" und warum es zählt
Das Kontextfenster ist der Textabschnitt, den das Modell auf einmal "sehen" kann—Ihr Prompt plus Gesprächsverlauf oder Dokumenttext. Ein größeres Fenster erlaubt es dem Modell, Ideen über mehr Sätze oder Seiten hinweg zu verbinden, Beschränkungen zu behalten und Fragen zu beantworten, die auf früheren Details beruhen.
Kontext ist jedoch nicht gratis.
Die zentrale Begrenzung: Attention-Kosten wachsen mit Länge
Selbstaufmerksamkeit vergleicht Token miteinander. Je länger die Sequenz, desto mehr Vergleiche sind nötig (etwa quadratisch zur Sequenzlänge).
Darum sind sehr lange Kontextfenster in Speicher und Rechenaufwand teuer, und viele moderne Bemühungen zielen darauf ab, Attention effizienter zu gestalten.
Skalierung entfaltete allgemeines Verhalten
Wenn Transformer in großem Maßstab trainiert werden, werden sie oft nicht nur bei einer engen Aufgabe besser. Sie zeigen breite, flexible Fähigkeiten—Zusammenfassen, Übersetzen, Schreiben, Codieren und Schließen—weil dieselbe allgemeine Lernmaschine auf riesige, vielfältige Daten angewendet wird.
Moderne Varianten auf derselben Blaupause
RAG-Workflows prototypen
Teste Retrieval, Embeddings und Tool-Loops, ohne das gleiche Gerüst neu aufzubauen.
Das ursprüngliche Transformer-Design ist noch immer der Bezugspunkt, aber die meisten Produktions-LLMs sind "Transformer plus": kleine, praktische Änderungen, die den Kernblock (Attention + MLP) erhalten und gleichzeitig Geschwindigkeit, Stabilität oder Kontextlänge verbessern.
Häufige Verbesserungen, die Sie sehen werden
Viele Upgrades ändern weniger, was das Modell ist, und mehr, wie es besser trainiert und betrieben wird:
- Bessere Positionsmethoden: Alternativen zu klassischen sinusförmigen Positionen (oft rotary- oder relative-Stil) können Langreichweitenverarbeitung verbessern.
- Attention-Optimierungen: Implementierungen, die Speicher reduzieren und Durchsatz erhöhen (z. B. gefusete Kernel oder effizientere Attention-Berechnungen).
- Normalisierungsanpassungen: Variationen, wo und wie Normalisierung angewandt wird, verbessern Trainingsstabilität und reduzieren Sensitivität gegenüber Hyperparametern.
Diese Änderungen verändern selten die grundlegende "Transformer-Natur"—sie verfeinern sie.
Ansätze für Langkontext (grob)
Kontext von ein paar tausend Token auf zehntausende oder hunderttausende zu erweitern, beruht oft auf sparsamer Attention (nur auf ausgewählte Token achten) oder effizienten Attention-Varianten (approximiere oder restrukturiere Attention, um die Rechnung zu reduzieren).
Der Kompromiss betrifft meist Genauigkeit, Speicher und Engineering-Komplexität.
Mixture-of-Experts (MoE): mehr Kapazität ohne lineare Kosten
MoE-Modelle fügen mehrere "Expert"-Subnetzwerke hinzu und leiten jedes Token nur durch eine Teilmenge. Konzeptuell: Man bekommt ein größeres Gehirn, aber man aktiviert nicht alles jedes Mal.
Das kann die Rechenkosten pro Token für eine gegebene Parameteranzahl senken, erhöht jedoch die Systemkomplexität (Routing, Ausgleich der Experten, Bereitstellung).
Wie man Variantenbehauptungen bewertet
Wenn ein Modell eine neue Transformer-Variante anpreist, fragen Sie nach:
- Benchmarks, die für Ihre Aufgaben relevant sind (nicht nur Schlagzeilenzahlen)
- Latenz (time-to-first-token und tokens/sec)
- Kosten (Training und Inferenz), inklusive Speicher- und Hardwarebedarf
Die meisten Verbesserungen sind real—aber selten kostenlos.
Was das für Teams bedeutet, die mit LLMs bauen
Transformer-Ideen wie Selbstaufmerksamkeit und Skalierung sind faszinierend—aber Produktteams erleben sie meist als Abwägungen: wie viel Text man einspeisen kann, wie schnell die Antwort kommt und was eine Anfrage kostet.
Ein Modell oder Anbieter wählen: die vier Trade-offs
Kontextlänge: Längerer Kontext erlaubt mehr Dokumente, Chatverlauf und Anweisungen. Er erhöht aber auch Token-Kosten und kann Antworten verlangsamen. Wenn Ihr Feature "lies diese 30 Seiten und beantworte" erfordert, priorisieren Sie Kontextlänge.
Latenz: Nutzernahe Chat- und Copilot-Erfahrungen leben oder sterben an Reaktionszeiten. Streaming-Ausgaben helfen, aber Modellwahl, Region und Batching sind ebenfalls wichtig.
Kosten: Preise sind meist pro Token (Eingabe + Ausgabe). Ein Modell, das 10 % "besser" ist, kann 2–5× so teuer sein. Nutzen Sie preisähnliche Vergleiche, um zu entscheiden, welches Qualitätsniveau die Kosten wert ist.
Qualität: Definieren Sie sie für Ihren Anwendungsfall: faktische Genauigkeit, Befolgung von Anweisungen, Ton, Tool-Nutzung oder Code. Evaluieren Sie mit echten Beispielen aus Ihrer Domäne, nicht nur generischen Benchmarks.
Wann Embeddings der Generierung überlegen sind
Wenn Sie hauptsächlich Suche, Deduplizierung, Clustering, Empfehlungen oder "ähnliches finden" brauchen, sind Embeddings (oft Encoder-Modelle) in der Regel günstiger, schneller und stabiler als das Prompting eines Chatmodells. Verwenden Sie Generierung nur für den finalen Schritt (Zusammenfassungen, Erklärungen, Entwürfe) nach der Retrieval-Stufe.
Für eine tiefere Aufschlüsselung verweisen Sie Ihr Team auf einen technischen Erklärer wie /blog/embeddings-vs-generation.
Wo sich das in realen Arbeitsabläufen zeigt
Wenn Sie Transformer-Fähigkeiten in ein Produkt überführen, ist die harte Arbeit meist weniger die Architektur als vielmehr der Workflow drumherum: Prompt-Iteration, Grounding, Evaluation und sichere Bereitstellung.
Ein praktischer Weg ist die Nutzung einer vibe-coding-Plattform wie Koder.ai, um LLM-gestützte Features schneller zu prototypisieren und zu liefern: Sie können die Web-App, Backend-Endpunkte und das Datenmodell im Chat beschreiben, im Planungsmodus iterieren und dann Quellcode exportieren oder mit Hosting, Custom Domains und Rollbacks per Snapshots bereitstellen. Das ist besonders nützlich, wenn Sie Retrieval, Embeddings oder Tool-Calling-Schleifen experimentell einsetzen und enge Iterationszyklen ohne ständigen Neuaufbau derselben Infrastruktur wollen.
Eine praktische Checkliste zur Einführung
- Schreiben Sie ein einseitiges Spec: Nutzerziel, Fehlermodi und was "gut" bedeutet.
- Entscheiden Sie, was in Ihren Daten verankert werden muss (RAG, Zitationen oder Tool-Aufrufe).
- Setzen Sie Budgets für Tokens, Latenz und monatliche Ausgaben; messen Sie diese in Staging.
- Fügen Sie Sicherheitsmaßnahmen hinzu: Ablehnungen, Redaktion und "Ich weiß es nicht"-Verhalten.
- Bauen Sie Evaluation früh ein: Golden Prompts, Regressionstests und menschliche Überprüfung.
- Planen Sie Modellwechsel: Halten Sie Prompts und Routing konfigurierbar.