10. Dez. 2025·6 Min
OpenAPI aus Verhalten erzeugen mit Claude Code – ehrlich
Lerne, wie du aus Verhalten OpenAPI erzeugst mit Claude Code, es mit deiner API-Implementierung vergleichst und einfache Client- und Server-Validierungsbeispiele erstellst.
Warum OpenAPI-Verträge driften (und warum das wichtig ist)
Ein OpenAPI-Vertrag ist eine gemeinsame Beschreibung deiner API: welche Endpunkte es gibt, was du sendest, was zurückkommt und wie Fehler aussehen. Es ist die Vereinbarung zwischen dem Server und allem, was ihn aufruft (Web-App, Mobile-App oder ein anderer Dienst).
Das Problem ist Drift. Die laufende API ändert sich, aber die Spec nicht. Oder die Spec wird "aufgeräumt", damit sie schöner aussieht als die Realität, während die Implementierung weiterhin seltsame Felder zurückgibt, Statuscodes fehlen oder Fehlerformen inkonsistent sind. Mit der Zeit hören die Leute auf, der OpenAPI-Datei zu vertrauen, und sie wird nur noch ein weiteres Dokument, das alle ignorieren.
Drift entsteht meist aus normalen Zwängen: ein schneller Fix wird ausgeliefert, ohne die Spec zu aktualisieren, ein neues optionales Feld wird "vorübergehend" hinzugefügt, die Pagination entwickelt sich, oder Teams aktualisieren unterschiedliche "Quellen der Wahrheit" (Backend-Code, eine Postman-Collection und eine OpenAPI-Datei).
Ehrlichkeit bedeutet, dass die Spec dem echten Verhalten entspricht. Wenn die API manchmal 409 bei Konflikten zurückgibt, gehört das in den Vertrag. Wenn ein Feld nullable ist, sag es. Wenn Auth nötig ist, lass es nicht vage.
Ein guter Workflow liefert dir:
- Eine OpenAPI-Datei, die beabsichtigtes und beobachtetes Verhalten widerspiegelt
- Eine einfache Menge an Prüfungen, um Drift früh zu erkennen, bevor Clients kaputtgehen
- Konkrete Client- und Server-Validierungsbeispiele, die du in dein Codebase kopieren kannst
Der letzte Punkt ist wichtig, weil ein Vertrag nur hilft, wenn er durchgesetzt wird. Eine ehrliche Spec plus wiederholbare Prüfungen macht aus "API-Dokumentation" etwas, auf das Teams sich verlassen können.
Vom beabsichtigten Verhalten ausgehen, nicht vom Code
Wenn du damit beginnst, Code zu lesen oder Routen zu kopieren, wird deine OpenAPI beschreiben, was heute existiert — inklusive der Eigenheiten, die du vielleicht nicht versprechen möchtest. Beschreibe stattdessen, was die API für einen Aufrufer tun soll, und benutze die Spec, um zu prüfen, ob die Implementierung übereinstimmt.
Bevor du YAML oder JSON schreibst, sammle pro Endpoint eine kleine Menge Fakten:
- Was er tut (Methode und Pfad)
- Was er akzeptiert (Header, Query-, Path-Parameter, Body)
- Was er zurückgibt (Erfolgsstatuscode, Antwortform, wichtige Header)
- Was fehlschlagen kann (wahrscheinliche Fehler, Statuscodes, Fehler-Body-Form)
- Wer ihn aufruft (Auth und Rollen, falls relevant)
Schreibe das Verhalten dann als Beispiele. Beispiele zwingen dich, spezifisch zu sein, und machen es einfacher, einen konsistenten Vertrag zu entwerfen.
Für eine Tasks-API könnte ein Happy-Path-Beispiel lauten: „Erstelle eine Task mit title und erhalte id, title, status und createdAt zurück.“ Füge übliche Fehlerfälle hinzu: „Fehlt title, dann 400 mit {\"error\":\"title is required\"}“ und „Keine Auth gibt 401.“ Wenn du schon Randfälle kennst, nimm sie auf: ob doppelte Titel erlaubt sind und was passiert, wenn eine Task-ID nicht existiert.
Halte Regeln als einfache Sätze, die nicht von Code-Details abhängen:
- "
titleist erforderlich und 1–120 Zeichen." - "List liefert bis zu 50 Items, außer
limitist gesetzt (max 200)." - "
dueDateist ein ISO 8601 Date-Time." - "Schreib-Endpunkte benötigen ein User-Token."
Entscheide abschließend deinen v1-Scope. Wenn du unsicher bist, halte v1 klein und klar (create, read, list, update status). Suchfunktionen, Bulk-Updates und komplexe Filter später — so bleibt der Vertrag glaubwürdig.
Eine leichtgewichtige Vorlage, um Endpunkte zu beschreiben
Bevor du Claude Code bittest, ein Spec zu schreiben, notiere das Verhalten in einem kleinen, wiederholbaren Format. Ziel ist, es schwer zu machen, Lücken versehentlich mit Vermutungen zu füllen.
Eine gute Vorlage ist kurz genug, dass du sie tatsächlich benutzt, aber konsistent genug, dass zwei Personen denselben Endpoint ähnlich beschreiben würden. Konzentriere dich darauf, was die API tut, nicht wie sie implementiert ist.
Endpoint behavior note template
Use one block per endpoint:
METHOD + PATH:
Purpose (1 sentence):
Auth:
Request:
- Query:
- Headers:
- Body example (JSON):
Responses:
- 200 OK example (JSON):
- 4xx example (status + JSON):
Edge cases:
Data types (human terms):
Schreibe mindestens eine konkrete Anfrage und zwei Antworten. Einschließlich Statuscodes und realistischen JSON-Bodies mit echten Feldnamen. Wenn ein Feld optional ist, zeige ein Beispiel, in dem es fehlt.
Nenne Randfälle explizit. Das sind die Stellen, an denen Specs leise falsch werden, weil alle etwas anderes angenommen haben: leere Ergebnisse, ungültige IDs (400 vs 404), Duplikate (409 vs idempotent), Validierungsfehler und Pagination-Limits.
Notiere auch Datentypen in einfachen Worten, bevor du über Schemas nachdenkst: Strings vs Numbers, Date-Time-Formate, Booleans und Enums (Liste erlaubter Werte). Das verhindert ein „schönes" Schema, das nicht zu realen Payloads passt.
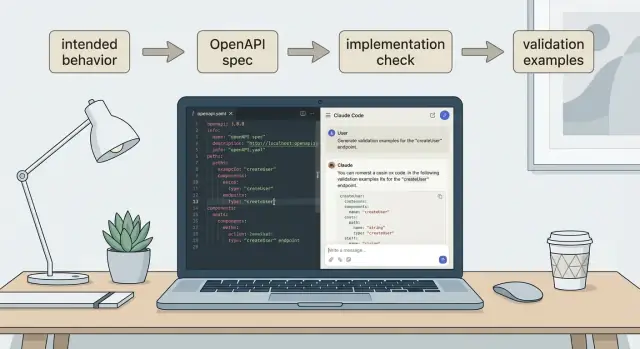
Entwirf das OpenAPI-Spec mit Claude Code (Prompting, das funktioniert)
Claude Code funktioniert am besten, wenn du ihn wie einen sorgfältigen Schreiber behandelst. Gib ihm deine Verhaltensnotizen und strenge Regeln, wie das OpenAPI aussehen soll. Wenn du nur sagst "schreibe ein OpenAPI-Spec", bekommst du meist Vermutungen, inkonsistente Namensgebung und fehlende Fehlerfälle.
Füge zuerst deine Verhaltensnotizen ein, dann einen engen Instruktionsblock. Ein praktisches Prompt sieht so aus:
You are generating an OpenAPI 3.1 YAML spec.
Source of truth: the behavior notes below. Do not invent endpoints or fields.
If anything is unclear, list it under ASSUMPTIONS and leave TODO markers in the spec.
Requirements:
- Include: info, servers (placeholder), tags, paths, components/schemas, components/securitySchemes.
- For each operation: operationId, tags, summary, description, parameters, requestBody (when needed), responses.
- Model errors consistently with a reusable Error schema and reference it in 4xx/5xx responses.
- Keep naming consistent: PascalCase schema names, lowerCamelCase fields, stable operationId pattern.
Behavior notes:
[PASTE YOUR NOTES HERE]
Output only the OpenAPI YAML, then a short ASSUMPTIONS list.
Nachdem du den Draft bekommst, scanne zuerst die ASSUMPTIONS. Dort wird Ehrlichkeit gewonnen oder verloren. Genehmige, was korrekt ist, korrigiere, was falsch ist, und führe den Lauf mit aktualisierten Notizen erneut aus.
Um Namensgebung konsistent zu halten, nenne Konventionen vorab und halte dich daran. Beispielsweise ein stabiles operationId-Muster, Tag-Namen nur als Substantive, singular Schema-Namen, ein gemeinsames Error-Schema und ein Auth-Schema-Name, der überall verwendet wird.
Wenn du in einem vibe-coding Workspace wie Koder.ai arbeitest, hilft es, die YAML-Datei früh als echte Datei zu speichern und in kleinen Diffs zu iterieren. So siehst du, welche Änderungen aus genehmigten Verhaltensentscheidungen stammen und welche das Modell geraten hat.
Validiere die Spec, bevor du sie mit der laufenden API vergleichst
Schneller deployen und testen
Deploye und hoste deine API zusammen mit der App, damit Teams den Vertrag End-to-End testen können.
Bevor du irgendetwas mit Production vergleichst, stelle sicher, dass die OpenAPI-Datei intern konsistent ist. Das ist der schnellste Ort, um Wunschdenken und vage Formulierungen zu finden.
Lies jeden Endpoint so, als wärst du Client-Entwickler. Konzentriere dich darauf, was ein Aufrufer senden muss und worauf er sich verlassen kann.
Ein praktischer Review-Check:
- Required vs optional: markiere Pflichtfelder korrekt und vermeide "alles optional".
- Typen und Formate: sei explizit bei UUIDs, Emails, Date-Time, min/max-Werten.
- Beispiele: Füge pro Endpoint mindestens ein realistisches Request- und Response-Beispiel hinzu und halte Beispiele mit Schemas synchron.
- Statuscodes: Richte dich nach den Verhaltensnotizen (create ist oft 201, nicht 200). Entscheide 400 vs 422 und sei konsistent.
- Auth: Gib an, was pro Endpoint erforderlich ist und ob Rollen den Zugang beeinflussen.
Fehlerantworten verdienen besondere Aufmerksamkeit. Wähle eine gemeinsame Form und verwende sie überall. Manche Teams halten es sehr simpel ({ error: string }), andere nutzen ein Objekt ({ error: { code, message, details } }). Beides kann funktionieren, aber mische die Formen nicht über Endpunkte hinweg, da Client-Code sonst Sonderfälle anhäuft.
Ein kurzer Szenario-Check hilft: Wenn POST /tasks title verlangt, sollte das Schema es als required markieren, die Fehlerantwort zeigen, wie der Fehlerkörper tatsächlich aussieht, und die Operation klarstellen, ob Auth nötig ist.
Vergleiche die Spec mit der laufenden API-Implementation
Sobald die Spec wie beabsichtigt liest, behandle die laufende API als die Wahrheit dessen, was Clients heute erleben. Ziel ist nicht, zwischen Spec und Code zu "gewinnen", sondern Unterschiede früh zu entdecken und für jeden eine klare Entscheidung zu treffen.
Für den ersten Durchlauf sind echte Request-/Response-Beispiele oft die einfachste Option. Logs und automatisierte Tests funktionieren auch, wenn sie zuverlässig sind.
Achte auf typische Abweichungen: Endpunkte, die an einer Stelle existieren, an einer anderen nicht; Unterschiede in Feldnamen oder Formen; Statuscode-Abweichungen (200 vs 201, 400 vs 422); undokumentiertes Verhalten (Pagination, Sortierung, Filter) und Auth-Unterschiede (Spec sagt public, Code verlangt Token).
Beispiel: Dein OpenAPI sagt POST /tasks gibt 201 mit {id,title} zurück. Du rufst die laufende API auf und bekommst 200 plus {id,title,createdAt}. Das ist nicht "nah genug", wenn du Client-SDKs aus dem Spec generierst.
Bevor du etwas änderst, entscheide, wie du Konflikte löst:
- Wenn das Verhalten korrekt, aber undokumentiert ist: Spec korrigieren.
- Wenn die Spec der vereinbarte Vertrag ist: Code anpassen.
- Wenn beides nicht stimmt: Passe zuerst das beabsichtigte Verhalten an, und aktualisiere dann beides.
Halte jede Änderung klein und reviewbar: ein Endpoint, eine Antwort, eine Schema-Änderung. So ist es einfacher zu reviewen und nachzutesten.
Erzeuge Client- und Server-Validierungsbeispiele aus dem Vertrag
Wenn du eine Spec hast, der du vertraust, verwandle sie in kleine Validierungsbeispiele. Das ist, was verhindert, dass Drift wieder einschleicht.
Serverseitige Validierung (ungerechte Anfragen ablehnen)
Auf dem Server bedeutet Validierung: schnell fehlschlagen, wenn ein Request nicht dem Vertrag entspricht, und einen klaren Fehler zurückgeben. Das schützt deine Daten und macht Bugs leichter auffindbar.
Eine einfache Art, serverseitige Validierungsbeispiele darzustellen, ist sie als Cases mit drei Teilen zu schreiben: Input, erwartete Ausgabe und erwarteter Fehler (ein Error-Code oder Nachrichtenmuster, nicht exakter Text).
Beispiel (Vertrag sagt title ist required und 1 bis 120 Zeichen):
{
"name": "Create task without title returns 400",
"request": {"method": "POST", "path": "/tasks", "body": {"title": ""}},
"expect": {"status": 400, "body": {"error": {"code": "VALIDATION_ERROR"}}}
}
Client-seitige Validierung (brechende Änderungen früh erkennen)
Auf dem Client geht es darum, Drift zu erkennen, bevor Nutzer betroffen sind. Wenn der Server eine andere Form zurückgibt oder ein erforderliches Feld verschwindet, sollten Tests das melden.
Halte Client-Checks auf das beschränkt, worauf du dich wirklich verlässt, z. B. "eine Task hat id, title, status". Vermeide, jedes optionale Feld oder genaue Reihenfolgen zu prüfen. Du willst Fehler bei Breaking Changes, nicht bei harmlosen Ergänzungen.
Einige Richtlinien, damit Tests lesbar bleiben:
- Prüfe lieber Präsenz und Typ statt exakte Werte.
- Assertiere nur Pflichtfelder, außer ein optionales Feld ist für dein Feature kritisch.
- Bei Fehlern prüfe Status und einen Error-Code, nicht komplette Nachrichten.
- Erlaube zusätzliche Felder, außer der Vertrag verbietet sie explizit.
Wenn du mit Koder.ai arbeitest, kannst du diese Beispiel-Cases neben deiner OpenAPI-Datei speichern und als Teil desselben Reviews aktualisieren, wenn sich Verhalten ändert.
Beispiel-Szenario: eine einfache Tasks-API End-to-End
Baue deine API im Chat
Erstelle ein Web- plus API-Projekt aus dem Chat und iteriere an Endpunkten, während sich der Vertrag entwickelt.
Stell dir eine kleine API mit drei Endpunkten vor: POST /tasks erstellt eine Aufgabe, GET /tasks listet Aufgaben, und GET /tasks/{id} gibt eine Aufgabe zurück.
Beginne, indem du ein paar konkrete Beispiele für einen Endpoint schreibst, als würdest du es einem Tester erklären.
Für POST /tasks könnte beabsichtigtes Verhalten sein:
- Erfolg: sende
{ "title": "Buy milk" }und erhalte 201 mit einem neuen Task-Objekt, inklusiveid,titleunddone:false. - Fehler 1: sende
{}und erhalte 400 mit einem Fehler wie{ "error": "title is required" }. - Fehler 2: sende
{ "title": "x" }(zu kurz) und erhalte 422 mit{ "error": "title must be at least 3 characters" }.
Wenn Claude Code das OpenAPI entwirft, sollte der Ausschnitt für diesen Endpoint Schema, Statuscodes und realistische Beispiele erfassen:
paths:
/tasks:
post:
summary: Create a task
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/CreateTaskRequest'
examples:
ok:
value: { "title": "Buy milk" }
responses:
'201':
description: Created
content:
application/json:
schema:
$ref: '#/components/schemas/Task'
examples:
created:
value: { "id": "t_123", "title": "Buy milk", "done": false }
'400':
description: Bad Request
content:
application/json:
schema:
$ref: '#/components/schemas/Error'
examples:
missingTitle:
value: { "error": "title is required" }
'422':
description: Unprocessable Entity
content:
application/json:
schema:
$ref: '#/components/schemas/Error'
examples:
tooShort:
value: { "error": "title must be at least 3 characters" }
Eine häufige Abweichung ist subtil: Die laufende API liefert 200 statt 201, oder sie liefert { "taskId": 123 } statt { "id": "t_123" }. Das sind "fast gleich"-Unterschiede, die generierte Clients brechen.
Behebe das, indem du eine Wahrheit wählst. Wenn das beabsichtigte Verhalten korrekt ist, ändere die Implementierung so, dass sie 201 und die vereinbarte Task-Form zurückgibt. Wenn das Produktionsverhalten bereits genutzt wird, aktualisiere die Spec (und die Verhaltensnotizen), um die Realität abzubilden, und füge fehlende Validierungen und Fehlerantworten hinzu, damit Clients nicht überrascht werden.
Häufige Fehler, die einen Vertrag unehrlich machen
Ein Vertrag wird unehrlich, wenn er aufhört, Regeln zu beschreiben und stattdessen das dokumentiert, was deine API an einem guten Tag zurückgegeben hat. Ein einfacher Test: Könnte eine neue Implementierung diesen Spec bestehen, ohne heutige Eigenheiten zu kopieren?
Eine Falle ist Overfitting. Du nimmst eine einzige Antwort und machst sie zur Regel. Beispiel: Deine API gibt aktuell dueDate: null für jede Aufgabe zurück, also sagt die Spec, das Feld sei immer nullable. Die echte Regel könnte aber sein: "required, wenn status scheduled ist." Der Vertrag sollte die Regel ausdrücken, nicht nur den aktuellen Datensatz.
Fehler sind ein typischer Ort, an dem Ehrlichkeit bricht. Es ist verlockend, nur Erfolgsantworten zu spezifizieren, weil sie sauber aussehen. Clients brauchen aber die Basics: 401, wenn das Token fehlt, 403 für verbotenen Zugang, 404 für unbekannte IDs und eine konsistente Validierungsantwort (400 oder 422).
Weitere Muster, die Probleme verursachen:
- Namen und Typen drift across Endpoints (
taskIdin einer Route,idin einer anderen, oderprioritymal als String, mal als Number). - Beispiele widersprechen Schemas (Enum-Werte passen nicht, Date-Time-Beispiele sind nicht ISO 8601).
- Typen werden zu breit gemacht, um Entscheidungen zu vermeiden (alles wird
string, alles wird optional). - Die Spec liest sich wie Marketing ("schnell", "sicher") statt wie ein testbarer Vertrag.
Ein guter Vertrag ist testbar. Wenn du keinen fehlschlagenden Test aus der Spec schreiben kannst, ist sie noch nicht ehrlich.
Schnelle Checks, bevor du die OpenAPI-Datei teilst oder veröffentlichst
Plane den Vertrag zuerst
Nutze den Planungsmodus, um Eingaben, Ausgaben und Fehlerfälle zu entscheiden, bevor Code generiert wird.
Bevor du die OpenAPI-Datei an ein anderes Team gibst (oder in Docs einfügst), mache einen Schnellcheck: Kann jemand sie benutzen, ohne deine Gedanken lesen zu müssen?
Beginne mit Beispielen. Eine Spec kann gültig, aber dennoch nutzlos sein, wenn jede Anfrage und Antwort abstrakt ist. Für jede Operation: mindestens ein realistisches Request-Beispiel und ein Erfolgs-Response-Beispiel. Für Fehler: ein Beispiel pro häufigem Fehler (Auth, Validierung) reicht meistens.
Prüfe dann Konsistenz. Wenn ein Endpoint { "error": "..." } zurückgibt und ein anderer { "message": "..." }, bekommen Clients überall verzweigte Logik. Wähle eine einzige Fehlerform und benutze sie überall sowie vorhersehbare Statuscodes.
Eine kurze Checkliste:
- Pflichtfelder, Formate (email, uuid, date-time) und Enums sind explizit.
- Statuscodes sind absichtlich und konsistent über ähnliche Endpunkte.
- Fehlerantworten enthalten Schema und Beispiele, nicht nur einen Status.
- Du machst 2–3 echte Calls pro Endpoint (Tests, curl, Postman oder Logs) und vergleichst Payloads mit der Spec.
- Du kannst einen kleinen Client-Call allein aus der Spec schreiben, ohne Header, Feldnamen oder Nullbarkeit zu raten.
Ein praktischer Trick: Wähle einen Endpoint, tu so, als hättest du die API nie gesehen, und beantworte: "Was sende ich, was bekomme ich zurück und was bricht?" Wenn die OpenAPI das nicht klar beantwortet, ist sie noch nicht bereit.
Nächste Schritte: Mach es zur Gewohnheit (und halte Änderungen sicher)
Dieser Workflow zahlt sich aus, wenn er regelmäßig läuft, nicht nur während eines Release-Stresses. Wähle eine einfache Regel und bleibe dabei: Führe den Ablauf aus, wenn ein Endpoint sich ändert, und erneut bevor du eine aktualisierte Spec veröffentlichst.
Halte Ownership einfach. Die Person, die einen Endpoint ändert, aktualisiert die Verhaltensnotizen und den Spec-Entwurf. Eine zweite Person reviewt den "Spec vs Implementation"-Diff wie einen Code-Review. QA- oder Support-Kollegen sind oft gute Reviewer, weil sie unklare Antworten und Randfälle schnell bemerken.
Behandle Vertrags-Edits wie Code-Edits. Wenn du ein Chat-getriebenes Builder-Tool wie Koder.ai nutzt, hilft ein Snapshot vor riskanten Änderungen und Rollback bei Bedarf, um Iteration sicher zu halten. Koder.ai unterstützt auch den Export von Quellcode, was es erleichtert, Spec und Implementierung nebeneinander im Repo zu halten.
Eine Routine, die meist funktioniert, ohne Teams zu bremsen:
- Schreibe Verhaltensnotizen, wenn du einen neuen Endpoint hinzufügst
- Validere die Spec und führe Contract-Tests vor dem Merge aus
- Vergleiche die Spec mit der laufenden API vor dem Release
- Erstelle Snapshots vor riskanten Änderungen; rolle zurück, wenn der Diff verwirrend wird
Nächste Aktion: Wähle einen Endpoint, der bereits existiert. Schreibe 5–10 Zeilen Verhaltensnotizen (Inputs, Outputs, Fehlerfälle), generiere ein Draft-OpenAPI daraus, validiere es, vergleiche es mit der laufenden Implementierung. Behebe eine Abweichung, teste erneut und wiederhole. Nach einem Endpoint bleibt die Gewohnheit meist erhalten.
FAQ
What does “OpenAPI drift” mean in plain terms?
OpenAPI-Drift ist, wenn die API, die tatsächlich läuft, nicht mehr mit der OpenAPI-Datei übereinstimmt, die geteilt wird. Die Spec kann neue Felder, Statuscodes oder Auth-Regeln vermissen oder ein "ideales" Verhalten beschreiben, dem der Server nicht folgt.
Das ist wichtig, weil Clients (Apps, andere Dienste, generierte SDKs, Tests) Entscheidungen auf Basis des Vertrags treffen, nicht auf Basis dessen, was dein Server "gewöhnlich" macht.
What are the most common ways drift shows up for client teams?
Client-Fehler werden zufällig und schwer zu debuggen: Eine mobile App erwartet 201, bekommt aber 200, ein SDK kann eine Antwort nicht deserialisieren, weil ein Feld umbenannt wurde, oder Fehlerbehandlung versagt, weil sich die Error-Form ändert.
Selbst wenn nichts abstürzt, verlieren Teams das Vertrauen in die Spec und hören auf, sie zu benutzen – dadurch geht dein Frühwarnsystem verloren.
Why shouldn’t I start the OpenAPI spec by copying backend code?
Weil Code das aktuelle Verhalten widerspiegelt, inklusive ungewollter Eigenheiten, die du langfristig vielleicht nicht versprechen willst.
Besser ist: Beschreibe zuerst das beabsichtigte Verhalten (Eingaben, Ausgaben, Fehler) und verifiziere dann, dass die Implementierung dazu passt. So erhältst du einen Vertrag, den du durchsetzen kannst, statt nur einen Schnappschuss der heutigen Routen.
What’s the minimum “behavior notes” I should write per endpoint?
Für jeden Endpoint erfasse:
- Purpose: eine Ein-Satz-Beschreibung, was er macht
- Auth: benötigter Token/Rollen oder öffentlich
- Request: Query-/Path-Parameter, Header und ein JSON-Body-Beispiel
- : mindestens ein Erfolgsbeispiel und ein oder zwei realistische Fehlerbeispiele mit Statuscodes
How do I keep error responses consistent across the whole spec?
Wähle eine Error-Body-Form und verwende sie überall wieder.
Eine einfache Standardwahl ist entweder:
{ "error": "message" }, oder{ "error": { "code": "...", "message": "...", "details": ... } }
Mache das über alle Endpunkte und Beispiele hinweg konsistent. Konsistenz ist wichtiger als Komplexität, weil Clients diese Form hartkodieren werden.
How can I prompt Claude Code so it doesn’t make up endpoints or fields?
Gib Claude Code deine Verhaltensnotizen und strikte Regeln und sag ihm, nichts zu erfinden. Eine praktische Anweisung:
- "Source of truth is the behavior notes. Do not guess."
- "If unclear, add
TODOin the spec and list it under ASSUMPTIONS." - "Include reusable schemas (like
Error) and reference them." - "Use consistent naming (PascalCase schemas, lowerCamelCase fields)."
Nach der Generierung prüfe zuerst die – dort beginnt Drift, wenn du Vermutungen akzeptierst.
What should I check in the OpenAPI file before I compare it to the running API?
Prüfe die Spec zuerst selbst:
- Required vs optional Felder sind korrekt markiert
- Formate sind explizit (UUID, Email, ISO 8601 date-time)
- Beispiele stimmen mit Schemas überein (Enums, Typen, Nullbarkeit)
- Statuscodes sind bewusst gewählt und konsistent (z. B. Create oft
201) - Auth-Anforderungen sind pro Endpoint angegeben
So findest du Wunschdenken, bevor du Production vergleichst.
When the spec and the running API disagree, which one should I change?
Behandle die laufende API als das, was Benutzer heute erleben, und entscheide Fall für Fall:
- Wenn das Verhalten korrekt, aber undokumentiert ist: Spec aktualisieren
- Wenn die Spec der vereinbarte Vertrag ist: Code anpassen
- Wenn beides nicht stimmt: Zuerst beabsichtigtes Verhalten ändern, dann beides aktualisieren
Halte Änderungen klein (ein Endpoint oder eine Antwort), damit du schnell retesten kannst.
What do “server-side” vs “client-side” contract validation checks look like?
Serverseitige Validierung: Lehnt Requests ab, die den Vertrag verletzen, und liefert klare, konsistente Fehler (Status + Error-Code/-Form).
Clientseitige Validierung: Erkennt Breaking Changes früh, indem nur das geprüft wird, worauf die Clients sich wirklich verlassen:
- Pflichtfelder sind vorhanden und haben richtige Typen
- Statuscodes stimmen mit erwarteten Flows überein
- Fehlerantworten haben die vereinbarte Form
Vermeide, jeden optionalen Feldwert zu prüfen, damit Tests auf echte Brüche und nicht auf harmlose Ergänzungen reagieren.
What’s a simple habit to prevent drift from coming back?
Eine praktische Routine:
- Verhaltensnotizen und Spec aktualisieren, wenn ein Endpoint sich ändert
- OpenAPI-Datei validieren (Schemas, Beispiele, Statuscodes, Auth)
- Einige echte Request/Response-Beispiele gegen die Spec vergleichen vor dem Release
- Kleine Vertragsprüfungen in Tests hinzufügen, damit Drift automatisch auffällt
Wenn du mit Koder.ai arbeitest, kannst du die OpenAPI-Datei neben dem Code halten, Snapshots vor riskanten Änderungen erstellen und bei Bedarf zurückrollen.